
决策树不仅仅用于表格数据
图片由 Editor | ChatGPT 提供
引言
决策树是一种通用、可解释且对各种用例都有效的技术,几十年来一直是成熟的机器学习技术之一,广泛用于分类和回归任务。而且,它们仍然被广泛使用——无论是作为独立模型,还是作为更强大的集成方法(如随机森林和梯度提升机)的组成部分。
它们还有另一个吸引人的特性,进一步拓展了其通用性的边界:除了完全结构化的表格数据之外,它们还可以适应各种格式的数据。本文将从理论和实践的平衡角度探讨决策树的这一方面。
决策树快速概览
决策树是一种用于预测任务(即分类和回归)的监督学习模型。它们在标记示例集上进行训练,也就是说,数据示例具有已知的预测输出,例如,一组收集的动物标本的属性以及每项观测所属的物种。树是逐渐构建的,与训练数据集被迭代地递归地划分为子集的过程并行,以寻求每个子集尽可能多的类别(或数值标签)同质性。一旦训练完成,模型就学习了一组分层的决策规则,这些规则应用于数据属性,并在视觉上表示为一棵树(见下图)。
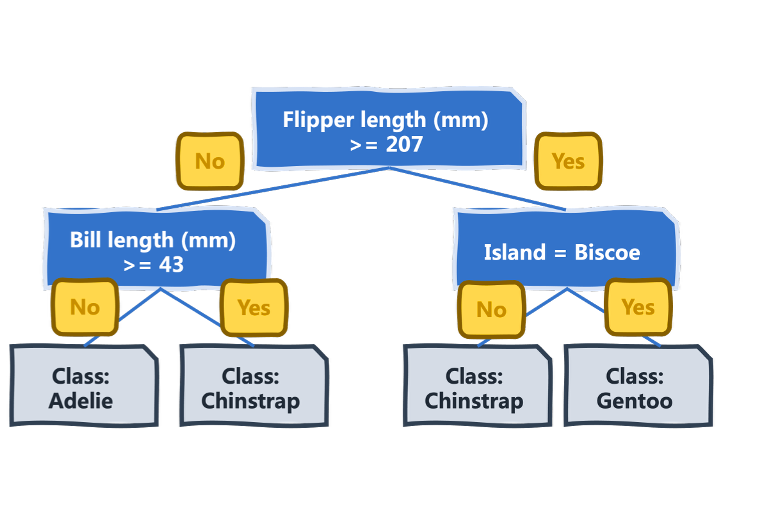
用于企鹅物种分类的决策树概览
作者提供图片
对于具有未知标签的示例应用推理来预测其标签,包括从上到下检查这些规则或条件,最终导向一个“叶节点”,指向该未知标签的类别或值预测,具体取决于问题是涉及分类还是回归。
决策树中的表格数据之外
结构化或表格数据,组织成由数值和分类属性(列)描述的实例(行),构成了大多数经典机器学习模型(包括决策树)使用的典型数据格式。然而,它们也可以适应不严格是表格的数据集或其一部分。
非表格数据的常见示例包括文本、图像和时间序列。通过应用适当的预处理技术,这些数据格式可以转换为更结构化的形式。例如,像客户产品评论这样的文本序列,可以通过特征提取或嵌入使其结构化,然后将其用作决策树分类器的输入,以分析客户评论背后的积极或消极情绪。
另一种利用决策树进行包含部分非结构化数据(例如,结合了表格属性和产品高分辨率图像的产品数据)的预测任务的策略是使用混合解决方案,将深度学习模型与决策树相结合。例如,考虑一个卷积神经网络(CNN),它被训练用于以结构化格式从图像中提取特征(推断大小、形状、颜色等属性),然后将这些基于图像的特征传递给像随机森林这样的基于树的模型,以计算预测,例如估计的产品销售额。
在研究领域,已经有直接将基于决策树的模型改编用于处理图数据和分层数据等非表格数据的努力,尽管其主流应用仍然很少见。
实际示例
为了以一种实际的方式结束,我们将说明如何在一组结合了纯表格数据和文本数据的数据集上训练一个基于决策树的模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.metrics import classification_report, confusion_matrix import seaborn as sns import matplotlib.pyplot as plt from scipy.sparse import hstack url = "https://raw.githubusercontent.com/gakudo-ai/open-datasets/refs/heads/main/customer_support_dataset.csv" df = pd.read_csv(url) df = df.dropna(subset=['prior_tickets', 'account_age_days', 'text', 'label']) text_vec = TfidfVectorizer(max_features=1000, ngram_range=(1, 2), stop_words='english') X_text = text_vec.fit_transform(df['text']) X_num = df[['prior_tickets', 'account_age_days']].values X = hstack([X_text, X_num]) le = LabelEncoder() y = le.fit_transform(df['label']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) clf = DecisionTreeClassifier(max_depth=6, random_state=42) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) y_test_labels = le.inverse_transform(y_test) y_pred_labels = le.inverse_transform(y_pred) print(classification_report(y_test_labels, y_pred_labels, zero_division=0)) cm = confusion_matrix(y_test_labels, y_pred_labels, labels=le.classes_) sns.heatmap(cm, annot=True, fmt='d', xticklabels=le.classes_, yticklabels=le.classes_, cmap='Blues') plt.xlabel('预测值') plt.ylabel('真实值') plt.title('混淆矩阵') plt.show() |
本质上,这段代码做了以下事情:
- 使用一个包含三个预测属性的数据集来描述客户支持工单。
- 其中一个是文本,在输入决策树模型之前需要进行预处理。
- 采用 TF-IDF 向量化器来获取每个文本的向量表示。
- 之后,将这个新特征与其他特征合并,以训练决策树分类器,并在测试集上对其进行评估。
您可能会执行此代码,并因其性能而感到失望(正确预测的次数与错误预测的次数大致相等)。这是符合预期的,因为我们使用的是一个只有 100 个实例的小型数据集,并且从文本表示中学习通常需要更多实例。
结论
本文讨论了决策树和像随机森林这样的基于决策树的机器学习模型处理非表格数据的能力。从文本到图像再到时间序列,机器学习模型和数据可以进行预处理或组合在一起,以适应许多人乍一看认为不可能处理的数据。






暂无评论。