为新的数据集开发神经网络预测模型可能具有挑战性。
一种方法是首先检查数据集并构思可能适用的模型,然后探索简单模型在数据集上的学习动态,最后使用健壮的测试框架开发和调整模型以适应数据集。
这个过程可以用于开发有效的神经网络模型,用于分类和回归预测建模问题。
在本教程中,您将学习如何为 Wood 的哺乳成像分类数据集开发多层感知器(MLP)神经网络模型。
完成本教程后,您将了解:
- 如何加载和汇总 Woods 哺乳成像数据集,并利用这些结果来建议数据准备和模型配置。
- 如何探索简单MLP模型在数据集上的学习动态。
- 如何开发模型性能的稳健估计,调整模型性能并对新数据进行预测。
让我们开始吧。

为Woods乳腺X光数据集开发一个神经网络
照片来源:Larry W. Lo,部分权利保留。
教程概述
本教程分为4个部分,它们是:
- Woods 哺乳成像数据集
- 神经网络学习动态
- 稳健的模型评估
- 最终模型及预测
Woods 哺乳成像数据集
第一步是定义和探索数据集。
我们将使用“mammography”标准二分类数据集,有时也称为“Woods Mammography”。
该数据集归功于 Kevin Woods 等人,以及 1993 年的论文《用于检测乳腺 X 线照片中微钙化点的模式识别技术的比较评估》。
该问题的重点是通过放射影像扫描来检测乳腺癌,特别是检测出现在乳腺 X 线照片上的微钙化簇。
有两种类别,目标是使用给定分割对象的特征来区分微钙化和非微钙化。
- 非微钙化:阴性病例,或多数类。
- 微钙化:阳性病例,或少数类。
乳腺成像数据集是一个广泛使用标准机器学习数据集,用于探索和演示许多专门为不平衡分类设计的技术。
注意:为了清晰起见,我们 不是 在“解决乳腺癌”。我们正在探索一个标准分类数据集。
下面是数据集中前 5 行的样本
|
1 2 3 4 5 6 |
0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223,'-1' 0.15549112,-0.16939038,0.67065219,-0.85955255,-0.37786573,-0.94572324,'-1' -0.78441482,-0.44365372,5.6747053,-0.85955255,-0.37786573,-0.94572324,'-1' 0.54608818,0.13141457,-0.45638679,-0.85955255,-0.37786573,-0.94572324,'-1' -0.10298725,-0.3949941,-0.14081588,0.97970269,-0.37786573,1.0135658,'-1' ... |
你可以在此处了解更多关于此数据集的信息:
我们可以直接从 URL 将数据集加载为 pandas DataFrame;例如:
|
1 2 3 4 5 6 7 8 |
# 加载哺乳成像数据集并汇总其形状 from pandas import read_csv # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' # 加载数据集 df = read_csv(url, header=None) # 总结形状 print(df.shape) |
运行示例将直接从 URL 加载数据集并报告数据集的形状。
在此情况下,我们可以确认该数据集有 7 个变量(6 个输入和 1 个输出),并且数据集包含 11,183 行数据。
对于神经网络来说,这是一个适度的规模数据集,表明小型网络是合适的。
鉴于其规模不大,使用 k 折交叉验证也是个好主意,因为与训练/测试拆分相比,它能提供更可靠的模型性能估计,而且与处理大型数据集相比,单个模型能在几秒钟内拟合完成,而不是几小时或几天。
|
1 |
(11183, 7) |
接下来,我们可以通过查看摘要统计信息和数据图来进一步了解数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 显示哺乳成像数据集的统计摘要和图表 from pandas import read_csv from matplotlib import pyplot # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' # 加载数据集 df = read_csv(url, header=None) # 显示摘要统计信息 print(df.describe()) # plot histograms df.hist() pyplot.show() |
运行示例首先加载数据,然后打印每个变量的摘要统计信息。
我们可以看到,数值普遍较小,均值接近零。
|
1 2 3 4 5 6 7 8 9 |
0 1 ... 4 5 count 1.118300e+04 1.118300e+04 ... 1.118300e+04 1.118300e+04 mean 1.096535e-10 1.297595e-09 ... -1.120680e-09 1.459483e-09 std 1.000000e+00 1.000000e+00 ... 1.000000e+00 1.000000e+00 min -7.844148e-01 -4.701953e-01 ... -3.778657e-01 -9.457232e-01 25% -7.844148e-01 -4.701953e-01 ... -3.778657e-01 -9.457232e-01 50% -1.085769e-01 -3.949941e-01 ... -3.778657e-01 -9.457232e-01 75% 3.139489e-01 -7.649473e-02 ... -3.778657e-01 1.016613e+00 max 3.150844e+01 5.085849e+00 ... 2.361712e+01 1.949027e+00 |
然后为每个变量创建直方图。
我们可以看到,可能大多数变量呈指数分布,而变量 5(最后一个输入变量)可能是高斯分布,并带有异常值/缺失值。
我们可能可以通过对每个变量使用幂变换来获得一些好处,以使概率分布的偏斜程度降低,这可能会提高模型性能。
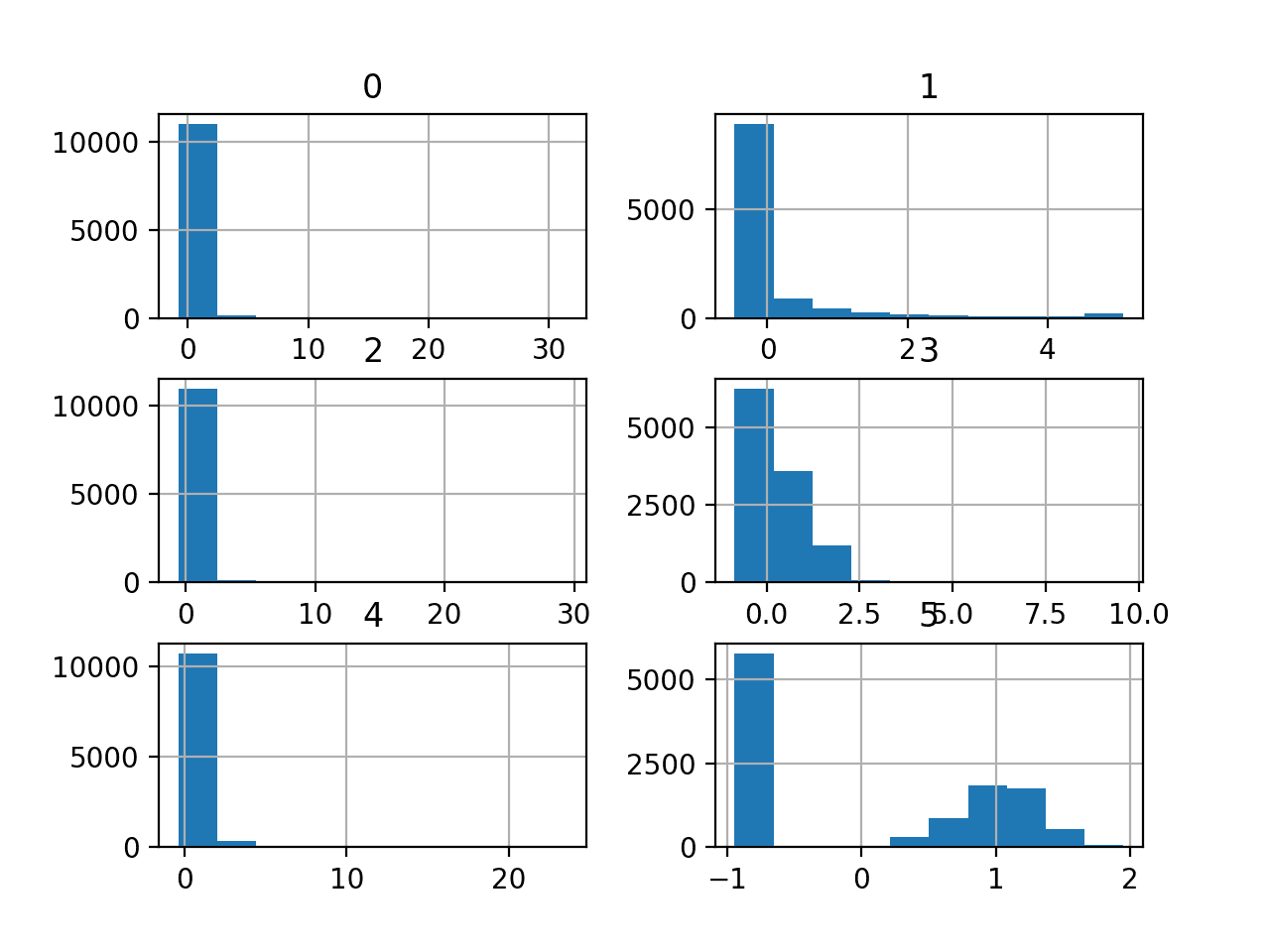
哺乳成像分类数据集的直方图
了解数据集的实际不平衡程度可能会有所帮助。
我们可以使用 Counter 对象来计算每个类别的样本数,然后利用这些计数来汇总分布。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 汇总哺乳成像数据集的类别比例 from pandas import read_csv from collections import Counter # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' # 将csv文件加载为数据框 dataframe = read_csv(url, header=None) # 总结类别分布 target = dataframe.values[:,-1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
运行此示例可以汇总类别分布,确认存在严重的类别不平衡,多数类(无癌症)占约 98%,少数类(癌症)占约 2%。
|
1 2 |
Class='-1', Count=10923, Percentage=97.675% Class='1', Count=260, Percentage=2.325% |
这很有用,因为如果我们使用分类准确率,那么任何准确率低于约 97.7% 的模型在此数据集上都没有技能。
现在我们熟悉了数据集,让我们探索一下如何开发神经网络。
神经网络学习动态
我们将使用 TensorFlow 为数据集开发多层感知机 (MLP) 模型。
我们无法知道什么模型架构或学习超参数最适合这个数据集,因此我们必须进行实验和探索,找出有效的方法。
考虑到数据集规模不大,使用小批量大小可能是一个好主意,例如 16 或 32 行。在开始阶段,使用随机梯度下降的 Adam 版本是一个好主意,因为它可以自动调整学习率,并且在大多数数据集上效果都很好。
在我们认真评估模型之前,最好回顾学习动态并调整模型架构和学习配置,直到我们获得稳定的学习动态,然后再考虑如何充分利用模型。
我们可以通过简单的训练/测试拆分数据并查看学习曲线的图表来实现这一点。这将帮助我们查看模型是否正在过度拟合或拟合不足;然后我们可以相应地调整配置。
首先,我们必须确保所有输入变量都是浮点值,并将目标标签编码为整数值 0 和 1。
|
1 2 3 4 5 |
... # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) |
接下来,我们可以将数据集分割为输入和输出变量,然后分割为 67/33 的训练集和测试集。
我们必须确保拆分是按类别分层的,以确保训练集和测试集具有与主数据集相同的类别标签分布。
|
1 2 3 4 5 |
... # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, stratify=y, random_state=1) |
我们可以定义一个最小的 MLP 模型。
在此情况下,我们将使用一个包含 50 个节点的隐藏层和一个输出层(任意选择)。我们将在隐藏层中使用 ReLU 激活函数和“he_normal”权重初始化,因为它们结合起来是很好的实践。
模型的输出是用于二分类的sigmoid 激活,我们将最小化二元交叉熵损失。
|
1 2 3 4 5 6 7 |
... # 定义模型 model = Sequential() model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') |
我们将为训练 300 个 epoch(任意选择)拟合模型,批量大小为 32,因为这是一个中等大小的数据集。
我们使用原始数据来拟合模型,我们认为这可能是个好主意,但这只是一个重要的起点。
|
1 2 |
... history = model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0, validation_data=(X_test,y_test)) |
训练结束后,我们将评估模型在测试集上的性能,并报告分类准确率作为性能指标。
|
1 2 3 4 5 6 |
... # 预测测试集 yhat = model.predict_classes(X_test) # 评估预测 score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) |
最后,我们将绘制训练过程中训练集和测试集上交叉熵损失的学习曲线。
|
1 2 3 4 5 6 7 8 9 |
... # 绘制学习曲线 pyplot.title('学习曲线') pyplot.xlabel('Epoch') pyplot.ylabel('交叉熵') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show() |
将所有内容整合在一起,下面列出了在癌症生存数据集上评估我们的第一个 MLP 的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 在哺乳成像数据集上拟合一个简单的 MLP 模型并查看学习曲线 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, stratify=y, random_state=1) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 history = model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0, validation_data=(X_test,y_test)) # 预测测试集 yhat = model.predict_classes(X_test) # 评估预测 score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 绘制学习曲线 pyplot.title('学习曲线') pyplot.xlabel('Epoch') pyplot.ylabel('交叉熵') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show() |
运行示例首先在训练数据集上拟合模型,然后报告测试数据集上的分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到该模型表现优于一个无技能模型,因为准确率约为 97.7%,在此情况下达到了约 98.8% 的准确率。
|
1 |
Accuracy: 0.988 |
然后创建训练集和测试集上损失的学习曲线图。
我们可以看到,模型很快就找到了数据集上的良好拟合,并且似乎没有过度拟合或拟合不足。
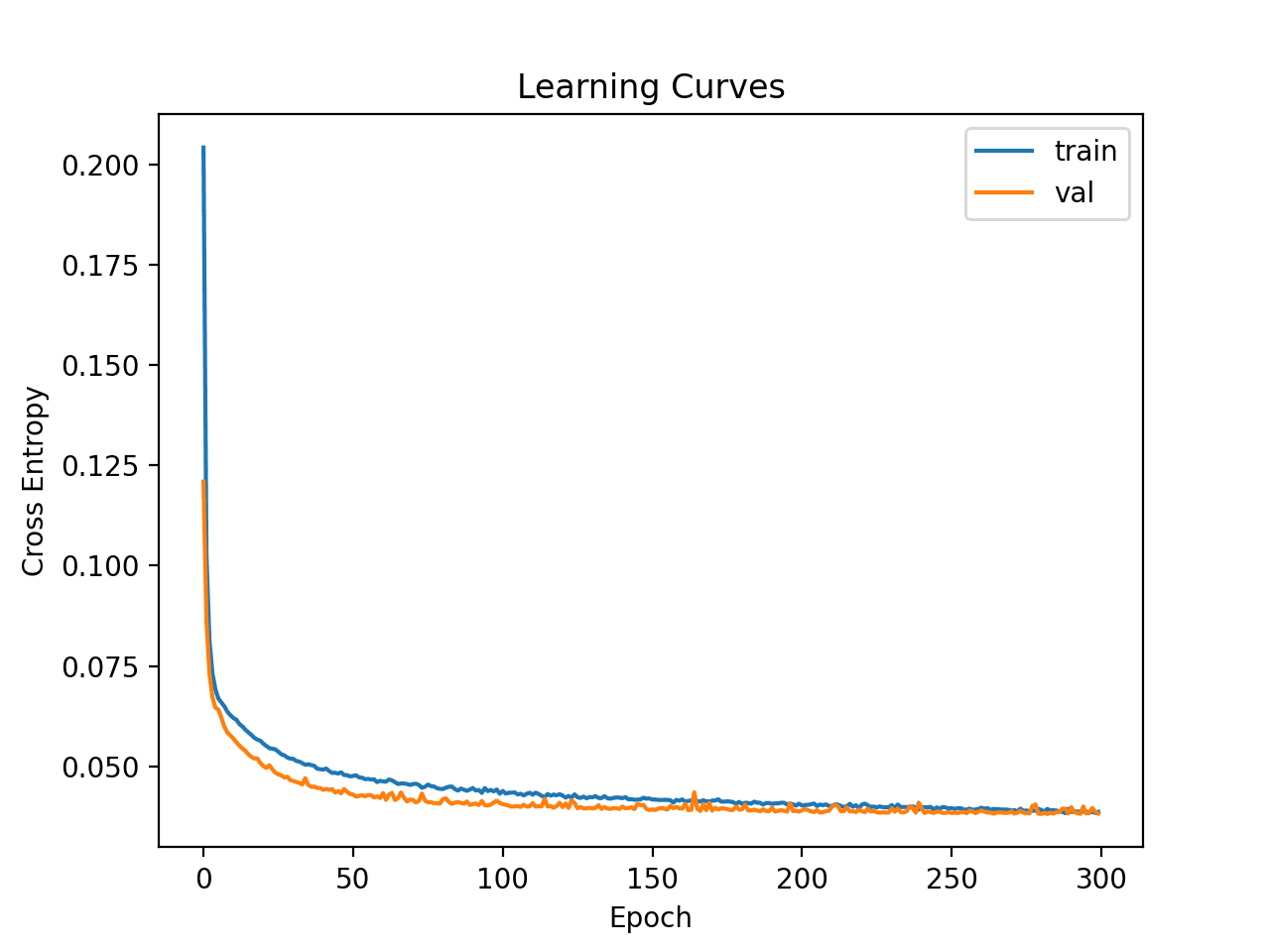
简单多层感知器在哺乳成像数据集上的学习曲线
现在我们对简单 MLP 模型在数据集上的学习动态有了一些了解,我们可以着手开发更稳健的模型性能评估。
稳健的模型评估
k 折交叉验证过程可以提供更可靠的 MLP 性能估计,尽管它可能非常耗时。
这是因为必须拟合和评估 k 个模型。当数据集规模较小时,例如癌症生存数据集,这不是问题。
我们可以使用StratifiedKFold类并手动枚举每个折叠,拟合模型,对其进行评估,然后在程序结束时报告评估分数的平均值。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 准备交叉验证 kfold = KFold(10) # 枚举划分 scores = list() for train_ix, test_ix in kfold.split(X, y): # 拟合和评估模型... ... ... # 汇总所有分数 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
我们可以使用这个框架来为基础配置开发可靠的 MLP 模型性能估计,甚至可以针对一系列不同的数据准备、模型架构和学习配置进行评估。
重要的是,在上一节中使用 k 折交叉验证来估计性能之前,我们首先对模型在该数据集上的学习动态有了初步了解。如果我们直接开始调整模型,我们可能会得到好的结果,但如果不行,我们可能不知道原因,例如模型是过度拟合还是拟合不足。
如果我们再次对模型进行大的更改,最好回到并确认模型正在正确收敛。
下面列出了使用此框架评估上一节中基础 MLP 模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# 对哺乳成像数据集的基本模型进行 k 折交叉验证 from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 准备交叉验证 kfold = StratifiedKFold(10, random_state=1) # 枚举划分 scores = list() for train_ix, test_ix in kfold.split(X, y): # 分割数据 X_train, X_test, y_train, y_test = X[train_ix], X[test_ix], y[train_ix], y[test_ix] # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0) # 预测测试集 yhat = model.predict_classes(X_test) # 评估预测结果 score = accuracy_score(y_test, yhat) print('>%.3f' % score) scores.append(score) # 汇总所有分数 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例将报告每次评估过程的模型的性能,并在运行结束时报告分类准确率的平均值和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 MLP 模型达到了平均约 98.7% 的准确率,这与我们上一节的粗略估计非常接近。
这证实了我们之前的预期,即基本模型配置可能比该数据集的朴素模型效果更好。
|
1 2 3 4 5 6 7 8 9 10 11 |
>0.987 >0.986 >0.989 >0.987 >0.986 >0.988 >0.989 >0.989 >0.983 >0.988 Mean Accuracy: 0.987 (0.002) |
接下来,我们看看如何拟合最终模型并使用它来做出预测。
最终模型及预测
选择模型配置后,我们可以使用所有可用数据训练最终模型,并用它来对新数据进行预测。
在此案例中,我们将使用带有 dropout 和小型批次大小的模型作为我们的最终模型。
我们可以像以前一样准备数据并拟合模型,但这次是在整个数据集上,而不是在一个训练子集上。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 le = LabelEncoder() y = le.fit_transform(y) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') |
然后,我们可以使用此模型对新数据进行预测。
首先,我们可以定义一个新数据行。
|
1 2 3 |
... # 定义一行新数据 row = [0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223] |
注意:我从数据集中取了第一行,预期的标签是“-1”。
然后我们可以进行预测。
|
1 2 3 |
... # 进行预测 yhat = model.predict_classes([row]) |
然后对预测结果进行逆变换,以便我们可以使用或解释正确标签下的结果(对于此数据集,它只是一个整数)。
|
1 2 3 |
... # 逆变换以获得类别标签 yhat = le.inverse_transform(yhat) |
在这种情况下,我们将只报告预测结果。
|
1 2 3 |
... # 报告预测结果 print('Predicted: %s' % (yhat[0])) |
将所有内容整合在一起,下面列出了为哺乳成像数据集拟合最终模型并使用它对新数据进行预测的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 拟合最终模型并对哺乳成像数据集的新数据进行预测 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 le = LabelEncoder() y = le.fit_transform(y) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X, y, epochs=300, batch_size=32, verbose=0) # 定义一行新数据 row = [0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223] # 进行预测 yhat = model.predict_classes([row]) # 逆变换以获得类别标签 yhat = le.inverse_transform(yhat) # 报告预测结果 print('Predicted: %s' % (yhat[0])) |
运行示例会将模型拟合到整个数据集,并为新数据的单行进行预测。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型为输入行预测了“-1”标签。
|
1 |
Predicted: '-1' |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
总结
在本教程中,您学习了如何为 Wood 的哺乳成像分类数据集开发多层感知器(MLP)神经网络模型。
具体来说,你学到了:
- 如何加载和汇总 Woods 哺乳成像数据集,并利用这些结果来建议数据准备和模型配置。
- 如何探索简单MLP模型在数据集上的学习动态。
- 如何开发模型性能的稳健估计,调整模型性能并对新数据进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






在医学领域,更常用的敏感性和特异性不是更好的可用性估计吗?
也许可以。
我尝试编写了一个自定义回调函数来计算 F1 和 AUC 分数。在那里我发现添加密集层并没有显著提高准确率,但对 AUC 和 F1 分数有贡献。
因此,通过在训练集上使用 SMOTE 和 3 个密集层,我在 190 个 epoch 获得了这些结果:
Accuracy = 0.974
ROC AUC = 0.961
Recall AUC = 0.718
F1 score = 0.615
full_path = path+’mammography.csv’
# 加载数据集
X, y = load_dataset(full_path)
# 定义模型
model = get_nn()
# 计算准确率、AUC 和 F1 分数
def acc_auc_f1(y_test, yhat, tresh=0.5)
pred = (yhat > tresh).astype(“int32″)
precision, recall, _ = precision_recall_curve(y_test, yhat)
accuracy, auc_score, f_score = accuracy_score(y_test, pred), auc(recall, precision), f1_score(y_test, pred)
return accuracy, auc_score, f_score
# 自定义回调函数,在 F1 分数(F1 或选定的指标)增加时执行 lambda 函数
class AucActionCallback(Callback)
def __init__(self, action, validation_data, verbose=0, metric=’f1′)
super(AucActionCallback, self).__init__()
self.metric = metric.lower() # metric 可以是 ‘acc’,’auc’, ‘f1’
self.action, self.verbose = action, verbose
(self.X_val, self.y_val) = validation_data # 应该是元组 (X_test, y_test)
def on_train_begin(self, logs=None)
self.best = 0.0 # 初始化最佳值为 0
def on_epoch_end(self, epoch, logs=None)
# 计算分数
accuracy, auc_score, f_score = acc_auc_f1(self.y_val, self.model.predict(self.X_val))
accuracy = round(accuracy * 100, 2)
# 存储到日志中 – history
logs[‘acc’], logs[‘auc’], logs[‘f1’] = accuracy, auc_score, f_score
# 根据选择的指标计算电流
current = f_score if self.metric == ‘f1’ else auc_score if self.metric == ‘auc’ else accuracy
# 打印分数
if self.verbose >= 2
print(f”{epoch}: Accuracy {accuracy}% \tAUC {round(auc_score, 4)} \tF1 score = {round(f_score, 4)}”)
# 更新最佳值
if current > self.best
if self.verbose >= 1
print(f”{epoch}: >>> action at \t{self.metric.upper()} = {round(current,5)} > {round(self.best,5)}”)
self.best = current
self.action() # 执行 lambda
# 训练集必须是分层的
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, test_size=0.3, stratify=y)
# 仅在测试集上应用 SMOTE – 为正确计算应保持验证集不变
X_train, y_train = SMOTE().fit_resample(X_train, y_train)
# F1 分数提高时保存模型
filePathWeights = path+”NN.best.hdf5″
checkpoint = AucActionCallback(lambda: model.save(filePathWeights), validation_data=(X_test, y_test), verbose=2)
# 拟合模型
history = model.fit(X_train, y_train, epochs=200, batch_size=32, verbose=0, callbacks=[checkpoint])
# 加载最佳权重
model.load_weights(filePathWeights)
干得好!
如何在评论中格式化 Python 代码?
您可以在代码周围添加 PRE 标签。
在相同条件下(在训练集 70/30 上使用 SMOTE),XGBClassifier 在几秒钟内得到了这个结果
准确率 = 99.45
ROC AUC = 0.945
召回率 AUC = 0.885
F1 分数 = 0.884
嗨,您能将完整的代码输入到 Word 文件或记事本中吗?
这会帮助您复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
请问您有关于此项目的报告吗?
我没有。