数据在机器学习中扮演着重要角色。
在谈论数据时,理解和使用正确的术语至关重要。
在这篇文章中,您将确切地了解如何在机器学习中描述和谈论数据。阅读完这篇文章后,您将了解机器学习中用于描述数据的术语和命名法。
通过我的新书 《机器学习统计学》 开启您的项目,书中包含分步教程和所有示例的Python源代码文件。
这将极大地帮助您理解机器学习算法。

如何在机器学习中谈论数据
图片由 PROWilliam J Sisti 提供,部分权利保留。
让我们开始吧。
您所知道的数据
您如何看待数据?
想象一个电子表格,比如 Microsoft Excel。您有列、行和单元格。
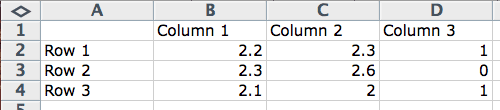
机器学习中的数据术语
- 列:一列描述了单一类型的数据。例如,您可能有一列体重、身高或价格。一列中的所有数据都将具有相同的比例,并且彼此之间具有相关意义。
- 行:一行描述了一个单独的实体或观测,而列描述了该实体或观测的属性。您拥有的行越多,您就拥有越多来自问题领域的示例。
- 单元格:单元格是行和列中的单个值。它可以是实数值(1.5)、整数(2)或类别(“红色”)。
这可能就是您思考数据、列、行和单元格的方式。
总的来说,我们可以称这类数据为:表格数据。这种形式的数据在机器学习中很容易处理。
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
机器学习中已知的数据
机器学习有不同的视角,提供了不同的领域观点。例如,有统计学视角和计算机科学视角。
接下来,我们将看看用于指代您所知道的数据的不同术语。
统计学习视角
统计学视角将数据置于机器学习算法试图学习的假设函数 (f) 的上下文中。
也就是说,给定一些输入变量 (input),预测输出变量 (output) 是什么。
output = f(input)
那些作为输入的列被称为输入变量。
而您可能并非总拥有、并且希望在未来预测新输入数据的列,则被称为输出变量。它也称为响应变量。
output variable = f(input variables)
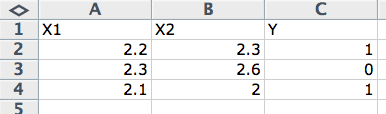
统计学习视角
通常,您会有一个以上的输入变量。在这种情况下,输入变量组被称为输入向量。
output variable = f(input vector)
如果您过去学过一些统计学,您可能知道另一种更传统的术语。
例如,统计学教科书可能会将输入变量称为自变量,将输出变量称为因变量。这是因为在预测问题的表述中,输出依赖于输入或自变量,或者说是它们的函数。
dependent variable = f(independent variables)
数据在机器学习算法的方程和描述中使用了简写。统计学视角中使用的标准简写是将输入变量称为大写“x”(X),将输出变量称为大写“y”(Y)。
Y = f(X)
当您有多个输入变量时,可以使用整数来表示它们在输入向量中的顺序,例如,对于前三列中的数据,为 X1、X2 和 X3。
计算机科学视角
计算机科学术语和统计学术语在数据方面有很大的重叠。我们将探讨关键差异。
一行通常描述一个实体(如一个人)或一个关于实体的观测。因此,一行中的列通常被称为该观测的属性。在建模问题和进行预测时,我们可能会提到输入属性和输出属性。
output attribute = program(input attributes)
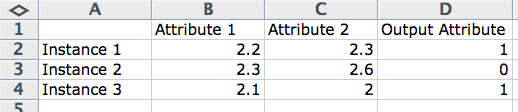
计算机科学视角
列的另一个名称是特征,其原因与属性相同,特征描述了观测的某个属性。这在处理需要从原始数据中提取特征来构建观测的数据时更为常见。
这方面的例子包括图像、音频和视频等模拟数据。
output = program(input features)
另一种计算机科学的说法是,一行数据或一个观测被称为一个实例。之所以这样称呼,是因为一行可以被视为问题领域中观测或生成的数据的一个示例或单个实例。
prediction = program(instance)
模型与算法
还有最后一点澄清很重要,那就是算法和模型之间的区别。
这可能会令人困惑,因为算法和模型都可以互换使用。
我喜欢的一种观点是,将模型视为从数据中学到的特定表示,而算法是学习它的过程。
model = algorithm(data)
例如,决策树或一组系数是一个模型,而 C5.0 和最小二乘线性回归是学习这些相应模型的算法。
总结
在这篇文章中,您学习了描述机器学习数据时的关键术语。
- 您从电子表格中的表格数据标准理解开始,即列、行和单元格。
- 您学习了统计学中的输入变量和输出变量的术语,它们分别可以表示为 X 和 Y。
- 您学习了计算机科学中的属性、特征和实例的术语。
- 最后,您了解到模型和算法的讨论可以区分为学习到的表示和学习过程。
您对这篇文章或机器学习中的数据术语有任何疑问吗?请留言提问,我会尽力回答。







晚上好!
我觉得有点难理解,我刚接触这个领域,正在学习 Python,我想在一家化学学校实现一个学习系统,用 Python 做一个分子模拟器,让学生可以一个一个地学习分子。但我仍然有很多疑问,很少有人愿意和我一起做这件事,我已经向政府求助,但没有回应。这很困难,但在巴西要将一个想法付诸实践仍然非常困难。
很遗憾听到这个消息,请坚持下去。
我最好的入门建议在这里:
https://machinelearning.org.cn/start-here/
另外,这里的一些常见问题可能会有帮助
https://machinelearning.org.cn/faq/
您好。感谢您提供的所有好文章。我有一个关于由所选术语推导出的矩阵表示的问题。如果我将行 V 表示为实体,列 M 表示为特定实体的属性,并创建这个 VxM 矩阵,那么如果我选择反向分析它,作为一个 MxV 矩阵,这有什么区别吗?也就是说,在第一种情况下,我会想到 |V| 维空间中的 |M| 个点;而在第二种情况下,我会想到 |M| 维空间中的 |V| 个点(假设每列是一个点)。例如,在其中一个上运行聚类与在另一个上运行聚类有什么区别吗?
谢谢!
不客气。
好问题。是的,从我们的建模角度来看,这很重要,但从数学角度来说,它不太重要——数学并不关心。
也许其中一些教程会有帮助
https://machinelearning.org.cn/start-here/#linear_algebra
谢谢您的回复。我会去看看的。
不客气。