深度学习神经网络是一类灵活的机器学习算法,在各种问题上表现良好。
神经网络使用误差反向传播算法进行训练,该算法涉及计算模型在训练数据集上造成的错误,并按比例更新模型权重。这种训练方法的局限性在于,每个类别的样本都被同等对待,对于不平衡数据集来说,这意味着模型在某个类别的适应程度要远高于另一个类别。
反向传播算法可以更新,以按类别重要性对误分类错误进行加权,这被称为加权神经网络或成本敏感型神经网络。这使得模型在具有严重倾斜的类别分布的数据集中能够更多地关注少数类样本而不是多数类样本。
在本教程中,您将了解用于不平衡分类的加权神经网络。
完成本教程后,您将了解:
- 标准神经网络算法如何不支持不平衡分类。
- 如何修改神经网络训练算法以按类别重要性对误分类错误进行加权。
- 如何为神经网络配置类别权重并评估其对模型性能的影响。
立即开始您的项目,阅读我的新书《Python不平衡分类》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何为不平衡分类开发成本敏感的神经网络
照片来源:Bernard Spragg。NZ,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 不平衡分类数据集
- Keras 中的神经网络模型
- 深度学习用于不平衡分类
- 带 Keras 的加权神经网络
不平衡分类数据集
在我们深入研究神经网络在不平衡分类方面的修改之前,让我们先定义一个不平衡分类数据集。
我们可以使用 make_classification() 函数 来定义一个合成的不平衡二分类数据集。我们将生成 10,000 个样本,少数类与多数类的比例约为 1:100。
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=4) |
生成后,我们可以总结类别分布,以确认数据集的创建符合预期。
|
1 2 3 4 |
... # 总结类别分布 counter = Counter(y) print(counter) |
最后,我们可以创建一个样本的散点图,并根据类别标签对其进行着色,以帮助理解对该数据集中的样本进行分类的挑战。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
综合起来,生成合成数据集并绘制样本的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=4) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结类别分布。
我们可以看到数据集的类别分布约为1:100,多数类有不到10,000个样本,少数类有100个样本。
|
1 |
Counter({0: 9900, 1: 100}) |
接下来,创建数据集的散点图,显示多数类(蓝色)的大量样本和少数类(橙色)的少量样本,并存在一些适度的类别重叠。
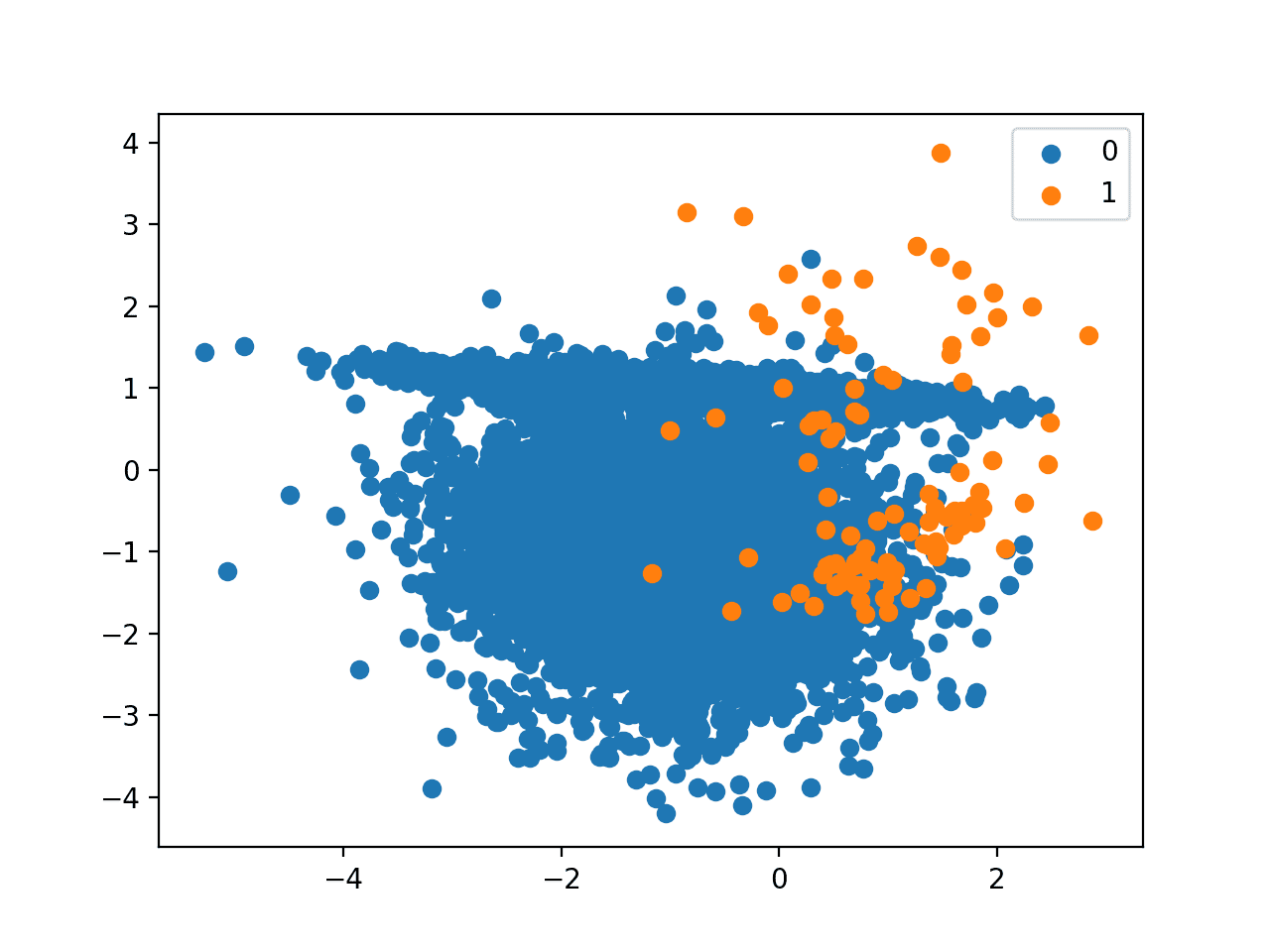
类别比例为 1:100 的二分类数据集的散点图
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Keras 中的神经网络模型
接下来,我们可以在数据集上拟合一个标准神经网络模型。
首先,我们可以定义一个函数来创建合成数据集并将其拆分为单独的训练集和测试集,每组包含 5,000 个样本。
|
1 2 3 4 5 6 7 8 9 10 |
# 准备训练和测试数据集 def prepare_data(): # 生成 2d 分类数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=4) # 分割为训练集和测试集 n_train = 5000 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy |
可以使用 Keras 深度学习库来定义一个多层感知器神经网络。我们将定义一个神经网络,它接受两个输入变量,有一个包含 10 个节点的隐藏层,然后是一个预测类别标签的输出层。
我们将在隐藏层中使用流行的 ReLU 激活函数,并在输出层中使用 sigmoid 激活函数,以确保预测值是 [0,1] 范围内的概率。模型将使用随机梯度下降和默认学习率进行拟合,并根据交叉熵损失进行优化。
网络架构和超参数并未针对该问题进行优化;相反,当训练算法稍后修改为处理倾斜的类别分布时,该网络提供了一个比较的基础。
下面的 `define_model()` 函数定义并返回模型,将输入变量的数量作为参数传递给网络。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 定义神经网络模型 def define_model(n_input): # 定义模型 model = Sequential() # 定义第一个隐藏层和可见层 model.add(Dense(10, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) # 定义输出层 model.add(Dense(1, activation='sigmoid')) # 定义损失和优化器 model.compile(loss='binary_crossentropy', optimizer='sgd') return model |
模型定义后,就可以在训练数据集上进行拟合。
我们将模型拟合 100 个训练周期,使用默认批次大小。
|
1 2 3 |
... # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) |
拟合后,我们可以使用该模型对测试数据集进行预测,然后使用 ROC AUC 分数来评估预测结果。
|
1 2 3 4 5 6 |
... # 对测试数据集进行预测 yhat = model.predict(testX) # 评估预测的 ROC AUC 分数 score = roc_auc_score(testy, yhat) print('ROC AUC: %.3f' % score) |
总而言之,拟合标准神经网络模型在不平衡分类数据集上的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 在不平衡分类数据集上的标准神经网络 from sklearn.datasets import make_classification from sklearn.metrics import roc_auc_score from keras.layers import Dense 从 keras.models 导入 Sequential # 准备训练和测试数据集 def prepare_data(): # 生成 2d 分类数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=4) # 分割为训练集和测试集 n_train = 5000 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy # 定义神经网络模型 def define_model(n_input): # 定义模型 model = Sequential() # 定义第一个隐藏层和可见层 model.add(Dense(10, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) # 定义输出层 model.add(Dense(1, activation='sigmoid')) # 定义损失和优化器 model.compile(loss='binary_crossentropy', optimizer='sgd') return model # 准备数据集 trainX, trainy, testX, testy = prepare_data() # 定义模型 n_input = trainX.shape[1] model = define_model(n_input) # 拟合模型 model.fit(trainX, trainy, epochs=100, verbose=0) # 对测试数据集进行预测 yhat = model.predict(testX) # 评估预测的 ROC AUC 分数 score = roc_auc_score(testy, yhat) print('ROC AUC: %.3f' % score) |
运行示例将在不平衡数据集上评估神经网络模型并报告 ROC AUC。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行该示例几次并比较平均结果。
在这种情况下,模型达到了约 0.949 的 ROC AUC 分数。这表明该模型与 ROC AUC 为 0.5 的朴素分类器相比具有一定的技能。
|
1 |
ROC AUC: 0.949 |
这为不对标准神经网络训练算法进行的任何修改提供了比较基线。
深度学习用于不平衡分类
神经网络模型通常使用误差反向传播算法进行训练。
这包括使用模型的当前状态对训练集样本进行预测,计算预测的误差,然后使用误差更新模型权重,并将误差的归属从输出层向前一直到输入层反向分配给不同的节点和层。
鉴于对误分类错误的均衡关注,大多数标准的神经网络算法并不适合具有严重倾斜类别分布的数据集。
大多数现有的深度学习算法并未考虑到数据不平衡问题。因此,这些算法在平衡数据集上表现良好,但在不平衡数据集上的性能无法保证。
此训练过程可以进行修改,使某些样本比其他样本的错误更大或更小。
通过更改要最小化的误差函数,也可以考虑误分类成本。反向传播学习过程不应最小化平方误差,而应最小化误分类成本。
实现此目的的最简单方法是根据样本的类别来固定误差分数的加权,对于更重要类别的样本,预测错误会增加,而对于不太重要类别的样本,预测错误会减少或保持不变。
… 成本敏感学习方法基于对错误分类样本相关成本的考虑来解决数据不平衡问题。特别是,它为样本的错误分类分配不同的成本值。
对于少数类样本,可以应用较大的误差权重,因为在不平衡分类问题中,它们通常比多数类样本更重要。
- 大权重:分配给少数类样本。
- 小权重:分配给多数类样本。
对神经网络训练算法进行的此修改被称为加权神经网络或成本敏感型神经网络。
通常,在定义成本或“权重”以用于成本敏感学习时,需要格外小心。但是,对于仅关注误分类的不平衡分类,权重可以使用训练数据集中观察到的类别分布的倒数。
带 Keras 的加权神经网络
Keras Python 深度学习库支持类别加权。
用于训练 Keras 神经网络模型的 fit() 函数接受一个名为 `class_weight` 的参数。此参数允许您定义一个字典,该字典将类别整数值映射到要应用于每个类别的权重。
此函数用于训练各种类型的神经网络,包括多层感知器、卷积神经网络和循环神经网络,因此类别加权功能可用于所有这些网络类型。
例如,类别 0 和 1 的 1 比 1 权重可以定义如下:
|
1 2 3 4 |
... # 拟合模型 weights = {0:1, 1:1} history = model.fit(trainX, trainy, class_weight=weights, ...) |
类别加权可以通过多种方式定义;例如:
- 领域专业知识,通过与主题专家交谈确定。
- 调优,通过超参数搜索(如网格搜索)确定。
- 启发式方法,使用一般的最佳实践指定。
使用类别加权的最佳实践是使用训练数据集中类别分布的倒数。
例如,测试数据集的类别分布是少数类与多数类的比例为 1:100。此比例的倒数可以与多数类的 1 和少数类的 100 一起使用,例如
|
1 2 3 4 |
... # 拟合模型 weights = {0:1, 1:100} history = model.fit(trainX, trainy, class_weight=weights, ...) |
代表相同比例的分数没有相同的影响。例如,使用 0.01 和 0.99 分别作为多数类和少数类的权重,可能导致性能比使用 1 和 100 差(在本例中确实如此)。
|
1 2 3 4 |
... # 拟合模型 weights = {0:0.01, 1:0.99} history = model.fit(trainX, trainy, class_weight=weights, ...) |
原因是来自多数类和少数类的样本的误差都会减少。此外,多数类误差的减少被大大缩减为非常小的数字,这些数字可能对模型权重的影响有限或非常小。
因此,建议使用整数来表示类别权重,例如 1 表示不变,100 表示类别 1 的误分类错误比类别 0 的误分类错误具有 100 倍的影响或惩罚。
我们可以使用上一节中定义的相同评估程序来评估具有类别权重的神经网络算法。
我们期望带类别权重的神经网络版本比没有类别权重的训练算法版本表现更好。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 在不平衡分类数据集上的带类别权重的神经网络 from sklearn.datasets import make_classification from sklearn.metrics import roc_auc_score from keras.layers import Dense 从 keras.models 导入 Sequential # 准备训练和测试数据集 def prepare_data(): # 生成 2d 分类数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=2, weights=[0.99], flip_y=0, random_state=4) # 分割为训练集和测试集 n_train = 5000 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] return trainX, trainy, testX, testy # 定义神经网络模型 def define_model(n_input): # 定义模型 model = Sequential() # 定义第一个隐藏层和可见层 model.add(Dense(10, input_dim=n_input, activation='relu', kernel_initializer='he_uniform')) # 定义输出层 model.add(Dense(1, activation='sigmoid')) # 定义损失和优化器 model.compile(loss='binary_crossentropy', optimizer='sgd') return model # 准备数据集 trainX, trainy, testX, testy = prepare_data() # 获取模型 n_input = trainX.shape[1] model = define_model(n_input) # 拟合模型 weights = {0:1, 1:100} history = model.fit(trainX, trainy, class_weight=weights, epochs=100, verbose=0) # 评估模型 yhat = model.predict(testX) score = roc_auc_score(testy, yhat) print('ROC AUC: %.3f' % score) |
运行示例将准备合成的不平衡分类数据集,然后评估带类别权重的神经网络训练算法版本。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行该示例几次并比较平均结果。
报告的 ROC AUC 分数,在这种情况下,显示的分数优于未加权版本的训练算法,约为 0.973,而未加权版本约为 0.949。
|
1 |
ROC AUC: 0.973 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 带神经网络的成本敏感学习, 1998.
- 不平衡数据集上的深度神经网络训练, 2016.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
总结
在本教程中,您了解了用于不平衡分类的加权神经网络。
具体来说,你学到了:
- 标准神经网络算法如何不支持不平衡分类。
- 如何修改神经网络训练算法以按类别重要性对误分类错误进行加权。
- 如何为神经网络配置类别权重并评估其对模型性能的影响。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






以下包实现了 85 种 SMOTE 变体
https://github.com/analyticalmindsltd/smote_variants
已在 40 个基准数据库上进行了测试。这可能是查找最佳过采样器的最佳来源。
感谢分享。
对于从客户查询中进行产品分类,如果我有一个 50k 行的预标记数据集,包含两列,一列是客户查询,另一列有 50 个类别(50 个产品标签)
我将使用此数据集作为训练数据集。我需要输入哪些参数
# 定义第一个隐藏层和可见层
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# 定义输出层
model.add(Dense(1, activation=’sigmoid’))
我的数据集也碰巧是多标签问题。例如,客户查询“T 恤短袖”同时被标记为 A 类和 B 类
那么在这种情况下,您能推荐一些解决方案吗?
非常感谢
这里的多标签示例可能会给您一些启发
https://machinelearning.org.cn/how-to-develop-a-convolutional-neural-network-to-classify-satellite-photos-of-the-amazon-rainforest/
模型结果仍然训练有素……AI 仍需进化
你具体指的是什么?
你好 Jason,
我听说过元模型在机器学习中被描述为“连接”两个或多个模型。
它何时何地可以使用?它是否可以在 sklearn 和/或 keras 中使用?
优点/缺点是什么?
您有示例吗?
谢谢
不太对。
您通过平均或其他类似方法组合多个模型。
您将多个输入模型连接到一个更广泛的模型中,例如文本和静态数据,或时间序列和静态数据。我有许多示例,但也许可以从这里的基础开始
https://machinelearning.org.cn/keras-functional-api-deep-learning/
您好,文章很棒。如何修改这些以用于多类别问题?我在损失函数和最终层上遇到麻烦,我有 7 个类别,不知道是应该只使用一个神经元在最终层还是七个。这同时也是一个类别不平衡问题。
提前感谢
谢谢。
凭我目前的理解,我认为 Keras 不支持多类别分类的成本敏感学习。
您好 Jason,感谢您坦诚的回答!此致敬礼。
不客气。
Jason,对于不平衡文本分类任务,有什么好的实践/技巧吗?
很好的问题。
嗯,我建议仔细选择指标、加权模型,并探索阈值移动和校准。
嗨,Jason,
在 define_model 函数中,哪个参数最能表明我们处理的是不平衡数据?我的意思是,与用于平衡数据集的函数完全相同。
抱歉,我没听懂你的问题。
也许你可以换个说法?
def define_model(n_input)
# 定义模型
model = Sequential()
# 定义第一个隐藏层和可见层
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# 定义输出层
model.add(Dense(1, activation=’sigmoid’))
# define loss and optimizer
model.compile(loss=’binary_crossentropy’, optimizer=’sgd’)
return model
我的意思是,上面代码中的哪个参数表明我们处理的是不平衡数据?
没有。
或者,如果你有平衡数据,你会以同样的方式定义你的模型吗?
你可以为不平衡数据设置“class_weight”参数。
这就是本教程的重点。也许你该重读一遍?
哦,好的……我明白了……唯一有助于更准确地分类不平衡数据的是 fit 部分的 class_weight……对吗?
在本教程中,是的。
嗨,Jason,
感谢您精彩的教程!
据我理解,在 Keras 的 (.fit) 方法中设置 class_weight 参数,对于不平衡数据集,它是为了对少数类(相对于多数类)的损失或错误施加更强的惩罚,以强制更好地拟合少数类数据集的损失或错误,因为代码看到少数类数据集的时间更少。
直观地说,我认为我可以完全复制相同的学习效果,只需将少数类数据集复制足够多的次数,使其与多数类数据集的数量相同(我的意思是重复相同的少数类数据集,直到获得与多数类相同数量)?或者 class_weight 方法是否比其他方法更好?
谢谢
不客气。
你可以使用过采样获得类似的结果,但这是一个略有不同的机制,例如,每次批次更新的权重惩罚(随机组成)与训练集的组成不同。
嗨,Jason,
感谢您出色的帖子。我希望这项技术也能用于文本分类。
如果我使用 sklearn 的 train_test_split 方法来定义训练和测试数据集,会发生什么?
不客气!
也许可以试试,看看它是否适合你的数据集。
Jason,请阐明一下
1. 在训练不平衡分类的深度学习模型并使用类权重时,应该优先监控哪个性能指标?(在 model.compile 期间)
2. 在同一情况下,在 EarlyStopping 回调函数中,应该使用哪个期望的性能参数?(即 EarlyStopping(monitor=??? , mode=???)
选择一个对你的项目有意义的指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
Early stopping 应该使用 loss,而不是 metric。
谢谢你的教程!我从未见过如此详细地解释不平衡数据的教程。
但是,我在使用类权重处理不平衡数据时遇到了一个问题。
我使用的是 Keras,我的数据集的比例是 10:1。所以我设置了 weights = {0:1, 1:10}
但是它的性能没有提高。我检查了准确率、精确率、召回率、F1分数。
但这些指标甚至变差了。
这可能吗?你有什么原因的猜想吗?
你能给我一些提高性能的建议吗?
谢谢!
也许可以尝试其他方法
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
根据教程,分配类权重可以平衡数据集。那么,我们能依靠准确率本身来评估最终模型吗?
是的,选择一个你信任的指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
嗨,我目前正在为我的实习做研究,您的文章非常有帮助。只有一个部分我不清楚。您能再解释一下为什么权重 1-100 比 0.01-1 更好吗?
谢谢
这可能会在学习过程中对模型产生更大的惩罚。
我为我的数据集试过了,这个方法在计算 ROC AUC 时只是给出了各种各样的值。我担心这太随机了,我不能将其用作验证指标。
也许你可以收集更多训练数据来减少模型的方差?
也许你可以将一套最终模型集成在一起,以减少预测的方差?
嗨 Jason
一切都还好吗?
通过机器学习相关主题的谷歌搜索,我找到了你的博客。
我想祝贺你的工作,并请求一个建议。
我正在攻读硕士学位,并且参加了一个小组,我们选择了的工作,即开发一个分类器,该分类器在样本被第一个分类器错误分类后,能够识别并正确地对它们进行分类。
我做了很多研究,但我承认我很难找到可以作为开发基础的文章。
如果你有什么建议,我将不胜感激
Carlos Reis
谢谢!
听起来像是一个很棒的项目。听起来像一个堆叠模型
https://machinelearning.org.cn/?s=stacking&post_type=post&submit=Search
谢谢您的建议
不客气。
嗨,Jason,
谢谢你的教程。我正在做一个项目,其中我的输入张量是一个不平衡的二元矩阵(m x n x 1)。当我尝试在 fit_generator 中使用类权重时,我遇到了以下错误:“ValueError:
class_weightnot supported for 3+ dimensional targets.” 如果您有什么建议,将非常有帮助。在我的情况下,1 的数量最多是 [ min(m, n)],其余是 0。感谢您的时间。
此致,
Sutanu
是的,我相信类权重只支持二维目标,例如分类。
Jason,我想知道是否可以在 R 中训练具有加权样本的神经网络回归?如果可以,您能否推荐一些相关的 R 包?谢谢!
Bob,如果这是与时间序列相关的应用……抱歉,我没有关于 R 中时间序列预测的资料。
我有一本关于 Python 时间序列的书。
R 中已经有一些很棒的时间序列预测书籍,例如,请参阅此帖子
R 中时间序列预测的最佳书籍
https://machinelearning.org.cn/books-on-time-series-forecasting-with-r/
Jason,我想知道您能否推荐一些用于加权神经网络回归(非时间序列)的 Python 包?目前,我的数据集存在明显的异方差问题。处理它的最佳方法之一是使用加权回归。
Leon,
希望以下内容对您有帮助
https://machinelearning.org.cn/deep-learning-models-for-multi-output-regression/
成本敏感方法如何改进神经网络的训练过程?
Ifran…以下资源展示了对训练过程的好处的研究,特别是对于深度学习模型。
https://arxiv.org/pdf/1508.03422