
针对领域特定 LLM 的自定义微调。
作者 | Ideogram 提供图片
自定义 LLM 微调简介
微调一个大型语言模型 (LLM) 是指采用一个预训练模型——通常是一个像 GPT 或 Llama 模型那样拥有数百万到数十亿参数的模型——并对其进行持续训练,将其暴露于新的数据中,从而更新模型权重(或通常是部分权重)。这可以有多种原因,例如使 LLM 保持最新的数据,或调整其以适应更窄、更特定于领域的任务或应用。
本文讨论并阐述了后一种微调 LLM 的原因,揭秘了自定义 LLM 微调如何使您的模型领域特定。
需要澄清的是,当我们提到“自定义微调”时,我们并不是指一种特定或不同的 LLM 微调方法。总的来说,无论其目的是适应特定领域还是不适应,微调过程基本上是相同的:关键的区别在于用于训练的数据,在自定义微调的情况下,这些数据是专门策划的,其范围仅限于目标领域、风格或应用需求。通过特定领域数据集进行自定义微调有助于您的模型更好地理解专业术语以及与领域相关的要求和细微差别。
下图说明了针对领域特定 LLM 进行自定义 LLM 微调的本质
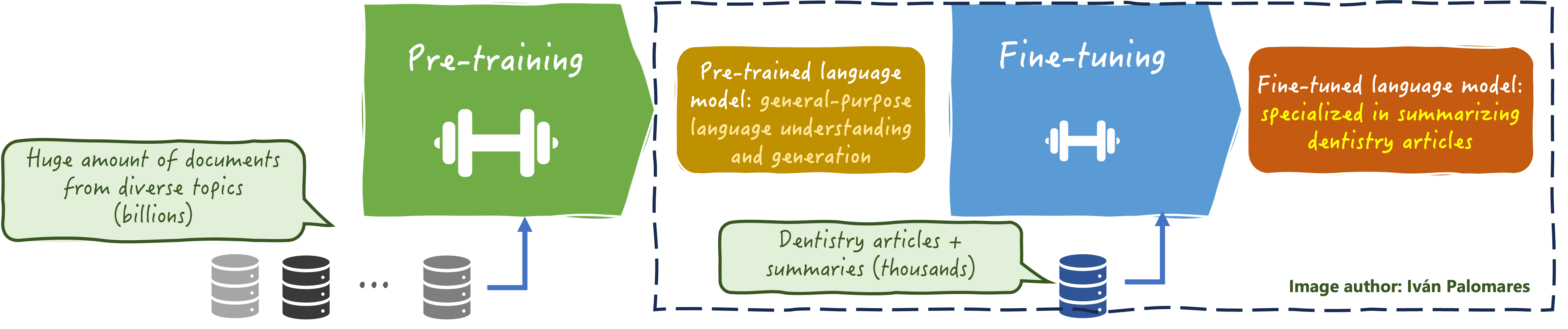
自定义 LLM 微调
作者提供图片
在自定义 LLM 微调中,一些重要的元素和方面需要注意:
- 用于微调 LLM 的数据必须高质量且相关,涵盖可能在您的目标领域(如牙科、禅宗佛教原理或加密货币等)独有的代表性语言模式、术语和表达(行话)。
- 某些特定领域的数据需要 LLM 具备深入的事实知识才能有效地从中学习。成功的微调过程应能够从数据中提炼出这些深入的知识,并将其注入“模型DNA”中,以尽量减少微调后生成关于该领域不精确信息的风险。
- 合规性、责任和许可也是需要考虑的关键方面。自定义 LLM 微调过程应确保模型符合道德和行业标准及法规,以减轻潜在风险。有时,具有不太严格许可的模型(如 Apache 许可)有助于实现更大的定制化和对您最终微调模型的控制。
- 微调后的持续监控和评估对于确保对特定领域数据进行微调的过程成功,以及新 LLM 在其预期的新范围内更有效是必不可少的。
Python 中的自定义微调示例
让我们看一个实际示例,微调一个相对易于管理的 LLM,例如通过 Hugging Face Transformers 库提供的 `falcon-rw-1b`(约 13 亿参数)。本文的目的不是对代码进行详尽的介绍,而是概述自定义 LLM 微调所涉及的主要实际步骤。
1. 设置与入门
在使用 Hugging Face 模型时,微调通常需要确定 LLM 的类型及其预训练的目标任务(例如,文本生成),并加载用于管理该类型模型的适当自动类(在本例中为 `AutoModelForCausalLM`)。还必须导入 `Trainer` 和 `TrainingArguments`,因为它们将在微调模型中发挥基础性作用。
当然,每个加载的预训练模型都必须附带一个关联的分词器,以妥善处理数据输入。
|
1 |
pip install transformers datasets peft bitsandbytes accelerate |
|
1 2 3 4 5 6 7 8 9 10 11 |
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments from datasets import Dataset from peft import LoraConfig, get_peft_model model_name = "tiiuae/falcon-rw-1b" tokenizer = AutoTokenizer.from_pretrained(model_name) if tokenizer.pad_token is None: tokenizer.pad_token = tokenizer.eos_token model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, device_map="auto") |
2. 获取和准备领域特定数据
我们考虑一个小型数据集——在实际的微调过程中,这将是一个大得多的数据集——包括与慢性病相关的问答对。对于像我们加载的这样的以文本生成为重点的 LLM 来说,这是完全可以的,因为它可以无缝执行的任务之一是生成式问答(与抽取式问答相反,后者是模型尝试从称为上下文的现有信息中提取答案)。
|
1 2 3 4 5 6 7 8 9 10 11 |
domain_data = [ {"text": "Q: What are the symptoms of diabetes? A: Increased thirst, frequent urination, fatigue."}, {"text": "Q: How is hypertension treated? A: Through lifestyle changes and medications."}, {"text": "Q: What causes anemia? A: Low levels of iron or vitamin B12 in the body."} ] dataset = Dataset.from_list(domain_data) def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True) tokenized_dataset = dataset.map(tokenize_function, batched=True) |
在继续微调模型之前,需要对数据集进行分词。
3. 微调模型
此过程涉及实例化 `TrainingArguments` 和 `Training` 对象,我们在此设置训练轮数和学习率等配置方面,调用 `train()` 方法,并保存微调后的模型。可以选择使用 LoRA(低秩适应)等技术,通过智能地冻结模型权重的显著部分,使微调过程更轻量级。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
lora_config = LoraConfig( r=8, lora_alpha=16, target_modules=["query_key_value"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) model = get_peft_model(model, lora_config) training_args = TrainingArguments( output_dir="./results", per_device_train_batch_size=2, num_train_epochs=2, logging_steps=10, save_steps=20, save_total_limit=2, optim="paged_adamw_8bit", learning_rate=2e-4, ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset, ) trainer.train() model.save_pretrained("./custom-finetuned-llm") tokenizer.save_pretrained("./custom-finetuned-llm") |
总结
在本文中,我们对自定义微调大型语言模型以适应更特定领域的流程进行了平衡的概述——既有理论也有实践。这是一个计算密集型的过程,需要高质量、代表性的数据才能成功。





暂无评论。