你必须理解你的数据,才能从机器学习算法中获得最佳结果。
数据可视化可能是总结和了解数据最快、最有效的方式。
在这篇文章中,你将确切地了解如何使用数据可视化来更好地理解你的数据,以便在 R 中进行机器学习。
如果你是开发人员,刚刚开始使用 R 进行机器学习,或者正打算开始,这篇文章非常适合你。
请跟随本文的 R 方法,或在你的当前或下一个项目中使用它们。
用我的新书《R 语言机器学习精通》启动你的项目,其中包括分步教程和所有示例的 R 源代码文件。
让我们开始吧。

在 R 中使用可视化更好地理解数据
图片来源:Cory M. Grenier,保留部分权利。
理解你的数据以获得最佳结果
更好地理解你的数据将使机器学习算法产生更好的结果。
你将能够清理、转换并最好地呈现你拥有的数据。数据越能向机器学习算法揭示问题的结构,你的模型就越准确。
此外,对数据更深入的理解甚至可能暗示要尝试哪些特定的机器学习算法。
可视化你的数据以更快理解
提高你对数据集理解的最快方法是将其可视化。
可视化意味着从原始数据创建图表和绘图。
属性的分布或散布图可以帮助你发现异常值、奇怪或无效数据,并让你了解可能应用的データ转换。
属性之间关系的图表可以让你了解可能冗余的属性、可能需要的重采样方法,以及最终预测问题可能有多困难。
现在,让我们看看如何使用 R 创建数据图表。
需要更多关于R机器学习的帮助吗?
参加我为期14天的免费电子邮件课程,了解如何在您的项目中使用R(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
在 R 中可视化你的数据
在本节中,你将了解如何在 R 中快速可视化你的数据。
本节分为三个部分
- 可视化包:关于 R 可视化包选项的简要说明。
- 单变量可视化:可用于独立理解每个属性的图表。
- 多变量可视化:可帮助你更好地理解属性之间交互的图表。
让我们开始吧。
1. 可视化包
在 R 中有许多可视化数据的方法,但有一些包已经成为最普遍有用的包。
- graphics:非常适合快速绘制基本数据图。
- lattice:更漂亮的图表,在实践中通常更有用。
- ggplot2:当你想呈现结果时,可以生成精美的图表。
我通常坚持使用 graphics 包中的简单图表进行快速粗略的可视化,并使用 lattice(通过 caret 包)的包装器进行更有用的多变量图表。
我认为 ggplot2 图表非常出色且美观,但对于快速粗略的数据可视化来说有点大材小用。
2. 单变量可视化
单变量图是没有交互的单个属性图。目标是了解每个属性的分布、集中趋势和散布。
直方图
直方图提供了一个数值属性的条形图,该属性被分成若干个 bin,高度显示落入每个 bin 的实例数。
它们对于了解属性的分布很有用。
|
1 2 3 4 5 6 7 |
# 加载数据 data(iris) # 为每个属性创建直方图 par(mfrow=c(1,4)) for(i in 1:4) { hist(iris[,i], main=names(iris)[i]) } |
你可以看到,大多数属性都显示高斯或双高斯分布。你可以在花瓣宽度和长度列中看到非常小的花的测量值。
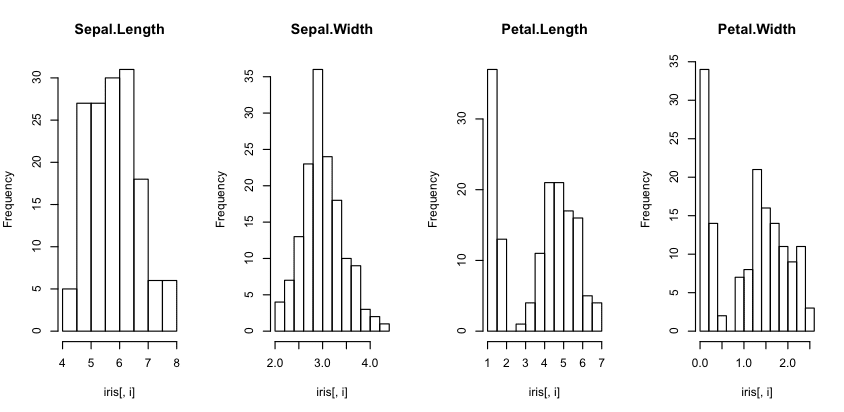
R 中的直方图
密度图
我们可以使用密度图将直方图平滑成线。这些对于更抽象地描绘每个变量的分布很有用。
|
1 2 3 4 5 6 7 8 9 |
# 加载库 library(lattice) # 加载数据集 data(iris) # 按属性创建更简单的密度图面板 par(mfrow=c(1,4)) for(i in 1:4) { plot(density(iris[,i]), main=names(iris)[i]) } |
使用与直方图示例相同的数据集,我们可以看到花瓣测量值的双高斯分布。我们还可以看到萼片宽度可能呈指数(类拉普拉斯)分布。
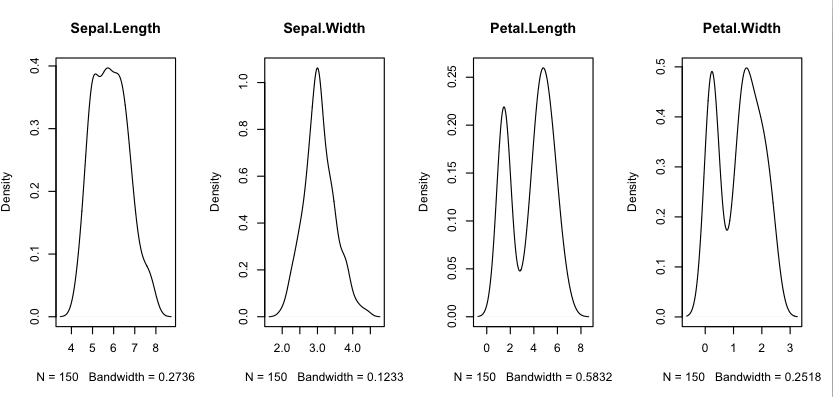
R 中的密度图
箱线图
我们可以使用箱线图以不同的方式查看数据分布。箱线图包含数据中间的 50%,线显示中位数,箱线图的须显示数据的合理范围。位于须之外的任何点都是离群值的良好候选。
|
1 2 3 4 5 6 7 |
# 加载数据集 data(iris) # 为每个属性创建单独的箱线图 par(mfrow=c(1,4)) for(i in 1:4) { boxplot(iris[,i], main=names(iris)[i]) } |
我们可以看到所有数据的范围相似(并且单位都是厘米)。我们还可以看到萼片宽度对于此样本可能有一些异常值。
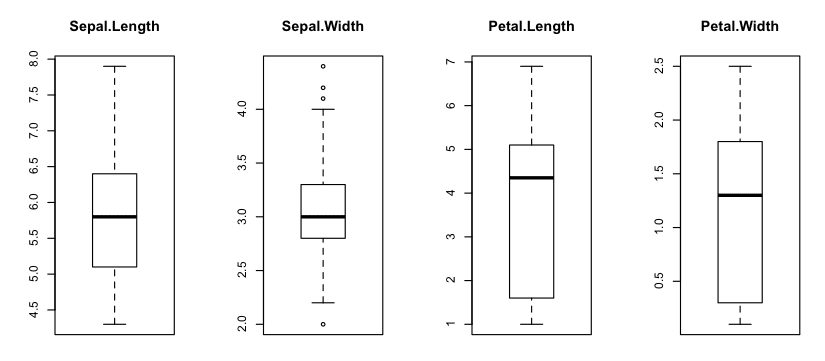
R 中的箱线图
条形图
在具有分类而非数值属性的数据集中,我们可以创建条形图,以了解属于每个类别的实例的比例。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载库 library(mlbench) # 加载数据集 data(BreastCancer) # 为每个分类属性创建条形图 par(mfrow=c(2,4)) for(i in 2:9) { counts <- table(BreastCancer[,i]) name <- names(BreastCancer)[i] barplot(counts, main=name) } |
我们可以看到,有些图表具有良好的混合分布,而另一些图表则显示少数标签具有压倒性的实例数量。
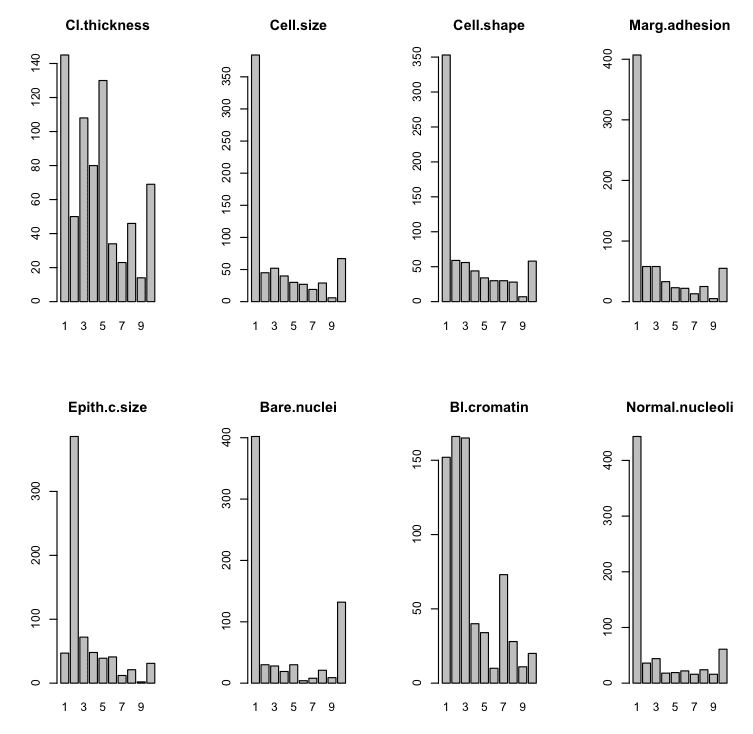
R 中的条形图
缺失图
缺失数据可能会对建模产生重大影响。有些技术会忽略缺失数据,而另一些则会崩溃。
你可以使用缺失图来快速了解数据集中缺失数据的数量。x 轴表示属性,y 轴表示实例。水平线表示实例的缺失数据,垂直块表示属性的缺失数据。
|
1 2 3 4 5 6 7 |
# 加载库 library(Amelia) library(mlbench) # 加载数据集 data(Soybean) # 创建缺失图 missmap(Soybean, col=c("black", "grey"), legend=FALSE) |
我们可以看到有些实例在部分或大部分属性上缺失了大量数据。
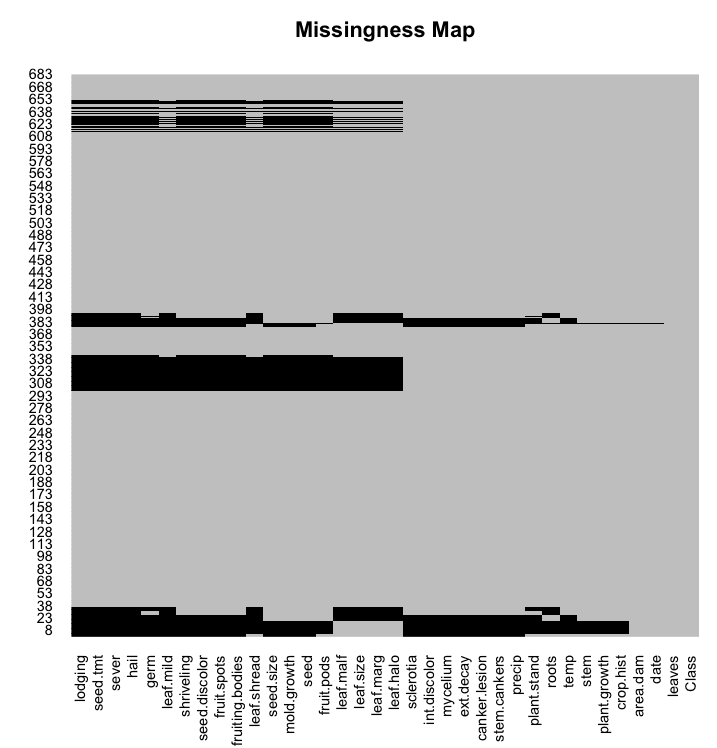
R 中的缺失图
3. 多变量可视化
多变量图是属性之间关系或交互的图。目标是了解数据组(通常是成对属性)的分布、集中趋势和散布。
相关图
我们可以计算每对数值属性之间的相关性。这些成对相关性可以在相关矩阵图中绘制,以了解哪些属性同时变化。
|
1 2 3 4 5 6 7 8 |
# 加载库 library(corrplot) # 加载数据 data(iris) # 计算相关性 correlations <- cor(iris[,1:4]) # 创建相关图 corrplot(correlations, method="circle") |
使用了点状表示,其中蓝色代表正相关,红色代表负相关。点越大,相关性越大。我们可以看到矩阵是对称的,对角线是完全正相关的,因为它显示了每个属性与自身的相关性。我们可以看到有些属性高度相关。
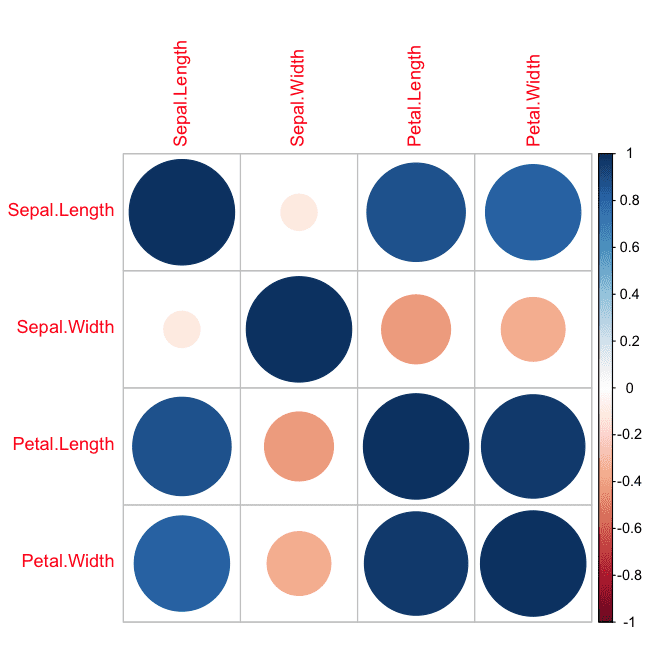
R 中的相关矩阵图
散点图矩阵
散点图将两个变量一起绘制,一个在 x 轴上,一个在 y 轴上,点显示交互。点的分布表示属性之间的关系。你可以为数据集中的所有属性对创建散点图,这称为散点图矩阵。
|
1 2 3 4 |
# 加载数据 data(iris) # 所有 4 个属性的成对散点图 pairs(iris) |
请注意,该矩阵是对称的,显示了轴颠倒的相同图表。这有助于从多个角度查看数据。请注意花瓣长度和宽度之间的线性(对角线)关系。
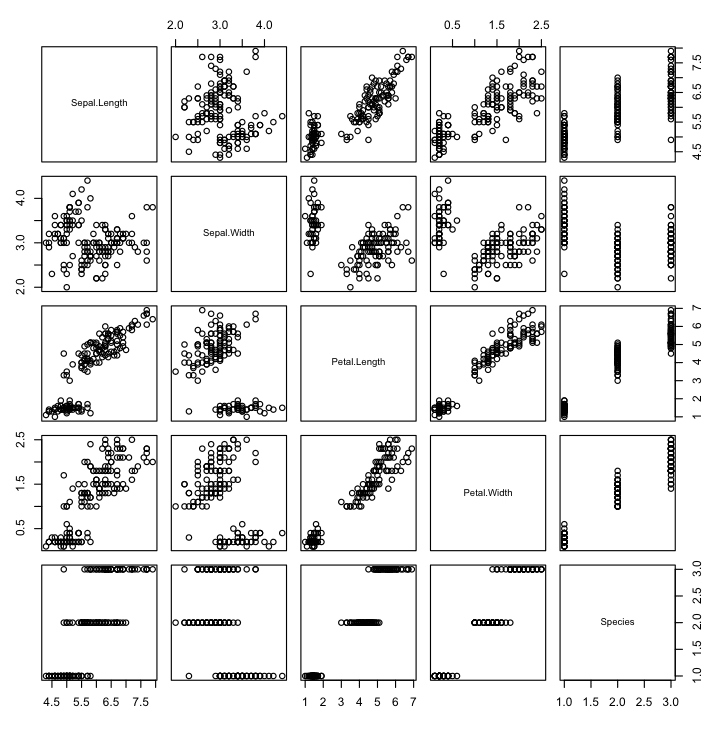
R 中的散点图矩阵
按类别分类的散点图矩阵
在分类问题中,散点图矩阵中的点可以根据类别标签着色。这有助于发现类别的清晰(或不清晰)分离,并可能让人了解问题的难度。
|
1 2 3 4 |
# 加载数据 data(iris) # 按类别着色的成对散点图 pairs(Species~., data=iris, col=iris$Species) |
请注意,在大多数成对图中,点按类别标签清晰分离。
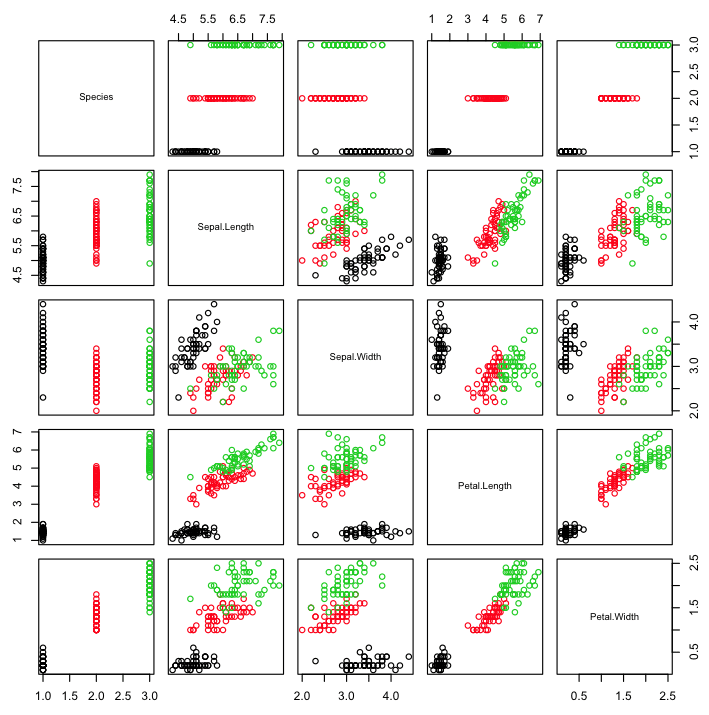
R 中按类别分类的散点图矩阵
按类别划分的密度
我们可以按类别值查看每个属性的密度分布。与散点图矩阵一样,按类别划分的密度图有助于查看类别的分离。它还可以帮助理解属性中类别值的重叠。
|
1 2 3 4 5 6 7 8 9 |
# 加载库 library(caret) # 加载数据 data(iris) # 按类别值划分的每个属性的密度图 x <- iris[,1:4] y <- iris[,5] scales <- list(x=list(relation="free"), y=list(relation="free")) featurePlot(x=x, y=y, plot="density", scales=scales) |
我们可以看到有些类别完全不重叠(例如花瓣长度),而其他属性则很难区分(萼片宽度)。
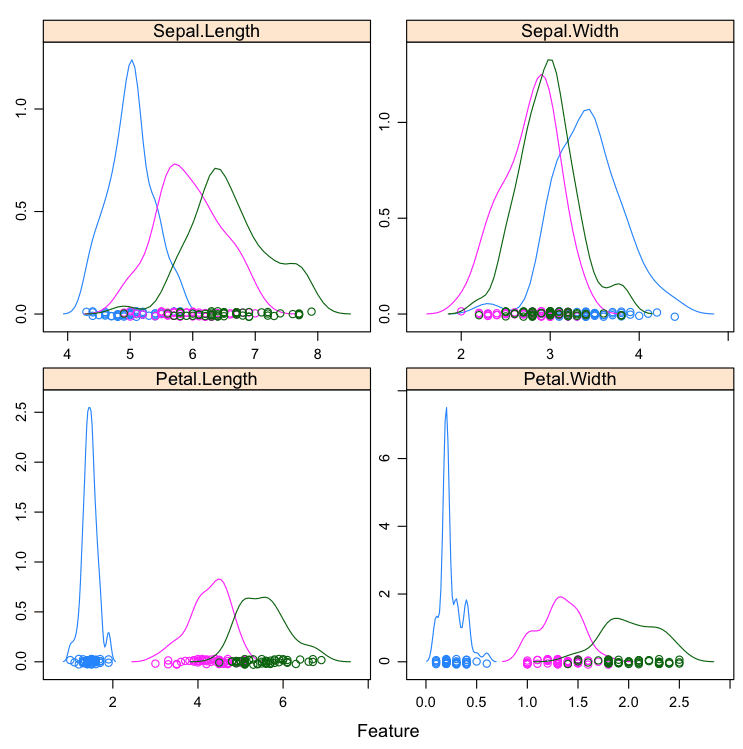
R 中按类别划分的密度图
按类别划分的箱线图
我们还可以按类别值查看每个属性的箱线图分布。这也有助于理解每个属性与类别值的关系,但与密度图的角度不同。
|
1 2 3 4 5 6 7 8 |
# 加载 caret 库 library(caret) # 加载iris数据集 data(iris) # 按类别值划分的每个属性的箱线图 x <- iris[,1:4] y <- iris[,5] featurePlot(x=x, y=y, plot="box") |
这些图有助于理解属性-类别组的重叠和分离。我们可以看到花瓣长度属性的 Setosa 类别有很好的分离。
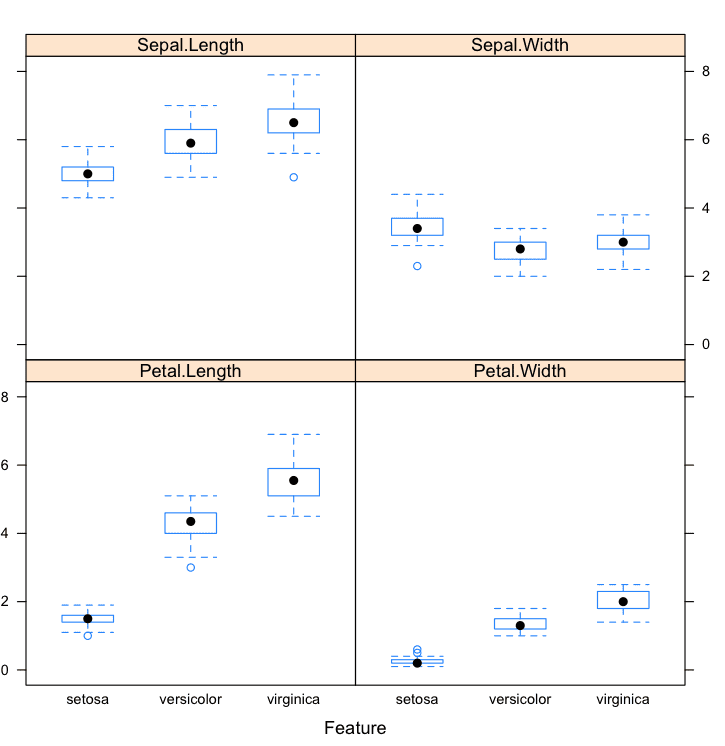
R 中按类别划分的箱线图
额外的可视化
你可能会发现另一种有用的可视化类型是数据集的投影。
有时使用主成分分析或自组织映射进行的投影可以提供对数据的洞察。
你有没有在这篇文章中没有涉及到的最喜欢的数据可视化方法?请留言,我很乐意听取你的意见。
数据可视化技巧
- 查看图表。花时间查看你生成的图表并思考它们。尝试将你所看到的内容与一般问题领域以及数据中的特定记录联系起来。目标是了解你的数据,而不是生成图表。
- 丑陋的图表,而不是漂亮的。你的目标是了解你的数据,而不是创建漂亮的可视化。如果图表很丑,请不要担心。你不会把它们展示给任何人。
- 写下想法。当你查看数据可视化时,你会产生很多想法。例如要查看的数据分割、要应用的转换和要测试的技术。把它们都写下来。当你后来绞尽脑汁想出更多方法来获得更好的结果时,它们将是无价的。
你可以在 R 中可视化数据
你不需要成为 R 程序员。提供的“食谱”是完整的,提供你需要获得结果的一切。你可以立即运行它们,也可以将它们用作你自己项目中的模板。花点时间研究一下所使用的函数,以了解更多关于 R 编程的信息。
你不需要成为数据可视化专家。数据可视化是一个广阔的领域,关于它的书籍也很多。专注于了解你的数据,而不是创建大量花哨的图表。这些图表在学习完之后实际上会被扔掉。
你不需要准备自己的数据集。R 中有许多可用数据集供你使用。你不需要等到收集自己的数据。你还可以从 UCI 机器学习仓库下载数据集,其中有数百个来自各种有趣研究领域的数据集可供选择。
你不需要很多时间。快速进行可视化。从可视化中了解数据应该只需要几分钟或几小时,而不是几天或几周。如果你花费了几个小时以上,你可能正在尝试让图表过于漂亮。让它们变得“丑陋”一些,专注于学习。
总结
在这篇文章中,你了解了数据可视化的重要性,以便更好地理解你的数据。
你发现了一些方法,可以用来可视化并提高你对独立属性(使用单变量图)及其交互(使用多变量图)的理解。
- 单变量图
- 直方图
- 密度图
- 箱线图
- 条形图
- 缺失图
- 多变量图
- 相关图
- 散点图矩阵
- 按类别分类的散点图矩阵
- 按类别划分的密度
- 按类别划分的箱线图
行动步骤
你完成这些方法了吗?
- 启动您的 R 交互式环境。
- 将每个方法键入或复制粘贴到你的环境中。
- 花点时间了解每个方法的工作原理,并使用 R 帮助来了解更多关于所使用函数的信息。
在你的当前或下一个机器学习项目中使用本文中的可视化方法。如果你这样做了,我很乐意听到你的消息。
你对这篇文章有任何疑问吗?请留言提问。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。






这太棒了,谢谢!我刚刚开始接触 R 和机器学习。订阅了你的网站,非常喜欢这些课程。请继续努力!
Elia,很高兴你觉得有用。
嘿,Jason,这个看起来真的很酷,我喜欢这些指导。但我接下来期望的是,我的可视化如何帮助我获得这些洞察力?你如何将从中学到的所有推论用于建模以及创建新特征?我看到很多 Kaggle 玩家制作了出色的图表,发现了洞察力并将其用于特征工程。但我真的缺乏将洞察力转化为建模行动的技能。我所知道的就是绘制散点图,寻找异常值,然后删除它们。这是我目前利用绘图知识所采取的行动。
你展示了一些有趣的事情,例如在箱线图 Petal.length 中,Sentosa 类有很好的分离。同样,在密度图中 Petal.Width 也不重叠。所以我想知道我将如何将它们用于建模和特征工程。如果你也能分享这些技巧,那就太棒了
好问题,Thanish。
一个值得寻找的好东西是高斯单变量分布或接近高斯的分布。接近高斯的分布可以通过 box-cox 变换来修正。高斯分布可能表明类似的方法可能会表现良好,例如线性/逻辑回归、LDA、PCA 等。
数据可视化和特征工程的问题是针对具体问题的。数据可以告诉你很多关于如何提取新特征的信息,但抽象地讨论这个问题非常困难/不可能。我希望有一天能写一本关于这个主题的完整书籍。
亲爱的杰森,
对于包含 10 个属性和 50,000 个观测值的数据集,
我无法运行以下命令:
pairs(Species~., data=iris, col=iris$Species)
我也尝试使用以下命令更改边距:
graphics.off()
par("mar")
par(mar=c(1,1,1,1))
但它仍然没有显示。
有什么线索吗?
你可能正在尝试绘制过多的观测值,请尝试使用你的数据集的一个较小的样本。