预测建模机器学习项目,例如分类和回归,总是涉及某种形式的数据准备。
数据集所需的数据准备具体取决于数据的特性,例如变量类型,以及将用于建模它们的算法可能对数据施加的期望或要求。
然而,有一系列标准的数据准备算法可以应用于结构化数据(例如,像电子表格中那样形成一个大表格的数据)。这些数据准备算法可以按类型组织或分组到一个框架中,这在为特定项目比较和选择技术时会很有帮助。
在本教程中,您将了解预测建模机器学习任务中执行的常见数据准备任务。
完成本教程后,您将了解:
- 数据清洗等技术可以识别和修复数据中的错误,例如缺失值。
- 数据转换可以改变数据集中变量的比例、类型和概率分布。
- 特征选择和降维等技术可以减少输入变量的数量。
通过我的新书《机器学习数据准备》**启动您的项目**,其中包括**分步教程**和所有示例的**Python源代码文件**。
让我们开始吧。

机器学习数据准备技术巡览
照片由 Nicolas Raymond 拍摄,保留部分权利。
教程概述
本教程分为六个部分;它们是:
- 常见数据准备任务
- 数据清洗
- 特征选择
- 数据转换
- 特征工程
- 降维
常见数据准备任务
我们可以将数据准备定义为将原始数据转换为更适合建模的形式。
然而,在预测建模项目中,数据准备步骤之前和之后都有重要的步骤,它们为要执行的数据准备提供了信息。
应用机器学习过程包括一系列步骤。
我们可能会在任何给定项目的步骤之间来回跳转,但所有项目都具有相同的通用步骤;它们是:
- **步骤1**:定义问题。
- **步骤2**:准备数据。
- **步骤3**:评估模型。
- **步骤4**:最终确定模型。
我们关注数据准备步骤(步骤2),在机器学习项目的数据准备步骤中,您可能会使用或探索一些常见或标准的任务。
正如您所期望的,执行的数据准备类型取决于您的数据。
然而,当您完成多个预测建模项目时,您会一次又一次地看到并需要相同类型的数据准备任务。
这些任务包括:
- **数据清洗**:识别并纠正数据中的错误或失误。
- **特征选择**:识别与正在预测的目标变量最相关的输入变量。
- **数据转换**:改变变量的比例或分布。
- **特征工程**:从可用数据中派生新变量。
- **降维**:创建数据的紧凑投影。
这提供了一个粗略的框架,我们可以用它来思考和导航我们在给定项目中可能考虑的,带有结构化或表格数据的不同数据准备算法。
让我们依次仔细看看每一个。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据清洗
数据清洗涉及修复“**混乱**”数据中系统性问题或错误。
最有效的数据清洗涉及深厚的领域专业知识,可能包括识别和处理可能不正确的特定观察。
数据可能存在不正确值的原因有很多,例如输入错误、损坏、重复等等。领域专业知识可以识别明显错误的观察结果,因为它们与预期不同,例如一个人的身高为200英尺。
一旦识别出混乱、嘈杂、损坏或错误的观察结果,就可以对其进行处理。这可能涉及删除一行或一列。或者,它可能涉及用新值替换观察结果。
然而,有一些通用的数据清洗操作可以执行,例如:
- 使用统计数据定义正常数据并识别异常值。
- 识别具有相同值或没有方差的列并将其删除。
- 识别重复的数据行并将其删除。
- 将空值标记为缺失。
- 使用统计数据或学习模型估算缺失值。
数据清洗通常在其他数据准备操作之前执行。
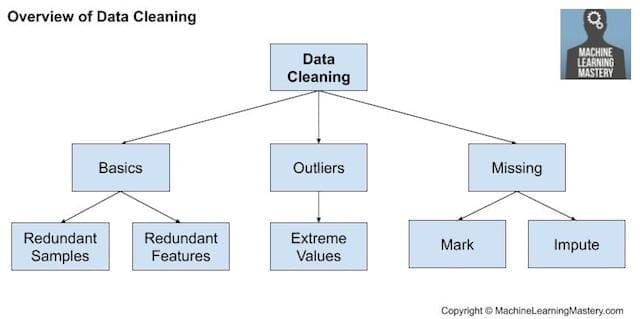
数据清洗概述
有关数据清洗的更多信息,请参阅教程:
特征选择
特征选择是指用于选择与正在预测的目标变量最相关的输入特征子集的技术。
这很重要,因为不相关和冗余的输入变量可能会分散或误导学习算法,可能导致预测性能下降。此外,理想的做法是仅使用进行预测所需的数据来开发模型,例如,倾向于尽可能简单的表现良好的模型。
特征选择技术通常分为使用目标变量的(**监督**)和不使用目标变量的(**无监督**)。此外,监督技术可以进一步分为在模型拟合过程中自动选择特征的模型(**内在**)、明确选择导致最佳性能模型的特征的模型(**包装**)和对每个输入特征进行评分并允许选择子集的模型(**过滤**)。
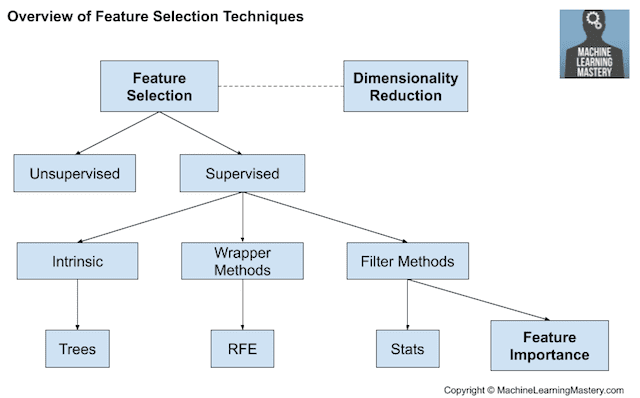
特征选择技术概述
统计方法在对输入特征进行评分时很受欢迎,例如相关性。然后可以根据分数对特征进行排名,并将分数最大的子集用作模型的输入。统计度量的选择取决于输入变量的数据类型以及对可以使用不同统计度量的回顾。
有关如何根据数据类型选择统计特征选择方法的概述,请参阅教程:
此外,在预测建模项目中,我们可能会遇到不同的常见特征选择用例,例如:
- 分类目标变量的分类输入.
- 分类目标变量的数值输入。
- 回归目标变量的数值输入。
当存在混合的输入变量数据类型时,可以使用不同的过滤方法。或者,可以使用诸如流行的 RFE 方法之类的包装方法,该方法与输入变量类型无关。
对输入特征相对重要性进行评分的更广泛领域被称为特征重要性,存在许多基于模型的技术,其输出可用于辅助解释模型、解释数据集或选择用于建模的特征。
有关特征重要性的更多信息,请参阅教程
数据转换
数据转换用于更改数据变量的类型或分布。
这是一个包含各种技术的大类,它们可以同样容易地应用于输入和输出变量。
回想一下,数据可能有几种类型,例如**数值型**或**类别型**,每种类型都有子类型,例如数值型的整数和实数值,以及类别型的名义型、序数型和布尔型。
- **数值数据类型**:数字值。
- **整数**:没有小数部分的整数。
- **实数**:浮点值。
- **类别数据类型**:标签值。
- **序数型**:具有排名顺序的标签。
- **名义型**:没有排名顺序的标签。
- **布尔型**:值True和False。
下图提供了这种高层数据类型分解的概述。
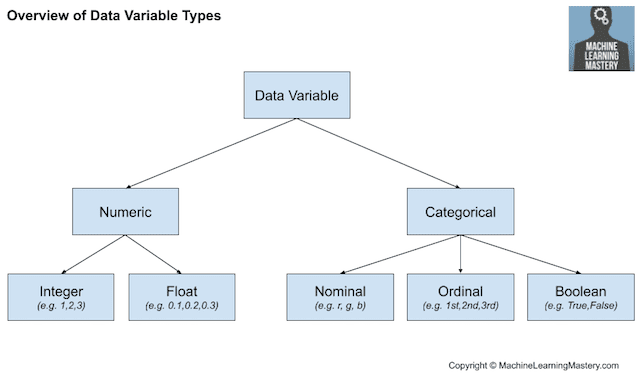
数据变量类型概述
我们可能希望将数值变量转换为序数变量,这个过程称为离散化。或者,我们可能将类别变量编码为整数或布尔变量,这在大多数分类任务中是必需的。
- **离散化转换**:将数值变量编码为序数变量。
- **序数转换**:将类别变量编码为整数变量。
- **独热转换**:将类别变量编码为二进制变量。
对于实数值数值变量,它们在计算机中的表示方式意味着在0-1范围内具有比数据类型更宽泛的范围更多的分辨率。因此,可能需要将变量缩放到此范围,这称为归一化。如果数据具有高斯概率分布,则将数据转换为均值为零、标准差为一的标准高斯分布可能更有用。
- **归一化转换**:将变量缩放到0到1的范围。
- **标准化转换**:将变量缩放到标准高斯分布。
数值变量的概率分布可以改变。
例如,如果分布接近高斯分布,但存在偏斜或偏移,则可以使用幂变换使其更接近高斯分布。或者,可以使用分位数变换来强制一个概率分布,例如对具有不寻常自然分布的变量施加均匀分布或高斯分布。
- **幂变换**:改变变量的分布使其更接近高斯分布。
- **分位数变换**:强制施加一个概率分布,例如均匀分布或高斯分布。
数据转换的一个重要考虑是,这些操作通常对每个变量分别执行。因此,我们可能希望对不同的变量类型执行不同的操作。
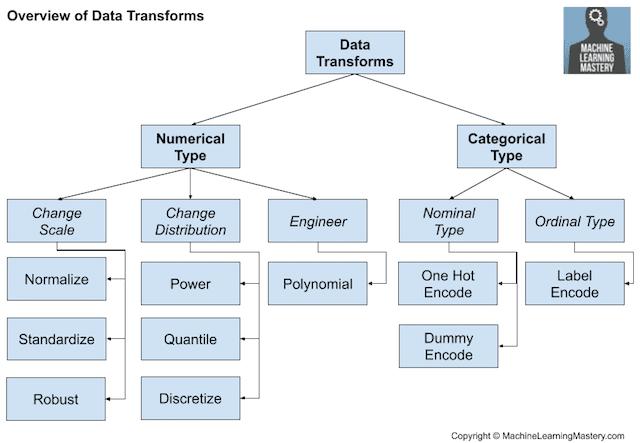
数据转换技术概述
我们可能还希望将来在新的数据上使用转换。这可以通过将转换对象与在所有可用数据上训练的最终模型一起保存到文件中来实现。
特征工程
特征工程是指从可用数据创建新输入变量的过程。
新特征的工程高度依赖于您的数据和数据类型。因此,它通常需要领域专家的协作,以帮助识别可以从数据中构建的新特征。
这种专业性使得将其推广到通用方法成为一个具有挑战性的话题。
然而,有一些技术可以重复使用,例如:
- 为某种状态添加布尔标志变量。
- 添加组或全局汇总统计量,例如均值。
- 为复合变量的每个组成部分添加新变量,例如日期-时间。
一种源自统计学的流行方法是创建数值输入变量的副本,这些副本通过简单的数学运算(例如将其提升到幂次或与其他输入变量相乘)进行更改,这称为多项式特征。
- **多项式变换**:创建数值输入变量的副本,这些副本被提升到幂次。
特征工程的主题是为单个观测添加更广泛的上下文或分解复杂变量,这两者都是为了提供对输入数据更直接的视角。
我喜欢将特征工程视为一种数据转换,尽管将数据转换视为一种特征工程同样合理。
降维
数据集的输入特征数量可以被认为是数据的维度。
例如,两个输入变量一起可以定义一个二维区域,其中数据的每一行定义该空间中的一个点。这个想法可以扩展到任意数量的输入变量,以创建大型多维超体。
问题在于,这个空间维数越多(例如,输入变量越多),数据集就越有可能代表该空间中非常稀疏且可能不具代表性的采样。这被称为维度诅咒。
这促使了特征选择,尽管特征选择的替代方法是将数据投影到较低维空间,同时仍然保留原始数据最重要的属性。
这通常被称为降维,并提供了特征选择的替代方案。与特征选择不同,投影数据中的变量与原始输入变量没有直接关系,这使得投影难以解释。
最常见的降维方法是使用矩阵分解技术:
- 主成分分析 (PCA)
- 奇异值分解 (SVD)
这些技术的主要影响是它们消除了输入变量之间的线性依赖关系,例如相关变量。
还存在其他发现较低维度的方法。我们可能将这些称为基于模型的方法,例如 LDA 和可能的自动编码器。
- 线性判别分析 (LDA)
有时也可以使用流形学习算法,例如 Kohonen 自组织映射和 t-SNE。
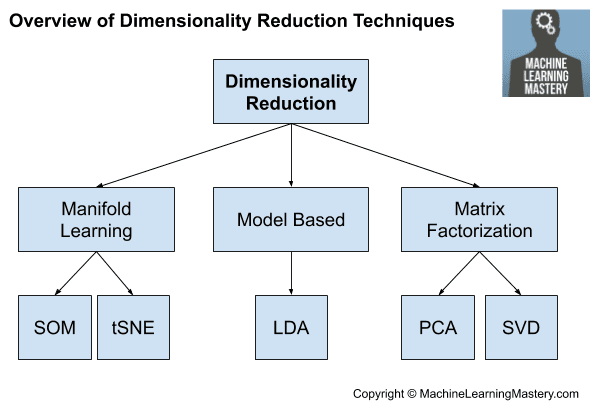
降维技术概述
有关降维的更多信息,请参阅教程:
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 特征工程和选择:预测模型的实用方法, 2019.
- 应用预测建模, 2013.
- 数据挖掘:实用机器学习工具和技术,第4版,2016年。
文章
总结
在本教程中,您了解了预测建模机器学习任务中执行的常见数据准备任务。
具体来说,你学到了:
- 数据清洗等技术可以识别和修复数据中的错误,例如缺失值。
- 数据转换可以改变数据集中变量的比例、类型和概率分布。
- 特征选择和降维等技术可以减少输入变量的数量。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨,Jason,阅读你发表的文章是一段美妙的旅程。非常感谢。
谢谢,很高兴它有帮助。
流程图表示非常棒,让主题更清晰……非常感谢……这值得收藏并反复回顾。
不客气,很高兴能帮到你!
我喜欢数据准备技术的分解——图表非常有用。我总是读你的文章,你让它们很容易理解。
感谢你的时间和奉献!!!!
谢谢!
非常感谢这篇关于ML项目“数据准备”步骤的有趣且令人大开眼界的文章。
只是一个笔误,我想,在以下句子中:
“还存在其他方法可以发现较低的降维。我们可能将这些称为基于LDA和可能的自动编码器的方法。”
我认为“Model”这个词不见了,我认为它是“基于模型”而不是仅仅“基于”。
谢谢,已修复!
非常感谢关于数据准备的富有洞察力的系列文章 🙂
不客气!
您的帖子信息量很大,感谢您的知识分享。请继续这样做。
谢谢!
你好。
如果允许我打印页面以便离线方便阅读,我将不胜感激。但每次我点击“打印”时,“感谢您的注册”框(或其他框)都会不断弹出!你能让它消失吗?非常感谢。
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/how-can-i-print-a-tutorial-page-without-the-sign-up-form
尊敬的Jason博士,
感谢您在教程底部提供了降维技术汇总图表。
我知道你已经掌握了SVD和PCA等所有技术。
是否可以提供以下五个主题的链接?它们是流形学习 – SOM & tSNE、基于模型的 – LDA、PCA & SVD。
谢谢你,
悉尼的Anthony
我还有一篇关于此主题的教程已经编写并安排了,其中包含一些流形学习方法。
感谢您的建议。scikit-learn 不提供 SOM,tsne 提供了,但它不支持这种监督学习中的用法。
杰森,感谢您的资料,一如既往的高质量。您不认为在降维中提及因子分析和PCA是值得的吗?它在特征提取过程中也非常有用。
此致。
好建议,谢谢!
感谢您提供的有益教程,请继续鼓励我们
不客气。
我喜欢您清晰地组织主题的方式,我是视觉学习者,您的图表为我提供了更容易整合知识的方法。
最近我只有一个困惑,那就是如何识别我们是面临“离群值”还是“异常值”,以及如何处理这些值,例如:区分它们的技术,如何在清洗或转换过程中处理异常值,以及这样做是否合适。
谢谢!
好问题,请看这个
https://machinelearning.org.cn/how-to-use-statistics-to-identify-outliers-in-data/
还有这个。
https://machinelearning.org.cn/robust-scaler-transforms-for-machine-learning/
它很棒也很恰当,它阐明了您用父节点分类的各种方法,对我来说真是天赐之物。非常感谢您。
谢谢!
阅读您的文章很棒,它提供了很好的即时见解。
谢谢。
杰森,这是一篇精彩的文章,
如果是一对多关系数据,例如银行贷款数据集,我有一个问题,
如果一个客户有2个受抚养人,每个受抚养人有不同的工资和不同的员工信息,
我发现可以采用两种方法:
第一种,汇总工资,创建一个新列“申请人数量”并填充为2,汇总信用额度,必须跳过一些。
第二种方法,我们可以将受抚养人拆分为两条记录,具有相同的申请号,每条记录的详细信息都填充了其对应的受抚养人信息。
我能知道哪种方法更好吗?
谢谢。
我预计将所有数据简化为一条记录可能是合适的,但这确实取决于数据的具体情况和项目目标。
非常感谢Jason,非常感谢您的回复
不客气。
这是一个很好的概述,但您没有深入探讨图像数据的数据清洗。诚然,这是我的宠物话题,因为我是Python库cleanX的作者,但我希望您将来能涵盖图像的数据清洗!
感谢您的建议!
你好 Jason,
在您的数据转换概述图中,您提到序数类型数据应该接收标签编码转换,我以为这种标签编码是在标签(一维)的情况下,它应该是序数或分类的。为什么序数类型数据不能接收虚拟转换?
非常感谢您在这里所做的一切工作。
序数数据是第一、第二、第三等。标签编码器将这些视为标签,并将其转换为0、1、2等。这是一个单一值。虚拟编码器是独热编码,它转换为多个0或1值的列。当然,您也可以对序数数据这样做,但您将无法保留2大于1、1大于0的信息。通常这不是我们想要的。
你好,
感谢您的这篇文章。
我的问题如下:
我们应该在归一化之前进行特征选择吗?此外,如果我有一个不平衡数据集,应该先处理哪个问题?
谢谢你,
是的,你应该这样做。那会更好。对于不平衡数据,你可以在准备阶段保持不变,但在训练阶段处理它。例如,请参阅https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
大家好,
感谢您的学习材料。
我有三个大文件,共同的列是“ID”。在这种情况下,在合并/连接之前还是之后清洗数据(填充、删除重复项、缩放等)是最好的方法?
合并过程,无论是在数据清洗之前还是之后,都会产生许多额外的缺失值!这让我非常困惑如何解决这个问题以及如何开始解决它。
谢谢你,
托尼
嗨托尼……以下资源应该有助于澄清:
https://machinelearning.org.cn/handle-missing-data-python/
https://machinelearning.org.cn/statistical-imputation-for-missing-values-in-machine-learning/
https://machinelearning.org.cn/binary-flags-for-missing-values-for-machine-learning/