支持向量机算法对于平衡分类是有效的,但它在不平衡数据集上表现不佳。
SVM 算法找到一个超平面决策边界,该边界能最好地将样本分成两类。通过使用允许一些点被错误分类的间隔,使分割变得柔和。默认情况下,此间隔在不平衡数据集上倾向于多数类,尽管可以通过更新它来考虑每个类别的重要性,从而显著提高算法在类别分布偏斜的数据集上的性能。
这种根据类别重要性按比例加权间隔的 SVM 修改通常被称为加权 SVM 或成本敏感型 SVM。
在本教程中,您将学习用于不平衡分类的加权支持向量机。
完成本教程后,您将了解:
- 标准支持向量机算法在不平衡分类中的局限性。
- 支持向量机算法如何进行修改,以便在训练期间根据类别重要性按比例加权间隔惩罚。
- 如何为 SVM 配置类别权重以及如何对不同的类别权重配置进行网格搜索。
通过我的新书《使用 Python 进行不平衡分类》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。

如何为不平衡分类实现加权支持向量机
照片由 Bas Leenders 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 不平衡分类数据集
- 不平衡分类的 SVM
- 使用 Scikit-Learn 的加权 SVM
- 网格搜索加权 SVM
不平衡分类数据集
在我们深入研究用于不平衡分类的 SVM 修改之前,让我们首先定义一个不平衡分类数据集。
我们可以使用 make_classification() 函数来定义一个合成的不平衡两类分类数据集。我们将生成 10,000 个样本,其中少数类与多数类的比例约为 1:100。
|
1 2 3 4 |
... # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) |
生成后,我们可以总结类别分布,以确认数据集的创建符合预期。
|
1 2 3 4 |
... # 总结类别分布 counter = Counter(y) print(counter) |
最后,我们可以创建一个样本的散点图,并根据类别标签对其进行着色,以帮助理解对该数据集中的样本进行分类的挑战。
|
1 2 3 4 5 6 7 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
综合起来,生成合成数据集并绘制样本的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先创建数据集并总结类别分布。
我们可以看到数据集的类别分布约为1:100,多数类有不到10,000个样本,少数类有100个样本。
|
1 |
Counter({0: 9900, 1: 100}) |
接下来,创建数据集的散点图,显示多数类(蓝色)的大量样本和少数类(橙色)的少量样本,并存在一些适度的类别重叠。
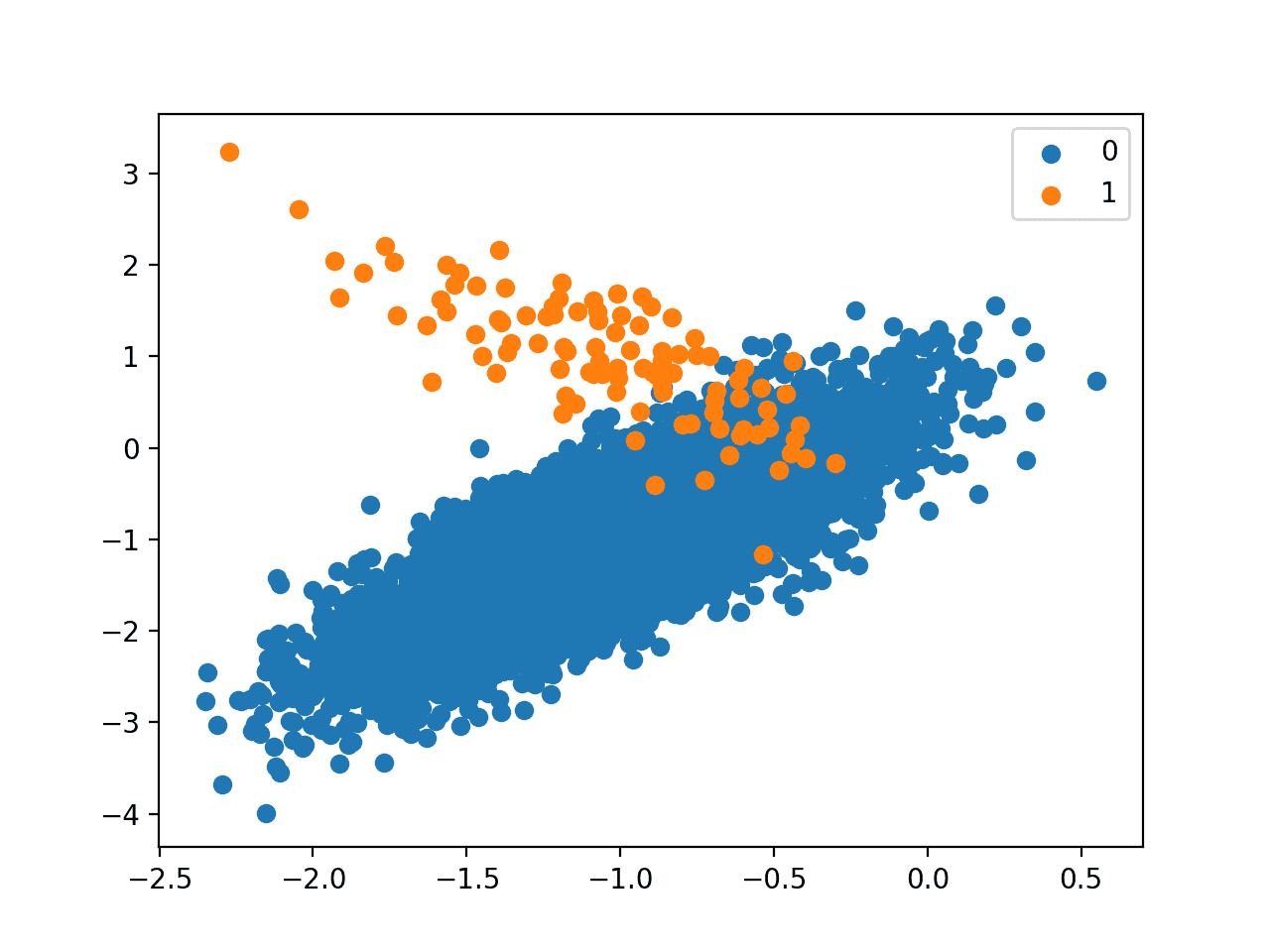
具有1比100类别不平衡的二元分类数据集散点图
接下来,我们可以在数据集上拟合一个标准的 SVM 模型。
SVM 可以使用 scikit-learn 库中的 SVC 类来定义。
|
1 2 3 |
... # 定义模型 model = SVC(gamma='scale') |
我们将使用重复交叉验证来评估模型,进行三次 10 折交叉验证。模型性能将使用重复和所有折叠的平均 ROC 曲线下面积 (ROC AUC) 进行报告。
|
1 2 3 4 5 6 7 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('平均 ROC AUC: %.3f' % mean(scores)) |
结合以上内容,下面列出了在不平衡分类问题上定义和评估标准 SVM 模型的完整示例。
SVM 是二进制分类任务的有效模型,但默认情况下,它们在不平衡分类中无效。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在不平衡分类数据集上拟合 SVM from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) # 定义模型 model = SVC(gamma='scale') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('平均 ROC AUC: %.3f' % mean(scores)) |
运行该示例,评估不平衡数据集上的标准 SVM 模型并报告平均 ROC AUC。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
我们可以看到该模型具有技能,ROC AUC 超过 0.5,在本例中平均分数为 0.804。
|
1 |
平均 ROC AUC: 0.804 |
这为对标准 SVM 算法进行的任何修改提供了比较基线。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
不平衡分类的 SVM
支持向量机,简称 SVM,是一种有效的非线性机器学习算法。
SVM 训练算法寻找一条线或超平面,以最佳方式分离类别。超平面由一个间隔定义,该间隔最大化决策边界与来自两个类别的最近样本之间的距离。
粗略地说,间隔是分类边界和最近的训练集点之间的距离。
— 第 343-344 页,《应用预测建模》,2013 年。
数据可以使用核函数进行转换,以允许定义线性超平面来分离转换后的特征空间中的类别,这对应于原始特征空间中的非线性类别边界。常见的核变换包括线性、多项式和径向基函数变换。这种数据转换被称为“核技巧”。
通常,即使进行了数据转换,类别也无法分离。因此,间隔被软化以允许一些点出现在决策边界的错误一侧。这种间隔的软化由一个正则化超参数控制,称为软间隔参数,lambda 或大写 C(“C”)。
…其中 C 代表正则化参数,用于控制最大化类别间分离间隔和最小化错误分类实例数量之间的权衡。
— 第 125 页,《从不平衡数据集学习》,2018 年。
C 值表示硬间隔,不容忍间隔的违反。小的正值允许一些违反,而大的整数值,例如 1、10 和 100,允许更软的间隔。
… [C] 决定了我们容忍的间隔(和超平面)违反的数量和严重程度。我们可以将 C 视为 n 个观测值可以违反间隔的预算。
— 第 347 页,《统计学习导论:及其在 R 中的应用》,2013 年。
尽管有效,但当类别分布严重倾斜时,SVM 表现不佳。因此,为了使它们在不平衡数据集上更有效,对算法进行了许多扩展。
尽管 SVM 通常为平衡数据集生成有效的解决方案,但它们对数据集中的不平衡很敏感,并生成次优模型。
— 第 86 页,《不平衡学习:基础、算法和应用》,2013 年。
C 参数在模型拟合期间用作惩罚,特别是决策边界的寻找。默认情况下,每个类别具有相同的权重,这意味着间隔的柔软度是对称的。
鉴于多数类中的样本显著多于少数类,这意味着软间隔,进而决策边界将偏向多数类。
… [学习] 算法将偏向多数类,因为专注于它将导致分类误差和间隔最大化之间更好的权衡。这将以少数类为代价,特别是当不平衡率很高时,因为此时忽略少数类将导致更好的优化结果。
— 第 126 页,《从不平衡数据集学习》,2018 年。
也许 SVM 用于不平衡分类的最简单和最常见的扩展是根据每个类别的重要性按比例加权 C 值。
为了在 SVM 中适应这些因素,提出了一种实例级加权修改。[…] 权重值可以根据类别之间的不平衡比率或单个实例复杂性因素给出。
— 第 130 页,《从不平衡数据集学习》,2018 年。
具体来说,训练数据集中的每个样本都有自己的惩罚项(C 值),用于拟合 SVM 模型时计算间隔。样本的 C 值可以计算为全局 C 值的加权,其中权重是根据类别分布按比例定义的。
- C_i = weight_i * C
少数类可以使用更大的权重,使间隔更软,而多数类可以使用更小的权重,迫使间隔更硬并防止错误分类的样本。
- 小权重:较小的 C 值,对错误分类样本的惩罚较大。
- 大权重:较大的 C 值,对错误分类样本的惩罚较小。
这会促使间隔以较小的灵活性包含多数类,但允许少数类灵活地将多数类样本错误分类到少数类一侧(如果需要)。
也就是说,修改后的 SVM 算法不会倾向于将分离超平面偏向少数类样本以减少总错误分类,因为少数类样本现在被分配了更高的错误分类成本。
— 第 89 页,《不平衡学习:基础、算法和应用》,2013 年。
这种 SVM 的修改可以称为加权支持向量机 (Weighted Support Vector Machine, WSVM),或者更一般地,类加权 SVM (Class-Weighted SVM)、实例加权 SVM (Instance-Weighted SVM) 或成本敏感型 SVM (Cost-Sensitive SVM)。
基本思想是为不同的数据点分配不同的权重,以便 WSVM 训练算法根据训练数据集中数据点的相对重要性学习决策曲面。
— 《用于数据分类的加权支持向量机》,2007 年。
使用 Scikit-Learn 的加权 SVM
scikit-learn Python 机器学习库提供了支持类别加权的 SVM 算法实现。
LinearSVC 和 SVC 类提供了 class_weight 参数,可以将其指定为模型超参数。class_weight 是一个字典,定义了每个类别标签(例如 0 和 1)以及在计算软间隔时应用于 C 值的权重。
例如,类别 0 和 1 的 1 比 1 权重可以定义如下:
|
1 2 3 4 |
... # 定义模型 weights = {0:1.0, 1:1.0} model = SVC(gamma='scale', class_weight=weights) |
类别加权可以通过多种方式定义;例如:
- 领域专业知识,通过与主题专家交谈确定。
- 调优,通过超参数搜索(如网格搜索)确定。
- 启发式方法,使用一般的最佳实践指定。
使用类别加权的最佳实践是使用训练数据集中类别分布的倒数。
例如,测试数据集的类别分布是少数类与多数类的比例为 1:100。这个比例的倒数可以用作多数类为 1,少数类为 100;例如
|
1 2 3 4 |
... # 定义模型 weights = {0:1.0, 1:100.0} model = SVC(gamma='scale', class_weight=weights) |
我们也可以使用分数定义相同的比例并达到相同的结果;例如
|
1 2 3 4 |
... # 定义模型 weights = {0:0.01, 1:1.0} model = SVC(gamma='scale', class_weight=weights) |
通过将 class_weight 设置为“balanced”,可以直接使用此启发式方法。例如
|
1 2 3 |
... # 定义模型 model = SVC(gamma='scale', class_weight='balanced') |
我们可以使用上一节中定义的相同评估过程来评估具有类别加权的 SVM 算法。
我们预期类别加权版本的 SVM 将比没有类别加权的标准版本 SVM 表现更好。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在不平衡分类数据集上使用类别权重进行 SVM from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) # 定义模型 model = SVC(gamma='scale', class_weight='balanced') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='roc_auc', cv=cv, n_jobs=-1) # 总结性能 print('平均 ROC AUC: %.3f' % mean(scores)) |
运行该示例,准备合成的不平衡分类数据集,然后使用重复交叉验证评估类别加权版本的 SVM 算法。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
报告了平均 ROC AUC 分数,在这种情况下,显示出比未加权版本的 SVM 算法更好的分数,0.964 对比 0.804。
|
1 |
平均 ROC AUC:0.964 |
网格搜索加权 SVM
使用训练数据逆比例的类别权重只是一种启发式方法。
使用不同的类别权重可能会获得更好的性能,这也将取决于用于评估模型的性能指标的选择。
在本节中,我们将对加权 SVM 的一系列不同类别权重进行网格搜索,并找出哪个权重产生了最佳的 ROC AUC 分数。
我们将尝试以下类别 0 和 1 的权重:
- 类别 0:100,类别 1:1
- 类别 0:10,类别 1:1
- 类别 0:1,类别 1:1
- 类别 0:1,类别 1:10
- 类别 0:1,类别 1:100
这些可以定义为 GridSearchCV 类的网格搜索参数,如下所示
|
1 2 3 4 |
... # 定义网格 balance = [{0:100,1:1}, {0:10,1:1}, {0:1,1:1}, {0:1,1:10}, {0:1,1:100}] param_grid = dict(class_weight=balance) |
我们可以使用重复交叉验证对这些参数执行网格搜索,并使用 ROC AUC 评估模型性能。
|
1 2 3 4 5 |
... # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格搜索 grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=cv, scoring='roc_auc') |
执行后,我们可以总结最佳配置以及所有结果,如下所示:
|
1 2 3 4 5 6 7 8 9 |
... # 报告最佳配置 print("最佳: %f 使用 %s" % (grid_result.best_score_, grid_result.best_params_)) # 报告所有配置 means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) |
结合以上内容,以下示例在不平衡数据集上对 SVM 算法的五种不同类别权重进行网格搜索。
我们可能会期望启发式类别加权是表现最好的配置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 使用 SVM 对不平衡分类进行网格搜索类别权重 from numpy import mean from sklearn.datasets import make_classification from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=4) # 定义模型 model = SVC(gamma='scale') # 定义网格 balance = [{0:100,1:1}, {0:10,1:1}, {0:1,1:1}, {0:1,1:10}, {0:1,1:100}] param_grid = dict(class_weight=balance) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格搜索 grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=cv, scoring='roc_auc') # 执行网格搜索 grid_result = grid.fit(X, y) # 报告最佳配置 print("最佳: %f 使用 %s" % (grid_result.best_score_, grid_result.best_params_)) # 报告所有配置 means = grid_result.cv_results_['mean_test_score'] stds = grid_result.cv_results_['std_test_score'] params = grid_result.cv_results_['params'] for mean, stdev, param in zip(means, stds, params): print("%f (%f) with: %r" % (mean, stdev, param)) |
运行示例会使用重复的k折交叉验证评估每个类别权重,并报告最佳配置和相关的平均ROC AUC分数。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到1:100多数类与少数类加权取得了最佳的平均ROC分数。这与通用启发式方法的配置相符。
探索更极端的类别权重以查看它们对平均ROC AUC分数的影响可能会很有趣。
|
1 2 3 4 5 6 |
最佳:0.966189,使用 {'class_weight': {0: 1, 1: 100}} 0.745249 (0.129002) 使用: {'class_weight': {0: 100, 1: 1}} 0.748407 (0.128049) 使用: {'class_weight': {0: 10, 1: 1}} 0.803727 (0.103536) 使用: {'class_weight': {0: 1, 1: 1}} 0.932620 (0.059869) 使用: {'class_weight': {0: 1, 1: 10}} 0.966189 (0.036310) 使用: {'class_weight': {0: 1, 1: 100}} |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 控制支持向量机的敏感性, 1999.
- 用于数据分类的加权支持向量机, 2005.
- 用于数据分类的加权支持向量机, 2007.
- 成本敏感型支持向量机, 2012.
书籍
- 《统计学习导论:R语言应用》(An Introduction to Statistical Learning: with Applications in R), 2013.
- 应用预测建模, 2013.
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
- sklearn.utils.class_weight.compute_class_weight API.
- sklearn.svm.SVC API.
- sklearn.svm.LinearSVC API.
- sklearn.model_selection.GridSearchCV API.
文章
总结
在本教程中,您学习了用于不平衡分类的加权支持向量机。
具体来说,你学到了:
- 标准支持向量机算法在不平衡分类中的局限性。
- 支持向量机算法如何进行修改,以便在训练期间根据类别重要性按比例加权间隔惩罚。
- 如何为 SVM 配置类别权重以及如何对不同的类别权重配置进行网格搜索。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...
")





如果我有一个不平衡的文本分类案例,客户搜索被分类为 50 个产品类别。
那么在这种情况下,我需要为所有 50 个类别设置权重吗?还是可以专注于样本最多和最少的类别?
很好的问题!
这取决于您项目的目标。
加权最重要的类别是一个很好的开始,然后看看是否可以通过更精细的加权做得更好。
在使用 Scikit-learn 的 SVM 的 class_weight 字典的情况下,我根据使用的分数得到了不同的结果。例如,如果我有一个正类比负类频繁四倍,那么以下两种定义类别权重的方式会有所不同
class_weight = {1: 0.25, 0: 1} 和
class_weight = {1: 1, 0: 4}。
根据您的文章,应该没有任何区别,对吗?
不同的分数定义上就会影响模型。
整数与分数在拟合模型时将具有或多或少的权重。
您好,我有一个关于使用 Scikit-Learn 定义 SVM 的字典 class_weight 的问题。我正在处理一个不平衡的二元分类问题,其中正类的频率是负类的 4 倍。我注意到如果我按以下方式定义字典,结果会有所不同
class_weight = {1: 1/4, 0: 1}
class_weight = {1: 1, 0: 4}
我猜区别在于权重乘以错误分类惩罚 C,而 C 乘以 4 或除以 4 存在实质性差异。
我期待您的答复,
谢谢
是的,正是如此。
尝试两种方法,并使用性能最好的模型。
“C 值表示硬间隔,不容忍间隔的违反。小的正值允许一些违反,而大的整数值,例如 1、10 和 100,允许更软的间隔。”
较大的 C 值不是应该允许更硬的间隔而不是更软的间隔吗?因为据我所知,C 值越高,它对错误分类的容忍度就越低。
是的,硬间隔——正如所写。也许重新阅读这句话?
“少数类可以使用更大的权重,使间隔更软,”
我认为“更软”应该改为“更硬”。
较大的值往往具有更硬的间隔。这导致了有利于少数类的边界。
感谢您的反馈,Ahmad!
我不明白为什么评分函数是“roc_auc”,如果链接中的 ROC 曲线下面积 (ROC AUC) 说
“当观测值在每个类别之间平衡时,ROC 曲线是合适的,而精确召回曲线适用于不平衡数据集。”
我们不应该使用“average_precision”吗,它表示从预测分数计算平均精度 (AP),AP 总结了精确召回曲线
好问题,也许这有助于理解这个分数以及何时使用它
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
感谢 Jason 详细的解释和所有支持的链接,以便更深入地理解。
我们的目标不应该是减少假阴性。您不应该关注基于召回率的方法吗?
也许,选择一个性能指标是重要的一步
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
还有一件事。在调整模型之前,我应该进行特征缩放吗?如果应该,那么我们应该如何决定缩放的类型?
缩放将作为建模流程的一部分执行。
嗨,Jason,我在我的一个项目中运行了类似的代码,其中我改变了类权重。
在那里,我的加权类贡献是正类0.2,负类99.8。所以我在网格搜索中将权重设置为['balanced', {0:100,1:1}, {0:10,1:1}, {0:1,1:1}, {0:1,1:10}, {0:1,1:100}, {0:0.173, 1:99.826}],正如预期的那样,最佳分数是{0:0.173, 1:99.826},roc分数为97.2,但训练分数为95。所以我想问的是,我是否应该在不进行交叉验证的情况下运行网格搜索,并在训练集和测试集上进行拟合,以比较所有值的分数以获得最佳组合?或者是否有其他方法?因为分数不应该在训练或测试中出现偏差。你有什么建议?
我建议设计一个测试工具,它能最好地捕捉你期望如何使用最终模型。然后,我建议使用该测试工具来评估和选择候选模型,包括网格搜索。
我的建议是使用重复分层K折交叉验证,可能重复3次以上,10折,并使用管道进行所有转换和模型。但你可以使用任何你想要的方法。
嗨 Jason
感谢你的精彩文章
我需要样本多于特征的不平衡高维医学数据集
我寻求你的建议
哪种数据集在研究中用得最多,我可以用来应用我的想法并与其他人进行比较
请给我数据来源
提前感谢
不客气!
这里有一些你可以使用的测试数据集的想法
https://machinelearning.org.cn/standard-machine-learning-datasets-for-imbalanced-classification/
你好 Jason。
感谢你的帖子。“重复分层k折交叉验证”与“分层k折交叉验证”的区别是什么,除了重复操作之外?前者有什么明显的好处吗?
谢谢!
没有其他区别。
嗨,Jason,
我尝试使用SVM处理具有不平衡数据集的多分类问题。
我的数据集包含三个类别A、B和C,比例分别为72%、13%和15%。
我尝试使用class_weight='balanced',并输出每个类别的概率。
Cohen's kappa得分被视为评估指标。
我的导师告诉我,在得到输出概率后,我可以为A、B、C设置不同的权重,并将这些权重乘以相应的类别,然后将概率最高的类别指定为输出类别。例如,A、B、C的输出概率分别为[0.90, 0.03, 0.07],相应的权重为[1, 5.5, 4.8],相应的乘积结果为[0.90,0.16,0.34],因此选择了类别A作为输出类别。
我的问题是,我可以在模型训练后对A、B、C进行权重分配吗?
我感觉有点像作弊。
谢谢!
也许你可以将权重调整作为 k 折交叉验证测试流程的一部分,例如,将其视为使用验证数据集的超参数调优。
亲爱的Janson,
谢谢!
抱歉回复晚了!
你的意思是,我可以在验证过程中进行这个操作,将权重与验证集的输出概率相乘,以获得优化结果,然后将选定的权重输入到测试集,再使用argmax函数获得最终的输出类别吗?
我这样做对吗?
也许可以尝试一下。
亲爱的 Jason,
我非常感谢你的分享!
我参考了你的相关帖子构建了一个堆叠分类器。
并按照你的建议在验证过程中调整了权重。
它比单独使用堆叠分类器取得了更好的结果。
此外,你给了我信任我的想法的信心。
非常感谢!
干得好!
谢谢你,Jason!
我想我可以参考这篇帖子。
https://machinelearning.org.cn/probability-calibration-for-imbalanced-classification/?unapproved=612041&moderation-hash=58c27e99d9d98e4253854b259b1fc73f#comment-612041.