Keras 库提供了一种在训练深度学习模型时计算和报告一套标准指标的方法。
除了为分类和回归问题提供标准指标外,Keras 还允许你在训练深度学习模型时定义和报告自己的自定义指标。如果你想跟踪一个更能反映模型在训练期间技能的性能度量,这将特别有用。
在本教程中,你将学习如何使用内置指标,以及如何在 Keras 中训练深度学习模型时定义和使用自己的指标。
完成本教程后,您将了解:
- Keras 指标的工作原理以及如何在训练模型时使用它们。
- 如何使用 Keras 中的回归和分类指标,并附带示例。
- 如何定义和使用你自己的自定义 Keras 指标,并附带示例。
立即开始你的项目,阅读我的新书《Python 深度学习》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2020年1月更新:更新了Keras 2.3和TensorFlow 2.0的API。

指标以及如何在 Keras 中使用自定义指标进行深度学习(Python)
照片由 Indi Samarajiva 拍摄,保留部分权利。
教程概述
本教程分为4个部分,它们是:
- Keras 指标
- Keras 回归指标
- Keras 分类指标
- Keras 中的自定义指标
Keras 指标
Keras 允许你列出在模型训练期间要监控的指标。
你可以通过在模型的 `compile()` 函数中指定“metrics”参数并提供函数名称列表(或函数名称的别名)来做到这一点。
例如
|
1 |
model.compile(..., metrics=['mse']) |
你可以列出的具体指标可以是 Keras 函数的名称(例如 `mean_squared_error`)或这些函数的字符串别名(例如 ‘mse‘)。
指标值在每个 epoch 结束时在训练数据集上记录。如果还提供了验证数据集,则记录的指标也会为验证数据集计算。
所有指标都会在详细输出以及调用 `fit()` 函数返回的 history 对象中报告。在这两种情况下,指标函数的名称都用作指标值的键。对于验证数据集的指标,键前面会加上 “val_” 前缀。
损失函数和显式定义的 Keras 指标都可以用作训练指标。
Keras 回归指标
以下是你可以在 Keras 中用于回归问题的指标列表。
- 均方误差:`mean_squared_error`、`MSE` 或 `mse`
- 平均绝对误差:`mean_absolute_error`、`MAE`、`mae`
- 平均绝对百分比误差:`mean_absolute_percentage_error`、`MAPE`、`mape`
- 余弦相似度:`cosine_proximity`、`cosine`
下面的示例在简单的模拟回归问题上演示了这 4 个内置回归指标。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from numpy import array from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 准备序列 X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) # 创建模型 model = Sequential() model.add(Dense(2, input_dim=1)) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam', metrics=['mse', 'mae', 'mape', 'cosine']) # 训练模型 history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2) # 绘制指标 pyplot.plot(history.history['mean_squared_error']) pyplot.plot(history.history['mean_absolute_error']) pyplot.plot(history.history['mean_absolute_percentage_error']) pyplot.plot(history.history['cosine_proximity']) pyplot.show() |
注意:由于算法或评估程序的随机性,或数值精度的差异,你的结果可能有所不同。请尝试运行示例几次并比较平均结果。
运行该示例会在每个 epoch 结束时打印指标值。
|
1 2 3 4 5 6 7 8 9 10 11 |
... 第96/100个周期 0s - loss: 1.0596e-04 - mean_squared_error: 1.0596e-04 - mean_absolute_error: 0.0088 - mean_absolute_percentage_error: 3.5611 - cosine_proximity: -1.0000e+00 第97/100个周期 0s - loss: 1.0354e-04 - mean_squared_error: 1.0354e-04 - mean_absolute_error: 0.0087 - mean_absolute_percentage_error: 3.5178 - cosine_proximity: -1.0000e+00 第98/100个周期 0s - loss: 1.0116e-04 - mean_squared_error: 1.0116e-04 - mean_absolute_error: 0.0086 - mean_absolute_percentage_error: 3.4738 - cosine_proximity: -1.0000e+00 Epoch 99/100 0s - loss: 9.8820e-05 - mean_squared_error: 9.8820e-05 - mean_absolute_error: 0.0085 - mean_absolute_percentage_error: 3.4294 - cosine_proximity: -1.0000e+00 Epoch 100/100 0s - loss: 9.6515e-05 - mean_squared_error: 9.6515e-05 - mean_absolute_error: 0.0084 - mean_absolute_percentage_error: 3.3847 - cosine_proximity: -1.0000e+00 |
然后会创建一个展示 4 个指标在训练 epoch 中变化的折线图。
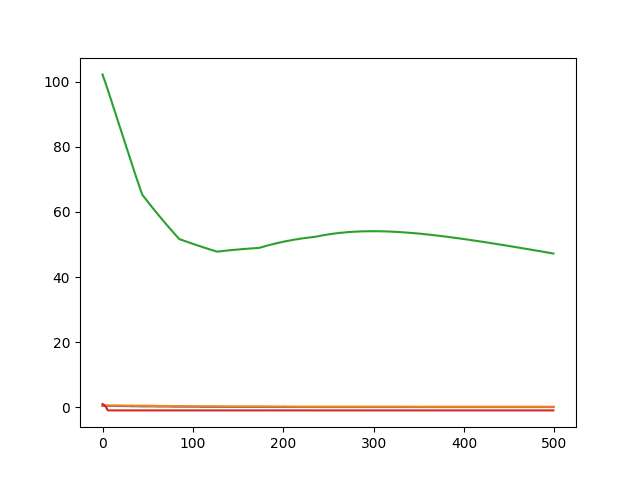
回归的内置 Keras 指标折线图
请注意,指标使用字符串别名值 [‘mse‘, ‘mae‘, ‘mape‘, ‘cosine‘] 指定,并在 history 对象上使用其展开的函数名作为键进行引用。
我们也可以使用展开的名称来指定指标,如下所示
|
1 |
model.compile(loss='mse', optimizer='adam', metrics=['mean_squared_error', 'mean_absolute_error', 'mean_absolute_percentage_error', 'cosine_proximity']) |
如果函数已导入到脚本中,我们也可以直接指定函数名。
|
1 2 |
from keras import metrics model.compile(loss='mse', optimizer='adam', metrics=[metrics.mean_squared_error, metrics.mean_absolute_error, metrics.mean_absolute_percentage_error, metrics.cosine_proximity]) |
你也可以使用损失函数作为指标。
例如,你可以像这样使用均方根对数误差(`mean_squared_logarithmic_error`、`MSLE` 或 `msle`)损失函数作为指标
|
1 |
model.compile(loss='mse', optimizer='adam', metrics=['msle']) |
Keras 分类指标
以下是你可以在 Keras 中用于分类问题的指标列表。
- 二元准确率:`binary_accuracy`、`acc`
- 分类准确率:`categorical_accuracy`、`acc`
- 稀疏分类准确率:`sparse_categorical_accuracy`
- Top k 分类准确率:`top_k_categorical_accuracy`(需要指定 k 参数)
- 稀疏 Top k 分类准确率:`sparse_top_k_categorical_accuracy`(需要指定 k 参数)
准确率是特殊的。
无论你的问题是二元分类问题还是多分类问题,你都可以指定 ‘accuracy‘ 指标来报告准确率。
下面是一个演示内置准确率指标的二元分类问题的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from numpy import array from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # 准备序列 X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) y = array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) # 创建模型 model = Sequential() model.add(Dense(2, input_dim=1)) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(X, y, epochs=400, batch_size=len(X), verbose=2) # 绘制指标 pyplot.plot(history.history['accuracy']) pyplot.show() |
注意:由于算法或评估程序的随机性,或数值精度的差异,你的结果可能有所不同。请尝试运行示例几次并比较平均结果。
运行该示例会在每个训练 epoch 结束时报告准确率。
|
1 2 3 4 5 6 7 8 9 10 11 |
... Epoch 396/400 0s - loss: 0.5934 - acc: 0.9000 Epoch 397/400 0s - loss: 0.5932 - acc: 0.9000 Epoch 398/400 0s - loss: 0.5930 - acc: 0.9000 Epoch 399/400 0s - loss: 0.5927 - acc: 0.9000 Epoch 400/400 0s - loss: 0.5925 - acc: 0.9000 |
会创建一个准确率随 epoch 变化的折线图。
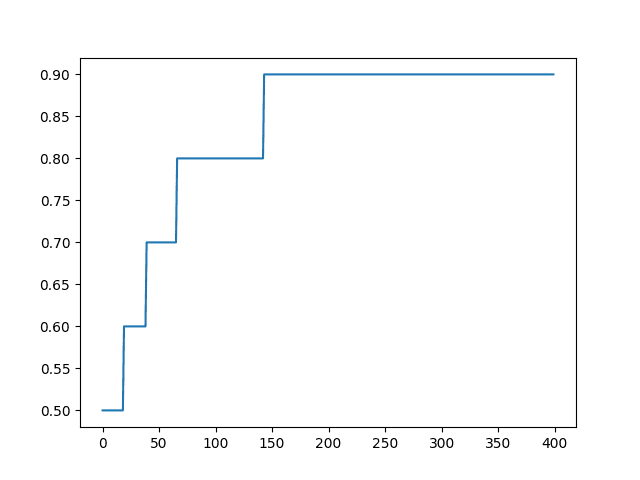
分类的内置 Keras 指标折线图
Keras 中的自定义指标
你还可以定义自己的指标,并在调用 `compile()` 函数时,在“metrics”参数的函数列表中指定函数名称。
我经常关注的一个指标是均方根误差,即 RMSE。
你可以通过查看现有指标的代码来了解如何编写自定义指标。
例如,以下是 Keras 中 均方误差损失函数和指标的代码。
|
1 2 |
def mean_squared_error(y_true, y_pred): return K.mean(K.square(y_pred - y_true), axis=-1) |
K 是 Keras 使用的后端。
从这个示例和其他损失函数和指标的示例中可以看出,方法是使用后端标准数学函数来计算感兴趣的指标。
例如,我们可以编写一个自定义指标来计算 RMSE,如下所示
|
1 2 3 4 |
from keras import backend def rmse(y_true, y_pred): return backend.sqrt(backend.mean(backend.square(y_pred - y_true), axis=-1)) |
可以看出,该函数与 MSE 的代码相同,只是在结果外部包装了 `sqrt()`。
我们可以在回归示例中测试这一点。请注意,我们直接列出函数名,而不是将其作为字符串或别名提供给 Keras 进行解析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from numpy import array from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot from keras import backend def rmse(y_true, y_pred): return backend.sqrt(backend.mean(backend.square(y_pred - y_true), axis=-1)) # 准备序列 X = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) # 创建模型 model = Sequential() model.add(Dense(2, input_dim=1, activation='relu')) model.add(Dense(1)) model.compile(loss='mse', optimizer='adam', metrics=[rmse]) # 训练模型 history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2) # 绘制指标 pyplot.plot(history.history['rmse']) pyplot.show() |
注意:由于算法或评估程序的随机性,或数值精度的差异,你的结果可能有所不同。请尝试运行示例几次并比较平均结果。
运行该示例会在每个训练 epoch 结束时报告自定义 RMSE 指标。
|
1 2 3 4 5 6 7 8 9 10 11 |
... Epoch 496/500 0s - loss: 1.2992e-06 - rmse: 9.7909e-04 Epoch 497/500 0s - loss: 1.2681e-06 - rmse: 9.6731e-04 Epoch 498/500 0s - loss: 1.2377e-06 - rmse: 9.5562e-04 Epoch 499/500 0s - loss: 1.2079e-06 - rmse: 9.4403e-04 Epoch 500/500 0s - loss: 1.1788e-06 - rmse: 9.3261e-04 |
运行结束时,会创建一个自定义 RMSE 指标的折线图。
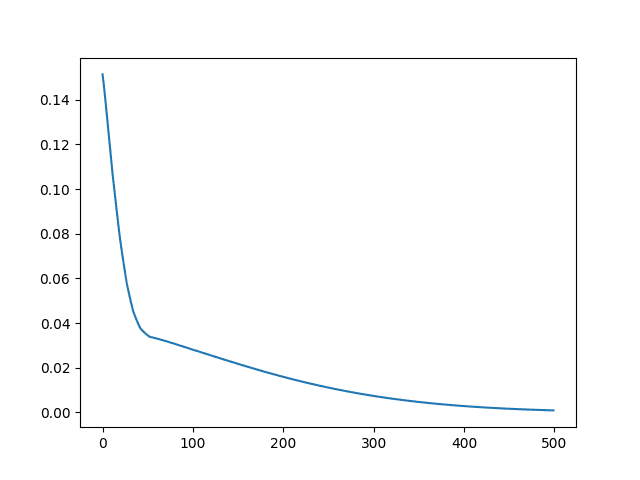
回归的自定义 RMSE Keras 指标折线图
你的自定义指标函数必须操作 Keras 的内部数据结构,这些数据结构可能因使用的后端而异(例如,在使用 tensorflow 时为 `tensorflow.python.framework.ops.Tensor`),而不是直接操作原始的 yhat 和 y 值。
因此,我建议尽可能使用后端数学函数以获得一致性和执行速度。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
总结
在本教程中,你了解了如何在训练深度学习模型时使用 Keras 指标。
具体来说,你学到了:
- Keras 指标的工作原理以及如何配置模型在训练期间报告指标。
- 如何使用 Keras 内置的分类和回归指标。
- 如何在训练深度学习模型时高效地定义和报告自己的自定义指标。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






离题但仍然有趣
1) 如何在训练 1 个模型的时间内训练一个模型集成
http://www.kdnuggets.com/2017/08/train-deep-learning-faster-snapshot-ensembling.html
2) 何时不使用深度学习
http://www.kdnuggets.com/2017/07/when-not-use-deep-learning.html
感谢分享。
嗨,Jason,
再次感谢关于 Keras 的另一个精彩话题,但我是一个 R 用户!
我可以在 R 中使用 Keras,但如何在 Keras R 中实现自定义指标 'rmse' 呢?
因为我在 github 仓库中找到了类似这样的内容
metric_mean_squared_error <- function(y_true, y_pred) {
keras$metrics$mean_squared_error(y_true, y_pred)
}
attr(metric_mean_squared_error, "py_function_name") <- "mean_squared_error"
而我的差劲
rmse <- function(y_true, y_pred) {
K$sqrt(K$mean(K$square(y_pred – y_true)))
}
不起作用(返回“NaN”)
好的,我终于让它返回一个与“NaN”不同的值,但结果与 Keras 的“mse”的平方根不符?!也许是因为 'axis = -1' 参数?
抱歉,我没有使用过 Keras R,我目前无法给你好的建议。
嗨,Jason,
感谢您关于 Keras 评估指标的非常好的主题。您能告诉我如何计算宏 F 值和微 F 值吗?
先谢谢了
抱歉,John,我对那些分数不太熟悉。
也许你可以找个定义自己写代码?
您是否考虑过使用 scikit-learn 的实现?https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.f1_score.html
或者这些与 tensorflow 不兼容?
请看这里
https://machinelearning.org.cn/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
嗨,Jason,
我在代码中使用了你的“def rmse”,但它返回了与 mse 相同的结果。
# 定义数据和目标值
X = TFIDF_Array
Y = df[‘Shrinkage’]
# 计算 RMSE 的自定义指标
def RMSE(y_true, y_pred)
return backend.sqrt(backend.mean(backend.square(y_pred – y_true), axis=-1))
# 定义基本模型
def regression_model()
# 创建模型
model = Sequential()
model.add(Dense(512, input_dim=X.shape[1], kernel_initializer=’uniform’, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(1, kernel_initializer=’uniform’))
# 编译模型
model.compile(loss=’mse’, optimizer=’sgd’, metrics=[RMSE])
return model
# 评估模型
estimator = KerasRegressor(build_fn=regression_model, nb_epoch=100, batch_size=32, verbose=0)
kfold = KFold(n_splits=3, random_state=1)
reg_results = cross_val_score(estimator, X, Y, cv=kfold)
您是否尝试了文章中的示例——完全复制——并且对您有效?
Epoch 496/500
0s – loss: 3.9225e-04 – rmse: 0.0170
Epoch 497/500
0s – loss: 3.8870e-04 – rmse: 0.0169
Epoch 498/500
0s – loss: 3.8518e-04 – rmse: 0.0169
Epoch 499/500
0s – loss: 3.8169e-04 – rmse: 0.0168
Epoch 500/500
0s – loss: 3.7821e-04 – rmse: 0.0167
它的结果与您的不同。
Epoch 497/500
0s – loss: 0.0198 – mean_squared_error: 0.0198
Epoch 498/500
0s – loss: 0.0197 – mean_squared_error: 0.0197
Epoch 499/500
0s – loss: 0.0197 – mean_squared_error: 0.0197
Epoch 500/500
0s – loss: 0.0196 – mean_squared_error: 0.0196
而这些是我使用
metrics=[‘mean_squared_error’]
时得到的结果。我没有看到 MSE 和 RMSE 有任何区别。
请指导。谢谢。
是的,这是可以预期的。机器学习算法是随机的,这意味着相同的算法在相同的数据上每次运行时都会产生不同的结果。有关更多详细信息,请参阅这篇博文。
https://machinelearning.org.cn/randomness-in-machine-learning/
亲爱的 Jason,
再次感谢您精彩的博客和清晰的解释
如果我理解正确,RMSE 应该等于 sqrt(mse),但我的数据不是这样
Epoch 130/1000
10/200 [>………………………..] – ETA: 0s – loss: 0.0989 – rmse: 0.2656
200/200 [==============================] – 0s 64us/step – loss: 0.2856 – rmse: 0.4070
请问,我们如何计算决定系数?
mse 可能是每个 batch 结束时计算的,而 rmse 可能是 epoch 结束时计算的,因为它是一个指标。
嗨 Jason,感谢您有用的博文。关于你在这里的回复,有个小问题,如果 rmse 指标是在每个 epoch 结束时计算的,为什么在你训练时,它在 epoch 期间会不断更新?
我认为它是按 batch 计算/估计的。
感谢您的回复。如果是这样,为什么 MSE 损失函数的平方根不等于上面提到的 RMSE 指标值,如果它们都是在每个 batch 结束时计算的?
它们应该是相等的,如果不相等,那么用于计算分数的样本就有区别——例如 batch 与 epoch,或者两个计算之间的精度差异导致舍入错误。
如果这很重要,你可以尝试深入研究代码。
总的来说,我建议对模型性能进行单独的独立评估,并且只将训练值用作粗略/方向性评估。
对于决定系数,我使用此基本代码
S1, S2 = 0, 0
for i in range(len(Y))
S1 = S1 + (Y_pred_array[i] – mean_y)**2
S2 = S2 + (Y_array[i] – mean_y)**2
R2 = S1/S2
但这给出了错误的结果
如何处理 Y_pred 作为可迭代对象,它也是一个 Tensor?
谢谢
我遇到了同样的问题。阅读文档可以看到,默认情况下,指标是按批次进行评估然后取平均值的。
“在这种情况下,您在训练和评估期间跟踪的标量指标值是在一个时期内(或在一次 model.evaluate() 调用中)看到的所有批次的每个批次指标值的平均值。”
有关详细信息,请参阅 https://keras.org.cn/api/metrics/
我的建议是通过 evaluate() 函数手动计算指标,以获得模型性能的真实估计。
训练期间报告的任何分数都只是粗略的近似。
感谢您的文章。Keras 如何以每个批次的方式计算平均统计量?它是在内部(神奇地)累积到该时期为止的总和和计数并打印度量,还是它为每个批次计算度量,然后在每个时期结束时对整个数据重新计算度量?
我相信总和会在每个批次结束时或每个时期结束时累积并打印。我不记得是哪个了。
很棒的文章,而且一如既往地及时;
问题是我正在尝试根据 IoU(交并比)计算损失,而且我不知道如何使用我的后端(TensorFlow)来实现。
我的输出如下(xmin,ymin,xmax,ymax)
谢谢
抱歉,我没有实现(或听说过)该度量。
model.compile(loss=’mse’, optimizer=’adam’, metrics=[rmse])
Epoch 496/500
0s – loss: 1.2992e-06 – rmse: 9.7909e-04
loss 是 mse。mse = rmse^2 吗? 上面的值 (9.7909e-04)^2 是 9.6e-8,这与 1.2992e-06 不符。是我误解了什么吗?谢谢。
损失和度量可能不是同时计算的,例如,批次结束 vs. 时代结束。
感谢您的回复。
history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2)
我以为一个批次的持续时间等于一个时期,因为 batch_size=len(X)。如果这是正确的呢?
此外,看起来每个迭代都会更新时期的损失。
Epoch 496/500
0s – loss: 1.2992e-06 – rmse: 9.7909e-04
不,一个时期包含 1 个或多个批次。通常使用 32 个样本作为批次。
在此了解更多信息
https://machinelearning.org.cn/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
非常感谢您花时间解释和查找链接。
我很抱歉。我认为我没有正确地表达我的想法。
在上面的示例中,history = model.fit(X, X, epochs=500, batch_size=len(X), verbose=2)
batch_size=len(X)
batch_size:整数或 None。每次梯度更新的样本数。如果未指定,batch_size 将默认为 32。
由于 batch_size 已指定为 testset 的长度,我是否可以认为一个时期包含 1 个批次,并且一个批次的结束就是一个时期的结束?模型 'mse' 损失是 rmse^2。
是的,没错。
感谢 Jason 的精彩文章。我有 2 个问题;
1) 我有一个管道,其中包含一个序列,例如:Normalizer –> KerasRegressor
我可以简单地使用 history = pipeline.fit(..) 然后绘制指标吗?
2) 我有一个 KFold 交叉验证,如下所示:
kfold = StratifiedKFold(n_splits=3)
results = cross_val_score(pipeline, X, Y, cv=kfold, scoring = mape)
我如何绘制这 3 个 CV 拟合的指标?
谢谢。
不,我不认为你可以轻易访问使用 sklearn 包装器时的历史记录。
你好 Jason Brownlee 博士
感谢您的精彩教程。
这两行有什么区别
score = model.evaluate(data2_Xscaled, data2_Yscaled, verbose=verbose)
y_hat = model.predict(data2_Xscaled)
目标度量是自定义的 def rmse(y_true, y_pred)
score 值也应该等于 y_hat
一个评估模型,另一个进行预测。
你好 Jason,
感谢您的工作。
我在具有有序类别的多类别分类问题中使用了 MAE 作为度量。
因为,在我的问题中,将类别 5 的记录归类为类别 4 与将其归类为类别 1 是不同的。
我的模型是
network %
layer_dense(units = 32, activation = “relu”, input_shape = c(38)) %>%
layer_dense(units = 5, activation = “softmax”)
network %>% compile(
optimizer = “rmsprop”,
loss = “categorical_crossentropy”,
metrics = c(“mae”)
)
但是模型没有正确计算 MAE。
是否可以将 MAE 用于此分类问题?
谢谢
MAE 不是分类的适当误差度量,它适用于回归问题。
您可以在这里了解分类和回归的区别
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-classification-and-regression
您是否编写了 mean_iou 度量的代码?
mean_iou 是什么?
嗨,Jason,
在定义自定义度量函数时,y_true 和 y_pred 的类型是 Tensor。如果我有一个需要 numpy 数组作为输入的函数,如何将 y_true 和 y_pred 转换为 numpy 数组?
您需要使用 Tensor 类型。这是 Keras 的预期。
亲爱的 Jason,
如何在 Python 中将精确率和召回率度量用于 Keras 的深度学习?
提前感谢。
您可以使用我们的模型进行预测,然后使用 sklearn 库中的精确率和召回率度量。
Jason 先生您好
我有一个问题困扰了我很久。
对于多输出回归问题,MSE 损失函数具体计算什么?
先谢谢您了。
不错的文章(们)Jason。
运行时,我想对类别进行分桶并进行评估。所以我尝试了这个函数,但它返回
nan。def my_metric(y_true, y_pred)
actual = tf.floor( y_true / 10 )
predicted = tf.floor( y_pred / 10 )
return K.categorical_crossentropy(actual, predicted)
抱歉,我无法调试您的代码。也许可以发布到 stackoverflow?
抱歉。非常感谢。学到了一些好东西:)
Jason 先生您好
对于多输出回归问题,MSE 损失函数具体计算什么?
是所有输出变量的 MSE 之和,还是平均值或其他什么?
先谢谢您了。
模型预测与真实值之间平方差的平均值。
这只是一个输出,如果有多个输出怎么办?
您可以计算每个时间步或输出的度量。我有一个例子在这里
https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
非常感谢您的教程。现在我每天都关注您的 Twitter 提案。太棒了!
我有两个问题
1) 关于最后一个示例中的顺序模型;
如果我删除激活定义 = ‘relu’,在您的最后一个代码示例中……我得到了一个惊人的更好的 RMSE 性能值……这是否意味着回归问题在不使用输出层激活的情况下效果更好?这是偶然结果还是有深刻原因?
2) 使用相同的架构模型,回归方法(我们省略了输出层的激活)还是多类别分类(我们设置了适当的 ‘softmax’ 作为输出层的激活),哪种更好,假设例如,我们分析相同的问题,例如,我们有所有连续标签输出或任何离散多类别标签(例如,通过其等效整数对连续数字进行四舍五入),对于一系列实数样本……我的意思是,使用回归分析与多类别分类有什么内在的优势或行为吗?
谢谢
JG
选择和激活函数的优点很大程度上取决于具体问题。
关于输出层中的激活,我想你问的是,经验法则是:
– 回归:使用 ‘linear’
– 二元分类:使用 ‘sigmoid’
– 多类别分类:使用 ‘softmax’。
这有帮助吗?
如果我将线性回归的预测输出想象成一条连续的曲线,或者想象成同一问题中用于对大型多类别分类进行分段的不同输出,使用相同的顶级模型架构(显然具有不同的单位和输出激活、损失和编译度量等)……哪种模型更好,回归还是多类别(对于相同的问题方法)?
我的直觉是多类别更好,因为它更关注线性回归曲线的特定分段输出(类),并且甚至在输出层有更多单位,因此涉及更多分析。不用太担心,我以后会尝试用一些具体的例子来查找我的问题。
顺便问一下,你喜欢女子篮球吗?恭喜澳大利亚在两小时前击败了西班牙……
抱歉,我不明白。
分类模型最适合分类,对于回归来说表现非常差。
抱歉,我不是体育迷:)
谢谢您的教程。
我遵循了所有步骤,并成功使用了自己的度量函数。我也能够绘制它。
我遇到的问题是,当我尝试加载模型和保存的权重以便使用 model.evaluate_generator() 时。我一直收到错误:“Exception has occurred: ValueError too many values to unpack (expected 2)”
我想知道您是否知道如何解决这个问题。
我没见过这个。您的 Keras 版本是最新的吗?v2.2.4 或更高版本?
如何从 model.compile 步骤中提取和存储 “loss” 和 “metrics” 的准确率输出来将这些浮点值传递给 mlflow 的 log_metric() 函数?
history = regr.compile(optimizer, loss = ‘mean_squared_error’, metrics =[‘mae’])
我的 “history” 变量一直显示为 “None type”
这很奇怪,我以前没见过。
也许可以发布到 keras 用户组
https://machinelearning.org.cn/get-help-with-keras/
布朗利博士,您好,
根据定义,rmse 应该是 mse 的平方根。
但是如果我们用批次拟合 keras,rmse 将无法正确计算。
您能否就如何正确使用自定义 rmse 度量进行批次拟合给我一些建议?
如果您将 RMSE 添加为度量,它将在每个时期结束时正确计算。
为什么在这种情况下余弦相似度值为负?既然相同向量的点积计算为 +1.0,它不应该是正的吗?
也许是因为框架期望最小化损失。
在这种情况下,负值的正确解释是什么?在您提到的示例中,由于两个向量是相同的,所以我们得到的值是 -1.0。当我搜索它的含义时,某些博客提到它意味着向量是相似的,但在相反的方向上。这似乎不是一个正确的解释,因为两个向量是相同的。
抱歉,我没有这方面的内容,也许这会有帮助
https://en.wikipedia.org/wiki/Cosine_similarity
这篇帖子再次帮助了我。你是最棒的。:)
我有一个关于为我的项目编写自定义度量的问题。
假设 g 和 v 是模型的两个输入,而 v 在下一个时间步是输出。g 和 v 之间存在关系。模型的损失函数是输出的 MSE。但是当涉及到度量时,我想将其定义为预测的 g 和观察到的 g 的 MSE。
当我编写自定义度量来计算 MSE 时,我不知道如何使 y_true 表示观察到的 g。
我说明清楚了吗?
先谢谢您了。
编写自定义函数并手动评估模型性能可能更容易。
感谢您的建议。
我使用了您在另一篇文章中介绍的方法:https://machinelearning.org.cn/implement-machine-learning-algorithm-performance-metrics-scratch-python/
它有效。
非常感谢!
干得好!
我正在尝试构建自己的准确率函数,该函数检查输出序列是否与真实答案相同。例如,如果真实答案是 “ 0.2 0.4 0.6 0.8 ”,那么 “ 0.4 0.6 0.8 0.2 ” 或 “0.8 0.6 0.4 0.2 ” 都将被定义为正确。您有什么想法或建议吗?
您不应使用准确率,而应使用误差,例如 MSE、MAE 或 RMSE。
但我希望结果是 1 和 0,而不是中间值。这可能吗?
也祝您圣诞快乐,昨天忘了说了。
您可以将浮点值四舍五入为 0/1。
我在您的博客中没有找到专门关注损失函数的帖子,所以我将问题提交到此帖子下。
我的模型有两个输出特征。我不确定损失函数是如何工作的。损失函数返回两个计算误差的总和还是加权总和或其他值?
MSE = MSEa + MSEb?
MSE = 0.5*MSEa + 0.5*MSEb?
如果它返回加权总和,我能定义权重吗?
先谢谢您了。
您可以选择如何管理多输出的损失计算。
我预计添加常量 1 或 0.5 在实践中不会有任何区别。
你好,Brownlee 博士,
我想定义自定义的监视度量,例如用于 Early Stopping 和 ModelCheckpoint 的 AUC,以及用于监视选项和其他回调,以及用于 model.compile 的度量。
我该怎么做?
我期待您的答复。
谢谢,
创建回调列表,并将其传递给 fit() 函数的 “callbacks” 参数。
感谢您的教程。
Precision 和 Recall 度量已从最新版本的 keras 中删除,他们说该度量具有误导性,您是否知道如何创建自定义的 Precision 和 Recall 度量?
是的,您可以使用模型进行预测,然后使用 sklearn 计算指标
https://scikit-learn.cn/stable/modules/classes.html#module-sklearn.metrics
非常感谢您的教程。
我想写一个自定义指标函数。该函数是 PSNR(峰值信噪比),它通常用于衡量有损压缩编解码器重建的质量。我的损失函数是 MSE。
PSNR 是基于 MSE 结果计算的。所以我想知道是否有办法使用拟合过程中计算出的损失来编写这个 PSNR 函数。或者我应该在函数体内计算 MSE,然后使用该信息计算 PSNR?
另外,在你的代码中
def rmse(y_true, y_pred)
return backend.sqrt(backend.mean(backend.square(y_pred – y_true), axis=-1))
在训练过程中 rmse 的输入是什么?它是如何分配 y_true 和 y_pred 的?
函数输入是真实的 y 值和预测的 y 值。
非常感谢您的回复,Jason。
这个自定义指标应该返回一个张量,对吗?
我在计算中必须使用 log10。但 Keras 只有 e 的对数(tf.keras.backend.log(x))。
所以我使用了 math.log10,在 model.compile() 时遇到了一个错误。这是之前的代码
def PSNR(y_true, y_pred)
max_I = 1.0
return 20*math.log10(max_I) – 10*math.log10( backend.mean( backend.square(y_pred – y_true),axis=-1)
然后,我想到可以用 numpy 来计算最后一行,然后将结果制成一个张量。
所以我把代码改成了
def PSNR(y_true, y_pred)
max_I = 1.0
val = 20*math.log10(max_I) – 10*math.log10(np.mean( np.square(y_pred – y_true),axis=-1))
newTensor = K.variable(value = val)
return newTensor
我没有收到任何错误。但这是正确的方法吗?
是的,您必须在张量上操作。
抱歉,我没有能力审查/调试您的方法。
谢谢你,Jason。
我该如何解决这个错误信息?请帮忙!
为了访问 val_acc,您必须使用验证数据集拟合模型。例如,在 model.fit(...) 的调用中设置 validation_data=(…)
可以为 mse 指定目标值吗?
系统是否可以测试收敛性?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
嗨,Jason,
epochs 的数量有限制吗?在我的数据集(回归)中,epochs 越多,模型的性能就越好…… 甚至超过 500 个。超过 2000 个 epochs 正常吗?
并不是真的。
在回归中……理想情况下,应该何时停止增加 epochs?是否可以通过 RMSE 图来验证?
当模型在保留验证数据集上不再改进时。
嗨,Jason,
在 Keras 的自定义指标部分的代码中,您将 rmse 函数定义为如下:
def rmse(y_true, y_pred)
return backend.sqrt(backend.mean(backend.square(y_pred – y_true), axis=-1))
为什么必须写 axis=-1?我不明白 axis=-1 在这里是什么意思。
我从函数中删除了 axis=-1,但它仍然可以运行?
它明确指定沿最后一个维度计算误差,通常是样本,但对于编码器-解码器 LSTM,它将是时间步。
您好,布朗利先生,
-> 感谢这篇教程,您帮了我很多。
对于我的论文,我在 Keras 中进行了一个回归 CNN,使用了这里介绍的四种指标,因为它们对回归很有意义。
关于 cosine_proximity 指标,我有一个问题:如果底层公式的分子和分母中的向量是 1 维向量(即仅仅是真实和预测的实值标签),那么该指标是否总是解析为 1?
– 为什么它对回归网络如此有趣,或者也许是指具有多个回归输出的网络?
– 您是否知道它的值如何可能解析为“-1”而不是“+1”,即使真实标签和预测标签都为正?
来自比利时的诚挚问候
抱歉,我无法就余弦相似度指标给出良好的即时答复。
我希望将来能介绍它。
嗨!
我正在尝试训练一个使用 Keras 实现的循环神经网络,并使用均方误差作为损失函数。是否可能存在大于 1 的损失,而网络生成的模型又能按预期工作?
也许可以。
当尝试使用以 rmse 作为指标的模型进行保存时。
在加载模型期间
load_model(….),,,
它会给出以下错误:
ValueError: Unknown metric function:rmse
什么是指标是时间序列数据的最佳指标?
我的 MSE 模型要么能很好地捕捉高信号,要么就无法捕捉低信号。
我想要一个更好的指标,能够同时保留相关性和 MSE。
谢谢你
好问题,您必须向 load_model() 函数提供一个字典,该字典指示 rmse 函数的含义。
例如,假设 rmse 函数已定义
谢谢回复,但我仍然收到错误。
IndexError: 元组索引超出范围
C:\ProgramData\Anaconda3\lib\site-packages\numpy\core\_methods.py in _count_reduce_items(arr, axis)
53 items = 1
54 for ax in axis
—> 55 items *= arr.shape[ax]
56 return items
57
IndexError: 元组索引超出范围
很遗憾听到这个。我没有好主意。
也许可以试试在 stackoverflow 上搜索/发帖?
什么是指标是时间序列数据的最佳指标?
我的 MSE 模型要么能很好地捕捉高信号,要么就无法捕捉低信号。
我想要一个更好的指标,能够同时保留相关性和 MSE。
我认为 RMSE 或 MAPE 有用。
非常有信息量的博客。但您能否告诉我如何使用召回率作为指标?
只需将其插入到上面的示例中。
您好,先生。
请问,如果我规范化了我的数据集(X 和 Y),例如使用 MinMaxScaler,并且如果我使用 MSE 或 RMSE 作为损失和/或指标,那么预期的结果(mse 和 rmse)也是规范化后的,对吗?
如何获得原始数据(X 和 Y)的“真实” MSE 和 RMSE(反规范化后)?
提前表示感谢。
正确。
您可以通过首先对预测结果进行逆变换来获得真实误差,然后计算误差指标。这些对象通常提供 inverse_transform() 函数。
好的。没错,我做到了。谢谢!还有一件事…
但是,如果我例如规范化 X 并标准化 Y,或者反之呢?
在对预测结果进行逆变换(predict(X_test) = Y_pred)时,我应该使用哪个缩放器来获得“真实”的 Y_pred 的逆变换?
是规范化的逆变换还是标准化的逆变换?
您明白我的意思吗?
提前表示感谢。
您应该以相反的顺序逆变换应用于 y 的变换。
这可能会给您一些启发
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
我尝试使用自定义损失函数,但总是遇到错误。
马氏距离(或其平方值的“广义平方点间距离”[3])也可以定义为两个随机向量 x 和 y 之间的一种测度,它们具有相同的分布和协方差矩阵 S。
d(x,y) = square [Transpose(x-y) * Inverse(S)* (x-y)]
(https://en.wikipedia.org/wiki/Mahalanobis_distance)
n_classes = 4
n_samples=800
X, y = make_classification(n_samples=n_samples, n_features=20, n_informative=4, n_redundant=0, n_classes=n_classes, n_clusters_per_class=2)
y = to_categorical(y)
Xtrainb, testXb, ytrainb, ytestb = train_test_split(X, y, test_size = 0.3, random_state=42)
x_trainb = np.reshape(Xtrainb, (Xtrainb.shape[0], Xtrainb.shape[1], 1))
Xtestb = np.reshape(testXb, (testXb.shape[0], testXb.shape[1], 1))
densesize = 4
input_datab = Input(shape=(Xtrainb.shape[1],1))
epochs = 10
batch_size = 32
########
def mahalanobis(y_true, y_pred)
x_minus_mn_with_transpose = K.transpose(y_true – y_pred)
Covariance = covr1(y_true, y_pred)
inv_covmat = tf.linalg.inv(Covariance)
x_minus_mn = y_true – y_pred
left_term = K.dot(x_minus_mn, inv_covmat)
D_square = K.dot(left_term, x_minus_mn_with_transpose)
return D_square
def covr1(y_true, y_pred)
#x_mean = K.mean(y_true)
#y_mean = K.mean(y_pred)
Cov_numerator = K.sum(((y_true – y_pred)*(y_true – y_pred)))
Cov_denomerator = len(Xtrainb)-1
Covariance = (Cov_numerator / Cov_denomerator)
return Covariance
conv1= Conv1D(filters=80, kernel_size=2, padding=’same’, input_dim=Xtrainb.shape[1])(input_datab)
maxpool = MaxPooling1D(pool_size=3, stride=3 )(conv1)
conv2= Conv1D(filters=50, kernel_size=2, padding=’same’, input_dim=Xtrainb.shape[1])(maxpool)
maxpool = MaxPooling1D(pool_size=3, stride=3)(conv2)
flatten = Flatten()(maxpool)
dense = Dense(84, activation=’relu’)(flatten)
dense = Dense(1024, activation=’relu’)(flatten)
dense = Dense(densesize, activation=’softmax’)(dense)
model = Model(inputs=[input_datab],outputs=[dense])
model.compile(loss= mahalanobis, optimizer=’adam’, metrics=[‘acc’])
hist = model.fit(x_trainb, ytrainb, validation_data=(Xtestb, ytestb), epochs=epochs, batch_size=batch_size)
听到这个消息我很难过,我这里有一些建议可能会有帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
你好先生,
我正在开发 MLPRegressor 模型,例如…
#创建模型
nn=MLPRegressor(hidden_layer_sizes=(2, 1,),activation=’logistic’,max_iter=2000,solver=’adam’,learning_rate_init=0.1,momentum=0.7,early_stopping=True,
validation_fraction=0.15,)
history = nn.fit(X_train, y_train, )
我该如何绘制 mape、r^2,以及如何预测新样本?我使用 minmax scaler 对数据进行了缩放??
对数据集进行预测,然后绘制真实 y 值与预测 y 值。
如果您使用的是 scikit-learn 而不是 keras,那么这将帮助您进行预测。
https://machinelearning.org.cn/make-predictions-scikit-learn/
尊敬的 Brownlee 教授
我尝试了以下代码:
from math import sqrt
Y = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) + 0.001
Y_hat = model.predict(X)
print(Y)
print(Y_hat)
score = model.evaluate(Y, Y_hat)
print(model.metrics_names)
print(“RMSE from score”, score[1])
print(“RMSE by hand”, sqrt(mean_squared_error(Y, Y_hat)))
并得到:
[0.101 0.201 0.301 0.401 0.501 0.601 0.701 0.801 0.901 1.001]
[[0.20046636]
[0.28566912]
[0.37087193]
[0.4557818 ]
[0.5314531 ]
[0.60712445]
[0.6827957 ]
[0.758467 ]
[0.8341383 ]
[0.90980965]]
10/10 [==============================] – 0s 98us/step
[‘loss’, ‘rmse’]
RMSE from score 0.0007852882263250649
RMSE by hand 0.06390388739172052
我不明白为什么最后两行的值不同。它们不应该相同吗?
抱歉,我之前的帖子是错误的。应该是:
Y = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) + 0.001
Y_hat = model.predict(Y).reshape(-1)
print(Y)
print(Y_hat)
score = model.evaluate(Y, Y)
print(model.metrics_names, score)
print(“RMSE by hand”, sqrt(mean_squared_error(Y, Y_hat)))
但问题是一样的,我无法解释为什么报告的 rmse 与最后一行不同。
应该是一样的。我不知道原因,抱歉。
我认为 rmse 定义不正确。我相信它应该是,没有 “, -1”
def rmse(y_true, y_pred)
return backend.sqrt( backend.mean(backend.square(y_pred – y_true)))
而不是
def rmse(y_true, y_pred)
return backend.sqrt(backend.mean(backend.square(y_pred – y_true), axis=-1))
您可以尝试使用以下代码进行调试:
import numpy as np
Y = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]) + 0.001
Y_hat = model.predict(Y).reshape(-1)
print(Y)
print(Y_hat)
score = model.evaluate(Y, Y)
print(model.metrics_names, score)
print(“RMSE by formular”, sqrt(mean_squared_error(Y, Y_hat)))
print(“Error are”, Y-Y_hat)
print(“Squared Error are”, (Y-Y_hat) ** 2)
print(“Mean Squared Error are”, np.mean((Y-Y_hat) ** 2))
print(“Root Mean Squared Error is”, sqrt(np.mean((Y-Y_hat) ** 2)))
用我修正后的代码,我得到了:
[0.101 0.201 0.301 0.401 0.501 0.601 0.701 0.801 0.901 1.001]
[0.38347098 0.38347098 0.38347098 0.38347098 0.38347098 0.38347098
0.38347098 0.38347098 0.38347098 0.38347098]
10/10 [==============================] – 0s 6ms/step
[‘loss’, ‘rmse’] [0.11056597530841827, 0.33251461386680603]
RMSE by formular 0.33251461887730416
Error are [-0.28247098 -0.18247098 -0.08247098 0.01752902 0.11752902 0.21752902
0.31752902 0.41752902 0.51752902 0.61752902]
Squared Error are [7.97898558e-02 3.32956594e-02 6.80146292e-03 3.07266461e-04
1.38130700e-02 4.73188735e-02 1.00824677e-01 1.74330481e-01
2.67836284e-01 3.81342088e-01]
Mean Squared Error are 0.11056597176711884
Root Mean Squared Error is 0.33251461887730416
但是如果我使用您带有“, -1”的版本,我得到:
[0.101 0.201 0.301 0.401 0.501 0.601 0.701 0.801 0.901 1.001]
[0.35035747 0.39923668 0.44811586 0.49699506 0.54587424 0.59475344
0.64363265 0.69251186 0.741391 0.7902702 ]
10/10 [==============================] – 0s 6ms/step
[‘loss’, ‘rmse’] [0.02193305641412735, 0.1278020143508911]
RMSE by formular 0.14809812299213124
Error are [-0.24935747 -0.19823668 -0.14711586 -0.09599506 -0.04487424 0.00624656
0.05736735 0.10848814 0.159609 0.21072979]
Squared Error are [6.21791493e-02 3.92977809e-02 2.16430749e-02 9.21505186e-03
2.01369724e-03 3.90194594e-05 3.29101280e-03 1.17696773e-02
2.54750319e-02 4.44070447e-02]
Mean Squared Error are 0.021933054033792435
Root Mean Squared Error is 0.14809812299213124
注意,evaluate 返回 0.1278020143508911 而不是正确的 0.14809812299213124。
谢谢,我将调查。
如果我使用 model.train_on_batch 而不是 model.fit,如何获得损失函数的不同组成部分?我看到 model.train_on_batch 只返回一个标量,它是损失函数不同组成部分的总和?
谢谢你。
我手头上没有确切答案,也许这些资源中的一个会有帮助。
https://machinelearning.org.cn/get-help-with-keras/
# VAE 模型 = 编码器(+采样) + 解码器
# 构建编码器模型
def encoder_model(inputs)
x1 = Dense(intermediate_dim_1, activation=’relu’)(inputs)
x2 = Dense(intermediate_dim_2, activation=’relu’)(x1)
x3 = Dense(intermediate_dim_3, activation=’relu’)(x2)
x4 = Dense(intermediate_dim_4, activation=’relu’)(x3)
z_mean_encoded = Dense(latent_dim, name=’z_mean’)(x4)
z_log_var_encoded = Dense(latent_dim, name=’z_log_var’)(x4)
# 实例化编码器模型
encoder = Model(inputs, [z_mean_encoded, z_log_var_encoded], name=’encoder’)
return encoder, z_mean_encoded, z_log_var_encoded
# 构建解码器模型
def decoder_model()
latent_inputs = Input(shape=(latent_dim,), name=’z_sampling’)
x4 = Dense(intermediate_dim_4, activation=’relu’)(latent_inputs)
x3 = Dense(intermediate_dim_3, activation=’relu’)(x4)
x2 = Dense(intermediate_dim_2, activation=’relu’)(x3)
x1 = Dense(intermediate_dim_1, activation=’relu’)(x2)
outputs = Dense(original_dim)(x1)
# 实例化解码器模型
decoder = Model(latent_inputs, outputs, name=’decoder’)
return decoder
def recon_loss(inputs,outputs)
reconstruction_loss = mse(inputs, outputs)
return K.mean(reconstruction_loss)
def latent_loss()
kl_loss = 1 + z_log_var_encoded – K.square(z_mean_encoded) – K.exp(z_log_var_encoded)
kl_loss = K.sum(kl_loss, axis=-1)
kl_loss *= -0.5
return K.mean(kl_loss)
# # reconstruction_loss *=
# kl_loss = 1 + z_log_var_encoded – K.square(z_mean_encoded) – K.exp(z_log_var_encoded)
# kl_loss = K.sum(kl_loss, axis=-1)
# kl_loss *= -0.5
# kl_loss_metric = kl_loss
# kl_loss *= beta
# vae_loss = K.mean(reconstruction_loss + kl_loss)
def total_loss(inputs,outputs, z_mean_encoded,z_log_var_encoded,beta)
reconstruction_loss = mse(inputs, outputs)
kl_loss = 1 + z_log_var_encoded – K.square(z_mean_encoded) – K.exp(z_log_var_encoded)
kl_loss = K.sum(kl_loss, axis=-1)
kl_loss *= -0.5
kl_loss *= beta
return K.mean(reconstruction_loss + kl_loss)
def sampling(args)
“””从各向同性单位高斯分布采样(重参数化技巧)。
# 参数
args (tensor): Q(z|X) 的均值和对数方差
# 返回
z (tensor): 采样得到的潜在向量
"""
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1] # 返回张量或变量的形状,作为整数或None条目的元组。
# 默认情况下,random_normal 的均值为 0,标准差为 1.0
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
if __name__ == ‘__main__’
x_trn,x_val,y_trn,y_val = train_test_split(Cp_inputs, X_all, test_size=0.2,shuffle=True,random_state=0)
original_dim = x_trn.shape[1]
x_trn = np.reshape(x_trn, [-1, original_dim])
x_val = np.reshape(x_val, [-1, original_dim])
input_shape = (original_dim, )
inputs = Input(shape=input_shape, name=’encoder_input’)
# 定义中间层维度和潜在层维度
intermediate_dim_1 = 128
intermediate_dim_2 = 256
intermediate_dim_3 = 128
intermediate_dim_4 = 64
latent_dim = 3
# 定义 batch_size / epochs / beta
epochs = 10
batch_size = 128
beta = 0.05
encoder, z_mean_encoded, z_log_var_encoded = encoder_model(inputs)
# 使用重参数化技巧将采样作为输入
z_sampled = Lambda(sampling, output_shape=(latent_dim,), name=’z’)([z_mean_encoded, z_log_var_encoded]) # 重参数化技巧
decoder = decoder_model()
# 实例化 VAE 模型
outputs = decoder(z_sampled) # z_sampled = 从 [z_mean_encoded 和 z_log_var_encoded] 中采样得到的 z
vae = Model(inputs, outputs, name=’vae_mlp’)
total_loss = total_loss(inputs, outputs, z_mean_encoded, z_log_var_encoded, beta)
vae.compile(optimizer=’adam’, metrics=[recon_loss, latent_loss])
history = vae.fit(x_trn, epochs=epochs, batch_size=batch_size, validation_data=(x_val, None),verbose = 2)
————————————————————————————————————–
结果
第 1/10 纪元
– 1s – loss: 34.2770 – val_loss: 4.7581
第 2/10 纪元
– 0s – loss: 4.1537 – val_loss: 3.4654
第 3/10 纪元
– 0s – loss: 3.2343 – val_loss: 2.7032
第 4/10 纪元
– 0s – loss: 2.5479 – val_loss: 2.5234
第 5/10 纪元
– 0s – loss: 2.3551 – val_loss: 2.2926
第 6/10 纪元
– 0s – loss: 2.2032 – val_loss: 2.1937
第 7/10 纪元
– 0s – loss: 1.9983 – val_loss: 2.0159
第 8/10 纪元
– 0s – loss: 1.8385 – val_loss: 1.6428
第 9/10 纪元
– 0s – loss: 1.6508 – val_loss: 1.5881
第 10/10 纪元
– 0s – loss: 1.5189 – val_loss: 1.4624
——————————————————————-
我正在尝试构建一个 VAE 模型,但它没有给出任何指标值,而这些指标是定义为 [recon_loss, latent_loss] 的。
你能解决这个问题吗?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
Jason,我可以在 Keras 回归问题中找到准确率吗?根据您的笔记,对于 Keras 回归问题,只有 mse、rmse、mae。有可能找到此方法的准确率吗?
不,请看这个
https://machinelearning.org.cn/faq/single-faq/how-do-i-calculate-accuracy-for-regression
谢谢 Jason 🙂
不客气!
Jason,我想问你,如何知道模型是否在回归方面表现良好?因为之前你说过我们无法知道回归的准确率。是根据他们的损失 mse、mae 和 rmse 来决定模型是否表现良好吗?我的意思是,如果 mse 的损失低于 1,那么模型就很好吗?
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
我在 Keras 中有一个问题,我正在训练 Keras 并进行编译
例如 model.compile(loss=’binary_crossentropy’,optimizer=’Nadam’, metrics=[precision_m])
在编译阶段将精度作为指标。
在所有这些之后,我们执行 model.evaluate,它会返回两个值,例如 loss 和 accuracy
如果我将精度作为指标,它将基于精度进行训练,对吧?训练完成后,model.evaluate 会返回 loss 和 precision 值,
我说的对吗?
请澄清一下我的疑问。
正确。
将回归损失函数用于分类模型进行编译是否合适?例如
model.compile(loss=mse,mae ,optimizer=adam.metrics=recall)
请对此提出建议,我为分类 Keras 模型使用了 mae 作为损失函数,它给出了 0.455 的召回率。
这个模型可以吗?
不。它会优化到错误的目标/目的。
您好,先生,
我有一个关于 Keras 编译的问题。
model.compile(loss=””,optmizer=””,metrics=[mae,mse,rmse])
在这里,我在编译阶段提供了 3 个指标。
那么 Keras 模型将基于哪个指标进行优化呢?因为我们一次性提供了 3 个指标,Keras 模型。
指标不用于优化模型,它们仅用于衡量模型性能。
损失是优化的。
嗨,Jason,
我使用了下面的代码片段来编译模型。
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[tf.keras.metrics.Precision()])
我的问题是,如何使用模型的 history 对象来绘制每个 epoch 结束时模型精度的折线图?我应该在下面的括号中使用什么?
plt.plot(model.history[‘???’])
提前感谢
这里有一个例子
https://machinelearning.org.cn/display-deep-learning-model-training-history-in-keras/
谢谢你的帮助!
不客气。
嗨,Jason,
使用 MSE 作为损失函数和 RMSE 作为指标是否可以?我听说不应该为同一个模型使用相同或非常相似的函数。这种说法对吗?如果我必须使用 metrics=RMSE,应该使用哪个损失函数(如果不允许使用 MSE)?非常感谢!
是的。
你好,
我通过子类化 Metric 类来创建自定义的精度指标。一切看起来都很好;我的意思是,没有运行时错误。但当我看到输出中记录的精度分数时,我怀疑有些地方不对。
这是我的代码及其输出
(X_train_10, y_train_10), (X_test_10, y_test_10) = keras.datasets.cifar10.load_data()
X_train_10 = X_train_10 / 255.
X_test_10 = X_test_10 / 255.
class PrecisionMetric(keras.metrics.Metric)
def __init__(self, name = ‘precision’, **kwargs)
super(PrecisionMetric, self).__init__(**kwargs)
self.tp = self.add_weight(‘tp’, initializer = ‘zeros’)
self.fp = self.add_weight(‘fp’, initializer = ‘zeros’)
def update_state(self, y_true, y_pred)
y_true = tf.cast(y_true, tf.bool)
y_pred = tf.cast(y_pred, tf.bool)
true_p = tf.logical_and(tf.equal(y_true, True), tf.equal(y_pred, True))
false_p = tf.logical_and(tf.equal(y_true, False), tf.equal(y_pred, True))
self.tp.assign_add(tf.reduce_sum(tf.cast(true_p, self.dtype)))
self.fp.assign_add(tf.reduce_sum(tf.cast(false_p, self.dtype)))
def reset_states(self)
self.tp.assign(0)
self.fp.assign(0)
def result(self)
return self.tp / (self.tp + self.fp)
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = np.array(X_train_10.shape[1: ])))
for _ in range(2)
model.add(keras.layers.Dense(50, activation = ‘elu’, kernel_initializer = ‘he_normal’))
model.add(keras.layers.Dense(1, activation = ‘sigmoid’))
loss = keras.losses.binary_crossentropy
optimizer = keras.optimizers.SGD()
model.compile(loss = loss, optimizer = optimizer, metri)
# 转换为二元分类
y_train_5 = (y_train_10 == 5)
y_test_5 = (y_test_10 == 5)
history = model.fit(X_train_10, y_train_5, epochs = 5)
第 1/5 周期
1563/1563 [==============================] – 5s 3ms/step – loss: 0.2954
第2/5个周期
1563/1563 [==============================] – 4s 3ms/step – loss: 0.2779
第3/5个周期
1563/1563 [==============================] – 4s 2ms/step – loss: 0.2701
第4/5个周期
1563/1563 [==============================] – 3s 2ms/step – loss: 0.2660
第5/5个周期
1563/1563 [==============================] – 3s 2ms/step – loss: 0.2629
感谢分享。
抱歉,我没有能力审查/调试您的代码。
嗨,Jason,
有趣的教程!
当使用正确的(自定义)指标(例如 ‘rmse’)保存 Keras 模型(通过 .save 方法)后,当您想再次加载模型(通过 load_model() 方法)时,它会因为无法识别您自己定义的 ‘rmse’ 指标而报错……如何解决 Keras 加载问题?
谢谢。
谢谢!
好问题,加载模型时需要定义该函数,并通过 load_model() 函数的 custom_objects 参数来指定该函数。
https://keras.org.cn/api/models/model_saving_apis/
我明白了
model = load_model(‘model.h5’, custom_objects={‘rmse’:rmse} )
非常感谢 Jason!
做得好!不客气。
你好,
我正在尝试使用平均绝对百分比误差(mean absolute percentage error),并且我使用了 loss: ‘mse’,而 mape 的结果大约是 600 和 800,这是什么问题?
也许模型与您的数据不太匹配?
也许您需要使用不同的模型配置?
也许您需要使用不同的模型?
也许您需要使用数据准备方法?
也许您的预测问题非常困难?
我可以使用不同的指标进行 checkpoint(val_accuracy)、earlystopping(val_loss)、compile(accuracy) 吗?
还是应该一样?
是的,这些都可以不同。
你好,
我可以使用每个 epoch 计算出的(mse mape)指标值来比较不同的 LSTM 模型吗?还是应该考虑最后一个 epoch 的值?
非常感谢。
Kubra… 您可能会受益于以下关于交叉验证的资源
https://machinelearning.org.cn/repeated-k-fold-cross-validation-with-python/
你好。
何时应使用 binary_crossentropy 指标,何时应使用 binary_accuracy 来优化我们的模型?
何时应使用 categorical_crossentropy 指标,何时应使用 categorical_accuracy?
Juan… 您可能会对以下资源感兴趣
https://neptune.ai/blog/performance-metrics-in-machine-learning-complete-guide
https://towardsdatascience.com/metrics-to-evaluate-your-machine-learning-algorithm-f10ba6e38234