有时,数据只有以图表等可视化形式呈现时,才具有意义。
能够为自己和他人快速可视化数据样本,是应用统计学和应用机器学习中的一项重要技能。
在本教程中,您将了解在 Python 中可视化数据时需要掌握的五种图表类型,以及如何使用它们来更好地理解自己的数据。
完成本教程后,您将了解:
- 如何使用折线图绘制时间序列数据,使用条形图绘制分类数量。
- 如何使用直方图和箱线图汇总数据分布。
- 如何使用散点图汇总变量之间的关系。
通过我的新书《机器学习统计学》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 8 月更新:更新了 IQR 描述中的印刷错误。

Python 数据可视化方法简介
图片由 Ian Sutton 拍摄,保留部分权利。
教程概述
本教程分为7个部分;它们是:
- 数据可视化
- Matplotlib 简介
- 折线图
- 条形图
- 直方图
- 箱线图
- 散点图
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据可视化
数据可视化是应用统计学和机器学习中的一项重要技能。
统计学确实侧重于数据的定量描述和估计。数据可视化提供了一套重要的工具,用于获得定性理解。
这在探索和了解数据集时很有帮助,可以帮助识别模式、损坏数据、异常值等等。借助一些领域知识,数据可视化可以用于在图表中表达和演示关键关系,这些关系比关联或显著性度量更能直观地传达给您和利益相关者。
数据可视化和探索性数据分析本身就是完整的领域,我将推荐更深入地阅读文末提到的一些书籍。在本教程中,让我们看看您可以用来更好地理解数据的基本图表。
对于基本数据可视化,您需要熟练掌握五种关键图表。它们是:
- 折线图
- 条形图
- 直方图
- 箱线图
- 散点图
通过了解这些图表,您可以快速对您遇到的大多数数据获得定性理解。
在本教程的其余部分,我们将仔细研究每种图表类型。
Matplotlib 简介
Python 中有许多出色的绘图库,我建议您探索它们以创建可呈现的图形。
对于您自己使用的快速简陋图表,我建议使用 matplotlib 库。它是许多其他绘图库和高级库(如 Pandas)中绘图支持的基础。
matplotlib 提供了一个上下文,可以在显示图像或将其保存到文件之前绘制一个或多个图。可以通过 pyplot 上的函数访问该上下文。该上下文可以按如下方式导入:
|
1 |
from matplotlib import pyplot |
导入此上下文并将其命名为 plt 有一些约定;例如
|
1 |
import matplotlib.pyplot as plt |
我们不会使用此约定,而是坚持使用标准的 Python 导入约定。
图表通过创建和调用上下文来制作;例如
|
1 |
pyplot.plot(...) |
轴、标签、图例等元素可以在此上下文上作为单独的函数调用进行访问和配置。
通过调用 show() 函数,可以在新窗口中显示上下文上的绘图。
|
1 2 |
# 显示绘图 pyplot.show() |
或者,上下文上的绘图可以保存到文件,例如 PNG 格式的图像文件。savefig() 函数可以用于保存图像。
|
1 |
pyplot.savefig('my_image.png') |
这是使用 matplotlib 库最基本的速成课程。
有关更多详细信息,请参阅用户指南和教程末尾的资源。
折线图
折线图通常用于呈现以固定时间间隔收集的观测值。
x 轴表示固定时间间隔,例如时间。y 轴显示观测值,按 x 轴排序并用一条线连接。
折线图可以通过调用 plot() 函数并传入固定时间间隔的 x 轴数据和观测值的 y 轴数据来创建。
|
1 2 |
# 创建折线图 pyplot.plot(x, y) |
折线图对于呈现时间序列数据以及任何观察值之间存在顺序的序列数据都很有用。
下面的示例创建了一个 100 个浮点值的序列作为 x 轴,并将 x 轴的函数正弦波作为 y 轴上的观测值。结果以折线图的形式绘制。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 折线图示例 from numpy import sin from matplotlib import pyplot # x 轴的一致间隔 x = [x*0.1 for x in range(100)] # y 轴的 x 函数 y = sin(x) # 创建折线图 pyplot.plot(x, y) # 显示折线图 pyplot.show() |
运行示例会创建一个折线图,显示 x 轴上熟悉的正弦波模式,y 轴上观测值之间具有一致的间隔。
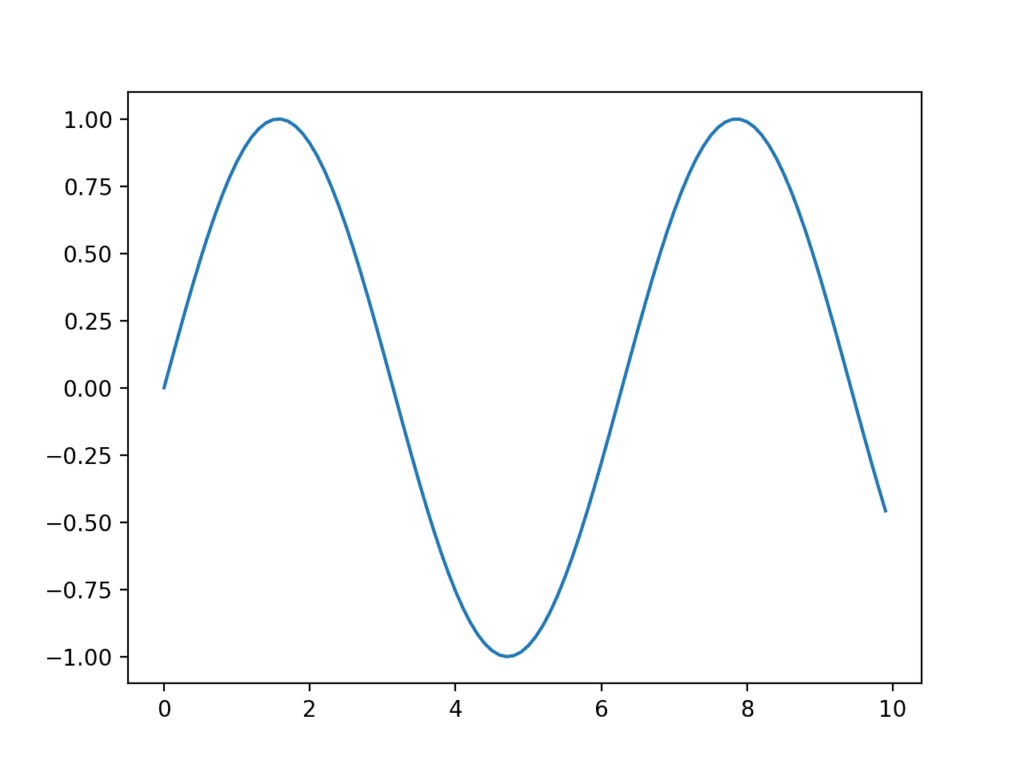
折线图示例
条形图
条形图通常用于呈现多个类别的相对数量。
x 轴表示类别,并均匀分布。y 轴表示每个类别的数量,并从基线到 y 轴上的适当级别绘制为条形。
条形图可以通过调用 bar() 函数并传入 x 轴的类别名称和 y 轴的数量来创建。
|
1 2 |
# 创建条形图 pyplot.bar(x, y) |
条形图对于比较多个点数量或估计值很有用。
下面的示例创建了一个包含三个类别的数据集,每个类别都用字符串标签定义。每个类别中的数量都绘制了一个随机整数值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 条形图示例 from random import seed from random import randint from matplotlib import pyplot # 为随机数生成器设置种子 seed(1) # 类别名称 x = ['red', 'green', 'blue'] # 每个类别的数量 y = [randint(0, 100), randint(0, 100), randint(0, 100)] # 创建条形图 pyplot.bar(x, y) # 显示折线图 pyplot.show() |
运行示例会创建条形图,显示 x 轴上的类别标签和 y 轴上的数量。
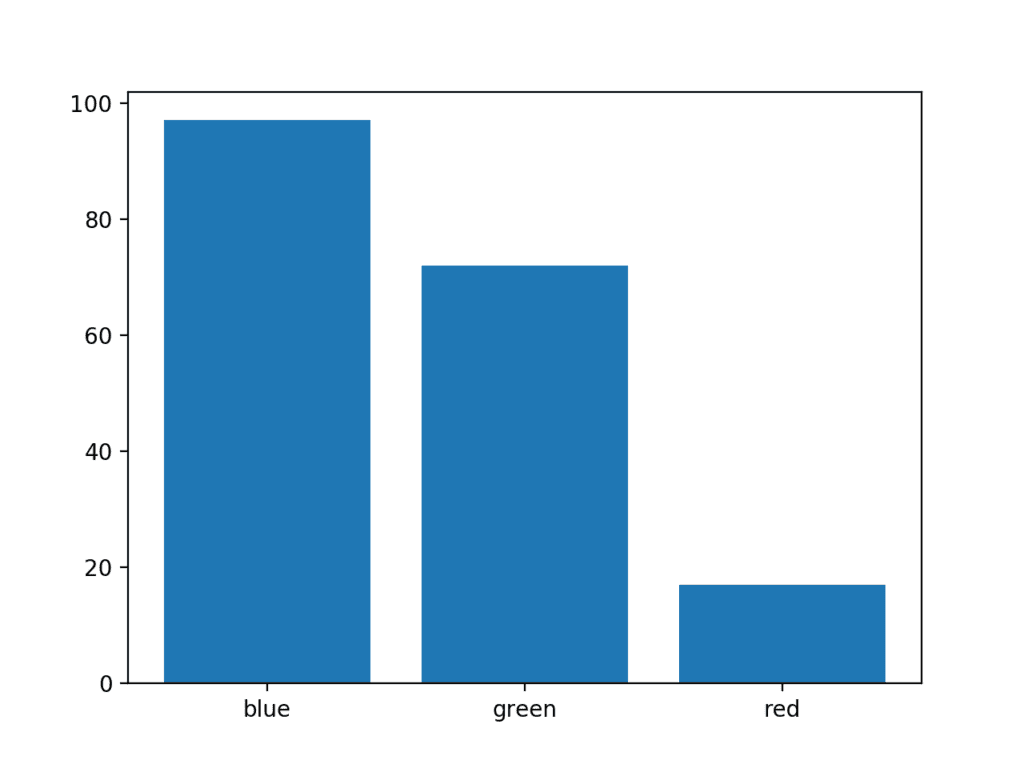
条形图示例
直方图
直方图通常用于汇总数据样本的分布。
x 轴表示观测值的离散区间或箱体。例如,值在 1 到 10 之间的观测值可以分成五个箱体,值 [1,2] 分配给第一个箱体,[3,4] 分配给第二个箱体,依此类推。
y 轴表示数据集中属于每个箱体的观测值的频率或计数。
本质上,数据样本被转换成条形图,其中 x 轴上的每个类别表示观测值的一个区间。
直方图是密度估计。密度估计可以很好地展示数据的分布。[...] 其思想是通过计算一系列连续区间(箱体)中的观测值数量来局部表示数据密度...
——《应用多变量统计分析》第 11 页,2015 年。
直方图可以通过调用 hist() 函数并传入表示数据样本的列表或数组来创建。
|
1 2 |
# 创建直方图 pyplot.hist(x) |
直方图对于汇总数据样本的分布很有价值。
下面的示例创建了一个包含 1,000 个从标准高斯分布中提取的随机数的数据集,然后将该数据集绘制成直方图。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 直方图示例 from numpy.random import seed from numpy.random import randn from matplotlib import pyplot # 为随机数生成器设置种子 seed(1) # 从高斯分布中提取的随机数 x = randn(1000) # 创建直方图 pyplot.hist(x) # 显示折线图 pyplot.show() |
运行示例后,我们可以看到条形的形状显示了高斯分布的钟形曲线。我们可以看到该函数自动选择了箱体数量,在这种情况下,将值按整数值分组。
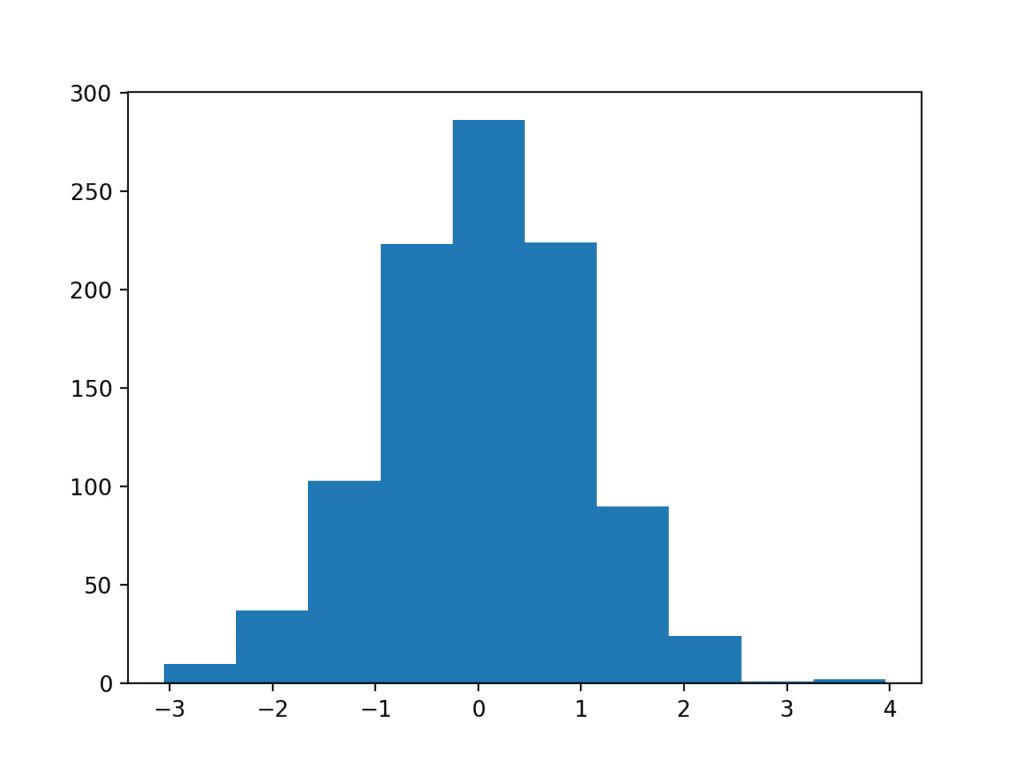
直方图示例
通常,仔细选择箱体数量可以帮助更好地展示数据分布的形状。箱体数量可以通过设置“bins”参数来指定;例如
|
1 2 |
# 创建直方图 pyplot.hist(x, bins=100) |
箱线图
箱线图(或简称箱图)通常用于汇总数据样本的分布。
x 轴用于表示数据样本,如果需要,可以在 x 轴上并排放置多个箱线图。
y 轴表示观测值。绘制一个箱体以汇总数据集的中间 50% 数据,从第 25 百分位数处的观测值开始,到第 75 百分位数处的观测值结束。这称为四分位距,或 IQR。中位数(即第 50 百分位数)用一条线绘制。
从箱体两端延伸的线称为须线,其长度计算为 (1.5 x IQR),以演示分布中合理值的预期范围。须线之外的观测值可能是异常值,并用小圆圈绘制。
箱线图是一种图形技术,用于显示变量的分布。它帮助我们了解位置、偏度、散布、分位数长度和异常点。[...] 箱线图是五数总括的图形表示。
——《应用多变量统计分析》第 5 页,2015 年。
箱线图可以通过调用 boxplot() 函数并传入数据样本作为数组或列表来绘制。
|
1 2 |
# 创建箱线图 pyplot.boxplot(x) |
箱线图对于汇总数据样本的分布很有用,可以作为直方图的替代。它们有助于快速了解箱体和须线中常见和合理值的范围。因为我们没有明确查看分布的形状,所以当数据具有未知或不寻常的分布(例如非高斯分布)时,通常使用此方法。
下面的示例在一个图表中创建了三个箱线图,每个箱线图都汇总了一个从略有不同的高斯分布中提取的数据样本。每个数据样本都创建为一个数组,所有三个数据样本数组都添加到一个列表中,该列表被填充到绘图函数中。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 箱线图示例 from numpy.random import seed from numpy.random import randn from matplotlib import pyplot # 为随机数生成器设置种子 seed(1) # 从高斯分布中提取的随机数 x = [randn(1000), 5 * randn(1000), 10 * randn(1000)] # 创建箱线图 pyplot.boxplot(x) # 显示折线图 pyplot.show() |
运行示例会创建一个显示三个箱线图的图表。我们可以看到每个图表在 y 轴上使用相同的比例,这使得第一个图表看起来被挤压,最后一个图表看起来展开。
在这种情况下,我们可以看到代表数据中间 50% 的黑色箱体,代表中位数的橙色线,代表合理数据范围的须线,最后是代表可能异常值的点。
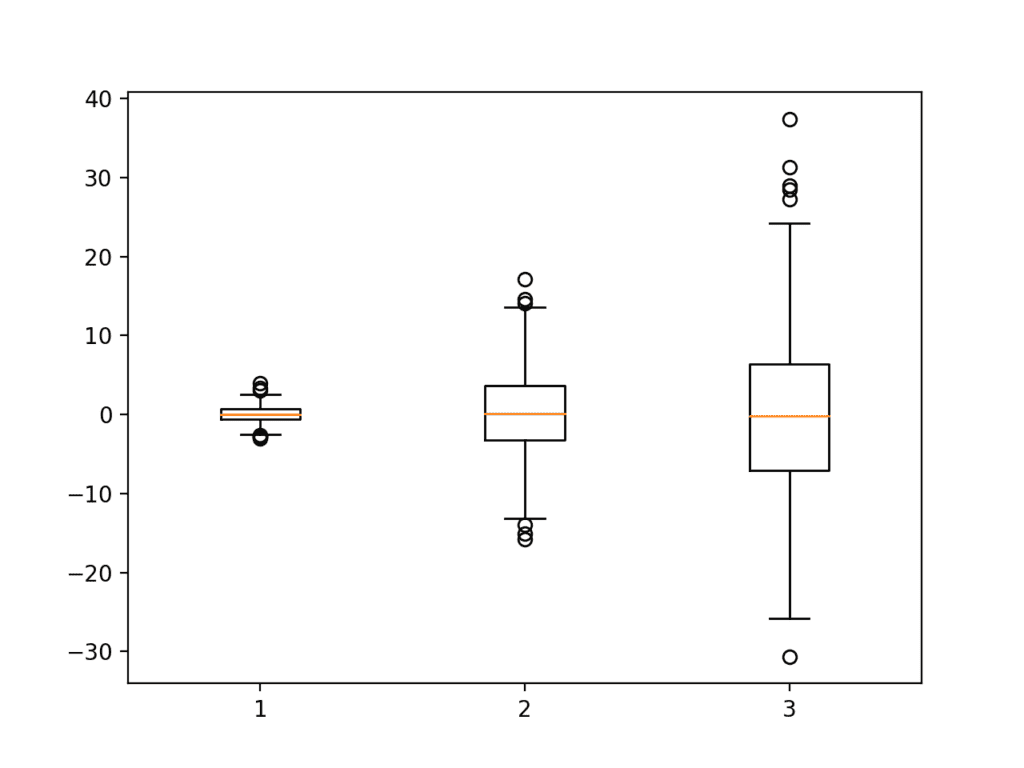
箱线图示例
散点图
散点图(或“散布图”)通常用于汇总两个配对数据样本之间的关系。
配对数据样本意味着对给定观测值记录了两个度量,例如一个人的体重和身高。
x 轴表示第一个样本的观测值,y 轴表示第二个样本的观测值。图上的每个点代表一个观测值。
散点图是变量相互对照的双变量或三变量图。它们帮助我们理解数据集中变量之间的关系。向下倾斜的散点图表示,当我们增加水平轴上的变量时,垂直轴上的变量会减少。
——《应用多变量统计分析》第 19 页,2015 年。
散点图可以通过调用 scatter() 函数并传入两个数据样本数组来创建。
|
1 2 |
# 创建散点图 pyplot.scatter(x, y) |
散点图对于显示两个变量之间的关联或相关性很有用。相关性可以量化,例如最佳拟合线,它也可以作为折线图绘制在同一图表上,使关系更清晰。
一个数据集可能对给定观测值有多个度量(变量或列)。散点图矩阵是一个图,包含数据集中每对变量(超过两个变量)的散点图。
下面的示例创建了两个相关的数据样本。第一个是从标准高斯分布中提取的随机数样本。第二个样本依赖于第一个样本,通过将第二个随机高斯值添加到第一个度量的值中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 散点图示例 from numpy.random import seed from numpy.random import randn from matplotlib import pyplot # 为随机数生成器设置种子 seed(1) # 第一个变量 x = 20 * randn(1000) + 100 # 第二个变量 y = x + (10 * randn(1000) + 50) # 创建散点图 pyplot.scatter(x, y) # 显示折线图 pyplot.show() |
运行示例会创建散点图,显示两个变量之间的正向关系。
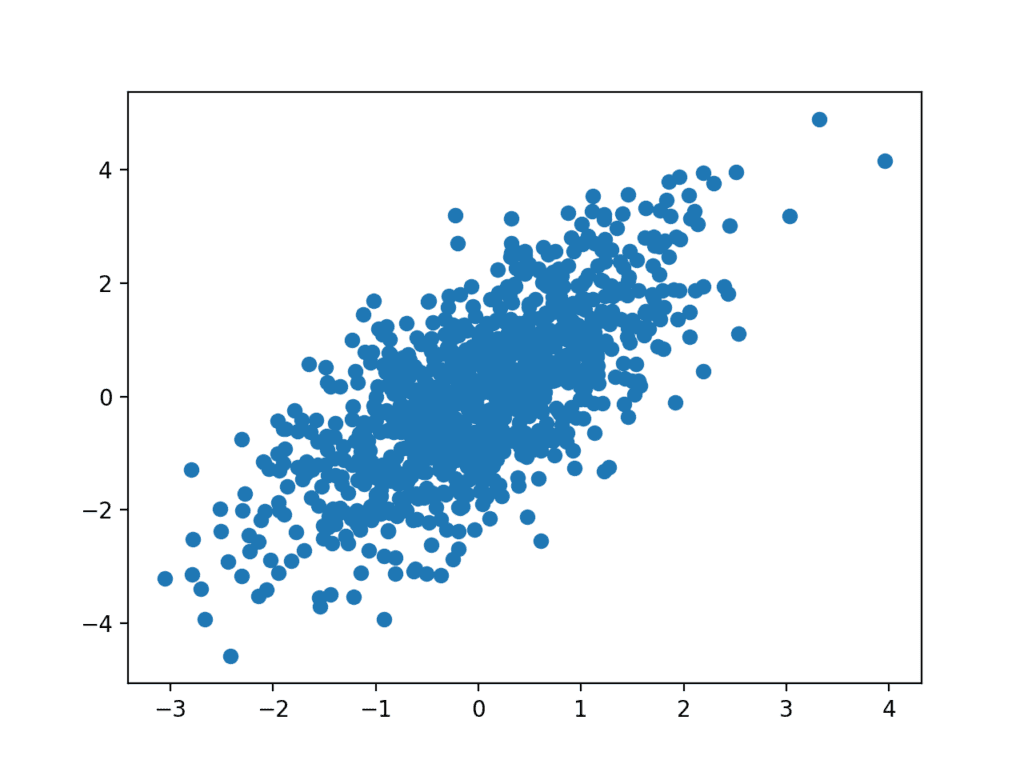
散点图示例
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 选择一个示例并更新它以使用您自己设计的数据集。
- 加载标准机器学习数据集并绘制变量。
- 编写方便的函数,轻松为您的数据创建图表,包括标签和图例。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
书籍
- 定量信息的视觉呈现, 2001.
- Python 数据分析:使用 Pandas、NumPy 和 IPython 进行数据整理, 2017.
- 应用多变量统计分析, 2015.
API
- matplotlib 库
- matplotlib 用户指南
- matplotlib.pyplot() API
- matplotlib.pyplot.show() API
- matplotlib.pyplot.savefig() API
- matplotlib.pyplot.plot() API
- matplotlib.pyplot.bar() API
- matplotlib.pyplot.hist() API
- matplotlib.pyplot.boxplot() API
- matplotlib.pyplot.scatter() API
文章
总结
在本教程中,您了解了 Python 中数据可视化的入门知识。
具体来说,你学到了:
- 如何使用折线图绘制时间序列数据,使用条形图绘制分类数量。
- 如何使用直方图和箱线图汇总数据分布。
- 如何使用散点图汇总变量之间的关系。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。





")

尊敬的Jason博士,
我想对“plot”和“scatter”函数发表一些评论。
虽然您可以使用“plot”和“scatter”获得等效图表,例如
“plot”和“scatter”可能无法互换。例如
虽然散点图在绘图中有些相似之处,但仍然难以看到折线图。如果 y 值不是时间序列顺序,问题会变得更糟。以下示例对此进行了演示
谢谢你,
悉尼的Anthony
不错的例子。
您能确认一下语法是
import matplotlib import pyplot
或者
from matplotlib import pyplot
使用
谢谢,已更正拼写错误。
请多指导我一些关于如何理解相关矩阵的知识?哪些特征是正相关的,哪些是负相关的?如何从相关矩阵中选择特征?
如果您知道任何课程或资料,请与我分享。
谢谢。
好问题,或许从这里开始
https://machinelearning.org.cn/how-to-use-correlation-to-understand-the-relationship-between-variables/
嗨,Jason,
我非常感谢之前收到的良好反馈和回复。
我收集了一些包含 5-6 个特征的数据,并自己进行了标注。
我想使用随机森林进行监督学习。
拥有 200 个观测值或实例的数据集是否太小而无法进行训练?
请为小型数据集推荐一个好的机器学习算法。
此致,
Deepthi
也许可以。
也许可以开发一些模型,并评估模型对特定问题训练数据集大小的敏感程度。
我不清楚下面的代码
# x 轴的一致间隔
x = [x*0.1 for x in range(100)]
# y 轴的 x 函数
y = sin(x)
# 创建折线图
pyplot.plot(x, y)
您能推荐其他资源来弄清楚这一点吗?
给我一些关于在机器学习中开始数学研究的信息。
具体是哪一部分?列表?正弦函数?绘图?
嗨,Jason,
我非常感谢这有用的教程。
但是当我在一个包含 100 个样本的数据集上应用“散点图”命令时,所显示的图表只显示了 75 个点(以蓝色圆圈表示)。
这有什么问题吗?
我非常期待您的回复。
祝好
Maryam
我在这篇文章中给出了一个按类别对点进行着色的示例,这可能会有所帮助
https://machinelearning.org.cn/generate-test-datasets-python-scikit-learn/
这非常有启发性。我想多加练习会有助于我习惯它。感谢您分享您的知识。
谢谢,很高兴对您有帮助。
谢谢您!抱歉问一个如此基本的问题,但您在哪里运行这些 Python 脚本以显示可视化?我一直在命令行学习 Python 并使用 Visual Studio Code,但似乎没有地方可以查看可视化。
在命令行上,操作如下:
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
我们如何知道何时以及为何使用哪种可视化?
每种可视化都针对特定类型的数据或回答特定问题。
从您的数据和问题开始,然后相应地选择。