Encoder-decoder 模型提供了一种使用循环神经网络解决机器翻译等具有挑战性的序列到序列预测问题的模式。
可以在 Keras Python 深度学习库中开发 Encoder-decoder 模型,Keras 博客上描述了一个使用此模型开发的 神经机器翻译系统 示例,并随 Keras 项目分发了示例代码。
在本帖中,您将了解如何根据 Keras 深度学习库的作者所述,为机器翻译定义一个 Encoder-decoder 序列到序列预测模型。
阅读本文后,你将了解:
- Keras 随附的神经机器翻译示例,并在 Keras 博客上进行了描述。
- 如何正确定义 Encoder-decoder LSTM 以训练神经机器翻译模型。
- 如何正确定义推理模型,以便使用训练好的 Encoder-decoder 模型翻译新的序列。
使用我的新书 《自然语言处理深度学习》 来 启动您的项目,其中包括分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- 更新 2018 年 4 月:有关应用此复杂模型的示例,请参阅博文:如何在 Keras 中开发用于序列到序列预测的 Encoder-decoder 模型

如何在 Keras 中定义用于神经机器翻译的 Encoder-decoder 序列到序列模型
照片由 Tom Lee 拍摄,保留部分权利。
Keras 中的序列到序列预测
Keras 深度学习库的作者 Francois Chollet 最近发布了一篇博文,其中通过一个代码示例介绍了如何为序列到序列预测开发 Encoder-decoder LSTM,标题为“Keras 中的序列到序列学习十分钟入门指南”。
博文中开发的 कोड 也已添加到 Keras 中,作为示例文件 lstm_seq2seq.py。
该博文开发了对该主题的经典论文中所述的 Encoder-decoder LSTM 的复杂实现。
- 使用神经网络进行序列到序列学习, 2014.
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014.
该模型应用于机器翻译问题,与该方法首次描述的源论文相同。从技术上讲,该模型是神经机器翻译模型。
Francois 的实现提供了在撰写本文时如何在 Keras 深度学习库中(正确地)实现序列到序列预测的模板。
在本帖中,我们将仔细研究训练模型和推理模型的具体设计方式以及它们的工作原理。
您将能够利用这些知识为自己的序列到序列预测问题开发类似的模型。
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
机器翻译数据
示例中使用的数据集是闪卡软件 Anki 中使用的简短法语和英语句子对。
该数据集称为“Tab 隔开的双语句子对”,是 Tatoeba 项目的一部分,并在 ManyThings.org 网站上列出,旨在帮助英语作为第二语言的学生。
教程中使用的数据集可从此链接下载
下面是解压下载的压缩文件后看到的 *fra.txt* 数据文件的前 10 行样本。
|
1 2 3 4 5 6 7 8 9 10 |
走。 Va ! 跑! Cours ! 跑! Courez ! 哇! Ça alors ! 着火! Au feu ! 救命! À l'aide ! 跳。 Saute。 停止! Ça suffit ! 停止! Stop ! 停止! Arrête-toi ! |
这个问题被框定为一个序列预测问题,其中输入的字符序列是英语,输出的字符序列是法语。
数据文件中近 150,000 个示例中,共使用了 10,000 个。准备好的数据的一些技术细节如下:
- 输入序列:填充到最大长度 16 个字符,词汇量为 71 个不同字符 (10000, 16, 71)。
- 输出序列:填充到最大长度 59 个字符,词汇量为 93 个不同字符 (10000, 59, 93)。
训练数据被构建为模型的输入由整个输入英语字符序列和整个输出法语字符序列组成。模型的输出是整个法语字符序列,但向前偏移一个时间步。
例如(使用最少的填充,不进行独热编码)
- Input1: [‘G’, ‘o’, ‘.’, ”]
- Input2: [ ”, ‘V’, ‘a’, ‘ ‘]
- Output: [‘V’, ‘a’, ‘ ‘, ‘!’]
机器翻译模型
神经翻译模型是一个 Encoder-decoder 循环神经网络。
它由一个读取可变长度输入序列的编码器和一个预测可变长度输出序列的解码器组成。
在本节中,我们将逐步介绍模型定义的每个元素,代码直接取自博文和 Keras 项目中的代码示例(撰写本文时)。
模型分为两个子模型:编码器负责输出输入英语序列的固定长度编码,解码器负责预测输出序列,每个输出时间步一个字符。
第一步是定义编码器。
编码器的输入是字符序列,每个字符都编码为长度为 *num_encoder_tokens* 的独热向量。
编码器中的 LSTM 层定义时将 `return_state` 参数设置为 `True`。这将返回 LSTM 层通常返回的隐藏状态输出,以及层中所有单元的隐藏状态和单元状态。这些用于定义解码器。
|
1 2 3 4 5 6 |
# 定义输入序列并处理。 encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 我们丢弃 `encoder_outputs`,只保留状态。 encoder_states = [state_h, state_c] |
接下来,我们定义解码器。
解码器输入定义为法语字符序列,其独热编码为长度为 *num_decoder_tokens* 的二进制向量。
LSTM 层被定义为同时返回序列和状态。最后一个隐藏状态和单元状态被忽略,仅引用隐藏状态序列。
重要的是,编码器的最后一个隐藏状态和单元状态用于初始化解码器的状态。这意味着每次编码器模型编码输入序列时,编码器模型的最后一个内部状态都将用作输出序列第一个字符的起点。这也意味着编码器和解码器 LSTM 层必须具有相同数量的单元,在本例中为 256。
使用一个 *Dense* 输出层来预测每个字符。这个 *Dense* 层用于一次性生成输出序列中的每个字符,而不是递归地生成,至少在训练期间是这样。这是因为在训练期间,模型需要整个目标序列作为输入。
Dense 层不需要包装在 `TimeDistributed` 层中。
|
1 2 3 4 5 6 7 8 9 |
# 设置解码器,使用 `encoder_states` 作为初始状态。 decoder_inputs = Input(shape=(None, num_decoder_tokens)) # 我们将解码器设置为返回完整的输出序列, # 并返回内部状态。我们不使用 # 返回状态,但在推理时会使用它们。 decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) |
最后,模型与编码器和解码器的输入以及目标输出序列一起定义。
|
1 2 3 |
# 定义将 # `encoder_input_data` 和 `decoder_input_data` 输入到 `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs) |
我们可以将所有这些整合到一个独立的示例中,配置并打印模型图。下面列出了定义模型的完整代码示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from keras.models import Model from keras.layers import Input 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.utils.vis_utils import plot_model # 配置 num_encoder_tokens = 71 num_decoder_tokens = 93 latent_dim = 256 # 定义输入序列并处理。 encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 我们丢弃 `encoder_outputs`,只保留状态。 encoder_states = [state_h, state_c] # 设置解码器,使用 `encoder_states` 作为初始状态。 decoder_inputs = Input(shape=(None, num_decoder_tokens)) # 我们将解码器设置为返回完整的输出序列, # 并返回内部状态。我们不使用 # 返回状态,但在推理时会使用它们。 decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) # 定义将 # `encoder_input_data` 和 `decoder_input_data` 输入到 `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 绘制模型 plot_model(model, to_file='model.png', show_shapes=True) |
运行该示例将创建一个模型图,这有助于您更好地理解所有组件是如何组合在一起的。
请注意,编码器 LSTM 不会将其输出直接传递给解码器 LSTM;如上所述,解码器使用最后一个隐藏状态和单元状态作为解码器的初始状态。
另请注意,解码器 LSTM 仅将其隐藏状态序列传递给 Dense 层进行输出,而不是像输出形状信息所示的那样传递最后一个隐藏状态和单元状态。
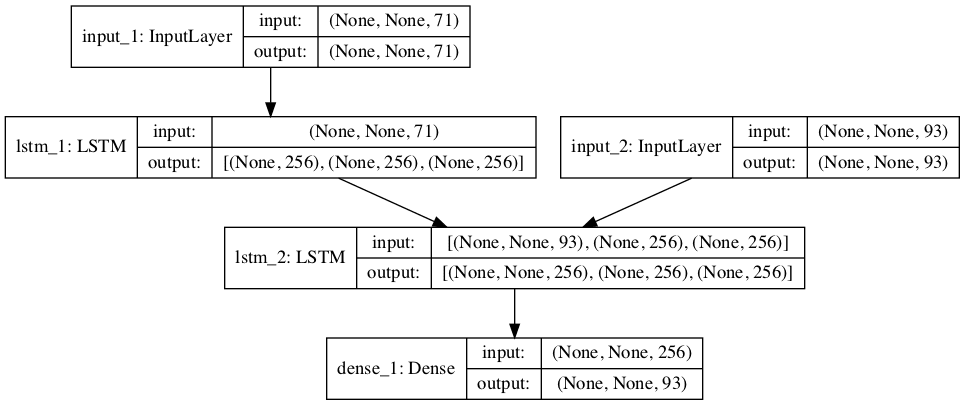
训练用 Encoder-Decoder 模型图
神经机器翻译推理
一旦定义的模型被训练,它就可以用来进行预测。具体来说,为英语源文本输出法语翻译。
为训练定义的模型已学习了此操作的权重,但模型的结构并非设计为递归调用以一次生成一个字符。
相反,需要新的模型来进行预测步骤,特别是用于编码英语输入字符序列的模型,以及一个接收到目前为止生成的法语字符序列和编码作为输入并预测序列中下一个字符的模型。
定义推理模型需要参考示例中用于训练的模型元素。或者,也可以定义一个具有相同形状的新模型并将权重从文件加载。
编码器模型被定义为接收训练模型中的输入层(*encoder_inputs*)并输出隐藏状态和单元状态张量(*encoder_states*)。
|
1 2 |
# 定义编码器推理模型 encoder_model = Model(encoder_inputs, encoder_states) |
解码器更为复杂。
解码器需要编码器的隐藏状态和单元状态作为新定义的编码器模型的初始状态。由于解码器是一个独立的模型,这些状态将作为输入提供给模型,因此必须首先将其定义为输入。
|
1 2 |
decoder_state_input_h = Input(shape=(latent_dim,)) decoder_state_input_c = Input(shape=(latent_dim,)) |
然后可以将其指定为解码器 LSTM 层的初始状态。
|
1 2 |
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c] decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs) |
对于要生成的翻译序列中的每个字符,编码器和解码器都将被递归调用。
首次调用时,编码器的隐藏状态和单元状态将用于初始化解码器 LSTM 层,这些状态直接作为输入提供给模型。
在后续对解码器的递归调用中,必须将最后一个隐藏状态和单元状态提供给模型。这些状态值已在解码器中;但是,由于模型在第一次调用时为了获取编码器的最终状态而定义的方式,我们必须在每次调用时重新初始化状态。
因此,解码器必须在每次调用时输出隐藏状态和单元状态以及预测的字符,以便将这些状态分配给一个变量,并在每个后续的递归调用中使用,以翻译给定的英语文本输入序列。
|
1 2 3 |
decoder_states = [state_h, state_c] decoder_outputs = decoder_dense(decoder_outputs) decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) |
我们可以将所有这些整合到一个独立的代码示例中,并结合上一节中训练模型的定义,因为它们会重用一些元素。完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
from keras.models import Model from keras.layers import Input 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.utils.vis_utils import plot_model # 配置 num_encoder_tokens = 71 num_decoder_tokens = 93 latent_dim = 256 # 定义输入序列并处理。 encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 我们丢弃 `encoder_outputs`,只保留状态。 encoder_states = [state_h, state_c] # 设置解码器,使用 `encoder_states` 作为初始状态。 decoder_inputs = Input(shape=(None, num_decoder_tokens)) # 我们将解码器设置为返回完整的输出序列, # 并返回内部状态。我们不使用 # 返回状态,但在推理时会使用它们。 decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = Dense(num_decoder_tokens, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs) # 定义将 # `encoder_input_data` 和 `decoder_input_data` 输入到 `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 绘制模型 plot_model(model, to_file='model.png', show_shapes=True) # 定义编码器推理模型 encoder_model = Model(encoder_inputs, encoder_states) # 定义解码器推理模型 decoder_state_input_h = Input(shape=(latent_dim,)) decoder_state_input_c = Input(shape=(latent_dim,)) decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c] decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs) decoder_states = [state_h, state_c] decoder_outputs = decoder_dense(decoder_outputs) decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) # 总结模型 plot_model(encoder_model, to_file='encoder_model.png', show_shapes=True) plot_model(decoder_model, to_file='decoder_model.png', show_shapes=True) |
运行示例将定义训练模型、推理编码器和推理解码器。
然后将创建这三个模型的所有图。
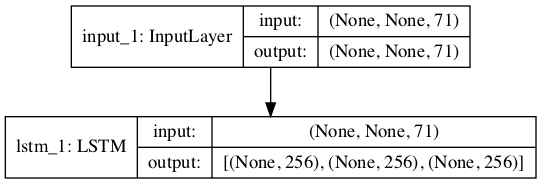
用于推理的 Encoder-Decoder 模型图
编码器图非常直接。
解码器显示了解码翻译序列中单个字符所需的三个输入:到目前为止的编码翻译输出,以及在递归调用模型以进行给定翻译时,首先从编码器提供,然后从解码器输出的隐藏状态和单元状态。
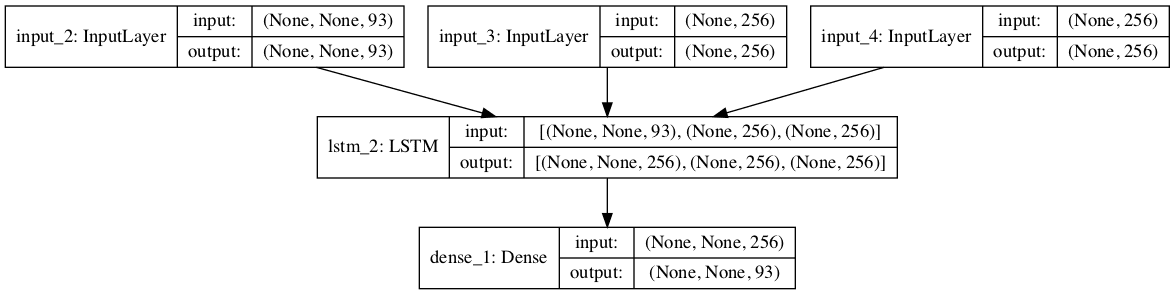
用于推理的解码器模型图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- Francois Chollet 在 Twitter 上
- Keras 中的序列到序列学习的十分钟入门
- Keras seq2seq 代码示例 (lstm_seq2seq)
- Keras 函数式 API
- Keras 中的 LSTM API
- 长短期记忆网络, 1997.
- 理解 LSTM 网络。, 2015.
- 使用神经网络进行序列到序列学习, 2014.
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014.
更新
有关如何在独立问题上使用此模型的示例,请参阅此帖
总结
在本帖中,您了解了如何根据 Keras 深度学习库的作者所述,为机器翻译定义一个 Encoder-decoder 序列到序列预测模型。
具体来说,你学到了:
- Keras 随附的神经机器翻译示例,并在 Keras 博客上进行了描述。
- 如何正确定义 Encoder-decoder LSTM 以训练神经机器翻译模型。
- 如何正确定义推理模型,以便使用训练好的 Encoder-decoder 模型翻译新的序列。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






Jason – 哪本书包含这篇文章?如果我没记错的话,我没在 LSTM 中看到过。
亲爱的 Tom,
您的代码非常有帮助……我需要和您谈谈一个与我的数据集相关的问题……不是这个代码。我可以得到您的电子邮件 ID 吗?
我参考了 lstm_seq2seq.py 代码来满足要求,我已正确执行,并获得了正确的结果。
我的要求是,我需要从用户那里获取输入,然后将其编码为状态向量,然后将其传递给解码器,为给定输入生成结果。我已经写了相关的逻辑。但我无法生成正确的结果。
userInput=”
count=0
while(userInput!=’quit’)
userInput = input(‘请输入英语句子或想停止(输入带引号的句子)’);
userInput=str(userInput)
f = open(‘testone.txt’, ‘a’ )
if userInput==’quit’
f.close()
else
f.write( userInput + ‘\n’ )
count=count+1
print(“count”,count)
# 从用户那里获取输入
# 将其保存在 testone.txt 文件中
test_path=’testone.txt’
test_texts = []
#target_texts = []
test_characters = set()
#target_characters = set()
lines = open(test_path).read().split(‘\n’)
for line in lines[: min(30, len(lines) – 1)]
test_text = line
test_texts.append(test_text)
#target_texts.append(target_text)
for char in test_text
if char not in test_characters
test_characters.add(char)
test_characters = sorted(list(test_characters))
num_testencoder_tokens = len(test_characters)
max_testencoder_seq_length = max([len(txt) for txt in test_texts])
print(‘Number of samples:’, len(test_texts))
#print(‘Number of unique input tokens:’, num_encoder_tokens)
print(“max test encoder seq length”,max_testencoder_seq_length)
print(“num_testencoder_tokens”,num_testencoder_tokens)
test_token_index = dict(
[(char, i) for i, char in enumerate(test_characters)])
print(“test_token_index”,test_token_index)
encoder_test_data = np.zeros(
(len(test_texts), max_testencoder_seq_length,num_testencoder_tokens),
dtype=’float32′)
print(“encoder_test_data”,encoder_test_data.shape)
for i,test_text in enumerate(test_texts)
for t, char in enumerate(test_text)
encoder_test_data[i, t,test_token_index[char]] = 1.
print(“encoder_test_data”,encoder_test_data.shape)
encoder_test_inputs = Input(shape=(None,num_testencoder_tokens))
print(“encoder_inputs”,encoder_test_inputs.shape)
encoder_test_inputs = Input(shape=(None, num_testencoder_tokens))
print(“—————-“,encoder_test_inputs.shape)
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_test_inputs)
print(“encoder_outputs”,encoder_outputs)
# 我们丢弃
encoder_outputs,只保留状态。encoder_test_states = [state_h, state_c]
print(“encoder_test_states”,encoder_test_states)
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_test_states)
print(‘encoder_test_inputs.shape’,encoder_test_inputs.shape)
print(‘encoder_test_states’,encoder_test_states)
encoder_test_model = Model(encoder_test_inputs, encoder_test_states)
print(encoder_test_model.summary)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# 反向查找令牌索引,以便将序列解码回
# 可读的内容。
reverse_input_char_index = dict(
(i, char) for char, i in test_token_index.items())
reverse_testtarget_char_index=dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq)
# 对输入进行编码,作为状态向量。
#print(input_seq)
states_value = encoder_test_model.predict(input_seq)
# 生成长度为 1 的空目标序列。
target_seq = np.zeros((1, 1, num_decoder_tokens))
# print(“target_seq”,target_seq)
# 使用起始字符填充目标序列的第一个字符。
target_seq[0, 0, target_token_index[‘\t’]] = 1.
# 采样循环,用于一批序列
# (为简化起见,此处我们假设批次大小为 1)。
stop_condition = False
decoded_sentence = ”
while not stop_condition
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
#print(“output_tokens”,output_tokens)
# 采样一个令牌
sampled_token_index = np.argmax(output_tokens[0, -1, :])
print(‘sampled_token_index’, sampled_token_index)
#sampled_char = reverse_target_char_index[sampled_token_index]
sampled_char = reverse_testtarget_char_index[sampled_token_index]
print(“sampled_char”,sampled_char)
decoded_sentence += sampled_char
# 退出条件:达到最大长度
# 或找到停止字符。
if (sampled_char == ‘\n’ or
len(decoded_sentence) > max_decoder_seq_length)
stop_condition = True
# 更新目标序列(长度为 1)。
target_seq = np.zeros((1, 1, num_decoder_tokens))
#print(“target_seq legnth”,len(target_seq))
target_seq[0, 0, sampled_token_index] = 1.
# 更新状态
states_value = [h, c]
return decoded_sentence
for seq_index in range(count)
#print(encoder_test_data[0:1])
input_seq = encoder_test_data[seq_index: seq_index + 1]
print(“input_seq”,input_seq.shape)
decoded_sentence = decode_sequence(input_seq)
print(‘-‘)
print(‘Input sentence:’, test_texts[seq_index])
print(‘Decoded sentence:’, decoded_sentence)
以上是我的代码,请建议我哪里出了问题。
抱歉,我无法为您调试代码。
问题究竟是什么?
实际上,在原始代码中,他们是在已经训练好的代码上进行测试的。在我的代码中,我正在做的是,我从控制台接收输入并将其存储在文件中。这些输入我提供给encoder_model。对于控制台输入,我没有得到像训练数据中那样的正确输出。
假设我从控制台输入了相同的单词,给encoder model,我也得到了错误的结果。
请告诉我哪里出错了。
也许你可以用静态数据来调试你的例子?
对于静态数据,它是可以工作的,但当我从用户那里获取输入时,我得不到正确的结果。
这可能与您读取输入并为其准备模型的方式有关。
如何使用keras对序列到序列模型进行预测,为什么我们不直接使用训练模型,为什么在这种情况下我们要创建推理模型,请解释一下。
我想知道,如何使用keras在序列到序列模型中预测模型未知输入的模型输出。
这是一个复杂的seq2seq模型。对于一个更简单的架构,请看这里。
https://machinelearning.org.cn/encoder-decoder-long-short-term-memory-networks/
我有一些未知的英文输入,我想把这些输入翻译成法语。所以我把这些文本输入转换成向量,就像在seq2sq模型中它们被编码成固定长度的向量一样。
我将这些输入与输入状态(隐藏状态、单元状态)一起提供给推理encoder_model,例如 encoder_model = Model(encoder_test_inputs, encoder_test_states)。
从这些中,我从encoder_model()中提取状态值,并将该状态值传递给decoder model,例如 decoder_model.predict(
[target_seq] + states_value),但如果我将未知输入提供给encoder_model,我会得到混乱的输出。
是否有任何不同的程序可以为给定的未知输入序列预测目标序列?请就此问题给我一些建议。
我能够解码已训练的数据,如果不是训练数据,我就无法解码。
一旦模型训练完成,您必须使用与训练数据相同的过程来编码新数据,然后调用model.predict()。
在其中,他们没有单独执行model.predict,而是单独执行encoder_model.predict和decoder_model.predict()。
正确。
如何使用keras预测未知目标序列的未知输入?对于未知输入,我是否需要再次创建输入层和编码器状态以及编码器模型,或者我需要使用相同的编码器模型,它将编码器输入和编码器状态作为参数?
推理模型可以像上面示例那样保存、加载和用于进行预测。
请解释一下这个推理解码器模型在这些示例中是如何工作的,我对编码器和解码器模型的训练、推理编码器模型都明白了,我没有理解这个例子中的推理解码器模型。
# 定义解码器推理模型
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
在训练模型中,我们传递解码器输入和初始状态作为编码器状态,但在推理中,我们传递的东西是不同的,为什么?原因是什么?
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs]
关键的区别在于,我们递归地将最后一个状态作为输入,第一次传递时从编码器状态开始。
这有帮助吗?
您能否进一步解释为什么这里不需要TimeDistributed?解码器中的Dense层必须为输入序列中的每个字符输出一个字符,那么它与必须应用TimeDistributed的情况有何不同?
好问题。Dense现在可以支持时间步长了!
您可以添加一个TimeDistribted包装器,效果相同。
我知道……Keras正变得有点令人困惑。
嗨 Jason,
我目前正在使用keras处理seq2seq模型。
我的需求:他们将有英文的测试用例,例如(加两个数字)。
输出:源应该为Python中那个特定的测试用例生成。
这个需求与语言翻译工具的差异很大。
请对此提出任何建议,如何进一步进行。
请看这篇博文,几乎完全是这个问题。
https://machinelearning.org.cn/learn-add-numbers-seq2seq-recurrent-neural-networks/
在预测目标字符时。
output_tokens, h, c = decoder_test_model.predict(
[target_seq] + states_value)
# 采样一个令牌
sampled_token_index = np.argmax(output_tokens[0, -1, :])
他们使用np.argmax(output_tokesn),你能解释一下它是如何工作的,以便预测目标字符吗?
问题究竟是什么?
argmax?看这里。
https://en.wikipedia.org/wiki/Arg_max
嗨Jason,感谢你写了详细的博客。
你尝试过保存和恢复模型以便以后进行推理吗?
我正在遵循lstm_seq2seq示例,其中model.save存储了HDF5文件,但是当我尝试恢复模型仅用于推理时,尽管模型在训练后进行推理时提供了良好的测试响应,但输出全是垃圾。
我没有尝试过,抱歉。
嗨,Jason,
我们可以用keras识别语法吗?比如什么是名词和代词,
请建议是否有使用keras识别语法的方法。
当然。这可以被看作是词语分类。
您必须准备一个数据集然后拟合您的模型。
你好 jason,
你是否有语言翻译的词级编码的例子,上面的例子是字符级编码,对吧?
如果你有例子,请分享链接。
是的,我的书里有一个例子。
https://machinelearning.org.cn/deep-learning-for-nlp/
这里提供的例子,他们对编码器和解码器进行了字符级编码,我想对编码器和解码器进行词级编码,使用相同的模型?
词级编码会比字符级编码更好吗?
对于词级编码,在开始之前,我需要遵循哪种方法?请给我建议。
这取决于问题是词级别还是字符级别更好。字符级别可能更灵活,但训练速度较慢,词级别可能需要更大的词汇量/内存,但训练速度更快。
抱歉,我不太明白,您能重述一下问题吗?
文章解释得很清楚!我想知道这些序列到序列模型是否可以应用于图像,例如处理不同尺寸的图像,并应用编码器-解码器进行分割?
也许吧,我不太明白,抱歉。您有例子吗?
假设我想开发一个神经网络,给定一张图片,它返回一个轮廓图(例如,汽车是蓝色的,人是绿色的),但我的数据集有各种不同尺寸的图片,导致它们无法堆叠成数组并直接放入CNN。当我们想要一张图片作为结果,但输入数据尺寸不统一时,是否可以将序列到序列的想法应用于这些图像?
有趣的挑战。
我认为seq2seq不是正确的框架,但我也可能弄错。
有很多方法可以解决这类问题,我鼓励您尝试几种。也许有一个网络输出红色和绿色图像,您可以在下游进行组合,或者也许网络输出一个所有像素都着色的图像。
“一个网络输出红色和绿色的图像,您可以在下游进行组合”:这很简单,但我没有想到……谢谢您的评论🙂
不客气,请告诉我您的进展。
我们能否存储模型状态并将其用于后续测试?
请建议我如何将状态存储到文件中,并将其用于后续。
可以,例如,使用pickle序列化状态LSTM变量。
你为什么要保存状态?
我将训练模型和测试模型分开编写,所以我想将encoder_inputs和encoder states馈送到推理模型,这就是为什么我想存储状态。
为了简单起见,我建议使用一个模型。
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.save(“seq2seq.h5”)
这里我正在从h5文件中加载模型。
model=model.load(seq2seq.h5)
之后,我使用pickle存储了训练模型的encoder_inputs、encoders_states。
接下来,我尝试使用encoder_inputs和encoder_states创建推理模型。
但我无法正确创建推理模型,我遇到了“图与输入层1断开连接”的问题。
encoder_model = Model(encoder_inputs, encoder_states
请建议我为什么会出现这个问题。
嘿,我遇到了同样的问题(我用R实现了一个seq 2 seq模型,但遇到了同样的问题),我用一个技巧解决了这个问题。
所以在训练完模型后,你可以使用keras的save model函数来保存它。然后我定义了一个函数来构建编码器模型,另一个函数来从我训练过的模型构建解码器模型。这是我的代码
这是R代码,但你可以将其改编为Python。技巧主要是创建新层并通过模型训练的权重进行设置。
谢谢分享,我添加了一些格式。
谢谢你的建议🙂
这应该能在Python中解决问题。
感谢分享!
是否‘s2s.h5’模型是你从编码器-解码器模型中保存的用于后续预测的唯一东西?
我的意思是,在主代码中,我们可以消除构建编码器接口和解码器接口,只保存模型吗?之后进行预测时,我们可以只通过‘s2s.h5’来检索和构建接口吗?
如果我这样做,我会收到这个错误
TypeError: Tensor objects are not iterable when eager execution is not enabled. To iterate over this tensor use tf.map_fn.
我的主要困惑是,我们是否必须在构建模型(训练)时构建编码器/解码器接口,还是不构建?
提前感谢!
当我构建编码器-解码器模型时,我收到这个错误
ValueError: Graph disconnected: cannot obtain value for tensor Tensor(“input_2:0”, shape=(None, None, 150, 150, 1), dtype=float32) at layer “input_2”. The following previous layers were accessed without issue: [‘input_1’]
你知道原因吗?
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Yating,你找到问题了吗?我的情况也一样,我运行的是 tensorflow 2.3。我猜这与 tensorflow 的版本有关。发生了一些奇怪的事情,当我运行笔记本单元格中的代码时,首先会出现错误,如果我再次运行该单元格,错误就会消失,但之后当我进行预测时,代码却无法运行。
嗨,Jason,
感谢这篇很棒的文章!我创建了一个 Tensorflow 实现。这提供了另一种关于 seq2seq 模型实现视角的看法。Tensorflow 实现的博客文章可以在 Data Blogger 上找到:https://www.data-blogger.com/2017/12/14/create-a-character-based-seq2seq-using-python-and-tensorflow/。
感谢分享 Kevin。
为了正确预测结果,我们可以为编码器和解码器添加更多 LSTM 层吗?
使用 Keras 为编码器和解码器添加更多层是一个好方法吗?
这会有帮助。试试看。
编码器和解码器模型是实现模型的良好方法,用于作为输入到模型的算法,输出是为指定语言生成源代码。
我正在尝试使用 Keras 的编码器和解码器模型来解决这个问题,这是一个好主意,还是有其他方法可以解决这个问题?
请给出建议。
我认为这是一个很好的起点。
嘿,首先感谢你的文章。我成功地设置了一个模型,只有一个编码器层和一个解码器层(都是 LSTM)。我想用多个 LSTM 层来训练我的模型。
我在解码器中添加了 1 个 LSTM 层,并用编码器的状态为它们都设置了状态。但是当我想要预测一个新序列时,输出非常糟糕。你有没有尝试过用 Keras 添加多个 LSTM?
你为什么不给编码器添加更多的 LSTM 层,可以知道原因吗?
实际上我也在尝试解决这个问题,请告诉我为什么你不给编码器添加更多的 LSTM 层,而是给解码器添加?
当我尝试创建复杂的模型时,我从基本模型开始,然后尝试改进它。
当然,你可以为编码器添加 8 层,为解码器添加 8 层。但我更喜欢一步一步地构建。我肯定会尝试为编码器添加层,但我认为这不会解决我的问题……解码器有 2 个 LSTM 的训练部分还可以,但问题在于当我尝试用推理模型预测某些内容时。
如何分享 2 个 LSTM 层的代码,你是如何实现的?我也尝试过 3 个 LSTM 层的编码器,以及 3 个 LSTM 层的解码器。但是创建推理解码器模型时,我遇到了形状问题。
如何分享 2 个 LSTM 层解码器的代码,你是如何实现的?我也尝试过 3 个 LSTM 层的编码器,以及 3 个 LSTM 层的解码器。但是创建推理解码器模型时,我遇到了形状问题。
为了使示例保持简单,我为编码器和解码器使用了一个层。
你需要调整模型,也许是更长的训练时间,新的批次大小和其他配置更改。
如何为编码器和解码器添加更多 LSTM 层?我在语法方面遇到一些麻烦。
请参阅这篇关于如何操作的教程。
https://machinelearning.org.cn/stacked-long-short-term-memory-networks/
给定测试用例,我需要为其生成一个脚本文件,我设法生成了还可以的结果。
但我想在我的测试用例中识别出哪些变量必须在脚本文件中也相同?请对此给出任何建议。
如何根据输入识别变量?
例如:定义一个整数变量 a : int a
定义一个整数变量 add : int add。
模型如何识别测试用例中的 a 和 add 变量?
请给出任何建议。
抱歉,我不太明白。
如果您在定义机器学习问题时遇到困难,也许这篇帖子会有帮助。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
通过为编码器和解码器模型添加更多 LSTM 层来提高准确性是一个好方法吗?
这可能是一个方法,取决于数据集。
感谢这篇帖子。它非常有帮助。
我们为什么只使用 10,000 个样本而不是 150,000 个样本?是因为内存需求巨大还是有其他原因?
是的,因为巨大的空间和时间复杂度。
感谢这个教程,它非常有帮助。在 https://blog.keras.org.cn/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html 中,他在 FAQ 部分提到了如何修改代码将其转换为 GRU seq2seq 模型,但他没有提到如何相应地修改推理模型,任何帮助都将非常感激,我在这里卡了很长时间了。再次感谢。
嗨 Soumil,
你是否解决了这个问题??
嗨,感谢教程。我们可以将此模型扩展到通用序列而不是仅语言模型吗?例如,输入和输出序列都是数值序列。感谢您的见解。
当然可以。
嗨 Jason,感谢这篇很棒的文章。
我想知道你为什么将输入填充为最大字符数为 16。我没有在模型中看到这个特定数字被明确引用。所以我想我可以将非填充输入提供给这个模型,序列到序列模型仍然会工作吗?
同样,如果我们填充输入和输出到一个有限的长度。我们不能只使用一个简单的序列分类架构,比如
inputs = Input(shape = (in_max_characters, in_char_vocab_size))
h1 = LSTM(128)(inputs)
outputs = TimeDistributed(Dense(output_char_vocab_size), input_shape = (out_max_characters, 128))
我的问题是关于填充在序列到序列模型中的概念和实际必要性。
我之前忘了在代码中添加 repeat vector。这是一个更新的版本。
inputs = Input(shape = (in_max_characters, in_char_vocab_size))
h1 = LSTM(128)(inputs)
h2 = RepeatVector(out_max_characters)(h1)
outputs = TimeDistributed(Dense(output_char_vocab_size), input_shape = (out_max_characters, 128))(h2)
对于这个模型,我认为不需要填充,因为它一次处理一个时间步。
嗨 Jason,非常感谢你的解释。
我想问一下模型的拟合。你是否提供了一个维度为 (10000,16,71) 的矩阵作为输入,并提供了一个维度为 (10000,59,93) 的矩阵作为输出?
在基于词的 sequence2sequence 模型(如 https://blog.keras.org.cn/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html 中所述)的情况下,他们引入了一个嵌入层。使用嵌入层,我该如何设置模型使其能够理解单个词是一个时间步?我是否应该将嵌入层的 input_dim 参数设置为 1,它会输出 (?,1,vocab_size)?或者我可以将嵌入层的 input_dim 参数设置为语料库句子的最大长度,它会输出 (?,maxlen,vocab_size)?
谢谢您的回复
使用嵌入层,你的输入将是一系列整数。嵌入层会将整数映射到高维向量。
因此,这篇帖子将帮助你重塑整数输入序列。
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
这有帮助吗?
是的,谢谢。
但是如果我有以下代码
i1=Input(shape=(2,))
emb=Embedding(input_dim=1, output_dim= 10 , input_length=1(i1) # tensor (num_sample, 2, 10)
lst=LSTM (16)(emb) # <- 是否有必要声明 input_shape?
在这种情况下,是否有必要声明 LSTM 的 input_shape?emb 是一个具有样本数、时间步和输出维度的 3D 张量。
非常感谢您的时间。
不,嵌入层会向 LSTM 层提供 3D 输入。
我正在使用序列到序列模型来预测给定文本文章的关键短语。我为此目的使用了与此博客中完全相同的模型。但是,我不确定在推理时是否会使用为模型训练的权重?
根据 GitHub 上的示例代码,在推理过程中,每个字符都需要被递归预测。为此,调用 encoder_model.predict() 来编码输入,调用 decoder_model.predict() 来预测输出。但是,在保存训练好的模型后,我们如何确保在推理时编码器模型和解码器模型使用了训练好的权重?
实际上,我得到的输出与输入无关。
也许保存的模型有问题。
也许可以尝试用一个小例子在内存中运行它,然后尝试保存/加载并重现结果,以确保没有错误。
很棒的教程。我想为图像创建一个序列到序列模型。
这是我的训练集的一个例子
x1 x2 x3 y1 y2 y3,其中 x1 x2 和 x3 是输入图像序列,y1, y2, 和 y3 是我想要预测的跟随图像序列。
我的问题是如何将 x1 x2 和 x3 表示为神经网络或编码器-解码器序列到序列模型的输入?
这听起来是一个具有挑战性的问题。也许你可以找到输出图像的模型示例,你可以用它们来做模型的输出部分。输入可以是修改过的 VGG 或类似网络。
非常感谢分享这篇很棒的文章,Jason。
我不理解推理模型。为什么在定义了编码器和解码器之后还需要推理模型?我们不是只需要定义编码器/解码器的输入/输出和结构,训练这个模型,然后用它来预测吗?现在非常困惑。预先感谢您的帮助。
在这里,我们使用了两个截然不同的模型,一个用于学习,一个用于进行预测。
鉴于需要在 Keras 中正确执行编码和解码,因此需要进行分离。
我建议编写包装函数来处理此类形式的模型训练/保存/加载/预测,以隐藏复杂性。
如何拟合模型?在你的 vanilla lstm 中,你使用了
model.fit(trainX, trainY, epochs=30, batch_size=64, validation_data=(testX, testY), callbacks=[checkpoint], verbose=2)
在这个模型中,等价物是什么?
这更复杂,这是一个例子。
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
为什么解码器输出比输入提前一个时间步?
George,你具体指的是什么?
Brownlee 博士,
首先,非常棒的教程!我收藏了您所有的文章。
我看了 https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py
其中包含这里的代码。在第 117 行,当他们创建解码器输出的目标值时,它说比解码器输入提前 1 个时间步。
你认为这是为什么?
抱歉,之前我没有说得足够具体。
对不起,George,我不知道。
这主要是因为我们想将解码器输入数据与解码器目标数据进行比较。所以解码器目标数据必须比解码器输入数据提前一个时间步。
你好 Jason,
在推理模式下,我们定义了一个 encoder_model
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
然后我们在这里使用这个模型
states_value = encoder_model.predict(input_seq)
我习惯于定义模型,然后编译和拟合,然后再用它进行预测。这里,我们只是定义模型然后预测。
显然,我遗漏了什么。你能详细说明一下这里后台发生了什么吗?
谢谢,
-MDB
我认为编译只适用于拟合 Keras 模型。
好的,谢谢 Jason。
在我的例子中,没有拟合。Jason,预测的权重是从哪里来的?
-MDB
来自仍在内存中的拟合模型。
嗨 Jason。我如何保存模型然后从保存的模型中再次使用它?
这里,一个好帖子(Github)和一个优秀帖子(这个)的区别。谢谢 amigo!
谢谢!
感谢这篇精彩的帖子。
我有一个问题,用于机器翻译的 LSTM 模型可以应用于对话生成吗?
如果可以,请告知我。如果可以,需要进行哪些主要的调整?
LSTM 可用作语言的生成模型,请参阅此处获取示例。
https://machinelearning.org.cn/?s=word+embedding&post_type=post&submit=Search
嗨 Jason,你的博客非常棒,我学到了很多,感谢你的开源工作!
我为此做了一些用于预测、回归任务的代码,但我也想理解其背后的数学原理。为什么在这种情况下我先使用 return sequence false,我的激活函数是什么?它们没有命名,在哪里可以知道默认的激活函数?提前感谢。
inputs = Input(shape=(时间步长, input_dim))
encoded = LSTM(n_dimensions, return_sequences=False, name=”encoder”)(inputs)
decoded = RepeatVector(时间步长)(encoded)
decoded = LSTM(input_dim, return_sequences=True, name=’decoder’)(decoded)
autoencoder = Model(inputs, decoded)
encoder = Model(inputs, encoded)
LSTM 和编码器-解码器不适合回归,除非你有一个输入和输出序列。
你可以在这里了解更多
https://machinelearning.org.cn/encoder-decoder-long-short-term-memory-networks/
我的输入是序列,100 个测量值,每个测量值包含 10,000 个数据点。我不理解的是,模型中内置的是哪种激活函数,在你的另一个链接中也没有提到函数是什么?
也许先使用默认值来评估模型性能?
嗨 Jason,抱歉误会了,但你抓住了重点。编码和解码层的默认激活函数是什么?
你可以在这里看到。
https://keras.org.cn/layers/recurrent/#lstm
你好 Jason,我该如何将其应用于双向架构?解码器部分一直出现错误
'ValueError: Dimensions must be equal, but are 256 and 512 for ‘lstm_2_1/MatMul_4’ (op: ‘MatMul’) with input shapes: [?,256], [512,512]。
‘
这里有一个创建双向 LSTM 的例子
https://machinelearning.org.cn/develop-bidirectional-lstm-sequence-classification-python-keras/
谢谢你,Jason。
没问题。
你好 Jason,当我尝试使用此模型时,我收到一个错误,要求 2 个输入数组。我知道这与这一行有关:model = Model([encoder_inputs, decoder_inputs], decoder_outputs),以及解码器部分。我有一个目标数组,我的模型应该最终对其进行编码和解码。但是如何在 model.fit(train, train…..) 中定义 decoder_inputs?
您能否确认您已精确复制所有代码?
你好 Jason,我刚开始学习 Python 和机器学习,没有 IT 背景,所以我的问题可能不够清晰,必要时我会稍后提供详细信息。我知道您评论说它不适合时间序列,但我仍然想看到我的结果。如何使用这个编码器-解码器模型进行滑动窗口处理?您能给我提供步骤或模块来说明如何进行吗?提前感谢。
我最好的建议在这里
https://machinelearning.org.cn/faq/single-faq/how-do-i-use-lstms-for-time-series-forecasting
这有帮助吗?
我有点困惑,因为我对机器学习是新手,您在这里描述的两个模型与您在此帖子中的模型有什么大的区别:https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
是的,链接的方法与研究论文中描述的方法定义相匹配。
上述方法是该方法的一种简化,更容易实现和理解,并且性能相似。
你好,先生,
我跟着你的教程,一切正常,直到我将模型训练到极限。我有 8GB 内存和另外 8GB 交换空间。我可以通过硬件监视器看到内存已满。有什么方法可以避免内存问题,或者可以一遍又一遍地重新训练模型来处理不同的数据集?附注:我对这些东西是新手🙂
===========================
使用 TensorFlow 后端。
英语词汇量:8773
英语最大长度:9
德语词汇量:15723
德语最大长度:17
回溯(最近一次调用)
文件“train_model.py”,第 85 行,在
trainY = encode_output(trainY, eng_vocab_size)
文件“train_model.py”,第 48 行,在 encode_output
y = array(ylist)
内存错误
听到这个消息我很难过。
也许可以尝试在 EC2 上运行示例,它有更多的 RAM?
也许可以尝试使用渐进式加载,而不是将所有数据加载到内存中?
训练时尝试使用更小的批次大小,例如 32 或 16。希望它能起作用。
嗨,Json,
我们如何查看模型的得分?我的意思是训练集上的精度、召回率……?
通常,我们使用 BLEU 或 ROGUE 等指标来评估 NMT 系统的性能。
嗨,Jason,
我读了你的博客,真的很容易理解。但有一件事让我很困惑,我在某个地方看到了一个带有 repeatvector 的 seq2seq 模型。您能告诉我区别吗?是否有任何论文描述了带推理的模型和带 repeatvector 的模型?提前感谢。
这是一个更简单的设计,其中每个时间步的输出仅取决于上下文向量。编码器的内部状态与解码器不共享。
实现起来更简单,并且效果与 Keras 一样好,甚至更好。
更多信息在这里
https://machinelearning.org.cn/encoder-decoder-long-short-term-memory-networks/
嗨,Jason,
非常感谢您提供的精彩教程。
我在接口模型的逻辑方面遇到了一个非常大的问题。
接口模型将预测我们没有标签的数据的标签,我说对了吗?
那么,decode_sequence(input_seq)
我们有这个
# 生成长度为 1 的空目标序列。
target_seq = np.zeros((1, 1, num_decoder_tokens))
# 使用起始字符填充目标序列的第一个字符。
target_seq[0, 0, target_token_index[‘\t’]] = 1.
第二个输入(我们解码器的输入)在此处设置为 [1, 0, 0, ..., 0]。意味着一个零序列。另一方面,这个输入在预测目标序列方面很有影响力。
我们该如何做到这一点?我的意思是,为什么我们在知道它将用于预测输出数据时,将输入解码器设置为这样?
当然,我期望因为这是一个零向量,不管编码器状态如何,模型都会将所有内容欠拟合到零,而这正是我现在的情况!
也许试试这个更简单的方法
https://machinelearning.org.cn/encoder-decoder-long-short-term-memory-networks/
我刚注意到解码器的性质是设计为一次解码一个 token。这意味着它不接受 token 序列并预测 token 序列。
话虽如此,解码器输入用于跟踪在时间步长中发现的每个 token,因此它只有预测下一个 token 的起点。
明白了!
谢谢 Jason!你的博客是我向所有人推荐的第一选择!
正确。
你好,我需要一个单独的编码器和三个从它并行分支出来的解码器。有人能建议如何编写吗?
尝试多输出模型
https://machinelearning.org.cn/keras-functional-api-deep-learning/
潜在维度(latent dim)是什么意思?我该如何找到适合我的问题的值?
也许可以试试这个更简单的教程
https://machinelearning.org.cn/develop-neural-machine-translation-system-keras/
你好 Jason 🙂
非常感谢您的教程,它非常有帮助
我仍然是深度学习的新手……我尝试在数据集上训练模型,但我想知道如何重新加载我保存的模型以在新数据集上进行测试?
我在这里提供了保存和加载 Keras 模型的示例
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
这是我见过的关于 sequence2sequence 的最好的教程之一!
只有一个疑问,推理模型是如何连接到我们训练的实际模型的?在进行预测时,如果我尝试加载先前训练的模型,结果与训练时不同。基本上,我不清楚模型、encoder_model 和 decoder_model 是如何链接的?
这可能是一个重复的查询,但我没有找到任何答案。任何帮助都将不胜感激。提前感谢!
它们通过使用相同的权重链接,但接口不同。
你好 Jason,编码器中是否存在反向传播?如果存在,那么损失函数是如何计算的,因为我们没有任何目标变量?
是的,我们从输出到解码器再到编码器进行反向传播。
你好 Jason,
感谢您的快速回复,但我的问题更多。
在编码器步骤中,我们将为给定的输入句子(在机器翻译的情况下)创建一个思想向量并将其提供给解码器。那么在反向传播期间,在编码器中我们没有进行任何预测,为什么我们需要更新权重?
*希望您能对此进行简要说明,因为我找不到任何解释 Seq2Seq 模型中反向传播的材料。*
谢谢!
可以将其视为一个大型模型,错误会像任何其他神经网络一样向后传播。
你好,
感谢您提供如此出色的教程。您能否为我们共享堆叠层的代码?从我看到的情况来看,我们中的许多人都很难堆叠解码器和编码器。
我像这样堆叠了编码器
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_hidden = LSTM(latent_dim, return_state=True, return_sequences=True)(encoder_inputs)
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_hidden)
以及像这样堆叠解码器
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# 我们将解码器设置为返回完整的输出序列,
# 并返回内部状态。我们在训练模型中不使用
# 返回状态,但在推理时会使用它们。
decoder_hidden = LSTM(latent_dim, return_sequences=True, return_state=True)(decoder_inputs,
initial_state=encoder_states)
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_hidden)
问题在于推理,模型似乎在训练,但我在推理时得到了奇怪的结果。
您能否发布您在训练和推理期间如何堆叠其他层?
谢谢
我正在从事 Seq2Sql(自然语言到 SQL)项目,并且我需要检测问题中的特定单词
例如:Rick 的姓是什么?
对于这个例子,Rick 应该被检测为所需的单词。
SELECT last_name FROM student WHERE first_name=’Rick’ ; 以及列名
例如:Leo 多大了?
对于这个例子,Leo 应该被检测为所需的单词。
我该如何编写一个机器学习程序来检测任何问题中的这些词?请帮助。
我已经编写了从 select 列检测模型,但在 where 子句处遇到了问题。
您将需要数千或数百万个输入和输出示例来学习。
也许可以对输入和输出进行词级别建模?
我想将这些编码器和解码器模型存储到另一台机器上,而无需训练输入样本,我可以直接输入输入样本进行预测,它应该能立即预测,
请提供建议。
这篇帖子向您展示了如何保存
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
从 model.load(“model.h5”) 加载模型后,我们是否仍需要编译模型,或者可以直接使用它。
我相信您不再需要在加载后编译模型。
我对如何测试模型感到困惑。我所做的是进行交叉验证,但模型总是为测试数据返回无意义的输出。但对于训练数据却给出极好的输出。我的训练准确率约为 99%,验证数据约为 97%。但测试数据不佳。有什么想法吗?谢谢
准确率是 NLP 问题的一个糟糕衡量标准,我建议您使用 BLEU 或类似的指标。
你好 Jason,
我们使用了 lstm_seq2seq 模型,没有对模型进行任何更改。使用的数据集与 fra-eng(在 http://www.manythings.org/anki/fra-eng.zip 中)相同,除了输出等于输入,即 eng-eng。
该模型在短句(长度 1 或 2)上取得了不错的结果,但在长句(大于 3)上的结果不佳。
好的结果示例
输入:Got it 输出:Got it
输入:Got it 输出:Got it
坏结果示例
输入:Is anybody here? 输出:Is anyobe youre?
输入:It was fabulous. 输出:It was afbucky.
也许可以确认您的库是最新的?
也许可以尝试重新拟合模型几次?
谢谢 Jason 的回答
当然。
我们尝试了不同的模型,例如具有 512 和 1024 个神经元、2 层和 4 层的模型。但输出没有显著变化!!!
也许可以尝试调整优化算法的参数,例如学习率等。
Jason 我想设计一个用于文本到向量表示的模型。每个文本文件表示为一个向量。我尝试实现 seq2seq 编码器-解码器 LSTM,然后为每个文本获取编码器向量。但我失败了!
你能帮我吗?
听起来是个不错的方法。具体是什么问题?
老师,我的问题是这里我们对句子或序列中的每个字符进行了独热编码,我们可以使用 word2vec 或 GloVe 等词嵌入吗?因为 GloVe 适合使用,因为我们没有进行任何语义相似性。我想将我的单词嵌入到 GloVe 嵌入中,然后将它们发送给编码器。如果我不使用独热编码进行矢量化,而是使用词级别嵌入,那会如何工作?
谢谢
也许您可以使用字符嵌入,我没有示例,抱歉。
你好,
好帖子。
这里的损失函数是什么?如果我使用 RNN 编码器-解码器进行时间序列分析,可以使用与自编码器相同的损失函数(重构损失 + 正则化损失)吗?谢谢,
没有损失函数,我们只是在解释一个架构。
更多关于损失函数的信息
https://machinelearning.org.cn/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/
谢谢你。
是损失函数在进行降维,还是隐藏层的数量?我猜我们必须使用条件概率来查找解码器中的下一个最佳单词(使用束搜索)?如果可能创建一个从头开始解释 RNN 编码器-解码器完整实现的帖子,那将非常棒!谢谢,
我确实有很多,也许可以从这里开始
https://machinelearning.org.cn/start-here/#lstm
你好 Sangeet,
我也在为我的项目做类似的事情。
您是否能够计算解码器处的条件概率来预测序列?
谢谢
我是一名博士生,我正在研究语义索引。此外,我需要一个针对英语到任何语言的 seq2seq 训练模型供我的工作使用。我在哪里可以找到一个?
抱歉,我不知道,也许可以尝试谷歌搜索?
你好,Brownlee 博士。
我对序列到序列模型的确切工作原理感到有些困惑,特别是如何确定解码器 RNN 单元的数量。
对于基于单词的英法翻译,例如,是否必须使解码器单元的数量适合最长的法语句子(例如,最长的目标实例)?那么生成的可能的最长句子与训练数据中最长的目标实例相同吗?
好问题,我推荐使用这种基于 LSTM 自编码器的更简单的方法
https://machinelearning.org.cn/develop-neural-machine-translation-system-keras/
您是如何得出 latent_dim 为 256 的?这个数字的目的是什么/重要性是什么?
这是任意的。更多信息请看这里
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
输出的维度必须与输入的维度相同吗?例如,我的输入维度可以是 (n_samples, 120 steps per sample, 20 features),输出可以是 (n_samples, 7 steps per sample) 吗?
也就是说,我使用 120 个时间步,每个时间步有 20 个特征来预测 7 个时间步,而我不需要这些特征。
不行。
输入和输出的长度可以使用编码器-解码器模型变化。
那么我的 decoder_input 会是什么样的?它会是 Input(shape=(None,)) 还是 Input(batch_shape=(None, 7)) ?
输入形状与输出形状无关。听起来您的输入形状将是 [n, 120, 20],输出形状将是 [n, 7]。
是的——抱歉造成了困扰——我正在尝试弄清楚我的解码器层的输入应该是什么样的,我尝试了几种方法,但遇到了维度错误。
AttributeError Traceback (最近一次调用)
in
9 latent_dim = 256
10 # 定义一个输入序列并对其进行处理。
—> 11 encoder_inputs = Input(shape=(None, num_encoder_tokens))
12 encoder = LSTM(latent_dim, return_state=True)
13 encoder_outputs, state_h, state_c = encoder(encoder_inputs)
~\Anaconda3\lib\site-packages\keras\engine\input_layer.py in Input(shape, batch_shape, name, dtype, sparse, tensor)
176 name=name, dtype=dtype,
177 sparse=sparse,
–> 178 input_tensor=tensor)
179 # 返回包括 _keras_shape 和 _keras_history 在内的张量。
180 # 请注意,在这种情况下,train_output 和 test_output 是相同的指针。
~\Anaconda3\lib\site-packages\keras\legacy\interfaces.py 中的 wrapper(*args, **kwargs)
89 warnings.warn(‘Update your
' + object_name + 'call to the ‘ +90 ‘Keras 2 API: ‘ + signature, stacklevel=2)
—> 91 return func(*args, **kwargs)
92 wrapper._original_function = func
93 return wrapper
~\Anaconda3\lib\site-packages\keras\engine\input_layer.py in __init__(self, input_shape, batch_size, batch_input_shape, dtype, input_tensor, sparse, name)
37 if not name
38 prefix = ‘input’
—> 39 name = prefix + ‘_’ + str(K.get_uid(prefix))
40 super(InputLayer, self).__init__(dtype=dtype, name=name)
41
~\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py in get_uid(prefix)
72 “””
73 global _GRAPH_UID_DICTS
—> 74 graph = tf.get_default_graph()
75 if graph not in _GRAPH_UID_DICTS
76 _GRAPH_UID_DICTS[graph] = defaultdict(int)
AttributeError: 模块‘tensorflow’没有属性‘get_default_graph’
我运行上面的代码时遇到了这种错误
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
from keras.utils.vis_utils import plot_model
# 配置
num_encoder_tokens = 71
num_decoder_tokens = 93
latent_dim = 256
# 定义输入序列并处理。
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# 我们丢弃
encoder_outputs,只保留状态。encoder_states = [state_h, state_c]
# 设置解码器,使用
encoder_states作为初始状态。decoder_inputs = Input(shape=(None, num_decoder_tokens))
# 我们将解码器设置为返回完整的输出序列,
# 并返回内部状态。我们在训练模型中不使用
# 返回状态,但在推理时会使用它们。
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation=’softmax’)
decoder_outputs = decoder_dense(decoder_outputs)
# 定义将
#
encoder_input_data&decoder_input_data转换为decoder_target_data的模型model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 绘制模型
plot_model(model, to_file=’model.png’, show_shapes=True)
# 定义编码器推理模型
encoder_model = Model(encoder_inputs, encoder_states)
# 定义解码器推理模型
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
# 总结模型
plot_model(encoder_model, to_file=’encoder_model.png’, show_shapes=True)
plot_model(decoder_model, to_file=’decoder_model.png’, show_shapes=True)
很遗憾听到这个消息,我以前没见过这个错误。
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨,Jason,
我知道 BLEU 分数是这类问题的常见指标,因为多个不同的翻译都可以被认为是正确的。由于准确率是一个糟糕的度量,您如何在训练和验证步骤中按 epoch 数来衡量损失?该图会无法解读吗?
如果它无法解读,那么测试这种模型结构下的过拟合/欠拟合有什么好的方法?
祝好,
Kyle
好问题,Kyle。
损失仍然是衡量模型拟合程度的可靠指标,因为它是 SGD 正在优化的指标。
嗨,Jason,
只是一个小问题……
如果我们有 250 个输入到编码器-解码器模型的基数,我们可以定义 LSTM 潜在维度大小大于 250 还是需要更小才能压缩?
例如,LSTM 隐藏单元的数量为 400 或 600?
尝试不同的单元数量并比较性能。
嗨,Jason,
当使用大于输入序列基数的 LSTM 单元进行测试时,自编码器表现更好。我们从中可以得到什么直观感受?
过度参数化 + 正则化非常强大。
谢谢 Jason。
你好,Jason。
这是一篇很棒的文章,感谢您发布了如此精彩的内容。
我正在使用 GloVe 嵌入研究抽象文本摘要。
自编码器用于编码目的。
执行完上述代码后,我该如何获得摘要文本?
配置的前 3 行如下所示:
# 配置
num_encoder_tokens = EMBED_SIZE #EMBED_SIZE = 50
num_decoder_tokens = 93
latent_dim = LATENT_SIZE #Y-Dimension of the sentence vector
代码片段:-
encoding_0 = encoder_model.predict(next(test_gen)[0])
encoding_1 = encoder_model.predict(next(test_gen)[1])
我的简单问题是,在定义了解码器推理模型后,如何获得摘要文本?
因为在使用 decoder_moel.predict(np.array(next(predict_gen))) 后,
我收到了以下错误:-
ValueError: Error when checking model : the list of Numpy arrays that you are passing to your model is not the size the model expected. Expected to see 3 array(s), but instead got the following list of 1 arrays: [array([[[ 0. , 0. , 0. , …, 0. ,
0. , 0. ],
[ 0. , 0. , 0. , …, 0. ,
0. , 0. ],
您能帮帮我吗。
谢谢。
错误表明输入的形状不符合模型的预期。
您可以更改输入或更改模型。
谢谢 Jason。
我解决了这个问题。
很高兴听到这个消息。
你好..很棒的文章和评论…一个新手问题…我们如何决定可变 latent_dim?
也许是试错法。
我有一个问题,也许是个愚蠢的问题。
遵循您的帖子和这个例子
https://github.com/keras-team/keras/blob/master/examples/lstm_seq2seq.py
如果您创建了编码器-解码器模型。然后您训练模型并保存权重
model.save(‘s2s.h5’)
当我们想加载权重时,我们应该
– 重新创建模型。
– 将权重加载到模型中(而不是训练它)-> model.load_weights(‘s2s.h5’)
– 进行预测???
还有别的需要吗?
这是我的疑问。预测模型(encoder_model & decoder_model)如何访问训练?
是否有必要做些什么让预测模型(encoder_model & decoder_model)具有训练过的权重?
救命,我在这件事上迷失了!
您可以一起保存权重和模型。无需重新创建模型。
所以,是的,但保存一个文件,加载一个文件,进行预测。这里有一个例子
https://machinelearning.org.cn/save-load-keras-deep-learning-models/
不需要访问训练,学习已经发生并包含在权重中。
对于解码器输入,为什么我们考虑法语文本?难道不应该只是编码器的返回状态吗?
了解之前生成的内容很有用。
这似乎是教师强制方法?有没有不使用教师强制方法的实现?
是的,会的。
不,我相信我所有的例子都使用了教师强制——因为它非常有效。
嗨,Jason,
我想知道如何将 lstm 代码更改为 gru 代码,我知道 gru 只有一个状态,所以我更改了下面的代码
“””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = GRU(latent_dim, return_state=True)
encoder_outputs, encoder_states = encoder(encoder_inputs)
decoder_inputs = Input(shape=(None, num_encoder_tokens))
decoder_gru = GRU(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _= decoder_gru(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_encoder_tokens, activation=’softmax’)
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer=’rmsprop’, loss=’categorical_crossentropy’,
metrics=['accuracy'])
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=5,
validation_split=0.2)
model.save(‘s2s.h5’)
encoder_model = Model(encoder_inputs, encoder_states)
decoder_states_inputs = Input(shape=(latent_dim,))
decoder_outputs, decoder_states = decoder_gru(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states) #error
“”””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””””
我在我输入的代码末尾遇到了错误“#error”。
这是我得到的:ValueError: Dimensions must be equal, but are 98 and 256 for ‘add_3’ (op: ‘Add’) with input shapes: [1,?,?,98], [?,256]。
很遗憾听到这个消息,我有一些建议可能会有帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
您检查过验证数据集的准确率吗?当我设置 model.fit() 和 validation_split=0.2 时,准确率低于 88%。顺便说一下,我想提高这个数字,所以我堆叠了 LSTM 层。我还尝试使用 dropout 和其他优化器。但是情况变得更糟了。您能给我一些关于如何改进结果的建议吗?此外,对于教师强制,我们不需要设置编码器 LSTM 的 initial_state 吗?
是的,我在这里有一些建议
https://machinelearning.org.cn/start-here/#better
非常感谢您的快速回复。顺便说一句,我想知道您是否尝试过改进此帖子中模型的性能(LSTM seq2seq)。
是的,那里的建议包含了很多好主意,也许可以从这个开始
https://machinelearning.org.cn/improve-deep-learning-performance/
您好。
我该如何向此代码添加“注意力”?
我无法将“decoderattention”应用于此代码。
谢谢。
是的。抱歉,我没有示例。
嗨,Jason,
我很好奇“{decoder_inputs] + decoder_states_inputs”这行在编码器-解码器模型中很常见。这是将解码器输入与编码器的单元状态一起初始化吗?“+”号后跟“[decoder_inputs]”是否允许我们进行这种初始化?
一如既往,您文章的详尽和信息丰富让我赞叹不已。我非常感谢您的工作。
它会连接列表/数组。
嗨,Jason,
您能告诉我如何将可变长度的整数编码输入传递给以下模型吗?
il = Input(shape=(None,))
el = Embedding(len(train_vocabulary), 64)(il)
gl = GRU(64)(el)
ol = Dense(3, activation=”sigmoid”)(gl)
classification_model = Model(inputs=il, outputs=ol)
我将输入准备成列表的列表,其中子列表的长度不同,但我无法将它们传递给模型。但是,如果我使用填充,一切都会正常工作。那么,是否无法在没有填充的情况下使用可变长度?
您必须使用零填充。
也许看看这个
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
嗨,Jason,
我正在使用 glove 向量和 400,000 的 vocab_size,并且使用了大约 10,000 个训练示例
decoder_output 需要独热编码,这会导致内存不足错误。
我该如何解决这个问题?
也许使用更小的词汇量?
也许尝试在一台拥有更多 RAM 的机器上运行(AWS ec2)?
谢谢 Jason。
我还有一个疑问
为什么我们需要推理模型或解码模型来进行测试?训练有什么帮助?我唯一能看到的是它有助于确定编码器输入。我是否遗漏了什么?在我看来,训练的全部意义都消失了。
嗨 Jason
是否有任何用于语音转文本的预训练 seq to seq 模型?需要了解如何通过迁移学习技术进行使用。是否有任何链接包含示例?
我认为有,也许可以看看
https://hugging-face.cn/
你好 Jason,只是想问一个小问题
在推理模型部分,当模型被初始化时,解码器的隐藏状态和单元状态要与输出一起返回,我完全理解为什么。我不清楚的是 decoder_outputs 和 decoder_state 之间的加法。我认为 decoder_outputs 和 decoder_state 都代表不同的值,它们将在下一次递归调用解码器时使用,那么将它们相加作为一个量意味着什么?谢谢。
正确。
h 被称为隐藏状态,但它实际上只是层的输出。
c 是层的内部隐藏状态。
这些来自编码器的上一个时间步,并作为输入/初始化传递给解码器。
希望这能有所帮助,也许可以尝试跟踪变量以查看它们是如何使用的。
我可能有一个线索,如果我错了请纠正我。这是因为它与 LSTM 单元的计算方式有关吗?
是的,我建议查看该主题的原始论文。
你好!Jason,这篇文章中的 seq2seq 架构与您在《Python 中的 LSTMs》一书的第 111 页,第 9.3 章中的 seq2seq 架构有什么区别?
这本书中的架构使用了 RepeatVector 和 TimeDistributed 层。上面的架构使用了 return states 并创建了独立的编码器和解码器。两种架构的结果相同吗?您能否向我解释一下区别以及何时选择其中一种更好?这两种架构都是 seq2seq,都可以用于语言翻译吗?提前感谢。
好问题。
书中的示例简单高效,基于 LSTM 自编码器。我推荐这种方法。
上面的示例要复杂得多,并且基于动态 rnn,更接近原始的编码器-解码器论文。
在我看来,两者的实际性能似乎都差不多。
“Dense 层不需要包装在 TimeDistributed 层中” – 这是为什么?
我们不需要为每个时间步输出字符吗?当我们将 Dense 层添加到其中时,它是否只应用于 lstm 的最后一个时间步输出,因此我们最终只得到一个字符预测而不是整个句子。为什么会起作用?您能解释一下吗,Jason?
Dense 层将为 LSTM 输出时间步输出一个值。
你好,
在我的序列到序列模型中,我必须并行传递 n 个数据点进行推理,如何做到?
一个样本可以有多个时间步和多个特征。
你好。Jason
我们需要在每个 time_step(max_len) 的循环中运行解码器,然后使用每个解码器的输出来作为下一个解码器的输入。为了实现这一点,我应用了一个 for 循环。您是如何使用您的训练代码实现此机制的?您的代码是否处理了该机制?如果处理了,是如何处理的?
我明白了 Jason…您使用的是教师强制。如果我说错了请纠正我。非常好的博客 Jason。
是的。
请看这个例子
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
谢谢您的时间。
不客气。
嗨 Jason,您提到“为训练定义的模型已经学习了该操作的权重,但模型的结构并非设计为可以递归调用以一次生成一个字符。”
在定义推理模型的结构时,您能否指出具体是哪几行代码表明我们将使用训练模型的已学习权重?似乎推理模型的代码根本没有提及训练模型?
嗨 Echo…最后的代码列表可以用于基于定义和训练模型的先前步骤进行实际预测。在这种特定情况下,最后一部分并未显示。我鼓励您为自己的目的扩展该示例,并告诉我们您对模型准确性的发现。