电影评论可以分为褒义或贬义。
电影评论文本的评估是一个分类问题,通常称为情感分析。开发情感分析模型的一种流行技术是使用词袋模型,该模型将文档转换为向量,其中文档中的每个词都被分配一个分数。
在本教程中,您将学习如何使用词袋表示法开发一个深度学习预测模型,用于电影评论情感分类。
完成本教程后,您将了解:
- 如何准备用于受限词汇建模的评论文本数据。
- 如何使用词袋模型准备训练和测试数据。
- 如何开发一个多层感知器词袋模型,并使用它对新的评论文本数据进行预测。
通过我的新书《自然语言处理深度学习》来启动您的项目,其中包括逐步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2017 年 10 月更新:修复了加载和命名褒义和贬义评论时的一个小错误(感谢 Arthur)。
- 2020 年 8 月更新:更新了电影评论数据集的链接。

如何开发用于预测电影评论情感的深度学习词袋模型
照片由 jai Mansson 拍摄,保留部分权利。
教程概述
本教程分为4个部分,它们是:
- 电影评论数据集
- 数据准备
- 词袋表示
- 情感分析模型
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
电影评论数据集
电影评论数据是 Bo Pang 和 Lillian Lee 在 2000 年代初期从 imdb.com 网站检索的电影评论集合。这些评论是作为他们自然语言处理研究的一部分而收集和提供的。
这些评论最初于 2002 年发布,但更新和清理后的版本于 2004 年发布,称为“v2.0”。
该数据集包含 1,000 条褒义和 1,000 条贬义电影评论,这些评论均摘自 imdb.com 上托管的 rec.arts.movies.reviews 新闻组档案。作者将此数据集称为“极性数据集”。
我们的数据包含 1000 条褒义和 1000 条贬义评论,所有评论均在 2002 年之前撰写,每个作者(共 312 位作者)每个类别最多 20 条评论。我们将此语料库称为极性数据集。
—— 《情感教育:基于最小割的主观性摘要情感分析》,2004 年。
数据已经过一些清理,例如
- 数据集仅包含英文评论。
- 所有文本都已转换为小写。
- 标点符号(如句号、逗号和括号)周围有空格。
- 文本已分成每行一句。
这些数据已用于一些相关的自然语言处理任务。对于分类,经典模型(如支持向量机)在该数据上的性能范围在 70% 到 80% 之间(例如 78%-82%)。
更复杂的数据准备可能会通过 10 折交叉验证获得高达 86% 的结果。这给了我们一个大概的范围,如果我们要将此数据集用于现代方法的实验,其结果将在 80 年代中低水平。
...根据下游极性分类器的选择,我们可以实现高度统计学意义的改进(从 82.8% 提高到 86.4%)
—— 《情感教育:基于最小割的主观性摘要情感分析》,2004 年。
您可以从此处下载数据集
- 电影评论极性数据集 (review_polarity.tar.gz, 3MB)
解压缩文件后,您将看到一个名为“txt_sentoken”的目录,其中包含两个子目录,分别包含贬义评论和褒义评论的文本“neg”和“pos”。评论存储在单独的文件中,命名约定为每个 neg 和 pos 的 cv000 到 cv999。
接下来,我们来看看如何加载和准备文本数据。
数据准备
在本节中,我们将探讨 3 件事
- 将数据分为训练集和测试集。
- 加载并清理数据以去除标点符号和数字。
- 定义首选词汇表。
拆分为训练集和测试集
我们假装正在开发一个系统,可以预测电影评论文本的情感是褒义还是贬义。
这意味着模型开发完成后,我们需要对新的文本评论进行预测。这将需要对这些新评论执行与模型训练数据相同的全部数据准备。
我们将通过在任何数据准备之前将训练和测试数据集进行拆分,来确保此约束内置于我们模型的评估中。这意味着测试集中任何可能有助于我们更好地准备数据(例如使用的词汇)的知识在数据准备和模型训练期间都不可用。
话虽如此,我们将使用最后 100 条褒义评论和最后 100 条贬义评论作为测试集(200 条评论),其余 1,800 条评论作为训练数据集。
这是 90% 训练,10% 拆分的数据。
通过使用评论的文件名可以轻松实现这种拆分,其中名为 000 到 899 的评论用于训练数据,名为 900 及以后的评论用于测试模型。
加载和清理评论
文本数据已经相当干净,所以不需要太多准备工作。
我们不会过多地深入细节,我们将使用以下方法准备数据
- 按空格分割标记。
- 从单词中删除所有标点符号。
- 删除所有不纯粹由字母字符组成的单词。
- 删除所有已知停用词。
- 删除所有长度小于等于 1 个字符的单词。
我们可以将所有这些步骤放入一个名为 clean_doc() 的函数中,该函数接受从文件加载的原始文本作为参数,并返回一个清理后的标记列表。我们还可以定义一个名为 load_doc() 的函数,该函数从文件加载文档,以便与 clean_doc() 函数一起使用。
下面列出了清理第一条褒义评论的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from nltk.corpus import stopwords import string # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', string.punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档 filename = 'txt_sentoken/pos/cv000_29590.txt' text = load_doc(filename) tokens = clean_doc(text) print(tokens) |
运行示例会打印出一长串干净的标记。
我们可能还想探索更多清理步骤,我将它们留作进一步练习。我很想看看你能想出什么。
|
1 2 |
... ['creepy', 'place', 'even', 'acting', 'hell', 'solid', 'dreamy', 'depp', 'turning', 'typically', 'strong', 'performance', 'deftly', 'handling', 'british', 'accent', 'ians', 'holm', 'joe', 'goulds', 'secret', 'richardson', 'dalmatians', 'log', 'great', 'supporting', 'roles', 'big', 'surprise', 'graham', 'cringed', 'first', 'time', 'opened', 'mouth', 'imagining', 'attempt', 'irish', 'accent', 'actually', 'wasnt', 'half', 'bad', 'film', 'however', 'good', 'strong', 'violencegore', 'sexuality', 'language', 'drug', 'content'] |
定义词汇表
在使用词袋模型时,定义一个已知词汇表很重要。
词汇量越多,文档的表示就越大,因此将词汇限制在那些被认为具有预测性的词汇中很重要。这在事前很难知道,通常测试不同的假设以构建有用的词汇表很重要。
我们已经在上一节中看到了如何从词汇表中去除标点符号和数字。我们可以对所有文档重复此操作,并构建一个所有已知单词的集合。
我们可以将词汇表开发为计数器,它是一个单词及其计数的字典映射,允许我们轻松更新和查询。
每个文档都可以添加到计数器中(一个名为 add_doc_to_vocab() 的新函数),我们可以遍历负面目录中的所有评论,然后是正面目录(一个名为 process_docs() 的新函数)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
from string import punctuation from os import listdir from collections import Counter from nltk.corpus import stopwords # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档并添加到词汇表 def add_doc_to_vocab(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 更新计数 vocab.update(tokens) # 加载目录中的所有文档 def process_docs(directory, vocab): # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 将文档添加到词汇表 add_doc_to_vocab(path, vocab) # 定义词汇表 vocab = Counter() # 将所有文档添加到词汇表 process_docs('txt_sentoken/pos', vocab) process_docs('txt_sentoken/neg', vocab) # 打印词汇表大小 print(len(vocab)) # 打印词汇表中最重要的词 print(vocab.most_common(50)) |
运行示例表明我们有一个包含 44,276 个单词的词汇表。
我们还可以看到电影评论中最常用的前 50 个单词的样本。
请注意,此词汇表是根据训练数据集中的那些评论构建的。
|
1 2 |
44276 [('film', 7983), ('one', 4946), ('movie', 4826), ('like', 3201), ('even', 2262), ('good', 2080), ('time', 2041), ('story', 1907), ('films', 1873), ('would', 1844), ('much', 1824), ('also', 1757), ('characters', 1735), ('get', 1724), ('character', 1703), ('two', 1643), ('first', 1588), ('see', 1557), ('way', 1515), ('well', 1511), ('make', 1418), ('really', 1407), ('little', 1351), ('life', 1334), ('plot', 1288), ('people', 1269), ('could', 1248), ('bad', 1248), ('scene', 1241), ('movies', 1238), ('never', 1201), ('best', 1179), ('new', 1140), ('scenes', 1135), ('man', 1131), ('many', 1130), ('doesnt', 1118), ('know', 1092), ('dont', 1086), ('hes', 1024), ('great', 1014), ('another', 992), ('action', 985), ('love', 977), ('us', 967), ('go', 952), ('director', 948), ('end', 946), ('something', 945), ('still', 936)] |
我们可以遍历词汇表,并删除所有出现次数较少的单词,例如在所有评论中只使用过一次或两次的单词。
例如,以下代码片段将仅检索在所有评论中出现 2 次或更多次的标记。
|
1 2 3 4 |
# 保留出现次数最少的标记 min_occurane = 2 tokens = [k for k,c in vocab.items() if c >= min_occurane] print(len(tokens)) |
运行上述示例并添加此功能后,词汇量减少了一半以上,从 44,276 个词减少到 25,767 个词。
|
1 |
25767 |
最后,词汇表可以保存到一个名为 vocab.txt 的新文件中,我们稍后可以加载该文件并用它来过滤电影评论,然后再对它们进行编码以进行建模。我们定义了一个名为 save_list() 的新函数,该函数将词汇表保存到文件中,每个词一行。
例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 将列表保存到文件 def save_list(lines, filename): # 将行转换为单个文本块 data = '\n'.join(lines) # 打开文件 file = open(filename, 'w') # 写入文本 file = file.write(data) # 关闭文件 file.close() # 将标记保存到词汇表文件 save_list(tokens, 'vocab.txt') |
运行词汇表上的最小出现过滤器并将其保存到文件后,您现在应该有一个名为 vocab.txt 的新文件,其中只包含我们感兴趣的单词。
文件中单词的顺序会有所不同,但应该看起来像以下内容
|
1 2 3 4 5 6 7 8 9 10 11 |
阿伯丁 骗子 伯特 性欲 哈姆雷特 阿琳 可用 角落 网页 哥伦比亚 ... |
我们现在准备从评论中提取特征以进行建模。
词袋表示
在本节中,我们将介绍如何将每条评论转换为可提供给多层感知器模型的表示形式。
词袋模型是一种从文本中提取特征的方法,以便文本输入可以与神经网络等机器学习算法一起使用。
每个文档(在这种情况下是评论)都被转换为向量表示。表示文档的向量中的项目数量对应于词汇表中的单词数量。词汇量越大,向量表示越长,因此上一节中更倾向于使用较小的词汇表。
文档中的单词被评分,分数放置在表示中相应的位置。我们将在下一节中介绍不同的单词评分方法。
在本节中,我们关注将评论转换为向量,以便训练第一个神经网络模型。
本节分为 2 个步骤
- 将评论转换为标记行。
- 使用词袋模型表示对评论进行编码。
评论到标记行
在我们能够将评论转换为用于建模的向量之前,我们必须首先对其进行清理。
这包括加载它们,执行上面开发的清理操作,过滤掉不在所选词汇表中的词,并将剩余的标记转换为一个准备好进行编码的单个字符串或行。
首先,我们需要一个函数来准备一个文档。下面列出了函数 doc_to_line(),它将加载文档,清理它,过滤掉词汇表中没有的标记,然后将文档作为以空格分隔的标记字符串返回。
|
1 2 3 4 5 6 7 8 9 |
# 加载文档,清理并返回标记行 def doc_to_line(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] return ' '.join(tokens) |
接下来,我们需要一个函数来处理目录中(例如“pos”和“neg”)的所有文档,将文档转换为行。
下面列出了 process_docs() 函数,它正是这样做的,它接受目录名和词汇表集作为输入参数,并返回一个已处理文档的列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 加载目录中的所有文档 def process_docs(directory, vocab): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines |
最后,我们需要加载词汇表并将其转换为一个集合,以便在清理评论时使用。
|
1 2 3 4 5 |
# 加载词汇表 vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = vocab.split() vocab = set(vocab) |
我们可以将所有这些结合起来,重用之前章节中开发的加载和清理函数。
下面的完整示例展示了如何准备训练数据集中的正面和负面评论。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
from string import punctuation from os import listdir from collections import Counter from nltk.corpus import stopwords # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档,清理并返回标记行 def doc_to_line(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] return ' '.join(tokens) # 加载目录中的所有文档 def process_docs(directory, vocab): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines # 加载词汇表 vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = vocab.split() vocab = set(vocab) # 加载所有训练评论 positive_lines = process_docs('txt_sentoken/pos', vocab) negative_lines = process_docs('txt_sentoken/neg', vocab) # 总结我们所拥有的 print(len(positive_lines), len(negative_lines)) |
电影评论到词袋向量
我们将使用 Keras API 将评论转换为编码文档向量。
Keras 提供了 Tokenizer 类,可以完成我们在上一节中处理的一些清理和词汇表定义任务。
最好自己完成这些工作,以便确切知道做了什么以及为什么。尽管如此,Tokenizer 类方便易用,可以轻松地将文档转换为编码向量。
首先,必须创建 Tokenizer,然后将其拟合到训练数据集中的文本文档上。
在这种情况下,它们是上一节中开发的 positive_lines 和 negative_lines 数组的聚合。
|
1 2 3 4 5 |
# 创建分词器 tokenizer = Tokenizer() # 在文档上拟合分词器 docs = positive_lines + negative_lines tokenizer.fit_on_texts(docs) |
此过程确定了一种一致的方式,将词汇表转换为具有 25,768 个元素的固定长度向量,这是词汇表文件 vocab.txt 中单词的总数。
接下来,可以使用 Tokenizer 通过调用 texts_to_matrix() 对文档进行编码。该函数接受要编码的文档列表和编码模式,后者是用于对文档中的单词进行评分的方法。这里我们指定“freq”根据单词在文档中的频率进行评分。
这可以用于编码训练数据,例如
|
1 2 3 |
# 编码训练数据集 Xtrain = tokenizer.texts_to_matrix(docs, mode='freq') print(Xtrain.shape) |
这将对训练数据集中的所有褒义和贬义评论进行编码,并打印出结果矩阵的形状,即 1,800 个文档,每个文档的长度为 25,768 个元素。它已准备好用作模型的训练数据。
|
1 |
(1800, 25768) |
我们可以用类似的方式编码测试数据。
首先,需要修改上一节中的 process_docs() 函数,使其仅处理测试数据集中的评论,而不是训练数据集中的评论。
我们通过添加 is_trian 参数并使用它来决定要跳过哪些评论文件名来支持加载训练集和测试集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 加载目录中的所有文档 def process_docs(directory, vocab, is_trian): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if is_trian and filename.startswith('cv9'): continue if not is_trian and not filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines |
接下来,我们可以像处理训练集一样加载和编码测试集中的褒义和贬义评论。
|
1 2 3 4 5 6 7 8 |
... # 加载所有测试评论 positive_lines = process_docs('txt_sentoken/pos', vocab, False) negative_lines = process_docs('txt_sentoken/neg', vocab, False) docs = negative_lines + positive_lines # 编码训练数据集 Xtest = tokenizer.texts_to_matrix(docs, mode='freq') print(Xtest.shape) |
我们可以将所有这些放在一个示例中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
from string import punctuation from os import listdir from collections import Counter from nltk.corpus import stopwords from keras.preprocessing.text import Tokenizer # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档,清理并返回标记行 def doc_to_line(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] return ' '.join(tokens) # 加载目录中的所有文档 def process_docs(directory, vocab, is_trian): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if is_trian and filename.startswith('cv9'): continue if not is_trian and not filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines # 加载词汇表 vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = vocab.split() vocab = set(vocab) # 加载所有训练评论 positive_lines = process_docs('txt_sentoken/pos', vocab, True) negative_lines = process_docs('txt_sentoken/neg', vocab, True) # 创建分词器 tokenizer = Tokenizer() # 在文档上拟合分词器 docs = negative_lines + positive_lines tokenizer.fit_on_texts(docs) # 编码训练数据集 Xtrain = tokenizer.texts_to_matrix(docs, mode='freq') print(Xtrain.shape) # 加载所有测试评论 positive_lines = process_docs('txt_sentoken/pos', vocab, False) negative_lines = process_docs('txt_sentoken/neg', vocab, False) docs = negative_lines + positive_lines # 编码训练数据集 Xtest = tokenizer.texts_to_matrix(docs, mode='freq') print(Xtest.shape) |
运行示例会打印出编码训练数据集和测试数据集的形状,分别为 1,800 个和 200 个文档,每个文档都具有相同大小的编码词汇表(向量长度)。
|
1 2 |
(1800, 25768) (200, 25768) |
情感分析模型
在本节中,我们将开发多层感知器 (MLP) 模型来将编码文档分类为褒义或贬义。
这些模型将是简单的前馈网络模型,在 Keras 深度学习库中称为 Dense 的全连接层。
本节分为 3 个部分
- 第一个情感分析模型
- 比较单词评分模式
- 对新评论进行预测
第一个情感分析模型
我们可以开发一个简单的 MLP 模型来预测编码评论的情感。
该模型将有一个输入层,其大小等于词汇表中的单词数量,也等于输入文档的长度。
我们可以将其存储在一个名为 n_words 的新变量中,如下所示
|
1 |
n_words = Xtest.shape[1] |
我们还需要所有训练和测试评论数据的类别标签。我们确定性地加载并编码了这些评论(先负面,再正面),因此我们可以直接指定标签,如下所示
|
1 2 |
ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)]) ytest = array([0 for _ in range(100)] + [1 for _ in range(100)]) |
我们现在可以定义网络了。
所有的模型配置都是通过很少的试错发现的,不应被视为针对此问题进行了调整。
我们将使用一个具有 50 个神经元和一个修正线性激活函数的单隐藏层。输出层是一个具有 Sigmoid 激活函数的单个神经元,用于预测负面评论为 0,正面评论为 1。
该网络将使用高效的Adam 梯度下降实现和二元交叉熵损失函数进行训练,适用于二元分类问题。我们将在训练和评估模型时跟踪准确率。
|
1 2 3 4 5 6 |
# 定义网络 model = Sequential() model.add(Dense(50, input_shape=(n_words,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译网络 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
接下来,我们可以在训练数据上拟合模型;在这种情况下,模型很小,很容易在 50 个 epoch 中拟合。
|
1 2 |
# 拟合网络 model.fit(Xtrain, ytrain, epochs=50, verbose=2) |
最后,模型训练完成后,我们可以通过在测试数据集上进行预测并打印准确率来评估其性能。
|
1 2 3 |
# 评估 loss, acc = model.evaluate(Xtest, ytest, verbose=0) print('Test Accuracy: %f' % (acc*100)) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
from numpy import array from string import punctuation from os import listdir from collections import Counter from nltk.corpus import stopwords from keras.preprocessing.text import Tokenizer from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档,清理并返回标记行 def doc_to_line(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] return ' '.join(tokens) # 加载目录中的所有文档 def process_docs(directory, vocab, is_trian): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if is_trian and filename.startswith('cv9'): continue if not is_trian and not filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines # 加载词汇表 vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = vocab.split() vocab = set(vocab) # 加载所有训练评论 positive_lines = process_docs('txt_sentoken/pos', vocab, True) negative_lines = process_docs('txt_sentoken/neg', vocab, True) # 创建分词器 tokenizer = Tokenizer() # 在文档上拟合分词器 docs = negative_lines + positive_lines tokenizer.fit_on_texts(docs) # 编码训练数据集 Xtrain = tokenizer.texts_to_matrix(docs, mode='freq') ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)]) # 加载所有测试评论 positive_lines = process_docs('txt_sentoken/pos', vocab, False) negative_lines = process_docs('txt_sentoken/neg', vocab, False) docs = negative_lines + positive_lines # 编码训练数据集 Xtest = tokenizer.texts_to_matrix(docs, mode='freq') ytest = array([0 for _ in range(100)] + [1 for _ in range(100)]) n_words = Xtest.shape[1] # 定义网络 model = Sequential() model.add(Dense(50, input_shape=(n_words,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译网络 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合网络 model.fit(Xtrain, ytrain, epochs=50, verbose=2) # 评估 loss, acc = model.evaluate(Xtest, ytest, verbose=0) print('Test Accuracy: %f' % (acc*100)) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
运行示例,我们可以看到模型在 50 个 epoch 内轻松拟合训练数据,达到 100% 的准确率。
在测试数据集上评估模型,我们可以看到模型表现良好,准确率超过 90%,远高于原始论文中 80 年代中低水平的范围。
尽管如此,需要注意的是,这并非苹果与苹果的比较,因为原始论文使用 10 折交叉验证来估计模型技能,而不是单一的训练/测试分割。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... 第 46/50 轮 0s - 损失:0.0167 - 准确率:1.0000 第 47/50 轮 0s - 损失:0.0157 - 准确率:1.0000 第 48/50 轮 0s - 损失:0.0148 - 准确率:1.0000 第 49/50 轮 0s - 损失:0.0140 - 准确率:1.0000 第 50/50 轮 0s - 损失:0.0132 - 准确率:1.0000 测试准确率:91.000000 |
接下来,我们来看看词袋模型中不同的词评分方法。
比较词评分方法
Keras API 中 Tokenizer 的 texts_to_matrix() 函数提供了 4 种不同的词评分方法;它们是
- “binary”:词汇出现(1)或不出现(0)。
- “count”:每个词的出现次数以整数表示。
- “tfidf”:每个词根据其频率进行评分,在所有文档中常见的词会受到惩罚。
- “freq”:词汇根据其在文档中的出现频率进行评分。
我们可以评估上一节中开发的模型在每种支持的词评分模式下拟合的技能。
这首先涉及开发一个函数,该函数根据选定的评分模型创建已加载文档的编码。该函数创建分词器,在训练文档上拟合它,然后使用选定的模型创建训练和测试编码。函数 prepare_data() 实现了此行为,给定训练和测试文档列表。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 准备文档的词袋编码 def prepare_data(train_docs, test_docs, mode): # 创建分词器 tokenizer = Tokenizer() # 在文档上拟合分词器 tokenizer.fit_on_texts(train_docs) # 编码训练数据集 Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode) # 编码训练数据集 Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode) return Xtrain, Xtest |
我们还需要一个函数来评估给定数据特定编码的 MLP。
由于神经网络是随机的,当在相同数据上拟合相同模型时,它们可能会产生不同的结果。这主要是因为随机初始权重和迷你批次梯度下降期间模式的混洗。这意味着模型的任何一次评分都是不可靠的,我们应该根据多次运行的平均值来估计模型技能。
下面的函数,名为 evaluate_mode(),接受编码文档,并通过在训练集上训练 MLP 并在测试集上估计技能 30 次来评估 MLP,并返回所有这些运行的准确率分数列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 评估神经网络模型 def evaluate_mode(Xtrain, ytrain, Xtest, ytest): scores = list() n_repeats = 30 n_words = Xtest.shape[1] for i in range(n_repeats): # 定义网络 model = Sequential() model.add(Dense(50, input_shape=(n_words,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译网络 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合网络 model.fit(Xtrain, ytrain, epochs=50, verbose=2) # 评估 loss, acc = model.evaluate(Xtest, ytest, verbose=0) scores.append(acc) print('%d accuracy: %s' % ((i+1), acc)) return scores |
我们现在准备评估 4 种不同词评分方法的性能。
将所有这些整合在一起,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
from numpy import array from string import punctuation from os import listdir from collections import Counter from nltk.corpus import stopwords from keras.preprocessing.text import Tokenizer from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 Dropout from pandas import DataFrame from matplotlib import pyplot # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 file = open(filename, 'r') # 读取所有文本 text = file.read() # 关闭文件 file.close() return text # 将文档转换为干净的令牌 def clean_doc(doc): # 按空格分割成标记 tokens = doc.split() # 从每个标记中删除标点符号 table = str.maketrans('', '', punctuation) tokens = [w.translate(table) for w in tokens] # 删除所有非字母字符的标记 tokens = [word for word in tokens if word.isalpha()] # 过滤停用词 stop_words = set(stopwords.words('english')) tokens = [w for w in tokens if not w in stop_words] # 过滤短标记 tokens = [word for word in tokens if len(word) > 1] return tokens # 加载文档,清理并返回标记行 def doc_to_line(filename, vocab): # 加载文档 doc = load_doc(filename) # 清理文档 tokens = clean_doc(doc) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] return ' '.join(tokens) # 加载目录中的所有文档 def process_docs(directory, vocab, is_trian): lines = list() # 遍历文件夹中的所有文件 for filename in listdir(directory): # 跳过测试集中的任何评论 if is_trian and filename.startswith('cv9'): continue if not is_trian and not filename.startswith('cv9'): continue # 创建要打开的文件的完整路径 path = directory + '/' + filename # 加载并清理文档 line = doc_to_line(path, vocab) # 添加到列表 lines.append(line) return lines # 评估神经网络模型 def evaluate_mode(Xtrain, ytrain, Xtest, ytest): scores = list() n_repeats = 30 n_words = Xtest.shape[1] for i in range(n_repeats): # 定义网络 model = Sequential() model.add(Dense(50, input_shape=(n_words,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译网络 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合网络 model.fit(Xtrain, ytrain, epochs=50, verbose=2) # 评估 loss, acc = model.evaluate(Xtest, ytest, verbose=0) scores.append(acc) print('%d accuracy: %s' % ((i+1), acc)) 返回 分数 # 准备文档的词袋编码 def prepare_data(train_docs, test_docs, mode): # 创建分词器 tokenizer = Tokenizer() # 在文档上拟合分词器 tokenizer.fit_on_texts(train_docs) # 编码训练数据集 Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode) # 编码训练数据集 Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode) return Xtrain, Xtest # 加载词汇表 vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = vocab.split() vocab = set(vocab) # 加载所有训练评论 positive_lines = process_docs('txt_sentoken/pos', vocab, True) negative_lines = process_docs('txt_sentoken/neg', vocab, True) train_docs = negative_lines + positive_lines # 加载所有测试评论 positive_lines = process_docs('txt_sentoken/pos', vocab, False) negative_lines = process_docs('txt_sentoken/neg', vocab, False) test_docs = negative_lines + positive_lines # 准备标签 ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)]) ytest = array([0 for _ in range(100)] + [1 for _ in range(100)]) modes = ['binary', 'count', 'tfidf', 'freq'] results = DataFrame() for mode in modes: # 为模式准备数据 Xtrain, Xtest = prepare_data(train_docs, test_docs, mode) # 评估模式数据上的模型 results[mode] = evaluate_mode(Xtrain, ytrain, Xtest, ytest) # 总结结果 print(results.describe()) # 绘制结果 results.boxplot() pyplot.show() |
运行该示例可能需要一些时间(在配备CPU而非GPU的现代硬件上大约需要一个小时)。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
运行结束时,将提供每种单词评分方法的汇总统计数据,总结了每种模式下30次运行中模型技能得分的分布。
我们可以看到,“freq”和“binary”方法的平均得分似乎优于“count”和“tfidf”。
|
1 2 3 4 5 6 7 8 9 |
binary count tfidf freq count 30.000000 30.00000 30.000000 30.000000 mean 0.915833 0.88900 0.856333 0.908167 std 0.009010 0.01012 0.013126 0.002451 min 0.900000 0.86500 0.830000 0.905000 25% 0.906250 0.88500 0.850000 0.905000 50% 0.915000 0.89000 0.857500 0.910000 75% 0.920000 0.89500 0.865000 0.910000 max 0.935000 0.90500 0.885000 0.910000 |
还展示了结果的箱线图,总结了每种配置的准确度分布。
我们可以看到,“freq”配置的分布很紧凑,考虑到它的性能也很好,这令人鼓舞。此外,我们可以看到“binary”以适度的分布取得了最好的结果,并且可能是此数据集的首选方法。
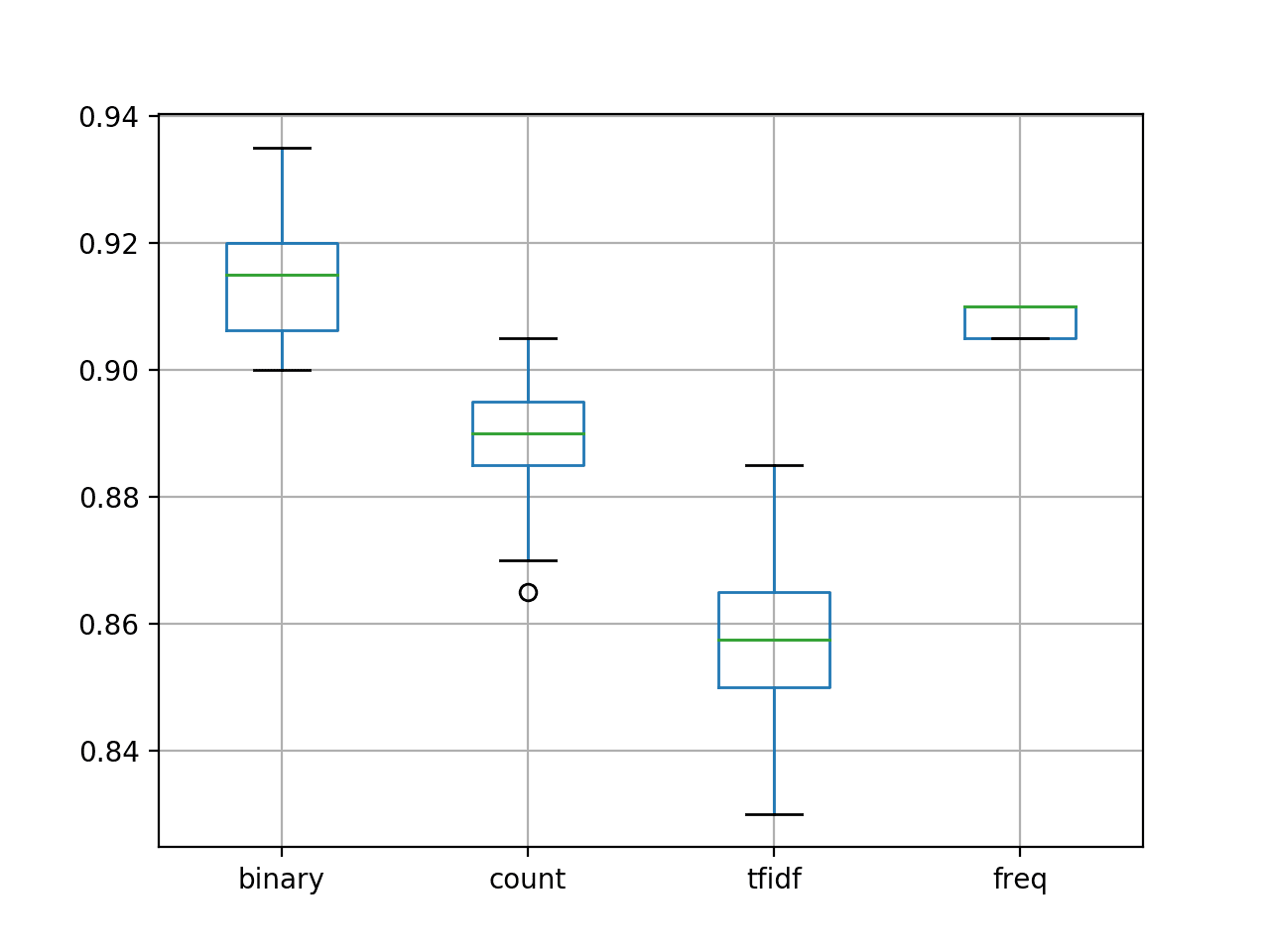
使用不同单词评分方法的模型准确度箱线图
对新评论进行预测
最后,我们可以使用最终模型对新的文本评论进行预测。
这就是我们最初想要这个模型的原因。
预测新评论的情感涉及遵循用于准备测试数据的相同步骤。具体来说,加载文本,清理文档,按选定的词汇过滤标记,将剩余的标记转换为一行,使用Tokenizer对其进行编码,然后进行预测。
我们可以通过调用predict()直接使用拟合模型预测类别值,该函数将返回一个可以四舍五入为0(负面评论)或1(正面评论)的整数值。
所有这些步骤都可以放入一个名为predict_sentiment()的新函数中,该函数需要评论文本、词汇、分词器和拟合模型,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 将评论分类为负面(0)或正面(1) def predict_sentiment(review, vocab, tokenizer, model): # 清理 tokens = clean_doc(review) # 按词汇表过滤 tokens = [w for w in tokens if w in vocab] # 转换为一行 line = ' '.join(tokens) # 编码 encoded = tokenizer.texts_to_matrix([line], mode='freq') # 预测 yhat = model.predict(encoded, verbose=0) return round(yhat[0,0]) |
我们现在可以对新的评论文本进行预测。
下面是使用上面开发的带有频率词评分模式的简单MLP对一个明显正面和一个明显负面评论的示例。
|
1 2 3 4 5 6 |
# 测试正面文本 text = 'Best movie ever!' print(predict_sentiment(text, vocab, tokenizer, model)) # 测试负面文本 text = 'This is a bad movie.' print(predict_sentiment(text, vocab, tokenizer, model)) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行示例几次并比较平均结果。
运行该示例可以正确分类这些评论。
|
1 2 |
1 0 |
理想情况下,我们应该在所有可用数据(训练和测试)上拟合模型以创建最终模型,并将模型和分词器保存到文件中,以便可以在新软件中加载和使用它们。
扩展
本节列出了一些扩展,如果您希望从本教程中获得更多内容。
- 管理词汇表。探索使用更大或更小的词汇表。也许您可以使用更少的词语获得更好的性能。
- 调整网络拓扑。探索替代的网络拓扑,例如更深或更宽的网络。也许您可以使用更合适的网络获得更好的性能。
- 使用正则化。探索使用正则化技术,例如Dropout。也许您可以延迟模型的收敛并实现更好的测试集性能。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
论文
- 情感教育:基于最小割的主观性摘要的情感分析, 2004.
API
总结
在本教程中,您学习了如何开发一个词袋模型来预测电影评论的情感。
具体来说,你学到了:
- 如何准备用于受限词汇建模的评论文本数据。
- 如何使用词袋模型准备训练和测试数据。
- 如何开发一个多层感知器词袋模型,并使用它对新的评论文本数据进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。

")
")
")


优秀的示例代码和解释。
谢谢。
谢谢你,Jason。非常有趣的工作。
谢谢你。
解释得很好。谢谢
谢谢 Hirak。
解释得很清楚
谢谢 Chetana。
谢谢你,Jason,解释得很清楚。
谢谢。
你好,能给我源代码吗,谢谢84!
源代码在帖子中。使用复制粘贴。
谢谢你 Jason。你在我的职业成长中扮演着关键角色。
很高兴听到这个消息!
很棒的文章,Jason。
实际上,下面的几行代码有一个小错误
positive_lines = process_docs(‘txt_sentoken/neg’, vocab)
negative_lines = process_docs(‘txt_sentoken/pos’, vocab)
谢谢 Arthur,已修复!
Jason 写的文章非常棒。我的评论不仅针对这篇具体的文章,而是针对整个网站。这真的很有帮助。
谢谢 Kapil!
感谢您这篇精彩而简洁的文章!
谢谢。
尊敬的先生,
您能否也帮助我们用R语言撰写上述文章。
我是一个R语言学习者,正在寻找像您这样的人的文章来学习。
您的帮助将不胜感激。
谢谢
此致
Vijay
谢谢你的建议 Vijay。
干得好!演示非常清晰。
此致
谢谢 Jacek。
嗨,Jason,
我按照指示创建了模型。但是当我尝试对新文本进行预测时,我收到一个错误,提示输入形状不同。
当我们拟合模型时,输入形状是根据训练数据获取的。然而,tokenizer.text_to_matrix 为新文本提供了不同的形状。因此,模型无法用于预测新文本。
您能否提出解决方案。
谢谢,
Sappy
您必须以与训练数据文本完全相同的方式准备新文本。
我建议使用与准备训练数据相同的函数甚至编码器。
杰森博士,
我已经使用了模型并将其保存到磁盘为.h5文件。然后我使用load_model()函数加载了它。现在我尝试使用上面的代码进行预测,并得到这个错误:“Tokenizer”对象没有属性“word_index”。整个过程中都使用了相同的函数。我找不到问题所在。请指正。
听到这个消息我很难过,我以前从未见过这个错误。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
谢谢你,Jason 博士!真是非常有价值的教程!
在玩模型时我注意到,以不同点分割数据(至少在这种情况下)会导致非常不同的准确度(高达5%的差异)。也就是说,我们从开头/中间或从最后的评论中获取测试数据——所有这些都会产生不同的结果。因此,我进一步尝试了使用 sklearn train_test_split 和不同的 random_state 数字来在不同点分割数据集——结果在很大程度上取决于此。(这是因为分词器每次都会适应不同的词元集。)
解决这种情况并从中获得最佳结果的最佳方法是什么?
非常棒且重要的观察,Vladimir。
请参阅此文章以获取更稳健的模型评估策略
https://machinelearning.org.cn/evaluate-skill-deep-learning-models/
好,我喜欢这种简单的方法。谢谢分享。
不客气。
Jason,
请查看一种更优雅的文本预处理、将其编码为词条矩阵并转换为数组的方法。我在我的博客中创建了一个教程,灵感来自您的精彩文章
https://silversurfer0.github.io/tutorial/2018/01/22/NLP_with_Keras.html
所以,想法是使用 sklearn CountVectorizer!它接受参数并进行所有必要的预处理:分词、定义词语大小、过滤停用词、包含特定频率出现的词语,甚至允许进行 N-gram!
感谢您,
祝好!——Vladimir
做得好!
此外,有时将所有部分分开进行学习(例如对于初学者)或为了更多控制/微调也是很好的。
真的很有帮助!!!!!!!
谢谢,听到这个我很高兴。
嗨,Jason,
我按照指示创建了模型。但是当我尝试对新文本进行预测时,我总是得到结果为0。请帮忙。
也许您的模型需要更多调优?
当我运行预测函数时,它给了我这个…!!!
print(predict_sentiment(text, vocab, tokenizer, model))
NameError: 名称“model”未定义
看起来你可能漏掉了教程中的一些代码。
这是我运行的代码,请 Jason 先生帮我找出错误或我遗漏了什么。
from numpy import array
from string import punctuation
from os import listdir
from collections import Counter
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
来自 keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from pandas import DataFrame
from matplotlib import pyplot
# 加载文档到内存
def load_doc(filename)
# 以只读方式打开文件
file = open(filename, ‘r’)
# 读取所有文本
text = file.read()
# 关闭文件
file.close()
return text
# 将文档转换为干净的令牌
def clean_doc(doc)
# 按空格分割成令牌
tokens = doc.split()
# 从每个令牌中去除标点符号
table = str.maketrans(”, ”, punctuation)
tokens = [w.translate(table) for w in tokens]
# 移除所有非字母的剩余标记
tokens = [word for word in tokens if word.isalpha()]
# 过滤掉停用词
stop_words = set(stopwords.words(‘english’))
tokens = [w for w in tokens if not w in stop_words]
# 过滤掉短标记
tokens = [word for word in tokens if len(word) > 1]
return tokens
# 加载文档,清理并返回标记行
def doc_to_line(filename, vocab)
# 加载文档
doc = load_doc(filename)
# 清理文档
tokens = clean_doc(doc)
# 按词汇过滤
tokens = [w for w in tokens if w in vocab]
return ‘ ‘.join(tokens)
# 加载目录中的所有文档
def process_docs(directory, vocab, is_trian)
lines = list()
# 遍历文件夹中的所有文件
for filename in listdir(directory)
# 跳过测试集中的任何评论
if is_trian and filename.startswith(‘cv9’)
continue
if not is_trian and not filename.startswith(‘cv9’)
continue
# 创建要打开的文件的完整路径
path = directory + ‘/’ + filename
# 加载并清理文档
line = doc_to_line(path, vocab)
# 添加到列表中
lines.append(line)
return lines
# 评估神经网络模型
def evaluate_mode(Xtrain, ytrain, Xtest, ytest)
scores = list()
n_repeats = 2
n_words = Xtest.shape[1]
for i in range(n_repeats)
# 定义网络
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
# 编译网络
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
# 拟合网络
model.fit(Xtrain, ytrain, epochs=50, verbose=2)
# 评估
loss, acc = model.evaluate(Xtest, ytest, verbose=0)
scores.append(acc)
print(‘%d accuracy: %s’ % ((i+1), acc))
return scores
# 准备文档的词袋编码
def prepare_data(train_docs, test_docs, mode)
# 创建分词器
tokenizer = Tokenizer()
# 在文档上拟合分词器
tokenizer.fit_on_texts(train_docs)
# 编码训练数据集
Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)
# 编码训练数据集
Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)
return Xtrain, Xtest
# 加载词汇表
vocab_filename = ‘vocab.txt’
vocab = load_doc(vocab_filename)
vocab = vocab.split()
vocab = set(vocab)
# 加载所有训练评论
positive_lines = process_docs(‘txt_sentoken/pos’, vocab, True)
negative_lines = process_docs(‘txt_sentoken/neg’, vocab, True)
train_docs = negative_lines + positive_lines
# 加载所有测试评论
positive_lines = process_docs(‘txt_sentoken/pos’, vocab, False)
negative_lines = process_docs(‘txt_sentoken/neg’, vocab, False)
test_docs = negative_lines + positive_lines
# 准备标签
ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)])
ytest = array([0 for _ in range(100)] + [1 for _ in range(100)])
modes = [‘binary’, ‘count’, ‘tfidf’, ‘freq’]
results = DataFrame()
for mode in modes
# 为模式准备数据
Xtrain, Xtest = prepare_data(train_docs, test_docs, mode)
# 评估模式下的模型数据
results[mode] = evaluate_mode(Xtrain, ytrain, Xtest, ytest)
# 总结结果
print(results.describe())
# 绘制结果
#results.boxplot()
#pyplot.show()
# 将评论分类为负面(0)或正面(1)
def predict_sentiment(review, vocab, tokenizer, model)
# 清理
tokens = clean_doc(review)
# 按词汇过滤
tokens = [w for w in tokens if w in vocab]
# 转换为一行
line = ‘ ‘.join(tokens)
# 编码
encoded = tokenizer.texts_to_matrix([line], mode=’freq’)
# 预测
yhat = model.predict(encoded, verbose=0)
return round(yhat[0,0])
# 测试正面文本
text = ‘Best movie ever!’
print(predict_sentiment(text, vocab, tokenizer, model))
# 测试负面文本
text = ‘This is a bad movie.’
print(predict_sentiment(text, vocab, tokenizer, model))
我这里有一些想法
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
非常感谢 Jason 先生
当我运行预测函数时,它给了我这个…!!!
print(predict_sentiment(text, vocab, tokenizer, model))
NameError: name 'model' is not defined 同样的问题,我需要创建一个新文件并导入其他文件吗?(对不起,我是Python新手)
看起来你没有从示例中复制所有的代码。
您能给我们一个完整的代码吗?我不知道如何包含最后一部分的函数部分来获取一个时态的结果!
内容很棒。
谢谢。
非常感谢!
很高兴它有帮助。
你认为词干提取能提高分类准确性,还是会带来过拟合?
这可能会简化问题,进而提高技能。
您能更详细地解释一下 predict 函数吗?我每次想在新数据上测试时都需要运行训练代码吗?谢谢您
我在这里更详细地解释了如何使用 Keras 模型进行预测
https://machinelearning.org.cn/faq/single-faq/how-do-i-make-predictions
嗨,Jason 博士,
这是一篇非常好的文章,谢谢你,它让我清楚了很多观点。
我有一个问题。我想知道是否可以使用 K 折交叉验证来代替训练测试分割?或者在文档分类的情况下,K 折交叉验证不是必需的?
致以最诚挚的问候。
如果你有资源,这是一个好主意,但当我们处理 NLP 模型时,我们通常没有。
谢谢你。
此致。
嗨,Jason,
您的博客,就像这篇一样,对我的工作有很大帮助。
我想看看“嵌入”与词袋模型相比表现如何。
您有没有使用嵌入进行情感分析的教程?
此致,
Emmanuel
谢谢 Emmanuel!
是的,我有很多这样的教程,请在博客搜索中输入“embedding”。
谢谢你。我的目标是使用多项式贝叶斯改进我现有的“经典”词袋方法在情感分析和文档分类方面的性能。它在文档分类方面表现良好。
然而,我正在寻找一个性能更好的模型,特别是对于我的情感分析,考虑到评论是多种语言的。
您会考虑/认为在CNN中使用多通道、N-gram会提高整体性能吗?
非常感谢您的回复:).
我不会猜测,我会设计实验来发现。
它实际上提高了准确性!
非常感谢您的精彩教程!您的教程极大地提高了我的机器学习技能和理解能力。
祝好,
Emmanuel
谢谢,干得好!
Jason,我是Python新手……很想按照您上面提供的指导设置……我下载了电影预览数据集……但是如何运行第一段代码呢?“下面列出了清理第一个正面评论的示例。”……当我将这段代码放入Python的IDLE中时,它会返回一个语法错误。对于这样一个新手问题我深感抱歉……我想一旦我明白了如何应用您的代码,我就可以让其余的代码运行起来了。
感谢您写出如此精彩的文章!希望我能尽快让它运行起来。
我建议从命令行运行代码,我这里有一个示例
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
我使用的是相同的CNN模型,准确度为0.8,但当我进行预测时,所有结果都是正面的,请问您有什么想法吗?
也许可以尝试重新运行示例几次并比较结果?
嗨
您可能知道为什么 yhat(如上面 Model.predict 调用的返回值)的秩是2而不是1吗?根据您上面的示例,我期望 yhat 是 [1] 而不是 [[1]]。
谢谢
每个输入样本都会进行一次预测。
你好 Jason,谢谢你的这篇文章,它真的很有帮助 🙂
我有几个问题,我想知道你是否能帮我。我们能将词袋模型与 CNN 或 RNN 一起使用吗?另外,使用验证集会提高准确性吗?你还提到了在 GPU 上运行程序,我们需要做哪些主要更改?
谢谢
不能,词袋模型丢弃了 CNN 和 LSTM 所需的时间顺序。
验证数据集不会影响模型性能,它用于评估模型性能。
您必须配置底层后端(tensorflow)以使用 CPU 或 GPU。我不提供这方面的说明。
谢谢你 Jason,这很有帮助。
很高兴听到这个消息。
NameError: 名称“model”未定义
Jason 提到要保存模型和分词器文件,如下所示——
“理想情况下,我们应该在所有可用数据(训练和测试)上拟合模型以创建一个最终模型,并将模型和分词器保存到文件中,以便它们可以在新软件中加载和使用。”
拟合模型后请保存模型——
model.save(‘my_model.h5’)
获取分词器文件后,请保存分词器文件——
from pickle import dump
dump(tokenizer, open(‘tokenizer.pkl’, ‘wb’))
看起来你可能漏掉了一些代码行。
你好 Vinay,
你能告诉我我们需要在哪里准确地指定以下代码行吗?
“from pickle import dump
dump(tokenizer, open(‘tokenizer.pkl’, ‘wb’))”
以及这一行
“model.save(‘my_model.h5’)”
第一种情况我们将分词器保存到文件,第二种情况我们将模型保存到文件。
你好,
我想读取表示为整数序列的原始数据(系统调用,ADFA-LD 数据集),我该怎么做,我不能使用上面提到的模式吗?
谢谢
您必须用一个唯一的数字来编码词汇表中的每个单词。
但是我的词汇表是一组整数(介于1和340之间),每个整数代表一个唯一的系统调用。
太棒了!也许可以先原型化几个模型?
问题在于如何定义 Xtrain 和 Ytrain,因为我只有文本而不是数组。我尝试使用唯一数字进行编码,但出现了同样的问题:我得到了 Ytrain 或其他形状的错误。
问题是:训练模型时,我们是否必须拥有带列和行的数据集?有没有一种方法可以直接使用序列,而无需转换它们?
谢谢,抱歉打扰您
通常,模型将接受多个样本作为输入,其中每个样本都是编码单词(编码文本)的向量。
或许可以尝试运行上面的示例,看看文本是如何编码并作为输入传递给模型的?
我试过这个,我得到了这个错误
valueError: 请指定一个维度(num_words 参数),或者先在一些文本数据上进行拟合
听到这个消息我很难过,我这里有一些建议可能有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Kahina,
我也遇到了同样的错误。后来我意识到我的“vocab.txt”是空的。
好建议。
嗨,Jason,
执行代码后,我得到了如下错误——
(数组([[0. , 0.01519757, 0.00911854, …, 0. , 0. ,
0. ],
[0. , 0. , 0. , …, 0. , 0. ,
0. ],
[0. , 0.03007519, 0.01879699, …, 0. , 0. ,
0. ],
……,
[0. , 0.01201923, 0.01442308, …, 0. , 0. ,
0. ],
[0. , 0.01230769, 0.01538462, …, 0. , 0. ,
0. ],
[0. , 0. , 0.008 , …, 0. , 0. ,
0. ]]),
然而在你的代码中,我看到输出只有1或0。
我甚至没有改变代码中的一个词。它完全一样。你能告诉我问题可能出在哪里吗?谢谢!
听到这个消息我很难过,我这里有一些建议可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
抱歉,我不是指错误。我是指输出
嘿,Jason,我觉得这里的方法和词嵌入编码方法很相似。我想知道哪个部分使用了词袋模型?是以下部分吗?我们为什么一开始要使用序列编码?谢谢。
modes = ['binary', 'count', 'tfidf', 'freq']
results = DataFrame()
for mode in modes:
# prepare data for mode
Xtrain, Xtest = prepare_data(train_docs, test_docs, mode)
# evaluate model on data for mode
results[mode] = evaluate_mode(Xtrain, ytrain, Xtest, ytest)
# summarize results
print(results.describe())
# plot results
results.boxplot()
pyplot.show()
词袋是单词到计数向量的映射。
向量没有顺序,它们不是序列。
嗨,先生,这是一个非常好的模型!!
我的代码有一个疑问。
我已经在 NLP 中构建了一个模型,但我不知道如何预测我的结果,您能帮我写代码吗?
你可以调用 model.predict()
也许这会有帮助。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
你好,你能帮我解决这个错误吗?这段代码来自深度学习的NLP。
代码
text = ‘ 史上最佳电影!太棒了,我推荐。 ’
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print( ‘ 评论:[%s]\n情感:%s (%.3f%%) ’ % (text, sentiment, percent*100))
# 测试负面文本
text = ‘ 这是一部烂片。 ’
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print( ‘ 评论:[%s]\n情感:%s (%.3f%%) ’ % (text, sentiment, percent*100))
错误
NameError Traceback (最近一次调用)
in
171 # 测试正面文本
172 text = ‘ 史上最佳电影!太棒了,我推荐。 ’
–> 173 percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
174 print( ‘ 评论:[%s]\n情感:%s (%.3f%%) ’ % (text, sentiment, percent*100))
175 # 测试负面文本
在 predict_sentiment(review, vocab, tokenizer, model) 中
140 #return round(yhat[0,0])
141 percent_pos = yhat[0,0]
–> 142 if round(percent_post) == 0
143 return(1-percent_post), ‘NEGATIVE’
144 return percent_pos, ‘POSITIVE’
NameError: name 'percent_post' 未定义
看起来代码已被更改并添加了 percent_post 函数。
抱歉,我不了解那个函数。
嗨,Jason博士,
感谢您的分享,这非常有帮助!我很好奇程序到底是如何知道哪些评论是正面的,哪些是负面的?我理解这行代码将评论标记为0和1
“ytrain = array([0 for _ in range(900)] + [1 for _ in range(900)])”,但程序如何知道范围内的哪些评论是负面的,哪些是正面的?为什么两个范围都是900?
谢谢!
Quinn
不客气。
它从例子中学习。
在那段代码中,我们正在准备示例的类标签,以便模型可以学习。这些数字指的是每个类别中的示例数量。
啊,我明白了。您能确认我的以下理解是否正确吗?
我们将训练语料库变量定义为“docs = negative_lines + positive_lines”。因此,负面评论在数组的前半部分,而正面评论在后半部分。由于我们知道每个部分都有900条评论,我们可以简单地将前900条标记为0表示负面,将另外900条标记为1表示正面。如果我们将“docs”定义为相反的方式,即“docs = positive_lines + negative_lines”,那么在标记评论时,我们应该使用“ytrain = array([1 for _ in range(900)] + [0 for _ in range(900)])”。
以上说法正确吗?再次非常感谢您。
正确。
谢谢你。我还有一个问题,我看到我们只使用正面或负面评论。通常不建议在训练数据集中包含中性评论吗?
我之所以问这个问题,是因为我有一系列句子,目前我将其分为正面/负面,其中有一些句子是中性的。我倾向于将它们作为中性包含在内,而不是完全排除。
那是个好主意,也是教程的一个自然延伸。
谢谢你。在这种情况下,你有什么建议来标记正面/负面/中性评论吗?用1表示正面,0表示中性,-1表示负面是否合理?还是最好都保持正面,即使用0、1和2?我试图在网上查找相关信息,但发现的信息有限。再次感谢!
这并不重要。
先生,您好,
当我尝试创建模型时,准确率只有65.5%。我们如何才能提高模型性能、准确率等?
这里有一些建议。
https://machinelearning.org.cn/start-here/#better
嗨,Jason!
感谢这篇精彩的帖子!我有一个包含4种语言的文本不平衡数据集,带有两个标签,我想用 CNN 进行二元分类。
有什么过程指导吗?它与单语言数据集有何不同?
再次感谢!
有趣,我建议你发挥创造力,尝试一系列不同的方法。
我建议原型化不同的方法,例如,为每种语言设计不同的输入模型,也许共享一个输出模型。
你好,谢谢你精彩的教程。
我是 NLP 新手,对两件事感到困惑。
1)为什么我们从评论中创建了词汇表列表,然后在下一步又对评论进行了分词?
2)单词得分的作用是什么?它们是表示单词是正面还是负面,还是仅仅显示它们在评论数据集中出现的频率?
再次感谢!
好问题。
我们希望控制模型中使用的词汇表,例如,将词语限制在那些最有用/最相关的词语可以使模型简单/快速/有效。
我们在这个教程中预测情感,只要有训练数据,你可以预测任何你喜欢的东西。
感谢您的回复!
不客气。
嗨 Jason
精彩的文本分类教程!
我根据您的其他NLP教程,为代码添加了额外的选项,以评估多种敏感性分析,例如
– 使用 k 折交叉验证 Sklearn API,评估不同训练-验证数据集分组的统计变异。
– 通过添加深度学习层(或不添加),如嵌入层和一维卷积层,以更好地捕获词语模式提取,然后在将其注入模型全连接部分的密集层之前,评估结果改进情况。在使用嵌入层的情况下,我还添加了使用 GloVe 预训练词向量权重(或不使用)的选项。
– 使用 keras 函数(如:“texts_to_sequences()”、“one_hot()2”或“texts_to__matrix()”)对文档文本词语进行“编码”的不同选项。
– 设置“词特征”数量的不同选项,例如任何文档中包含的最大词语长度(1,301),或所有文档中不同词汇词的数量(24,875),甚至是大于最大长度的任意特征数量(例如100,000!)。
顺便说一下,我尝试在密集层使用 kernel_regulrarizer 参数,例如“l1-l2”,但我得到了一个意想不到的结果,模型根本没有学习(50%的准确率)。!
我还在最后(而不是像您那样在开始)应用了训练-验证分割。也就是说,在执行所有词语准备、清理、获取词汇和为整个数据集编码词语/特征之后。
我得到的最佳结果约为89%的准确率。
我对在模型中添加嵌入层的影响很好奇,它将由例如[文档数量,词特征数量]定义的2D输入文本文档更改为3D [文档数量,词特征数量,词向量坐标数量]……这个嵌入层是否适用于NLP以外的ML/DL其他领域(例如计算机视觉、时间序列),还是只特定于NLP?
在我的案例中,情感分析中最令人困惑的部分是将文本文档转换为文本、行、单词、清理、获取文档词汇……最后应用编码将单词转换为数字的繁琐过程!我期望新的 API 能够以更强大、更简单的 API 克服这个漫长的过程!
谢谢
非常酷,谢谢分享。
是的,嵌入可以与任何分类或序数输入一起使用,例如
https://machinelearning.org.cn/how-to-prepare-categorical-data-for-deep-learning-in-python/
同意,清理文本毫无乐趣。
谢谢你,Jason!
我将查看建议的深度学习分类变量编码教程
祝您有个美好的一天!
你也一样!
亲爱的 Jason,
我浏览了教程,出现了一个错误
==> AttributeError: 模块 'tensorflow.python.framework.ops' 没有属性 '_TensorLike'
当它在程序末尾执行函数“evaluate_mode()”时
results[mode] = evaluate_mode(Xtrain, ytrain, Xtest, ytest)
我修复了这么多错误,并且运行良好,但这个很难。我尝试了几次,但无法修复。因此,如果可能的话,我需要您的帮助。提前感谢您的帮助。
听到你遇到麻烦我很难过,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我想将 BOW 模型应用于一个包含问答列的 Excel 表格(xlsx),我需要您的帮助。提前感谢!
首先将您的电子表格另存为 CSV 文件,以便您可以在 Python 中加载它们。
有没有什么邮箱或其他平台我可以联系您,我想和您分享一些事情,并需要您的帮助。谢谢!
是的,菜单中链接的联系页面
https://machinelearning.org.cn/contact/
嗨,Jason,
有没有办法使用上述方法分析二元词?我认为 keras 中的 tokenizer 库不支持它。有没有办法创建一个固定长度的词袋模型向量,词汇受限,就像本教程中一样,但是使用二元词?
词袋有一个固定的词汇表,但不关心文档长度。
您可以使用二元词袋而不是单词,但这会是一个巨大的向量。真让人头疼。
谢谢你,Jason!
我有一个带标签的情感检测数据集,还有一个西班牙语情感词典。
我计算 TF 方案以获得表达式(术语,单词)在文档中出现的频率。我想通过检查词典术语在句子中的存在来合并有效的词汇特征,并获得一个代表每个情感类别(愤怒、恐惧、悲伤和快乐)的向量。最后,为了进行分类,将 TF 句子表示和基于单词的特征的串联用作不同机器学习算法的输入。
我如何合并有效的词典特征以获得向量?以及如何将 TF 与词典串联并将其用作不同 ML 的输入?
也许可以集成这两个不同的模型?
或许可以使用具有独立输入子模型的多元输入神经网络模型,每个子模型对应一种特征类型?
或许可以将上述两种方法与一个大的串联向量输入进行对比?
我正在向专家学习新知识。虽然很有趣
谢谢。
拍得不错,哥们。在文明国家,未经同意偷拍半裸女性,你可能会被判做社区服务,但在鸸鹋岛显然不会。