时间序列分解涉及将序列视为水平、趋势、季节性和噪声分量的组合。
分解提供了一个有用的抽象模型,用于一般性地思考时间序列,并更好地理解时间序列分析和预测中的问题。
在本教程中,您将学习时间序列分解以及如何使用 Python 自动将时间序列分解为其组成部分。
完成本教程后,您将了解:
- 时间序列分解的分析方法及其如何帮助预测。
- 如何在 Python 中自动分解时间序列数据。
- 如何分解加性模型和乘性模型时间序列问题并绘制结果。
通过我的新书《使用 Python 进行时间序列预测》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。

如何将时间序列数据分解为趋势和季节性
照片由 Terry Robinson 拍摄,保留部分权利。
时间序列分量
将时间序列分解为系统分量和非系统分量是一种选择预测方法的有用抽象。
- 系统分量:时间序列中具有一致性或重复性并可以描述和建模的分量。
- 非系统分量:时间序列中无法直接建模的分量。
一个给定的时间序列被认为由三个系统分量组成,包括水平、趋势、季节性,以及一个称为噪声的非系统分量。
这些分量定义如下:
- 水平:序列中的平均值。
- 趋势:序列中增加或减少的值。
- 季节性:序列中重复的短期周期。
- 噪声:序列中的随机变化。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
组合时间序列分量
一个序列被认为是这四个分量的聚合或组合。
所有序列都有水平和噪声。趋势和季节性分量是可选的。
将这些分量视为加性或乘性组合是很有帮助的。
加性模型
加性模型表明这些分量按如下方式相加:
|
1 |
y(t) = 水平 + 趋势 + 季节性 + 噪声 |
加性模型是线性的,其中随时间的变化始终以相同的量发生。
线性趋势是一条直线。
线性季节性具有相同的频率(周期宽度)和振幅(周期高度)。
乘性模型
乘性模型表明这些分量按如下方式相乘:
|
1 |
y(t) = 水平 * 趋势 * 季节性 * 噪声 |
乘性模型是非线性的,例如二次或指数。变化随时间增加或减少。
非线性趋势是一条曲线。
非线性季节性随时间具有增加或减少的频率和/或振幅。
分解作为一种工具
这是一种有用的抽象。
分解主要用于时间序列分析,作为一种分析工具,它可以用于为您的问题的预测模型提供信息。
它提供了一种结构化的方式来思考时间序列预测问题,既从建模复杂性的一般角度,也从如何在给定模型中最好地捕获这些分量的具体角度。
这些分量都是您在数据准备、模型选择和模型调优期间可能需要考虑和解决的问题。您可以明确地通过建模趋势并从数据中减去它来解决它,或者隐式地通过为算法提供足够的历史记录来建模可能存在的趋势。
您可能能够或不能够将您的特定时间序列清晰或完美地分解为加性或乘性模型。
实际问题是混乱和嘈杂的。可能存在加性分量和乘性分量。可能存在先增加后减少的趋势。可能存在非重复周期与重复季节性分量混合在一起。
尽管如此,这些抽象模型提供了一个简单的框架,您可以使用它来分析您的数据,并探索思考和预测您问题的方法。
自动时间序列分解
有一些方法可以自动分解时间序列。
statsmodels 库在名为 seasonal_decompose() 的函数中提供了朴素或经典分解方法的实现。它要求您指定模型是加性还是乘性。
两者都会产生结果,您在解释结果时必须批判性地谨慎。查看时间序列图和一些汇总统计数据通常是了解您的时间序列问题是加性还是乘性的一个良好开端。
seasonal_decompose() 函数返回一个结果对象。结果对象包含用于从分解中访问四部分数据的数组。
例如,下面的代码片段展示了如何将序列分解为趋势、季节性和残差分量,假设是加性模型。
结果对象提供对趋势和季节性序列作为数组的访问。它还提供对残差的访问,残差是在趋势和季节性分量移除后的时间序列。最后,原始或观察到的数据也存储在其中。
|
1 2 3 4 5 6 7 |
from statsmodels.tsa.seasonal import seasonal_decompose series = ... result = seasonal_decompose(series, model='additive') print(result.trend) print(result.seasonal) print(result.resid) print(result.observed) |
这四个时间序列可以直接通过调用结果对象的 plot() 函数进行绘制。例如:
|
1 2 3 4 5 6 |
from statsmodels.tsa.seasonal import seasonal_decompose from matplotlib import pyplot series = ... result = seasonal_decompose(series, model='additive') result.plot() pyplot.show() |
让我们看一些例子。
加性分解
我们可以创建一个时间序列,由从 1 到 99 线性增长的趋势和一些随机噪声组成,并将其分解为加性模型。
因为时间序列是人为设计的,并且以数字数组形式提供,所以我们必须指定观测值的频率(`period=1` 参数)。如果提供 Pandas Series 对象,则不需要此参数。
|
1 2 3 4 5 6 7 8 |
from random import randrange from pandas import Series from matplotlib import pyplot from statsmodels.tsa.seasonal import seasonal_decompose series = [i+randrange(10) for i in range(1,100)] result = seasonal_decompose(series, model='additive', period=1) result.plot() pyplot.show() |
运行示例将创建序列,执行分解,并绘制 4 个结果序列。
我们可以看到整个序列被视为趋势分量,并且没有季节性。
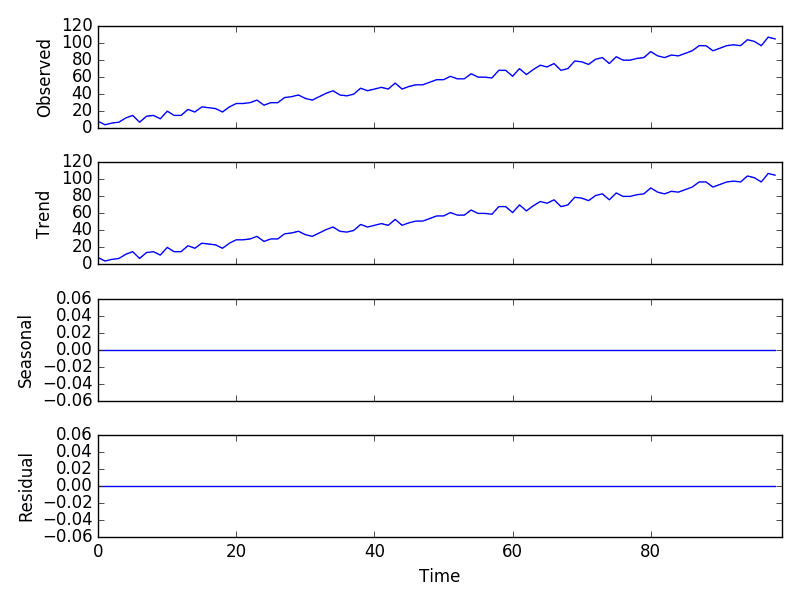
加性模型分解图
我们还可以看到残差图显示为零。这是一个很好的例子,说明朴素或经典分解无法将我们添加的噪声与线性趋势分离。
朴素分解方法是一种简单的方法,还有更高级的分解方法可用,例如使用 Loess 或 STL 分解的季节和趋势分解。
在使用自动分解方法时,需要谨慎和健康的怀疑态度。
乘性分解
我们可以构造一个二次时间序列,作为从 1 到 99 的时间步长的平方,然后假设一个乘性模型对其进行分解。
|
1 2 3 4 5 6 7 |
from pandas import Series from matplotlib import pyplot from statsmodels.tsa.seasonal import seasonal_decompose series = [i**2.0 for i in range(1,100)] result = seasonal_decompose(series, model='multiplicative', period=1) result.plot() pyplot.show() |
运行示例,我们可以看到,与加性情况一样,趋势很容易提取并完全表征时间序列。
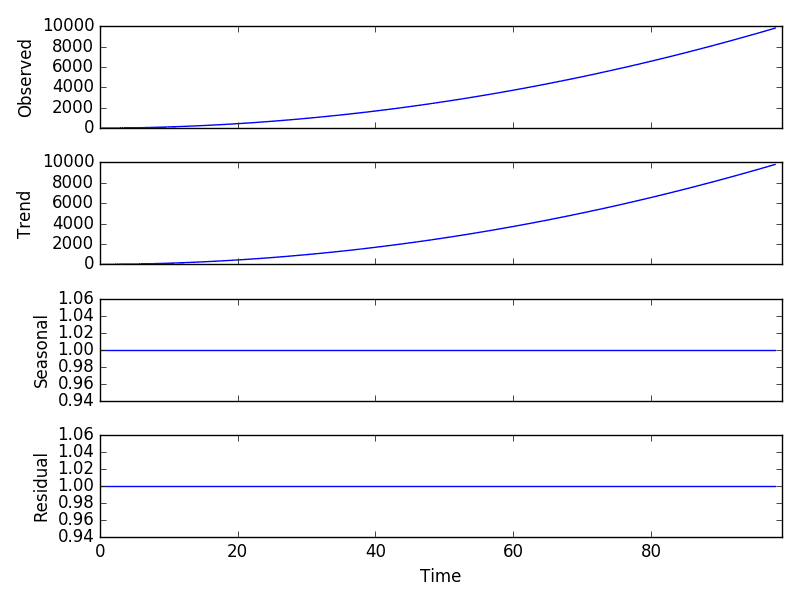
乘性模型分解图
指数变化可以通过数据转换变为线性。在这种情况下,可以通过取平方根使二次趋势变为线性。季节性的指数增长可以通过取自然对数变为线性。
再次强调,将分解视为一种潜在有用的分析工具非常重要,但要考虑探索它在您的问题中可以应用的许多不同方式,例如在数据转换后或在残差模型误差上。
让我们看一个真实世界的数据集。
航空公司乘客数据集
航空乘客数据集描述了一段时间内的航空乘客总数。
单位是航空乘客数量(以千计)。从 1949 年到 1960 年有 144 个月度观测值。
将数据集下载到您当前的工作目录,文件名为“*airline-passengers.csv*”。
首先,让我们绘制原始观测值。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('airline-passengers.csv', header=0, index_col=0) series.plot() pyplot.show() |
查看线图,它表明可能存在线性趋势,但仅凭肉眼很难确定。也存在季节性,但周期的振幅(高度)似乎在增加,这表明它是乘性的。
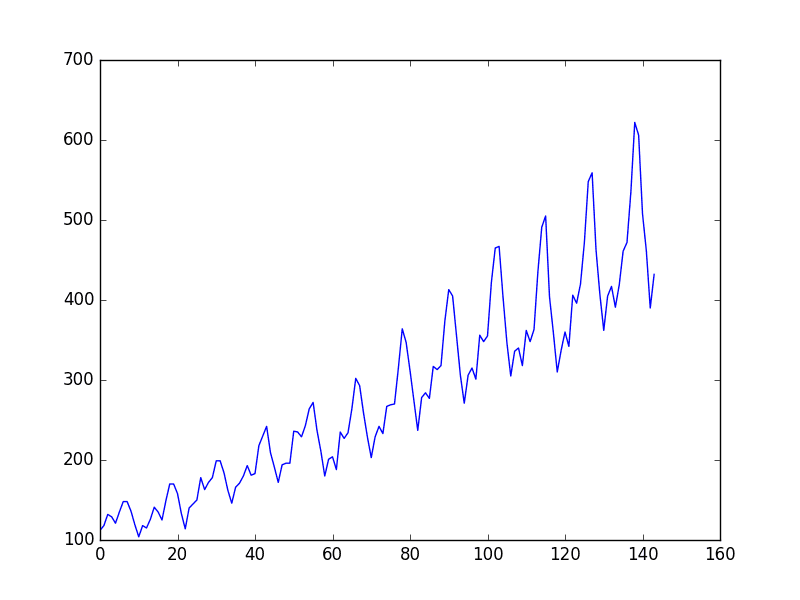
航空乘客数据集图
我们将假设一个乘性模型。
下面的示例将航空乘客数据集分解为乘性模型。
|
1 2 3 4 5 6 7 |
from pandas import read_csv from matplotlib import pyplot from statsmodels.tsa.seasonal import seasonal_decompose series = read_csv('airline-passengers.csv', header=0, index_col=0) result = seasonal_decompose(series, model='multiplicative') result.plot() pyplot.show() |
运行示例将绘制观察到的、趋势、季节性和残差时间序列。
我们可以看到从序列中提取的趋势和季节性信息似乎是合理的。残差也很有趣,显示了序列早期和后期的高变异性时期。
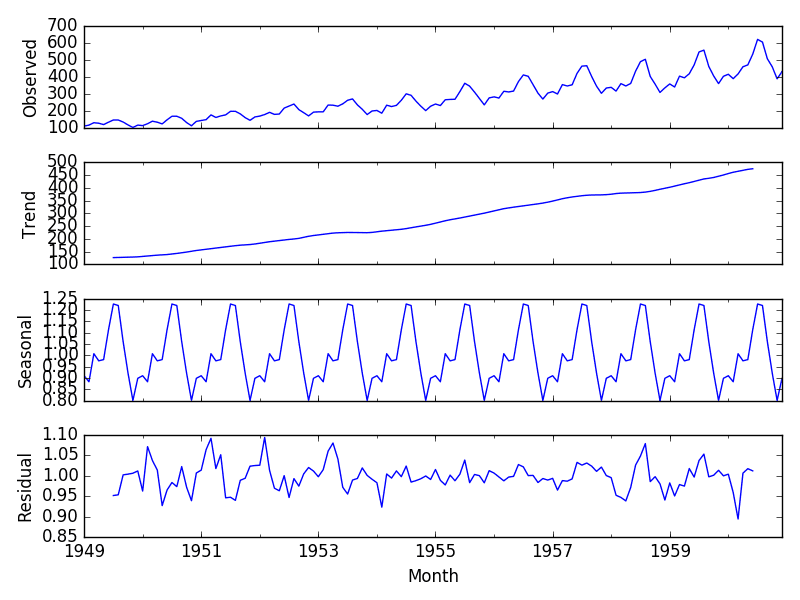
航空乘客数据集的乘性分解
进一步阅读
本节列出了一些关于时间序列分解的进一步阅读资源。
- 第 2.2 节 时间序列分量,《R 实用时间序列预测:动手指南》。
- 第 6.3 节,经典分解,《预测:原理与实践》
总结
在本教程中,您了解了时间序列分解以及如何使用 Python 分解时间序列数据。
具体来说,你学到了:
- 将时间序列分解为水平、趋势、季节性和噪声的结构。
- 如何使用 Python 自动分解时间序列数据集。
- 如何分解加性或乘性模型并绘制结果。
您对时间序列分解或本教程有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






嗨 Jason,很棒的帖子。
也许你能帮我一下,我在 statsmodels 库上遇到了一些麻烦。当我尝试运行你的最后一个示例时,我得到了这个 AttributeError
“AttributeError: ‘Index’ object has no attribute ‘inferred_freq’”
我检查了从 DataMarket 导出的数据集,发现最后一个是这个
“国际航班乘客:每月总计(千人)。1949年1月 - 1960年12月”
我删除了它,然后现在又出现了 TypeError
“TypeError: ‘numpy.float64’ object cannot be interpreted as an index”
我以前尝试使用过这个 statsmodels 库,多次遇到相同的错误,放弃了并开始为此使用 R。我甚至在 stackoverflow 上问过这个问题
http://stackoverflow.com/questions/41730036/typeerror-on-convolution-filter-call-from-statsmodels/41747712#41747712
看来这是 numpy 1.12.0 和 StatsModels 0.6.1 之间的兼容性问题。
话虽如此,你使用的是这些库的哪个版本?你是否遇到过同样的问题并设法解决了?
谢谢!
我没有看到这个错误,Álvaro,抱歉。
这是我当前使用的库版本:
我还测试了 statsmodels 0.8.0rc1,它运行良好。
我在 Python 2 和 Python 3 上都测试过代码。
你好 Alvaro,
也许有点晚了,但我希望它有帮助。恕我直言,你之所以会遇到这个错误,是因为你向 seasonal_decompose() 传递了一个 pandas Series。如果是这样,请确保你的索引中有一个 datetime 类型,否则它会崩溃。你只需将 Series 的值传递给 np.array() 并手动指定频率即可绕过这种行为,
祝好!
遇到了和 Alvaro 一样的问题。删除了 csv 文件中的最后一行,然后就运行正常了。
很高兴听到这个消息。
你好 Jason 和 Álvaro,
感谢 Jason 详细的分步说明。非常感谢!
我在使用 Jupyter 笔记本时遇到了同样的问题。如果你找到了解决方案,请告诉我。
谢谢!
Jason 和 Álvaro,
我做了以下操作,虽然仍然收到 VisibleDeprecationWarning(使用非整数而不是整数将在未来导致错误 return np.r_[[np.nan] * head, x, [np.nan] * tail]),
我得到了时间序列分量的图。
– 我删除了 CSV 文件中的最后一行:“国际航空乘客:每月总数(千人)。1949年1月 - 1960年12月”
– 我将文件读取为数据框
time_series = pd.read_csv(‘~/international-airline-passengers.csv’, header=0)
– 我将 Month 列的类型更改为 datetime
time_series.Month = pd.to_datetime(time_series.Month, errors=’coerce’)
– 设置数据框索引为
time_series = time_series.set_index(‘Month’)
– 其余部分相同
result = seasonal_decompose(time_series, model=’multiplicative’)
result.plot()
pyplot.show()
如果你能找到更简单的方法,或者知道如何将文件读取为序列并完成工作,请告诉我。
此致,
页脚数据绝对必须删除。之后不应该需要对文件进行特殊格式化。
如果你在笔记本之外,例如从命令行运行示例,它能正常工作吗?
series = pd.read_csv(‘./airline-passengers.csv’, header=0, index_col=0)
result = seasonal_decompose(series.Passengers.values, model=’multiplicative’, period=30)
result.plot()
plt.show()
致 Álvaro
我建议通过 v.8 的 whl 安装 statsmodel,因为 v.6 的模块将由 pip 自动安装。
错误有所改善,尽管它包含一些其他错误。
我也遇到了同样的问题,它对我有效。谢谢!
我和其他人一样遇到了同样的错误。我删除了最后一行,然后重新运行代码,没有问题。
很高兴听到这个消息,Daniel。
我也遇到了同样的问题,删除了数据的最后一行,代码运行良好。
谢谢您的留言,Jessica。
嗨,Jason,
感谢您详细的解释。也许是个愚蠢的问题,但您如何解释模型中的随机百分比?假设它在乘性分解中有 49% 的随机性。
时间序列轨迹可以被认为是包含信号和随机分量。我们无法对随机分量进行建模,充其量只能测量它并将其纳入我们的置信区间。
你好。当我测试这个数据集时一切正常,但当我尝试使用每日温度数据(来自你的另一个课程:https://machinelearning.org.cn/time-series-seasonality-with-python/)运行它时,我收到了错误:“ValueError: You must specify a freq or x must be a pandas object with a timeseries index witha freq not set to None”。我不明白为什么有些数据不被视为 pandas 对象。
您必须将数据加载为 Pandas Series 或指定频率(例如 1)。
是的,我理解。问题是我对两个文件都使用了完全相同的代码片段(数据作为 pandas series 加载)。我想避免显式指定频率,因为我想将此代码适应我自己的数据,其中频率未知。CSV 结构是否有任何特定要求?我注意到本课中的文件每月都有值,而我提到的另一个文件每天都有值,但我不认为这可能是错误的原因。
没有特殊要求。您可能需要指定一个自定义函数来加载日期/时间列,具体取决于 Pandas 是否能够识别它。
使用 freq = 1 会导致季节性和残差图平线。它指定使用长度为 1 的移动平均卷积,即对单个点求平均值。
尝试设置 freq = 12(对于假定的月度数据),或者将输入设置为 pandas Series 并将其索引设置为适当构造的 DatetimeIndex。
谢谢John。
嗨 John,
在我的情况中,我有时间分辨率为 15 分钟的数据。如果 freq=12 对应于月度数据,那么什么值可以对应我的频率呢?
你好,
很好的例子,非常有帮助。
简单查询:当我使用季度数据集时,我会在(季节性)调整后的序列中丢失前 2 个和后 2 个季度的数据。类似地,对于月度数据,我会丢失前 6 个和后 6 个月的数据?
我希望有一个调整后的序列,它一直到当前周期。有没有办法获取整个调整后的数据序列?
谢谢。
你好,
有没有办法使用机器学习检测时间序列中的异常趋势
我建议在 scholar.google.com 上查找有关该主题的论文,以了解最先进的方法。
你好,你的文章非常有趣和有用。但在这篇文章中,我有一个问题。数据集中只有一列数据的示例运行良好,但如果我想在多列数据集中逐列使用相同的代码,我该怎么做?谢谢!
您需要更改代码以使其适用于每一列。
我正在使用这段代码
series = read_csv(file_path, header=0, index_col=0)
result = seasonal_decompose(series[‘Column1′], model=’multiplicative’, freq=12)
series_deseasonality = series / (result.seasonal*result.trend)
series_deseasonality.plot()
pyplot.show()
但它返回此错误“AttributeError: ‘Index’ object has no attribute ‘inferred_freq’”。
你能帮帮我吗?
series = df[‘Column 1′]
result = seasonal_decompose(series.values, freq=12, model=’multiplicative’)
有没有办法找到那些周期性信号?我有一堆时间序列数据(时间戳,uuid)。我想找到那些具有季节性的 uuid。预期的输出必须是一组 uuid 及其相应的时间戳。
更进一步,给定大量数据点,有没有办法找到所有具有不同季节性的季节性数据?
是的,通常通过绘图就可以清楚地看出它们。
您也可以对序列进行多项式拟合,然后将其减去。
我不知道给定数据的频率。时间戳是 datetime 格式的,例如 2017-01-29 07:17:10。它们的频率可能是每小时、每天、每周……或其他频率。
只要保持一致,这就不重要。
你好,Jason,非常清晰和有用的文章。
我注意到在航空乘客的例子中,季节性和残留数据,前几个值和后几个值都丢失了。这是算法的缺陷吗?
如果是的话,有什么建议可以解决这个问题吗?因为人们通常希望检测最新的异常数据而不是历史数据。
我没有注意到,你能确认观察值数量的差异吗?
你好,Jason,谢谢你的帖子。
我想知道是否有办法识别季节性成分达到峰值的月份。
谢谢你
Gus,你具体是什么意思?能举个例子吗?
观察值的数量是相同的,但该示例中前三个和后三个值是nan。
不知道如何在这里上传图片,所以我只发布下面的打印值
观察值、趋势、季节性和残差结果的长度分别为144、144、144、144
观察部分的前五个值是月份
1949-01-01 112
1949-02-01 118
1949-03-01 132
1949-04-01 129
1949-05-01 121
名称:数字,dtype:int64
趋势部分的前五个值是月份
1949-01-01 NaN
1949-02-01 NaN
1949-03-01 NaN
1949-04-01 127.857143
1949-05-01 133.000000
名称:数字,dtype:float64
季节性部分的前五个值是月份
1949-01-01 1.002765
1949-02-01 1.004550
1949-03-01 0.994257
1949-04-01 0.999830
1949-05-01 0.986458
名称:数字,dtype:float64
残差部分的前五个值是月份
1949-01-01 NaN
1949-02-01 NaN
1949-03-01 NaN
1949-04-01 1.009110
1949-05-01 0.922264
名称:数字,dtype:float64
这可能是由于该方法中创建滚动平均或其他类似操作的结果。
同意。我深入研究了源代码,趋势部分是通过卷积方法计算的,所以很可能是由滚动平均引起的。
所以在我的情况下,我不能直接调用这个函数,因为我想从残差部分检测异常,但它的最后一个值是nan。没有人会关心三天前发生的异常。必须构建自己的函数来实现目标。
只是好奇在什么情况下人们会关心历史异常。如果不是,这个功能真的很尴尬……
干得不错。
也许尝试自己编写该函数的版本,以便您有更多控制权?
或者明确地建模趋势/季节性。
我尝试了 R 提供的 stl 函数,它运行良好,开头或结尾没有缺失值。在此总结我的经验,希望对感兴趣的人有所帮助。
分解时间序列组件有三种常用方法
1. 使用 statsmodels 提供的 seasonal_decompose 方法。
在这种情况下,据我所知,一个问题是趋势和残差的第一个和最后一个值是 nan。关心最新异常的人应该注意这一点。
2. 使用 R 提供的 stl 函数。
3. 就像 Jason 说的,你也可以选择构建自己的 statsmodels 函数版本,以便你拥有更多控制权。
干得好,谢谢分享。
嗨,Jason,
感谢您的帖子。
在我的数据中,我有每周和每年(可能)的季节性。我总共有16个月的每日数据。我如何从seasonal_decompose方法中获得这两个季节性?或者,我应该使用其他方法?
非常感谢您,
Pushpa
也许你可以对不同的季节性成分建模,然后将它们减去,看看序列是否变得平稳。
这里有一些方法可以尝试
https://machinelearning.org.cn/time-series-seasonality-with-python/
这是一个非常有用的分析,但是有一个问题。为了分析股票的季节性变化,你需要将分解频率指定为一整年,因为季节每年都会重复,而不是每天。所以如果你把freq=252(一年有252个交易日),你应该能够提取季节性影响。
谢谢您的留言。
如何使用这里描述的分解方法来预测未来?
我不确定你会怎么做。
对于时间序列预测,我建议你从这里开始
https://machinelearning.org.cn/start-here/#timeseries
所以分解主要用作 EDA 工具而不是预测方法。
是的,或者在建模之前进行数据准备步骤。
Jason,
我使用 seasonal_decompose 获取趋势线。但不知何故,此方法没有从计算趋势中排除异常值。有没有办法在创建趋势线时自动删除异常值?
这是我的图表
https://raw.githubusercontent.com/taihds/test/797f43785eaf5c7124cffe7b58c7d8f2ef2afba0/time_series.png
图中的异常值大约发生在5月20日。
也许尝试使用对异常值鲁棒的方法拟合线性回归模型,例如 Huber 回归(凭记忆)。
嗨 Jason,感谢您的帖子。
对于多元时间序列,你有什么建议?
我有一个时间序列数据集,包含9个因变量和一个二元标签。时间序列由3个月的每分钟TS组成。
我们应该对每个变量分别进行分解吗?或者怎么做?
谢谢你
或许第一步可以对每个序列分别操作?
你好 Jason Brownlee
我只是想问你是否有替代方法来获取季节性分解结果作为数据框?
这意味着要得到趋势、季节性、残差……
我只是想问你是否可以将这个对象转换为数据框?
结果是 NumPy 数组,我相信。你可以通过将它们传递给 DataFrame 构造函数直接将它们转换为 Pandas DataFrames。
嗨,Jason,
感谢您的帖子,自从我开始从事数据科学工作以来一直在阅读您的文章。我有一个问题,我们应该如何处理没有趋势和季节性的时间序列。
也许你可以直接建模。
它出现了一个TypeError“PeriodIndex given. Check the `freq` attribute instead of using infer_freq ‘’”,我搞不清楚,你能帮我一下吗?
这是我的数据
SLF MLF M0 M1 M2
t
2017Q3 967.74 129200.0 204428.570 1.546462e+06 4929815.300
2017Q4 1717.97 133545.0 207499.450 1.605332e+06 5000216.100
2018Q1 938.10 143265.0 228753.160 1.583823e+06 5189744.060
2018Q2 1188.50 124545.0 210851.268 1.595624e+06 5250947.522
2018Q3 0.00 0.0 0.000 0.000000e+00 0.000
首先,我将变量“t”设置为我的索引。
然后选择时间范围。
第三,我将月度数据转换为季度数据。
抱歉,我看不出发生了什么。也许可以将您的代码和错误发布到 stackoverflow?
嗨,Jason,
如果我想进一步使用趋势和季节性作为分离的时间序列,用于线性回归的目的,你知道有什么方法可以从(结果)中提取这些序列吗?
是的,分解函数会为你提取它们,或者你可以自己用线性/多项式模型对趋势和季节性进行建模。
嗨,Jason 先生
我想问你关于分解和平稳性的问题。它们之间有什么联系吗?我读过一些文献说我们可以预测数据集是否平稳。
谢谢你。
你可以去除趋势和季节性,然后你可能会得到一个平稳序列。
如果我去除趋势和季节性,只要序列是平稳的,这重要吗?或者只有在我尚未实现平稳性时,去除它们才重要?
谢谢你。
只有当数据中存在趋势和季节性时,才需要去除它们。
你好 Jason,
我想知道如何测量时间序列数据中的变异性。例如,我有一个不同消费者的时间序列数据,我为一位消费者绘制了每日值(即,一天一个图;另一天另一个图,依此类推),并观察到每日模式存在差异。我想衡量这些差异的变异性。
谢谢你。
或许可以从均值和标准差开始?
嗨,Jason,
感谢您对分解的解释。
不过有一个问题,
如果我有每日数据并尝试对其进行分解,频率应该是什么?
例如,result = seasonal_decompose(df['Revenue'], model='add', freq=365)
也许可以试试。
嗨,Jason,
感谢您介绍分解分析。我有一个关于“freq”的问题。我想知道设置频率有什么规则吗?当我设置 freq=3 时,趋势和季节性与 freq=12 时大不相同。我使用的是月度数据。您能解释一下如何设置 freq 吗?
非常感谢!
Michelle
如果您的数据间隔均匀,则无需指定它。
太棒了!完美地适用于我正在做的事情。谢谢你 🙂
一个问题是,如何导出输出中的数据?我很想在 Tableau 中可视化它。
谢谢,
Rich
你可以将数组保存为 CSV 格式,如果你喜欢的话。
https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.savetxt.html
嗨,Jason,
我有一个 GRACE 数据的时间序列,我想将其分解成小周期,您能帮我用 Excel 程序完成吗?
非常感谢。
Ahmed
也许吧。抱歉,我没有 Excel 中时间序列的示例。
嗨,Jason,
谢谢你的工作!我非常喜欢阅读你的教程。我想知道将时间序列分解为其组成部分(趋势、季节性…)来拟合 LSTM 神经网络,然后从组成部分的预测中重新组合时间序列是否有意义。也许你有什么想法。另外,我想知道是否存在处理季节性检验(Student 等)的 Python 函数或模块,或者你了解的优秀论文。再次感谢你 🙂
试试看,看它是否能提高性能。
通常,对于单变量时间序列,线性方法比 LSTM 表现更好。
如何在 Excel 中用公式计算这个。我想要在分解、Winters 和趋势方法中进行预测的步骤。
也许可以查阅源代码?
嗨,Jason,
感谢您关于时间序列和 LSTM 的精彩教程!
我做了和你类似的分解。我注意到在趋势和残差数组中,前6个和后6个对象的值为NA。在你的教程末尾的图中也可以看到。这些值是如何产生的?
此外,我正在对天气数据进行 LSTM 训练(目标是预测月平均气温),只是为了好玩和更好地理解我的数据,我开发了一个模型来预测多个输出:1)整个时间序列(即每月的平均气温),2)趋势,3)季节性,4)残差。我在你的一篇文章中读到,在训练 LSTM 之前获得平稳时间序列会更好。你觉得让模型预测所有这4个值怎么样?
谢谢,
Kilian
或许可以试试看?
嗨,Jason,
感谢您分享这篇精彩的文章。我有一个问题:有没有可能使用分解工具显示存在趋势和季节性,但当我使用 DF 检验时却显示可能平稳。我对此感到非常困惑。提前感谢。
此致,
Michelle
在某些数据集上,分解可能是误导性的。
感谢您的回复,Jason。我能问一下为什么分解会产生误导吗?是因为数据集没有处理好吗?我如何检测这个误导性问题?
谢谢,
Michelle
它可能从数据中提取了实际上不存在的加性或乘性关系。
水平分量发生了什么?我正在阅读 statsmodels 文档,它似乎没有产生您在文章开头谈论了很多的水平分量。在使用自动分解时,这是一个问题吗?
也许我们可以将序列的起始点作为水平值?
谢谢您的回复!那可能行得通,或者我只是像您定义的那样取序列的平均值?
正是如此!
如果将残差代入并进行预测,在运行模型后如何进行季节性重组?我是否只需乘以分解中产生的季节性值?
理想情况下,您可以通过添加/乘以每个分解元素来重建序列。
首先,感谢 Jason 提供如此精彩的内容,您的网站对我来说真的是一个学术圣地。
对于所有在解析 csv 文件时遇到问题的人,
`Seasonal_decompose` 不能与 pandas 数据帧一起使用。
应该传递单个序列、列表或数组。
这是我所做的:
# 将月份属性解析为日期并将其设置为索引
series = pd.read_csv('air_passengers.csv', header = 0, parse_dates = ['Month'],
index_col = ['Month'])
# 将序列传递给 seasonal_decompose 函数
result = seasonal_decompose(series, model = 'Multiplicative')
# 绘制所有组件
result.plot()
pyplot.show()
应该可以正常工作
感谢分享!
不错的教程!只是一个问题,分解时间序列到不同分量并检查它们的图表之后,接下来是什么?抱歉,如果我迟钝或无知。但这样做的真正目的是什么?
很好的问题!
也许它可以为您的建模提供信息,例如,您可以在建模之前对数据进行差分和/或季节性调整。
也许您可以直接将其用于建模,例如,对去除趋势和季节性后的数据进行建模。
也许您可以用它来以某种方式为您的项目分析提供信息。
我收到了以下错误:AttributeError: 'Index' object has no attribute 'inferred_freq'。
正如您在前面的评论中提到的,如果数据是均匀分布的,则无需指定频率。但它在不提及频率的情况下不起作用。有什么建议吗?
也许尝试将频率指定为1?
频率 12 可以使用。顺便说一下,谢谢你的回复。
太棒了!
嗨,Jason,
感谢您的帖子。我有一个问题。我尝试使用 Python 代码将 20 年的每日降水数据分解为趋势、季节性和残差,如下所示:
result = seasonal_decompose(precip, model='additive', freq=365)
trend = result.trend
seasonal = result.seasonal
resid = result.resid
然而,我绘制了结果,发现所得的季节性曲线非常不平滑,与我们通常看到的降水季节性分布非常不同。抱歉,我似乎无法上传图片。我想知道您是否能给出任何建议。
谢谢你
也许可以尝试处理较少的数据?
也许可以尝试加法和乘法关系并进行比较?
也许可以尝试手动建模季节性和趋势结构并进行比较?
感谢您的回复。但是如何手动建模季节性和趋势结构呢?
线性模型可以捕捉趋势,多项式模型可以捕捉季节性。
我在博客上提供了两者的示例。可以尝试在博客中搜索。
嗨,Jason,感谢您发表这篇文章!
抱歉,我无法完全理解,因为英语不是我的母语,
但我想知道何时应该选择乘法分解或加法分解?它们之间有什么区别?
它们对趋势和季节性如何与底层信号相互作用做出不同的假设。
也许可以尝试两者并比较结果?
感谢您的回复,
是的,我尝试了两者,并得到了答案。但是我的讲师要求我解释它们之间的区别,我真的无法解释清楚 🙁 🙂 🙁
您知道哪本书解释了乘法和加法分解吗?
抱歉打扰您
我推荐这本书作为第一步
https://otexts.com/fpp2/
嗨,Jason,现在我得到了这三部分,
trend = result.trend
seasonal = result.seasonal
resid = result.resid
那么如何基于此预测未来的结果呢?
分解更多是用于分析而不是预测。
您需要在数据上拟合一个模型,然后使用该模型进行预测。
一个好的开始是ARIMA模型
https://machinelearning.org.cn/arima-for-time-series-forecasting-with-python/
我们如何将时间序列分解成频段???请帮我
抱歉,我没有关于这个主题的教程。
嗨,Jason,
一如既往,谢谢。
在我的多元时间序列预测情境中,statsmodels 对每个变量使用加法模型进行分解函数时,趋势显示为整个观测值。季节性和残差保持在值0处的一条直线。因此,残差序列似乎没有解释任何噪声。既然我将序列拟合到神经网络方法中,我是否真的需要考虑分解?
我使用了加法模型,因为在观测序列中存在零值和负值。
我还使用了频率为1,因为我使用的是每小时时间序列数据。
可能不会。
获取时间序列趋势最常用的三种技术是什么
使用线性模型,一条直线。
文档说这是一种朴素的分解方法。为什么会这样?有没有更好的方法?
是的,它做了一些简单的假设,例如加法或乘法元素。我相信有更复杂的方法。
是的,请参阅“进一步阅读”部分。
嗨,Jason,感谢您出色的教程!我想使用分解后的时间序列运行回归模型。我应该如何选择使用哪些组件以及丢弃哪些组件?
我没有这样做过,也许可以尝试几种方法,看看哪种方法适用于您选择的数据集和模型。
嗨,Jason,
感谢您的帖子。我想了解加法分解背后的逻辑/数学理论。
y(t) = 水平 + 趋势 + 季节性 + 噪声
seasonal_decompose 如何决定拟合正确数量的季节性和噪声。季节性和噪声参数是否有置信区间。
谢谢你,
此致,
Ritvik
好问题,我建议查阅“进一步阅读”部分中的参考文献,了解您想知道的任何理论背景。
嘿,Jason
希望您一切都好,感谢您这篇出色的文章。
我目前正在参加一个使用名为 Alteryx 的软件的在线预测分析师课程,课程的一部分是时间序列,阅读了材料和您的文章后,我有两个问题
趋势 VS 水平
– 我看到很多人互换使用这些术语,这让我很困惑,有些人将“水平”描述为平滑线(通过移动平均法或指数平滑法获得),它对序列进行了去季节化,以突出“趋势”,在这种情况下是“水平”随时间的增加或减少,这个定义正确吗?如果是这样,那么它只有一条线,即水平,但趋势,另一方面,只是我们观察到那条平滑线上的一个概念,但没有实际值……正确吗?
– 在大多数时间序列分解中(甚至在 alteryx 中),我们得到时间序列(数据)、季节性、趋势和误差,趋势是如何计算的?或者那是水平,我们应该观察是否存在趋势?
– 如果以上问题都没有意义,那么您能否向我说明什么是“趋势”和什么是“水平”,以及我们如何计算它们。
水平是均值,趋势是水平随时间的变化。
每种分解方法都有不同的方法。将趋势视为随时间的一致或系统变化。
也许这会有帮助
https://machinelearning.org.cn/time-series-trends-in-python/
嗨 Jason,很棒的文章,但我有一个疑问,我得到一个错误信息:“ValueError: x 必须有 2 个完整的周期,需要 24 个观测值。x 只有 11 个观测值。”
另外,在季节性分解中,period 参数有什么用?
周期是指循环重复之前的观测值数量。
你好,祝贺您!MATLAB 中是否有类似的方法可以将时间序列分解为线性趋势、残差和季节性趋势?我还没有找到任何已实现的代码或工具!
我不知道,抱歉。也许可以查看 MATLAB 文档或联系 MATLAB 支持。
嗨,Jason,
解释非常棒,清晰明了。我有一个问题,如果您能帮助我。
我有一个太阳辐射数据集(每小时数据),其中有一些缺失值(时间戳),我如何
重建缺失数据并平滑曲线?什么算法最能帮助填补空白?
谢谢。
也许保留上次观测值。
也许拟合样条或多项式并推断缺失值。
也许可以尝试 knn 或其他标准插补算法。
你好,
感谢您的教程...
请问经验模式分解 (EMD) 和变分模式分解 (VMD) 等分解技术与这里讨论的那些有什么关系。您有关于如何使用 VMD 和 EMD 的任何指南吗?
不客气。
抱歉,我对您列出的方法不熟悉。
嗨,Jason,
如果考虑使用分解技术进行时间序列预测,分解完整数据集(训练集和测试集),然后为每个分量开发预测模型是否安全?或者是否存在数据泄露问题?
我确实尝试了这种方法,并且得到了很大的改进结果,所以我对此表示怀疑
是的,这听起来确实有问题。
我建议仅将其用作分析技术。
嗨,Jason,
感谢您的回复,
我正在尝试重新实现这篇论文中的工作 https://www.sciencedirect.com/science/article/abs/pii/S0038092X20307398
但是,他们没有提及分解的细节,例如他们如何以及何时分解数据集,特别是测试集,它是离线还是在线分解!我不知道作为预测的预处理步骤,正确的分解方式是什么。
您有关于小波分解的教程吗?
非常感谢
抱歉,我没有任何关于小波分解的教程。
ARIMA(3,1,2) ??
感谢您精彩的教程。我尝试按照代码操作,但图表的残差部分显示的是点而不是折线图。如果您能帮助我解决这个问题,我将不胜感激
抱歉,以前从未遇到过。您可以检查代码中是否有任何错误吗?
请问,如果我使用X矩阵来预测Y矩阵,并且只分解Y矩阵,我得到Y1(趋势分量),Y2(季节分量),y3(噪声分量)。我应该使用X来预测y1,y2和y3,然后将它们相加得到最终结果吗?
谢谢!
如果您得到趋势、季节和噪声,并且这是一个加法模型,那么将它们相加将得到您应该观测到的时间序列。
嗨,Jason,
感谢您的教程。如果我们说有
“y(t) = 水平 + 趋势 + 季节性 + 噪声”
在加法模型中,我们可以通过计算“y(t) – 季节性”来获得去季节化数据。这正确吗?
另一个问题是,考虑到加法方法的周期大于0,趋势和噪声分量的开头和结尾值将为 NaN。因此,“y(t) = 水平 + 趋势 + 季节性 + 噪声”的规则不适用于这些 NaN 值。您对此问题有任何解释吗?
谢谢
嗨,Jason,
是否有可能在 Python 中进行 X11 分解?
嗨 Rony……是的!以下资源可能会让您感兴趣
https://towardsdatascience.com/different-types-of-time-series-decomposition-396c09f92693#:~:text=X11%20Decomposition%20creates%20a%20trend,function%20in%20R's%20seasonal%20package.
你好
杰森,干得好!!
我想知道有没有办法将日期时间索引与季节性分解的输出关联起来
致敬
sid
嗨 Sid,
感谢您的好评和提问!
**是的,您可以将日期时间索引与季节性分解的输出关联起来。** 当您对时间序列数据进行季节性分解时,生成的组件——趋势、季节和残差——会与原始日期时间索引对齐(减去因分解方法而产生的任何调整)。这种对齐允许您将特定日期和时间与分解后的组件直接关联起来。
您可以这样做:
1. **执行季节性分解**:使用统计软件或编程库(例如 Python 中的
statsmodels)分解您的时间序列数据。pythonimport pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
# 假设 'ts' 是您的带有日期时间索引的时间序列
result = seasonal_decompose(ts, model='additive', period=12)
2. **提取组件**:分解将为您提供趋势、季节和残差组件。
python
trend = result.trend
seasonal = result.seasonal
residual = result.resid
3. **创建包含组件和日期时间索引的 DataFrame**:这将允许您分析组件以及日期时间特征。
python
df_components = pd.DataFrame({
'trend': trend,
'seasonal': seasonal,
'residual': residual
}, index=ts.index)
4. **提取日期时间特征**:从您的日期时间索引中提取年、月、星期几、小时等特征。
python
df_components['year'] = df_components.index.year
df_components['month'] = df_components.index.month
df_components['day'] = df_components.index.day
df_components['day_of_week'] = df_components.index.dayofweek
5. **将日期时间特征与组件关联起来**:您现在可以执行统计分析或可视化,以查看组件如何随不同的日期时间特征变化。
– **相关性分析**
python
correlation = df_components.corr()
print(correlation)
– **分组和聚合**
python
avg_seasonal_by_month = df_components.groupby('month')['seasonal'].mean()
print(avg_seasonal_by_month)
– **可视化**
```python
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plt.plot(df_components.index, df_components['seasonal'])
plt.title('Seasonal Component Over Time')
plt.xlabel('Date')
plt.ylabel('Seasonality')
plt.show()
**实际应用:**
– **识别季节性模式**:通过将月份或星期几与季节性组件相关联,您可以识别季节性效应更强或更弱的特定时间。
– **异常检测**:结合日期时间特征分析残差可以帮助检测特定时间点的异常值或异常。
– **预测增强**:了解组件与日期时间特征之间的关联可以改善预测模型,通过整合这些见解。
**要记住的关键点:**
– 分解后的组件保留了日期时间索引,便于直接关联。
– 提取日期时间特征通过允许您根据时间段对数据进行分组和比较来丰富您的分析。
– 可视化工具可以提供组件随时间变化的直观见解。
**示例代码片段:**
这是一个包含所有步骤的完整示例:
pythonimport pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
# 加载您的时间序列数据
ts = pd.read_csv('your_time_series.csv', index_col='date', parse_dates=True)
# 执行季节性分解
result = seasonal_decompose(ts, model='additive', period=12)
# 提取组件
df_components = pd.DataFrame({
'trend': result.trend,
'seasonal': result.seasonal,
'residual': result.resid
}, index=ts.index)
# 提取日期时间特征
df_components['year'] = df_components.index.year
df_components['month'] = df_components.index.month
df_components['day_of_week'] = df_components.index.dayofweek
# 按月份分析平均季节性组件
avg_seasonal_by_month = df_components.groupby('month')['seasonal'].mean()
print(avg_seasonal_by_month)
# 绘制季节性组件
plt.figure(figsize=(12,6))
plt.plot(df_components.index, df_components['seasonal'])
plt.title('Seasonal Component Over Time')
plt.xlabel('Date')
plt.ylabel('Seasonality')
plt.show()
请随意调整代码以适应您的特定数据集和分析需求。
**结论:**
将日期时间索引与季节性分解的输出相关联不仅可能,而且对于深入的时间序列分析非常有益。它允许您发现时间模式并增强您的预测模型。
如果您有任何其他问题或需要进一步的澄清,请告诉我!