曲线拟合是一种优化,它为某个定义的函数找到一组最佳参数,该函数最适合给定的观测数据集。
与监督学习不同,曲线拟合要求您定义将示例输入映射到输出的函数。
这个映射函数,也称为基函数,可以是你喜欢的任何形式,包括直线(线性回归)、曲线(多项式回归)等等。这提供了定义曲线形状的灵活性和控制力,其中优化过程用于查找函数特定的最佳参数。
在本教程中,您将了解如何在 Python 中执行曲线拟合。
完成本教程后,您将了解:
- 曲线拟合涉及为将示例输入映射到输出的函数找到最佳参数。
- SciPy Python 库提供了用于曲线拟合的 API,可以拟合数据集的曲线。
- 如何在 SciPy 中使用曲线拟合来拟合一系列不同的曲线到一组观测值。
开始您的项目,请阅读我的新书《机器学习优化》,其中包含分步教程和所有示例的Python 源文件。
让我们开始吧。
Python 曲线拟合
照片由 Gael Varoquaux 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 曲线拟合
- 曲线拟合 Python API
- 曲线拟合示例
曲线拟合
曲线拟合是一个优化问题,它找到一条最适合一系列观测值的线。
最容易在二维空间中考虑曲线拟合,例如图表。
考虑我们已经从问题领域收集了输入和输出的示例数据。
x 轴是自变量或函数的输入。 y 轴是因变量或函数的输出。我们不知道将示例输入映射到输出的函数形式,但我们怀疑我们可以用标准的函数形式来近似该函数。
曲线拟合首先包括定义映射函数(也称为 基函数或目标函数)的函数形式,然后搜索函数参数以最小化误差。
误差的计算方法是使用领域中的观测值,将输入传递到我们候选的映射函数,计算输出,然后将计算出的输出与观测到的输出进行比较。
拟合后,我们可以使用映射函数来插值或外插领域中的新点。通常,我们会将一系列输入值通过映射函数进行计算,得出一系列输出值,然后绘制结果的折线图,以显示输出随输入的变化情况以及该线与观测点的拟合程度。
曲线拟合的关键在于映射函数的形式。
输入和输出之间的直线可以定义为
- y = a * x + b
其中 *y* 是计算出的输出,*x* 是输入,*a* 和 *b* 是使用优化算法找到的映射函数的参数。
这被称为线性方程,因为它是一个加权输入和。
在线性回归模型中,这些参数被称为系数;在神经网络中,它们被称为权重。
这个方程可以推广到任意数量的输入,这意味着曲线拟合的概念不限于二维(一个输入和一个输出),但可以有许多输入变量。
例如,对于两个输入变量的线性映射函数可能如下所示
- y = a1 * x1 + a2 * x2 + b
方程不一定是直线。
我们可以通过添加指数来在映射函数中添加曲线。例如,我们可以添加一个加权的输入平方项
- y = a * x + b * x^2 + c
这被称为 多项式回归,而平方项意味着它是一个二次多项式。
到目前为止,可以通过最小化最小二乘法来拟合这类线性方程,并且可以解析计算。这意味着我们可以使用一些线性代数来找到参数的最佳值。
我们也可能希望将其他数学函数添加到方程中,例如正弦、余弦等。每个项都由一个参数加权并加到整体中以得到输出;例如
- y = a * sin(b * x) + c
将任意数学函数添加到我们的映射函数中,通常意味着我们无法解析计算参数,而是需要使用迭代优化算法。
这被称为 非线性最小二乘法,因为目标函数不再是凸的(它是非线性的),并且不易求解。
既然我们对曲线拟合有了初步了解,让我们看看如何在 Python 中执行曲线拟合。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
曲线拟合 Python API
我们可以在 Python 中为我们的数据集执行曲线拟合。
SciPy 开源库提供了 curve_fit() 函数,用于通过非线性最小二乘法进行曲线拟合。
该函数将与输入和输出数据相同的参数,以及要使用的映射函数的名称作为参数。
映射函数必须接受输入数据样本和一些参数。这些剩余的参数将是通过非线性最小二乘优化过程进行优化的系数或权重常数。
例如,我们可能有一些从领域中加载的观测值,作为输入变量 *x* 和输出变量 *y*。
|
1 2 3 4 |
... # 从文件中加载输入变量 x_values = ... y_values = ... |
接下来,我们需要设计一个映射函数来拟合数据中的一条线,并将其实现为一个接受输入和参数的 Python 函数。
它可以是一条直线,在这种情况下,它看起来会像这样
|
1 2 3 |
# 目标函数 def objective(x, a, b, c): return a * x + b |
然后,我们可以调用 curve_fit() 函数,使用我们定义的函数来拟合数据集中的一条直线。
函数 *curve_fit()* 返回映射函数的最佳值,例如系数的值。它还返回估计参数的协方差矩阵,但目前我们可以忽略它。
|
1 2 3 |
... # 拟合曲线 popt, _ = curve_fit(objective, x_values, y_values) |
拟合完成后,我们可以使用最佳参数和我们的映射函数 *objective()* 来计算任意输入的输出。
这可能包括我们已经从领域收集的示例的输出,可能包括插值观测值的新值,或者可能包括超出观测值范围的外插值。
|
1 2 3 4 5 6 7 |
... # 定义新的输入值 x_new = ... # 解压目标函数的最佳参数 a, b, c = popt # 使用最佳参数计算新值 y_new = objective(x_new, a, b, c) |
既然我们已经熟悉了使用曲线拟合 API,让我们来看一个实际示例。
曲线拟合示例
我们将开发一条曲线来拟合一些经济数据的真实观测值。
在此示例中,我们将使用所谓的“Longley 经济回归”数据集;您可以在此处了解更多信息
在实际示例中,我们将自动下载数据集。
该数据集有七个输入变量和 16 行数据,其中每行定义了 1947 年至 1962 年间经济细节的摘要。
在此示例中,我们将探讨拟合人口规模与就业人数之间的关系。
下面的示例从 URL 加载数据集,选择“人口”作为输入变量,选择“就业”作为输出变量,并创建散点图。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制“人口”与“就业”的关系图 from pandas import read_csv from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/longley.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 选择输入和输出变量 x, y = data[:, 4], data[:, -1] # 绘制输入与输出的关系图 pyplot.scatter(x, y) pyplot.show() |
运行示例加载数据集,选择变量,并创建散点图。
我们可以看到这两个变量之间存在关系。具体来说,随着人口的增加,就业总人数也在增加。
认为我们可以拟合一条直线到这些数据是合理的。
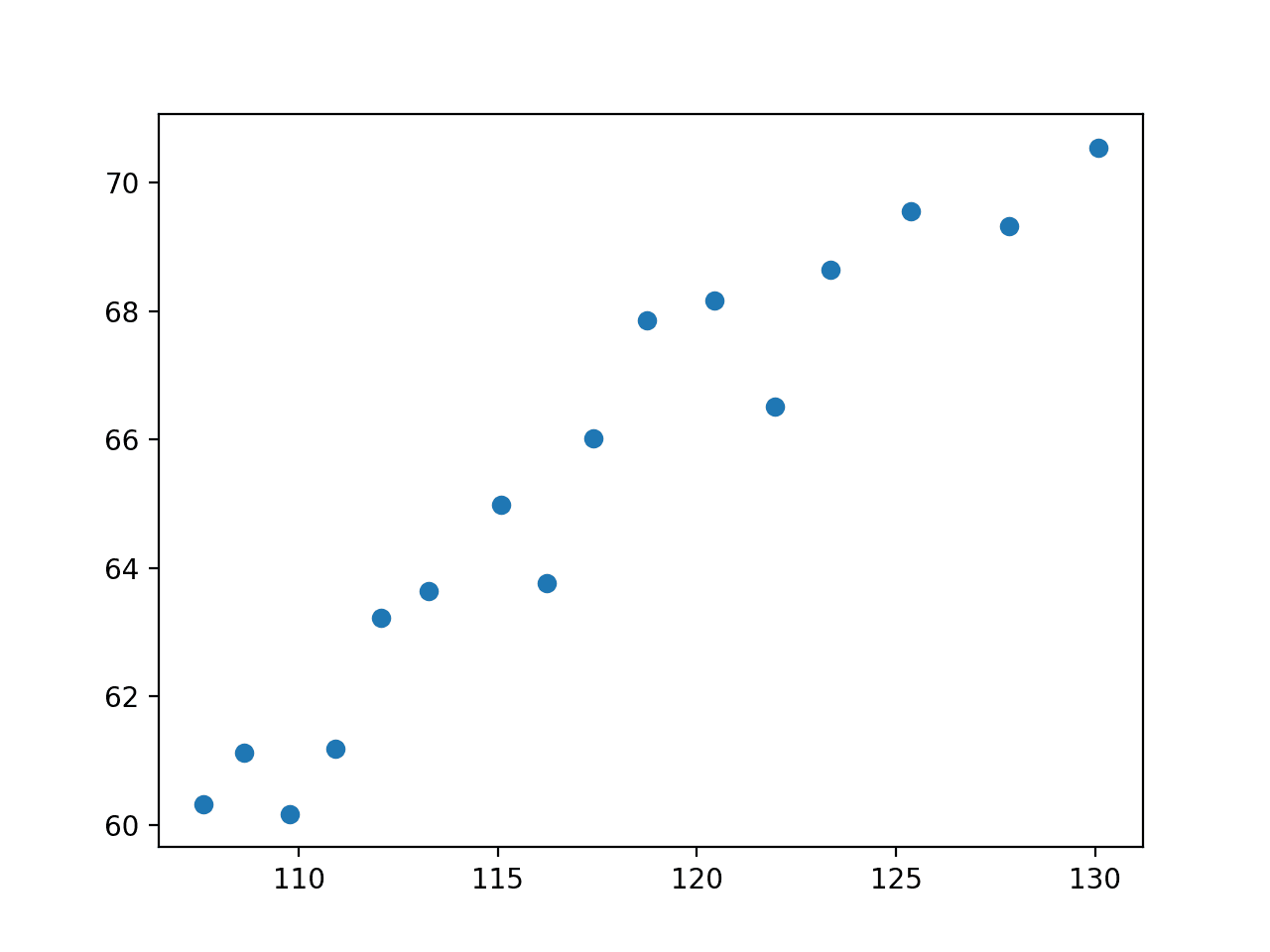
人口与总就业人数的散点图
首先,我们将尝试拟合一条直线到这些数据,如下所示
|
1 2 3 |
# 定义真实的目标函数 def objective(x, a, b): return a * x + b |
我们可以使用曲线拟合来查找“a”和“b”的最佳值,并总结找到的值
|
1 2 3 4 5 6 |
... # 曲线拟合 popt, _ = curve_fit(objective, x, y) # 总结参数值 a, b = popt print('y = %.5f * x + %.5f' % (a, b)) |
然后,我们可以像以前一样创建散点图。
|
1 2 3 |
... # 绘制输入与输出的关系图 pyplot.scatter(x, y) |
在散点图之上,我们可以绘制具有优化参数值的函数线。
这包括首先定义一个介于数据集中观察到的最小值和最大值之间的输入值序列(例如,在 120 到 130 之间)。
|
1 2 3 |
... # 定义介于最小和最大已知输入值之间的输入序列 x_line = arange(min(x), max(x), 1) |
然后,我们可以计算每个输入值的输出值。
|
1 2 3 |
... # 计算该范围内的输出值 y_line = objective(x_line, a, b) |
然后绘制输入与输出的折线图以查看该线
|
1 2 3 |
... # 为映射函数创建折线图 pyplot.plot(x_line, y_line, '--', color='red') |
总而言之,下面的示例使用曲线拟合来查找我们经济数据的直线参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 拟合经济数据的直线 from numpy import arange from pandas import read_csv from scipy.optimize import curve_fit from matplotlib import pyplot # 定义真实的目标函数 def objective(x, a, b): return a * x + b # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/longley.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 选择输入和输出变量 x, y = data[:, 4], data[:, -1] # 曲线拟合 popt, _ = curve_fit(objective, x, y) # 总结参数值 a, b = popt print('y = %.5f * x + %.5f' % (a, b)) # 绘制输入与输出的关系图 pyplot.scatter(x, y) # 定义介于最小和最大已知输入值之间的输入序列 x_line = arange(min(x), max(x), 1) # 计算该范围内的输出值 y_line = objective(x_line, a, b) # 为映射函数创建折线图 pyplot.plot(x_line, y_line, '--', color='red') pyplot.show() |
运行示例执行曲线拟合,并找到我们目标函数的最佳参数。
首先,报告了参数的值。
|
1 |
y = 0.48488 * x + 8.38067 |
接下来,创建了一个图表,显示原始数据和拟合到数据的线。
我们可以看到这是一个相当不错的拟合。
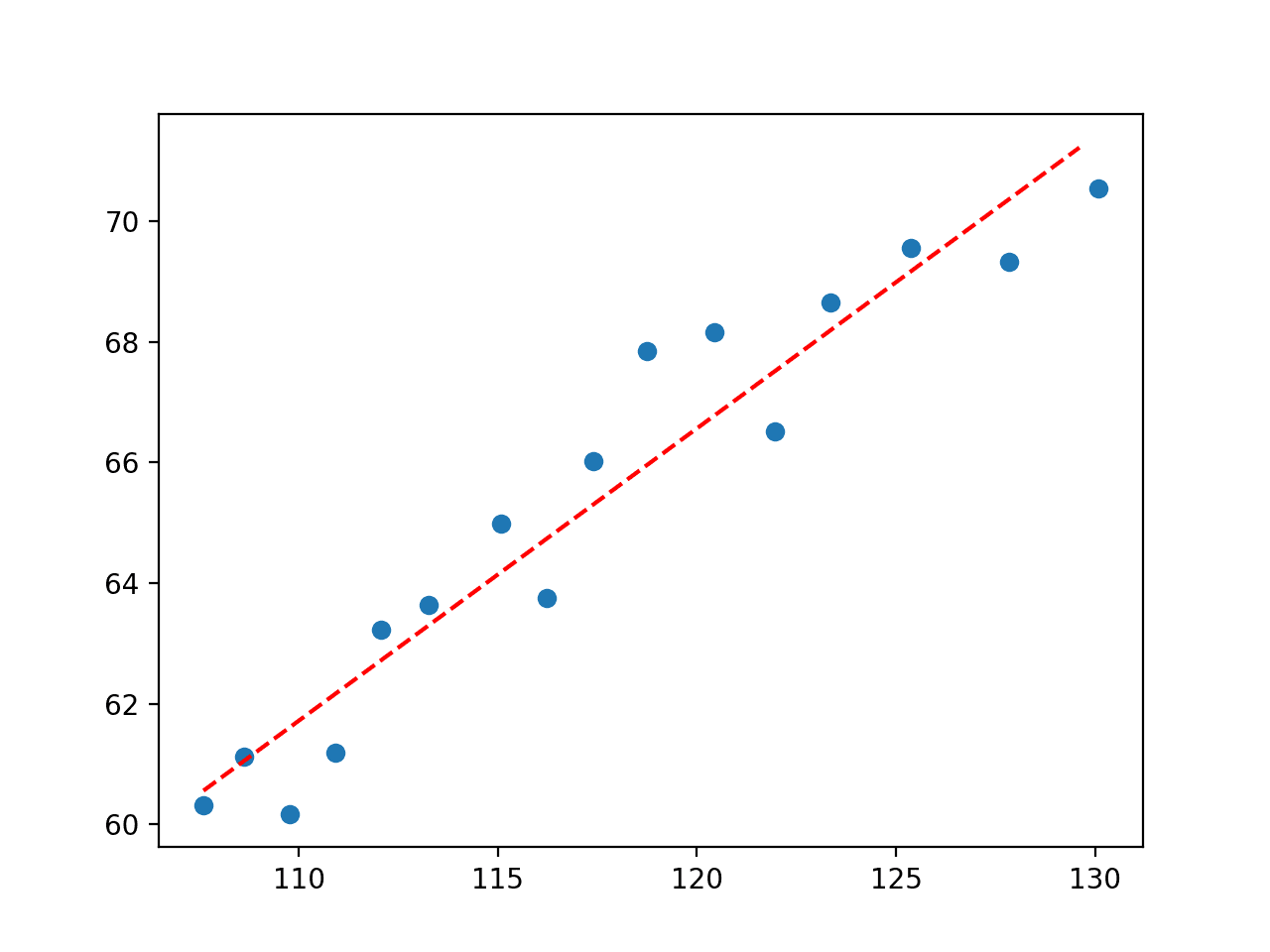
经济数据集直线拟合图
到目前为止,这并不令人兴奋,因为我们可以通过在数据上拟合线性回归模型来实现相同的效果。
让我们通过在目标函数中添加平方项来尝试多项式回归模型。
|
1 2 3 |
# 定义真实的目标函数 def objective(x, a, b, c): return a * x + b * x**2 + c |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 拟合经济数据的二次多项式 from numpy import arange from pandas import read_csv from scipy.optimize import curve_fit from matplotlib import pyplot # 定义真实的目标函数 def objective(x, a, b, c): return a * x + b * x**2 + c # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/longley.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 选择输入和输出变量 x, y = data[:, 4], data[:, -1] # 曲线拟合 popt, _ = curve_fit(objective, x, y) # 总结参数值 a, b, c = popt print('y = %.5f * x + %.5f * x^2 + %.5f' % (a, b, c)) # 绘制输入与输出的关系图 pyplot.scatter(x, y) # 定义介于最小和最大已知输入值之间的输入序列 x_line = arange(min(x), max(x), 1) # 计算该范围内的输出值 y_line = objective(x_line, a, b, c) # 为映射函数创建折线图 pyplot.plot(x_line, y_line, '--', color='red') pyplot.show() |
首先报告了最佳参数。
|
1 |
y = 3.25443 * x + -0.01170 * x^2 + -155.02783 |
接下来,创建了一个图表,显示了该线与领域中的观测值之间的关系。
我们可以看到我们定义的三次多项式方程在视觉上比我们首先测试的直线更适合数据。
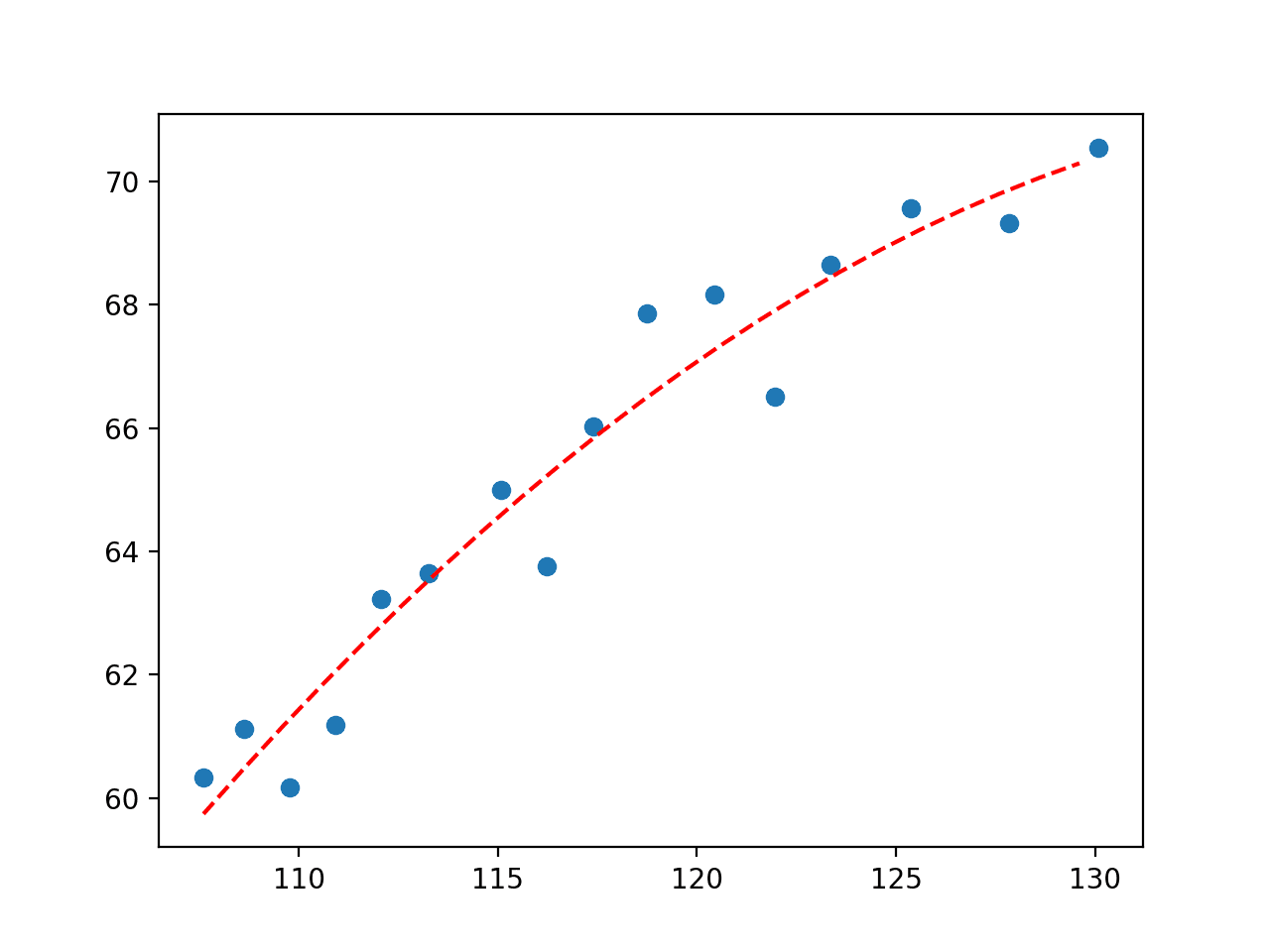
经济数据集二次多项式拟合图
我们可以继续添加更多的多项式项到方程中以更好地拟合曲线。
例如,下面是一个将五次多项式拟合到数据的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 拟合经济数据的五次多项式 from numpy import arange from pandas import read_csv from scipy.optimize import curve_fit from matplotlib import pyplot # 定义真实的目标函数 def objective(x, a, b, c, d, e, f): return (a * x) + (b * x**2) + (c * x**3) + (d * x**4) + (e * x**5) + f # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/longley.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 选择输入和输出变量 x, y = data[:, 4], data[:, -1] # 曲线拟合 popt, _ = curve_fit(objective, x, y) # 总结参数值 a, b, c, d, e, f = popt # 绘制输入与输出的关系图 pyplot.scatter(x, y) # 定义介于最小和最大已知输入值之间的输入序列 x_line = arange(min(x), max(x), 1) # 计算该范围内的输出值 y_line = objective(x_line, a, b, c, d, e, f) # 为映射函数创建折线图 pyplot.plot(x_line, y_line, '--', color='red') pyplot.show() |
运行示例可以拟合曲线并绘制结果,再次捕捉了数据关系随时间变化的细微之处。
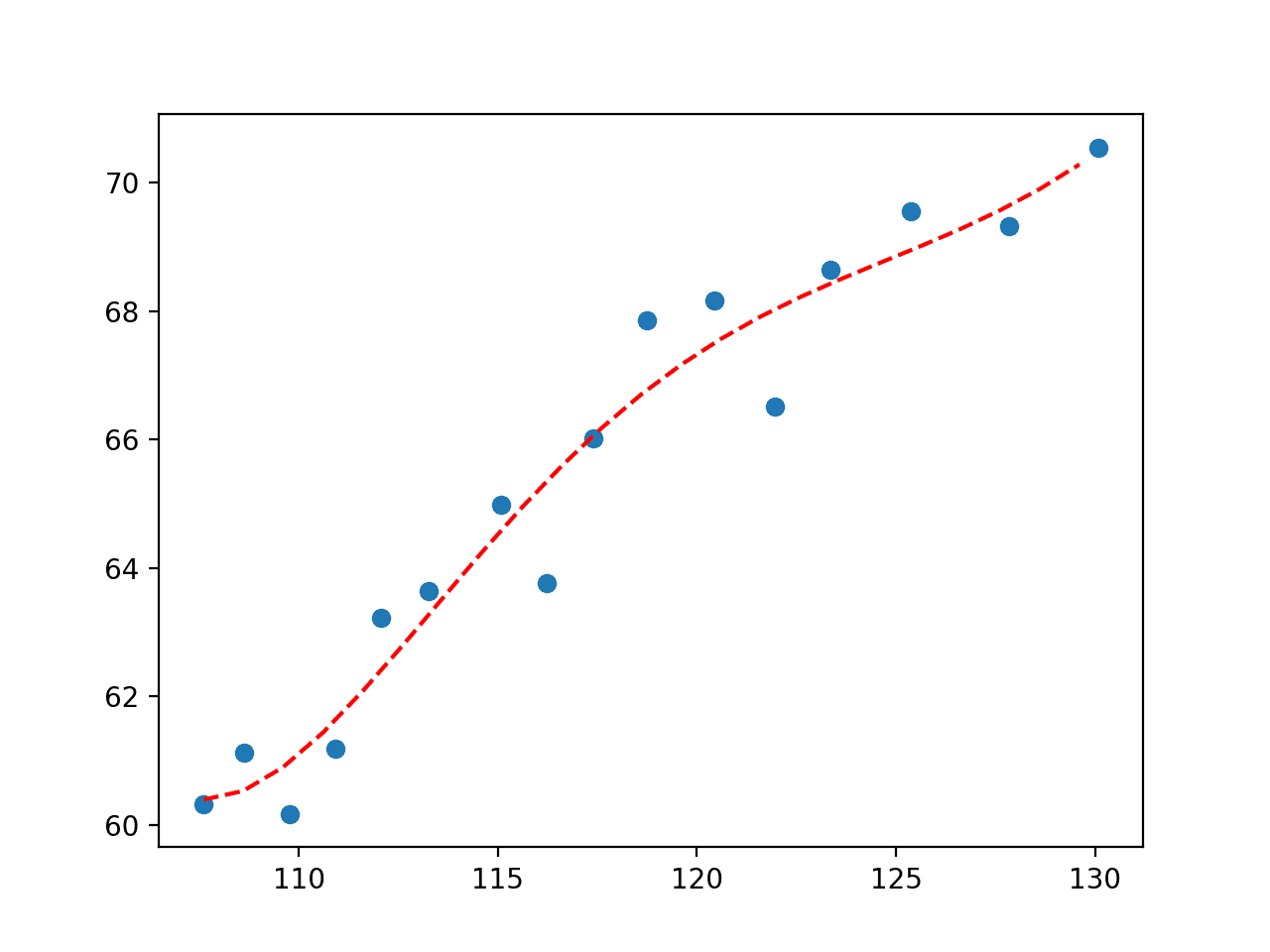
经济数据集五次多项式拟合图
重要的是,我们不限于线性回归或多项式回归。我们可以使用任何任意基函数。
例如,也许我们想要一条有波浪线来捕捉观测值中的短期波动。我们可以将正弦曲线添加到方程中,并找到最能将此元素集成到方程中的参数。
例如,下面列出了一个使用正弦波和二次多项式的任意函数
|
1 2 3 |
# 定义真实的目标函数 def objective(x, a, b, c, d): return a * sin(b - x) + c * x**2 + d |
使用此基函数拟合曲线的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 拟合经济数据的直线 from numpy import sin from numpy import sqrt from numpy import arange from pandas import read_csv from scipy.optimize import curve_fit from matplotlib import pyplot # 定义真实的目标函数 def objective(x, a, b, c, d): return a * sin(b - x) + c * x**2 + d # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/longley.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 选择输入和输出变量 x, y = data[:, 4], data[:, -1] # 曲线拟合 popt, _ = curve_fit(objective, x, y) # 总结参数值 a, b, c, d = popt print(popt) # 绘制输入与输出的关系图 pyplot.scatter(x, y) # 定义介于最小和最大已知输入值之间的输入序列 x_line = arange(min(x), max(x), 1) # 计算该范围内的输出值 y_line = objective(x_line, a, b, c, d) # 为映射函数创建折线图 pyplot.plot(x_line, y_line, '--', color='red') pyplot.show() |
运行示例可以拟合曲线并绘制结果。
我们可以看到,添加正弦波达到了预期的效果,显示出周期性的波动,并带有上升趋势,这提供了另一种捕捉数据关系的方式。
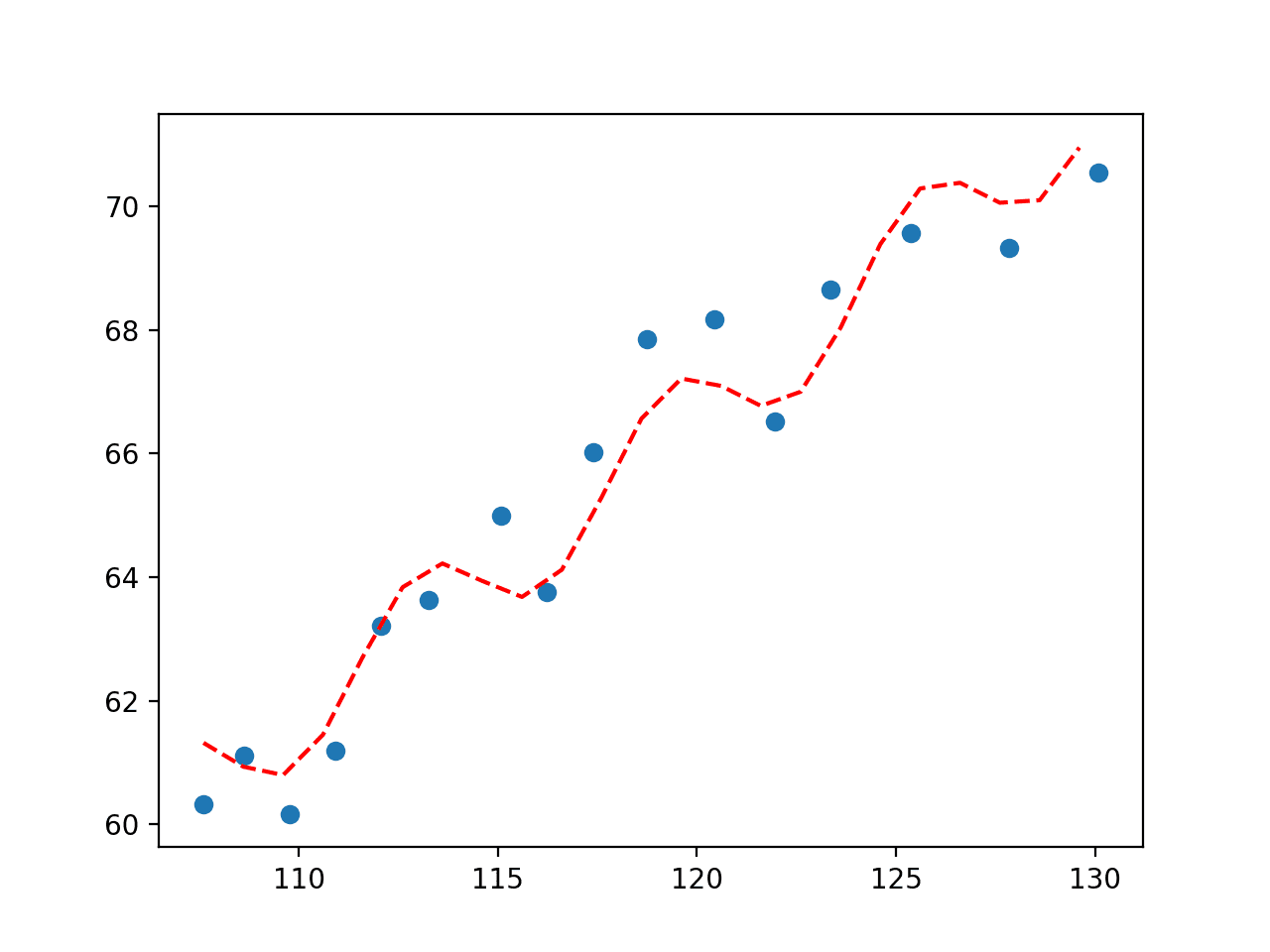
经济数据集正弦波拟合图
如何选择最佳拟合?
如果您想要最佳拟合,您应该将问题建模为回归监督学习问题,并测试一套算法以发现哪种算法在最小化误差方面最佳。
在这种情况下,当您想要显式定义函数,然后发现您的函数参数最适合拟合数据中的一条线时,曲线拟合是合适的。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 模式识别与机器学习, 2006.
API
文章
总结
在本教程中,您了解了如何在 Python 中执行曲线拟合。
具体来说,你学到了:
- 曲线拟合涉及为将示例输入映射到输出的函数找到最佳参数。
- 与监督学习不同,曲线拟合要求您定义将示例输入映射到输出的函数。
- 如何在 SciPy 中使用曲线拟合来拟合一系列不同的曲线到一组观测值。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







太棒了 Jason!!
一如既往,非常有帮助。
感谢您的工作。
谢谢!
亲爱的Jason Brownlee,
谢谢这篇很棒的文章。
我想知道您是否可以进一步阐述如何解释和分析拟合函数中的协方差矩阵。
感谢您的时间。
诚挚地,
谢谢!
好建议。
精彩的文章!谢谢
谢谢!
很棒的教程,我已成功完成!
唯一需要做的不同之处是导入 numpy 和 scipy 才能使其正常工作。
问题:如何衡量或计算曲线与真实数据的误差?
您可以计算预期值和预测值之间的误差,通常是 MAE 或 RMSE。
感谢分享这些信息。非常有价值。一些朋友推荐了你的资料。
我想知道,你有没有在 YouTube 上发布课程和练习题?
请评论您的机器学习方法和在线课程。
不客气。
抱歉,我没有 YouTube 视频。
我在这里提供自学电子书课程。
https://machinelearning.org.cn/products/
感谢这篇文章!您是否有关于添加约束的好的链接或教程?例如,我正在尝试将几个高斯函数的和拟合到一组数据上。我正在尝试添加约束:
– 每个高斯函数的面积
– 每个高斯函数的中心
– 不同高斯函数的相对面积
– 等等。
我一直使用惩罚方法来应用约束。试错(调整惩罚因子)使我能够获得可信的结果,但我想知道当添加更多约束时,是否有系统的方法来找到好的惩罚因子。随着我添加更多的约束(惩罚因子的微小变化会导致不同的拟合),解决方案会变得有点不稳定。
有趣的项目。抱歉,我暂时没有好的评论。也许可以查阅一本关于多元分析或多元统计学的书籍?
感谢您的精彩分享!
我修改了您的代码,从本地机器读取 CSV 数据文件。我保存了 CSV 文件并进行了这些更改;但不知何故,我没有得到我想要的结果。
import pandas as pd
data = pd.read_csv(‘data.csv’, delimiter=’,’)
也许这会有帮助。
https://machinelearning.org.cn/load-machine-learning-data-python/
这是非常好的信息。我有一个问题是如何对多个样本进行曲线拟合。例如,我们有四次独立实验运行的用户 1 到用户 4 的数据点。理想情况下,我想将这 4 次运行合并,创建一个“适合”所有四次运行的曲线,并给出一个最优的方程。我不清楚如何使用 Python 的曲线拟合函数来实现这一点。您能澄清一下如何实现吗?
谢谢。
我不太确定您的意思——让我试试——如果您想要一个能普遍适用于四个样本的曲线,也许可以将这四个样本合并成一个样本,然后拟合一条曲线?
这有帮助吗?
谢谢,这篇帖子帮了我很多。
不客气。
您推荐哪个 Python 包来评估最佳拟合?
通常我们使用误差度量,如 R^2 或 MSE。
你好,Jason。感谢这篇非常有用的文章。
我有一个愚蠢的问题,因为我是 Python 的新手。
在您的示例中,您输入了,
# 选择输入和输出变量
x, y = data[:, 4], data[:, -1]
为什么 x=data[:,4] 和 y=data[:,-1]?
在 .csv 数据集中,人口似乎在第 5 列,总就业人数在最后一列。那么,x 和 y 的列索引是如何对应 4 和 -1 的?
再次感谢。
好问题,如果您不熟悉 Python 数组索引,这将有所帮助。
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
哇,这么大的灵活性……
感谢您的快速回复!
不客气。
伙计,这是我遇到的关于曲线拟合最好的文章。非常感谢。
谢谢!
我需要做一个黑体拟合。函数是
def bb(x, T)
from scipy.constants import h,k,c
x = 1e-6 * x # 从 um 转换为米
return 2*h*c**2 / (x**5 * (np.exp(h*c / (x*k*T)) – 1))
我该如何处理温度 T 的输入?
先谢谢了
R. Baer
抱歉,我不知道。
你好,我有一个问题,我正在尝试使用 LRP(线性响应平台)对我的数据进行一些分析,但我对分段线方程以及如何将其插入 Python 感到很迷茫。你能帮忙吗?
抱歉,我对“LRP”不太熟悉。
很棒的教程!但我遇到了一个错误
from scipy.optimize import curve_fit
def objective (qi,a,b)
return qi*n + b
chargedata = loadtxt(“242E1charges.tsv”, float, skiprows = 1)
qi = chargedata[:,:]
n = qi//qs
plot(qi,n, “rd”, label =”data points”)
fit, _ = curve_fit(objective, qi, n)
我用 qi 代替 x。
弹出的错误是
函数调用结果不是一个合适的浮点数数组。
有什么方法可以解决这个问题吗?我对 Python 比较陌生,所以如果解决方案很简单,我很抱歉。
抱歉,这看起来是自定义代码。
也许您可以在 stackoverflow.com 上发布您的代码、数据和错误。
你好,有什么方法可以在时间序列上进行曲线拟合吗?
您的教程非常有帮助,谢谢!
目前不确定,也许可以使用相同的方法。
嗨!
如何使用曲线拟合进行预测?
曲线拟合不是用于预测,也许您想使用时间序列预测方法。
https://machinelearning.org.cn/start-here/#timeseries
嗨,Jason,
感谢分享重要信息。
我的实验数据包括输入和相应的输出。我想找到最佳的拟合模型。正如您在最后一段中所说,使用“回归监督学习问题”。您能否详细说明一下,或者提供一个带源代码的示例?
也许这会有帮助。
https://machinelearning.org.cn/?s=regression&post_type=post&submit=Search
我们可以对 x 和 y 不单调的二维数组 [x,y] 进行曲线拟合吗?
也许可以尝试一下。
谢谢,您把它做得对我们来说如此简单!
不客气!
感谢您发布的这篇精彩文章。帮助了我很多。
很高兴听到这个消息。
非常好的帖子。有个疑问,是否可以将 3 个特征与 1 个目标变量一起进行曲线拟合?例如,温度、湿度和风速与目标变量植物真菌生长。
请帮助。谢谢
如果所有值都是浮点数,当然可以。只需定义您的目标函数(例如,增长取决于温度还是温度的平方?)并调用 curve_fit()。
您好,感谢您发布的这篇精彩文章。
如果我的最佳拟合方程如下所示。这是否意味着 x^2 和 x^3 的系数为 0,或者它们非常小以至于无法以 5 位小数显示?如果是后者,我该如何获得 x^2 和 x^3 系数的非零值?
y = -0.00839 * x + 0.00000 * x^2 + -0.00000 * x^3 + 5.10433
先谢谢您了。
这取决于您的数据。如果您的 x 很大,x^2 和 x^3 可能更大,因此显示为零。在这种情况下,您仍然可以通过打印 “%.9f” 而不是 “%.5f” 来找到更高精度的系数。如果您的 x 不大,那只能说明曲线拟合建议您使用线性而不是三次曲线。
很棒的教程!我想知道如何定义一个用于曲线拟合的模型,如果模型是根据时间序列计算的(计算结果基于前一个结果)?
我不太明白您在问什么,但可以这样想:如果您在心中知道您的模型是 y=f(x) 并且知道 x 和 y 是什么,那么您就可以对其进行曲线拟合。
我的意思是,如果我的模型是 y(t) = y(t-1) + a + bx(t),其中 t 是索引。我们如何将其定义为曲线拟合方程?
曲线拟合可能不是全部步骤。您可以考虑 ∆y(t) = y(t)-y(t-1) 并将您的方程重写为 ∆y(t) = a + bx(t);然后您可以在此基础上进行曲线拟合。之后,您可以进行积分以根据 x(t) 恢复 y(t)。
太棒了。非常感谢。
Jithesh,非常欢迎!
非常有用的帖子!我正在使用这个拟合模型来拟合微生物生长曲线,并且在找到 Y(根据 X)时遇到困难。有什么建议吗?我确信这很容易解决,但我对编码是新手。
你好 Mairana…对于初学者来说,以下内容可能是一个很好的起点。
https://machinelearning.org.cn/regression-machine-learning-tutorial-weka/
嗨,Jason,
多年前购买了您的一些资料——很棒的东西!
现在我回来了,这是从零开始的出色解释。
问题:您是否有关于这个最后陈述的博客文章或其他资料——
“如果您想要最佳拟合,您将把问题建模为一个回归监督学习问题,并测试一套算法以发现哪种算法在最小化误差方面最好。”
谢谢!
你好 Kevin…以下资源可能与您有关
https://machinelearning.org.cn/regression-tutorial-keras-deep-learning-library-python/
https://machinelearning.org.cn/linear-regression-tutorial-using-gradient-descent-for-machine-learning/
https://machinelearning.org.cn/linear-regression-for-machine-learning/
如果您对模型有任何具体目标,我们可以帮助您澄清其他方法。
非常有用的页面。干得好!
感谢您的反馈 EllieM!
这非常有帮助——我已将此页面加入书签,因为我相信我以后会再次遇到类似问题。我需要将 x/y 值拟合到一条直线,以便为新值确定 x。这正是我需要的!
谢谢你
感谢您的精彩反馈 Mariana!
尊敬的 Jason 和社区:
我对我的曲线拟合问题有点迷茫,希望能得到一些帮助🙂
我正在尝试将 a * exp(b * x + c) + d 这样的曲线与 13 个数据点(观测值)进行拟合。我所做的与这里描述的完全一样,但出于某种原因,“解决方案”参数基本上使我得到一条直线(在观测范围内)。我很想分享图表,但似乎无法在此评论部分进行。
有人遇到过这种情况吗,有什么建议吗?
非常感谢任何提示!
此致,N
你好 Nadja…以下资源包含许多可能对您有帮助的示例。
https://gekko.readthedocs.io/en/latest/index.html
你好。我的问题有点不同。我有几条曲线会随着参数 A 而变化。例如,我有一条针对 A1 的曲线,以及一条针对 A2 的不同曲线。如果参数 A1 < A < A2,我如何获得 A 的曲线?
你好 Mina…以下资源可能有助于澄清。
https://www.kaggle.com/code/residentmario/non-parametric-regression/notebook
你好,我在使用您的任意函数代码时遇到了“‘Series’ 对象不可调用”错误,而且似乎问题出在我代码的这一行
x, y = data3[“Vertices”], data3[“Avg Comparisons”]
其中 data3 是一个 Dataframe。您知道为什么会发生这种情况吗?
你好 Wong…您是复制粘贴的代码还是自己输入的?另外,您可能想尝试在 Google Colab 中运行代码。让我们知道您的发现!
非常感谢您发布此内容。问题:curve_fit 函数返回参数(x 的系数和截距等)之间的协方差。如果参数之间存在高协方差,这意味着什么?这不好吗?如果是,为什么?谢谢!
感谢这篇文章,James。您是否有额外的代码来计算拟合的 RMSE 和 Rsq 值?
你好 Josh…以下内容可能与您有关。
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
我想这也会包括预测建模……
感谢这篇文章 – 是否可以获取拟合曲线每个系数的检验统计量和 p 值?
你好 Christopher…非常欢迎!以下讨论提供了一些关于回归结果的考虑因素。
https://stackoverflow.com/questions/27928275/find-p-value-significance-in-scikit-learn-linearregression
在此示例中:
# 定义真实的目标函数
def objective(x, a, b, c, d)
return a * sin(b – x) + c * x**2 + d
.
.
.
popt, _ = curve_fit(objective, x, y)
我收到此错误“输入不正确:函数输入向量长度 N=4 必须不超过函数输出向量长度 M=2”。您能帮忙修复吗?
您好…您遇到的错误消息“输入不正确:函数输入向量长度 N=4 必须不超过函数输出向量长度 M=2”通常与使用
scipy.optimize模块中的curve_fit函数有关。此错误表明您的函数期望的参数数量与传递给它的数据的维度或形状之间存在不匹配。在
curve_fit函数的上下文中,目标函数应定义为以自变量(x)作为第一个参数,以所有要优化的参数作为后续参数。然后它应该返回因变量(y)。让我们重新审视您的函数pythonfrom numpy import sin
# 定义真实目标函数
def objective(x, a, b, c, d):
return a * sin(b - x) + c * x**2 + d
根据此定义,函数
objective期望五个参数:x、a、b、c和d。以下是将其与curve_fit结合使用的分步说明:1. 确保您的
x和y数据格式正确,为数组。2. 为参数
a、b、c和d提供初始猜测。以下是包括虚拟数据和曲线拟合过程在内的完整示例:
pythonimport numpy as np
from scipy.optimize import curve_fit
from numpy import sin
# 定义目标函数
def objective(x, a, b, c, d)
return a * sin(b - x) + c * x**2 + d
# 创建虚拟数据
x_data = np.linspace(0, 4, 50) # 0 到 4 的 50 个点
y_data = objective(x_data, 2.5, 1.3, 0.5, 1.0) + 0.2 * np.random.normal(size=x_data.size) # 添加一些噪声
# a, b, c, d 的初始猜测
initial_guess = [1.0, 1.0, 1.0, 1.0]
# 执行曲线拟合
popt, pcov = curve_fit(objective, x_data, y_data, p0=initial_guess)
# 打印优化后的参数
print("Optimized Parameters:", popt)
此脚本执行以下操作:
– 按要求定义目标函数。
– 使用目标函数和一些噪声生成一些虚拟
x数据和相应的y数据。– 提供参数
[a, b, c, d]的初始猜测。– 使用
curve_fit根据数据优化参数。请确保您的
x和y数据尺寸兼容且格式正确为 numpy 数组。如果您的数据或设置有很大不同,您可能需要相应地调整示例。如果您仍然遇到问题,请确保数据维度和类型已正确设置以供curve_fit处理。