双向LSTM是传统LSTM的扩展,可以提高模型在序列分类问题上的性能。
在所有输入序列时间步都可用的问题中,双向LSTM在输入序列上训练两个LSTM,而不是一个。第一个LSTM按原样处理输入序列,第二个LSTM处理输入序列的倒序副本。这可以为网络提供额外的上下文,并导致问题上更快、更充分的学习。
在本教程中,您将了解如何使用Keras深度学习库在Python中为序列分类开发双向LSTM。
完成本教程后,您将了解:
- 如何开发一个小型、人为构造且可配置的序列分类问题。
- 如何开发用于序列分类的LSTM和双向LSTM。
- 如何比较双向LSTM中使用的合并模式的性能。
快速启动您的项目,阅读我的新书《Python长短期记忆网络》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。
- 2020年1月更新:更新了Keras 2.3和TensorFlow 2.0的API。

如何在 Python 中使用 Keras 开发用于序列分类的双向 LSTM
照片作者:Cristiano Medeiros Dalbem,保留部分权利。
概述
本教程分为6个部分;它们是
- 双向LSTM
- 序列分类问题
- 用于序列分类的LSTM
- 用于序列分类的双向LSTM
- 比较LSTM与双向LSTM
- 比较双向LSTM的合并模式
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
本教程假定您已安装 Keras (v2.0.4+),并使用 TensorFlow (v1.1.0+) 或 Theano (v0.9+) 作为后端。
本教程还假定您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
需要 LSTM 帮助进行序列预测吗?
参加我的免费7天电子邮件课程,了解6种不同的LSTM架构(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
双向LSTM
双向循环神经网络(RNN)的思想很简单。
它包括将网络中的第一个循环层复制一份,使其有两个并排的层,然后将输入序列按原样提供给第一层,并将输入序列的倒序副本提供给第二层。
为了克服常规RNN的限制……我们提出了一种双向循环神经网络(BRNN),该网络可以使用特定时间帧的过去和未来所有可用输入信息进行训练。
…
其思想是将常规RNN的状态神经元分为负责正向时间方向(前向状态)的部分和负责负向时间方向(后向状态)的部分。
— Mike Schuster 和 Kuldip K. Paliwal,《双向循环神经网络》,1997年
这种方法在长短期记忆(LSTM)循环神经网络中得到了极好的应用。
之所以使用双向序列输入,最初是因为在语音识别领域,有证据表明,听者是利用整个话语的上下文来理解所说内容,而不是进行线性解读。
…依赖未来信息乍一看似乎违反了因果关系。我们如何根据尚未说出的内容来理解我们听到的话?然而,人类听者正是这样做的。起初没有意义的声音、单词甚至整个句子,在未来的上下文中会变得有意义。我们必须记住的是,区分真正在线的任务——要求在每次输入后都有输出——以及那些仅在某个输入段结束时才需要输出的任务。
— Alex Graves 和 Jurgen Schmidhuber,《使用双向LSTM和其他神经网络架构进行逐帧音素分类》,2005年
双向LSTM的使用可能并不适用于所有序列预测问题,但在适合的领域中,它可以提供更好的结果。
我们发现双向网络比单向网络有效得多……
— Alex Graves 和 Jurgen Schmidhuber,《使用双向LSTM和其他神经网络架构进行逐帧音素分类》,2005年
需要明确的是,输入序列中的时间步仍然是逐个处理的,只是网络同时在两个方向上遍历输入序列。
Keras中的双向LSTM
Keras通过Bidirectional层包装器支持双向LSTM。
此包装器将一个循环层(例如第一个LSTM层)作为参数。
它还允许您指定合并模式,即在将前向和后向输出传递到下一层之前如何组合它们。选项有:
- ‘sum‘:输出相加。
- ‘mul‘:输出相乘。
- ‘concat‘:输出连接在一起(默认),为下一层提供加倍的输出数量。
- ‘ave‘:取输出的平均值。
默认模式是连接,这在双向LSTM的研究中经常使用。
序列分类问题
我们将定义一个简单的序列分类问题来探索双向LSTM。
该问题定义为一个介于0和1之间的随机值序列。该序列被用作问题的输入,每个数字按时间步提供一个。
每个输入都关联一个二元标签(0或1)。输出值全部为0。一旦输入值在序列中的累积和超过某个阈值,输出值将从0变为1。
使用的阈值为序列长度的1/4。
例如,以下是一个包含10个输入时间步(X)的序列:
|
1 |
0.63144003 0.29414551 0.91587952 0.95189228 0.32195638 0.60742236 0.83895793 0.18023048 0.84762691 0.29165514 |
对应的分类输出(y)将是:
|
1 |
0 0 0 1 1 1 1 1 1 1 |
我们可以在Python中实现这一点。
第一步是生成一个随机值序列。我们可以使用random模块中的random()函数。
|
1 2 |
# 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(10)]) |
我们可以将阈值定义为输入序列长度的四分之一。
|
1 2 |
# 计算改变类别值的截止值 limit = 10/4.0 |
输入序列的累积和可以使用cumsum() NumPy函数计算。此函数返回一个累积和值序列,例如:
|
1 |
pos1, pos1+pos2, pos1+pos2+pos3, ... |
然后,我们可以计算输出序列,即每个累积和值是否超过了阈值。
|
1 2 |
# 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) |
下面的函数名为get_sequence(),将所有这些组合在一起,以序列长度作为输入,并返回新问题案例的X和y分量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from random import random from numpy import array from numpy import cumsum # 创建一个序列分类实例 def get_sequence(n_timesteps): # 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(n_timesteps)]) # 计算改变类别值的截止值 limit = n_timesteps/4.0 # 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) return X, y |
我们可以通过以下方式使用此函数来测试一个新的10时间步序列:
|
1 2 3 |
X, y = get_sequence(10) print(X) print(y) |
运行示例后,将首先打印生成的输入序列,然后是匹配的输出序列。
|
1 2 3 |
[ 0.22228819 0.26882207 0.069623 0.91477783 0.02095862 0.71322527 0.90159654 0.65000306 0.88845226 0.4037031 ] [0 0 0 0 0 0 1 1 1 1] |
用于序列分类的LSTM
我们可以先为序列分类问题开发一个传统的LSTM。
首先,我们必须更新get_sequence()函数,将输入和输出序列重塑为3维,以满足LSTM的期望。期望的结构具有维度[样本数,时间步数,特征数]。
分类问题有1个样本(例如,一个序列),可配置的时间步数,以及每个时间步1个特征。
因此,我们可以按如下方式重塑序列:
|
1 2 3 |
# 将输入和输出数据重塑为适合LSTM的格式 X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) |
更新后的get_sequence()函数如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 创建一个序列分类实例 def get_sequence(n_timesteps): # 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(n_timesteps)]) # 计算改变类别值的截止值 limit = n_timesteps/4.0 # 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) # 将输入和输出数据重塑为适合LSTM的格式 X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) return X, y |
我们将序列定义为具有10个时间步。
接下来,我们可以为该问题定义一个LSTM。输入层将有10个时间步,每个时间步有1个特征,input_shape=(10, 1)。
第一个隐藏层将有20个内存单元,输出层将是一个全连接层,为每个时间步输出一个值。在输出上使用sigmoid激活函数来预测二元值。
TimeDistributed包装层用于输出层,以便在给定整个输入序列的情况下,可以为每个时间步预测一个值。这要求LSTM隐藏层返回一个序列值(每个时间步一个),而不是为整个输入序列返回一个单一值。
最后,由于这是一个二元分类问题,因此使用二元交叉熵(Keras中的binary_crossentropy)。使用高效的ADAM优化算法来查找权重,并在每个epoch计算并报告准确率。
|
1 2 3 4 5 |
# 定义 LSTM model = Sequential() model.add(LSTM(20, input_shape=(10, 1), return_sequences=True)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
LSTM将训练1000个epoch。每个epoch都会为网络生成一个新的随机输入序列进行拟合。这确保了模型不会记住单个序列,而是能够泛化解决方案来解决该问题的所有可能的随机输入序列。
|
1 2 3 4 5 6 |
# 训练 LSTM for epoch in range(1000): # 生成新的随机序列 X,y = get_sequence(n_timesteps) # 在此序列上拟合模型一个 epoch model.fit(X, y, epochs=1, batch_size=1, verbose=2) |
训练完成后,网络将在另一个随机序列上进行评估。然后将预测结果与预期的输出序列进行比较,以提供系统能力的具体示例。
|
1 2 3 4 5 |
# 评估 LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from random import random from numpy import array from numpy import cumsum from keras.models import Sequential 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import TimeDistributed # 创建一个序列分类实例 def get_sequence(n_timesteps): # 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(n_timesteps)]) # 计算改变类别值的截止值 limit = n_timesteps/4.0 # 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) # 将输入和输出数据重塑为适合LSTM的格式 X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) 返回 X, y # 定义问题属性 n_timesteps = 10 # 定义 LSTM model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练 LSTM for epoch in range(1000): # 生成新的随机序列 X,y = get_sequence(n_timesteps) # 在此序列上拟合模型一个 epoch model.fit(X, y, epochs=1, batch_size=1, verbose=2) # 评估 LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
运行示例打印了每个epoch的损失和分类准确率。
这提供了模型如何泛化解决方案以解决序列分类问题的清晰思路。
注意:您的结果可能因算法或评估程序的随机性质或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
我们可以看到模型表现良好,最终准确率在90%到100%之间波动。虽然不完美,但足以满足我们的需求。
与预期值的比较显示了一个新的随机序列的预测,结果大部分是正确的,只有一个错误。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... 纪元 1/1 0秒 - loss: 0.2039 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.2985 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.1219 - acc: 1.0000 纪元 1/1 0秒 - loss: 0.2031 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.1698 - acc: 0.9000 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] |
用于序列分类的双向LSTM
既然我们知道如何为序列分类问题开发LSTM,我们可以扩展该示例来演示双向LSTM。
我们可以通过将LSTM隐藏层包装在Bidirectional层中来实现,如下所示:
|
1 |
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1))) |
这将创建隐藏层的两个副本,一个按原样处理输入序列,另一个处理倒序的输入序列。默认情况下,这些LSTM的输出值将被连接。
这意味着TimeDistributed层将接收10个时间步的40个输出(20个单元+20个单元),而不是10个时间步的20个输出。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from random import random from numpy import array from numpy import cumsum from keras.models import Sequential 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import TimeDistributed from keras.layers import Bidirectional # 创建一个序列分类实例 def get_sequence(n_timesteps): # 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(n_timesteps)]) # 计算改变类别值的截止值 limit = n_timesteps/4.0 # 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) # 将输入和输出数据重塑为适合LSTM的格式 X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) 返回 X, y # 定义问题属性 n_timesteps = 10 # 定义 LSTM model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1))) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练 LSTM for epoch in range(1000): # 生成新的随机序列 X,y = get_sequence(n_timesteps) # 在此序列上拟合模型一个 epoch model.fit(X, y, epochs=1, batch_size=1, verbose=2) # 评估 LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
运行示例,我们看到与上一个示例类似的输出。
注意:您的结果可能因算法或评估程序的随机性质或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
双向LSTM的使用效果是使LSTM能够更快地学习问题。
这在运行结束时从模型的能力来看并不明显,而是在模型随时间推移的能力来看。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... 纪元 1/1 0秒 - loss: 0.0967 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.0865 - acc: 1.0000 纪元 1/1 0秒 - loss: 0.0905 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.2460 - acc: 0.9000 纪元 1/1 0秒 - loss: 0.1458 - acc: 0.9000 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[0] 预测 [0] 预期:[1] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] 预期:[1] 预测 [1] |
比较LSTM与双向LSTM
在此示例中,我们将比较传统LSTM与双向LSTM随时间推移的性能。
我们将实验调整为仅训练模型250个epoch。这是为了让我们清楚地了解每个模型的学习过程以及双向LSTM的学习行为有何不同。
我们将比较三种不同的模型;具体来说:
- LSTM(按原样)
- 带有反向输入序列的LSTM(例如,可以通过将LSTM层的“go_backwards”参数设置为“True”来实现)
- 双向LSTM
这种比较将有助于表明双向LSTM实际上可以提供比简单地反转输入序列更多的东西。
我们将定义一个函数来创建和返回具有前向或后向输入序列的LSTM,如下所示:
|
1 2 3 4 5 6 |
def get_lstm_model(n_timesteps, backwards): model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model |
我们可以开发一个类似的函数来处理双向LSTM,其中合并模式可以作为参数指定。默认的连接可以通过将merge_mode设置为'concat'值来指定。
|
1 2 3 4 5 6 |
def get_bi_lstm_model(n_timesteps, mode): model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model |
最后,我们定义一个函数来拟合模型,并检索和存储每个训练epoch的损失,然后在模型拟合后返回收集的损失值列表。这是为了我们能够绘制每个模型配置的对数损失并进行比较。
|
1 2 3 4 5 6 7 8 9 |
def train_model(model, n_timesteps): loss = list() for _ in range(250): # 生成新的随机序列 X,y = get_sequence(n_timesteps) # 在此序列上拟合模型一个 epoch hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0) loss.append(hist.history['loss'][0]) return loss |
综上所述,完整的示例代码如下。
首先创建一个传统的LSTM并进行拟合,然后绘制对数损失值。接着使用带有反向输入序列的LSTM重复此过程,最后是带有连接合并的LSTM。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
from random import random from numpy import array from numpy import cumsum from matplotlib import pyplot from pandas import DataFrame from keras.models import Sequential 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import TimeDistributed from keras.layers import Bidirectional # 创建一个序列分类实例 def get_sequence(n_timesteps): # 创建一个[0,1]范围内的随机数序列 X = array([random() for _ in range(n_timesteps)]) # 计算改变类别值的截止值 limit = n_timesteps/4.0 # 确定累积序列中每个项的类别结果 y = array([0 if x < limit else 1 for x in cumsum(X)]) # 将输入和输出数据重塑为适合LSTM的格式 X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) 返回 X, y def get_lstm_model(n_timesteps, backwards): model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model def get_bi_lstm_model(n_timesteps, mode): model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model def train_model(model, n_timesteps): loss = list() for _ in range(250): # 生成新的随机序列 X,y = get_sequence(n_timesteps) # 在此序列上拟合模型一个 epoch hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0) loss.append(hist.history['loss'][0]) return loss n_timesteps = 10 results = DataFrame() # LSTM 前向 model = get_lstm_model(n_timesteps, False) results['lstm_forw'] = train_model(model, n_timesteps) # LSTM 后向 model = get_lstm_model(n_timesteps, True) results['lstm_back'] = train_model(model, n_timesteps) # 双向 concat model = get_bi_lstm_model(n_timesteps, 'concat') results['bilstm_con'] = train_model(model, n_timesteps) # 结果的折线图 results.plot() pyplot.show() |
运行此示例将创建一个线图。
注意:您的结果可能因算法或评估程序的随机性质或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,在250个训练周期中,LSTM前向(蓝色)和LSTM后向(橙色)表现出相似的对数损失。
我们可以看到,双向LSTM的对数损失有所不同(绿色),更早地下降到一个较低的值,并且通常比其他两种配置低。
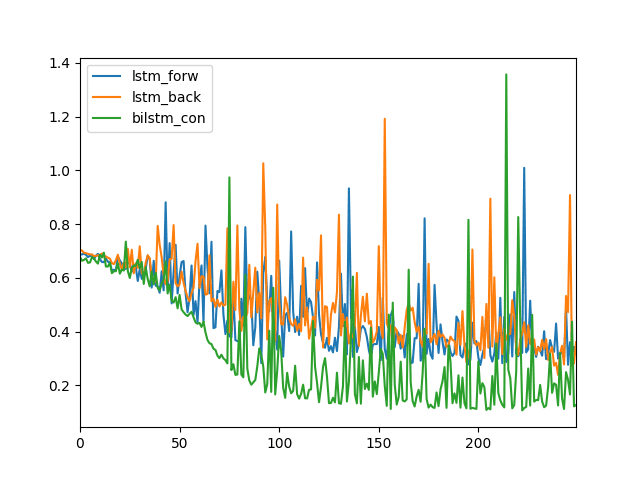
LSTM、反向LSTM和双向LSTM的对数损失折线图
比较双向LSTM的合并模式
有4种不同的合并模式可用于组合双向LSTM层的输出。
它们是拼接(默认)、乘法、平均和求和。
我们可以通过更新上一节的示例来比较不同合并模式的行为,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
n_timesteps = 10 results = DataFrame() # sum merge (求和合并) model = get_bi_lstm_model(n_timesteps, 'sum') results['bilstm_sum'] = train_model(model, n_timesteps) # mul merge (乘法合并) model = get_bi_lstm_model(n_timesteps, 'mul') results['bilstm_mul'] = train_model(model, n_timesteps) # avg merge (平均合并) model = get_bi_lstm_model(n_timesteps, 'ave') results['bilstm_ave'] = train_model(model, n_timesteps) # concat merge (拼接合并) model = get_bi_lstm_model(n_timesteps, 'concat') results['bilstm_con'] = train_model(model, n_timesteps) # 结果的折线图 results.plot() pyplot.show() |
运行示例将创建一个折线图,比较每种合并模式的对数损失。
注意:您的结果可能因算法或评估程序的随机性质或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
不同的合并模式会导致不同的模型性能,具体取决于您的具体序列预测问题。
在这种情况下,我们可以看到求和(蓝色)和拼接(红色)合并模式可能会带来更好的性能,或者至少更低的对数损失。
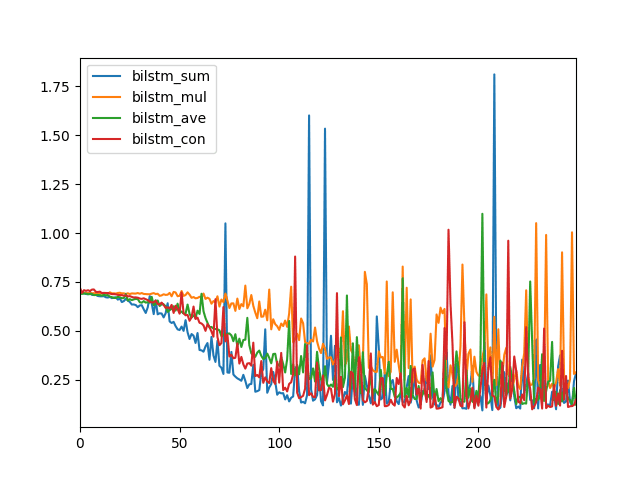
用于比较双向LSTM合并模式的折线图
总结
在本教程中,您将了解如何使用Keras在Python中开发用于序列分类的双向LSTM。
具体来说,你学到了:
- 如何开发一个人为设计的序列分类问题。
- 如何开发用于序列分类的LSTM和双向LSTM。
- 如何比较用于序列分类的双向LSTM的合并模式。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






很棒的帖子!您认为双向LSTM是否可用于时间序列预测问题?
是的,问题是它们能否提高您问题的性能。试试看。
谢谢,有torch版本的实现案例吗?期待收到最新的学习网站!
这可能有助于作为起点
https://machinelearning.org.cn/pytorch-tutorial-develop-deep-learning-models/
太棒了,谢谢
很高兴它有帮助!
嗨,Jason,
实际上,我通常需要使用多线程(多工作线程)来加载Keras模型以提高我的系统性能。但是,当我使用多线程处理Keras模型时,它会遇到图的错误,所以我改为使用多进程。我想问您是否有其他解决方案用于Keras的多工作线程?希望您能理解我的意思。
谢谢你。
是的,我建议在AWS上使用GPU。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
谢谢,Jason,这篇帖子真是太棒了!
不客气,Yitzhak。
你好Jason,非常感谢您的工作。我读了您博客上的大约50篇文章!
我仍然在努力理解如何重塑滞后数据以用于LSTM,并非常感谢您的帮助。
我正在处理多日时间序列的序列分类。我已经将数据(2D)滞后在一起,并使用与您代码非常相似的代码生成了差分特征,并生成了约+5和-4窗口的多个前瞻和后视特征。
# 将时间序列转换为监督学习问题
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
return df
我的数据集使用Conv1D残差网络获得了不错的结果,但LSTM实验完全失败。
我像这样重塑数据以用于Conv1D:
X = X.reshape(X.shape[0], X.shape[1], 1)相同的数据形状是否适用于LSTM或双向LSTM?我认为它需要不同,但我花了几个小时搜索也无法弄清楚。
如果可以,感谢您的帮助!
顺便说一下,我的问题不是预测任务——它是多类别分类:查看特定日的数据,并结合周围的滞后/差分日数据,将其归类为10种不同类型的事件之一。
很好。序列分类。
一天可能是一条序列,并由许多特征组成。
谢谢约翰!
您是在处理序列分类问题还是序列回归问题?您是想对整个序列进行分类还是预测序列中的下一个值?这将决定您想要的LSTM类型。
LSTM的输入是3D的,形式为[样本数,时间步数,特征数]。
样本是序列。
时间步数是滞后观测值。
特征是在每个时间步测量的东西。
这有帮助吗?
你好 Jason,
谢谢这篇博文。
我想在CNN之后使用2D LSTM(与gridlstm或multi diagonal LSTM相同),输入是3D RGB(W * H * D)图像
keras是否开发了GridLSTM或多向LSTM?
我看到tensorflow开发了GridLSTM。可以将其链接到keras吗?
谢谢你。
您可以使用CNN作为LSTM的前端模型。
抱歉,我没听说过“grid lstm”或“multi-directional lstm”。
好文章,Jason!我有两个问题:
1. Bidirectional() 是否可以在没有TimeDistributed()包装器的情况下用于回归模型?
2. 我可以有两个Bidirectional()层吗,还是模型会太复杂?
3. Bidirectional() 是否需要更多输入数据来训练?
提前感谢!🙂
你好Marianico,
1. 可以。
2. 如果您愿意,可以尝试一下。
3. 可能会,测试一下这个假设。
非常感谢Jason先生!
不客气。
Jason,这篇帖子非常好。我目前正在处理一个CNN+LSTM问题。这篇帖子真的很有帮助。
顺便问一下,您是否有CNN + LSTM用于序列分类的经验?输入是随时间变化的医疗扫描的帧。
我们正在经历快速过拟合(5个周期后准确率达到95%)。
减缓过拟合的最佳实践是什么?
是的,我的书中有一个小例子。
考虑使用dropout和其他形式的正则化。也可以尝试更大的批量大小。
告诉我进展如何。
Jason你好!首先祝贺您的工作,我通过您的帖子学到了很多东西。
关于这个话题:我正在处理具有不同长度的时间序列的问题,我想对每个时间序列的每个固定长度窗口进行二元分类。
我知道n_timesteps应该是窗口的固定长度,但是这样我将为每个时间序列获得不同数量的样本。一种解决方案可能是定义一个固定的样本大小,并为较小的时间序列添加“零”窗口,但我想知道是否有其他选择。您对此问题有什么建议吗?
提前感谢!
你好Ed,是的,使用零填充并带有掩码来忽略零值。
如果您知道每隔n个时间步需要进行一次预测,请考虑将每n个时间步的组拆分为长度为n的单独样本。这将使建模更加容易。
告诉我进展如何。
你好 Jason,
我有一个关于如何使用LSTM输出序列的每个时间步的问题。我的问题是0-1分类。我只想为每个样本(一个序列)输出多个标签(对应于该序列)。我的数据都是3D的,包括标签和输入。但我得到的输出是错误的。它们(预测标签)都为0。
这是我的代码
###
model = Sequential()
model.add(Masking(mask_value= 0,input_shape=(maxlen,feature_dim)))
model.add (LSTM(int(topos[0]), activation=act, kernel_initializer=’normal’, return_sequences=True))
model.add(TimeDistributed(Dense(1, activation=’sigmoid’)))
model.compile(loss=’binary_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, callbacks=[tensorboard], validation_data=(x_val,y_val), shuffle=True, initial_epoch=0)
###
这样对吗?非常感谢。
也许您需要一个更大的模型,更多的训练,更多的数据等等……
这里有一些想法
https://machinelearning.org.cn/improve-deep-learning-performance/
非常好的帖子,我正在尝试。
谢谢。
嗨 Jason
我们是在每个时间步将一个序列值[即sequence[i]]输入到LSTM吗?如果是这样,这个sequence[i]是否会通过LSTM的所有内存单元?还是随着时间步的增加,它会逐渐通过每个内存单元?
谢谢
每个输入同时通过该层的所有单元。
好文章,Jason。我最喜欢通过例子学习。我买了您的一系列书,感觉比实际课程学到的更多,并且对它们非常满意。
谢谢Jacob,我写这些是为了帮助人们,很高兴听到它有帮助!
嗨 Jason
我正在研究基于输入正弦序列预测余弦序列。
我尝试像下面这样重新定义get_sequence:
在main函数中,我将损失函数从“binary_crossentropy”更改为MSE,因为根据我的理解,binary_crossentropy会产生0/1损失,而我正在处理连续函数用例。
model.compile(loss=’mean_squared_error’, optimizer=’adam’, metrics=[‘acc’])
可惜模型不收敛,并产生类似二元的结果。
预期:[ 0.55061242] 预测:[1]
有什么建议吗?
此致
Ami
修改后的完整代码
===============
我在这里有一个长长的想法列表。
https://machinelearning.org.cn/improve-deep-learning-performance/
感谢这篇精彩的文章。想知道您是否有关于双向LSTM用于语言翻译的文章?因为我看到有些在编码器和解码器中都使用了双向,有些只在编码器中使用。
这可以帮助您入门。
https://machinelearning.org.cn/develop-bidirectional-lstm-sequence-classification-python-keras/
我们不需要修改任何东西……只需放入双向层……仅此而已……在不同的问题中,如[神经机器翻译]……我们需要修改什么吗?
并不是真的。
如何向解码器添加注意力层……我认为那也只需一行代码……
请看这些帖子。
https://machinelearning.org.cn/?s=attention&submit=Search
Jason,
双向LSTM和双向RNN是否是同一回事?
双向LSTM是一种双向RNN。双向GRU也是一种双向RNN。
你好 Jason,
感谢这篇非常清晰且信息丰富的帖子。
我的数据包含许多不同长度的时间序列,这些时间序列可能非常不同,并且规模会增长得很大——从几分钟到一小时以上的1 Hz样本。
因此,是否有办法在定义模型时不必指定n_timesteps,而只需在拟合或预测时指定?
我真的不想随意截断我的序列或用大量不必要的“零”来填充它们。
顺便说一下,我正在尝试检测序列中某些事件的相当罕见的发生情况;希望带有适当阈值的sigmoid预测概率可以解决这个问题。
谢谢,
Ehud。
您可以使用零填充并结合掩码来忽略零值。
我的博客上有很多例子。
先生,双向LSTM可以用于序列或时间序列预测吗?
也许,试试看。
在测试时需要完整的序列数据,还是可以在每个输入上在线运行?
换句话说:双向LSTM只是训练时间的修改,还是限制您必须拥有完整的序列才能进行分类?
谢谢!
这取决于模型在做出预测时期望接收什么作为输入。
谢谢Jason。对我这个LSTM初学者来说非常有用。非常感谢。
我的研究问题是关于语法错误检测,例如,“people who are good at maths has more chances to succeed.”。如何检测这个句子中的“has”是错误的?这个问题与您给出的示例非常不同。
我的建议是:首先用一个后置词器找到动词“has”,然后对左侧上下文“people who are good at maths”进行向量化并训练lstm,然后反向对右侧上下文“more chances to succeed”进行向量化并训练lstm。最后,将单词“has”预测为0或1。这是一种双向LSTM吗?
如果是,我们有这么多不同长度的句子,输入尺寸是可变的,如何处理这个问题?特别是,样本是整个句子,那么时间步和特征是什么?
听起来是一个有趣的项目。
对于可变长度的输入序列,我建议使用零填充,并使用掩码输入层来忽略零输入。
更多信息在此
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
当你在 LSTM 层设置 go_backwards 标志来训练模型时,当你用该模型进行预测时,预测结果会被反转吗?还是预测结果是正向的?
结果是正常的。
将时间序列视为一个用于预测下一步的序列。我们可以在内存中拥有整个序列,因此我们可以向前、向后甚至以无状态(时间无关)的方式读取它——所有这些都是为了预测下一步。
这有帮助吗?
内容很好,清楚地解释了如何使用双向 LSTM。希望这段代码在撰写本文时能与当前版本的 TensorFlow 和 Keras 兼容。
不客气。
我的代码运行正常。我一直保持所有教程的更新,当出现问题时。
为什么 model.add(TimeDistributed(Dense(2, activation=’sigmoid’))) 不起作用?请解释一下。
问题是什么?
也许将您的代码和错误发布到 stackoverflow?
哎呀……抱歉。我已经想明白了。不过还是感谢您的教程。
很高兴听到这个消息。
先生,
我正在研究一个 RNN,它可以区分单词的开头和结尾。
我来解释一下。
对于训练,我有一个包含句子的 WAV 文件(例如,“我是一个人”),以及一组单词。我还知道单词“I”出现在时间步 [20-30] 之间,“am”出现在 [50-70] 之间,“a”出现在 [85-90] 之间,“person”出现在 [115-165] 之间。
现在我希望 RNN 能够找出未知句子中的单词位置。
它不必说出单词是什么,只需要给出它的开头和结尾。
因此,类别的数量至少为三个,因为一个时间步可以被归类为 word_beginning、word_end 或 something_else。
something_else 可能表示静默区域或单词内部的时间。
到目前为止,我已经考虑将 WAV 文件分割成一系列重叠的窗口。
MFCC 允许——连续的 25 毫秒窗口,默认重叠 15 毫秒,因此我们可以在每个时间步获得 13 或 26 个 MFCC 系数。
由于涉及多个类别,这不是一个二元分类问题。
请您就此发表看法。
感谢您的聆听。
听起来是个很棒的问题,也是一个好的开始。
我预计需要大量的模型调优。
告诉我进展如何。
先生,我需要您的专业意见。
目前我将其转换为二元分类。
简单来说,数据被分为“中间”(=说话单词内的帧)和“结尾”(=单词边界处的帧)。
我希望静默区(两个单词之间的静默)会被学习为“结尾”类别。
但这并不奏效。
似乎神经网络将所有内容都归类为“中间”。尽管我在训练文件夹中提供了 38k 个两个类别的样本。
我认为我在这里犯了一个基本的错误。
这是代码
[code]
import math
import os
import random
from python_speech_features import mfcc
import scipy.io.wavfile as wav
import numpy as np
import tensorflow as tf
from scipy import stats
import re
WORD_LIST=[‘middle’,’ending’]
TEST_WORD_LIST=[‘middle’,’ending’]
MAX_STEPS=11
BATCH_SIZE=500
EPOCH=5000
INTERVAL=1
test_input=[]
train_input=[]
train_output=[]
test_output=[]
deviation_list=[]
def create_test_data(word)
index = WORD_LIST.index(word) if word in WORD_LIST else -1
files = os.listdir(‘/home/lxuser/test_data/’+word)
length_of_folder=len(files)
interval=INTERVAL
j=0
for i in range(int(length_of_folder/interval))
filecount=int(math.floor(j))
(test_rate,test_sig) = wav.read(‘/home/lxuser/test_data/’+word+’/’+files[filecount])
test_mfcc_feat = mfcc(test_sig,test_rate,numcep=26)
sth=test_mfcc_feat.shape[0]
test_padded_array=np.pad(test_mfcc_feat,[(MAX_STEPS-sth,0),(0,0)],’constant’)
test_input.append(test_padded_array)
temp_list = [0]*2
temp_list[index]=1
test_output.append(temp_list)
if(word==’middle’)
deviation_list.append(-1)
else
value=int(re.search(r’\d+’,files[filecount]).group())
deviation_list.append(value)
j=j+interval
if(j>length_of_folder-1)
j=0
def make_train_data(word)
int_class = WORD_LIST.index(word) if word in WORD_LIST else -1
files = os.listdir(‘/home/lxuser/train_dic/’+word)
length_of_folder=len(files)
interval=INTERVAL
random.shuffle(files)
j=0
for i in range(int(length_of_folder/interval))
(train_rate,train_sig) = wav.read(‘/home/lxuser/train_dic/’+word+’/’+files[int(math.floor(j))])
# print(word,files[int(math.floor(j))],’in training’)
train_mfcc_feat = mfcc(train_sig,train_rate,numcep=26)
train_test_mfcc_feat=train_mfcc_feat
sth=train_mfcc_feat.shape[0]
train_padded_array=np.pad(train_mfcc_feat,[(MAX_STEPS-sth,0),(0,0)],’constant’)
train_input.append(train_padded_array)
temp_list = [0]*2
temp_list[int_class]=1
train_output.append(temp_list)
j=j+interval
if(j>length_of_folder-1)
j=0
def shuffletrain()
rng_state = np.random.get_state()
np.random.shuffle(train_input)
np.random.set_state(rng_state)
np.random.shuffle(train_output)
if __name__== “__main__”
for i in WORD_LIST
make_train_data(i)
for i in TEST_WORD_LIST
create_test_data(i)
shuffletrain()
print “test and training data loaded”
data = tf.placeholder(tf.float32, [None, MAX_STEPS,26]) #Number of examples, number of input, dimension of each input
target = tf.placeholder(tf.float32, [None, 2])
num_hidden = 128
cell = tf.nn.rnn_cell.LSTMCell(num_hidden,state_is_tuple=True)
val, _ = tf.nn.dynamic_rnn(cell, data, dtype=tf.float32)
val = tf.transpose(val, [1, 0, 2])
last = tf.gather(val, int(val.get_shape()[0]) – 1)
weight = tf.Variable(tf.truncated_normal([num_hidden, int(target.get_shape()[1])]))
bias = tf.Variable(tf.constant(0.1, shape=[target.get_shape()[1]]))
prediction = tf.nn.softmax(tf.matmul(last, weight) + bias)
cross_entropy = -tf.reduce_sum(target * tf.log(tf.clip_by_value(prediction,1e-10,1.0)))
optimizer = tf.train.AdamOptimizer()
minimize = optimizer.minimize(cross_entropy)
mistakes = tf.not_equal(tf.argmax(target, 1), tf.argmax(prediction, 1))
error = tf.reduce_mean(tf.cast(mistakes, tf.float32))
if True
print(‘starting fresh model’)
init_op = tf.initialize_all_variables()
saver = tf.train.Saver()
sess = tf.Session()
sess.run(init_op)
#saver.restore(sess, “./1840frames-example-two-class-ten-from-each-model-2870.ckpt”)
incorrect = sess.run(error,{data: train_input, target: train_output})
print(‘Train error with now {:3.9f}%’.format(100 * incorrect))
incorrect = sess.run(error,{data: test_input, target: test_output})
print(‘test error with now {:3.9f}%’.format(100 * incorrect))
batch_size = BATCH_SIZE
no_of_batches = int(len(train_input)) / batch_size
for i in range(1000000)
print “Epoch “,str(i)
ptr = 0
for j in range(no_of_batches)
inp, out = train_input[ptr:ptr+batch_size], train_output[ptr:ptr+batch_size]
ptr+=batch_size
sess.run(minimize,{data: inp, target: out})
if((i!=0)and(i%10==0))
true_count=0
false_count=0
deviation=0
for test_count in range(len(test_output))
test_result_i=sess.run(prediction,{data:[test_input[test_count]]})
guess_class=np.argmax(test_result_i)
true_class=np.argmax(test_output[test_count])
print(‘true class guess class’,true_class,guess_class)
if(guess_class==true_class)
true_count+=1
if(true_class==1)
true_position=deviation_list[test_count]
predicted_position=920
deviation+=np.absolute(true_position-predicted_position)
#print(‘truepos’,true_position,’deviation so far’,deviation)
else
false_count+=1
print(‘true_count’,true_count,’false_count’,false_count,’deviation’,deviation)
incorrect = sess.run(error,{data: train_input, target: train_output})
print(‘Epoch {:2d} train error {:3.1f}%’.format(i , 100 * incorrect))
incorrect = sess.run(error,{data: test_input, target: test_output})
print(‘Epoch {:2d} test error {:3.1f}%’.format(i , 100 * incorrect))
save_path = saver.save(sess, “./1840frames-example-true-two-class-ten-from-each-model-%d.ckpt” % i)
print(“Model saved in path: %s” % save_path)
sess.close()
[/code]
我相信 — 你会很快指出我的错误。
我从相应文件夹的 WAV 文件中加载每个类的数据。
偏差只是为了统计结果。
你可以忽略它。
如果我的代码不清晰,请告诉我。
在这里,神经网络从 11 个时间步进行决策,每个时间步有 26 个值。
hidden=128 正常吗?
谢谢。
这里有一些可以尝试的通用想法。
https://machinelearning.org.cn/improve-deep-learning-performance/
它似乎记住了输入,因此训练误差很快就降至 0%,但在测试中,它将所有内容都归类为类别零。
谢谢您的聆听。
听起来像是过拟合。
我想让网络明白,如果它遇到包含静默数据(无论是在哪个部分)的输入,它就应该称之为类别 1,即使所有其他数据都指示类别 0。
抱歉频繁回复。
谢谢。
也许先头脑风暴一下,思考不同的方法来将其构建成一个监督学习问题。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
谢谢 Jason,很棒的帖子。您认为双向 LSTM 模型在情感分析方面怎么样,例如将标签分类为正面、负面和中性?有很多研究论文使用简单的 LSTM 模型来完成这个任务,但很少有关于 BiLSTM 模型(主要是语音识别)的。那么它对这个任务真的不值得吗?
不一定需要,请看这篇帖子。
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
尽管如此,还是运行一些实验并尝试双向。实验成本很低。
嗨,Jason!
感谢这篇帖子。
双向 LSTM 是否需要整个序列作为输入,还是只需要序列?
系列输入:x[t],其中 t=[0..n],完整的测量/模拟。
序列输入:x[t],其中 t=[0..10],[10..20],…[n-10, n],序列长度 = 10。
在第二种选择中,它可以用于在线预测任务,其中未来的输入是未知的。
LSTM 和双向 LSTM 都将单个样本作为输入,这可能是序列或子序列,具体取决于您的预测问题。
Jason,您的工作太棒了!
– 特别喜欢测试 LSTM vanilla vs. LSTM reversed vs. LSTM bidirectional。
– 即使一年后,我也看到没有人涵盖这一点(Andrew Ng、Advanced NLP Udemy、Udacity NLP)。
– 您的帖子让我重读了您的 LSTM 书。
弗朗哥
PS:Francois Chollet 关于 NLP 的一个有趣想法:1D-CNN + LSTM Bidirectional 用于文本分类,其中词序很重要(否则不需要 LSTM)。
谢谢!
是的,我目前也在写关于 1D CNN 的内容,它们非常有效。
另外,我已经有很多关于它们的内容了,从这里开始。
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
还有这里
https://machinelearning.org.cn/develop-n-gram-multichannel-convolutional-neural-network-sentiment-analysis/
还有这里
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
嗨,Jason,
感谢您的教程。
您能否解释一下为什么内存单元的数量大于时间步的数量。我假设它们应该是相同的,因为每个输入都连接到每个内存单元(https://colah.github.io/posts/2015-08-Understanding-LSTMs/)。
祝好
时间步长和网络第一个隐藏层的单元数是无关的。
嗨,Jason,
感谢您的快速回复。
我假设时间步 t 的输入,即 x(t),连接到一个内存单元 U(t)。如果输入样本包含 N 个时间步,则需要相应的 N 个内存单元。
U(0) -> U(1) -> … -> U(N-1)
^ ^ ^
x(0) -> x(1) -> … -> x(N-1)
在您的代码中,单元数为 20,而时间步数为 10。在这种情况下,x 如何连接到 U?
祝好,
模型一次处理一个时间步。
第一个隐藏层中的每个单元一次接收一个时间步的数据。
嗨 Jason,感谢精彩的解释!我的问题是
在我看来,向后运行的 RNN 完全没有机会解决问题,或者我错过了什么?只有向前运行的 RNN 才能看到数字,并有机会找出何时超出了限制。那么为什么双向 RNN 的性能要优于前向 RNN 呢?
双向模型会看两次数据,向前和向后(两个视角),从而有更多机会来解释它。
我觉得奇怪的是,四年来没有人提出这个问题或给出适当的答案。
你问题的实际答案是,由于序列生成的方式,LSTM 从右到左找到正确解决方案的机会与从左到右找到的机会大致相同。这开始让我感到困惑,当时我查看了比较这三个模型(前向、后向和双向)的图,但实际上它非常简单,只是基础概率论的问题。
由于序列的元素是从 [0.0, 1.0) 范围内的均匀分布中提取的,这意味着每个元素的期望值是 0.5,而一个 10 元素序列的元素总和的期望值将是 5。从 0 切换到 1 的阈值设置为 10 / 4 = 2.5,因此可以推断,无论你是向前还是向后,平均而言,切换都会在第 5 个时间步之后发生(5 * 0.5 = 2.5)。
向前 LSTM 与向后 LSTM 表现相同的唯一合理解释是:向前 LSTM 完全不知道它应该累加值并在总和超过 2.5 时切换。它学习到的,就像向后 LSTM 一样,是在第 5 个时间步之后进行切换。由于这正是切换在大多数情况下发生的地方(由于均匀分布),因此两个 LSTM 在大多数情况下都能猜出正确的解决方案。然而,对数损失的巨大波动表明,当序列恰好生成非常小的或非常大的数字时,LSTM 遵循的在中间进行切换的策略就会失败。
因此,从比较图中可以清楚地看出,当 LSTM 模型超出预测到第 5 个元素为止都是 0,之后都是 1 的情况时。这会通过向前 LSTM 图明显低于向后 LSTM 图并且振荡减少来显示,即它的预测变得更加一致,猜测性更小。如果你让训练运行更长时间,这种趋势会在大约 1000 个 epoch 后开始清晰显示,此时向前 LSTM 的对数损失会达到与双向 LSTM 相同(正如预期的那样),最终在大约 3000 个 epoch 后,甚至可能稍微优于它。与此同时,向后 LSTM 在大约 1000 个 epoch 后没有任何改进,这意味着它在那时已经完美地学会了基于概率的猜测策略,并且无法通过从右到左查看序列来获得进一步改进。
嗨 Jason,非常感谢您的精彩文章。
我有一个关于双向网络和预测的普遍问题。
假设我有一个游戏,每 3-5 秒有障碍物,并且根据玩家前 30 秒的游戏情况,我必须预测用户是否会在未来 5 秒内撞到障碍物 _i。
我为每个障碍物生成了大量特征,其中一个特征是“用户是否在前一个障碍物中撞到了”。
我现在应用了双向 LSTM,并获得了近乎 100% 的性能。
我是否正确地认为在此场景中使用 BiLSTM 是一种“作弊”,因为通过使用未来的特征,我实际上知道他是否撞到了障碍物 _i,因为我可以在障碍物 _i 之后立即查看“用户是否撞到上一个障碍物”这个特征!
因此,我不应该使用双向网络,而应该坚持使用 LSTM/RNN。
非常感谢您的帮助,
Bastian
这实际上取决于您如何构建问题。
嗨 Bastian,
我遇到类似的问题,也试图用双向 LSTM 进行预测,在训练时获得近乎 100% 的准确率,但在预测时输出无意义。我也得出了结论,双向 LSTM 不能那样使用。Jason 在这里的例子有点误导。
此致,Constanze
听起来像是训练数据过拟合。
我应该注意哪些线索来确定是否发生了过拟合?
谢谢!
训练集的表现很好,而测试集的表现很差。
嗨 Jason,我想问一下如何在 Keras 中设置双向 RNN 的初始状态?下面是我的代码,‘initial_state’ 设置在第三个双向 RNN 中。
encoder_input = ks.layers.Input(shape=(85,))
decoder_input = ks.layers.Input(shape=(85,))
encoder_inputs = Embedding(lenpinyin, 64, input_length=85, mask_zero=True)(encoder_input)
encoder = Bidirectional(LSTM(400, return_sequences=True), merge_mode=’concat’)(encoder_inputs)
encoder_outputs, forward_h, forward_c, backward_h, backward_c = Bidirectional(LSTM(400, return_sequences=True, return_state=True), merge_mode=’concat’)(encoder)
decoder_inputs = Embedding(lentext, 64, input_length=85, mask_zero=True)(decoder_input)
decoder = Bidirectional(LSTM(400, return_sequences=True), merge_mode=’concat’)(decoder_inputs, initial_state=[forward_h, forward_c, backward_h, backward_c])
decoder_outputs, _, _, _, _ = Bidirectional(LSTM(400, return_sequences=True, return_state=True), merge_mode=’concat’)(decoder)
decoder_outputs = TimeDistributed(Dense(lentext, activation=”softmax”))(decoder_outputs)
这里有一个例子可能会有帮助。
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
嗨,Jason,
我正在为序列分类的一个特定概念苦苦挣扎。假设我有一系列客户反馈句子,并希望使用无监督训练来按其性质对它们进行分组(客户对某个功能的投诉 vs. 他们提出的问题 vs. 一条一般性评论等)。我基本上想发现它们可能存在的自然分组。
所有这些模型似乎都在谈论沿序列时间步长的预测,但是预测如何导致有意义的句子分组(分类)呢?换句话说,您如何从预测句子中的下一个单词转变为发现句子组并确定该句子属于此组而不是另一组?
非常感谢!
抱歉,我通常没有关于无监督方法的内容。
如果您能让专家标记数千个示例,那么您就可以使用监督学习方法。
你好 jason,
您真是 LSTM 的救星。我真的很感激,并且学到了很多。
从代码来看,我能确认这是与输入序列长度相同的多步预测吗?
时间分布层是这里的关键吗?
我一直在尝试寻找多步预测的方法,我知道您有一篇使用 stateful = True 进行多步预测的博文,但我无法将其与双向 LSTM 结合使用,并且受限于 batch size 必须是 training size 的倍数。预测也是如此。
任何解释都将不胜感激。
我推荐这个教程
https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
您可以简单地将第一个隐藏层更改为双向 LSTM。
嗨,Jason,感谢您的精彩文章。
我注意到您在每个 epoch 都用新的样本进行训练。这是必要的吗?
1) 我们可以在每个 epoch 中使用所有数据进行训练吗?
2) 或者在每个 epoch,我应该只选择一个数据样本进行拟合,这意味着样本数= epoch 数?
您可以在每个 epoch 中使用相同的数据集来训练模型,选择的问题只是一个演示。
嗨 Jason,我有一个问题。通常输入到 BiLSTM 的所有输入的形状都是 [batch_size, time_steps, input_size]。我正在处理自动论文评分的问题,其中有一个额外的维度,即每篇论文的句子数量。所以对于我的情况,在通过 word2vec 嵌入后的典型批次形状是 [2,16,25,300]。这里每个批次中有 2 篇论文 (batch_size=2),每篇论文有 16 个句子,每个句子有 25 个单词(time_step=25),我使用 300 维的 word2vec(input_size=300)。因此,我显然需要以某种方式在维度 16 上循环这个批次。我尝试了很长时间,但一直找不到方法。例如,如果您遍历 tf.nn.bidirectional_dynamic_rnn(),它会在第二次迭代时报错,说 tf.nn.bidirectional_dynamic_rnn() kernel 已经存在。您能告诉我是否有其他方法可以做到这一点吗?提前非常感谢。
也许您可以将一篇文档中的句子合并成一个单词序列?
不能,因为我必须在句子级别上输入数据。还有其他方法吗?
您可以使用整个文档的自编码器。
您可以为每个句子进行预测。
我会试试的。同时,我们能否在此处使用 tf.map_fn()?例如,我们对批次进行转置,使其成为 [16,2,25,300],然后使用上述函数将其发送到双向 LSTM。我不太确定该怎么做。
我没做过,也许可以尝试一下,看看您能有什么发现。
我认为我问题的答案很简单,但我有些地方搞混了。如果您有时间,请看看我的代码(https://codeshare.io/5NNB0r)。这只是一个简单的 10 行代码,不会花费您太多时间。我也尝试了 tf.map_fn(),但到目前为止还没有成功。谢谢。
我很乐意提供帮助,但我没有能力审查代码。我每天会收到数百封类似的电子邮件请求。
嗨 Jason,我理解,非常感谢您的所有帮助。您也会很高兴知道我设法让代码工作了。我使用了 tf.map_fn() 将整个批次映射到 bilstm_layers。再次感谢。
干得好!
嗨 Jason,感谢又一篇很棒的文章。
我想知道您是否有关于使用 CNN-biLSTM 识别视频中动作的建议。我正尝试输入 10 帧序列提取的光流,但结果令人失望。我关心的一个问题是 (Shuffle = True)。我读到保持这样更好,但由于我的序列是有序的,我在读取输入帧/光流时无法容忍混洗。此外,当我尝试微调 CNN 与我的数据时,分类准确率很低(这很正常,因为它只基于帧),所以我想知道准确率是否重要,还是我应该只在我的数据上进行训练(无论最终准确率如何),移除顶层并将其用于我的 CNN-LSTM?
任何关于此事的技巧或教程都将非常感激。非常感谢!!
这篇博文将作为第一步有所帮助。
https://machinelearning.org.cn/cnn-long-short-term-memory-networks/
我在我的 LSTM 书籍中有更完整的例子。
https://machinelearning.org.cn/lstms-with-python/
你好,我正在为一个大学项目设计一个鸟类声音识别工具。它使用 MFCC 特征提取方法提取特征,但现在我在分类部分遇到了困难。我尝试了反向传播神经网络,但没有成功。您认为递归神经网络,因为擅长对时间序列进行分类,会是更好的解决方案吗?提取的鸟类声音特征中有很多重复的模式。
我建议尝试问题的多种不同框架、多种数据准备方法和多种建模算法,以_发现_最适合您特定问题的方法。
这个流程可能会有帮助。
https://machinelearning.org.cn/start-here/#process
出色的帖子!它帮助我完成了 Coursera 上的序列模型课程!我在最后一个作业上卡了一个小时,无法弄清楚双向 LSTM,然后我来看了您的教程,一切都变得清晰了。谢谢 Jason!
我很高兴它有所帮助!
您好,您的代码示例是否适用于多类别多标签意见挖掘分类问题?
并且是否可以将 w2v 矩阵作为输入提供给 NN?
谢谢
上面的例子是二分类。
我有过类别分类的例子。在这个阶段我还没有多标签分类的例子。
嗨,Jason,
不错的文章。我有一个关于您上面例子的疑问。
由于 Y 是(逻辑上)由前面数字的累加和确定的(例如,X1、X2、X3 ==> Y3),那么 LSTM 的反向如何从后面的时间步(例如 X4、X5、X6……)预测(或受益)Y3,因为它们与反向顺序无关?
但从您上面的丢失图来看,它确实有所帮助。
注意:我明白在语音识别中,这个概念真的很有帮助。
谢谢和问候,
M。
双向层使输入容量加倍,通过向前和向后处理序列,它为模型提供了更多机会来提取观测值中的序列相关性。
这太棒了,但我有点困惑(我的 Python 非常弱),因为我跟随着其他教程,大多数人都这样做:“xyz = model.fit(trainx, trainy, batch_size=batch_size, epochs=iterations, verbose=1, validation_data=(testx, testy),”
而这里不是这种情况。
它运行良好,但我找不到任何方法来对其进行诊断(因为我似乎无法将其连接到 tensorboard 而不使用“model.fit(…).”)。我也很想制作一个混淆矩阵和一个包含实际值和预测值的 DataFrame,但找到的所有指南似乎都需要我使用“model.fit()”格式。
fit() 函数返回模型。
predict() 函数返回您可以与真实值进行比较、计算性能和混淆矩阵的预测。
很棒的文章!但我有兴趣学习构建 CNN 和 MDLSTM,这可能有助于手写段落识别,而无需预分段。训练和构建它困难吗?您能否好心解释如何构建这样的模型并在 Keras 中进行训练?
抱歉,我对“MDLSTM”不熟悉。
嗨 Jason,感谢您的有用文章,我想知道是否可以堆叠双向 LSTM(多个层)?如果可以,如何堆叠?干杯。
是的,与堆叠 LSTM 的方式相同。
像这样吗?
我尝试了以下代码,但错误非常大,达到数百万。
model = Sequential()
model.add(Bidirectional(LSTM(50, activation=’relu’, return_sequences=True), input_shape=(n_steps, n_features)))
model.add(Bidirectional(LSTM(50, activation=’relu’)))
model.add(Dense(1))
model.compile(optimizer=’adam’, loss=’mse’)
也许模型需要为您的项目进行调整?
我明白了,所以代码结构或模型没有问题?
一眼看上去没问题,但我没有能力运行或调试您发布的代码。
尝试使用 epoch 数量=300 和 n_steps =50 的代码,也许这样您的代码就可以正常工作了。
你好!很棒的帖子!我有一个序列分类问题,其中输入序列的长度可能不同!我读了您关于准备可变长度序列的文章,但问题是,如果我截断长序列,我就无法对这些值进行分类。(截断丢失的值)。有没有解决这个问题的方法?
也许可以尝试零填充并向输入添加 Masking 层。
Masking 层应该可以!非常感谢!
您对处理掩码后非常长的序列以进行分类有什么建议吗?例如小批量处理……
这可能有帮助
https://machinelearning.org.cn/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
嗨 Jason!一如既往的精彩文章。我只有一个问题。我正在处理一个序列多分类问题,与上述博文不同,一个序列只有一个输出(而不是序列中的每个输入一个)。我需要进行哪些更改才能使其正常工作?
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
谢谢 Jason,我会看看的。
谢谢。
嗨 Jason 博士,请帮助我实现双向 LSTM。我将其应用于 JAMBOT Music Theory Aware Chord Based Generation of Polyphonic Music with LSTMs 项目中的 chord_lstm_training.py 和 polyphonic_lstm_training.py。但它给出了一个错误消息:“如果 RNN 是状态化的,它需要知道它的批次大小。指定输入张量的批次大小:”请帮忙。项目网站是 https://github.com/brunnergino/JamBot.git
抱歉,我不熟悉那个代码,也许可以联系作者?
嗨,Jason,
非常感谢您的教程,它们非常有趣且非常具有说明性。
我的问题是:我们能否使用 LSTM 来预测类别变量 V 多个时间步,即 t、t+1、t+2……?如果可以,该如何做?
谢谢您的回复
是的,这是一个时间序列分类。
你可以从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨
我需要构建一个 LSTM 来进行序列分类,当我们有超过两个类别时(类别是整数值(0,1,2,3))。
与您的示例不同,我构建了整个训练集,而不是一个接一个地构建。
我的问题是,在输出层使用 TimeDistributed 包装器时,我应该选择什么激活函数?
当我使用 Softmax 作为输出层激活函数,并使用 sparse_categorical_crossentropy 损失来编译模型时,我收到此错误:
收到了一个标签值 3,它超出了 [0,1) 的有效范围。
如果您使用 sparse categorical loss,那么模型必须有 n 个输出节点(每个类别一个)并且目标 y 变量必须有 1 个变量,包含 n 个值。
这有帮助吗?
是的。非常感谢。还有一个问题:在我的问题中,输入是时间序列数据,输出是与输入每个点对应的类序列。
我使用窗口方法来创建每个输入和输出序列,但问题是数据高度不平衡。我可以使用 LSTM 并考虑类权重,还是应该使用过采样或欠采样方法来平衡数据?
谢谢你的回复。
好问题。抱歉,我对时间序列的重新平衡技术不熟悉。
可能存在适用于 LSTM 的类权重,我以前没有用过。
谢谢你。
我刚刚发现,我们可以将 fit 函数中的 sample_weight 参数设置为一个权重数组(对应于类权重),并将 sample_weight_mode 设置为 ‘temporal’ 作为 compile 方法的参数。
干得不错。
嗨 Aida,我也在尝试做 LSTM 和 4 个类别。可以分享您的代码吗?我的代码无法正常工作。抱歉,谢谢!
如何将双向 LSTM 用于 seq2seq 模型?可能吗?
非常感谢您的博客!
是的。
非常感谢 Jason,感谢您的好文章。我有一个问题,我们能否使用此模型来识别医疗文档中的实体,例如疾病、药物名称等?
我读到一篇关于 CRF 和 BLSTM 组合方法的论文,但实际上需要帮助来构建模型,或者您也许可以为我指明方向。我设法使用 CRF 从文档中提取了实体,但不确定如何嵌入 BLSTM。非常感谢任何帮助。
如果您正在处理文本数据,也许可以从这里开始。
https://machinelearning.org.cn/start-here/#nlp
亲爱的 Jason,
我们可以使用双向 LSTM 模型进行程序语言建模,以生成代码预测或建议吗?它有什么好处吗?
也许可以在您的数据集上尝试一下,并与其他方法进行比较?
Adam 优化器(learning_rate = 0.001),批次大小 128。LSTM 有
隐藏维度 100,4 层,并且是双向的。
我想编码上述 LSTM 规范,但我不知道如何做到,因为像层数这样的参数并不明显放在哪里?
好问题,这有助于确定层数和节点/单元的数量。
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
嗨,Jason,
我像这样定义了一个 3DCNN 用于从我的视频数据集中提取特征。
model = Sequential()
model.add(
TimeDistributed(
MobileNetV2(weights=’imagenet’,include_top=False),
input_shape=sample_shape
)
)
model.add(
TimeDistributed(
GlobalAveragePooling2D()
)
)
现在我需要附加一个双向 LSTM 作为下一层??
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=( ?)))
不确定如何定义输入形状,因为它来自 3DCNN 池化层的输出。
抱歉,我对 3dcnn 不熟悉,建议您自己尝试。
嗨,Jason,
我是一名深度学习领域的新研究学生。在学习过程中,我浏览了您的大量教程。我非常赞赏您清晰易懂的总结。对我来说非常有帮助。我只想说声谢谢,谢谢您的奉献。现在,我将认真开始我的研究。
祝好,
Angela
谢谢 Angela,我很高兴我的教程对您有所帮助!
Hi Jason,感谢这个很棒的教程!
这种方法是否适用于多元时间序列?(即有几个时间序列,我们将它们分组并希望一起分类。)
我尝试过,但不确定如何处理这个层。
model.add(TimeDistributed(Dense(1, activation=’sigmoid’)))
处理此问题的最佳方法似乎是简单地将最后一个 LSTM 的 return_sequences 设置为 False,但我很好奇是否有其他方法?
如果我在另一篇博文中处理过这个问题,请道歉,我找不到。
此致,
是的,也许可以尝试改编本教程中列出的一个示例,使用双向层。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨,Jason,
感谢您的精彩分享!
我感到困惑,在合并双向输出时,modes =“concat”意味着许多输出成对连接,还是只是最后一个前向和后向输出相互连接。
该层的输出被连接起来,所以是前向和后向传递的输出。
嗨,Jason,
感谢您的精彩分享!
在(给定的例子中)使用双向 LSTM 时,TimeDistributed 包装器的目的是什么?
如果我们打算使用多个输入产生单个输出,使用它会有什么优势吗?
这将帮助您理解 time distributed 包装器的作用
https://machinelearning.org.cn/timedistributed-layer-for-long-short-term-memory-networks-in-python/
Bidirectional keras 包装器在掩码填充输入时是否存在一个故障,即它在一个方向上不计算掩码?
我没有遇到这个问题,也许可以测试一下以确认,然后向项目提出一个问题?
我测试了不同的 tensorflow 和 keras 版本(从 tf 导入)
tf 版本:2.1.0
tf.keras:2.2.4-tf
尽管在之前的 embed 层中指定了 mask_value=0,但在 BiDirectional 包装器中填充并未被掩码
print([layer.supports_masking for layer in model.layers])
>[True, False, True]
然而,
tf 版本:2.3.1
tf.keras 版本:2.4.0
在这些版本中填充已被掩码
print([layer.supports_masking for layer in model.layers])
[True, True, True]
我认为 tf 最近可能更新了这方面的内容。
感谢分享。
不客气,感谢您的文章!
感谢分享。我有一个问题,请回答我。
如何实现一个具有 256 个单元的 BiLSTM?LSTM 层没有 cell 参数。
节点/单元就是 cell。
快速提问——我有一个在线营销的 3D 数据集(家庭 * 天 * 在线广告),并且从该数据集中,我们为每个家庭进行训练——因此是一个 2D 矩阵,其中每一行代表一天,每一列代表一个潜在的广告。我只是想知道双向功能如何工作。
简单地反转矩阵会改变暴露的列以及家庭将接触到的广告,所以我们应该沿着时间序列轴(dim=1)反转矩阵。
这是思考这个问题的正确方式吗?以及该如何做到?
如果您可以应用 LSTM,那么您就可以应用双向 LSTM,在输入数据方面没有太大区别。
感谢分享。我有一个问题,请回答我。
我正在处理一个在频域中的数据库。实际上,对于每个样本,我都有一个单变量时间序列和 11 个类别。
每个时间序列的长度差异很大。对于最小类别,长度为 12,000,对于某些类别,最大长度为 56,000。
对于实现重叠窗口,我有点困惑,请帮帮我。
也许您可以将所有序列填充到相同的长度,然后使用掩码层来忽略填充值。
这可以帮助您理解滑动窗口
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
BiDirectional LSTMs 和掩码的问题似乎在于,通过向后读取数据,掩码会出现在前面(应该出现的位置)和后面(不应该出现的位置)。因此,我得到了奇怪的结果。
也许可以使用自定义模型,为每个序列的前向和后向路径提供一个输入,然后以两种不同的方式提供数据,一次提供给模型的每个输入头。
我正在使用深度学习(BLSTM)进行词性标注。在 BLSTM 层的填充和掩码方面遇到了困难。只对 LSTM 有效。
太棒了!
抱歉,我收到一个错误
:
“C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\python.exe” D:/PythonProject/HAR/Paper/mlmLSTM.py
2021-06-04 13:22:20.708270: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:22:20.708691: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2021-06-04 13:22:22.730407: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library nvcuda.dll
2021-06-04 13:22:23.660035: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties
pciBusID: 0000:01:00.0 name: GeForce MX330 computeCapability: 6.1
coreClock: 1.594GHz coreCount: 3 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 52.21GiB/s
2021-06-04 13:22:23.660883: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:22:23.661620: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublas64_11.dll’; dlerror: cublas64_11.dll not found
2021-06-04 13:22:23.662249: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublasLt64_11.dll’; dlerror: cublasLt64_11.dll not found
2021-06-04 13:22:23.665837: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cufft64_10.dll
2021-06-04 13:22:23.666999: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library curand64_10.dll
2021-06-04 13:22:23.667668: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusolver64_11.dll’; dlerror: cusolver64_11.dll not found
2021-06-04 13:22:23.668345: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusparse64_11.dll’; dlerror: cusparse64_11.dll not found
2021-06-04 13:22:23.669000: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudnn64_8.dll’; dlerror: cudnn64_8.dll not found
2021-06-04 13:22:23.669171: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflowcn.cn/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices…
2021-06-04 13:22:23.669965: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-06-04 13:22:23.670861: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix
2021-06-04 13:22:23.671169: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264]
回溯(最近一次调用)
File “D:\PythonProject\HAR\Paper\mlmLSTM.py”, line 27, in
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\training\tracking\base.py”, line 522, in _method_wrapper
result = method(self, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\sequential.py”, line 208, in add
layer(x)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\wrappers.py”, line 581, in __call__
return super(Bidirectional, self).__call__(inputs, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 945, in __call__
return self._functional_construction_call(inputs, args, kwargs,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 1083, in _functional_construction_call
outputs = self._keras_tensor_symbolic_call(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 816, in _keras_tensor_symbolic_call
return self._infer_output_signature(inputs, args, kwargs, input_masks)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 856, in _infer_output_signature
outputs = call_fn(inputs, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\wrappers.py”, line 694, in call
y = self.forward_layer(forward_inputs,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 660, in __call__
return super(RNN, self).__call__(inputs, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 1006, in __call__
outputs = call_fn(inputs, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent_v2.py”, line 1139, in call
inputs, initial_state, _ = self._process_inputs(inputs, initial_state, None)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 860, in _process_inputs
initial_state = self.get_initial_state(inputs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 642, in get_initial_state
init_state = get_initial_state_fn(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 2508, in get_initial_state
return list(_generate_zero_filled_state_for_cell(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 2990, in _generate_zero_filled_state_for_cell
return _generate_zero_filled_state(batch_size, cell.state_size, dtype)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 3006, in _generate_zero_filled_state
return tf.nest.map_structure(create_zeros, state_size)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\nest.py”, line 867, in map_structure
structure[0], [func(*x) for x in entries],
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\nest.py”, line 867, in
structure[0], [func(*x) for x in entries],
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 3003, in create_zeros
return tf.zeros(init_state_size, dtype=dtype)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\dispatch.py”, line 206, in wrapper
return target(*args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2911, in wrapped
tensor = fun(*args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2960, in zeros
output = _constant_if_small(zero, shape, dtype, name)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2896, in _constant_if_small
if np.prod(shape) < 1000
File "”, line 5, in prod
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\core\fromnumeric.py”, line 3051, in prod
return _wrapreduction(a, np.multiply, ‘prod’, axis, dtype, out,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\core\fromnumeric.py”, line 86, in _wrapreduction
return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\framework\ops.py”, line 867, in __array__
raise NotImplementedError(
NotImplementedError: Cannot convert a symbolic Tensor (bidirectional/forward_lstm/strided_slice:0) to a numpy array. This error may indicate that you’re trying to pass a Tensor to a NumPy call, which is not supported
进程以退出代码 1 结束
请帮助我
很抱歉听到这个消息,也许这些建议中的一些会对您有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,我想问一下,我现在遇到了这个错误
2021-06-04 13:51:55.949744: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:51:55.949948: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2021-06-04 13:51:58.240879: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library nvcuda.dll
2021-06-04 13:51:59.179144: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties
pciBusID: 0000:01:00.0 name: GeForce MX330 computeCapability: 6.1
coreClock: 1.594GHz coreCount: 3 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 52.21GiB/s
2021-06-04 13:51:59.180019: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:51:59.181090: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublas64_11.dll’; dlerror: cublas64_11.dll not found
2021-06-04 13:51:59.182227: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublasLt64_11.dll’; dlerror: cublasLt64_11.dll not found
2021-06-04 13:51:59.211775: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cufft64_10.dll
2021-06-04 13:51:59.217816: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library curand64_10.dll
2021-06-04 13:51:59.218823: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusolver64_11.dll’; dlerror: cusolver64_11.dll not found
2021-06-04 13:51:59.220086: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusparse64_11.dll’; dlerror: cusparse64_11.dll not found
2021-06-04 13:51:59.221200: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudnn64_8.dll’; dlerror: cudnn64_8.dll not found
2021-06-04 13:51:59.221417: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://tensorflowcn.cn/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices…
2021-06-04 13:51:59.222714: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-06-04 13:51:59.223413: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix
2021-06-04 13:51:59.223733: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264]
2021-06-04 13:52:00.392622: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (registered 2)
1/1 – 17s – loss: 0.7083 – accuracy: 0.4000
1/1 – 0s – loss: 0.6992 – accuracy: 0.4000
…………………………………………………………….
1/1 – 0s – loss: 0.1665 – accuracy: 0.9000
1/1 – 0s – loss: 0.1543 – accuracy: 0.9000
C:\Users\Zainal Arifien\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\sequential.py:450: UserWarning:
model.predict_classes()is deprecated and will be removed after 2021-01-01. Please use instead:*np.argmax(model.predict(x), axis=-1), if your model does multi-class classification (e.g. if it uses asoftmaxlast-layer activation).*(model.predict(x) > 0.5).astype("int32"), if your model does binary classification (e.g. if it uses asigmoidlast-layer activation).warnings.warn(‘
model.predict_classes()is deprecated and ‘预期:[0] 预测 [0]
预期:[0] 预测 [0]
预期:[0] 预测 [0]
预期:[0] 预测 [0]
Expected: [1] Predicted [0]
预期:[1] 预测 [1]
预期:[1] 预测 [1]
预期:[1] 预测 [1]
预期:[1] 预测 [1]
预期:[1] 预测 [1]
Process finished with exit code 0
也许是您的 tensorflow 安装有问题?也许试试重新安装?
很棒的文章!我正在寻找使用 Bi-LSTM 预测剩余有用寿命(RUL)的示例,特别是使用 C-MAPSS 数据集。是否可以将此代码改编为此?您是否有其他关于 RUL 使用 Bi-LSTM 的示例?非常感谢!
你好 Carlos……虽然我不能针对您的特定项目/应用发表评论,但我相信我们的资料在帮助您入门基本的机器学习概念方面会非常有用。
你是否正在寻找特定机器学习方法的示例代码?
也许我的博客上有一篇带有示例代码的教程。搜索博客
搜索机器学习精通
如果博客上没有示例,我无法随意告诉你到哪里获取代码。
尽管如此,我这里有一些想法
也许可以在 Google Scholar 上找到该方法的相关论文并给作者发邮件?
也许可以在 GitHub 上搜索?
也许可以在 Google 上搜索?
也许可以在 StackOverflow 或 CrossValidated 上搜索?
也许您可以在一本书中找到示例,使用 Google 图书搜索?
您好 Jason 博士,我需要有关 Bidirectional LSTM 实现的帮助,请。
–“前向路径”是否与“常规 lstm”相同?“仅前向路径”和“常规 lstm”之间有什么区别?
– 合并前向和后向层是否与 Bidirectional-lstm 相同?如果“是”,那么为什么在基础
论文“Bidirectional Recurrent Neural Networks/ IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 45, NO. 11, NOVEMBER 1997”中,“merge”与 bidirectional-lstm 不同?
谢谢您的回复
你好 star……以下资源可能有助于澄清
https://analyticsindiamag.com/complete-guide-to-bidirectional-lstm-with-python-codes/#:~:text=In%20bidirectional%2C%20our%20input%20flows,future%20and%20the%20past%20information.