
战略性处理缺失数据:Pandas 和 Scikit-learn 中的高级插补技术。
作者 | Ideogram 提供图片
引言
在许多真实世界的数据集中,缺失值出现的频率比不出现更高。由于各种原因,例如人为错误、数据损坏或不完整的数据收集过程(例如来自带有可选字段的调查),一个或多个属性可能存在缺失值。虽然存在处理包含缺失值的实例或属性的基本策略——例如完全删除行或列,或用默认值(通常是属性的均值或中位数)插补缺失值——但这些策略有时并不足够。
本文介绍了一些处理缺失数据的高级策略,即通过结合使用 Python 中的 Pandas 和 Scikit-learn 库实现的插补技术。
使用合成员工数据集
为了演示根据具体背景和问题需求插补缺失值的一些高级策略,我们将使用我(!)人工创建的一个数据集,您可以轻松地从下面的代码中指定的 URL 加载该数据集
|
1 2 3 4 5 6 |
import pandas as pd url = 'https://raw.githubusercontent.com/gakudo-ai/open-datasets/refs/heads/main/employees_dataset_with_missing.csv' df = pd.read_csv(url) print(f"加载数据集形状: {df.shape}") print(f"每列缺失值数量:\n{df.isnull().sum()}") |
通过链式方程进行多重插补
迭代插补方法“通过链式方程进行多重插补”(MICE)使用各种估计器,如随机森林、贝叶斯岭等,来插补缺失值。默认情况下,使用贝叶斯岭回归方法,该方法将缺失值视为需要学习的参数。
|
1 2 3 4 5 6 7 8 9 10 |
iterative_imputer = IterativeImputer(random_state=42, max_iter=10) df_iterative = pd.DataFrame( iterative_imputer.fit_transform(df), columns=df.columns, index=df.index ) print("\n1. 迭代插补 (MICE):") print(f"完整数据集形状: {df_iterative.shape}") print(f"缺失值数量: {df_iterative.isnull().sum().sum()}") |
结果显示所有缺失值都已不复存在。它们都已被插补。
您可以指定要使用的估计器而不是贝叶斯岭,例如,随机森林回归器,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 |
rf_iterative_imputer = IterativeImputer( estimator=RandomForestRegressor(n_estimators=10, random_state=42), random_state=42, max_iter=5 ) df_rf_iterative = pd.DataFrame( rf_iterative_imputer.fit_transform(df), columns=df.columns, index=df.index ) df_rf_iterative.head() |
输出
K-最近邻插补
就像标准的 K-NN 算法一样,这种插补缺失值的方法利用样本之间的相似性来估计给定实例中的缺失值。同样可以使用加权相似度和自定义度量。
此示例将目标实例中“受影响”属性具有已知值的相邻实例数量设置为 K=5,并且每个邻居对该属性缺失值估计的贡献与该邻居和目标实例之间的距离成反比加权。
|
1 2 3 4 5 6 7 8 9 10 |
knn_imputer = KNNImputer(n_neighbors=5, weights='distance') df_knn = pd.DataFrame( knn_imputer.fit_transform(df), columns=df.columns, index=df.index ) print("\n2. KNN 插补:") print(f"使用 {knn_imputer.n_neighbors} 个最近邻") print(f"剩余缺失值: {df_knn.isnull().sum().sum()}") |
另一种方法可以通过设置 weights='uniform' 来应用,在这种情况下,所有选定的邻居(本例中为十个)在对每个待处理目标实例中的缺失值估计的贡献中具有相同的权重。
|
1 2 3 4 5 6 7 8 |
knn_uniform = KNNImputer(n_neighbors=10, weights='uniform') df_knn_uniform = pd.DataFrame( knn_uniform.fit_transform(df), columns=df.columns, index=df.index ) print(f"剩余缺失值: {df_knn_uniform.isnull().sum().sum()}") |
使用多个估计器进行插补(集成)
另一种策略是构建多种不同类型的插补估计器,每个估计器生成一个带有插补值的完整数据集的不同版本。然后,通过检查每个数据集并关注包含缺失值的最关键属性,我们可以根据哪个估计器(或哪些估计器)为特定数据上下文提供了最真实或最一致的插补来决定使用其中一个或另一个,甚至执行两个或更多个的聚合。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
imputers = { 'bayesian_ridge': IterativeImputer(estimator=BayesianRidge(), random_state=42), 'extra_trees': IterativeImputer(estimator=ExtraTreesRegressor(n_estimators=10, random_state=42), random_state=42), 'rf_regressor': IterativeImputer(estimator=RandomForestRegressor(n_estimators=10, random_state=42), random_state=42) } imputed_datasets = {} for name, imputer in imputers.items(): imputed_datasets[name] = pd.DataFrame( imputer.fit_transform(df), columns=df.columns, index=df.index ) print("\n3. 基于不同估计器的插补数据集版本:") for name, dataset in imputed_datasets.items(): print(f"{name}: 平均收入 = ${dataset['income'].mean():.2f}") |
总结
此表总结了所探讨的三种方法的主要特点,并建议了何时使用(或避免使用)每种方法。
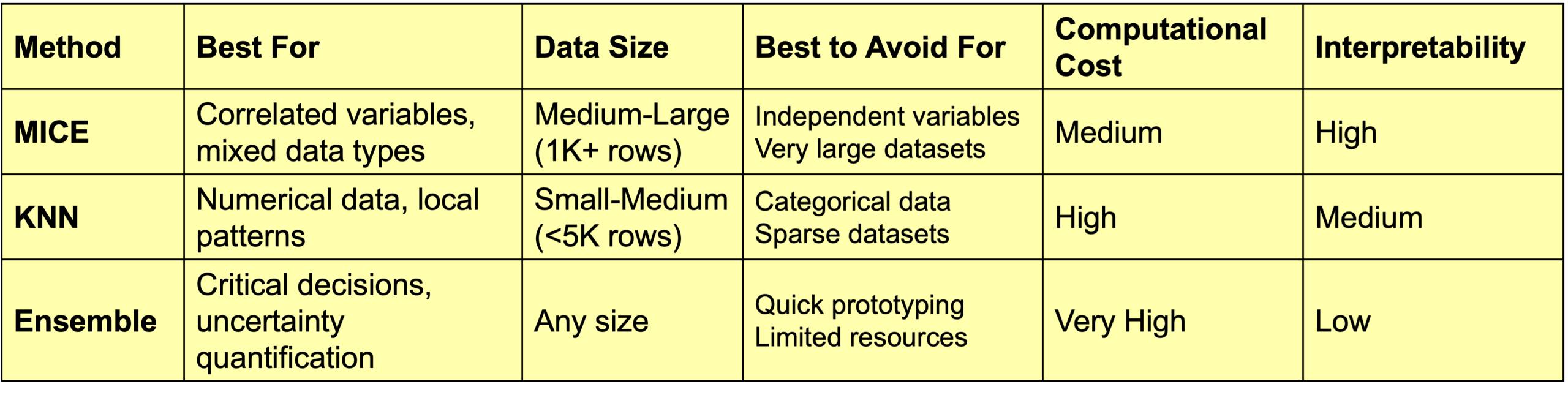
所探讨的三种插补方法的主要特点
总而言之,KNN 插补对于较小的数值数据集非常有效,因为它对于大型数据集来说计算成本很高。集成估计器往往提供最佳质量,但它们是最复杂且计算成本最高的方法,而 MICE 通常是一种平衡的方法,适用于各种场景。






暂无评论。