在机器学习中,交叉熵通常被用作损失函数。
交叉熵是信息论领域的一个度量,它建立在熵的基础上,通常用于计算两个概率分布之间的差异。它与KL散度密切相关但有所不同,KL散度计算的是两个概率分布之间的相对熵,而交叉熵可以被认为是计算分布之间的总熵。
交叉熵也与逻辑损失(称为对数损失)有关,并且经常被混淆。虽然这两种度量源自不同的领域,但当用作分类模型的损失函数时,它们计算的是相同的量,可以互换使用。
在本教程中,您将探索机器学习中的交叉熵。
完成本教程后,您将了解:
- 如何从零开始以及使用标准的机器学习库计算交叉熵。
- 在优化逻辑回归和人工神经网络等分类模型时,交叉熵可用作损失函数。
- 交叉熵与KL散度不同,但可以使用KL散度计算;它也与对数损失不同,但在用作损失函数时计算的是相同的量。
通过我的新书《机器学习的概率论》来启动您的项目,书中包含所有示例的分步教程和Python源代码文件。
让我们开始吧。
- 更新于2019年10月:给出了相同分布的交叉熵示例,并更新了对此情况的描述(感谢Ron U)。增加了一个计算已知类别标签熵的示例。
- 更新于2019年11月:改进了结构,增加了更多关于熵的解释。为预测的类别概率增加了直观解释。
- 更新于2020年12月:对信息和熵的介绍进行了微调,使其更加清晰。

机器学习交叉熵简明介绍
照片由 Jerome Bon 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是交叉熵?
- 交叉熵与KL散度的比较
- 如何计算交叉熵
- 两个离散概率分布
- 计算分布之间的交叉熵
- 计算一个分布与其自身的交叉熵
- 使用KL散度计算交叉熵
- 交叉熵作为损失函数
- 计算类别标签的熵
- 计算类别标签与概率之间的交叉熵
- 使用 Keras 计算交叉熵
- 对预测概率的交叉熵的直观理解
- 交叉熵与对数损失的比较
- 对数损失是负对数似然
- 对数损失和交叉熵计算的是相同的值
什么是交叉熵?
交叉熵是衡量对于给定的随机变量或事件集,两个概率分布之间差异的指标。
您可能还记得,信息量化了编码和传输一个事件所需的比特数。概率较低的事件信息量更大,概率较高的事件信息量较小。
在信息论中,我们喜欢描述一个事件的“意外程度”。一个事件越不可能发生,它就越令人意外,这意味着它包含更多的信息。
- 低概率事件(令人意外):信息量更多。
- 高概率事件(不令人意外):信息量更少。
对于一个事件 x,给定其概率 P(x),信息 h(x) 可以计算如下:
- h(x) = -log(P(x))
熵是从一个概率分布中随机选择一个事件进行传输所需的比特数。一个偏斜的分布熵较低,而事件概率相等的分布熵较大。
一个偏斜的概率分布“意外程度”较低,因此熵也较低,因为高概率事件占主导地位。均衡的分布更令人意外,因此熵更高,因为事件发生的可能性是均等的。
- 偏斜的概率分布(不令人意外):低熵。
- 均衡的概率分布(令人意外):高熵。
对于一个具有一组离散状态 x in X 及其概率 P(x) 的随机变量,熵 H(x) 可以计算如下:
- H(X) = – sum x in X P(x) * log(P(x))
如果您想了解更多关于计算事件信息和分布熵的内容,请参阅本教程。
交叉熵建立在信息论中熵的概念之上,它计算的是用一个分布与另一个分布相比,表示或传输一个平均事件所需的比特数。
… 当我们使用模型q时,交叉熵是编码来自源分布p的数据所需的平均比特数 …
— 第 57 页,《机器学习:概率视角》,2012年。
这个定义的直观理解是,如果我们考虑一个目标或底层概率分布 P 和一个目标分布的近似分布 Q,那么 Q 相对于 P 的交叉熵是使用 Q 而不是 P 来表示一个事件所需的额外比特数。
两个概率分布之间的交叉熵,例如 Q 相对于 P,可以正式表述为:
- H(P, Q)
其中 H() 是交叉熵函数,P 可能是目标分布,Q 是目标分布的近似。
交叉熵可以使用来自 P 和 Q 的事件概率计算如下:
- H(P, Q) = – sum x in X P(x) * log(Q(x))
其中 P(x) 是事件 x 在 P 中的概率,Q(x) 是事件 x 在 Q 中的概率,log 是以2为底的对数,意味着结果的单位是比特(bits)。如果使用以e为底的自然对数,结果的单位将是纳特(nats)。
这个计算适用于离散概率分布,对于连续概率分布也可以使用类似的计算,即使用事件的积分代替求和。
结果将是一个以比特为单位的正数,如果两个概率分布相同,它将等于该分布的熵。
注意:这个表示法看起来很像联合概率,或者更具体地说是 P 和 Q 之间的联合熵。这是有误导性的,因为我们用交叉熵来衡量概率分布之间的差异。而联合熵是一个不同的概念,它使用相同的表示法,但计算的是两个(或多个)随机变量的不确定性。
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
交叉熵与KL散度的比较
交叉熵不是KL散度。
交叉熵与散度度量有关,例如Kullback-Leibler(KL)散度,它量化了一个分布与另一个分布的差异程度。
具体来说,KL散度度量的是一个与交叉熵非常相似的量。它度量的是用 Q 而不是 P 来表示一条消息所需的平均额外比特数,而不是总比特数。
换句话说,KL散度是由于我们使用分布q而不是真实分布p来编码数据而需要的平均额外比特数。
— 第58页, 《机器学习:概率视角》,2012年。
因此,KL散度通常被称为“相对熵”。
- 交叉熵:用 Q 代替 P 表示一个事件所需的平均总比特数。
- 相对熵(KL散度):用 Q 代替 P 表示一个事件所需的平均额外比特数。
KL散度可以计算为 P 中每个事件的概率乘以 Q 中事件概率与 P 中事件概率之比的对数的负和。通常,对数以2为底,这样结果的单位就是比特。
- KL(P || Q) = – sum x in X P(x) * log(Q(x) / P(x))
求和中的值是给定事件的散度。
因此,我们可以通过将分布的熵加上KL散度计算出的额外熵来计算交叉熵。考虑到两种计算的定义,这是很直观的;例如:
- H(P, Q) = H(P) + KL(P || Q)
其中 H(P, Q) 是 Q 相对于 P 的交叉熵,H(P) 是 P 的熵,KL(P || Q) 是 Q 相对于 P 的散度。
一个概率分布的熵可以计算为每个事件的概率乘以该事件概率的对数的负和,其中对数以2为底以确保结果以比特为单位。
- H(P) = – sum x on X p(x) * log(p(x))
与KL散度一样,交叉熵是非对称的,意味着:
- H(P, Q) != H(Q, P)
我们稍后会看到,当交叉熵和KL散度被用作优化分类预测模型的损失函数时,它们计算的是相同的量。正是在这种情况下,你有时可能会看到交叉熵和KL散度是相同的。
关于KL散度的更多细节,请参阅教程。
如何计算交叉熵
在本节中,我们将通过一个小例子来具体说明交叉熵的计算。
两个离散概率分布
考虑一个随机变量,它有三个离散事件,分别为不同的颜色:红色、绿色和蓝色。
我们可能有两个关于这个变量的不同概率分布;例如:
|
1 2 3 4 5 |
... # 定义分布 events = ['red', 'green', 'blue'] p = [0.10, 0.40, 0.50] q = [0.80, 0.15, 0.05] |
我们可以绘制这些概率的条形图,将它们作为概率直方图直接进行比较。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 绘制分布图 from matplotlib import pyplot # 定义分布 events = ['red', 'green', 'blue'] p = [0.10, 0.40, 0.50] q = [0.80, 0.15, 0.05] print('P=%.3f Q=%.3f' % (sum(p), sum(q))) # 绘制第一个分布 pyplot.subplot(2,1,1) pyplot.bar(events, p) # 绘制第二个分布 pyplot.subplot(2,1,2) pyplot.bar(events, q) # 显示绘图 pyplot.show() |
运行该示例会为每个概率分布创建一个直方图,从而可以直接比较每个事件的概率。
我们可以看到,这两个分布确实是不同的。
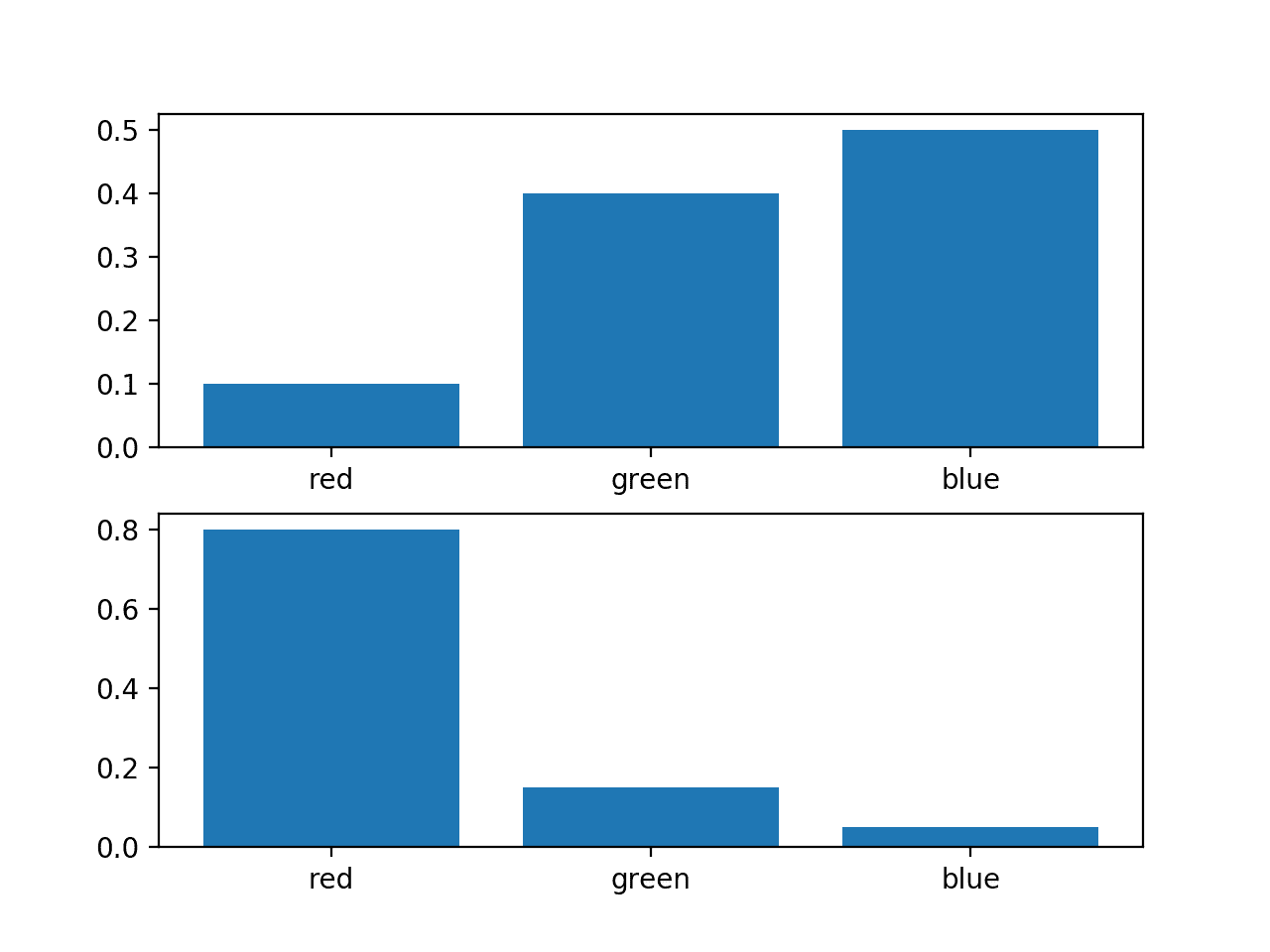
同一随机变量的两个不同概率分布的直方图
计算分布之间的交叉熵
接下来,我们可以开发一个函数来计算这两个分布之间的交叉熵。
我们将使用以2为底的对数,以确保结果的单位是比特。
|
1 2 3 |
# 计算交叉熵 def cross_entropy(p, q): return -sum([p[i]*log2(q[i]) for i in range(len(p))]) |
然后,我们可以使用这个函数来计算 P 相对于 Q 的交叉熵,以及反过来 Q 相对于 P 的交叉熵。
|
1 2 3 4 5 6 7 |
... # 计算交叉熵 H(P, Q) ce_pq = cross_entropy(p, q) print('H(P, Q): %.3f bits' % ce_pq) # 计算交叉熵 H(Q, P) ce_qp = cross_entropy(q, p) print('H(Q, P): %.3f bits' % ce_qp) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 计算交叉熵的示例 from math import log2 # 计算交叉熵 def cross_entropy(p, q): return -sum([p[i]*log2(q[i]) for i in range(len(p))]) # 定义数据 p = [0.10, 0.40, 0.50] q = [0.80, 0.15, 0.05] # 计算交叉熵 H(P, Q) ce_pq = cross_entropy(p, q) print('H(P, Q): %.3f bits' % ce_pq) # 计算交叉熵 H(Q, P) ce_qp = cross_entropy(q, p) print('H(Q, P): %.3f bits' % ce_qp) |
运行该示例,首先计算出 Q 相对于 P 的交叉熵略高于3比特,然后计算出 P 相对于 Q 的交叉熵略低于3比特。
|
1 2 |
H(P, Q): 3.288 比特 H(Q, P): 2.906 比特 |
计算一个分布与其自身的交叉熵
如果两个概率分布相同,那么它们之间的交叉熵将是该分布的熵。
我们可以通过计算 P vs P 和 Q vs Q 的交叉熵来证明这一点。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 计算相同分布交叉熵的示例 from math import log2 # 计算交叉熵 def cross_entropy(p, q): return -sum([p[i]*log2(q[i]) for i in range(len(p))]) # 定义数据 p = [0.10, 0.40, 0.50] q = [0.80, 0.15, 0.05] # 计算交叉熵 H(P, P) ce_pp = cross_entropy(p, p) print('H(P, P): %.3f bits' % ce_pp) # 计算交叉熵 H(Q, Q) ce_qq = cross_entropy(q, q) print('H(Q, Q): %.3f bits' % ce_qq) |
运行该示例,首先计算 Q vs Q 的交叉熵,其结果是 Q 的熵;然后计算 P vs P 的交叉熵,其结果是 P 的熵。
|
1 2 |
H(P, P): 1.361 比特 H(Q, Q): 0.884 比特 |
使用KL散度计算交叉熵
我们也可以使用KL散度来计算交叉熵。
用KL散度计算的交叉熵应该是完全相同的,同时计算分布之间的KL散度也可能很有趣,以了解相对熵或所需的额外比特数,而不是交叉熵计算的总比特数。
首先,我们可以定义一个函数来计算分布之间的KL散度,使用以2为底的对数,以确保结果的单位也是比特。
|
1 2 3 |
# 计算 kl 散度 KL(P || Q) def kl_divergence(p, q): return sum(p[i] * log2(p[i]/q[i]) for i in range(len(p))) |
接下来,我们可以定义一个函数来计算给定概率分布的熵。
|
1 2 3 |
# 计算熵 H(P) def entropy(p): return -sum([p[i] * log2(p[i]) for i in range(len(p))]) |
最后,我们可以使用 entropy() 和 kl_divergence() 函数来计算交叉熵。
|
1 2 3 |
# 计算交叉熵 H(P, Q) def cross_entropy(p, q): return entropy(p) + kl_divergence(p, q) |
为了保持示例简单,我们可以将 H(P, Q) 的交叉熵与 KL 散度 KL(P || Q) 和熵 H(P) 进行比较。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 使用 kl 散度计算交叉熵的示例 from math import log2 # 计算 kl 散度 KL(P || Q) def kl_divergence(p, q): return sum(p[i] * log2(p[i]/q[i]) for i in range(len(p))) # 计算熵 H(P) def entropy(p): return -sum([p[i] * log2(p[i]) for i in range(len(p))]) # 计算交叉熵 H(P, Q) def cross_entropy(p, q): return entropy(p) + kl_divergence(p, q) # 定义数据 p = [0.10, 0.40, 0.50] q = [0.80, 0.15, 0.05] # 计算 H(P) en_p = entropy(p) print('H(P): %.3f bits' % en_p) # 计算 kl 散度 KL(P || Q) kl_pq = kl_divergence(p, q) print('KL(P || Q): %.3f bits' % kl_pq) # 计算交叉熵 H(P, Q) ce_pq = cross_entropy(p, q) print('H(P, Q): %.3f bits' % ce_pq) |
运行示例后,我们可以看到交叉熵得分3.288比特是由P的熵1.361和KL散度计算出的额外1.927比特组成的。
这是一个有用的示例,清晰地展示了这三种计算之间的关系。
|
1 2 3 |
H(P): 1.361 比特 KL(P || Q): 1.927 比特 H(P, Q): 3.288 比特 |
交叉熵作为损失函数
在优化分类模型时,交叉熵被广泛用作损失函数。
你可能会遇到的两个例子包括逻辑回归算法(一种线性分类算法)和可用于分类任务的人工神经网络。
… 对于分类问题,使用交叉熵误差函数代替平方和误差函数,可以带来更快的训练速度和更好的泛化能力。
— 第235页,《模式识别与机器学习》,2006年。
分类问题是指那些涉及一个或多个输入变量并预测一个类别标签的问题。
输出变量只有两个标签的分类任务被称为二分类问题,而标签多于两个的问题则被称为类别或多类分类问题。
- 二分类:为给定样本预测两个类别标签中的一个的任务。
- 多类分类:为给定样本预测两个以上类别标签中的一个的任务。
我们可以看到,交叉熵的概念对于优化分类模型可能非常有用。
每个样本都有一个已知的类别标签,其概率为1.0,而所有其他标签的概率为0.0。模型可以估计一个样本属于每个类别标签的概率。然后可以使用交叉熵来计算这两个概率分布之间的差异。
因此,我们可以将一个样本的分类映射到具有概率分布的随机变量的概念上,如下所示:
- 随机变量:我们需要预测其类别标签的样本。
- 事件:可以预测的每个类别标签。
在分类任务中,我们知道一个输入的目标概率分布P,即类别标签0或1,分别解释为“不可能”或“确定”的概率。这些概率完全没有意外性,因此它们不包含信息内容,熵为零。
我们的模型旨在逼近目标概率分布 Q。
在分类的术语中,这些是实际概率和预测概率,或者说是 y 和 yhat。
- 期望概率 (y): 数据集中一个样本的每个类别标签的已知概率 (P)。
- 预测概率 (yhat): 模型预测的一个样本的每个类别标签的概率 (Q)。
因此,我们可以使用上面描述的交叉熵计算来估计单个预测的交叉熵;例如。
- H(P, Q) = – sum x in X P(x) * log(Q(x))
其中 X 中的每个 x 是一个可以分配给样本的类别标签,对于已知的标签,P(x) 将为 1,对于所有其他标签则为 0。
在二分类任务中,单个样本的交叉熵可以通过展开求和运算来表示,如下所示:
- H(P, Q) = – (P(class0) * log(Q(class0)) + P(class1) * log(Q(class1)))
你可能会在教科书中看到这种形式的交叉熵计算。
如果只有两个类别标签,概率模型通常采用正类标签的伯努利分布。这意味着类别1的概率由模型直接预测,而类别0的概率则为1减去预测的概率,例如:
- 预测的 P(class0) = 1 – yhat
- 预测的 P(class1) = yhat
在为分类任务计算交叉熵时,通常使用以e为底的自然对数。这意味着单位是纳特(nats),而不是比特(bits)。
我们通常感兴趣的是最小化模型在整个训练数据集上的交叉熵。这通过计算所有训练样本的平均交叉熵来实现。
计算类别标签的熵
回想一下,当两个分布相同时,它们之间的交叉熵等于该概率分布的熵。
在为分类任务准备数据时,类别标签通常使用值 0 和 1 进行编码。
例如,如果一个分类问题有三个类别,而一个样本的标签是第一类,那么其概率分布将是 [1, 0, 0]。如果一个样本的标签是第二类,它关于这两个事件的概率分布将是 [0, 1, 0]。这被称为独热编码。
这个概率分布不包含任何信息,因为结果是确定的。我们知道类别。因此,这个变量的熵为零。
这是一个重要的概念,我们可以通过一个实例来演示它。
假设我们有一个3分类问题,并且每个类别都有一个样本。我们可以将每个样本表示为一个离散的概率分布,其中样本所属类别的概率为1.0,其他所有类别的概率为0.0。
我们可以计算每个“变量”在所有“事件”上的概率分布的熵。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 来自一个有3个类别的分类任务的样本熵 from math import log2 from numpy import asarray # 计算熵 def entropy(p): return -sum([p[i] * log2(p[i]) for i in range(len(p))]) # 类别 1 p = asarray([1,0,0]) + 1e-15 print(entropy(p)) # 类别 2 p = asarray([0,1,0]) + 1e-15 print(entropy(p)) # 类别 3 p = asarray([0,0,1]) + 1e-15 print(entropy(p)) |
运行该示例会计算每个随机变量的熵。
我们可以看到,在每种情况下,熵都是0.0(实际上是一个非常接近零的数字)。
请注意,我们必须给0.0的值加上一个非常小的值,以避免log()函数计算出错,因为我们不能计算log(0.0)。
|
1 2 3 |
9.805612959471341e-14 9.805612959471341e-14 9.805612959471341e-14 |
因此,一个已知类别标签的熵总是0.0。
这意味着,对于一个类别标签,如果两个分布(真实分布和预测分布)具有相同的概率分布,它们的交叉熵也总是0.0。
回想一下,当我们在训练数据集上使用交叉熵评估模型时,我们会对数据集中所有样本的交叉熵求平均。
因此,在训练模型时,交叉熵为0.0表示预测的类别概率与训练数据集中的概率完全相同,即损失为零。
我们也可以同样地最小化KL散度作为损失函数,而不是交叉熵。
回想一下,KL散度是传输一个变量相比于另一个变量所需的额外比特数。它是交叉熵减去类别标签的熵,而我们知道类别标签的熵反正也是零。
因此,对于分类任务,最小化KL散度和最小化交叉熵是等价的。
最小化这个KL散度完全等同于最小化分布之间的交叉熵。
— 第132页,《深度学习》,2016年。
在实践中,交叉熵损失为0.0通常表明模型已经过拟合了训练数据集,但那是另一个话题了。
计算类别标签与概率之间的交叉熵
交叉熵在分类中的使用,常常根据类别数量有不同的特定名称,这与分类任务的名称相呼应;例如:
- 二元交叉熵:作为二分类任务损失函数的交叉熵。
- 分类交叉熵:作为多类分类任务损失函数的交叉熵。
我们可以通过一个实际的例子来具体说明如何使用交叉熵作为损失函数。
考虑一个二分类任务,包含以下10个实际类别标签(P)和预测类别标签(Q)。
|
1 2 3 4 |
... # 定义分类数据 p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3] |
我们可以列举这些概率,并使用上一节开发的交叉熵函数,通过 log()(自然对数)而不是 log2() 来计算每个概率的交叉熵。
|
1 2 3 |
# 计算交叉熵 def cross_entropy(p, q): return -sum([p[i]*log(q[i]) for i in range(len(p))]) |
对于每个实际概率和预测概率,我们必须将预测值转换为每个事件的概率分布,在这种情况下,类别 {0, 1} 的概率分别是 1 减去类别 0 的概率和类别 1 的概率。
然后,我们可以计算交叉熵,并对所有样本重复此过程。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 为每个样本计算交叉熵 results = list() for i in range(len(p)): # 为每个事件 {0, 1} 创建分布 expected = [1.0 - p[i], p[i]] predicted = [1.0 - q[i], q[i]] # 计算这两个事件的交叉熵 ce = cross_entropy(expected, predicted) print('>[y=%.1f, yhat=%.1f] ce: %.3f nats' % (p[i], q[i], ce)) results.append(ce) |
最后,我们可以计算数据集中所有样本的平均交叉熵,并将其作为模型在该数据集上的交叉熵损失报告。
|
1 2 3 4 |
... # 计算平均交叉熵 mean_ce = mean(results) print('Average Cross Entropy: %.3f nats' % mean_ce) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 计算分类问题的交叉熵 from math import log from numpy import mean # 计算交叉熵 def cross_entropy(p, q): return -sum([p[i]*log(q[i]) for i in range(len(p))]) # 定义分类数据 p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3] # 为每个样本计算交叉熵 results = list() for i in range(len(p)): # 为每个事件 {0, 1} 创建分布 expected = [1.0 - p[i], p[i]] predicted = [1.0 - q[i], q[i]] # 计算这两个事件的交叉熵 ce = cross_entropy(expected, predicted) print('>[y=%.1f, yhat=%.1f] ce: %.3f nats' % (p[i], q[i], ce)) results.append(ce) # 计算平均交叉熵 mean_ce = mean(results) print('Average Cross Entropy: %.3f nats' % mean_ce) |
运行该示例会打印出每个样本的实际和预测概率以及以纳特(nats)为单位的交叉熵。
最终报告了所有样本的平均交叉熵损失,本例中为 0.247 纳特。
|
1 2 3 4 5 6 7 8 9 10 11 |
>[y=1.0, yhat=0.8] ce: 0.223 nats >[y=1.0, yhat=0.9] ce: 0.105 nats >[y=1.0, yhat=0.9] ce: 0.105 nats >[y=1.0, yhat=0.6] ce: 0.511 nats >[y=1.0, yhat=0.8] ce: 0.223 nats >[y=0.0, yhat=0.1] ce: 0.105 nats >[y=0.0, yhat=0.4] ce: 0.511 nats >[y=0.0, yhat=0.2] ce: 0.223 nats >[y=0.0, yhat=0.1] ce: 0.105 nats >[y=0.0, yhat=0.3] ce: 0.357 nats 平均交叉熵: 0.247 纳特 |
这就是在使用交叉熵损失函数优化逻辑回归模型或神经网络模型时,交叉熵损失的计算方式。
使用 Keras 计算交叉熵
我们可以使用Keras深度学习API中的binary_crossentropy()函数来计算我们这个小数据集的交叉熵损失,从而验证同样的计算结果。
完整的示例如下所示。
注意:此示例假设您已安装Keras库(例如2.3或更高版本)并配置了后端库,如TensorFlow(2.0或更高版本)。如果没有,您可以跳过运行此示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 使用 keras 计算交叉熵 from numpy import asarray from keras import backend from keras.losses import binary_crossentropy # 准备分类数据 p = asarray([1, 1, 1, 1, 1, 0, 0, 0, 0, 0]) q = asarray([0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]) # 转换为 keras 变量 y_true = backend.variable(p) y_pred = backend.variable(q) # 计算平均交叉熵 mean_ce = backend.eval(binary_crossentropy(y_true, y_pred)) print('Average Cross Entropy: %.3f nats' % mean_ce) |
运行该示例,我们可以看到报告了相同的平均交叉熵损失 0.247 纳特。
这证实了手动计算交叉熵的正确性。
|
1 |
平均交叉熵: 0.247 纳特 |
对预测概率的交叉熵的直观理解
我们可以进一步深化对预测类别概率交叉熵的直观理解。
例如,既然平均交叉熵损失为0.0代表一个完美的模型,那么大于零的平均交叉熵值究竟意味着什么呢?
我们可以在一个二分类问题上探讨这个问题,其中类别标签为0和1。这是一个具有两个事件的离散概率分布,一个事件的概率是确定的,另一个事件的概率是不可能的。
然后,我们可以计算不同“预测”概率分布的交叉熵,这些分布从与目标分布完美匹配过渡到完全相反的概率分布。
我们预期,随着预测概率分布与目标分布的偏离越来越大,计算出的交叉熵也会增加。
下面的示例实现了这一点,并绘制了预测概率分布与目标[0, 1](对于两个事件)相比的交叉熵结果,就像我们在二分类任务中看到的交叉熵一样。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 预测概率分布与标签的交叉熵 from math import log from matplotlib import pyplot # 计算交叉熵 def cross_entropy(p, q, ets=1e-15): return -sum([p[i]*log(q[i]+ets) for i in range(len(p))]) # 为两个事件定义目标分布 target = [0.0, 1.0] # 为第一个事件定义概率 probs = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 为这两个事件创建概率分布 dists = [[1.0 - p, p] for p in probs] # 计算每个分布的交叉熵 ents = [cross_entropy(target, d) for d in dists] # 绘制概率分布与交叉熵的关系图 pyplot.plot([1-p for p in probs], ents, marker='.') pyplot.title('Probability Distribution vs Cross-Entropy') pyplot.xticks([1-p for p in probs], ['[%.1f,%.1f]'%(d[0],d[1]) for d in dists], rotation=70) pyplot.subplots_adjust(bottom=0.2) pyplot.xlabel('Probability Distribution') pyplot.ylabel('Cross-Entropy (nats)') pyplot.show() |
运行该示例会计算每个概率分布的交叉熵分数,然后将结果绘制成折线图。
我们可以看到,正如预期的那样,当预测的概率分布与目标分布匹配时,交叉熵从0.0开始(最左边的点),然后随着预测的概率分布偏离目标而稳定增加。
我们还可以看到,当预测的概率分布与目标分布完全相反时,即[1, 0]与目标[0, 1]相比,交叉熵出现了急剧的跳跃。
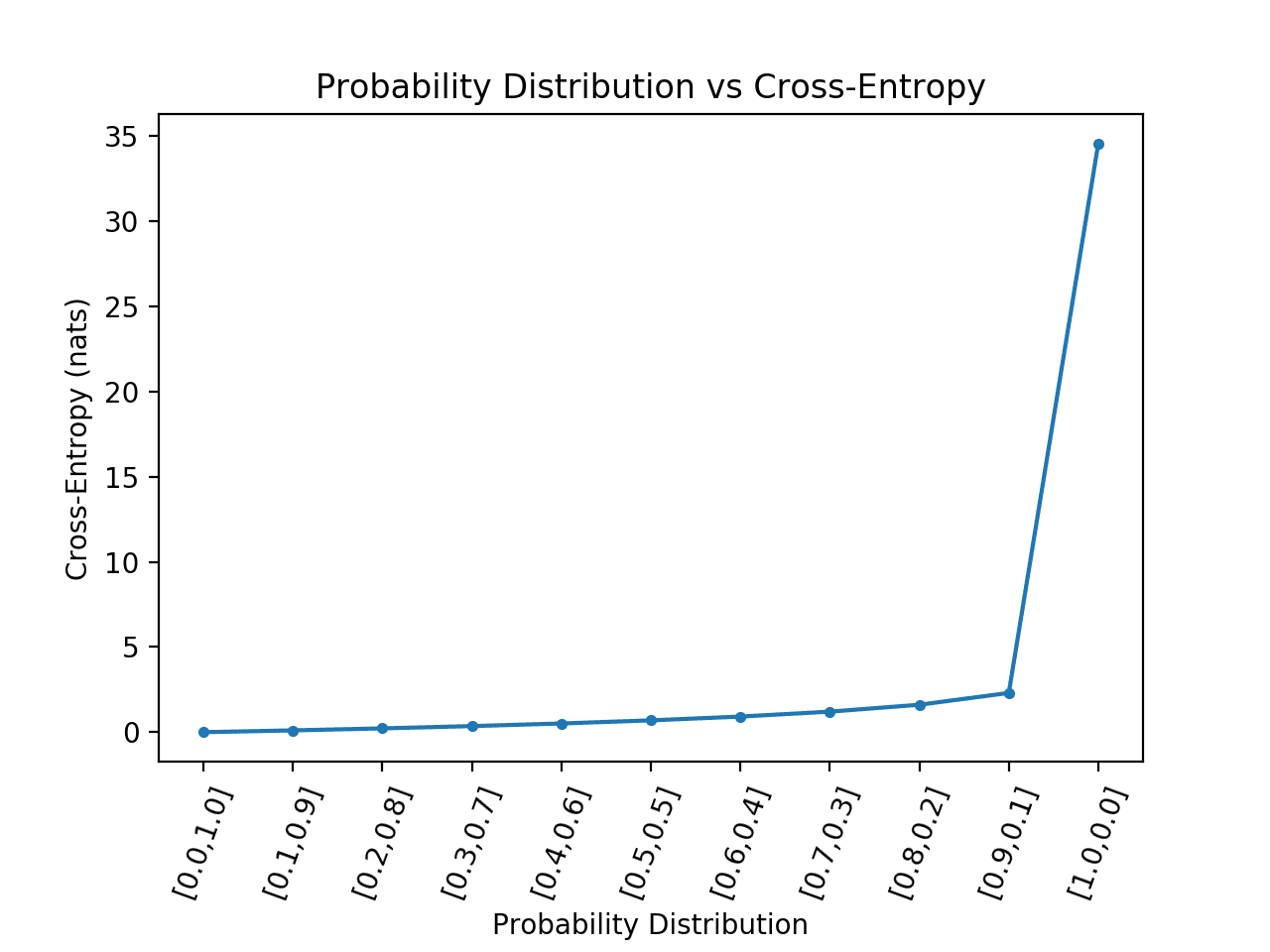
二分类任务中概率分布与交叉熵关系的折线图
对于二分类任务,我们的模型不会在所有情况下都预测出完全相反的概率分布。
因此,我们可以移除这种情况并重新计算该图。
下面列出了更新后的代码版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 预测概率分布与标签的交叉熵 from math import log from matplotlib import pyplot # 计算交叉熵 def cross_entropy(p, q, ets=1e-15): return -sum([p[i]*log(q[i]+ets) for i in range(len(p))]) # 为两个事件定义目标分布 target = [0.0, 1.0] # 为第一个事件定义概率 probs = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1] # 为这两个事件创建概率分布 dists = [[1.0 - p, p] for p in probs] # 计算每个分布的交叉熵 ents = [cross_entropy(target, d) for d in dists] # 绘制概率分布与交叉熵的关系图 pyplot.plot([1-p for p in probs], ents, marker='.') pyplot.title('Probability Distribution vs Cross-Entropy') pyplot.xticks([1-p for p in probs], ['[%.1f,%.1f]'%(d[0],d[1]) for d in dists], rotation=70) pyplot.subplots_adjust(bottom=0.2) pyplot.xlabel('Probability Distribution') pyplot.ylabel('Cross-Entropy (nats)') pyplot.show() |
运行该示例可以更好地理解概率分布差异与计算出的交叉熵之间的关系。
我们可以看到一个超线性关系,即预测概率分布与目标偏离得越多,交叉熵的增加就越大。

移除了极端情况的二分类任务中概率分布与交叉熵的折线图
这样的图可以用来指导解读二分类数据集上模型报告的平均交叉熵。
例如,您可以使用这些交叉熵值来解释 Keras 神经网络模型在二分类任务上报告的平均交叉熵,或者使用 logloss 指标评估的 scikit-learn 中的二分类模型。
你可以用它来回答一个普遍的问题:
什么是好的交叉熵分数?
如果你使用的是纳特(nats)(通常情况下都是),并且你的平均交叉熵低于0.2,那么你已经有了一个很好的开始;如果低于0.1或0.05,那就更好了。
另一方面,如果你的平均交叉熵大于0.2或0.3,你可能还有改进的空间;如果平均交叉熵大于1.0,那么你的模型在数据集中的许多样本上做出了很差的概率预测,肯定出问题了。
我们可以将这些关于平均交叉熵的直观理解总结如下:
- 交叉熵 = 0.00:完美的概率。
- 交叉熵 < 0.02:非常好的概率。
- 交叉熵 < 0.05:走在正确的轨道上。
- 交叉熵 < 0.20:还行。
- 交叉熵 > 0.30:不太好。
- 交叉熵 > 1.00:非常糟糕。
- 交叉熵 > 2.00:出问题了。
这个列表将为您解释逻辑回归模型或人工神经网络模型的交叉熵(对数损失)提供一个有用的指南。
您还可以为每个类别计算单独的平均交叉熵分数,这有助于弄清楚您的模型在哪些类别上具有良好的概率,而在哪些类别上可能出错了。
交叉熵与对数损失的比较
交叉熵不是对数损失,但当它们被用作分类问题的损失函数时,计算的是相同的量。
对数损失是负对数似然
逻辑损失是指通常用于优化逻辑回归模型的损失函数。
它也可能被称为对数损失(这容易引起混淆)或简称log loss。
许多模型是在一个称为最大似然估计(MLE)的概率框架下进行优化的,这涉及到寻找一组最能解释观测数据的参数。
这涉及到选择一个似然函数,该函数定义了在给定模型参数的情况下,一组观测(数据)的可能性。当使用对数似然函数时(这很常见),通常被称为优化模型的对数似然。因为在实践中最小化一个函数比最大化一个函数更常见,所以通过在前面添加一个负号来反转对数似然函数。这将其转换为负对数似然函数,简称NLL。
在最大似然估计框架下,为伯努利概率分布函数(两类)推导对数似然函数时,计算结果如下:
- 负对数似然(P, Q) = -(P(class0) * log(Q(class0)) + P(class1) * log(Q(class1)))
这个量可以通过计算所有训练样本的对数似然函数的平均值来得到。
对于二分类问题,负对数似然通常简称为“对数损失”,作为逻辑回归的损失函数。
- 对数损失 = 伯努利概率分布下的负对数似然
我们可以看到,负对数似然的计算与伯努利概率分布函数(两个事件或类别)的交叉熵计算是相同的。实际上,多项分布(多类别分类)的负对数似然也与交叉熵的计算相匹配。
关于对数损失和负对数似然的更多信息,请参阅教程:
对数损失和交叉熵计算的是相同的值
对于分类问题,“对数损失”、“交叉熵”和“负对数似然”是可以互换使用的。
更普遍地,在分类模型的损失函数语境中,“交叉熵”和“负对数似然”是可以互换使用的。
逻辑回归的负对数似然由[…]给出。这也被称为交叉熵误差函数。
— 第246页,《机器学习:概率视角》,2012年。
因此,计算对数损失将得到与计算伯努利概率分布的交叉熵相同的值。我们可以通过使用scikit-learn API中的log_loss()函数来计算对数损失来证实这一点。
对上一节中相同的实际概率和预测概率集计算平均对数损失,应该会得到与计算平均交叉熵相同的结果。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 使用 scikit-learn 计算分类问题的对数损失 from sklearn.metrics import log_loss from numpy import asarray # 定义分类数据 p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3] # 将数据定义为期望格式,例如每个事件 {0, 1} 的概率 y_true = asarray([[1-v, v] for v in p]) y_pred = asarray([[1-v, v] for v in q]) # 计算平均对数损失 ll = log_loss(y_true, y_pred) print('Average Log Loss: %.3f' % ll) |
运行该示例,得到预期的 0.247 对数损失结果,这与使用平均交叉熵计算出的 0.247 纳特相匹配。
|
1 |
平均对数损失:0.247 |
这并不意味着对数损失计算的是交叉熵,或者交叉熵计算的是对数损失。
相反,它们是源自不同研究领域的不同量,在为分类任务计算损失函数的条件下,最终得到了等价的计算和结果。具体来说,交叉熵损失函数等价于在伯努利或多项分布下的最大似然函数。
这展示了最大似然估计研究与信息论在离散概率分布上的联系。
这不仅限于离散概率分布,而这一事实对于许多初次听到的从业者来说是令人惊讶的。
具体而言,在最大似然估计框架下优化的线性回归,会为目标变量假设一个高斯连续概率分布,并涉及最小化均方误差函数。这等同于具有高斯概率分布的随机变量的交叉熵。
任何由负对数似然组成的损失函数,都是由训练集定义的经验分布与由模型定义的概率分布之间的交叉熵。例如,均方误差是经验分布与高斯模型之间的交叉熵。
— 第132页,《深度学习》,2016年。
这有点令人难以置信,它来自连续随机变量的微分熵领域。
这意味着,如果您计算覆盖相同事件(即具有相同的均值和标准差)的两个高斯随机变量之间的均方误差,那么您实际上是在计算这两个变量之间的交叉熵。
这也意味着,如果您正在使用均方误差损失来优化用于回归问题的神经网络模型,您实际上是在使用交叉熵损失。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
API
文章
总结
在本教程中,您了解了用于机器学习的交叉熵。
具体来说,你学到了:
- 如何从零开始以及使用标准的机器学习库计算交叉熵。
- 在优化逻辑回归和人工神经网络等分类模型时,交叉熵可用作损失函数。
- 交叉熵与KL散度不同,但可以使用KL散度计算;它也与对数损失不同,但在用作损失函数时计算的是相同的量。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨
感谢这篇博文。
让我有点困惑的是,在示例中,我们将标签 0 和 1 解释为用于计算目标分布和预测分布之间交叉熵的概率值!
如果标签是 4 和 7 而不是 0 和 1 呢?!
谢谢。
好问题。对于二元分类,无论标签是什么,我们都将它们映射到 0 和 1。
我建议阅读有关伯努利分布的资料。
https://machinelearning.org.cn/discrete-probability-distributions-for-machine-learning/
嗨,Jason,
一个小小的修正建议:在文章开头的“什么是交叉熵?”部分,您提到“结果将是一个以比特为单位的正数,如果两个概率分布相同,则为0。”。
然而,相同概率分布的交叉熵 H(P,P) 是该概率分布的熵 H(P),而相同概率分布的 KL 散度确实会得到零。
谢谢,
Ron U
谢谢 Ron!
我会安排时间更新帖子,并给出一个你所指情况的具体例子。例如。
H(P, P): 1.361 比特
H(Q, Q): 0.884 比特
更新:我已经更新了帖子,以正确地讨论这种情况。
再次感谢!
为什么不用
zip?谢谢你的提示,Hugh,这是一个更简洁的方法!
尊敬的Jason博士,
在“如何计算交叉熵”小标题下的最后几行,您给出了一个简单的例子,输出如下
请问用‘通俗易懂’的语言解释一下这些数字的含义。
例如,如果上面的例子产生以下结果
或者如果我们有这个
这是另一个虚构数字的例子。
将第一个输出与“虚构数字”进行比较,比特数越低是否意味着拟合得更好?模型更可预测?
另外
我理解比特是一个二进制数。例如 1 = 1(十进制),11 = 3(十进制),101 = 5(十进制)。
二进制系统中的比特数是一个整数。比特的分数是什么意思?
悉尼的Anthony
我们通常使用交叉熵来评估模型,例如,比较真实类别与概率预测。
在这种情况下,我们会比较在所有样本上计算的平均交叉熵,较低的值代表更好的拟合。解释具体的数值通常没有太大用处。
尊敬的Jason博士,
谢谢您的回复。
请问另一个问题
怎么会有小数比特呢?例如熵 = 3.2285 比特。0.2285 比特是什么意思?
谢谢你,
悉尼的Anthony
回想一下,这是一个包含许多事件的分布的平均值。
更多地把它看作一个度量,而不是计算机中清晰的比特。
很棒的文章,希望能看到更多关于机器学习和人工智能的内容。
谢谢!
你好,
您能为“全为0或全为1的值或这些值的混合的分布的熵将等于0.0。”这句话提供一个例子吗?
这是否意味着一个包含这些值的混合分布,例如 P(X=1) = 0.4 和 P(X=0) = 0.6 的分布,其熵为零?但这应该是不对的,因为 0.4 * log(0.4) + 0.6 * log(0.6) 不为零。
谢谢!
好问题。
抱歉,这确实令人困惑。
我的意思是类别标签的概率分布将始终为零。
我已更新教程使其更清晰,并给出了一个计算示例。
嗨 Jason!这是我见过的关于交叉熵和 KL 散度的最好的文章!我终于能理解它们了 😉 非常感谢这篇内容全面的文章。
我有一个小问题:在“对预测概率的交叉熵直观理解”部分,第一个用于绘制可视化的代码块中,代码如下
# 为两个事件定义目标分布
target = [0.0, 0.1]
# 为第一个事件定义概率
probs = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
# 为这两个事件创建概率分布
dists = [[p, 1.0 – p] for p in probs]
# 计算每个分布的交叉熵
ents = [cross_entropy(target, d) for d in dists]
我不太明白为什么两个事件的目标概率是 [0.0, 0.1]?您能再解释一下吗?谢谢!
谢谢!我在这上面花了很多功夫,很高兴能得到赞赏 🙂
是的,看起来是个笔误。我会尽快修复它。它应该是 [0,1]。
更新:我已经更新了代码并重新生成了图表。再次感谢!
Jason,我非常感谢您关于机器学习主题的各种帖子。如果可以的话,我想就我过去觉得有帮助的一点补充一下评论。
我看到这里没有真正强调的一点,而我在其他资料中(例如 https://tdhopper.com/blog/cross-entropy-and-kl-divergence/)看到过,那就是交叉熵和KL散度“相差一个常数”,即在您的表达式中
H(P, Q) = H(P) + KL(P || Q),
H(P) 相对于 Q 是一个常数。在大多数机器学习任务中,P 通常被固定为“真实”分布,而 Q 是我们通过迭代试图完善以匹配 P 的分布。
“在许多这些情况下,????被视为'真实'分布,而????是我们试图优化的模型.... 因为????是固定的,????(????) 不会随模型的参数而改变,并且可以在损失函数中被忽略。” (https://stats.stackexchange.com/questions/265966/why-do-we-use-kullback-leibler-divergence-rather-than-cross-entropy-in-the-t-sne/265989)
您在说“因此,对于分类任务,最小化 KL 散度和交叉熵是等价的”时确实提到了这一点。
然而,至少对我来说,知道这两者“相差一个常数”使得直观上很明显为什么最小化一个等于最小化另一个,即使它们实际上旨在衡量不同的事物。
...因此,我认为这个“相差一个常数”是人们对交叉熵与 KL 散度感到困惑的另一个原因,也是为什么像您这样的指南如此有帮助!
谢谢你的留言,Scott。
是的,H(P) 是分布的熵。当类别标签为 0 和 1 时,它变为 0。我在文章末尾谈论类别标签时概述了这一点。
在这种情况下,常数为 0 意味着使用 KL 散度和交叉熵会得到相同的数值,即 KL 散度的值。
感谢这篇很棒的文章!
但让我困惑的是,您在文章中提到
”
结果将是一个以比特为单位的正数,如果两个概率分布相同,它将等于该分布的熵。”
然后又提到
“如果两个概率分布相同,那么它们之间的交叉熵将是该分布的熵。”
然后
“这意味着,对于一个类别标签,如果两个分布(真实的和预测的)具有相同的概率分布,那么它们的交叉熵也将始终为 0.0。”
“因此,在训练模型时,交叉熵为 0.0 表示预测的类别概率与训练数据集中的概率完全相同,即损失为零。”
我是否错过了什么?
这些陈述是正确的。
如果分布相同,交叉熵将等于分布间的熵。
在这种情况下,如果我们处理像 0 和 1 这样的类别标签,那么两个相同分布的熵将为零。
我们在上面的教程中通过一个计算示例演示了这一点。
这有帮助吗?
这与例子无关,它们都很好理解,谢谢。
只是我无法从数值上想象和理解它们。
再次阅读后我明白了,当任何分布的值只有1或0时,熵、交叉熵、KL散度都将为零。
只有当它们的值在0和1之间时,它们才会有数值。
正是如此!
早上好,Jason!
谢谢你这篇很棒的帖子!
关于 KL 散度的问题:在其定义中,我们有 log2(p[i]/q[i]),这表明可能出现除以零的错误。这在实际应用中会是一个可能的问题吗?还是由于某些原因它不会发生?
此致!
好问题,没问题,因为概率总是大于零,所以对数永远不会爆炸。
这里还有更多关于kl散度的内容
https://machinelearning.org.cn/divergence-between-probability-distributions/
是否可以把KL散度用作分类标准?
可能可以,当使用类别标签而不是概率时,它会和对数损失以及交叉熵相同。
谢谢你的回复。那么,假设最终的计算结果是“平均对数损失”,这个值意味着什么?
期望值和预测值的概率分布之间的平均差异,以比特为单位。
你好 Jason,祝贺你的解释。你好吗?我有一个疑问。如果我遇到 log(0),我的交叉熵会得到 -Inf。我应该用某个值替换 -Inf 吗?如果需要,应该用什么值?
祝好,
Gledson。
你不能对零取对数。一个好主意是总是在要取对数的值上加上一个非常小的值,例如 log(value + 1e-8)
嗨,Jason,
感谢您所有精彩的帖子,我已经读过其中一些了。
我正在研究流量分类,并已将我的数据转换为比特串,我想在字节上使用交叉熵。
假设有以下列表
p = [1, 0, 1, 1, 0, 0, 1, 0]
q = [1, 1, 1, 0, 1, 0, 0, 1]
当我使用
-sum([p[i] * log2(q[i]) for i in range(len(p))])时,我遇到了这个错误:ValueError: math domain error。S您能告诉我哪里做错了吗,以及如何在一个比特列表上实现交叉熵?
祝好,
不能计算 0.0 的对数。尝试在方程中添加一个很小的值,例如 1e-8 或 1e-15
我已经将流量转换成比特串,它不只是一些我可以随便添加任何值的随机数。
为什么我们在交叉熵中使用对数函数?
好问题,也许可以从这里开始
https://machinelearning.org.cn/what-is-information-entropy/
谢谢您!!
不客气。
你好 Jason,
非常感谢您所有精彩的帖子。
我有一个问题,如果我们有条件熵 H(y|x)=-sum P(x,y) log(P(y|x)
我们能说它等于交叉熵 H(x,y) = - sum y log y^ 吗?
如果这是正确的,我们可以在什么情况下这么说?即,在什么假设下。
先谢谢您了。
我想你是在问我条件熵是否与交叉熵相同。我粗略想来觉得不是,但或许可以查阅一本好的教科书来确认。
非常感谢您的回复,
我是在“Privacy-Preserving Adversarial Networks”这篇论文中看到的,作者们将条件熵作为成本函数,但在他们实现文章时,却使用了交叉熵。但他们没有说明为什么?
真有意思。
也许可以直接给作者发邮件。
在文本生成中,每个字符的比特数怎么能等于损失呢?
也许可以尝试重读上面详细阐述的教程。
这是对交叉熵极好的介绍。似乎以下句子之一在表述“意外程度”概念时可能有笔误。我的第一印象是第二句话应该说“不那么意外”。是这样吗?
“低概率事件更令人意外,因此含有更多的信息量。而事件等可能性的概率分布更令人意外,且具有更大的熵。”
谢谢。
是的,可以更清楚些。信息是关于事件的,熵是关于分布的,交叉熵是关于比较分布的。
在谈论信息/事件时,“意外”的含义与谈论熵/分布时不同。
我在教程开始时混淆了这两者的讨论。我已经更新了文本,使其更加清晰。
另请参阅此
https://machinelearning.org.cn/what-is-information-entropy/
这有帮助吗?
经过进一步考虑,第二句话似乎可以这样理解。
“在事件等可能性的概率分布中,没有事件具有更大或更小的可能性(分别对应更小或更大的意外程度),并且该分布具有更大的熵。”
抱歉纠缠于此。这是一个好观点,但有时会令人困惑。
人们说,当你能用非常简单的词语来描述一个概念时,你就已经理解了它,我觉得这里就是这种情况。做得非常棒!
谢谢!
“相对熵(KL 散度):用 Q 代替 P 表示一个事件所需的平均额外比特数。”
难道不应该说:相对熵(KL 散度):用 Q 代替 P 来表示一个来自 P 的事件所需的平均额外比特数。
因为期望是基于 P(x)*[…] 的。
亲爱的 Jason,
感谢您清晰的解释。为什么“在分类问题中使用交叉熵误差函数而不是平方和误差函数,可以带来更快的训练速度和更好的泛化能力”?
它更符合优化问题的目标。
感谢您的精彩解释。我正在训练一个神经网络,请问这个结果对于
数据集 准确率 交叉熵损失
训练集 97% 0.07
验证集 96.5% 0.48
测试集 98% 0.13
也许应该专注于你想要优化的指标,而不是损失。
嗨,Jason,
请问您能指导一下如何利用相关熵(correntropy)进行回归问题优化吗?
我认为交叉熵不适用于回归问题。您将如何定义所需的概率分布呢?
相关熵(交叉熵的一个特例)是一种非线性局部相似性度量,用于衡量两个随机变量在联合空间邻域内的相似性。
C. Liangjun, P. Honeine, Q. Hua, Z. Jihong, and S. Xia, “Correntropy- based robust multilayer extreme learning machines,” Pattern Recognit., vol. 84, pp. 357–370, Dec. 2018.
谢谢指出。我以为那是个笔误。查看所引论文的公式(13)和(14),您会发现它是均方误差(MSE)的修改版本。问题在于您需要创建自己的函数(例如,我没有看到 scikit-learn 中定义了相关熵),而且并非所有模型都允许您插入自己的损失函数。可能 scikit-learn 中的线性回归库无法做到这一点,您需要借助 scipy 来手动进行回归。
我明白了
谢谢 Adiran
Adrian 博士您好,
感谢您的宝贵意见,让我有了更深的理解。在实现过程中,我正在使用标签平滑(loss=tensorflow.keras.losses.CategoricalCrossentropy(label_smoothing=0.2))作为正则化器来提高性能。我观察到,虽然性能有相当不错的提升,但训练和验证损失仍然很高(接近0.5),尽管性能学习曲线收敛得很好。不使用标签平滑时,损失会降得很低(接近0.1),但收敛得不好或显示出过拟合。
我想知道
1. 这种在拟合良好时接近 0.5 的高损失是否可以接受?
2. 我有什么办法可以降低这个损失吗?
3. 您有标签平滑的替代建议吗?
注意:我在所有博客中都观察到标签平滑会导致这种损失增加。
恳请指导。
损失是一个连续的度量。因此,对于分类任务,我们还应该关注准确率。检查一下准确率,看看是否能给你更好的思路。
感谢指导。我会在这方面下功夫。
不客气。
你好
我正在研究交叉熵,我想计算两条路径之间的交叉熵;
作者在他的论文中写的代码是
交叉熵
输入
序列 X,序列 Y
输出
e:X 和 Y 的交叉熵
开始
for (int n=1; n<5; n++)
开始
for each (ngram in X.ngrams(n)) //读取 X 中长度为 n 的每个 ngram
开始
(token, history) = split (ngram);//拆分 ngram,使得 ngram = history + token
a = X.P(ngram);//ngram 在 X 序列中的概率
b = Y.ConditionalP(token,history);//在 Y 序列中给定 history 的 token 的概率
logb = (b!=0 ? Log(b) : Log(1/X.ngramCount));
c = a × logb;
e += c;
结束
结束
结束
你能帮我用 python 写这个吗??
感谢您的询问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
感谢您提供的交叉熵教程,非常感谢您的工作!不过我发现了一个小笔误,“discrete states” 在这句话中重复了两次:“Entropy H(x) can be calculated for a random variable with a set of x in X discrete states discrete states and their probability P(x) as follows:”
感谢您的反馈,Ayla!
笔误:熵 H(x) 可以通过以下方式计算,对于一个随机变量,其在 X 中的离散状态集合 x discrete states discrete states 及其概率 P(x)
“discrete states” 出现了两次
请告知,最大熵马尔可夫模型(MEMM)和多项式逻辑回归是否相同?我们如何在 weka 或 python 中实现 MEMM。
嗨,DataScientist...您可能会对以下资源感兴趣
https://www.davidsbatista.net/blog/2017/11/12/Maximum_Entropy_Markov_Model/
https://www.researchgate.net/publication/263037664_Intrusion_Detection_with_Hidden_Markov_Model_and_WEKA_Tool
亲爱的 Jason,
我正在尝试为图像分割实现自定义的二元交叉熵损失函数,但结果与 keras 后端损失函数不一致。您能在这方面帮助我吗?
在此先感谢。
嗨 Prasun...请查看关于同一主题的邮件。
你好 James,感谢你写出如此详尽的文章。
我对
对预测概率的交叉熵直观理解这一节有一个疑问。在代码中你写道# 定义两个事件的目标分布
target = [0.0, 1.0]
# 定义第一个事件的概率
probs = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0]
# 为两个事件创建概率分布
dists = [[1.0 - p, p] for p in probs]
注释 `定义第一个事件的概率` 难道不应该是 `定义第二个事件的概率` 吗?因为根据图表,从 (0.0, 1.0) 开始,这实际上与目标匹配,交叉熵/损失是最小的?
嗨 Shubham... 不太确定我理解你的疑问,但我会复查一下。感谢你的意见!
抱歉说得不够清楚。让我试着用更好的方式解释一下。在“对预测概率的交叉熵直观理解”部分,有如上一个评论中提到的代码。
在代码中,有一条注释“定义第一个事件的概率”。那条注释不应该是“定义第二个事件的概率”吗?我之所以这么问,是因为当我们计算“dists”变量时,我们是这样做的:“[[1.0 – p, p] for p in probs]”,这是否意味着“probs”中给出的“p”是针对第二个事件的?
如果我的理解有误,请告诉我。