Weka 是学习机器学习的绝佳平台。它提供了一个图形用户界面,用于在数据集上探索和试验机器学习算法,而无需您担心数学或编程。
Weka 的一个强大功能是 Weka Experimenter 界面。与用于过滤数据和尝试不同算法的 Weka Explorer 不同,Experimenter 用于设计和运行实验。它产生的实验结果是可靠的,并且足以发表(如果您知道自己在做什么)。
在上一篇文章中,您了解了如何在 Weka Explorer 中运行您的第一个分类器。
在这篇文章中,您将发现 Weka Experimenter 的强大功能。如果您按照分步说明进行操作,您将在不到五分钟的时间内设计并运行您的第一个机器学习实验。
使用我的新书《使用 Weka 进行机器学习精通》来
启动您的项目
,其中包含分步教程和所有示例的清晰屏幕截图。
第一个实验
照片由 mhofstrand 拍摄,保留部分权利
1. 下载并安装 Weka
访问Weka下载页面,找到适合您电脑的版本(Windows、Mac或Linux)。
Weka 需要 Java。您可能已经安装了 Java,如果没有,下载页面上列出的 Weka 版本(适用于 Windows)包含 Java 并会为您安装。我自己使用的是 Mac,就像 Mac 上其他一切一样,Weka 开箱即用。
如果您对机器学习感兴趣,那么我知道您一定能弄清楚如何下载和安装软件到自己的电脑。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
2. 启动Weka
启动Weka。这可能涉及在程序启动器中找到它,或双击 weka.jar 文件。这将启动 Weka GUI 选择器。
Weka GUI 选择器
Weka GUI 选择器让您可以选择 Explorer、Experimenter、KnowledgeExplorer 和 Simple CLI(命令行界面)中的一个。
单击“Experimenter”按钮启动 Weka Experimenter。
Weka Experimenter允许您设计自己的在数据集上运行算法的实验,运行实验并分析结果。它是一个强大的工具。
3. 设计实验
单击“New”按钮创建一个新的实验配置。
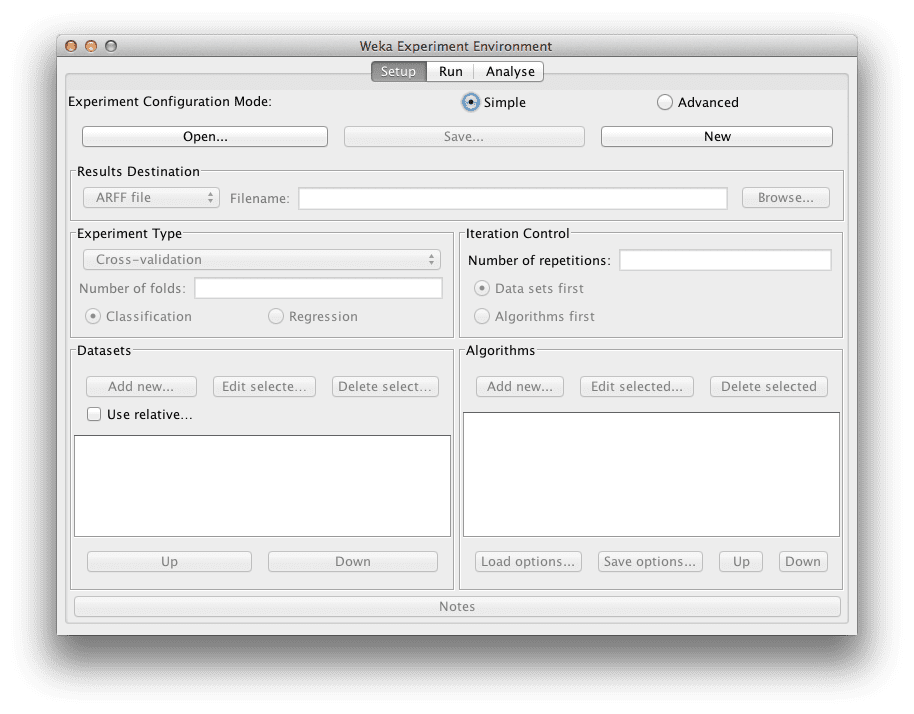
Weka Experimenter
开始新的实验
测试选项
Experimenter 会使用合理的默认值为您配置测试选项。该实验配置使用 10 折交叉验证。这是一个“分类”类型的问题,每个算法+数据集组合会运行 10 次(迭代控制)。
鸢尾花数据集
让我们先选择数据集。
- 在“Datasets”选择框中,单击“Add new…”按钮。
- 打开“data”目录并选择“iris.arff”数据集。
鸢尾花数据集是一个著名的统计学数据集,被机器学习研究人员广泛借用。它包含 150 个实例(行)和 4 个属性(列)以及用于鸢尾花种类(setosa、versicolor、virginica 之一)的类别属性。您可以在维基百科上阅读更多关于鸢尾花数据集的信息。
让我们选择 3 种算法来运行我们的数据集。
ZeroR
- 在“Algorithms”部分单击“Add new…”。
- 单击“Choose”按钮。
- 在“rules”选择框下单击“ZeroR”。
ZeroR 是我们可以运行的最简单的算法。它选择数据集中数量最多的类别值,并将其用于所有预测。鉴于所有三个类别值的比例相等(各 50 个实例),它选择第一个类别值“setosa”,并将其作为所有预测的答案。仅凭常识,我们知道 ZeroR 能给出的最佳结果是 33.33%(50/150)。这很好,可以作为我们要求算法超越的基准。
OneR
- 在“Algorithms”部分单击“Add new…”。
- 单击“Choose”按钮。
- 在“rules”选择框下单击“OneR”。
OneR 就像我们的第二简单的算法。它选择一个与类别值最相关的属性,并对其进行拆分以获得最佳预测精度。与 ZeroR 算法一样,该算法非常简单,您可以手动实现它,我们期望更复杂的算法能超越它。
J48
- 在“Algorithms”部分单击“Add new…”。
- 单击“Choose”按钮。
- 在“trees”选择框下单击“J48”。
J48 是一个决策树算法。它是 Java 中 C4.8 算法的实现(“J”代表 Java,48 代表 C4.8)。C4.8 算法是著名的 C4.5 算法的一个小扩展,它是一种非常强大的预测算法。
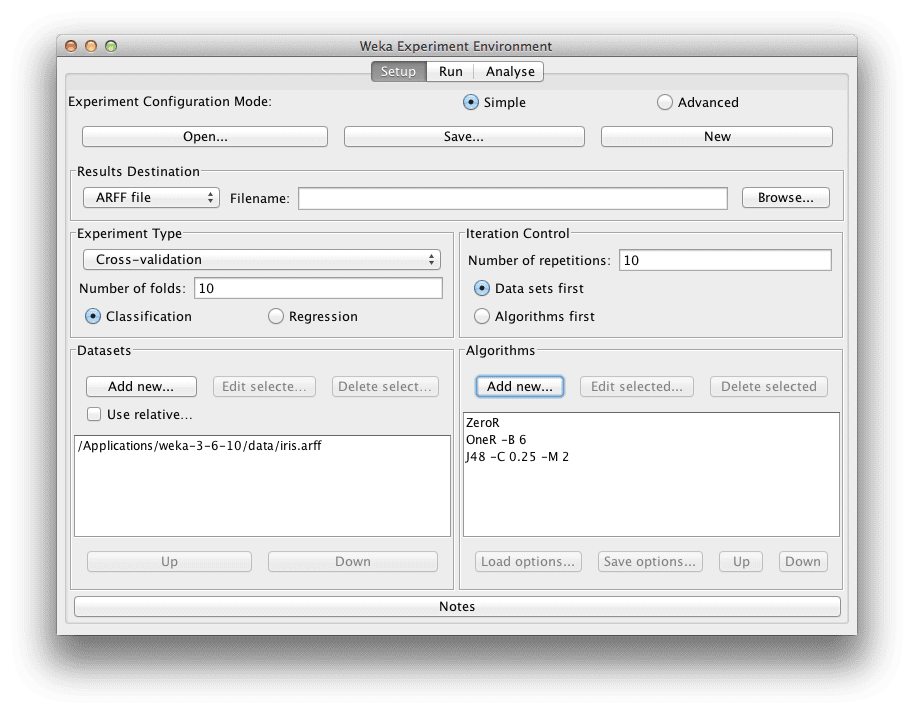
Weka Experimenter
配置实验
我们已准备好运行我们的实验。
4. 运行实验
单击屏幕顶部的“Run”选项卡。
此标签页是运行当前配置的实验的控制面板。
单击大的“Start”按钮开始实验,并关注“Log”和“Status”部分,以了解其运行情况。
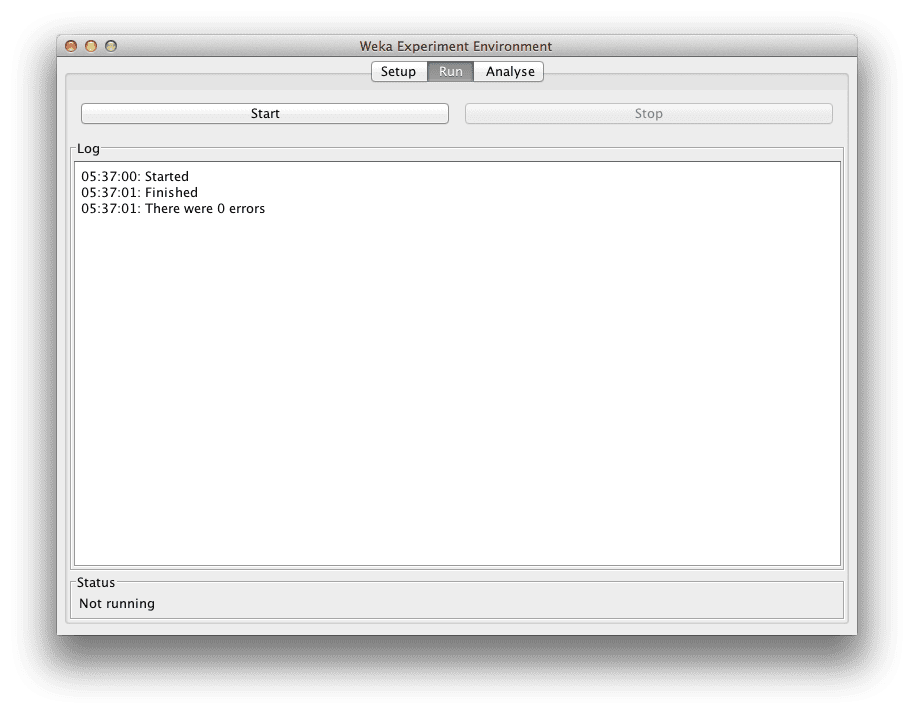
Weka Experimenter
运行实验
鉴于数据集很小且算法速度很快,实验应在几秒钟内完成。
5. 审阅结果
单击屏幕顶部的“Analyse”选项卡。
这将打开实验结果分析面板。
Weka Experimenter
加载实验结果
在“Source”部分单击“Experiment”按钮加载当前实验的结果。
算法排名
我们首先想知道哪个算法是最好的。我们可以通过算法击败其他算法的次数来对算法进行排名。
- 单击“Test base”的“Select”按钮,然后选择“Ranking”。
- 现在单击“Perform test”按钮。
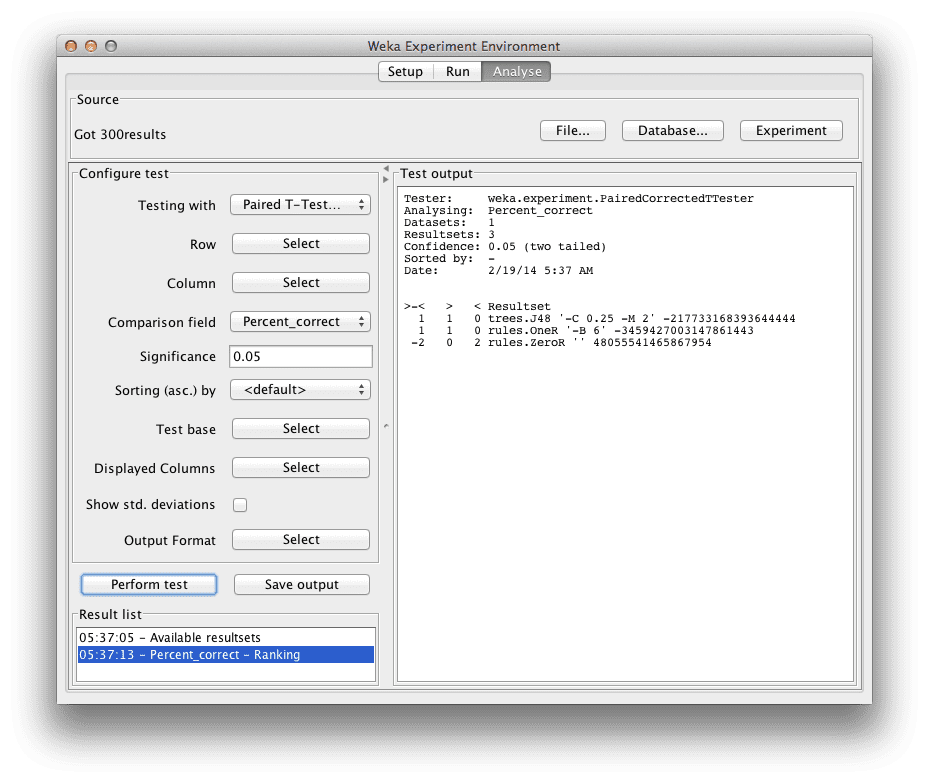
Weka Experimenter
对实验结果中的算法进行排名
排名表显示了每个算法在数据集中相对于所有其他算法的统计学上显著的获胜次数。获胜意味着准确率优于另一个算法的准确率,并且差异在统计学上是显著的。
我们可以看到 J48 和 OneR 都各有一次获胜,而 ZeroR 则有两次失败。这很好,这意味着 OneR 和 J48 都可能超越我们的 ZeroR 基准。
算法准确率
接下来,我们想知道算法取得了什么样的分数。
- 单击“Test base”的“Select”按钮,然后在列表中选择“ZeroR”算法,然后单击“Select”按钮。
- 单击“Show std. deviations”旁边的复选框。
- 现在单击“Perform test”按钮。
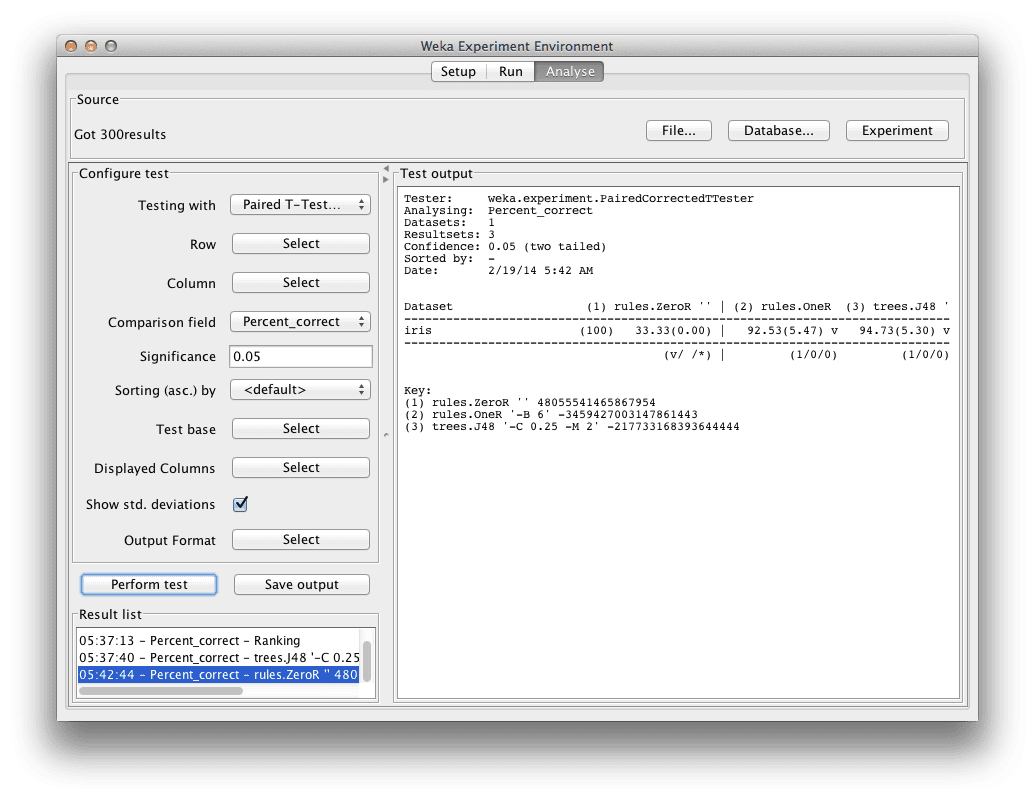
Weka Experimenter
算法精度与 ZeroR 的比较
在“Test output”中,我们可以看到一个包含 3 种算法结果的表格。每种算法都在数据集上运行了 10 次,报告的准确率是这 10 次运行的平均值和标准差(以百分比表示)。
我们可以看到 OneR 和 J48 算法的结果旁边都有一个小“v”。这意味着这些算法的准确率与 ZeroR 相比存在统计学上的显著差异。我们还可以看到这些算法的准确率与 ZeroR 相比很高,因此我们可以说这两种算法取得了比 ZeroR 基准显著更好的结果。
J48 的得分高于 OneR 的得分,所以接下来我们想看看这两个准确率得分之间的差异是否显著。
- 单击“Test base”的“Select”按钮,然后在列表中选择“J48”算法,然后单击“Select”按钮。
- 现在单击“Perform test”按钮。
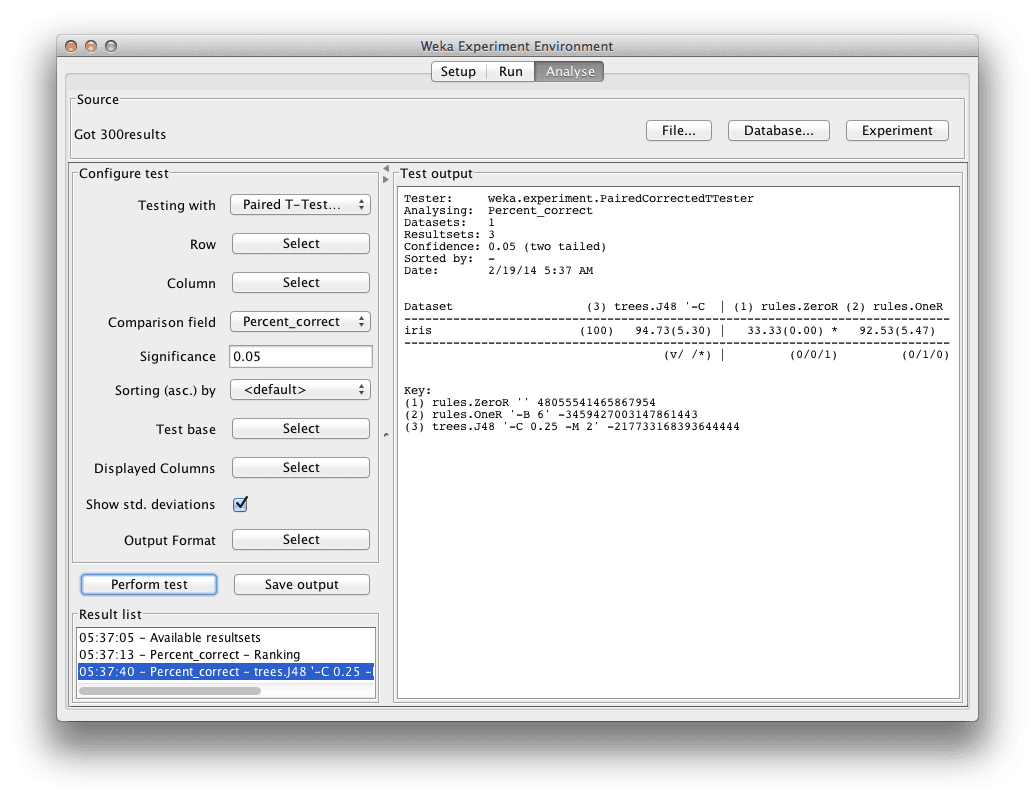
Weka Experimenter
算法精度与 J48 的比较
我们可以看到 ZeroR 的结果旁边有一个“*”,表示其结果与 J48 相比存在统计学上的差异。但我们已经知道了。我们没有在 OneR 算法的结果旁边看到“*”。这告诉我们,尽管 J48 和 OneR 之间的平均准确率不同,但这种差异在统计学上并不显著。
在其他条件相同的情况下,我们将选择 OneR 算法来解决这个问题,因为它比这两种算法更简单。
如果我们想报告结果,我们会说 OneR 算法的分类准确率为 92.53%(+/- 5.47%),这比 ZeroR 的 33.33%(+/- 5.47%)在统计学上显著更好。
总结
您已了解如何在 Weka 中使用一个数据集和三种算法配置机器学习实验。您还了解了如何分析实验结果以及在解释结果时统计显著性的重要性。
您现在已经掌握了在您选择的数据集上使用 Weka 提供的任何算法设计和运行实验的技能,并且能够有意义且自信地报告您取得的结果。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。





")
嗨
感谢教程。您能否解释一下 Weka 实验中迭代控制面板中的“数据集优先”和“算法优先”的意义?
尊敬的先生,
我对您的笔记很满意。
我对机器学习也很感兴趣……我需要知道如何对卫星图像进行分类。
WEKA 有多重回归算法吗?
是的,它有一个,叫做 SimpleLinearRegression。
在您的笔记末尾,您写道:
“如果我们想报告结果,我们会说 OneR 算法的分类准确率为 92.53%(+/- 5.47%),这比 ZeroR 的 33.33%(+/- 5.47%)在统计学上显著更好。”
将 ZeroR 的标准差报告为“(+/- 5.47%)”是否正确?因为当我运行实验时,ZeroR 的结果是 33.33%(+/- 0.00%)。
你好 Om,报告标准差和平均性能,在本例中是准确率,是一个好习惯。
这一切有什么好处?核心思想是什么?
你好 Mah,
好处是发现算法、算法配置和数据集表示的组合,从而在您的项目中获得更好的/最佳的预测性能。
是否也可以比较关联规则挖掘算法?
也许可以,您需要一个客观的技能衡量标准。抱歉,我没有做过,也许 Experimenter 没有为此设置。
请列出 2010 年后提出和开发的四种最先进的算法,并且也在 weka 中实现?
抱歉,我不知道。
Jason,您的教程非常有用。我几个月前下载了 weka,但由于专注于 PYTHON,我不知道它是一个强大的工具……
是的,它很强大,而且经常被忽视。
我认为从业者应该从 Weka 开始,然后再转向 Python 和 R 等工具。它可以教你流程,而不会让你陷入语法困境。
嗨,Jason,
对于更复杂的问题,是否可以在 GPU 上运行 Weka?
谢谢!
据我所知不行。可能有一些第三方扩展支持这一点。
Jason,这篇文章写得很好,但是当我一步一步地按照您的实验进行操作时,我卡住了,因为我找不到 data 目录中的 iris.arff。我哪里做错了?
谢谢。
如果它还没有,您可能需要单独下载它。
下载并解压 Weka 的 .zip 版本以获取数据文件。
非常感谢您的教程。非常有用的材料。
不客气,我很高兴它有所帮助。
很棒的教程!
YouTube 上还有一个关于 Weka 的入门课程(https://www.youtube.com/watch?v=LcHw2ph6bss)。该软件提供的选项数量确实相当多,让人不知所措。
感谢分享。
非常感谢 Jason 的这篇精彩教程,内容非常丰富!
我想知道是否有办法用聚类做同样的事情。我可以看到 Experimenter 只处理分类。
是否可以对特定数据集执行多个聚类任务,例如使用不同的“k”值的 SimpleKMeans?而不是在单击开始按钮之前手动选择“k”值。
也许有。抱歉,我没有关于 Weka 中聚类算法的材料。
非常感谢您提供的这篇文章,非常有帮助。我想问一下如何获得分类器的测试时间?
谢谢你
我不知道,抱歉。
也许可以尝试一些自定义代码,使用 API 并计算时间?
也许可以从命令行运行,并用一个执行计时的脚本包装它?
我按照步骤操作,得到了输出。但我仍然想深入了解这些算法。
没问题,你可以从这里开始
https://machinelearning.org.cn/start-here/#algorithms
你好,
我可以在 Weka 平台运行机器学习翻译吗?我有大约 300,000 个并行字符串,想知道是否可以在平台上训练模型,如果可以,需要多长时间。感谢您的回复。新年快乐。
我不知道,抱歉。
你好,
计算标准差的公式是什么?
非常感谢!
它将是样本标准差计算,在此页面上有所描述
https://en.wikipedia.org/wiki/Standard_deviation
感谢教程。但是,我想在同一图上绘制和比较结果。在 Experimenter 中是否可能?
也许有。抱歉,我没有示例。
你好,
感谢教程!但是,我在使用 experimenter 时遇到了一个问题:在我设置好实验并单击开始按钮后,实验在几秒钟后就停止了(开始按钮切换了,所以您可以再次单击它)。但是,屏幕上没有错误消息或完成消息。当我打开结果文件时,它基本上是空的。我真的不知道如何解决这个问题,如果有人能帮忙,我将非常感激。
也许请确认您的实验设置正确。
感谢您的教程,先生。非常有用的。
非常欢迎。
感谢您的教程,先生,我按照说明进行操作,但在单击 Run 时收到了错误消息。它说“类属性不是标称的”。
我该如何解决这个问题?我的数据集由 5 点李克特量表问卷调查结果组成。