对于给定的机器学习问题,应该使用哪种算法?
这是应用机器学习的挑战。这个问题没有快速的答案,但有一个可靠的过程供您使用。
在这篇文章中,您将了解如何通过直接在 Weka 中比较它们来为数据集找到好的甚至最好的机器学习算法。
阅读本文后,您将了解
- 发现好的甚至最好的机器学习算法以解决问题的过程。
- 如何在 Weka 中设计实验以比较不同机器学习算法的性能。
- 如何分析 Weka 实验结果。
开始您的项目,阅读我的新书《Weka 机器学习精通》,其中包含分步教程和所有示例的清晰屏幕截图。
让我们开始吧。

如何在 Weka 中比较机器学习算法的性能
照片来源:Clark H,部分权利保留。
解决问题的最佳机器学习算法
应用机器学习中最常见的问题是
什么算法最适合我的问题?
答案是无法提前知道的。如果您对问题有足够的了解,知道哪种算法最好,您就不需要使用机器学习了。您只需解决您的问题。
机器学习技术适用于那些必须从数据中学习解决方案的难题。传统技术无法在此类问题中得到应用。
关于选择算法,有很多经验法则。例如,如果一个算法期望数据具有特定的分布,而您的数据具有该分布,那么该算法可能适合您的问题。这存在两个问题:
- 许多算法可能期望满足您的问题,因此它们是适合的。
- 有时,即使算法的期望被违反,也能取得良好甚至最佳的结果。
经验法则适合作为起点,但不应作为选择算法的最终依据。
您问题的最佳机器学习算法是通过经验发现的。通过试错。
这是通过在您的问题上评估一系列截然不同的算法来完成的,找到有效的算法,然后重点关注那 2-3 种显示出潜力的算法。我称这种方法为“抽查”。
过程如下:
- 设计一个测试框架,包括训练数据集、任何数据预处理以及测试选项,例如 10 折交叉验证。
- 为了获得额外分数,请使用数据集的不同视图或表示形式重复实验。这将有助于最佳地暴露算法可以接收到的问题结构。
- 选择一系列具有不同算法假设的多元算法,例如线性模型、树模型、基于实例的方法、概率模型、神经网络等。
- 为了获得额外分数,让每种算法都发挥出最佳水平,包括每种算法的不同常用配置方案的变体。
- 在您的训练数据集上评估算法系列。
- 分析结果,并确定 2-3 种不同的算法进行进一步研究。
这个过程将始终引导您找到在您的机器学习问题上表现良好的算法。实际上,您只需要一个在可用时间内尽可能表现良好的模型。
找到您问题的最佳模型取决于您愿意投入多少时间尝试不同的算法以及调整表现良好的算法。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
在 Weka 中比较算法性能
您可以使用 Weka 的实验环境对您的问题进行机器学习算法的抽查。
在本教程中,您将设计、运行和分析您的第一个机器学习实验。
我们将使用 Pima 印第安人糖尿病发病数据集。每个实例代表一位患者的医疗详情,任务是预测该患者在未来五年内是否会患上糖尿病。有 8 个数值输入变量,它们的尺度各不相同。
最佳结果的准确率约为77%。
我们将在原始数据集上评估 5 种不同的机器学习算法。
- 逻辑回归 (Logistic)
- 朴素贝叶斯 (NaiveBayes)
- 分类和回归树或 CART (REPTree)
- k-最近邻或 KNN (IBk)
- 支持向量机或 SVM (SMO)
每种算法将使用默认算法配置进行评估。您自己可以调查的这个实验的自然扩展包括:
- 创建数据集的多个不同视图来评估算法,例如归一化、标准化等。
- 向算法系列中添加更多算法以进行评估。
- 为每种算法添加更多常用或标准算法配置的变体。
本教程分为3个部分:
- 设计实验。
- 运行实验。
- 审查实验结果。
1. 设计实验
Weka 实验环境是一个工具,可用于对数据集运行受控的机器学习算法实验。
Weka 实验环境允许您定义一个或多个要处理的数据集以及一个或多个要在数据集上工作的算法。然后,您可以运行并监控实验。最后,所有结果都会被收集并呈现供您分析。
在本节中,我们将定义一个涉及 Pima 印第安人糖尿病发病数据集、10 折交叉验证(默认)和 5 种常见分类算法的实验。
每种算法将在数据集上评估 10 次(10 次 10 折交叉验证),使用不同的随机数种子。这将为每种评估的算法产生 10 个略有不同的结果,一个我们可以稍后使用统计方法解释的小样本。
1. 打开 Weka GUI Chooser。
Weka GUI 选择器
2. 点击“Experimenter”按钮打开 Weka Experimenter 界面。
Weka 实验环境设置选项卡
3. 在“Setup”选项卡上,点击“New”按钮开始新实验。
4. 在“Dataset”面板中,点击“Add new…”按钮并选择 *data/diabetes.arff*。
5. 在“Algorithms”面板中,点击“Add new…”按钮,点击“Choose”按钮,然后选择“functions”组下的“Logistic”算法。点击“OK”按钮添加。
重复并添加以下 4 种额外算法:
- “bayes”组下的 NaiveBayes。
- “trees”组下的 REPTree。
- “lazy”组下的 IBk。
- “functions”组下的 SMO。
您可以通过点击“Setup”面板顶部的“Save”按钮来保存此实验定义。如果您想在未来创建实验的新变体,这将非常有用。您可以使用“Open”按钮加载定义。
最后,您可以将实验结果保存到 ARFF 文件。如果您想稍后加载和分析结果,这将非常有用。您可以在“Results Destination”面板中指定用于保存实验结果的文件。
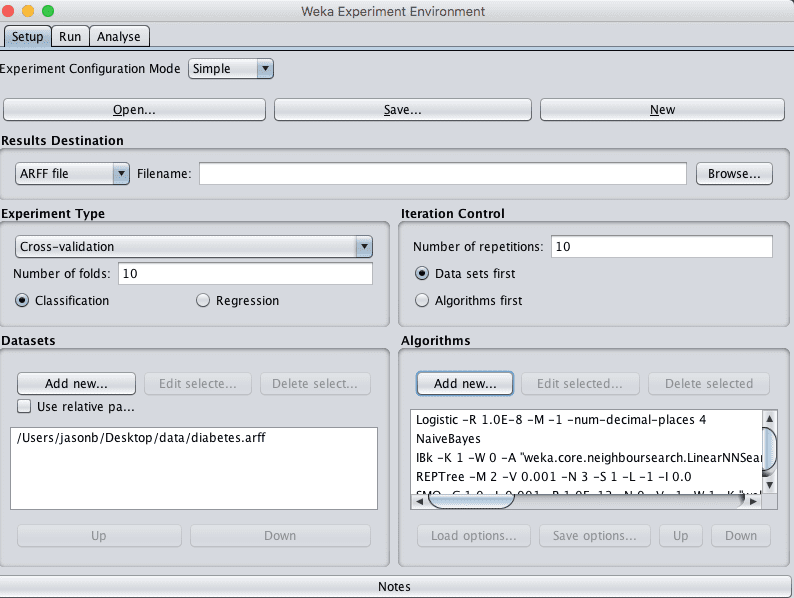
Weka 实验环境已配置的实验
2. 运行实验
现在是时候运行实验了。
1. 点击“Run”选项卡。
这里有几个选项。您能做的就是启动实验或停止正在运行的实验。
2. 点击“start”按钮运行实验。它应该在几秒钟内完成。这是因为数据集很小。
Weka 实验环境运行实验
3. 审查实验结果
Weka 实验环境的第三个面板用于分析实验结果。
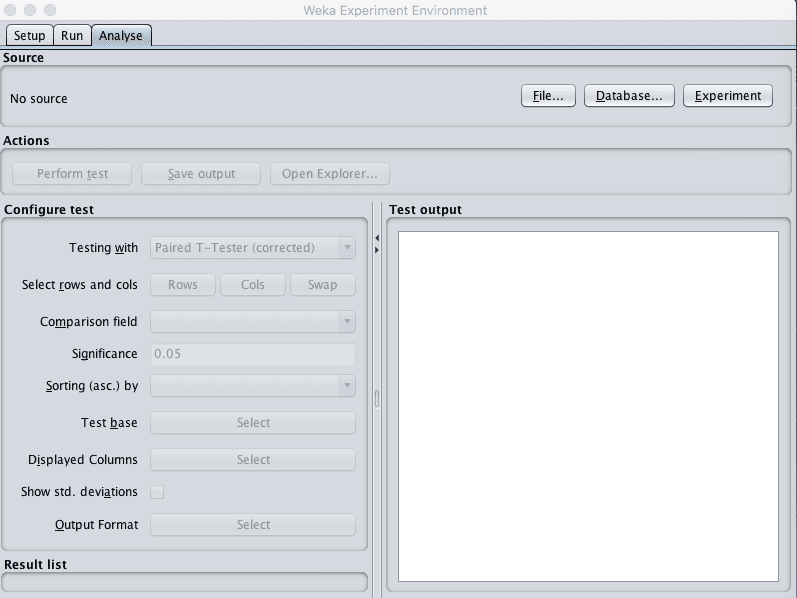
Weka 实验环境分析选项卡
您可以从以下位置加载结果:
- 文件,如果您在“Setup”选项卡上配置您的实验将结果保存到文件。
- 数据库,如果您在“Setup”选项卡上配置您的实验将结果保存到数据库。
- 实验,如果您刚刚在实验环境中运行了实验(我们刚刚完成了)。
通过点击“Source”面板中的“Experiment”按钮加载我们刚刚执行的实验结果。
您会看到加载了 500 个结果。这是因为我们有 5 种算法,每种算法都评估了 100 次,10 折交叉验证乘以 10 次重复。
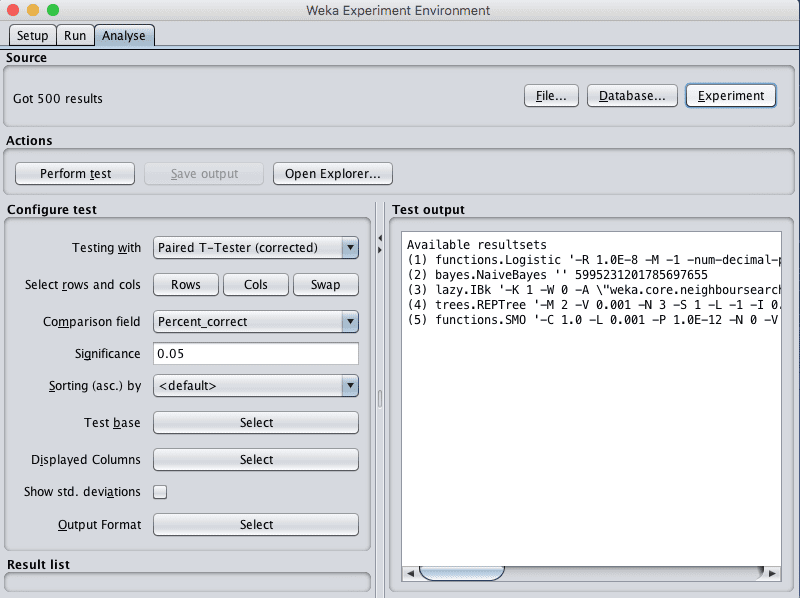
Weka 实验环境加载结果
收集了许多不同的性能指标的结果,例如分类准确率。
实验环境允许我们对不同的性能指标进行统计检验,以便我们能够从实验中得出结论。
例如,我们对实验中的两个问题感兴趣:
- 实验中评估的哪种算法性能最佳?如果您想立即创建一个性能良好的模型,了解这一点很有用。
- 算法的性能排名是什么?如果您想进一步研究和调整在问题上表现最佳的 2-3 种算法,了解这一点很有用。
我们可以在“Configure test”面板中配置结果摘要的显示方式。
“Testing with”选项可以选择统计检验的类型,默认设置为“Paired T-Tester (corrected)”。这就可以了,它将成对比较每种算法,并对收集结果的分布做出一些合理的假设,例如它们是从高斯分布中提取的。“Significance”参数设置显着性水平,默认为 0.05(5%),这同样是可以的。
我们不需要纠缠于统计显著性检验的技术细节。这些有用的默认设置将告知我们,我们审查的任何成对算法性能比较之间的差异是否具有统计学意义,置信度为 95%。
我们可以在“Comparison field”选项中选择用于比较算法的性能指标。默认是“Percent_correct”指标(准确率),这正是我们在第一步中感兴趣的。
我们可以将所有算法结果与一个基本结果进行比较。这可以通过“Test base”选项指定。默认是列表中评估的第一个算法,在本例中是逻辑回归。通过点击“Test base”旁边的“Select”按钮,我们可以看到这一点。
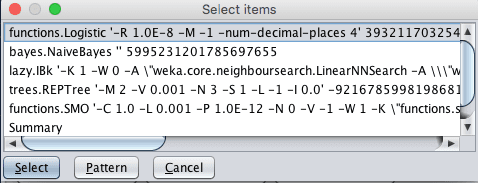
Weka 实验环境测试基准
点击“Actions”面板中的“Perform test”按钮执行统计检验并生成一些可供审查的输出。您应该会看到类似下面列出的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Tester: weka.experiment.PairedCorrectedTTester -G 4,5,6 -D 1 -R 2 -S 0.05 -result-matrix "weka.experiment.ResultMatrixPlainText -mean-prec 2 -stddev-prec 2 -col-name-width 0 -row-name-width 25 -mean-width 0 -stddev-width 0 -sig-width 0 -count-width 5 -print-col-names -print-row-names -enum-col-names" 分析: Percent_correct 数据集: 1 Resultsets: 5 置信度: 0.05 (双尾) 排序方式: - Date: 8/06/16 8:41 AM Dataset (1) functions | (2) bayes (3) lazy. (4) trees (5) funct -------------------------------------------------------------------------------- pima_diabetes (100) 77.47 | 75.75 70.62 * 74.46 * 76.80 -------------------------------------------------------------------------------- (v/ /*) | (0/1/0) (0/0/1) (0/0/1) (0/1/0) 键 (1) functions.Logistic '-R 1.0E-8 -M -1 -num-decimal-places 4' 3932117032546553727 (2) bayes.NaiveBayes '' 5995231201785697655 (3) lazy.IBk '-K 1 -W 0 -A \"weka.core.neighboursearch.LinearNNSearch -A \\\"weka.core.EuclideanDistance -R first-last\\\"\"' -3080186098777067172 (4) trees.REPTree '-M 2 -V 0.001 -N 3 -S 1 -L -1 -I 0.0' -9216785998198681299 (5) functions.SMO '-C 1.0 -L 0.001 -P 1.0E-12 -N 0 -V -1 -W 1 -K \"functions.supportVector.PolyKernel -E 1.0 -C 250007\" -calibrator \"functions.Logistic -R 1.0E-8 -M -1 -num-decimal-places 4\"' -6585883636378691736 |
我们可以看到,逻辑回归(我们的比较基准,标记为(1))在该问题上的准确率为 77.47%。此结果与其他 4 种算法进行了比较,并用数字表示,并在表格下方图例中进行了映射。
请注意 IBk 和 REPTree 结果旁边的“*”。这表明结果与逻辑回归结果有显着差异,但得分较低。NaiveBayes 和 SMO 的结果旁边没有任何字符,这表明结果与逻辑回归没有显着差异。如果一种算法的结果大于基准算法且差异显着,则结果旁边会出现一个小的“v”。
如果我们必须立即构建模型,我们可能会选择逻辑回归,但也可能选择朴素贝叶斯或 SMO,因为它们的结果没有显着差异。逻辑回归是一个不错的选择,因为它简单、易于理解且训练速度快。
我们可能不会选择 IBk 或决策树,至少不会选择它们的默认配置,因为我们知道逻辑回归可以做得更好,而且该结果具有统计学意义。
使用 Weka 实验进行错误调试
运行实验时有时会遇到错误。
“Run”选项卡中的日志将报告“there was 1 error”,但没有更多信息。
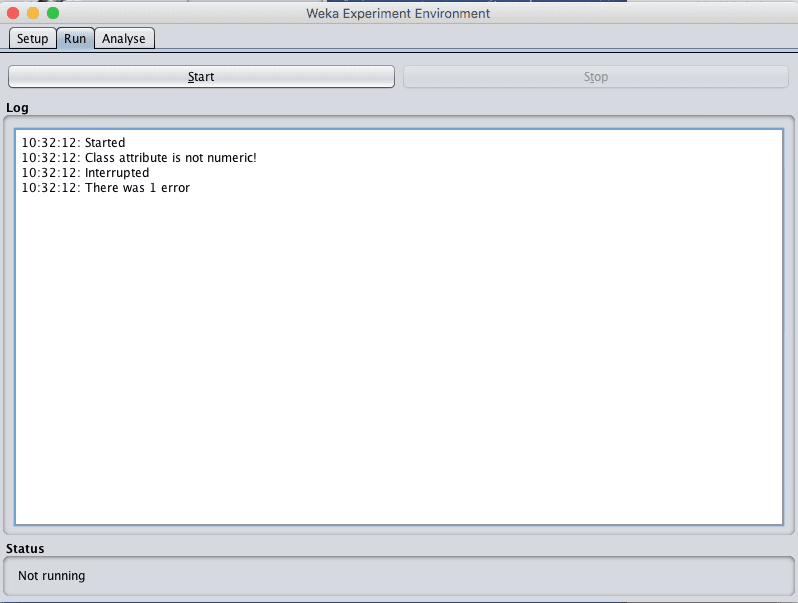
Weka 实验错误
通过查看 Weka 日志,可以轻松找出出了什么问题。
在 Weka GUI Chooser 中,点击“Program”菜单和“LogMenu”。
Weka 打开日志
这将打开 Weka 日志。
从上到下滚动日志,查找与您的实验相对应的错误。它可能是日志中的最后一个错误(在底部)。
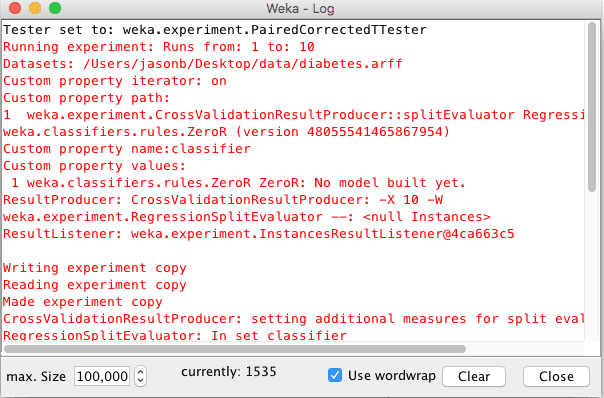
Weka 日志窗口
通常,实验错误会由以下两种原因之一引起:
- 您在 Weka Experimenter 的“Setup”选项卡上的“Experiment Type”面板中选择了错误的问类型。例如,您的问题可能是“Regression”类型问题,但您选择了“Classification”。
- 您在 Weka Experimenter 的“Setup”选项卡上的“Algorithms”面板中将错误类型的算法添加到实验中。例如,您可能将仅支持回归的算法(如 LinearRegression)添加到了分类类型问题中。
在查看 Weka 日志中的错误时,请注意可能表明上述问题类型的消息。
总结
在这篇文章中,您了解了如何为您的数据问题找到好的甚至最佳的机器学习算法。
具体来说,你学到了
- 一个通过抽查一系列不同的算法来解决问题,从而找到一组表现良好的算法以进行进一步研究的过程。
- 如何设计和运行实验以比较机器学习算法在数据集上的性能。
- 如何解释机器学习实验的结果,以回答关于您的问题。
您对比较您的数据集上的机器学习算法性能或对本文有任何疑问吗?在评论中提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






谢谢。这很有帮助
我很高兴听到 cautree。
嗨,Jason,
我尝试使用 weka 实验器比较 XGBoost、Random Forest 和 M5P 回归分类器。奇怪的是,实验器的结果显示 MRL 获胜,但当我尝试使用与我用于实验器相同的训练数据训练 XGBoost 时,与 Random Forest 和 M5P 相比,它显示出更糟糕的平均绝对误差和相对绝对误差。有什么想法为什么会这样?这似乎有悖常理。我是这方面的新手。
2 2 0 mlr.MLRClassifier ‘-learner regr.xgboost -params \”nrounds = 1000, nthread = 4\” -batch 100 -S 1’ -5715911392187197733
0 1 1 trees.M5P ‘-M 4.0’ -6118439039768244417
-2 0 2 trees.RandomForest ‘-P 100 -I 100 -num-slots 1 -K 0 -M 1.0 -V 0.001 -S 1’ 1116839470751428698
结果取决于许多因素,例如特定问题、数据准备和算法配置。
没有最好的算法
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
在实践中,我发现 xgboost 在各种问题上都表现得非常好。但不总是最好的。
嗨,在我的项目中,我需要比较三种不同的算法,是否正确,如果我只使用 Weka 中的默认参数来比较这三种不同的算法,以选择哪种算法是最合适的模型?
这是一种方法,尽管最好让每种算法都有很好的机会表现良好。
非常感谢您提供的清晰教程。很感激。
您有个人邮箱可以与您保持联系并询问一些问题吗?
谢谢你
您(以及任何读者)可以随时通过以下方式联系我:
https://machinelearning.org.cn/contact
我是日本人。我的英语不好,但我能理解您的课程。谢谢。
谢谢,很高兴对您有帮助。
我是越南人。我的英语不好。但我想问一个问题。Weka 的性能结果比 Python 中的许多算法都好。为什么?
很好的问题!
平均而言,没有更好或更坏,只是不同 - 平均而言。
不同的实现会产生不同的结果。这可能会令人沮丧。
谢谢。这非常有帮助。
不客气。
继续努力。
感谢您的反馈 Rosrja!
这非常有帮助…❤️????????
我们感谢您的反馈 Ralilo,并祝您在机器学习之旅中一切顺利!
我非常感激……我也为我得到的答案表示感谢❤️????
感谢您的支持 Ralilo!我们非常感谢!
如何引用本文档……我需要引用我的工作
你好 Ralilo…
如果你在自己的项目中使用我的代码或材料,请注明来源,包括
作者姓名,例如“Jason Brownlee”。
教程或书籍的标题。
网站名称,例如“Machine Learning Mastery”。
教程或书籍的 URL。
您访问或复制该代码的日期。
例如
Jason Brownlee,Python 中的机器学习算法,Machine Learning Mastery,来源:https://machinelearning.org.cn/machine-learning-with-python/,访问日期:2018 年 4 月 15 日。
另外,如果您的作品是公开的,请联系我,我很乐意出于普遍兴趣看看它。