Keras 是一个 Python 深度学习库,它提供对 TensorFlow 等强大数值库的简单便捷访问。
大型深度学习模型需要大量计算时间来运行。你可以在 CPU 上运行它们,但这可能需要数小时或数天才能获得结果。如果你在台式机上有 GPU,你可以大大加快深度学习模型的训练时间。
在这篇文章中,你将发现如何利用 Amazon Web Service (AWS) 基础架构来加速你的深度学习模型的训练。每小时只需几美元,而且通常更便宜,你就可以在工作站或笔记本电脑上使用此服务。
通过我的新书 《Python 深度学习》 开启你的项目,书中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- 更新 2016 年 10 月:已将示例更新为 Keras 1.1.0。
- 更新 2017 年 3 月:已更新为使用新的 AMI、Keras 2.0.2 和 TensorFlow 1.0。
- 更新 2019 年 2 月:已更新为使用新的“深度学习 AMI”和“p3.2xlarge”。

Amazon Web Services
照片由 Andrew Mager 拍摄,部分权利保留
教程概述
这个过程相当简单,因为大部分工作已经为我们完成了。
下面是该过程的概述。
- 设置您的 AWS 账户。
- 启动您的 AWS 实例。
- 登录并运行您的代码。
- 关闭您的 AWS 实例。
请注意,使用 Amazon 的虚拟服务器实例是收费的。对于临时模型开发,成本很低(例如,每小时不到一美元),这就是它如此吸引人的原因,但它不是免费的。
服务器实例运行的是 Linux。了解如何导航 Linux 或类 Unix 环境是理想的,但并非必需。我们只是运行 Python 脚本,所以不需要高级技能。
1. 设置您的 AWS 账户
您需要一个 Amazon Web Services 账户。
- 1. 您可以通过 Amazon Web Services 门户 创建一个账户,然后点击“Sign in to the Console”(登录控制台)。您可以从那里使用现有的 Amazon 账户登录,或创建一个新账户。
AWS 登录按钮
- 2. 您需要提供您的详细信息以及 Amazon 可以收费的有效信用卡。如果您已经是 Amazon 客户并且已保存信用卡信息,则此过程会快得多。
AWS 登录表单
拥有账户后,您可以登录 Amazon Web Services 控制台。
您将看到一系列可以访问的不同服务。
2. 启动您的 AWS 实例
现在您有了 AWS 账户,接下来要启动一个 EC2 虚拟服务器实例来运行 Keras。
启动实例就像选择要加载的镜像并启动虚拟服务器一样简单。幸运的是,已经有一个镜像提供了我们所需的大部分内容,它被称为 深度学习 AMI (Amazon Linux),由 Amazon 创建和维护。让我们将其作为实例启动。
- 1. 如果您尚未登录,请登录您的 AWS 控制台。

AWS 控制台
- 2. 点击 EC2 以启动新的虚拟服务器。
- 3. 从右上角的下拉菜单中选择“US West Oregon”。这一点很重要,否则您将找不到我们计划使用的镜像。
- 4. 点击“Launch Instance”(启动实例)按钮。
- 5. 点击“Community AMIs”(社区 AMI)。AMI 是 Amazon Machine Image(亚马逊机器镜像)。它是服务器的冻结实例,您可以选择它并在新虚拟服务器上实例化。
社区 AMI
- 6. 在“Search community AMIs”(搜索社区 AMI)搜索框中输入“Deep Learning AMI”(深度学习 AMI)并按 Enter。

深度学习 AMI
- 7. 点击搜索结果中的“Select”(选择)来选择 AMI。
- 8. 现在您需要选择要运行镜像的硬件。向下滚动并选择“p3.2xlarge”硬件(我以前推荐 g2 或 g3 实例 和 p2 实例,但 p3 实例 更新更快)。它包含一个 Tesla V100 GPU,我们可以用它来显著提高模型的训练速度。它还包括 8 个 CPU 核心、61GB RAM 和 16GB GPU RAM。注意:使用此实例大约每小时收费 3 美元。
p3.2xlarge EC2 实例
- 9. 点击“Review and Launch”(审查和启动)以完成服务器实例的配置。
- 10. 点击“Launch”(启动)按钮。
- 11. 选择您的密钥对。
- 如果您之前使用过 EC2 并拥有密钥对,请选择“Choose an existing key pair”(选择现有密钥对)并从列表中选择您的密钥对。然后勾选“I acknowledge…”(我确认…)。
- 如果您没有密钥对,请选择“Create a new key pair”(创建新密钥对)选项,并输入一个“Key pair name”(密钥对名称),例如 keras-keypair。点击“Download Key Pair”(下载密钥对)按钮。
选择您的密钥对
- 12. 打开终端,然后更改目录到您下载密钥对的位置。
- 13. 如果您还没有这样做,请限制您的密钥对文件的访问权限。这是 SSH 访问您的服务器所必需的。例如:
|
1 2 |
cd Downloads chmod 600 keras-aws-keypair.pem |
- 14. 点击“Launch Instances”(启动实例)。如果您是第一次使用 AWS,Amazon 可能需要验证您的请求,这可能需要长达 2 小时(通常只需几分钟)。
- 15. 点击“View Instances”(查看实例)以查看您的实例状态。
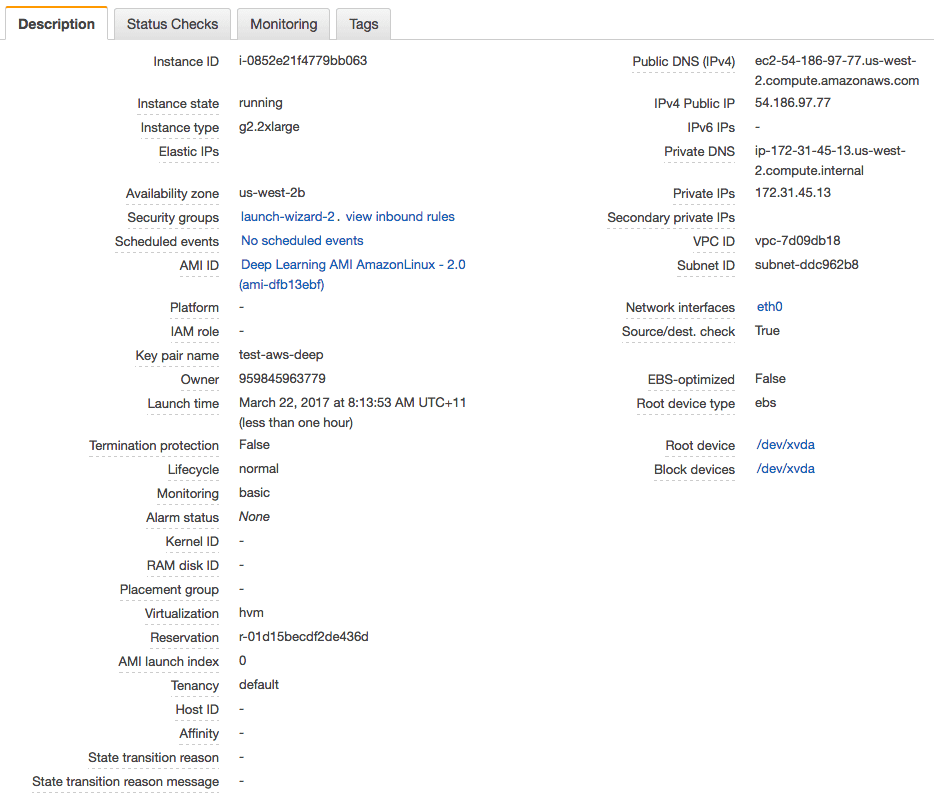
深度学习 AMI 状态
您的服务器现在正在运行,并已准备好供您登录。
3. 登录、配置和运行
现在您已经启动了服务器实例,是时候登录并开始使用了。
- 1. 如果您还没有这样做,请在您的 Amazon EC2 控制台中点击“View Instances”(查看实例)。
- 2. 将“Public IP”(公有 IP)(屏幕底部“Description”(描述)中的 IP)复制到剪贴板。在此示例中,我的 IP 地址是 54.186.97.77。请勿使用此 IP 地址,您的 IP 地址将不同。
- 3. 打开终端,然后更改目录到您下载密钥对的位置。使用 SSH 登录到您的服务器,例如:
|
1 |
ssh -i keras-aws-keypair.pem ec2-user@54.186.97.77 |
- 4. 出现提示时,键入“yes”并按 Enter。
您现在已登录到您的服务器。
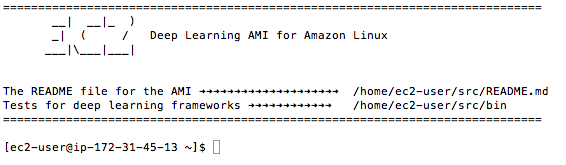
深度学习 AMI 的终端登录
实例会询问您希望使用哪个 Python 环境。我推荐使用
- TensorFlow(+Keras2)和 Python3(CUDA 9.0 和 Intel MKL-DNN)
您可以通过键入以下命令激活此虚拟环境:
|
1 |
source activate tensorflow_p36 |
这只需要一分钟。
您现在已准备好开始训练深度学习神经网络模型。
想在新实例上尝试什么?请参阅此教程
4. 关闭您的 AWS 实例
完成工作后,您必须关闭您的实例。
请记住,您需要按使用实例的时间付费。虽然便宜,但如果您不使用实例,您不希望它一直开启。
- 1. 在终端中退出您的实例,例如您可以键入:
|
1 |
exit |
- 2. 使用您的网络浏览器登录您的 AWS 账户。
- 3. 点击 EC2。
- 4. 从左侧菜单中点击“Instances”(实例)。
查看您的运行实例列表
- 5. 从列表中选择您正在运行的实例(如果您只有一个运行中的实例,它可能已自动选中)。

选择您正在运行的 AWS 实例
- 6. 点击“Actions”(操作)按钮,选择“Instance State”(实例状态),然后选择“Terminate”(终止)。确认您要终止正在运行的实例。
实例关闭并从您的实例列表中移除可能需要几秒钟。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
在 AWS 上使用 Keras 的技巧
以下是一些关于充分利用 AWS 实例上的 Keras 的技巧。
- 提前设计一套实验来运行。实验可能需要很长时间才能运行,您需要为使用时间付费。花时间设计一批实验在 AWS 上运行。将每个实验放入单独的文件中,并通过另一个脚本依次调用它们。这样,您可以从一次长时间运行(可能是一整晚)中回答多个问题。
- 将脚本作为后台进程运行。这将允许您关闭终端并关闭计算机,同时您的实验仍在运行。
您可以轻松地执行此操作:
|
1 |
nohup /path/to/script >/path/to/script.log 2>&1 < /dev/null & |
之后,您可以查看 script.log 文件中的状态和结果。 了解更多关于 nohup。
- 始终在实验结束时关闭您的实例。您不想收到一张巨额的 AWS 账单。
- 尝试使用 Spot 实例以获得更便宜但不太可靠的选择。Amazon 以更低的价格出售其硬件上的未使用时间,但代价是您的实例随时可能被关闭。如果您正在学习或您的实验并不关键,这可能是您的理想选择。您可以从 EC2 Web 控制台的左侧菜单中的“Spot Instance”(竞价实例)选项访问 Spot 实例。
有关在 AWS 上使用命令行命令的更多帮助,请参阅文章:
更多深度学习在 AWS 上的资源
以下是有关 AWS 和在云中构建深度学习的更多资源列表。
- Amazon Elastic Compute Cloud (EC2) 简介,如果您对此不熟悉
- Amazon Machine Images (AMI) 简介
- AMI Marketplace 上的深度学习 AMI(Amazon Linux)。
- P3 EC2 实例
总结
在这篇文章中,您发现了如何使用 Amazon Web Service 上的 GPU 在 Keras 中开发和评估您的大型深度学习模型。您学到了:
- Amazon Web Services 及其 Elastic Compute Cloud 提供了一种经济实惠的方式,可以在 GPU 硬件上运行大型深度学习模型。
- 如何设置和启动用于深度学习实验的 EC2 服务器。
- 如何更新服务器上的 Keras 版本并确认系统是否正常工作。
- 如何以后台任务批处理方式在 AWS 实例上运行 Keras 实验。
您对在 AWS 上运行模型或对此篇文章有任何疑问吗?请在评论中提问,我会尽力回答。






嗨,Jason,
你们有关于将模型部署为服务的教程吗?我想让用户能够上传一张图片,然后我可以用自定义分类器对它进行分类。
我看了您的书,我认为这部分内容没有涉及。我认为这将是您本书的一个很棒的毕业项目。
我目前没有关于将模型部署为服务的信息。
通常,您可以使用 MLaaS(如 Google Prediction、Amazon、Azure 或 BigML)。
我在实际操作中将模型部署为服务,但这始终是一项定制工作。例如,自定义输入传递和自定义模型输出处理。
因此,当我调用 theano 时,我得到这个错误:
CNMeM 已启用,初始大小为:95.0% 的内存,cuDNN 版本太旧。请更新到 v5,当前版本为 3007。
我该如何解决这个问题?
您可以忽略此错误。它不会影响示例。
感谢这篇很棒的教程。
1. 这仅限于特定示例,还是我可以在 AWS 上训练任何内容?
2. 如何将数据上传/下载到/从服务器?
3. 您是否知道有适用于 caffe 和 python 的基于 Windows 的服务器配置?
是的,您可以在合理范围内使用此 AWS 训练任何您喜欢的模型。
您可以使用安全复制命令从命令行将您的数据/代码复制到您的 AWS 实例,如下所示:
scp -r -i /path/to/keys yourdir ip.address:/path/
抱歉,我不知道 Windows 或 Windows 服务器。
感谢您提供的有用入门指南……期待将其应用于实际示例。
另外,根分区只有大约 4GB 的可用空间,但 /mnt 应该有大约 60GB。最好将较大的数据文件放在那里。
谢谢你的提示,Fred。
嗨!感谢精彩的教程!目前我正在训练 VGG16,与我的 CPU 相比,它的训练速度快了很多——每 epoch 870 秒 vs 70 秒 :)
顺便问一下,如果不是终止而是创建备份镜像然后每次从它开始呢?
很高兴听到这个消息,Alexander。
创建检查点并从检查点重新开始训练是一个好主意,以防出现问题。您可以在此处了解 Keras 中的模型检查点。
https://machinelearning.org.cn/check-point-deep-learning-models-keras/
如何使用 AWS 部署深度学习集群。
好问题,Linghai。我不知道。
告诉我进展如何。
该死!错过了。这是另一个让我经常访问您博客的原因。我花了一整夜才弄清楚如何在 AWS 上正确配置 cudnn、keras 和所有这些东西。我本可以只看这个博客然后使用 AMI。
很高兴您找到了这篇文章,Anurag。
你好,
我将一个开源 AWS AMI 链接到您的精彩指南,以便初学者可以安装。如果您觉得可以,请告诉我。
https://github.com/ritchieng/tensorflow-aws-ami
TFAMI 包含 Keras、TensorFlow 和 OpenAI Gym。这是最难安装的组合之一。所以我决定创建一个积极维护的开源 AMI。您可以随时推荐给初学者,而不是您目前推荐的那个。
TFAMI 在所有区域都可用。
祝好,
Ritchie
嗨 Ritchie,
干得好。我会在有时间的时候尝试您的 AMI——看起来很有用。
感谢分享。
嗨 Ritchie,
感谢您创建这个。但是,我尝试了您的 TFAMI.v2(弗吉尼亚州 ami-a96634be),在 p2.xlarge AWS Spot 请求中使用时,发现机器上找不到 GPU(输出如下)。有什么想法吗?
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so.5 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
E tensorflow/stream_executor/cuda/cuda_driver.cc:491] failed call to cuInit: CUDA_ERROR_NO_DEVICE
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:153] retrieving CUDA diagnostic information for host: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:160] hostname: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:185] libcuda reported version is: 367.57.0
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:356] driver version file contents: “””NVRM version: NVIDIA UNIX x86_64 Kernel Module 367.48 Sat Sep 3 18:21:08 PDT 2016
GCC version: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.2)
"""
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] kernel reported version is: 367.48.0
E tensorflow/stream_executor/cuda/cuda_diagnostics.cc:296] kernel version 367.48.0 does not match DSO version 367.57.0 — cannot find working devices in this configuration
I tensorflow/core/common_runtime/gpu/gpu_init.cc:81] No GPU devices available on machine.
如果我想使用 AWS AMI 在我的笔记本电脑上的数据集训练深度学习模型,我是否需要将数据上传到 AWS S3?
不,您可以上传到您的 EC2 服务器。
嗨,Jason,
您能否向我们展示如何将此部署到小型集群(例如,暂时是两台 GPU 机器)?我将非常非常感激。
另外,我刚买了您的 DL 和 ML 书籍(通过公司)。书中是否有额外的材料?
谢谢,
Sachin
嗨 Sachin,
抱歉,我没有将模型部署到集群的示例。
非常感谢您提供清晰的教程,Jason。我也已经购买了您的书籍。对我来说,除了一个例外之外,一切正常——我无法切换到 g2.2xlarge,由于我选择了 12 个月的免费试用,我只能选择 t2.micro。我到处查找但找不到切换到更快硬件的方法。
我不在乎按小时费率支付计算实例费用,但我不想被困在一个昂贵的开发者账户中,需要按月订阅,因为我的个人项目需要 AWS。
有没有解决办法?我查阅了预留实例,但同样,似乎我至少要被锁定 12 个月的服务。
谢谢你。
Katya,我不知道这是否适用于您,但我不得不专门请求增加限制才能访问 GPU 实例。请参阅 http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-resource-limits.html
除此之外,我按小时付费,没有订阅。
希望这有帮助。
说得好,谢谢 Hugues 的提示。
嗨 Katya,
我相信您可能需要联系 AWS 支持并请求访问更大的硬件。他们可能需要对您的账户进行快速检查,然后批准访问。这通常是一个非常快速的过程。
告诉我进展如何。
嗨 Jason
谢谢您的发布!我想知道 jupyter notebook 是否预装在此 AMI 中,还是我需要自己安装?谢谢!
我不知道 Jenny,我不用笔记本,只用命令行。
你好,
我在 ami-125b2c72 上运行 Faster RCNN 网络时遇到了一些错误。我应该为这个 AMI 安装哪个版本的 opencv?我需要更改/降级 CUDA 和 cuDNN 的版本吗?
嗨 Supriya,除了教程中提到的内容外,我没有安装或升级任何东西。没有 opencv,我也没有触碰 cuda 或 cudnn。
当我们停止实例时,所有数据都会被擦除,重新下载数据集和配置我们的代码似乎有点麻烦。我们应该使用 EBS 存储服务吗?或者您有什么建议?谢谢。
正确。
考虑使用 S3 等存储服务来存储数据集。看看 Amazon 的文档,但我认为将数据存储在 Amazon 基础架构中具有成本优势。
嗨 Jason,首先,抱歉离题讨论,
我想知道,是否可以运行在 Eclipse 环境中开发的 Java 项目(项目开发过程中导入了很多包)在 AWS 服务器上以获得高计算速度?如果可以,您能否提供一些参考?我对 Amazon AWS 是新手,发现描述有点复杂。
我喜欢这个教程,从中任何人都可以轻松理解步骤。
此致
是的,我看不出为什么不可以。抱歉,我没有教程或资源。
嗨,Jason,
不幸的是,ami-125b2c72 在 us-east-1 区域不再可用。您能推荐其他带有 Keras + GPU 的 AMI 吗?
祝好,
Nick
很抱歉听到这个消息,我会研究一下下一步的措施。
在那之前,我认为这个不错
https://github.com/ritchieng/tensorflow-aws-ami
不幸的是,这个也无法使用了:“最新更新:我们的 Amazon 积分已过期 ¯\_(ツ)_/¯ 因此,我们无法在所有区域托管这些 AMI”。我将尝试运行 Kaggle ML 镜像,这似乎是一个可行的镜像。
嗨 Nick,AMI 仍然可用,我刚刚自己使用过。
嗨,Jason,
感谢您的努力,但我仍然找不到它。今天,我再次在 N.Virginia 区域搜索了“Community AMI”部分,查找名称为 TFAMI.v3 和 ami-name: ami-0e969619。对 N.California 也做了同样的操作,检查了 TFAMI.v3 和 ami-08451468。未找到 AMI。
我认为您之所以能找到它,是因为您将其保存在了“My AMI”列表中。
我同意 Nick,它现在也没了。
我将找到一个可靠的替代品(或自己制作一个),并尽快更新教程。
更新:我已经更新了教程,使用了新的更好的 AMI。
你好,你决定不将 AMI 更新到 keras v 2.0.2 吗?看起来 AMI 是 v 1.2.2。
请注意教程中我展示如何更新 Keras 版本的部分。
谢谢。另外,您的教程非常棒,帮助很大。感谢分享。
谢谢 CK,很高兴听到这个。
我意识到这篇文章最初写于一年多以前,但现在 p2.xlarge 实例已可用,而 g2.2xlarge 的速度大约是其一半,还有理由继续使用后者吗?
有关性能比较,请参阅
http://blog.bitfusion.io/2016/11/03/quick-comparison-of-tensorflow-gpu-performance-on-aws-p2-and-g2-instances
以及 AWS 网站上的常见问题解答
P2 实例使用 NVIDIA Tesla K80 GPU,专为使用 CUDA 或 OpenCL 编程模型的通用 GPU 计算而设计。P2 实例为客户提供高带宽 20Gbps 网络、强大的单精度和双精度浮点能力以及纠错码 (ECC) 内存,非常适合深度学习、高性能数据库、计算流体动力学、计算金融、地震分析、分子建模、基因组学、渲染以及其他服务器端 GPU 计算工作负载。通过最新的驱动程序版本,P2 实例支持 CUDA 7.5 和 OpenCL 1.2。
G2 实例使用 NVIDIA GRID GPU,为使用 DirectX 或 OpenGL 的图形应用程序提供经济高效、高性能的平台。NVIDIA GRID GPU 还支持 NVIDIA 的快速捕获和编码 API。示例应用程序包括视频创建服务、3D 可视化、流媒体图形密集型应用程序以及其他服务器端图形工作负载。通过初始驱动程序版本,G2 实例支持 DirectX 9、10 和 11、OpenGL 4.3、CUDA 5.5、OpenCL 1.1 和 DirectCompute。
太好了,谢谢你的提醒,James!
Jason,您的教程是最好的教程之一。感谢您创建这些资源。
关于 AWS 与 Google Cloud ML,您有什么看法?
谢谢 Kim。不,我没有用过 Google,但我已经使用了 AWS 很多年,并且信任它。
你好,
选择哪种 EC2 实例类型是最好(正确)的?
我的意思是,适合本课程应用程序要求的实例类型是哪种?
不应该太贵也不应该太便宜,但必须实用(速度和内存……等)
这取决于您的问题。g2 和 p2 实例对我来说都很好。
你好
我尝试了多次来启动实例(ami-dfb13ebf),但在进行到第 7 步时:(第 7 步:查看实例启动)
启动失败
我联系了 AWS 并得到了以下回复:
(((感谢您联系我们。您看到的错误消息是由于没有访问特定实例类型的权限。您有一个默认的按需实例限制为二十个。我们很乐意为您提交一个限制增加请求,请告知我们您想要申请的实例类型。
希望这有帮助,如果您有任何问题,请告知我们。
此致,))))
请帮我开始这个课程,我还没有开始!
我如何在 putty 中进行操作,因为我的电脑是 Windows?
非常感谢您的帮助!
Saeed
我建议联系 AWS 支持,并要求更改您的帐户,以便您可以访问该实例。
你好,Jason!
首先,非常感谢您的博客和工作。我是一名对机器学习感兴趣的学生,在许多事情上,我的起点是您的博客。
我正在为我的硕士论文试验 LSTMs 和时间序列预测,并且我发现 GPU 计算(例如在 AWS 的 g2.2xlarge 实例上)比在便宜得多的仅 CPU 机器(甚至是我笔记本电脑的 core i5)上要慢得多。
您有过类似的经历吗?我已经阅读了一些博客和开发者帖子,他们说 tensorflow 后端对 lstm 的实现很慢,还有很多人也遇到了这个问题。我用 Theano 得到了几乎相同的结果。我已经知道批次大小对提高 GPU 性能有很大潜力,但不太确定问题是否是由于问题的顺序类型导致 GPU 无法胜过 CPU。
如果您能分享您的观点和经验,那将是非常棒的。
例如
https://news.ycombinator.com/item?id=14538086 或 https://groups.google.com/forum/#!topic/neon-users/3BDEEO6v_24
或者
https://groups.google.com/forum/#!topic/neon-users/3BDEEO6v_24
诚挚的问候,
Constantin
你好 Constantin,
是的,我经常遇到这种情况,只有在使用 LSTM 模型时。我现在正在拟合字幕生成模型(大型语言模型组件),并且我可能会在我的本地 i7 上运行,而不是在 AWS 的 GPU 上运行。
很高兴知道这是一个普遍的问题。我不会纠结,有工作要做,我会在任何地方运行我的代码,我只需要结果。
嗨,Jason,
根据您的博客,我创建了一个 AWS 账户并租用了一个 g2.2xlarge 实例。当我运行这段代码时——9.3 Grid Search Deep Learning Model Parameters(这是您书中的内容,我也买了您的书)。它需要很长时间,我等了 30 分钟。在 AWS 上需要这么长时间吗?我对 AWS 是新手,所以不确定它卡在哪一个阶段。
来自 keras.models import Sequential
from keras.layers import Dense
来自 keras.wrappers.scikit_learn 的 KerasClassifier
from sklearn.model_selection import GridSearchCV
import numpy
# 创建模型的功能,KerasClassifier 所必需
def create_model(optimizer=’rmsprop’, init=’glorot_uniform’)
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer=init, activation=’relu’))
model.add(Dense(8, kernel_initializer=init, activation=’relu’))
model.add(Dense(1, kernel_initializer=init, activation=’sigmoid’))
# 编译模型
model.compile(loss=’binary_crossentropy’, optimizer=optimizer, metrics=[‘accuracy’])
return model
# 设置随机种子以保证结果可复现
seed = 7
numpy.random.seed(seed)
# 加载皮马印第安人糖尿病数据集
dataset = numpy.loadtxt(“/home/ec2-user/pima-indians-diabetes.csv”, delimiter=”,”)
# 分割为输入 (X) 和输出 (Y) 变量
X = dataset[:,0:8]
Y = dataset[:,8]
# 创建模型
model = KerasClassifier(build_fn=create_model, verbose=0)
# grid search epochs, batch size and optimizer
optimizers = [‘rmsprop’, ‘adam’]
inits = [‘glorot_uniform’, ‘normal’, ‘uniform’]
epochs = [50, 100, 150]
batches = [5, 10, 20]
param_grid = dict(optimizer=optimizers, epochs=epochs, batch_size=batches, init=inits)
print param_grid
grid = GridSearchCV(estimator=model, param_grid=param_grid)
grid_result = grid.fit(X, Y)
# 总结结果
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
for mean, stdev, param in zip(means, stds, params)
print(“%f (%f) with: %r” % (mean, stdev, param))
不应该花太长时间。
多线程运行可能会导致 AWS 使用 GPU 出现问题。
尝试另一个更简单的示例,以确保 AWS 实例正常工作。
尝试将网格搜索简化为每个参数 1 个值,看看它是否能在合理的时间内完成。然后从那里扩展。
告诉我进展如何。
只是想告诉您 Keras 使用 TensorFlow 作为后端。我希望这不会影响性能?
我目前主要使用 TF 后端。
Hi Jason, 我尝试了几个小的代码,比如 cv 和一些小的代码。它们工作正常。这个需要很长时间。我尝试对其进行调整,但仍然需要很长时间。我计划在更大的数据集上运行一些代码。到时候会告诉您我的发现。
当然可以。
这篇文章很棒,就像我读过的您所有的文章一样。非常感谢。
我很想知道如何让 CNTK 在 Keras 中,在 AWS 上运行的教程,考虑到它在 LSTM 速度上相比 TensorFlow 和 Theano 的炒作。
我尝试使用微软的文档安装 CNTK 时遇到错误。
感谢您的建议 Stuart。
运行后
> python -c “import keras; print keras.__version__”
我得到
> 使用 TensorFlow 后端。
> 2.0.8
我现在使用 g2.2xlarge,AMI:Deep Learning AMI Amazon Linux – 3.3_Oct2017 (ami-78994d02)。
有没有办法确保 GPU 正在被使用?当我运行“pip list”时,列出的是“tensorflow (1.3.0)”,而不是“tensorflow-gpu”。
我也很困惑,因为我在 https://machinelearning.org.cn/tutorial-first-neural-network-python-keras/ 上 #6 运行了您的 Pima Indian 代码,在相同的 Deep Learning AMI 上,代码在 t2.large 上大约需要 15 秒,但在 p2.xlarge 上却需要 45 秒!这些时间是在我运行了多次之后。
为什么在 GPU 实例上运行速度会慢得多?
是的,在这篇文章中有一个命令可以用来检查 GPU 是否正在被使用以及使用的程度。
https://machinelearning.org.cn/command-line-recipes-deep-learning-amazon-web-services/
对于小问题,由于开销,GPU 可能会导致性能变差。像 MNIST 或 CIFAR 这样的大型图像分类问题将是一个很好的测试。
你好,
我正在尝试实现这个教程。我尝试使用不同的训练文本,但它比《爱丽丝梦游仙境》短得多,而且我的模型只输出了重复 1000 次的字母“a”。这是由于训练数据不够充分吗?关于需要多少数据,有什么经验法则吗……?
也许可以尝试更长时间地训练模型?
嗨,Jason,
我遵循了您的说明(选择了相同的集群,下载了相同的软件包等)。
我可以正常下载 scikit-learn,但是当我进入 python 并尝试导入 sklearn 时,它告诉我:
“ImportError: No module named sklearn”
我尝试了许多不同的方法来下载 scikit-learn,但都无效。有什么故障排除技巧吗?
谢谢
你好,
我之前运行的是 `python [scriptname.py`,但在运行 `python3 [scriptname.py]` 时它运行正常。
虚惊一场!
很高兴听到这个消息。
听起来 sklearn 没有正确安装。
感谢这篇很棒的教程。
我正在训练一本名为“Deep Learning with Python”的书中的一个卷积神经网络示例。
在我的笔记本电脑上,一台性能较差的 ThinkPad T540,每个 epoch 大约需要 55 秒。
我在 AWS Ubuntu GPU 计算 p2.xlarge 实例上运行了相同的代码,每个 epoch 仍然需要 42 秒。
我肯定有什么遗漏。是不是我有什么地方做错了,导致在 AWS 上如此缓慢?
谢谢,
蒂姆
可能是内存或硬盘速度?
可能是批次大小或其他配置?
感谢您的回复 Jason。
我希望是某些明显的问题。
您知道有什么方法可以检查 Keras 和 TensorFlow 后端是否正在使用 GPU 吗?
当您开始运行模型时,TensorFlow 通常会打印关于正在使用哪个 GPU 的调试信息。
您还可以使用 nvidia 工具来查看 GPU 利用率,我在这个帖子中提供了一些命令行输入:
https://machinelearning.org.cn/command-line-recipes-deep-learning-amazon-web-services/
你好,我在 AWS 中构建了一个机器学习模型(类型:二元分类),然后对其进行了评估。现在我想运行这个模型 100 次,看看完成时间和每次运行的成本。有什么方法可以做到吗?
当然,但您需要自己编写代码。
棒极了的帖子。
谢谢,很高兴对您有帮助。
更新/供参考:AWS 可能对启动 g2.2xlarge 和/或 p2.xlarge 实例(GPU 实例)有新的规定。我无法创建这两种实例,不得不联系亚马逊以“请求增加限制”来提高我目前对上述 2 种类型的 0 个实例的限制到 1 个。我刚刚提交了请求,当审查结果出来时,我会更新此评论。
但是,在等待访问 GPU 实例时。我已经完成了 Jasons 关于“免费”实例的教程。我建议您继续进行,因为这其中有几个步骤。我遇到的一个问题是,当我创建工作实例时,我尝试使用在尝试创建另一个实例时创建的密钥。这阻止了我 SSH 进入我的新实例。对于我们这些新手来说,您可能想为新实例创建一个新的密钥,以使事情在开始时保持简单。
很棒的建议,感谢分享 Eric!
这太棒了。感谢您的帖子。
我想知道一件事,如何设置 2 个 AWS 实例进行分布式计算?到目前为止,我有一个 AWS GPU 实例,我在上面训练我的 DL 模型。我想再创建一个并在并行中训练模型,以便训练速度更快。有什么方法可以做到吗?
谢谢你,
KK
抱歉,我没有 AWS 分布式计算的示例。
谢谢您的回复,先生。🙂
然后我使用 google colab GPU,它只比 CPU 快 3 倍。速度提升不应该接近 10 倍吗?
这取决于硬件、数据集和模型的类型。
嗨,Jason,
非极大值抑制(NonMaximum Supression)是一种避免对同一对象进行重复检测的方法。
但是,如果它们来自不同的类(在相似对象上),即使 NMS 阈值不变,您也会得到该对象上的两个实例。
我的问题是
如何自定义您的代码,使其认为只有一个对象,并且它应该为该对象选择置信度更高的类别?
所以现实中的一个对象在检测中应该只有一个对象。
感谢您的帮助。
您的项目很棒。
我相信大多数模型,如 yolo 和 rcnn,都直接在输出端实现了 NMS。无需深入研究。
那么我必须将 NMS 应用于输出,并对不同类别的相交矩形执行此操作吗?
是的。
嘿 Jason,我收到 AWS 的启动失败错误——“您请求的 vCPU 容量超过了您当前属于指定实例类型的实例桶的 vCPU 限制 0。” 您知道有什么变通方法吗?
谢谢!
也许直接联系 AWS 支持,他们响应很快。
我一直在与 AWS 合作解决这个问题,但没有成功。他们将我的 vCPU 限制增加到 10,但我仍然收到相同的错误消息。此外,当我尝试限制我下载的密钥对文件(名为 keras-keypair)的访问权限,运行您上面提供的代码(“chmod 600 keras-aws-keypair.pem”)时,我收到一条错误消息,说“没有这样的文件或目录”。我仔细检查过,文件在正确的目录中。但是当我尝试运行“chmod 600 keras-keypair.pem”时,我没有收到错误消息。这会不会是问题的根源?
谢谢
很抱歉听到您仍然遇到麻烦。
您必须在文件与您键入命令时位于同一位置时,在命令行中更改文件的权限。
否则,您必须指定文件的完整路径。
嘿,如何使用任何本地编辑器并在云端运行 notebook?我的笔记本电脑不好,不适合机器学习,我想在云端运行 notebook。
抱歉,我不使用笔记本,也不推荐使用它们
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
嗨,Jason,
你试过使用笔记本电脑的 GPU 吗?我最近在一个不同的环境中为我的笔记本电脑安装了 tensorflow gpu。而在另一个环境中,我只安装了 tensorflow。mnist 示例在有和没有 GPU 的情况下运行时,训练时间相同。
你是否知道为什么使用 GPU 没有提高性能?
一直以来都感谢你。
你好 tanuja……感谢你的提问!为了通过 GPU 获得性能提升,有必要针对专门设计用于利用 GPU 架构的功能。以下资源可能有助于理解如何在 Amazon Web Services 环境中训练 Keras 模型。
https://machinelearning.org.cn/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/