Cycle生成对抗网络(CycleGAN)是一种用于图像到图像翻译任务的深度卷积神经网络训练方法。
与其他用于图像翻译的GAN模型不同,CycleGAN不需要成对图像的数据集。例如,如果我们想将橙子的照片转换为苹果,我们不需要橙子已手动转换为苹果的训练数据集。这使得我们可以在不存在训练数据集的问题上开发翻译模型,例如将绘画转换为照片。
在本教程中,您将学习如何开发一个CycleGAN模型来将马的照片转换为斑马,反之亦然。
完成本教程后,您将了解:
- 如何加载和准备马到斑马的图像翻译数据集以进行建模。
- 如何训练一对CycleGAN生成器模型,用于将马翻译成斑马,以及将斑马翻译成马。
- 如何加载保存的CycleGAN模型并使用它们来翻译照片。
通过我的新书《Python生成对抗网络》来启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何使用 Keras 开发 CycleGAN 进行图像到图像翻译
照片来自A. Munar,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 什么是CycleGAN?
- 如何准备马到斑马数据集
- 如何开发CycleGAN以将马翻译成斑马
- 如何使用CycleGAN生成器进行图像翻译
什么是CycleGAN?
CycleGAN模型由Jun-Yan Zhu等人于2017年在其题为《Cycle一致对抗网络的无配对图像到图像翻译》的论文中提出。
CycleGAN模型的优点在于无需配对的示例即可进行训练。也就是说,它不需要在翻译前后同一场景的照片才能训练模型,例如白天和夜晚同一城市景观的照片。相反,该模型能够使用来自每个域的照片集合,并提取和利用图像集合中的底层风格以执行翻译。
模型架构由两个生成器模型组成:一个生成器(生成器-A)用于生成第一域(域-A)的图像,第二个生成器(生成器-B)用于生成第二域(域-B)的图像。
- 生成器-A -> 域-A
- 生成器-B -> 域-B
生成器模型执行图像翻译,这意味着图像生成过程以输入图像为条件,特别是来自另一域的图像。生成器-A以域-B中的图像作为输入,生成器-B以域-A中的图像作为输入。
- 域-B -> 生成器-A -> 域-A
- 域-A -> 生成器-B -> 域-B
每个生成器都有一个相应的判别器模型。第一个判别器模型(判别器-A)接收来自域-A的真实图像和来自生成器-A的生成图像,并预测它们是真实的还是假的。第二个判别器模型(判别器-B)接收来自域-B的真实图像和来自生成器-B的生成图像,并预测它们是真实的还是假的。
- 域-A -> 判别器-A -> [真/假]
- 域-B -> 生成器-A -> 判别器-A -> [真/假]
- 域-B -> 判别器-B -> [真/假]
- 域-A -> 生成器-B -> 判别器-B -> [真/假]
判别器和生成器模型以类似普通GAN模型的对抗性零和过程进行训练。生成器学会更好地欺骗判别器,判别器学会更好地检测假图像。在训练过程中,模型共同找到一个平衡点。
此外,生成器模型被正则化,不仅在目标域中创建新图像,而是翻译输入域的更重构版本。这是通过将生成图像作为对应生成器模型的输入,并将输出图像与原始图像进行比较来实现的。将图像通过两个生成器称为一个周期。成对的生成器模型共同训练以更好地重现原始源图像,这被称为周期一致性。
- 域-B -> 生成器-A -> 域-A -> 生成器-B -> 域-B
- 域-A -> 生成器-B -> 域-B -> 生成器-A -> 域-A
架构中还有一个元素,称为身份映射。这是生成器接收目标域中的图像作为输入,并期望生成相同的图像而不改变。这种对架构的添加是可选的,尽管它能更好地匹配输入图像的颜色配置文件。
- 域-A -> 生成器-A -> 域-A
- 域-B -> 生成器-B -> 域-B
现在我们熟悉了模型架构,我们可以逐一仔细查看每个模型以及如何实现它们。
该论文很好地描述了模型和训练过程,尽管官方Torch实现被用作每个模型和训练过程的最终描述,并为下面描述的模型实现提供了基础。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何准备马到斑马数据集
论文中CycleGAN的一个令人印象深刻的例子是将马的照片转换为斑马,反之亦然,将斑马转换为马。
论文作者称之为“物体变形”的问题,它也被展示在苹果和橘子的照片上。
在本教程中,我们将从头开始开发一个CycleGAN,用于将马的图像翻译成斑马,反之亦然(或物体变形)。
我们将此数据集称为“horses2zebra”。该数据集的zip文件大小约为111兆字节,可以从CycleGAN网页下载。
将数据集下载到当前工作目录。
您将看到以下目录结构
|
1 2 3 4 5 |
horse2zebra ├── testA ├── testB ├── trainA └── trainB |
“A”类别指马,“B”类别指斑马,数据集包括训练和测试元素。我们将加载所有照片并将其用作训练数据集。
照片是正方形的,形状为256×256,文件名类似“n02381460_2.jpg”。
下面的示例将加载训练和测试文件夹中的所有照片,并为类别A创建一个图像数组,为类别B创建另一个数组。
然后将两个数组以压缩NumPy数组格式保存到新文件中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 准备马和斑马数据集的示例 from os import listdir from numpy import asarray from numpy import vstack from keras.preprocessing.image import img_to_array from keras.preprocessing.image import load_img from numpy import savez_compressed # 将目录中的所有图像加载到内存中 def load_images(path, size=(256,256)): data_list = list() # 枚举目录中的文件名,假设所有都是图像 for filename in listdir(path): # 加载并调整图像大小 pixels = load_img(path + filename, target_size=size) # 转换为numpy数组 pixels = img_to_array(pixels) # 存储 data_list.append(pixels) return asarray(data_list) # 数据集路径 path = 'horse2zebra/' # 加载数据集A dataA1 = load_images(path + 'trainA/') dataAB = load_images(path + 'testA/') dataA = vstack((dataA1, dataAB)) print('Loaded dataA: ', dataA.shape) # 加载数据集B dataB1 = load_images(path + 'trainB/') dataB2 = load_images(path + 'testB/') dataB = vstack((dataB1, dataB2)) print('Loaded dataB: ', dataB.shape) # 保存为压缩numpy数组 filename = 'horse2zebra_256.npz' savez_compressed(filename, dataA, dataB) print('Saved dataset: ', filename) |
运行示例后,首先将所有图像加载到内存中,显示A类(马)有1187张照片,B类(斑马)有1474张照片。
然后将数组以压缩NumPy格式保存,文件名为“horse2zebra_256.npz”。注意:此数据文件约为570兆字节,比原始图像大,因为我们将像素值存储为32位浮点值。
|
1 2 3 |
Loaded dataA: (1187, 256, 256, 3) Loaded dataB: (1474, 256, 256, 3) Saved dataset: horse2zebra_256.npz |
然后我们可以加载数据集并绘制一些照片,以确认我们正确处理了图像数据。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 加载并绘制准备好的数据集 from numpy import load from matplotlib import pyplot # 加载数据集 data = load('horse2zebra_256.npz') dataA, dataB = data['arr_0'], data['arr_1'] print('Loaded: ', dataA.shape, dataB.shape) # 绘制源图像 n_samples = 3 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + i) pyplot.axis('off') pyplot.imshow(dataA[i].astype('uint8')) # 绘制目标图像 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + n_samples + i) pyplot.axis('off') pyplot.imshow(dataB[i].astype('uint8')) pyplot.show() |
运行示例后,加载数据集,确认示例的数量和彩色图像的形状符合我们的预期。
|
1 |
Loaded: (1187, 256, 256, 3) (1474, 256, 256, 3) |
创建一张图,显示来自马照片数据集(dataA)的三张图像和来自斑马数据集(dataB)的三张图像。

《Horses2Zeba》数据集照片图
现在我们已经准备好了数据集进行建模,我们可以开发CycleGAN生成器模型,该模型可以实现从一个类别到另一个类别的照片翻译,反之亦然。
如何开发CycleGAN以将马翻译成斑马
在本节中,我们将开发CycleGAN模型,用于将马的照片翻译成斑马,以及将斑马的照片翻译成马。
论文中描述的相同模型架构和配置已被用于各种图像到图像的翻译任务。该架构在论文主体中有描述,在论文的附录中有更多细节,并且完整的可用实现已开源,为Torch深度学习框架实现。
本节中的实现将使用Keras深度学习框架,直接基于论文中描述的模型以及作者代码库中的实现,旨在接受和生成大小为256×256像素的彩色图像。
该架构由四个模型组成,两个判别器模型和两个生成器模型。
判别器是一个深度卷积神经网络,它执行图像分类。它以源图像作为输入,并预测目标图像是真实图像还是伪造图像的可能性。使用了两个判别器模型,一个用于域-A(马),一个用于域-B(斑马)。
判别器的设计基于模型的有效感受野,它定义了模型的一个输出与输入图像像素数量的关系。这被称为PatchGAN模型,并且经过精心设计,使得模型的每个输出预测都映射到输入图像的70×70方形或块。这种方法的优点是相同的模型可以应用于不同大小的输入图像,例如大于或小于256×256像素。
模型的输出取决于输入图像的大小,但可能是一个值或一个值的方形激活图。每个值都是关于输入图像中某个块为真的可能性。如果需要,可以将这些值平均以给出整体可能性或分类分数。
模型中使用了卷积-批标准化-LeakyReLU层模式,这对于深度卷积判别器模型来说很常见。与其他模型不同,CycleGAN判别器使用实例标准化而不是批标准化。它是一种非常简单的标准化类型,它通过对每个输出特征图上的值进行标准化(例如,缩放到标准高斯分布),而不是在批次内的特征之间进行标准化。
keras-contrib项目提供了实例标准化的实现,该项目提供了社区提供的Keras功能的早期访问。
可以通过pip安装keras-contrib库,如下所示
|
1 |
sudo pip install git+https://www.github.com/keras-team/keras-contrib.git |
或者,如果您使用的是Anaconda虚拟环境,例如在EC2上
|
1 2 3 |
git clone https://www.github.com/keras-team/keras-contrib.git cd keras-contrib sudo ~/anaconda3/envs/tensorflow_p36/bin/python setup.py install |
新的InstanceNormalization层可以如下使用:
|
1 2 3 4 5 |
... from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization # 定义层 layer = InstanceNormalization(axis=-1) ... |
“axis”参数设置为-1,以确保每个特征图的特征都被标准化。
define_discriminator()函数下面实现了70×70 PatchGAN判别器模型,遵循论文中的模型设计。该模型接收256×256大小的图像作为输入,并输出一个预测块。该模型使用最小二乘损失(L2),实现为均方误差,并使用权重,以便模型更新具有通常效果的一半(0.5)。CycleGAN论文的作者推荐这种模型更新权重以减慢训练过程中判别器相对于生成器模型的变化速度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_image = Input(shape=image_shape) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(in_image) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 patch_out = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) # 定义模型 model = Model(in_image, patch_out) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.5]) return model |
生成器模型比判别器模型更复杂。
生成器是编码器-解码器模型架构。该模型接收源图像(例如马的照片)并生成目标图像(例如斑马的照片)。它首先将输入图像下采样或编码到瓶颈层,然后通过多个使用跳跃连接的 ResNet 层来解释编码,接着是一系列将表示上采样或解码到输出图像大小的层。
首先,我们需要一个函数来定义 ResNet 块。这些块由两个 3×3 CNN 层组成,其中块的输入沿通道方向与块的输出串联。
这在 `resnet_block()` 函数中实现,该函数创建两个带有 3×3 滤波器的“卷积-实例归一化”块,以及 1×1 步幅,并在第二个块后没有 ReLU 激活,这与官方 Torch 实现 `build_conv_block()` 函数 匹配。为简单起见,此处使用了相同的填充,而不是论文中推荐的反射填充。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成器resnet块 def resnet_block(n_filters, input_layer): # 权重初始化 init = RandomNormal(stddev=0.02) # 第一层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(input_layer) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # 第二层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) # 沿通道方向与输入层合并 g = Concatenate()([g, input_layer]) return g |
接下来,我们可以定义一个函数来创建 256×256 输入图像的 9-resnet 块版本。通过将 `image_shape` 设置为 (128x128x3) 并将 `n_resnet` 函数参数设置为 6,可以轻松地更改为 6-resnet 块版本。
重要的是,模型输出的像素形状与输入相同,像素值在 [-1, 1] 范围内,这对于 GAN 生成器模型来说是典型的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 定义独立的生成器模型 def define_generator(image_shape, n_resnet=9): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # c7s1-64 g = Conv2D(64, (7,7), padding='same', kernel_initializer=init)(in_image) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d128 g = Conv2D(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d256 g = Conv2D(256, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # R256 for _ in range(n_resnet): g = resnet_block(256, g) # u128 g = Conv2DTranspose(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # u64 g = Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # c7s1-3 g = Conv2D(3, (7,7), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model |
判别器模型直接在真实和生成的图像上进行训练,而生成器模型则不直接训练。
相反,生成器模型通过其相关的判别器模型进行训练。具体来说,它们被更新以最小化判别器对被标记为“真实”的生成图像预测的损失,称为对抗损失。因此,它们被鼓励生成更适合目标域的图像。
生成器模型也根据它们在使用另一个生成器模型进行源图像重构的有效性进行更新,称为循环损失。最后,生成器模型应在提供目标域的示例时输出没有翻译的图像,称为身份损失。
总而言之,每个生成器模型都通过四个输出与四个损失函数的组合进行优化:
- 对抗损失(L2 或均方误差)。
- 身份损失(L1 或平均绝对误差)。
- 前向循环损失(L1 或平均绝对误差)。
- 后向循环损失(L1 或平均绝对误差)。
这可以通过定义一个用于训练每个生成器模型的复合模型来实现,该模型仅负责更新该生成器模型的权重,尽管它需要与相关的判别器模型和其他生成器模型共享权重。
这在下面的 `define_composite_model()` 函数中实现,该函数接收一个已定义的生成器模型(`g_model_1`)、用于生成器模型输出的已定义判别器模型(`d_model`)以及另一个生成器模型(`g_model_2`)。其他模型的权重被标记为不可训练,因为我们只关心更新第一个生成器模型,即这个复合模型的焦点。
判别器连接到生成器的输出,以将生成的图像分类为真实或虚假。复合模型的第二个输入被定义为目标域(而不是源域)中的图像,生成器应输出该图像而不进行翻译,以实现身份映射。接下来,前向循环损失涉及将生成器的输出连接到另一个生成器,它将重构源图像。最后,后向循环损失涉及用于身份映射的目标域中的图像,该图像也通过另一个生成器传递,该生成器的输出作为输入连接到我们的主生成器,并输出该图像在目标域中的重构版本。
总而言之,一个复合模型有两个输入,分别用于来自 Domain-A 和 Domain-B 的真实照片,以及四个输出,分别用于判别器输出、身份生成的图像、前向循环生成的图像和后向循环生成的图像。
对于复合模型,只有第一个或主生成器模型的权重会被更新,并且是通过所有损失函数的加权总和来完成的。如论文所述,循环损失的权重比对抗损失的权重高 10 倍,身份损失的权重始终是循环损失的一半(5 倍),这与官方实现源代码一致。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 定义一个复合模型,通过对抗损失和循环损失来更新生成器 def define_composite_model(g_model_1, d_model, g_model_2, image_shape): # 确保我们正在更新的模型是可训练的 g_model_1.trainable = True # 标记判别器为不可训练 d_model.trainable = False # 标记其他生成器模型为不可训练 g_model_2.trainable = False # 判别器部分 input_gen = Input(shape=image_shape) gen1_out = g_model_1(input_gen) output_d = d_model(gen1_out) # 身份部分 input_id = Input(shape=image_shape) output_id = g_model_1(input_id) # 前向循环 output_f = g_model_2(gen1_out) # 后向循环 gen2_out = g_model_2(input_id) output_b = g_model_1(gen2_out) # 定义模型图 model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b]) # 定义优化算法配置 opt = Adam(lr=0.0002, beta_1=0.5) # 使用最小二乘损失和 L1 损失的加权来编译模型 model.compile(loss=['mse', 'mae', 'mae', 'mae'], loss_weights=[1, 5, 10, 10], optimizer=opt) return model |
我们需要为每个生成器模型创建一个复合模型,例如生成器-A(BtoA,用于斑马到马的翻译)和生成器-B(AtoB,用于马到斑马的翻译)。
在两个域之间进行所有这些前向和后向操作可能会令人困惑。下面是所有复合模型输入和输出的完整列表。身份损失和循环损失计算为每次翻译序列的输入和输出图像之间的 L1 距离。对抗损失计算为模型输出与目标值 1.0(真实)和 0.0(虚假)之间的 L2 距离。
生成器-A 复合模型(BtoA 或斑马到马)
模型的输入、转换和输出如下:
- 对抗损失:Domain-B -> Generator-A -> Domain-A -> Discriminator-A -> [真实/虚假]
- 身份损失:Domain-A -> Generator-A -> Domain-A
- 前向循环损失:Domain-B -> Generator-A -> Domain-A -> Generator-B -> Domain-B
- 后向循环损失:Domain-A -> Generator-B -> Domain-B -> Generator-A -> Domain-A
我们可以将输入和输出总结为:
- 输入:Domain-B, Domain-A
- 输出:真实, Domain-A, Domain-B, Domain-A
生成器-B 复合模型(AtoB 或马到斑马)
模型的输入、转换和输出如下:
- 对抗损失:Domain-A -> Generator-B -> Domain-B -> Discriminator-B -> [真实/虚假]
- 身份损失:Domain-B -> Generator-B -> Domain-B
- 前向循环损失:Domain-A -> Generator-B -> Domain-B -> Generator-A -> Domain-A
- 后向循环损失:Domain-B -> Generator-A -> Domain-A -> Generator-B -> Domain-B
我们可以将输入和输出总结为:
- 输入:Domain-A, Domain-B
- 输出:真实, Domain-B, Domain-A, Domain-B
定义模型是 CycleGAN 的难点;其余部分是标准的 GAN 训练,相对直接。
接下来,我们可以加载压缩 NumPy 格式的配对图像数据集。这将返回一个 NumPy 数组列表:第一个用于源图像,第二个用于相应的目标图像。
|
1 2 3 4 5 6 7 8 9 10 |
# 加载并准备训练图像 def load_real_samples(filename): # 加载数据集 data = load(filename) # 解包数组 X1, X2 = data['arr_0'], data['arr_1'] # 从 [0,255] 缩放到 [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 return [X1, X2] |
在每次训练迭代中,我们将需要来自每个域的真实图像样本作为判别器和复合生成器模型的输入。这可以通过选择随机样本批次来实现。
下面的 `generate_real_samples()` 函数实现了这一点,它将一个域的 NumPy 数组作为输入,并返回请求数量的随机选择的图像,以及用于 PatchGAN 判别器模型指示图像为真实的(`target=1.0`)的目标。因此,也提供了 PatchGAN 输出的形状,在 256×256 图像的情况下,它将是 16,即 16x16x1 的激活图,由 `patch_shape` 函数参数定义。
|
1 2 3 4 5 6 7 8 9 |
# 选择一批随机样本,返回图像和目标 def generate_real_samples(dataset, n_samples, patch_shape): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, patch_shape, patch_shape, 1)) return X, y |
同样,为了在每次训练迭代中更新每个判别器模型,需要一个生成的图像样本。
下面的 `generate_fake_samples()` 函数在给定生成器模型和源域的真实图像样本的情况下生成此样本。同样,为每个生成的图像提供了目标值,以及 PatchGAN 的正确形状,表明它们是虚假的或生成的(`target=0.0`)。
|
1 2 3 4 5 6 7 |
# 生成一批图像,返回图像和目标 def generate_fake_samples(g_model, dataset, patch_shape): # 生成伪造实例 X = g_model.predict(dataset) # 创建“假”类别标签 (0) y = zeros((len(X), patch_shape, patch_shape, 1)) return X, y |
通常,GAN 模型不会收敛;相反,它们在生成器和判别器模型之间找到一个平衡。因此,我们无法轻易判断训练是否应该停止。因此,我们可以保存模型,并使用它在训练期间定期生成样本图像到图像的翻译,例如每训练一个或五个 epoch。
然后,我们可以在训练结束时查看生成的图像,并使用图像质量来选择最终模型。
下面的 `save_models()` 函数将每个生成器模型保存到当前目录,格式为 H5,并在文件名中包含训练迭代次数。这将需要安装h5py 库。
|
1 2 3 4 5 6 7 8 9 |
# 将生成器模型保存到文件 def save_models(step, g_model_AtoB, g_model_BtoA): # 保存第一个生成器模型 filename1 = 'g_model_AtoB_%06d.h5' % (step+1) g_model_AtoB.save(filename1) # 保存第二个生成器模型 filename2 = 'g_model_BtoA_%06d.h5' % (step+1) g_model_BtoA.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) |
下面的 `summarize_performance()` 函数使用给定的生成器模型生成几个随机选择的源照片的翻译版本,并将图表保存到文件。
源图像绘制在第一行,生成的图像绘制在第二行。同样,绘图文件名包含训练迭代次数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, trainX, name, n_samples=5): # 选择一个样本输入图像 X_in, _ = generate_real_samples(trainX, n_samples, 0) # 生成翻译后的图像 X_out, _ = generate_fake_samples(g_model, X_in, 0) # 将所有像素从 [-1,1] 缩放到 [0,1] X_in = (X_in + 1) / 2.0 X_out = (X_out + 1) / 2.0 # 绘制真实图像 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + i) pyplot.axis('off') pyplot.imshow(X_in[i]) # 绘制翻译后的图像 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + n_samples + i) pyplot.axis('off') pyplot.imshow(X_out[i]) # 保存图到文件 filename1 = '%s_generated_plot_%06d.png' % (name, (step+1)) pyplot.savefig(filename1) pyplot.close() |
我们几乎准备好定义模型的训练了。
判别器模型直接在真实图像和生成的图像上进行更新,但为了进一步控制判别器模型的学习速度,会维护一个假图像池。
该论文为每个判别器模型定义了一个包含50张生成图像的图像池,该池首先被填充,然后根据概率将新图像替换现有图像添加到池中,或者直接使用生成的图像。我们可以为每个判别器实现一个图像列表,并使用下面的 `update_image_pool()` 函数来维护每个池列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 更新假图像的图像池 def update_image_pool(pool, images, max_size=50): selected = list() for image in images: if len(pool) < max_size: # 填充池 pool.append(image) selected.append(image) elif random() < 0.5: # 使用图像,但不将其添加到池中 selected.append(image) else: # 替换现有图像并使用替换后的图像 ix = randint(0, len(pool)) selected.append(pool[ix]) pool[ix] = image return asarray(selected) |
现在我们可以定义每个生成器模型的训练了。
下面的 `train()` 函数将所有六个模型(两个判别器、两个生成器和两个复合模型)作为参数,并结合数据集来训练模型。
批量大小固定为一张图像,以匹配论文中的描述,模型将训练 100个 epoch。考虑到马数据集有1187张图像,一个 epoch 被定义为1187个批次,训练迭代次数也相同。每个 epoch 都使用两个生成器生成图像,并且每五个 epoch 或 (1187 * 5) 5,935 次训练迭代保存一次模型。
模型更新的顺序是为了匹配官方的Torch实现。首先,从每个域中选择一批真实图像,然后为每个域生成一批假图像。然后,这些假图像用于更新每个判别器的假图像池。
接下来,通过复合模型更新生成器-A模型(斑马到马),然后更新判别器-A模型(马)。然后更新生成器-B(马到斑马)的复合模型和判别器-B(斑马)模型。
最后报告每个更新模型的损失。重要的是,只报告用于更新每个生成器的加权平均损失。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 训练cyclegan模型 def train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset): # 定义运行的属性 n_epochs, n_batch, = 100, 1 # 确定判别器的输出正方形形状 n_patch = d_model_A.output_shape[1] # 解包数据集 trainA, trainB = dataset # 准备假图像的图像池 poolA, poolB = list(), list() # 计算每个训练 epoch 的批次数量 bat_per_epo = int(len(trainA) / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 手动枚举 epoch for i in range(n_steps): # 选择一批真实样本 X_realA, y_realA = generate_real_samples(trainA, n_batch, n_patch) X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch) # 生成一批伪造样本 X_fakeA, y_fakeA = generate_fake_samples(g_model_BtoA, X_realB, n_patch) X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch) # 更新池中的假图像 X_fakeA = update_image_pool(poolA, X_fakeA) X_fakeB = update_image_pool(poolB, X_fakeB) # 通过对抗和循环损失更新生成器 B->A g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA]) # 更新判别器 A -> [真实/虚假] dA_loss1 = d_model_A.train_on_batch(X_realA, y_realA) dA_loss2 = d_model_A.train_on_batch(X_fakeA, y_fakeA) # 通过对抗和循环损失更新生成器 A->B g_loss1, _, _, _, _ = c_model_AtoB.train_on_batch([X_realA, X_realB], [y_realB, X_realB, X_realA, X_realB]) # 更新判别器 B -> [真实/虚假] dB_loss1 = d_model_B.train_on_batch(X_realB, y_realB) dB_loss2 = d_model_B.train_on_batch(X_fakeB, y_fakeB) # 总结性能 print('>%d, dA[%.3f,%.3f] dB[%.3f,%.3f] g[%.3f,%.3f]' % (i+1, dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2)) # 定期评估模型性能 if (i+1) % (bat_per_epo * 1) == 0: # 绘制 A->B 翻译 summarize_performance(i, g_model_AtoB, trainA, 'AtoB') # 绘制 B->A 翻译 summarize_performance(i, g_model_BtoA, trainB, 'BtoA') if (i+1) % (bat_per_epo * 5) == 0: # 保存模型 save_models(i, g_model_AtoB, g_model_BtoA) |
将所有这些结合起来,下面列出了在马匹和斑马之间进行图像翻译的CycleGAN模型的完整训练示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 |
# 在horse2zebra数据集上训练cyclegan的示例 from random import random from numpy import load from numpy import zeros from numpy import ones from numpy import asarray from numpy.random import randint from keras.optimizers import Adam from keras.initializers import RandomNormal from keras.models import Model from keras.models import Input 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.layers import Activation from keras.layers import Concatenate from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization from matplotlib import pyplot # 定义判别器模型 def define_discriminator(image_shape): # 权重初始化 init = RandomNormal(stddev=0.02) # 源图像输入 in_image = Input(shape=image_shape) # C64 d = Conv2D(64, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(in_image) d = LeakyReLU(alpha=0.2)(d) # C128 d = Conv2D(128, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C256 d = Conv2D(256, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # C512 d = Conv2D(512, (4,4), strides=(2,2), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 倒数第二层输出 d = Conv2D(512, (4,4), padding='same', kernel_initializer=init)(d) d = InstanceNormalization(axis=-1)(d) d = LeakyReLU(alpha=0.2)(d) # 补丁输出 patch_out = Conv2D(1, (4,4), padding='same', kernel_initializer=init)(d) # 定义模型 model = Model(in_image, patch_out) # 编译模型 model.compile(loss='mse', optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.5]) return model # 生成器resnet块 def resnet_block(n_filters, input_layer): # 权重初始化 init = RandomNormal(stddev=0.02) # 第一层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(input_layer) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # 第二层卷积层 g = Conv2D(n_filters, (3,3), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) # 沿通道方向与输入层合并 g = Concatenate()([g, input_layer]) return g # 定义独立的生成器模型 def define_generator(image_shape, n_resnet=9): # 权重初始化 init = RandomNormal(stddev=0.02) # 图像输入 in_image = Input(shape=image_shape) # c7s1-64 g = Conv2D(64, (7,7), padding='same', kernel_initializer=init)(in_image) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d128 g = Conv2D(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # d256 g = Conv2D(256, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # R256 for _ in range(n_resnet): g = resnet_block(256, g) # u128 g = Conv2DTranspose(128, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # u64 g = Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) g = Activation('relu')(g) # c7s1-3 g = Conv2D(3, (7,7), padding='same', kernel_initializer=init)(g) g = InstanceNormalization(axis=-1)(g) out_image = Activation('tanh')(g) # 定义模型 model = Model(in_image, out_image) return model # 定义一个复合模型,通过对抗损失和循环损失来更新生成器 def define_composite_model(g_model_1, d_model, g_model_2, image_shape): # 确保我们正在更新的模型是可训练的 g_model_1.trainable = True # 标记判别器为不可训练 d_model.trainable = False # 标记其他生成器模型为不可训练 g_model_2.trainable = False # 判别器部分 input_gen = Input(shape=image_shape) gen1_out = g_model_1(input_gen) output_d = d_model(gen1_out) # 身份部分 input_id = Input(shape=image_shape) output_id = g_model_1(input_id) # 前向循环 output_f = g_model_2(gen1_out) # 后向循环 gen2_out = g_model_2(input_id) output_b = g_model_1(gen2_out) # 定义模型图 model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b]) # 定义优化算法配置 opt = Adam(lr=0.0002, beta_1=0.5) # 使用最小二乘损失和 L1 损失的加权来编译模型 model.compile(loss=['mse', 'mae', 'mae', 'mae'], loss_weights=[1, 5, 10, 10], optimizer=opt) return model # 加载并准备训练图像 def load_real_samples(filename): # 加载数据集 data = load(filename) # 解包数组 X1, X2 = data['arr_0'], data['arr_1'] # 从 [0,255] 缩放到 [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 return [X1, X2] # 选择一批随机样本,返回图像和目标 def generate_real_samples(dataset, n_samples, patch_shape): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] # 生成“真实”类别标签 (1) y = ones((n_samples, patch_shape, patch_shape, 1)) 返回 X, y # 生成一批图像,返回图像和目标 def generate_fake_samples(g_model, dataset, patch_shape): # 生成伪造实例 X = g_model.predict(dataset) # 创建“假”类别标签 (0) y = zeros((len(X), patch_shape, patch_shape, 1)) 返回 X, y # 将生成器模型保存到文件 def save_models(step, g_model_AtoB, g_model_BtoA): # 保存第一个生成器模型 filename1 = 'g_model_AtoB_%06d.h5' % (step+1) g_model_AtoB.save(filename1) # 保存第二个生成器模型 filename2 = 'g_model_BtoA_%06d.h5' % (step+1) g_model_BtoA.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) # 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, trainX, name, n_samples=5): # 选择一个样本输入图像 X_in, _ = generate_real_samples(trainX, n_samples, 0) # 生成翻译后的图像 X_out, _ = generate_fake_samples(g_model, X_in, 0) # 将所有像素从 [-1,1] 缩放到 [0,1] X_in = (X_in + 1) / 2.0 X_out = (X_out + 1) / 2.0 # 绘制真实图像 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + i) pyplot.axis('off') pyplot.imshow(X_in[i]) # 绘制翻译后的图像 for i in range(n_samples): pyplot.subplot(2, n_samples, 1 + n_samples + i) pyplot.axis('off') pyplot.imshow(X_out[i]) # 保存图到文件 filename1 = '%s_generated_plot_%06d.png' % (name, (step+1)) pyplot.savefig(filename1) pyplot.close() # 更新假图像的图像池 def update_image_pool(pool, images, max_size=50): selected = list() for image in images: if len(pool) < max_size: # 填充池 pool.append(image) selected.append(image) elif random() < 0.5: # 使用图像,但不将其添加到池中 selected.append(image) else: # 替换现有图像并使用替换后的图像 ix = randint(0, len(pool)) selected.append(pool[ix]) pool[ix] = image return asarray(selected) # 训练cyclegan模型 def train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset): # 定义运行的属性 n_epochs, n_batch, = 100, 1 # 确定判别器的输出正方形形状 n_patch = d_model_A.output_shape[1] # 解包数据集 trainA, trainB = dataset # 准备假图像的图像池 poolA, poolB = list(), list() # 计算每个训练 epoch 的批次数量 bat_per_epo = int(len(trainA) / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 手动枚举 epoch for i in range(n_steps): # 选择一批真实样本 X_realA, y_realA = generate_real_samples(trainA, n_batch, n_patch) X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch) # 生成一批伪造样本 X_fakeA, y_fakeA = generate_fake_samples(g_model_BtoA, X_realB, n_patch) X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch) # 更新池中的假图像 X_fakeA = update_image_pool(poolA, X_fakeA) X_fakeB = update_image_pool(poolB, X_fakeB) # 通过对抗和循环损失更新生成器 B->A g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA]) # 更新判别器 A -> [真实/虚假] dA_loss1 = d_model_A.train_on_batch(X_realA, y_realA) dA_loss2 = d_model_A.train_on_batch(X_fakeA, y_fakeA) # 通过对抗和循环损失更新生成器 A->B g_loss1, _, _, _, _ = c_model_AtoB.train_on_batch([X_realA, X_realB], [y_realB, X_realB, X_realA, X_realB]) # 更新判别器 B -> [真实/虚假] dB_loss1 = d_model_B.train_on_batch(X_realB, y_realB) dB_loss2 = d_model_B.train_on_batch(X_fakeB, y_fakeB) # 总结性能 print('>%d, dA[%.3f,%.3f] dB[%.3f,%.3f] g[%.3f,%.3f]' % (i+1, dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2)) # 定期评估模型性能 if (i+1) % (bat_per_epo * 1) == 0: # 绘制 A->B 翻译 summarize_performance(i, g_model_AtoB, trainA, 'AtoB') # 绘制 B->A 翻译 summarize_performance(i, g_model_BtoA, trainB, 'BtoA') if (i+1) % (bat_per_epo * 5) == 0: # 保存模型 save_models(i, g_model_AtoB, g_model_BtoA) # 加载图像数据 dataset = load_real_samples('horse2zebra_256.npz') print('Loaded', dataset[0].shape, dataset[1].shape) # 根据加载的数据集定义输入形状 image_shape = dataset[0].shape[1:] # 生成器:A -> B g_model_AtoB = define_generator(image_shape) # 生成器:B -> A g_model_BtoA = define_generator(image_shape) # 判别器:A -> [真实/虚假] d_model_A = define_discriminator(image_shape) # 判别器:B -> [真实/虚假] d_model_B = define_discriminator(image_shape) # 复合模型:A -> B -> [真实/虚假, A] c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape) # 复合模型:B -> A -> [真实/虚假, B] c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape) # 训练模型 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset) |
该示例可以在CPU硬件上运行,但推荐使用GPU硬件。
该示例在现代GPU硬件上可能需要数小时才能运行。
如果需要,可以通过 Amazon EC2 访问廉价的 GPU 硬件;请参阅教程
注意:您的结果可能会因算法或评估程序的随机性、数值精度差异而有所不同。可以尝试运行几次该示例,并比较平均结果。
每次训练迭代都会报告损失,包括判别器 A 在真实和虚假样本上的损失 (dA),判别器 B 在真实和虚假样本上的损失 (dB),以及生成器 AtoB 和生成器 BtoA 的损失,每个损失是对抗性损失、身份损失、正向循环损失和反向循环损失的加权平均值 (g)。
如果判别器的损失降至零并长时间保持不变,请考虑重新启动训练,因为这表明训练失败。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>1, dA[2.284,0.678] dB[1.422,0.918] g[18.747,18.452] >2, dA[2.129,1.226] dB[1.039,1.331] g[19.469,22.831] >3, dA[1.644,3.909] dB[1.097,1.680] g[19.192,23.757] >4, dA[1.427,1.757] dB[1.236,3.493] g[20.240,18.390] >5, dA[1.737,0.808] dB[1.662,2.312] g[16.941,14.915] ... >118696, dA[0.004,0.016] dB[0.001,0.001] g[2.623,2.359] >118697, dA[0.001,0.028] dB[0.003,0.002] g[3.045,3.194] >118698, dA[0.002,0.008] dB[0.001,0.002] g[2.685,2.071] >118699, dA[0.010,0.010] dB[0.001,0.001] g[2.430,2.345] >118700, dA[0.002,0.008] dB[0.000,0.004] g[2.487,2.169] >Saved: g_model_AtoB_118700.h5 and g_model_BtoA_118700.h5 |
生成的图像图表在每个 epoch 结束时或每 1,187 次训练迭代后保存,文件名中包含迭代次数。
|
1 2 3 4 5 |
AtoB_generated_plot_001187.png AtoB_generated_plot_002374.png ... BtoA_generated_plot_001187.png BtoA_generated_plot_002374.png |
模型每五个 epoch 或 (1187 * 5) 5,935 次训练迭代保存一次,文件名中也包含迭代次数。
|
1 2 3 4 5 |
g_model_AtoB_053415.h5 g_model_AtoB_059350.h5 ... g_model_BtoA_053415.h5 g_model_BtoA_059350.h5 |
生成的图像图表可用于选择模型,更多的训练迭代不一定意味着更高质量的生成图像。
马匹到斑马的翻译在大约 50 个 epoch 后开始变得可靠。

训练 53,415 次迭代后,源马照片(上行)和翻译后的斑马照片(下行)的图。
斑马到马的翻译似乎对模型来说更具挑战性,尽管在 50 到 60 个 epoch 后也开始生成一些合理的翻译。
我怀疑如果再进行 100 个 epoch 的训练并进行权重衰减(如论文中所用),并且可能使用一个系统地处理每个数据集而不是随机采样的 Keras 数据生成器,可以获得更好的结果。

训练 90,212 次迭代后,源斑马照片(上行)和翻译后的马匹照片(下行)的图。
现在我们已经拟合了 CycleGAN 生成器,我们可以使用它们来以一种随性的方式翻译照片。
如何使用 CycleGAN 生成器进行图像翻译
可以加载已保存的生成器模型并用于随性的图像翻译。
第一步是加载数据集。我们可以使用在上一节中开发的相同的 `load_real_samples()` 函数。
|
1 2 3 4 |
... # 加载数据集 A_data, B_data = load_real_samples('horse2zebra_256.npz') print('Loaded', A_data.shape, B_data.shape) |
查看生成的图像图表,并选择一对我们可以用于图像生成的模型。在这种情况下,我们将使用大约在第 89 个 epoch(训练迭代 89,025)保存的模型。我们的生成器模型使用了 `keras_contrib` 库中的自定义层,特别是 `InstanceNormalization` 层。因此,在加载每个生成器模型时,我们需要指定如何加载此层。
这可以通过指定一个从层名称到对象的字典映射,并将其作为参数传递给 Keras 的 `load_model()` 函数来实现。
|
1 2 3 4 5 |
... # 加载模型 cust = {'InstanceNormalization': InstanceNormalization} model_AtoB = load_model('g_model_AtoB_089025.h5', cust) model_BtoA = load_model('g_model_BtoA_089025.h5', cust) |
我们可以使用我们在上一节中开发的 `select_sample()` 函数从数据集中选择一个随机照片。
|
1 2 3 4 5 6 7 |
# 从数据集中选择一个随机样本图像 def select_sample(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] return X |
接下来,我们可以使用 Generator-AtoB 模型,首先从域 A(马匹)中选择一张随机图像作为输入,使用 Generator-AtoB 将其翻译成域 B(斑马),然后使用 Generator-BtoA 模型重建原始图像(马匹)。
|
1 2 3 4 |
# 绘制 A->B->A A_real = select_sample(A_data, 1) B_generated = model_AtoB.predict(A_real) A_reconstructed = model_BtoA.predict(B_generated) |
然后,我们可以将这三张照片并排展示,分别是原始的或真实的照片、翻译后的照片以及原始照片的重建。下面的 show_plot() 函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 绘制图像、翻译和重建结果 def show_plot(imagesX, imagesY1, imagesY2): images = vstack((imagesX, imagesY1, imagesY2)) titles = ['Real', 'Generated', 'Reconstructed'] # 将范围从[-1,1]缩放到[0,1] images = (images + 1) / 2.0 # 按行绘制图像 for i in range(len(images)): # 定义子图 pyplot.subplot(1, len(images), 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(images[i]) # 标题 pyplot.title(titles[i]) pyplot.show() |
然后,我们可以调用此函数来绘制我们的真实照片和生成的照片。
|
1 2 |
... show_plot(A_real, B_generated, A_reconstructed) |
这是对两个模型的良好测试,但是,我们也可以执行相同的反向操作。
具体来说,是领域 B(斑马)中的真实照片翻译到领域 A(马),然后重建为领域 B(斑马)。
|
1 2 3 4 5 |
# 绘制 B->A->B B_real = select_sample(B_data, 1) A_generated = model_BtoA.predict(B_real) B_reconstructed = model_AtoB.predict(A_generated) show_plot(B_real, A_generated, B_reconstructed) |
将所有这些联系在一起,完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 使用保存的 CycleGAN 模型进行图像翻译的示例 from keras.models import load_model from numpy import load from numpy import vstack from matplotlib import pyplot from numpy.random import randint from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization # 加载并准备训练图像 def load_real_samples(filename): # 加载数据集 data = load(filename) # 解包数组 X1, X2 = data['arr_0'], data['arr_1'] # 从 [0,255] 缩放到 [-1,1] X1 = (X1 - 127.5) / 127.5 X2 = (X2 - 127.5) / 127.5 return [X1, X2] # 从数据集中选择一个随机样本图像 def select_sample(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 检索选定的图像 X = dataset[ix] return X # 绘制图像、翻译和重建结果 def show_plot(imagesX, imagesY1, imagesY2): images = vstack((imagesX, imagesY1, imagesY2)) titles = ['Real', 'Generated', 'Reconstructed'] # 将范围从[-1,1]缩放到[0,1] images = (images + 1) / 2.0 # 按行绘制图像 for i in range(len(images)): # 定义子图 pyplot.subplot(1, len(images), 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(images[i]) # 标题 pyplot.title(titles[i]) pyplot.show() # 加载数据集 A_data, B_data = load_real_samples('horse2zebra_256.npz') print('Loaded', A_data.shape, B_data.shape) # 加载模型 cust = {'InstanceNormalization': InstanceNormalization} model_AtoB = load_model('g_model_AtoB_089025.h5', cust) model_BtoA = load_model('g_model_BtoA_089025.h5', cust) # 绘制 A->B->A A_real = select_sample(A_data, 1) B_generated = model_AtoB.predict(A_real) A_reconstructed = model_BtoA.predict(B_generated) show_plot(A_real, B_generated, A_reconstructed) # 绘制 B->A->B B_real = select_sample(B_data, 1) A_generated = model_BtoA.predict(B_real) B_reconstructed = model_AtoB.predict(A_generated) show_plot(B_real, A_generated, B_reconstructed) |
运行示例时,首先会选择一张随机的马的照片,对其进行翻译,然后尝试重建原始照片。

使用 CycleGAN 将真实的马的照片、翻译成斑马的照片以及重建的马的照片绘制出来。
然后以相反的顺序执行类似的过程,选择一张随机的斑马照片,将其翻译成马,然后重建原始的斑马照片。

使用 CycleGAN 将真实的斑马的照片、翻译成马的照片以及重建的斑马的照片绘制出来。
注意:您的结果可能会因算法或评估程序的随机性、数值精度差异而有所不同。可以尝试运行几次该示例,并比较平均结果。
模型并不完美,尤其是斑马到马的模型,因此您可能需要生成许多翻译的示例进行审查。
似乎两个模型在重建图像时都更有效,这很有趣,因为它们执行的任务与处理真实照片时执行的任务基本相同。这可能表明在训练过程中对抗性损失不够强大。
我们可能还想以独立的方式将生成器模型用于单个照片文件。
首先,我们可以从训练数据集中选择一张照片。在这种情况下,我们将使用“horse2zebra/trainA/n02381460_541.jpg”。

马的照片
我们可以开发一个函数来加载此图像并将其缩放到首选大小 256×256,将像素值缩放到 [-1,1] 的范围,并将像素数组转换为单个样本。
下面的 load_image() 函数实现了这一点。
|
1 2 3 4 5 6 7 8 9 10 |
def load_image(filename, size=(256,256)): # 加载并调整图像大小 pixels = load_img(filename, target_size=size) # 转换为numpy数组 pixels = img_to_array(pixels) # 转换为样本 pixels = expand_dims(pixels, 0) # 从 [0,255] 缩放到 [-1,1] pixels = (pixels - 127.5) / 127.5 return pixels |
然后,我们可以加载选定的图像以及 AtoB 生成器模型,就像之前一样。
|
1 2 3 4 5 6 |
... # 加载图像 image_src = load_image('horse2zebra/trainA/n02381460_541.jpg') # 加载模型 cust = {'InstanceNormalization': InstanceNormalization} model_AtoB = load_model('g_model_AtoB_089025.h5', cust) |
然后,我们可以翻译加载的图像,将像素值缩回预期的范围,并绘制结果。
|
1 2 3 4 5 6 7 8 |
... # 翻译图像 image_tar = model_AtoB.predict(image_src) # 将范围从[-1,1]缩放到[0,1] image_tar = (image_tar + 1) / 2.0 # 绘制翻译后的图像 pyplot.imshow(image_tar[0]) pyplot.show() |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 使用保存的 CycleGAN 模型进行图像翻译的示例 from numpy import load from numpy import expand_dims from keras.models import load_model from keras_contrib.layers.normalization.instancenormalization import InstanceNormalization from keras.preprocessing.image import img_to_array from keras.preprocessing.image import load_img from matplotlib import pyplot # 将图像加载到首选大小 def load_image(filename, size=(256,256)): # 加载并调整图像大小 pixels = load_img(filename, target_size=size) # 转换为numpy数组 pixels = img_to_array(pixels) # 转换为样本 pixels = expand_dims(pixels, 0) # 从 [0,255] 缩放到 [-1,1] pixels = (pixels - 127.5) / 127.5 return pixels # 加载图像 image_src = load_image('horse2zebra/trainA/n02381460_541.jpg') # 加载模型 cust = {'InstanceNormalization': InstanceNormalization} model_AtoB = load_model('g_model_AtoB_100895.h5', cust) # 翻译图像 image_tar = model_AtoB.predict(image_src) # 将范围从[-1,1]缩放到[0,1] image_tar = (image_tar + 1) / 2.0 # 绘制翻译后的图像 pyplot.imshow(image_tar[0]) pyplot.show() |
运行示例会加载选定的图像,加载生成器模型,将马的照片翻译成斑马,然后绘制结果。
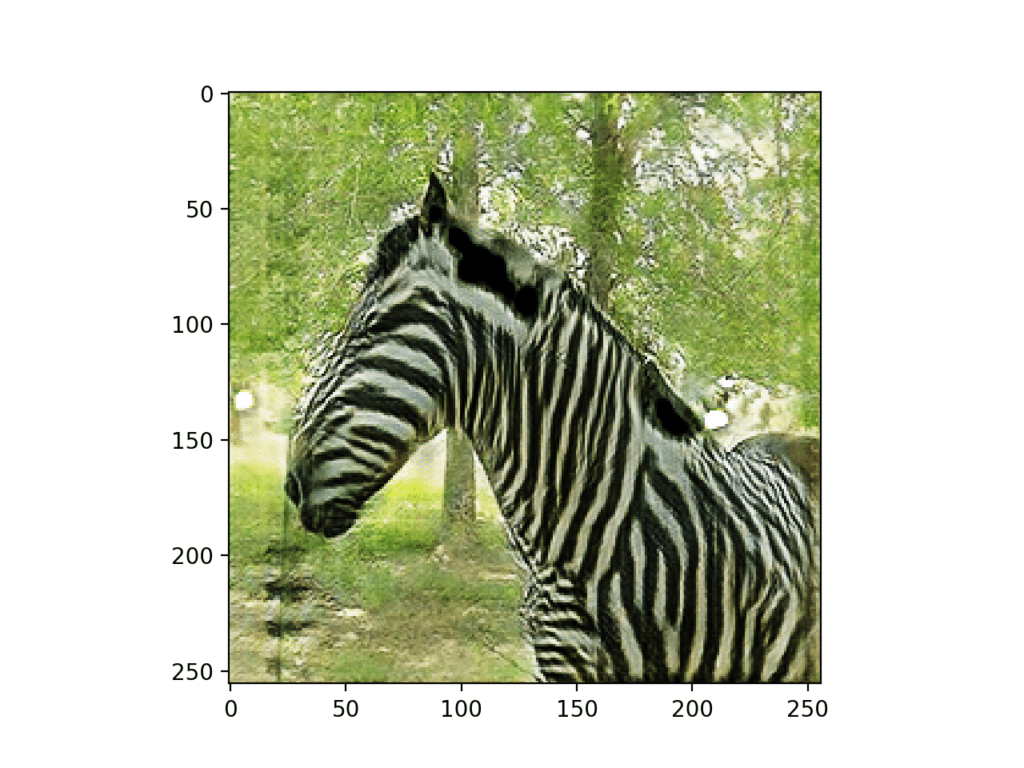
使用 CycleGAN 将真实的马的照片翻译成斑马的照片。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 较小的图像尺寸。将示例更新为使用较小的图像尺寸,例如 128×128,并将生成器模型的大小调整为使用 6 个 ResNet 层,就像 cycleGAN 论文中使用的一样。
- 不同的数据集。将示例更新为使用苹果到橙子数据集。
- 无身份映射。将示例更新为在没有身份映射的情况下训练生成器模型,并比较结果。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 使用循环一致对抗网络的未配对图像到图像转换, 2017.
项目
API
文章
总结
在本教程中,您学习了如何开发 CycleGAN 模型来将马的照片翻译成斑马,反之亦然。
具体来说,你学到了:
- 如何加载和准备马到斑马图像翻译数据集以进行建模。
- 如何训练一对 CycleGAN 生成器模型,用于将马翻译成斑马,以及将斑马翻译成马。
- 如何加载保存的CycleGAN模型并使用它们来翻译照片。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...






你好!文章写得非常好——我在 Google Colab 上成功运行了。
您能否进一步阐述一下为什么我们将图像数据压缩为 npz 文件?为什么我们需要 32 位颜色,这进一步增加了原始数据集的大小?
干得好!
谢谢。不需要使用 npz,我使用这种格式是因为它很方便,而且原始像素可能会占用大量空间!
感谢您的精彩教程。
您计划像这个 cycleGAN 教程一样,用 Keras 编写一个 starGAN 教程吗?
好问题,我将来可能会介绍它。
请将 Keras 的 starGAN 教程纳入您的计划。谢谢。
感谢您的建议。
如何使用多个 GPU 来训练模型?
好问题。我希望将来能涵盖这个主题。
好文章,我写了已经问过的问题,但如果您提供 CycleGAN 的多 GPU 版本,那将非常有帮助,因为许多模型都是基于 cycleGAN 开发的,如 UNIT、MUNIT、starGAN 和 DRIT。它将涵盖几乎所有这些模型。谢谢
感谢您的建议!
我非常欣赏您这篇好文章。
我有两个问题。
第一,在这篇文章中,默认训练是 100 个 epoch,但 pytorch 实现是 200 个 epoch。我必须更改 n_epochs 吗?或者这些实现是相同的(区别仅在于计数,对吗?)
第二,原始的 pytorch 实现似乎比这个实现更快。
这意味着原始实现经过了训练优化?还是平台性能差异?
如果您愿意,可以更改 epoch 的数量。
是的,我认为我的实现不如它可能的那样高效。
@Ebix,您能提供原始 pytorch 实现的链接吗?
请参阅教程的“扩展阅读”。
是否有可用的代码包版本?我特别需要教程代码的确切 TensorFlow 版本。
我在最后保存模型时(在“model.save(filename)”行)遇到许多弃用警告和一个错误。
示例适用于 Keras 2.3 和 TF2。
感谢您写得这么好的文章,一切都解释得很清楚!我正在处理单通道 tiff 图像,其像素值不同,最高可达 300 多。我该如何将像素值缩放到 [-1,1] 的范围?谢谢您的帮助!
谢谢。
这可能有帮助
https://machinelearning.org.cn/how-to-manually-scale-image-pixel-data-for-deep-learning/
还有这个。
https://machinelearning.org.cn/how-to-normalize-center-and-standardize-images-with-the-imagedatagenerator-in-keras/
我尝试使用单通道 tiff 图像运行代码,但我收到一个错误,消息是“ValueError: Depth of output (64) is not a multiple of the number of groups (3) for ‘model_4/conv2d_51/convolution’ (op: ‘Conv2D’) with input shapes: [?,?,?,3], [4,4,1,64]。”,错误发生在以下行:
“c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape”
完整的错误消息如下:
/base_layer.py in __call__(self, inputs, **kwargs)
449 # Actually call the layer,
450 # collecting output(s), mask(s), and shape(s).
–> 451 output = self.call(inputs, **kwargs)
452 output_mask = self.compute_mask(inputs, previous_mask)
453
/usr/local/lib/python3.6/dist-packages/keras/engine/network.py in call(self, inputs, mask)
568 return self._output_tensor_cache[cache_key]
569 else
–> 570 output_tensors, _, _ = self.run_internal_graph(inputs, masks)
571 return output_tensors
572
/usr/local/lib/python3.6/dist-packages/keras/engine/network.py in run_internal_graph(self, inputs, masks)
725 kwargs[‘mask’] = computed_mask
726 output_tensors = to_list(
–> 727 layer.call(computed_tensor, **kwargs))
728 output_masks = layer.compute_mask(computed_tensor,
729 computed_mask)
/usr/local/lib/python3.6/dist-packages/keras/layers/convolutional.py in call(self, inputs)
169 padding=self.padding,
170 data_format=self.data_format,
–> 171 dilation_rate=self.dilation_rate)
172 if self.rank == 3
173 outputs = K.conv3d(
/usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py in conv2d(x, kernel, strides, padding, data_format, dilation_rate)
3938 strides=strides,
3939 padding=padding,
-> 3940 data_format=tf_data_format)
3941
3942 if data_format == ‘channels_first’ and tf_data_format == ‘NHWC’
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/nn_ops.py in convolution(input, filter, padding, strides, dilation_rate, name, data_format, filters, dilations)
896 data_format=data_format,
897 dilations=dilation_rate,
–> 898 name=name)
899
900
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/nn_ops.py in convolution_internal(input, filters, strides, padding, data_format, dilations, name, call_from_convolution)
1007 data_format=data_format,
1008 dilations=dilations,
-> 1009 name=name)
1010 else
1011 if channel_index == 1
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/gen_nn_ops.py in conv2d(input, filter, strides, padding, use_cudnn_on_gpu, explicit_paddings, data_format, dilations, name)
1069 padding=padding, use_cudnn_on_gpu=use_cudnn_on_gpu,
1070 explicit_paddings=explicit_paddings,
-> 1071 data_format=data_format, dilations=dilations, name=name)
1072 _result = _op.outputs[:]
1073 _inputs_flat = _op.inputs
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/op_def_library.py in _apply_op_helper(self, op_type_name, name, **keywords)
792 op = g.create_op(op_type_name, inputs, dtypes=None, name=scope,
793 input_types=input_types, attrs=attr_protos,
–> 794 op_def=op_def)
795
796 # Conditionally invoke tfdbg v2’s op callback(s).
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/util/deprecation.py in new_func(*args, **kwargs)
505 ‘in a future version’ if date is None else (‘after %s’ % date),
506 instructions)
–> 507 return func(*args, **kwargs)
508
509 doc = _add_deprecated_arg_notice_to_docstring(
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in create_op(***failed resolving arguments***)
3355 raise TypeError(“Input #%d is not a tensor: %s” % (idx, a))
3356 return self._create_op_internal(op_type, inputs, dtypes, input_types, name,
-> 3357 attrs, op_def, compute_device)
3358
3359 def _create_op_internal(
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in _create_op_internal(self, op_type, inputs, dtypes, input_types, name, attrs, op_def, compute_device)
3424 input_types=input_types,
3425 original_op=self._default_original_op,
-> 3426 op_def=op_def)
3427 self._create_op_helper(ret, compute_device=compute_device)
3428 return ret
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in __init__(self, node_def, g, inputs, output_types, control_inputs, input_types, original_op, op_def)
1768 op_def, inputs, node_def.attr)
1769 self._c_op = _create_c_op(self._graph, node_def, grouped_inputs,
-> 1770 control_input_ops)
1771 # pylint: enable=protected-access
1772
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs)
1608 except errors.InvalidArgumentError as e
1609 # Convert to ValueError for backwards compatibility.
-> 1610 raise ValueError(str(e))
1611
1612 return c_op
ValueError: Depth of output (64) is not a multiple of the number of groups (3) for ‘model_4/conv2d_51/convolution’ (op: ‘Conv2D’) with input shapes: [?,?,?,3], [4,4,1,64].
我将非常感谢您的帮助,谢谢!
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
非常感谢 Jason,教程很棒!
我有一个错误,就像在检查目标时一样:expected model_51 to have shape (14, 12, 1) but got array with shape (14, 14, 1)
如果您有任何想法,我将非常乐意听取。
不客气。
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason,我刚学完代码,我是 python 新手,所以花了我大约 2 个月的时间才弄清楚每一行代码的每一个操作的含义
所以我终于把所有东西都整合起来进行训练了
训练在我的 Linux 和 Windows 10 的不同 CPU 上运行正常。
但是当我尝试在我的 Windows 10 的 1060 上运行时(安装了所有 CUDA、cuDNN、tf 1.14),我收到错误:
Resource exhausted: OOM when allocating tensor with shape [1,2560,64,64]
我尝试了 CUDA 9 和 10——我收到了相同的错误。
这是一个正常的张量形状吗?
很遗憾听到这个。可能是您的环境出了问题?
也许可以尝试减小批量大小?
也许可以尝试在 EC2 上运行
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
嗨,谢谢您的提示和这篇精彩的教程!
关于批量大小,您在定义训练函数之前写过
批量大小固定为一张图片,以匹配论文中的描述,并且模型适合 100 个 epoch。
所以批量大小已经是 1 张图片了……
我的 gtx 1060 有 3 GB。真是可惜,tensorflow 无法将进程分布到内存中……
我明白了。
也许可以尝试按比例缩小图像和模型?
是的……这是其中一个选项……
我刚回到这个页面想问您,当我改变分辨率时,我应该在代码中更改什么?当我想在 128×128 或 512×512 分辨率的图像上训练网络时,是否应该更改过滤器的数量?
或者它会完全自动适应新的分辨率吗?
我实际上有 5 台配备 Xeon 和 i7 处理器的 PC,所以我开始研究 https://tensorflowcn.cn/tutorials/distribute/multi_worker_with_keras
您是否尝试过将代码转换为多机器学习?如果尝试过,您能否做一个关于将训练函数转换为在本地网络的多台 PC 上运行的教程?
非常感谢。
我相信您将不得不为不同的分辨率图像进行调整。可能需要进行一些实验。
抱歉,我没有分布式机器学习的教程。
嗨 Jason,再次感谢
已测试——它终于奏效了。我不得不将所有图像重新格式化为 128×128,我发现
“通过将 image_shape 设置为 (128x128x3) 并将 n_resnet 函数参数设置为 6,可以轻松将其更改为 6-resnet 块版本。”
您说为了降低分辨率图像而应减少 resnet 块数量(从 256×256 的 9 个减少到 128×128 的 6 个)的这句话。
分辨率加倍的这个系数 1.5 (0.75) 是您通过测试得出的吗?
我猜分辨率越高——滤波越强——是这样吗?如果这是正确的,在 resnet 块数量之后,我还需要考虑更改什么?
干得好。
不,我想实现是基于这篇论文的。
@Arthur,你在你的CPU上训练了多久?
亲爱的 Jason,
感谢您的精彩教程。我已经在我的数据集(来自两个不同领域的医学图像)上实现了您的代码。我遇到了“反向效应”问题,即生成图像的背景颜色应该是白色而不是黑色(与源图像类似)。
有什么建议吗?谢谢。
有意思。
我有时也遇到过这种情况。也许可以尝试重新拟合模型?
我想问一下图像尺寸的问题。
如果我使用相同的模型,输入尺寸小于256*256,会对输出质量有影响吗?
是的,较大的图像更难生成,可能需要更大的模型和更多的训练。
在定义判别器和生成器时,GPU专用内存会完全耗尽。有什么办法可以避免这种情况吗?
我的GPU内存是6GB
也许可以使用更小的模型?
也许可以使用更小的图像?
也许可以在EC2实例上训练?
很棒!
在我的电脑上,这需要很长时间……我该如何添加检查点?这样我就可以从中断的地方继续了
在代码中我没看到任何 ModelCheckpoint()
我应该把它加在哪里?
对于这个
if (i+1) % (bat_per_epo * 5) == 0
更改为
if True
好的,明白了,但如何加载之前的呢?
例如,我生成了一个200.h5 和 300.h5 文件……然后断电……一天后,我如何从300.h5文件恢复训练并继续?
load_model(filename)
请参阅此以获取更多帮助
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
抱歉,你能从300.h5文件恢复训练并继续吗?你能给出建议,如何做吗?
是的,加载模型并像以前一样训练。
我按照您指示的,使用以下代码加载了检查点
cust = {‘InstanceNormalization’: InstanceNormalization}
g_model_AtoB = load_model(‘g_model_AtoB_005935.h5’, cust)
g_model_BtoA = load_model(‘g_model_BtoA_005935.h5’, cust)
然后我遇到了一个错误
ValueError: The name “functional_3” is used 2 times in the model. All layer names should be unique.
在调用时
model = Model([input_gen, input_id], [output_d, output_id, output_f, output_b])
我该如何加载它并成功继续训练?
我正在用生成器加载这个,我应该在复合模型之后加载这个吗?
我仍在寻找这个答案。如何从检查点或h5模型继续训练?
我遇到了和琼斯先生一样的问题……希望布朗利先生能帮忙……
您需要编写自定义代码,但您可以加载模型并像以前一样继续训练循环。
谢谢你的工作。如果我只想训练一个通道的数据集(256*256*1 或 512*512*1),我需要修改哪些代码?再次感谢。
可能是判别器的输入和生成器的输出。
谢谢你的回答,输入与训练数据的形状相同,我修改了生成器的输出(outpatch = conv2d(1,(4,4……..)。但是代码运行失败了,我想这涉及到restnet_block的调整。
可能有关。我建议您进行实验并查看layer summary() 的输出,了解形状如何变化。
生成器的输出形状:activation_180 (Activation) (None, 256, 256, 1) 0
ResourceExhaustedError: OOM when allocating tensor of shape [512] and type float
[[node instance_normalization_336/Const (defined at /home/istbi/anaconda3/envs/tf/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:408) ]]
生成器的输出形状似乎是正确的,但它仍然不是。
看起来您已经耗尽了内存,尝试在内存更大的EC2实例上运行?
谢谢,我认为您说得对,我在Jupyter Notebook上运行了代码。我停止了内核。但它没有释放RAM。现在似乎运行正常了。非常感谢您的帮助。
干得好。
我有一个疑问。
在define_generator()函数中,我们不应该编译生成器模型吗?
没必要。
有没有办法在GAN中使用数据生成器?
生成器可以直接使用,是的。
我们在教程的最后就是这样做的。
抱歉,但是我的数据集分辨率是128×128,这对您的模型来说重要吗?
图像是256×256。
如果您有不同尺寸的图像,可以调整它们的大小或更改模型。
非常感谢您的回答。这意味着我只需要更改n_resnet从9到6——
def define_generator(image_shape, n_resnet=9)?
抱歉,在您的代码中,我们可以保存模型,但是我的GPU只有6GB,我能否保存权重并在另一天继续训练模型?
是的。在上面的教程中,有保存/加载模型的示例。
Jason博士,谢谢您的回答,我现在可以加载模型了,但不知道如何继续训练,您能给我一些建议吗?
我按照您的建议做了,并制作了下一个脚本
g_model_AtoB=load_model(‘g_model_AtoB_0001300.h5′)
g_model_BtoA=load_model(g_model_BtoA_000130.h5’)
g_model_AtoB.summary()
g_model_BtoA.summary()
train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
但没有成功。
您可以使用与之前相同的训练过程。
抱歉,20个epoch后我得到的结果是——
dA[0.000,0.000] dB[0.000,0.000] g[0.599,0.812]
这意味着我需要重新开始吗?
也许可以。
抱歉——我们有以下损失——dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2
但是哪里有——对抗性损失?
来自教程
它们都是对抗性损失值。
你好!谢谢,完美的文章!
请帮我理解一下,我是否可以使用一个模型来训练多个对象?例如,一个模型将苹果转换为橙子,另一个模型将马转换为斑马?
今天,我计划用苹果和橙子数据集进行训练,
明天——斑马到马
可能不行,这个模型是为特定转换设计的。
嘿,你在ResNet实现中使用了concatenate(),而在你链接的文章中使用了add()。你能解释一下这样使用有什么区别吗?
在这种情况下,我试图匹配论文和pytorch实现。
感谢您的工作,
抱歉,我的结果是——
30032, dA[0.002,0.001] dB[0.003,0.007] g[2.713,2.400] ——看起来不错!)
但事实上,输出图像与输入图像看起来一样,Jason先生,您能推荐我更改模型吗?
马的照片输入和马的照片输出
也许可以尝试再次运行示例或运行更长时间?
Jason,感谢您的快速回复。
事实上,我使用的是私有数据集。
我已经尝试重新开始3次了,花费了大量时间,但结果一样。
我确定您的代码是好的,因为在其他私有数据集上,您的模型工作没有问题。
但现在,我不知道该怎么办,如果我继续训练,我会得到以下结果——
>1197, dA[0.000,0.000] dB[0.000,0.000] g[0.953,0.819]
但收到的图像并不好。
我更改了model.compile(loss=’mse’, optimizer=Adam(lr=0.0002, beta_1=0.5), loss_weights=[0.8]) #和loss_weights=[0.3] 但结果一样。
在我的情况下,看起来判别器工作不正常,但我可以更改哪些设置?
也许可以尝试更改模型,例如更小/更大,看看它对生成图像是否有影响?
你好,Mark,
你找到解决你的问题的方法了吗?我也遇到了同样的问题,而且还没有找到任何解决方案。如果你能分享你的发现,那将非常有帮助。提前感谢。
我每小时大约能处理750到800次迭代,这很慢吗?这是在使用Colab的GPU计算——我只是想知道这是否是正常的训练速度,并且好奇CycleGAN训练的某个部分(或Colab中的某个东西)是否可能是瓶颈?
非常感谢您的教程和解释,它们非常有帮助!
干得好!
也许可以考虑使用 ec2 p3 实例?
我的错——我想Colab上的GPU开关一开始没有生效,我重启了Colab页面并再次运行,现在速度达到了每小时大约3100次迭代。
有人知道这个速度仍然很慢吗?好奇您是否知道EC2上的近似速度。
谢谢!
干得好!
我的Colab GPU运行时每小时也大约900次迭代。你做了什么来加快速度吗?
嗨,Jason,
我正在使用您的模型并在summer2winter_Yosemite数据集上运行。
所以我想知道,是否可以使用您的相同参数运行我的模型?或者对于这个数据集,我是否需要使用其他模型或参数?如果我可以使用这个模型,您建议我更改哪些参数以获得更好的结果?
您可能需要根据数据集调整模型。
尝试调整模型架构和训练参数。
我的模型在第25个epoch就出现了0判别器错误,我运行的是6个resnet块。可能是什么原因?
听起来可能出了问题。也许可以尝试重新运行,也许可以尝试调整架构/训练配置?
你好Jason,抱歉,如果我看起来像在刷屏你的博客。我实现了一个9个resnet块的CycleGAN,并在summer 2 winter数据集上训练模型。我发现判别器损失从第8或第9个epoch开始就持续接近于0,所以我将判别器的学习率修改为0.000002的非常低的值。即使如此,到第5个epoch时,判别器损失仍在小数点后第二位,大约为0.06-0.1。我不知道如何继续。如果您能指导我一下,可能会有帮助。非常感谢您的所有资源。
也许可以尝试对架构或学习算法进行小改动,并观察效果。
你好Jason,非常感谢你的帮助。我弄清楚了问题所在,问题是,在生成器的最终Cs7-1-3层(在tanh激活之前),我还在relu激活中也启用了relu激活。之后我有了tanh激活,这导致了问题。
干得好!
你好Jason博士,谢谢你的精彩分享。
我遇到了以下错误
ResourceExhaustedError: OOM when allocating tensor with shape[1,128,128,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node model_9/conv2d_101/BiasAdd-0-0-TransposeNCHWToNHWC-LayoutOptimizer}}]]
提示:如果您想在OOM发生时看到已分配张量的列表,请为当前分配信息添加report_tensor_allocations_upon_oom到RunOptions。
[Op:__inference_keras_scratch_graph_94089]
有什么建议吗?谢谢
看起来您已经耗尽了内存,尝试使用更多内存的AWS EC2,或者更改数据/模型使其更小。
非常感谢您Jason博士的回复。改变数据/模型是否与减小批量大小相似?我很想从您那里得到一些解释!
不行。
批量大小影响学习率。
改变模型会影响更多,例如学习的方式和学习的内容。
仅供参考,
我使用的是 Intel Dual Core 3.4GHz CPU 和 3G RAM。我使用的是 Python 2.7。我将样本训练数据量从大约1067张图像减少到A和B各500张。我运行了您的第一个批处理代码,它下载图像并显示,没有问题。第二个批处理,我运行了除了最后一个“训练模型”之外的所有代码。代码运行了15分钟,然后出现了一个警告:
python2.7/site-packages/keras/engine/training.py:478: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set
model.trainablewithout callingmodel.compileafter ?“可训练权重与收集到的可训练权重之间存在差异”
然后,在20分钟后,内核崩溃了。
我认为内核崩溃是由于调用了CPU上不存在的包函数。
我猜我的电脑无法胜任这项任务。
尽管如此,这个网站写得很好,也很有教学意义。
此致。
您可以忽略该警告。
也许可以尝试Python 3。
确保您直接从命令行运行
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨Jason,再次感谢。直接从命令行运行有什么意义?
在IDE/Notebook中运行会导致许多读者遇到各种问题
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
直接从命令行运行对每个人都有效
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
感谢Jason的建议,我按照您的建议做了,但仍然使用的是python 2.7.18 64位。我直接从命令行运行您的代码。它运行,但速度非常慢。您现在可以说它可以在旧系统的PC(双核)CPU上运行,并且也是python 2。通过查看epoch和epoch计算时间内的步数,我计算出完成所有11,000个epoch需要大约4个月。所以我停止了PC运行了两个epoch。Python 3只比Python 2快1.3倍,不足以将其减少到一天。如果可能,我会尝试pypy,但我怀疑速度不会有提高。除非代码有一些机会可以减少计算所需的时间,例如减小批量大小(每epoch步数)或所需的epoch数。
尝试在EC2上通过GPU运行以加快速度
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
抱歉,我使用的是python 2.7.14而不是2.7.18。
我推荐Python 3.6。
嘿,Jason
感谢您在本网站提供的所有信息。它真的很有帮助。我有一个疑问,如果您能帮忙的话。
我保存了所有6个模型,判别器、生成器和复合模型,并在继续训练时重新加载它们。
这是正确的方法吗,还是我应该只保存和加载生成器模型?
因为在训练过程中,dA和dB的值会降到0.000__以下。
不客气。
您可以根据需要全部保存。不过没有必要,请参阅save_models()函数。
是的,save_model()只保存生成器模型。
因此,无论我是否对所有模型使用 model.load(),训练都能正常进行。
fn = “022553”
cust = {‘InstanceNormalization’: InstanceNormalization}
d_model_A = define_discriminator(image_shape)
d_model_A = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/d_model_A_”+fn+”.h5″,cust)
d_model_B = define_discriminator(image_shape)
d_model_B = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/d_model_B_”+fn+”.h5″,cust)
g_model_AtoB = define_generator(image_shape)
g_model_AtoB = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/g_model_AtoB_”+fn+”.h5″,cust)
g_model_BtoA = define_generator(image_shape)
g_model_BtoA = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/g_model_BtoA_”+fn+”.h5″,cust)
c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape)
c_model_AtoB = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/c_model_AtoB_”+fn+”.h5″,cust)
c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
c_model_BtoA = load_model(“/content/drive/My Drive/cycleGan/Horses&Zebra/TrainingFiles/c_model_BtoA_”+fn+”.h5″,cust)
那么还有什么可能导致训练错误?我尝试了多次重启训练。有什么能帮我训练的东西吗?
啊,我明白了。是的,您需要保存所有模型,然后再加载它们。
抱歉,您需要自己准备这个函数,我没有能力为您编写。
谢谢,我只是想确认一下我在保存和加载模型方面是否走对了方向。
但是,我在加载判别器模型时确实收到了一条警告:“未在保存文件中找到训练配置:模型*未*编译”。
您可以安全地忽略该警告。
对!谢谢您的帮助。
不客气。
先生,我在安装 keras-contrib 时遇到困难?我创建了一个 Anaconda 环境,其中安装了所有库……
但是如何在该 conda 环境中安装 keras-contrib 呢?
步骤 1:我激活环境,然后粘贴以下命令,
sudo pip install git+https://www.github.com/keras-team/keras-contrib.git
它会给我一个错误:“‘sudo’ 未被识别为内部或外部命令,
可执行程序或批处理文件”。
我使用了另一个命令,即,
git clone https://www.github.com/keras-team/keras-contrib.git
然后再次出现错误。
‘git’ 未被识别为内部或外部命令,
可执行程序或批处理文件。”
错误:找不到命令 'git' – 您是否已安装 'git' 并将其添加到 PATH?
先生,请指导我一下?我的 Keras 版本是 keras-2.3.1,Tensorflow 版本是 1.14。
也许您的机器不支持 sudo,例如您使用的是 Windows。
尝试不使用 sudo 命令。
亲爱的 Jason,
感谢您提供非常有用的教程。我正在尝试为训练过程添加学习率衰减的扩展,再训练 100 个 epoch(共 200 个),我想问您一些问题。
我是否应该只先创建模型(判别器和复合模型)并在学习率条件(如下所示)之后编译它们?
list_n_steps = list(range(n_steps))
for i in list_n_steps
if list_n_steps[i] < n_steps/2
lr = 0.0002
else
lr = 0.0002 – 0.0002*((i – (n_steps/2)) / (n_steps/2))
或者我应该将 for 循环包含在“train 函数”中,在枚举 epoch 之前或之中来更新/衰减学习率?
或者使用 tf.keras.optimizers.schedules.LearningRateSchedule 函数可以完成这项工作吗?
谢谢你。
手动衰减学习率可能更容易,因为您可以手动步进 epoch/batch。
感谢您提供如此翔实的教程。我有一个问题。
您能否进一步解释 update_image_pool() 的作用?如果直接使用假图像和标签训练模型会怎样?如何使用这些循环 GAN 来实现特征增强?
不客气。
update_image_pool() 有助于维护一个最近生成的假图像池。其思想是减轻模型更新对判别器的影响——通过平均模型最近已见图像的更新来减缓整个过程。
尝试使用此功能拟合模型和不使用此功能拟合模型,然后比较结果。
亲爱的Jason
来自日本的大粉丝。
在我运行了“将所有这些结合在一起,训练模型将照片从马翻译成斑马以及从斑马翻译成马的完整示例列在下面。”这句话之后,出现了一个错误:module ‘tensorflow.python.framework.ops’ has no attribute ‘_TensorLike’。我尝试了多种方法(例如更新 tensorflow),但错误仍然存在。您能帮我解决这个问题吗?非常感谢。
您能否确认您已更新 Keras 和 Tensorflow 的版本?
非常感谢您的回复
tensorflow 版本:2.3
keras 版本:2.3.1
也许可以尝试以下版本
tensorflow: 2.3.0
keras: 2.4.3
另外,请确保您直接复制了代码并在命令行中运行。
更多建议在这里
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
非常感谢,在我更新到 2.4.3 后,问题解决了!
很高兴听到这个!
你好杰森博士,
我正在尝试使用 CycleGAN 处理不同的数据集,例如从草图/边缘到图像。但是我的训练正好在 25 个 epoch 后停止,甚至没有达到 100 个。但是结果不太好,看起来如果训练模型更长时间可能会更好。
您有什么建议吗?原因可能是什么?我正在使用 Google Colab。
也许可以尝试训练更多的 epoch。
我遇到了同样的问题。将图像尺寸从 512 减小到 256 可以让它无限运行。
太棒了!
嗨 Jason,请问生成的图像图在哪里存储的,因为我使用的是 google colab?
—-> 1 AtoB_generated_plot_000115.png
2
3 BtoA_generated_plot_000115.png
NameError: name ‘AtoB_generated_plot_000115’ is not defined
&
—-> 1 g_model_AtoB_010925.h5
2 g_model_AtoB_011500.h5
3 …
4 g_model_BtoA_010925.h5
5 g_model_BtoA_011500.h5
NameError: name ‘g_model_AtoB_010925’ is not defined
抱歉,我从未用过 colab,也无法提供相关建议。
但是,在哪里可以查看生成的图像呢?
如果是在工作站或 AWS EC2 实例上运行,图像将保存在与代码文件相同的目录中。
非常感谢您提供的详细解释和实现。
如何在判别器和生成器中整合注意力层?
也许有。抱歉,我没有例子。或许可以尝试一下。
嗨 Jason,感谢您的博客,我这周从您那里学到了很多关于 GAN 的知识!您是否有关于如何修改架构以处理不同分辨率图像的资源/通用规则?
不客气!
不确定。更改输入或输出形状,然后调整块的数量以达到所需的大小。
嗨 Jason,感谢您的解释。我想问一下,在使用 Resnet 而不是 U-net 架构作为生成器模型时,有什么优势吗?
此致,
Joshua
试试看吧。
感谢 Jason 的这些教程,它们非常有用。我完全是 Python 和 ML 新手。
我尝试在 SageMaker 上运行此代码,使用的是 ml.t3.xlarge。
一切都很顺利,直到它达到
>259, dA[0.133,0.145] dB[0.171,0.158] g[6.446,6.557]
>260, dA[0.107,0.142] dB[0.223,0.144] g[9.232,8.902]。
然后它就突然停止了。没有任何错误消息。
我正在 ml.c4.8xlarge 上重试。同时,您认为在 260 epoch 突然停止的原因可能是什么?
也许是您的服务器有问题?
这个例子以及整个博客的质量都很高,比其他地方的都好。谢谢!我正在使用 Quadro P4000(8GB)在上面训练这个 GAN 示例,预计需要 30-40 小时才能完成 100 个 epoch。这听起来正常吗?这已经比我笔记本电脑的 GPU 快 4 倍了。与我运行过的类似图像矩阵的普通 U-net 相比,它们收敛所需的时间要少得多,我惊讶于这个 GAN 网络之间的差异。我仍然是新手,可能还没有直觉。
谢谢!
听起来太久了。我认为在好的 AWS EC2 实例上只需要一个晚上。
非常感谢您的教程!工作做得很好!
我现在有一个项目,我无法在 pix2pix GAN 和 cycle GAN 之间选择。您能帮我确定一下吗?
我有一个数据集,有两种可用数据:一种是由雷达设备生成的点云(点云丰富但有点嘈杂,最多 64 个点,具有 x、y 和 z 坐标,因此每帧最多 64*3 = 192),另一种是真实人类关键点数据,由某些深度摄像头生成(始终为 25 个关键点,例如头部、肩部、手等,具有 3 轴 x、y 和 z 坐标。因此,每帧的数据长度为 25*3 = 75)。我的数据是成对的,也就是说,对于每一帧,我都有雷达数据和相应的真实深度摄像头数据。我的目标是输入一帧雷达数据并获得该帧对应的真实人体关节数据。我设计了一个 CNN,结果非常好。我输入一帧雷达数据(为了保持相同的数据长度,我生成了一个特征图),然后进行一些卷积和全连接,最后预测出 75 个坐标的人体关节。每个点的误差非常低。这表明雷达点云坐标与人体关节坐标之间存在映射。
但是,在阅读了 pix2pix GAN 和 cycle GAN 之后,我觉得我的目标更像是风格迁移。雷达点云 -> 真实人体关节点云。由于我的数据是成对的,我觉得它更与 pix2pix GAN 相关?但 cycle GAN 也似乎非常相关。底线:1)输入一帧雷达点云数据,得到一帧人体关节预测。2)预测误差应该很低,至少与 CNN 相同。
您能给我一些建议吗?
也许这会有帮助。
当您有成对的训练数据时,pix2pix 是合适的;当您没有成对的训练数据时,cyclegan 是合适的。
这行是什么意思?
g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA])
那些 _,_,_,_ 值是什么?
这是 Python 的一种习惯用法,表示我们希望忽略的函数调用返回的值。
Jason 的教程很棒!
您能否帮我说明一下在使用灰度图像时需要进行哪些更改?
ValueError: layer conv2d_106 的输入 0 与层不兼容:期望轴 -1 的输入形状为 1,但接收到的输入形状为 (None, 256, 256, 3)。
在使用 define_composite_model (–>36 c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape)) 时,第 36 行出现 ValueError
37 # composite: B -> A -> [real/fake, B])
这似乎是 define_composite_model 中的这行 —> 11 output_d = d_model(gen1_out)
我不确定,您可能需要做一些试错。
我已将 define_generator 中的 g = Conv2D(3, (7,7), padding=’same’, kernel_initializer=init)(g)
更改为
# c7s1-3
g = Conv2D(1, (7,7), padding=’same’, kernel_initializer=init)(g)
这似乎解决了在——> 之前阻止程序的错误
非常感谢您的出色教程……
我正在关注您的大部分教程,因为您解释得非常清楚……谢谢。
我正在 Pycharm 中使用 GPU 实现此马到斑马翻译。但我遇到了这个错误
‘进程以退出代码 -1073740791 (0xC0000409) 结束’
您能帮我解决这个问题吗
抱歉,我无法提供帮助,此教程是针对 keras/tensorflow 的。
你好,先生,
我正在使用 CycleGAN 进行图像去雾。我的数据集包含 5800 张雾天图像和 5800 张真实图像。这些图像混合了室内和室外场景。我需要更改任何模型参数吗?如果需要,我该如何处理?这将对我非常有帮助。
我有一个 i5 第 8 代 12 GB RAM,这足够训练模型吗?
听起来是一个很棒的项目!
也许可以尝试不同大小的模型、不同的学习超参数等。
您可能需要使用渐进式加载,具体取决于您的数据是否适合 RAM。
您会制作关于对比无配对翻译(https://github.com/taesungp/contrastive-unpaired-translation,https://arxiv.org/pdf/2007.15651)的教程吗?
感谢您的建议。
你好,先生,
我正在使用此架构进行去雾项目。我所有的图像都肯定是 256×256 且有 3 个通道。
但是,当我定义复合模型时,我收到了以下警告
警告:tensorflow:模型是用形状(None, 256, 256, 3)的输入 Tensor("input_12:0", shape=(None, 256, 256, 3), dtype=float32) 构建的,但它被调用于一个形状不兼容的输入(None, 512, 512, 3)。
对于每个复合模型,都会出现相同的警告三次。
# 复合模型:A -> B -> [真实/虚假, A]
c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape)
# 复合模型:B -> A -> [真实/虚假, B]
c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
在这种情况下我该怎么办?
也许可以仔细检查一下您加载的图像大小是否符合您的预期。
嗨,您能否教我如何生成许多重建图像而不是翻译图像?重要的是将所有重建图像仅保存到文件中。
感谢您的建议。
嗨 Jason,非常棒的教程。
我在加载训练好的模型以进行进一步训练时遇到了问题,例如。
c_model_AtoB=keras.models.load_model((dirpath_total+’g_model_AtoB_000020’+’.h5′),custom_objects={‘InstanceNormalization’:keras_contrib.layers.InstanceNormalization},compile=True)
c_model_BtoA=keras.models.load_model((dirpath_total+’g_model_BtoA_000020’+’.h5′),custom_objects={‘InstanceNormalization’:keras_contrib.layers.InstanceNormalization},compile=True)
我将这些模型馈送到 train 函数中,但得到了错误
RuntimeError: 您必须先编译您的模型才能训练/测试。使用
model.compile(optimizer, loss)。有什么想法可以解决这个问题吗?
谢谢
克里斯
谢谢。
您可以忽略这个警告 Chris。或者,如果您愿意,可以在使用前编译模型。
嗨 Jason
这实际上是一个错误,我无法忽略它。我尝试在调用 train 函数之前通过编译来解决
################
#加载预训练模型
################
import keras_contrib
import keras
c_model_AtoB=keras.models.load_model((‘g_model_AtoB_000025’+’.h5′),custom_objects={‘InstanceNormalization’:keras_contrib.layers.InstanceNormalization})
c_model_BtoA=keras.models.load_model((‘g_model_BtoA_000025’+’.h5′),custom_objects={‘InstanceNormalization’:keras_contrib.layers.InstanceNormalization})
opt = Adam(lr=0.0002, beta_1=0.5)
c_model_AtoB.compile(loss=[‘mse’, ‘mae’, ‘mae’, ‘mae’], loss_weights=[1, 5, 10, 10], optimizer=opt)
c_model_BtoA.compile(loss=[‘mse’, ‘mae’, ‘mae’, ‘mae’], loss_weights=[1, 5, 10, 10], optimizer=opt)
################
#继续训练
################
train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, trainA,trainB)
然后我得到错误
ValueError: 维度必须相等,但却是 256 和 16,因为“{{node mean_squared_error/SquaredDifference}} = SquaredDifference[T=DT_FLOAT](functional_39/activation_101/Tanh, IteratorGetNext:2)”输入形状为:[1,256,256,3],[1,16,16,1]。
有什么建议吗?
提前感谢
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason
如何将 “dA_loss1,dA_loss2, dB_loss1,dB_loss2, g_loss1,g_loss2” 输出保存为 excel 文件并将其损失绘制成图片?
谢谢
Chuck
这可以帮助您将数组保存到文件。
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
抱歉,不是图片。将其损失绘制成图。
您可以将值保存到文件,然后稍后加载这些值并使用 matplotlib 进行绘图。
嗨,Jason,
我们能使用此模型进行单张图像雨去除,但使用无配对数据吗?
你为什么认为它不行?
你好 jason,
我遇到了这个错误。你能发布你使用的包的版本吗?
——————————————————————————
ValueError 回溯 (最近一次调用)
/tmp/ipykernel_50911/1939433363.py in
278 c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
279 # 训练模型
–> 280 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
/tmp/ipykernel_50911/1939433363.py in train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
233 X_realB, y_realB = generate_real_samples(trainB, n_batch, n_patch)
234 # 生成一批假样本
–> 235 X_fakeA, y_fakeA = generate_fake_samples(g_model_BtoA, X_realB, n_patch)
236 X_fakeB, y_fakeB = generate_fake_samples(g_model_AtoB, X_realA, n_patch)
237 # 从池中更新假样本
/tmp/ipykernel_50911/1939433363.py in generate_fake_samples(g_model, dataset, patch_shape)
156 def generate_fake_samples(g_model, dataset, patch_shape)
157 # 生成假实例
–> 158 X = g_model.predict(dataset)
159 # 创建“假”类标签(0)
160 y = zeros((len(X), patch_shape, patch_shape, 1))
~/anaconda3/lib/python3.8/site-packages/keras/engine/training.py in predict(self, x, batch_size, verbose, steps, callbacks, max_queue_size, workers, use_multiprocessing)
1718 “。考虑将其设置为 AutoShardPolicy.DATA。”)
1719
-> 1720 data_handler = data_adapter.get_data_handler(
1721 x=x,
1722 batch_size=batch_size,
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in get_data_handler(*args, **kwargs)
1381 if getattr(kwargs[“model”], “_cluster_coordinator”, None)
1382 return _ClusterCoordinatorDataHandler(*args, **kwargs)
-> 1383 return DataHandler(*args, **kwargs)
1384
1385
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in __init__(self, x, y, sample_weight, batch_size, steps_per_epoch, initial_epoch, epochs, shuffle, class_weight, max_queue_size, workers, use_multiprocessing, model, steps_per_execution, distribute)
1135 self._steps_per_execution_value = steps_per_execution.numpy().item()
1136
-> 1137 adapter_cls = select_data_adapter(x, y)
1138 self._adapter = adapter_cls(
1139 x,
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in select_data_adapter(x, y)
971 def select_data_adapter(x, y)
972 “””Selects a data adapter than can handle a given x and y.”””
–> 973 adapter_cls = [cls for cls in ALL_ADAPTER_CLS if cls.can_handle(x, y)]
974 if not adapter_cls
975 # TODO(scottzhu): This should be a less implementation-specific error.
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in (.0)
971 def select_data_adapter(x, y)
972 “””Selects a data adapter than can handle a given x and y.”””
–> 973 adapter_cls = [cls for cls in ALL_ADAPTER_CLS if cls.can_handle(x, y)]
974 if not adapter_cls
975 # TODO(scottzhu): This should be a less implementation-specific error.
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in can_handle(x, y)
208 flat_inputs += tf.nest.flatten(y)
209
–> 210 tensor_types = _get_tensor_types()
211
212 def _is_tensor(v)
~/anaconda3/lib/python3.8/site-packages/keras/engine/data_adapter.py in _get_tensor_types()
1652 def _get_tensor_types()
1653 try
-> 1654 import pandas as pd # pylint: disable=g-import-not-at-top
1655
1656 return (tf.Tensor, np.ndarray, pd.Series, pd.DataFrame)
~/anaconda3/lib/python3.8/site-packages/pandas/__init__.py in
27
28 try
—> 29 from pandas._libs import hashtable as _hashtable, lib as _lib, tslib as _tslib
30 except ImportError as e: # pragma: no cover
31 # hack but overkill to use re
~/anaconda3/lib/python3.8/site-packages/pandas/_libs/__init__.py in
11
12
—> 13 from pandas._libs.interval import Interval
14 from pandas._libs.tslibs import (
15 NaT,
pandas/_libs/interval.pyx in init pandas._libs.interval()
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
很难判断,但这似乎是一个 numpy 版本不匹配的问题。请参阅此处的不同答案,这可能会有帮助:https://stackoverflow.com/questions/66060487/valueerror-numpy-ndarray-size-changed-may-indicate-binary-incompatibility-exp
为什么你的 randint() 函数有 3 个参数?你能稍微解释一下 generate_real_samples 吗?谢谢。
参见https://numpy.com.cn/doc/stable/reference/random/generated/numpy.random.randint.html
那是 randint(high, low, size)
生成真实样本只是从数据集中选取一个样本(因此它是真实的),并将其标记为“1”。
你好,感谢你对代码的精彩解释!我有一个关于在加载模型时在最后保存图像的问题。对于你展示的将马转换为斑马的最后一部分,我该如何保存预测的图像?我想为目录中的多个图像文件执行此操作。我想从目录加载图像,然后进行预测,然后保存它们。你能帮帮我吗?谢谢!
一种简单的方法是使用 OpenCV 中的 imwrite 函数。请参阅此示例:https://stackoverflow.com/questions/26681756/how-to-convert-a-python-numpy-array-to-an-rgb-image-with-opencv-2-4
我的 NVIDIA 显卡有 4GB 内存,无法运行此代码。它生成了一个错误
”
File “C:…\AppData\Roaming\Python\Python38\site-packages\tensorflow\python\eager\execute.py”, line 59, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
ResourceExhaustedError: OOM when allocating tensor with shape[1,2560,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node model_5/model/concatenate_8/concat_1 (defined at D:/Documents/cycleGAN_TensorFlow_Learn/cyclegan_learn.py:334) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn’t available when running in Eager mode.
[Op:__inference_train_function_40064]
Errors may have originated from an input operation.
Input Source operations connected to node model_5/model/concatenate_8/concat_1
model_5/model/instance_normalization_20/add_3 (defined at D:…\Anaconda3\lib\site-packages\keras_contrib\layers\normalization\instancenormalization.py:130)
Function call stack
train_function
”
如何优化代码以适应 4GB GPU 内存运行?
批次大小是减少内存占用的关键,但由于此示例已使用批次大小为 1,因此您可能已经达到了极限。
>121, dA[0.126,0.137] dB[0.193,0.088] g[8.342,8.463]
>122, dA[0.138,0.135] dB[0.176,0.319] g[5.520,5.516]
>123, dA[0.181,0.222] dB[0.174,0.306] g[9.752,11.930]
>124, dA[0.278,0.218] dB[0.218,0.100] g[5.664,5.779]
>125, dA[0.126,0.127] dB[0.246,0.168] g[5.832,5.657]
>126, dA[0.190,0.284] dB[0.166,0.133] g[6.018,7.683]
>127, dA[0.174,0.157] dB[0.078,0.207] g[7.381,9.247]
>128, dA[0.229,0.315] dB[0.241,0.244] g[7.182,8.070]
>129, dA[0.156,0.193] dB[0.186,0.215] g[4.946,5.454]
从 >13, dA[0.989,0.453] dB[2.050,0.527] g[13.013,11.449] 到现在,它给出的值接近 0 >> 是否意味着有问题??
注意:rainA 是带面具的人脸,trainB 是不带面具的人脸
我找不到保存的模型,例如
g_model_AtoB_053415.h5
g_model_AtoB_059350.h5
…
g_model_BtoA_053415.h5
g_model_BtoA_059350.h5
我在哪里可以找到它??
注意:rainA 是带面具的人脸,trainB 是不带面具的人脸
你好,
感谢您的教程,有一个问题想问
define_composite_model 函数旨在实例化一个神经网络,该神经网络的第一个输出是判别器在将 g_model_1 生成的图像输入到其中时生成的输出。考虑到图像是生成的/假的而不是真实的,判别器的输出不应该是零吗?
你希望它是零。这就是训练判别器来识别真假的目标。
是的,我明白。但那样的话,输出的 discriminant 应该是零吗?
因为生成器输出的是假样本?我真的不明白这一部分。
理想情况下,您的判别器应该输出零,因为图像是由生成器提供的。但您的目标是通过改进您的生成器来让您的判别器出错。因此,当您完成时,您应该看不到判别器输出零,否则您的生成器就没有得到充分的训练。
嗨
我删除了环境并创建了一个新的,但当我尝试安装这个时
sudo pip install git+https://www.github.com/keras-team/keras-contrib.git
我收到了这个错误
return _CleanResult.from_link(link1) == _CleanResult.from_link(link2)
AttributeError: type object ‘_CleanResult’ has no attribute ‘from_link’
我谷歌了一下,他们说
这看起来又是一个 Python 补丁级别的类型不兼容问题。
有什么解决方案吗!!
我花了几天时间尝试运行此代码,但未能成功
如果您无法使用该版本,请尝试使用 tensorflow 的版本。您执行“pip install tensorflow_addons”,然后使用这些头文件
/anaconda3/envs/tensorflow_p36/bin/python setup.py install
在我的 anaconda3/envs/myEnvNAme/ .... 我没有 bin 和 python 文件夹来在其中安装 setup.py ..
有什么建议吗??
您需要找到 Anaconda 环境中 Python 解释器的路径。这里的命令行只是一个示例。
您好,能否指导我如何直接下载所有重建的图像?其次,如何用 randint 替换以选择所有图像而不是随机选择?
# 从数据集中选择一个随机样本图像
def select_sample(dataset, n_samples)
# 选择随机实例
ix = randint(0, dataset.shape[0], n_samples)
# 检索选定的图像
X = dataset[ix]
return X
嗨 Robert……感谢提问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
你好,你能教我如何避免重复选择样本吗?
def select_sample(dataset, n_samples)
# 选择随机实例
ix = randint(0, dataset.shape[0], n_samples)
# 检索选定的图像
X = dataset[ix]
return X
嗨 Robert,
以下内容可能对您有兴趣
https://machinelearning.org.cn/introduction-to-random-number-generators-for-machine-learning/
此致,
嗨 James,
非常感谢您的教程。我学到了很多。但是训练时需要很长时间。我的资源有限。你能上传训练好的 h5 文件,让我只运行你的代码(zebra horse dataset)吗?我只是在学习,这对将对我大有帮助。所以请……
嗨 Methmal……我们无法提供 h5 文件。我建议您研究一下带有 GPU 选项和增加内存资源量的 Google Colab。
我在这一行收到错误:‘X1, X2 = data[‘arr_0’], data[‘arr_1′]’
KeyError: ‘arr_0 is not a file in the archive’
你能帮忙吗
嗨 Ajinkya……你复制代码了吗?另外,您可能想在 Google Colab 中尝试您的实现。
感谢您的精彩教程。
不幸的是,我遇到了这个错误
Loaded (111, 256, 256, 3) (111, 256, 256, 3)
/usr/local/lib/python3.7/dist-packages/keras/optimizer_v2/adam.py:105: UserWarning: The
lrargument is deprecated, uselearning_rateinstead.super(Adam, self).__init__(name, **kwargs)
X_realA: (1, 256, 256, 3)
y_realA: (1, 16, 16, 1)
—————————————————————————
TypeError Traceback (most recent call last)
in ()
274 c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
275 # 训练模型
–> 276 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
in train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
237 g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA])
238 # 更新判别器 A–>[真实/虚假]
–> 239 dA_loss1, _, _, _, _ = d_model_A.train_on_batch(X_realA, y=y_realA)
240 dA_loss2, _, _, _, _ = d_model_A.train_on_batch(X_fakeA, y_fakeA)
241 # 通过对抗和循环损失更新生成器 A–>B
TypeError: cannot unpack non-iterable float object
如果您能帮我解决这个错误,我将不胜感激。
先谢谢您了。
嗨 Martian……感谢提问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
感谢您的帮助。
问题已解决。
代码运行正常,我得到了结果。
祝您一切顺利。
感谢这份信息丰富的教程。
其前景优于使用 train_step 子类化的自定义循环程序。
至于“GAURAV SURESH SINGH”和“israr”过去关于 multiGPU 实现的问题,是否已经解决了?
我找不到链接,所以请您告诉我。
嗨 STN……不客气!请澄清您要提问的问题,以便我们更好地为您提供帮助。
非常感谢您的回复。
我想更新此代码以支持多 GPU。
有没有实现方法可以并行化训练多个模型的 train_on_batch 循环?
或者,我应该像下面链接中描述的那样实现自定义训练吗?
https://tensorflowcn.cn/tutorials/distribute/multi_worker_with_ctl
你好,James,
感谢这个教程!我也在尝试实现多 GPU。起初我认为这应该很简单,因为这里的解释 https://tensorflowcn.cn/guide/migrate/mirrored_strategy。但是,我还没有成功。
您是否提供了此教程的多 GPU 版本?另外,因为我们在实现中使用 1 个批次,所以有意义使用具有 1 个批次输入数据的多 GPU 版本吗?
很棒的教程。
我想重新训练模型,但遇到了 load_model 的问题。它说:“警告:tensorflow:保存文件中未找到训练配置,因此模型*未*编译。请手动编译它。”
你有什么建议来解决它吗?
谢谢!
很棒的教程。
我想重新训练模型,但遇到了 load_model 的问题。它说:“警告:tensorflow:保存文件中未找到训练配置,因此模型*未*编译。请手动编译它。”
你有什么建议来解决它吗?
谢谢!
很棒的教程。
我想重新训练模型,但我遇到了 load_model 的一个错误。它说:
“警告:tensorflow:保存文件中未找到训练配置,因此模型*未*编译。请手动编译它”
并且 train 函数没有启动。
如果我运行:“c_model_AtoB.compile(loss=’mse’, optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss_weights=[0.5])”(对于 c_model_BtoA 也一样)
train 函数仍然有问题。
你有什么建议吗?
非常感谢
嗨 Oliver……以下讨论可能有助于澄清
https://stackoverflow.com/questions/53295570/userwarning-no-training-configuration-found-in-save-file-the-model-was-not-c
非常感谢。我会去看看。
(抱歉我的多次评论,很遗憾我无法删除它们)
以下行给了我错误,
g_loss2, _, _, _, _ = c_model_BtoA.train_on_batch([X_realB, X_realA], [y_realA, X_realA, X_realB, X_realA])
错误是,
Data cardinality is ambiguous
x sizes: 256, 256
y sizes: 1, 256, 256, 256
Make sure all arrays contain the same number of samples.
你能告诉我我哪里做错了什么吗?
嗨 Nibin……以下资源可能对您有帮助
https://stackoverflow.com/questions/62253289/valueerror-data-cardinality-is-ambiguous
这是一个很好的教程,我遵循了 pix2pix,它运行成功了。但是,我运行 CycleGan 时遇到了溢出错误。我是 Python 和 ML 的新手,不知道如何修复这个 bug。我检查了我的 CUDA 版本是 11.6,cudnn 8.3,python 3.9.7 和 tensorflow 2.10.0。并且我还在 window 11 上运行程序。您推荐哪个版本?我是否需要重置环境来运行 CycleGan 程序?因为我认为我可以运行 Pix2Pix 教程,所以也可以运行 CycleGan。在设置环境的过程中,我非常沮丧,因为它一直失败,而且我找不到问题所在。
OverflowError Traceback (most recent call last)
Cell In[25], line 8
6 d_model_A = define_discriminator(image_shape)
7 d_model_B = define_discriminator(image_shape)
—-> 8 c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape)
9 c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
10 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
Cell In[17], line 10, in define_composite_model(g_model_1, d_model, g_model_2, image_shape)
8 input_id = Input(shape=image_shape)
9 output_id = g_model_1(input_id)
—> 10 output_f = g_model_2(gen1_out)
11 gen2_out = g_model_2(input_id)
12 output_b = g_model_1(gen2_out)
File ~\anaconda3\envs\tensorflow\lib\site-packages\keras\utils\traceback_utils.py:70, in filter_traceback..error_handler(*args, **kwargs)
67 filtered_tb = _process_traceback_frames(e.__traceback__)
68 # To get the full stack trace, call
69 #
tf.debugging.disable_traceback_filtering()—> 70 raise e.with_traceback(filtered_tb) from None
71 finally
72 del filtered_tb
File ~\anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\tensor_util.py:455, in make_tensor_proto(values, dtype, shape, verify_shape, allow_broadcast)
453 else
454 _AssertCompatible(values, dtype)
–> 455 nparray = np.array(values, dtype=np_dt)
456 # check to them.
457 # We need to pass in quantized values as tuples, so don’t apply the shape
458 if (list(nparray.shape) != _GetDenseDimensions(values) and
459 not is_quantized)
OverflowError: Exception encountered when calling layer “conv2d_transpose_62″ ” f”(type Conv2DTranspose).
Python int too large to convert to C long
Call arguments received by layer “conv2d_transpose_62″ ” f”(type Conv2DTranspose)
• inputs=tf.Tensor(shape=(None, 1073741824, 1073741824, 259), dtype=float32)
抱歉。我在谷歌和 Stack Overflow 上搜索过,但没有更多人遇到此 bug。这就是我如此困惑的原因。
这是一个很好的教程,我遵循了 pix2pix,它运行成功了。但是,我运行 CycleGan 时遇到了溢出错误。我是 Python 和 ML 的新手,不知道如何修复这个 bug。我检查了我的 CUDA 版本是 11.6,cudnn 8.3,python 3.9.7 和 tensorflow 2.10.0。并且我还在 window 11 上运行程序。您推荐哪个版本?我是否需要重置环境来运行 CycleGan 程序?因为我认为我可以运行 Pix2Pix 教程,所以也可以运行 CycleGan。在设置环境的过程中,我非常沮丧,因为它一直失败,而且我找不到问题所在。
OverflowError Traceback (most recent call last)
Cell In[25], line 8
6 d_model_A = define_discriminator(image_shape)
7 d_model_B = define_discriminator(image_shape)
—-> 8 c_model_AtoB = define_composite_model(g_model_AtoB, d_model_B, g_model_BtoA, image_shape)
9 c_model_BtoA = define_composite_model(g_model_BtoA, d_model_A, g_model_AtoB, image_shape)
10 train(d_model_A, d_model_B, g_model_AtoB, g_model_BtoA, c_model_AtoB, c_model_BtoA, dataset)
Cell In[17], line 10, in define_composite_model(g_model_1, d_model, g_model_2, image_shape)
8 input_id = Input(shape=image_shape)
9 output_id = g_model_1(input_id)
—> 10 output_f = g_model_2(gen1_out)
11 gen2_out = g_model_2(input_id)
12 output_b = g_model_1(gen2_out)
File ~\anaconda3\envs\tensorflow\lib\site-packages\keras\utils\traceback_utils.py:70, in filter_traceback..error_handler(*args, **kwargs)
67 filtered_tb = _process_traceback_frames(e.__traceback__)
68 # To get the full stack trace, call
69 #
tf.debugging.disable_traceback_filtering()—> 70 raise e.with_traceback(filtered_tb) from None
71 finally
72 del filtered_tb
File ~\anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\tensor_util.py:455, in make_tensor_proto(values, dtype, shape, verify_shape, allow_broadcast)
453 else
454 _AssertCompatible(values, dtype)
–> 455 nparray = np.array(values, dtype=np_dt)
456 # check to them.
457 # We need to pass in quantized values as tuples, so don’t apply the shape
458 if (list(nparray.shape) != _GetDenseDimensions(values) and
459 not is_quantized)
OverflowError: Exception encountered when calling layer “conv2d_transpose_62″ ” f”(type Conv2DTranspose).
Python int too large to convert to C long
Call arguments received by layer “conv2d_transpose_62″ ” f”(type Conv2DTranspose)
• inputs=tf.Tensor(shape=(None, 1073741824, 1073741824, 259), dtype=float32)
嗨 Andy……您有什么问题需要我们帮助吗?如果有,请缩小您的查询范围。
我很抱歉。我想知道您运行此 CycleGan 的版本。基本上,我使用 4070ti GPU 和 anaconda 环境运行。我应该为此 CycleGan 设置什么软件?目前,我查看了评论,您推荐 keras 2.3 和 tensorflow2。我能都设置为最新版本吗?抱歉打扰您,因为我昨天很麻烦。
嗨 James,
使用更高分辨率的图像以及非正方形图像(例如 1600x1200px)的最佳方法是什么?
谢谢!
嗨 Daniel……以下资源可能对您有帮助
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/163
数据集的访问不起作用。有什么办法可以访问数据集吗?
嗨 Munesh……您是否收到错误消息?这将使我们能够更好地为您提供帮助。
教程很棒。但是否有任何好的预制模型架构可用于自定义数据。
嗨 Pallab……这是一个开放的研究领域。以下讨论可能对您有所帮助
https://stats.stackexchange.com/questions/336722/transfer-learning-on-generative-adversarial-networks-gans
为什么你不在 generate_model_class 中编译生成模型?而判别模型和组合模型都编译了。
嗨 xuemin……请澄清您的问题,以便我们更好地指导您。
为什么 define_discrimination 函数的末尾有 model.compile,而 define_generator 中没有 compile?
有人能告诉我我应该拥有哪些特定版本的 keras、tensorflow 吗??
我拥有的版本是
python-3.12
tensorflow-2.17
keras-3.5
NumPy-1.26.4
此外,如果有人能提供像此教程一样简单的 PyTorch 实现吗??
提前感谢
嗨 Rajesh……看起来您正在使用相当新版本的 Python、TensorFlow、Keras 和 NumPy。但是,有一些重要的注意事项和建议可以确保兼容性和稳定性
### 1. **兼容性检查:**
– **Python 3.12**:这是非常新的版本,许多软件包可能尚未完全兼容。您可能会遇到某些尚未更新以支持 Python 3.12 的库的问题。
– **TensorFlow 2.17**:这是非常新的 TensorFlow 版本。TensorFlow 和 Keras 是紧密集成的,因此如果它们在相似的时间发布,版本通常应该是兼容的。
– **Keras 3.5**:Keras 3.x 版本旨在与 TensorFlow 2.x 一起使用。但是,您应该验证与 TensorFlow 2.17 的兼容性,因为有时最新的 Keras 可能需要非常特定的 TensorFlow 版本。
### 2. **建议:**
– **Python**:考虑使用 Python 3.10 或 3.9 以更好地兼容更多库。Python 3.12 非常新,并非所有软件包都已获得完全支持。
– **TensorFlow**:确保 TensorFlow 2.17 和 Keras 3.5 设计为协同工作。请查看 TensorFlow 和 Keras 的发行说明以了解兼容性。如果您遇到问题,您可能需要降级到 TensorFlow 2.10-2.12,这些版本经过了广泛的测试并且是稳定的。
– **NumPy**: NumPy 1.26.4 通常是可以的,但如果您遇到兼容性问题,可以考虑降级到 1.23.x 版本,该版本得到了许多其他库的广泛支持。
### 3. **PyTorch 实现:**
– **PyTorch**: 如果您正在寻找 TensorFlow/Keras 的替代品,并且同样易于使用,PyTorch 是一个很好的选择。它以更直观而闻名,特别是对于研究人员和那些希望对模型有更多控制权的人来说。
– **PyTorch 中的 Keras 类 API**: 虽然 PyTorch 本身没有直接与 Keras 对应的功能,但 **
torch.nn** 模块非常用户友好,可以轻松构建模型。还有 **PyTorch Lightning** 或 **fastai** 等库,它们提供了与 Keras 类似的高级抽象,从而更容易实现模型。### 4. **PyTorch 的可能设置:**
– **Python 3.10**: 如果您决定切换到稍旧的 Python 版本以获得更好的兼容性。
– **PyTorch**: 您可以通过 pip 安装 PyTorch,命令如下:
pip install torch torchvision torchaudio
– **PyTorch Lightning 或 fastai**: 这些可以安装为:
pip install pytorch-lightning # 或者 fastai
切换到更稳定的 Python 版本并验证 TensorFlow 和 Keras 的兼容性,可以避免潜在的麻烦。如果您正在寻找像 Keras 一样用户友好但更灵活的东西,PyTorch 也是一个极佳的选择。
您是否需要有关如何将现有的 TensorFlow/Keras 代码迁移到 PyTorch 的指导?
非常感谢 James 博士!
现在,您能帮我处理一下 `continue_train` 选项吗?
在办公室工作日期间,模型仅训练 15-20 个 epoch。您能告诉我如何从先前保存的权重恢复训练吗?
你好 Rajesh… 不客气!要在 Keras 中为您的 CycleGAN 从先前保存的权重恢复训练,您可以使用 `continue_train` 方法,通过加载保存的模型权重并在中断的地方重新开始训练。以下是具体的步骤:
### 步骤 1:保存模型权重
确保您的训练脚本在每个 epoch 或定期保存模型权重。您可以使用 `model.save_weights` 方法来完成。
例如,在训练循环的每个 epoch 之后保存权重:
python
# 在每个 epoch 后保存模型权重
g_model.save_weights('g_model_weights_epoch_{:02d}.h5'.format(epoch))
d_model.save_weights('d_model_weights_epoch_{:02d}.h5'.format(epoch))
### 步骤 2:加载模型权重
当您想恢复训练时,可以在开始新的训练会话之前加载先前保存的权重。这将允许训练从中断的地方继续。
操作方法如下:
python
# 加载已保存的权重
g_model.load_weights('g_model_weights_epoch_20.h5') # 更改为您想恢复的 epoch
d_model.load_weights('d_model_weights_epoch_20.h5')
### 步骤 3:继续训练
加载权重后,您可以照常继续训练。Keras 将从模型权重保存的地方开始。
### 恢复训练的示例代码
python# 假设您已经定义了生成器和判别器模型 (g_model, d_model)
initial_epoch = 20 # 设置为您想恢复的 epoch 号
# 加载已保存的权重
g_model.load_weights('g_model_weights_epoch_{:02d}.h5'.format(initial_epoch))
d_model.load_weights('d_model_weights_epoch_{:02d}.h5'.format(initial_epoch))
# 从中断的地方继续训练
g_model.fit(
train_data,
epochs=100, # 您想运行的总 epoch 数
initial_epoch=initial_epoch, # 从先前完成的 epoch 开始
callbacks=[...], # 您正在使用的任何回调 (例如,ModelCheckpoint)
...
)
### 提示
– 确保将 `fit` 函数中的 `initial_epoch` 参数设置为您要恢复的 epoch。
– 使用 `ModelCheckpoint` 在训练期间自动按间隔保存您的权重。
通过使用此方法,您可以轻松地暂停和恢复您的 CycleGAN 训练,而无需丢失进度。
谢谢!完成数据预处理等工作后我会尝试的。实际上我的数据集很大(约 40GB)。
我想在 `.tiff` 图像上训练这个模型,数据集包含灰度图像和三通道图像。这是(不同通道的图像)导致我在加载和创建图像数组时遇到问题的原因吗?
错误是:
UnidentifiedImageError: cannot identify image file请帮忙!!
解决了!!
实际上,有一些四通道图像导致了错误。
我正在处理一个数据集中大多数图像尺寸高达 1280×1280 的项目。我担心将这些图像缩放到 256×256 可能会导致重要信息丢失。为了解决这个问题,我正在考虑对图像进行预处理,以保持其原始尺寸 1280×1280,并在必要时添加填充以保持尺寸一致。这是一个好的方法吗?如果不是,我应该考虑哪些替代方法?
你好,我正在训练这个模型用于一个巨大的数据集(热成像和光学图像)。在达到大约 20 个 epoch 后,
Epoch 20. Batch 6/12000, dA[0.002, 0.485] dB[0.005, 0.511] g[0.547, 0.701]这就是情况,在测试时,它会生成有噪声的图像。这种噪声模式从大约 epoch 5 开始,到 epoch 20,噪声只是略有波动。
同时,在 epoch 5 到 20 的范围内,dA、dB 和 g 的损失分别从约 3-4、3-4 和 15-20 下降。
如何解决这个问题??
你好 rajdeep…您在 CycleGAN 训练期间观察到的有噪声的图像生成,以及判别器 (dA, dB) 和生成器 (g) 损失的大幅下降,表明模型可能存在不稳定性或过拟合。以下是一些解决此问题的方法:
### 1. **平衡生成器和判别器**
– 低的判别器损失 (dA, dB) 表明判别器过于自信,这会压倒生成器并导致有噪声的输出。
– **解决方案**: 尝试调整生成器和判别器的损失权重。您可以调整对抗性损失和循环一致性损失在整个损失函数中的相对重要性。
python
cycle_loss_weight = 10 # 示例:增加循环一致性损失权重
identity_loss_weight = 0.5 # 示例:增加身份损失权重
### 2. **引入噪声正则化**
– 向判别器 (dA, dB) 的输入添加噪声可以帮助防止它们学习过快而压倒生成器。
– **解决方案**: 向判别器的输入添加高斯噪声或标签平滑,使其不那么自信并稳定训练。
python
# 标签平滑示例(使用 0.9 或 0.1 等值代替 0 和 1)
real_labels = 0.9
fake_labels = 0.1
### 3. **学习率调度**
– 随着训练的进行,恒定的学习率会导致过拟合,这可能解释了从 epoch 5 开始出现的噪声。
– **解决方案**: 在几个 epoch 后实现学习率衰减或调度器。
python
# Keras 中的 Adam 优化器示例
learning_rate_scheduler = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.0002, decay_steps=10000, decay_rate=0.9)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate_scheduler)
### 4. **增加模型正则化**
– 在生成器和判别器网络中添加 dropout 或实例归一化层,以减少过拟合并促进更稳定的训练。
– **解决方案**: 对生成器的层应用 dropout(例如,在 0.2 到 0.5 之间)或使用实例归一化而不是批量归一化,后者更适合图像生成任务。
### 5. **监控循环一致性损失**
– 生成器的循环一致性损失可能已大大降低,导致重建质量较差。
– **解决方案**: 如前所述,增加循环一致性损失的权重,以优先考虑保留图像特征而不是欺骗判别器。
### 6. **数据增强**
– 您可以从对热成像和光学图像都添加数据增强(如翻转、旋转或轻微缩放)中受益,以防止模型对训练集过拟合。
– **解决方案**: 在加载批次时使用 Keras 的图像数据生成器应用增强。
### 7. **生成器架构调整**
– 如果生成器不够强大,无法生成高质量的图像,您可以尝试更深层次的架构,例如增加残差块的数量或生成器中的通道数。
### 8. **PatchGAN 判别器**
– 确保您使用的是 PatchGAN 判别器,这有助于减少对局部特征而不是整个图像的过拟合。
—
通过应用这些策略,您应该能够稳定您的 CycleGAN 训练并减少有噪声图像的生成。如果噪声仍然存在,您可能需要密切监控损失趋势并动态调整学习率或引入更多正则化。
告诉我您想首先探索哪种方法!
我正在使用 .tif 格式的图像数据集进行训练,但它正在生成有噪声的图像。我需要将 .tif 图像的格式更改为 .png 吗?
或者还有什么?
你好 rajdeep… 不,您不必一定将 `.tif` 图像转换为 `.png`,尽管图像格式有时会影响预处理步骤(如缩放和归一化)。相反,有噪声的图像可能是由于其他因素引起的,例如:
1. **归一化和预处理:**
– 在将 `.tif` 图像输入 CycleGAN 模型之前,确保它们已正确归一化。由于 `.tif` 图像通常具有比 `.png` 更高的位深度,因此它们的像素值范围可能不同(例如,16 位 `.tif` 的范围是 0-65535,而 8 位 `.png` 的范围是 0-255)。
– 使用归一化步骤将像素值缩放到 0 到 1 或 -1 到 1 之间,具体取决于您的 CycleGAN 设置。
归一化示例
python
# 将 RGB 图像归一化到 [-1, 1] 范围
image = (image / 32767.5) - 1 # 假设是 16 位 .tif 图像
2. **训练设置导致的噪声结果:**
– **CycleGAN 超参数**: 调整超参数,例如学习率、损失函数权重(例如,循环一致性损失),或使用更复杂的优化器(如带梯度裁剪的 Adam)。
– **训练 epoch**: CycleGAN 通常需要大量的 epoch 才能稳定下来并避免生成有噪声的图像。如果您的模型训练时间不够长,请尝试增加 epoch 数。
– **批次大小**: 如果您使用的批次大小太小,可能会导致训练不稳定。如果可能,请尝试增加批次大小。
3. **数据集质量:**
– 确保您的 `.tif` 图像干净且经过一致的预处理。有时 `.tif` 图像可能带有伪影或噪声,这些都可能导致有噪声的输出。
– 检查 `.tif` 图像是否包含多个通道(例如,多光谱图像),并在需要时将其转换为 RGB。
4. **CycleGAN 架构调整:**
– 您也可以尝试调整生成器和判别器架构。添加 dropout 层、批量归一化或残差连接可能有助于平滑有噪声的结果。
5. **学习率调度:**
– CycleGAN 模型可以从训练过程中降低学习率中受益。考虑使用学习率调度器在训练过程中调整学习率。
如果这些策略不起作用,您可以尝试将 `.tif` 图像转换为 `.png` 或 `.jpeg`,看看是否能解决问题,但问题更有可能存在于训练过程或预处理中。
如果您需要任何这些步骤的帮助,请告诉我!