标题生成是一个具有挑战性的人工智能问题,它旨在根据给定照片生成人类可读的文本描述。
它需要计算机视觉领域的图像理解和自然语言处理领域的语言模型。
重要的是要考虑并测试多种方法来构建给定的预测建模问题,而且确实有许多方法可以构建照片标题生成问题。
在本教程中,您将发现可以构建标题生成问题的 3 种方式,以及如何为每种方式开发模型。
我们将探讨的三种标题生成模型是:
- 模型 1:生成
整个序列 - 模型 2:从词生成词
- 模型 3:从序列生成词
我们还将回顾在准备数据和开发标题生成模型时需要考虑的一些最佳实践。
通过我的新书《深度学习自然语言处理》来启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
模型 1:生成整个序列
第一种方法涉及根据照片生成照片的整个文本描述。
- 输入:照片
- 输出:完整的文本描述。
这是一个一对多的序列预测模型,它以一次性方式生成整个输出。
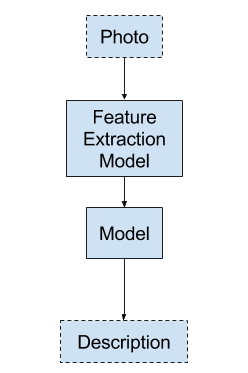
模型 1 – 生成整个序列
这个模型给语言模型带来了沉重的负担,需要它以正确的顺序生成正确的词语。
照片会通过一个特征提取模型,例如在 ImageNet 数据集上预训练的模型。
输出序列使用独热编码,允许模型预测序列中每个词在整个词汇表上的概率分布。
所有序列都填充到相同的长度。这意味着模型被迫在输出序列中生成多个“无词”时间步。
测试这种方法时,我发现需要一个非常大的语言模型,即便如此,也很难让模型超越 NLP 等效的持久性,例如,在整个序列长度上重复生成相同的单词作为输出。
模型 2:从词生成词
这是一种不同的方法,LSTM 根据照片和一个词作为输入生成一个词的预测。
- 输入 1:照片。
- 输入 2:先前生成的单词,或序列开始标记。
- 输出:序列中的下一个单词。
这是一个一对一的序列预测模型,它通过对模型的递归调用生成文本描述。
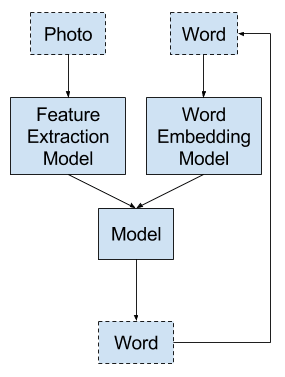
模型 2 – 从词生成词
这个词输入要么是用于指示序列开始的标记(首次调用模型时),要么是上次调用模型时生成的词。
照片通过特征提取模型,例如在 ImageNet 数据集上预训练的模型。输入词被整数编码并经过词嵌入。
输出词采用独热编码,允许模型预测整个词汇表中词的概率。
递归词生成过程重复进行,直到生成序列结束标记。
测试此方法时,我发现模型确实能生成一些不错的 N-gram 序列,但对于长描述,它会陷入重复相同词序列的循环中。模型中没有足够的记忆来记住之前生成的内容。
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型 3:从序列生成词
给定一张照片和已为该照片生成的词语序列作为输入,预测描述中的下一个词语。
- 输入 1:照片。
- 输入 2:之前生成的词语序列,或序列开始标记。
- 输出:序列中的下一个单词。
这是一个多对一的序列预测模型,它通过递归调用模型来生成文本描述。
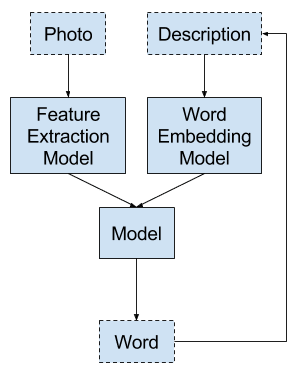
模型 3 – 从序列生成词
它是上述模型 2 的泛化,其中输入词序列为模型提供了生成序列中下一个词的上下文。
照片通过特征提取模型,例如在 ImageNet 数据集上预训练的模型。照片可以每次随序列提供,或者在开始时提供一次,这可能是更优选的方法。
输入序列被填充到固定长度,并进行整数编码以通过词嵌入。
输出词采用独热编码,允许模型预测整个词汇表中词的概率。
递归词生成过程重复进行,直到生成序列结束标记。
这似乎是该领域论文中描述的首选模型,并且可能是我们目前针对此类问题的最佳结构。
测试此方法时,我发现该模型确实能轻松生成可读的描述,其质量通常通过训练时间更长的更大模型来改进。此模型技能的关键在于对填充输入序列的掩码。如果没有掩码,生成的词语序列将非常糟糕,例如,序列结束标记会反复出现。
建模最佳实践
本节列出了一些在开发标题生成模型时的一般性建议。
- 预训练照片特征提取模型。使用在大型数据集(如 ImageNet)上预训练的照片特征提取模型。这称为迁移学习。2014 年赢得 ImageNet 竞赛的牛津视觉几何组 (VGG) 模型是一个很好的起点。
- 预训练词嵌入模型。使用预训练的词嵌入模型,其向量要么是在大型平均语料库上训练的,要么是在您的特定文本数据上训练的。
- 微调预训练模型。探索使预训练模型在您的模型中可训练,以查看它们是否可以根据您的特定问题进行调整,并略微提升技能。
- 文本预处理。预处理文本描述以减少要生成的词汇量,进而减少模型的大小。
- 照片预处理。对照片进行预处理以用于照片特征提取模型,甚至预提取特征,这样在训练模型时就不需要完整的特征提取模型。
- 填充文本。将输入序列填充到固定长度;这实际上是深度学习库对输入进行矢量化的要求。
- 掩码填充。在嵌入层上使用掩码以忽略“无词”时间步,当词是整数编码时,通常为零值。
- 注意力机制。在生成输出词时使用输入序列上的注意力机制,以实现更好的性能并理解模型在生成每个词时“关注”的位置。
- 评估。使用 BLEU 等标准文本翻译指标评估模型,并将生成的描述与多个参考图像标题进行比较。
您是否有自己开发健壮标题生成模型的最佳实践?
在下面的评论中告诉我。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- 展示与讲述:一个神经图像字幕生成器, 2015.
- 展示、关注和讲述:带视觉注意力的神经图像标题生成, 2015.
- 如何在图像标题生成器中放置图像, 2017.
- 图像自动描述生成:模型、数据集和评估指标综述, 2016.
总结
在本教程中,您学习了 3 种序列预测模型,它们可以用于解决为照片生成人类可读文本描述的问题。
您是否尝试过这些模型?
在下面的评论中分享您的经验。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






非常感谢 Jason。你强调了掩码。那到底是什么?你以前讲过吗?
是的,请看这篇文章
https://machinelearning.org.cn/handle-missing-timesteps-sequence-prediction-problems-python/
嗨 Jason,你会提供模型 2 的示例代码吗?我想知道如何只在第一次提供视觉特征,然后提供单词/值的序列
我的书中有一个模型 3 的例子,可以修改为模型 2。
根据我的经验,模型 3 最容易训练,并且具有更好的性能。
太棒了!我不明白你是用掩码在第一次提供视觉特征,还是影响初始状态?
我们将掩码填充词序列。
好的,所以你把视觉和文本特征连接起来提供。但是第一次你掩盖了单词序列。从第二次开始,你掩盖了视觉特征。是这样吗?
不,图像只提供一次,单词——迄今为止生成的描述——会填充到最大长度。
所以从第二次开始,你用全零代替视觉特征?我的意思是,你只应该在时间 1 提供图像,同时提供一个特殊的 START 词。然后,从时间 2 开始,你提供全零而不是视觉特征和之前预测的词。
不,这个网络有两个输入通道,一个用于图像,一个用于迄今为止生成的词序列。
嗯……抱歉,但我还是不清楚你如何只提供一次图像。
也许可以尝试运行这个例子,亲身体验一下
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/