词嵌入是自然语言处理中表示文本的一种现代方法。
词嵌入算法,如 word2vec 和 GloVe,是神经网络模型在机器翻译等自然语言处理问题上取得最先进结果的关键。
在本教程中,您将学习如何使用 Gensim 在 Python 中训练和加载用于自然语言处理应用的词嵌入模型。
完成本教程后,您将了解:
- 如何根据文本数据训练您自己的 word2vec 词嵌入模型。
- 如何使用主成分分析 (PCA) 可视化训练好的词嵌入模型。
- 如何从 Google 和 Stanford 加载预训练的 word2vec 和 GloVe 词嵌入模型。
通过我的新书《深度学习与自然语言处理》启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧。

如何使用 Gensim 在 Python 中开发词嵌入
图片作者:dilettantiquity,保留部分权利。
教程概述
本教程分为6个部分;它们是
- 词嵌入
- Gensim 库
- 开发 Word2Vec 嵌入
- 可视化词嵌入
- 加载 Google 的 Word2Vec 嵌入
- 加载 Stanford 的 GloVe 嵌入
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
词嵌入
词嵌入是一种提供词语密集向量表示的方法,它能捕捉词语的某些含义。
词嵌入比简单的词袋模型词编码方案(如词频和词计数)有所改进,后者会产生描述文档而非词语含义的大而稀疏的向量(大部分为 0 值)。
词嵌入通过使用算法,根据大量文本语料库训练一组固定长度的密集连续值向量。每个词都由嵌入空间中的一个点表示,这些点根据目标词周围的词进行学习和移动。
通过其上下文来定义一个词,使词嵌入能够学习词语的含义。词语的向量空间表示提供了一个投影,其中含义相似的词语在空间中局部聚集。
使用词嵌入而非其他文本表示是导致深度神经网络在机器翻译等问题上取得突破性性能的关键方法之一。
在本教程中,我们将学习如何使用两种不同的词嵌入方法:Google 研究人员开发的 word2vec 和 Stanford 研究人员开发的 GloVe。
Gensim Python 库
Gensim 是一个用于自然语言处理的开源 Python 库,主要侧重于主题建模。
它被宣传为
为人类服务的主题建模
Gensim 由捷克自然语言处理研究员 Radim Řehůřek 和他的公司 RaRe Technologies 开发并维护。
它不是一个“包罗万象”的 NLP 研究库(像 NLTK 那样);相反,Gensim 是一个成熟、专注且高效的用于主题建模的 NLP 工具套件。对于本教程来说,最值得注意的是,它支持 Word2Vec 词嵌入的实现,用于从文本中学习新的词向量。
它还提供了加载多种格式的预训练词嵌入,以及使用和查询已加载嵌入的工具。
我们将在本教程中使用 Gensim 库。
如果您没有设置 Python 环境,可以使用本教程
Gensim 可以通过 pip 或 easy_install 轻松安装。
例如,您可以在命令行中输入以下内容,通过 pip 安装 Gensim
|
1 |
pip install --upgrade gensim |
如果您在系统上安装 Gensim 时需要帮助,可以查阅 Gensim 安装说明。
开发 Word2Vec 嵌入
Word2vec 是一种从文本语料库学习词嵌入的算法。
有两种主要的训练算法可用于从文本中学习嵌入;它们是连续词袋 (CBOW) 和 skip-grams。
我们不会深入探讨这些算法,只说它们通常会查看每个目标词的词语窗口,以提供上下文,进而提供词语的含义。该方法由 Tomas Mikolov 开发,他曾就职于 Google,目前在 Facebook。
Word2Vec 模型需要大量文本,例如整个维基百科语料库。尽管如此,我们将使用一个小的内存中文本示例来演示其原理。
Gensim 提供了 Word2Vec 类用于处理 Word2Vec 模型。
从文本中学习词嵌入涉及将文本加载并组织成句子,然后将其提供给新的 `Word2Vec()` 实例的构造函数。例如
|
1 2 |
sentences = ... model = Word2Vec(sentences) |
具体来说,每个句子都必须进行分词,即分成单词并进行准备(例如,可能预过滤并转换为首选大小写)。
这些句子可以是加载到内存中的文本,也可以是逐步加载文本的迭代器,这对于非常大的文本语料库是必需的。
这个构造函数有很多参数;您可能希望配置的几个值得注意的参数是
- size:(默认 100)嵌入的维度数,例如,表示每个标记(单词)的密集向量的长度。
- window:(默认 5)目标词和目标词周围词之间的最大距离。
- min_count:(默认 5)训练模型时要考虑的词的最小计数;出现次数少于此计数的词将被忽略。
- workers:(默认 3)训练时使用的线程数。
- sg:(默认 0 或 CBOW)训练算法,可以是 CBOW (0) 或 skip gram (1)。
刚开始时,默认值通常就足够了。如果您的计算机有许多核心(大多数现代计算机都有),我强烈建议您将 `workers` 增加到与核心数匹配(例如 8)。
模型训练完成后,可以通过“wv”属性访问。这是实际的词向量模型,可以在其中进行查询。
例如,您可以打印学习到的标记(单词)词汇表,如下所示
|
1 2 |
words = list(model.wv.vocab) print(words) |
您可以查看特定标记的嵌入向量,如下所示
|
1 |
print(model['word']) |
最后,训练好的模型可以通过调用词向量模型上的 `save_word2vec_format()` 函数保存到文件中。
默认情况下,模型以二进制格式保存以节省空间。例如
|
1 |
model.wv.save_word2vec_format('model.bin') |
开始时,您可以将学习到的模型保存为 ASCII 格式并查看内容。
您可以通过在调用 `save_word22vec_format()` 函数时设置 `binary=False` 来完成此操作,例如
|
1 |
model.wv.save_word2vec_format('model.txt', binary=False) |
然后可以通过调用 `Word2Vec.load()` 函数再次加载保存的模型。例如
|
1 |
model = Word2Vec.load('model.bin') |
我们可以将所有这些与一个示例结合起来。
我们不从文件中加载大型文本文档或语料库,而是使用一个小的、内存中的预分词句子列表。模型经过训练,并将单词的最小计数设置为 1,以便不忽略任何单词。
模型学习完成后,我们进行总结,打印词汇表,然后打印单词“sentence”的单个向量。
最后,模型以二进制格式保存到文件中,然后加载并进行总结。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from gensim.models import Word2Vec # 定义训练数据 sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'], ['this', 'is', 'the', 'second', 'sentence'], ['yet', 'another', 'sentence'], ['one', 'more', 'sentence'], ['and', 'the' 'final', 'sentence']] # 训练模型 model = Word2Vec(sentences, min_count=1) # 总结加载的模型 print(model) # 总结词汇表 words = list(model.wv.vocab) print(words) # 访问一个单词的向量 print(model['sentence']) # 保存模型 model.save('model.bin') # 加载模型 new_model = Word2Vec.load('model.bin') print(new_model) |
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例会打印以下输出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Word2Vec(vocab=14, size=100, alpha=0.025) ['second', 'sentence', 'and', 'this', 'final', 'word2vec', 'for', 'another', 'one', 'first', 'more', 'the', 'yet', 'is'] [ -4.61881841e-03 -4.88735968e-03 -3.19508743e-03 4.08568839e-03 -3.38211656e-03 1.93076557e-03 3.90265253e-03 -1.04349572e-03 4.14286414e-03 1.55219622e-03 3.85653134e-03 2.22428422e-03 -3.52565176e-03 2.82056746e-03 -2.11121864e-03 -1.38054823e-03 -1.12888147e-03 -2.87318649e-03 -7.99703528e-04 3.67874932e-03 2.68940022e-03 6.31021452e-04 -4.36326629e-03 2.38655557e-04 -1.94210222e-03 4.87691024e-03 -4.04118607e-03 -3.17813386e-03 4.94802603e-03 3.43150692e-03 -1.44031656e-03 4.25637932e-03 -1.15106850e-04 -3.73274647e-03 2.50349124e-03 4.28692997e-03 -3.57313151e-03 -7.24728088e-05 -3.46099050e-03 -3.39612062e-03 3.54845310e-03 1.56780297e-03 4.58260969e-04 2.52689526e-04 3.06256465e-03 2.37558200e-03 4.06933809e-03 2.94650183e-03 -2.96231941e-03 -4.47433954e-03 2.89590308e-03 -2.16034567e-03 -2.58548348e-03 -2.06163677e-04 1.72605237e-03 -2.27384618e-04 -3.70194600e-03 2.11557443e-03 2.03793868e-03 3.09839356e-03 -4.71800892e-03 2.32995977e-03 -6.70911541e-05 1.39375112e-03 -3.84263694e-03 -1.03898917e-03 4.13251948e-03 1.06330717e-03 1.38514000e-03 -1.18144893e-03 -2.60811858e-03 1.54952740e-03 2.49916781e-03 -1.95435272e-03 8.86975031e-05 1.89820060e-03 -3.41996481e-03 -4.08187555e-03 5.88635216e-04 4.13103355e-03 -3.25899688e-03 1.02130906e-03 -3.61028523e-03 4.17646067e-03 4.65870230e-03 3.64110398e-04 4.95479070e-03 -1.29743712e-03 -5.03367570e-04 -2.52546836e-03 3.31060472e-03 -3.12870182e-03 -1.14580349e-03 -4.34387522e-03 -4.62882593e-03 3.19007039e-03 2.88707414e-03 1.62976081e-04 -6.05802808e-04 -1.06368808e-03] Word2Vec(vocab=14, size=100, alpha=0.025) |
正如您所见,只需稍加准备文本文档,就可以使用 Gensim 非常轻松地创建自己的词嵌入。
可视化词嵌入
在您学习了文本数据的词嵌入之后,使用可视化对其进行探索会很不错。
您可以使用经典投影方法将高维词向量降维到二维平面并绘制在图表上。
这些可视化可以为您学习到的模型提供定性诊断。
我们可以从训练好的模型中检索所有向量,如下所示
|
1 |
X = model[model.wv.vocab] |
然后我们可以使用 scikit-learn 中提供的方法(例如 PCA)在向量上训练投影方法,然后使用 matplotlib 绘制投影的散点图。
让我们看一个使用主成分分析或 PCA 的示例。
使用 PCA 绘制词向量
我们可以使用 scikit-learn PCA 类来创建词向量的 2 维 PCA 模型,如下所示。
|
1 2 |
pca = PCA(n_components=2) result = pca.fit_transform(X) |
生成的投影可以使用 matplotlib 绘制,如下所示,将两个维度作为 x 和 y 坐标。
|
1 |
pyplot.scatter(result[:, 0], result[:, 1]) |
我们可以更进一步,用单词本身标注图上的点。一个没有美观偏移的粗略版本如下所示。
|
1 2 3 |
words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) |
将所有这些与上一节中的模型结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from gensim.models import Word2Vec 从 sklearn.分解 导入 PCA from matplotlib import pyplot # 定义训练数据 sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'], ['this', 'is', 'the', 'second', 'sentence'], ['yet', 'another', 'sentence'], ['one', 'more', 'sentence'], ['and', 'the' 'final', 'sentence']] # 训练模型 model = Word2Vec(sentences, min_count=1) # 将二维 PCA 模型拟合到向量 X = model[model.wv.vocab] pca = PCA(n_components=2) result = pca.fit_transform(X) # 创建投影的散点图 pyplot.scatter(result[:, 0], result[:, 1]) words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) pyplot.show() |
运行示例会创建一个散点图,其中点用单词标注。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
鉴于用于拟合模型的语料库太小,很难从图中获取太多含义。
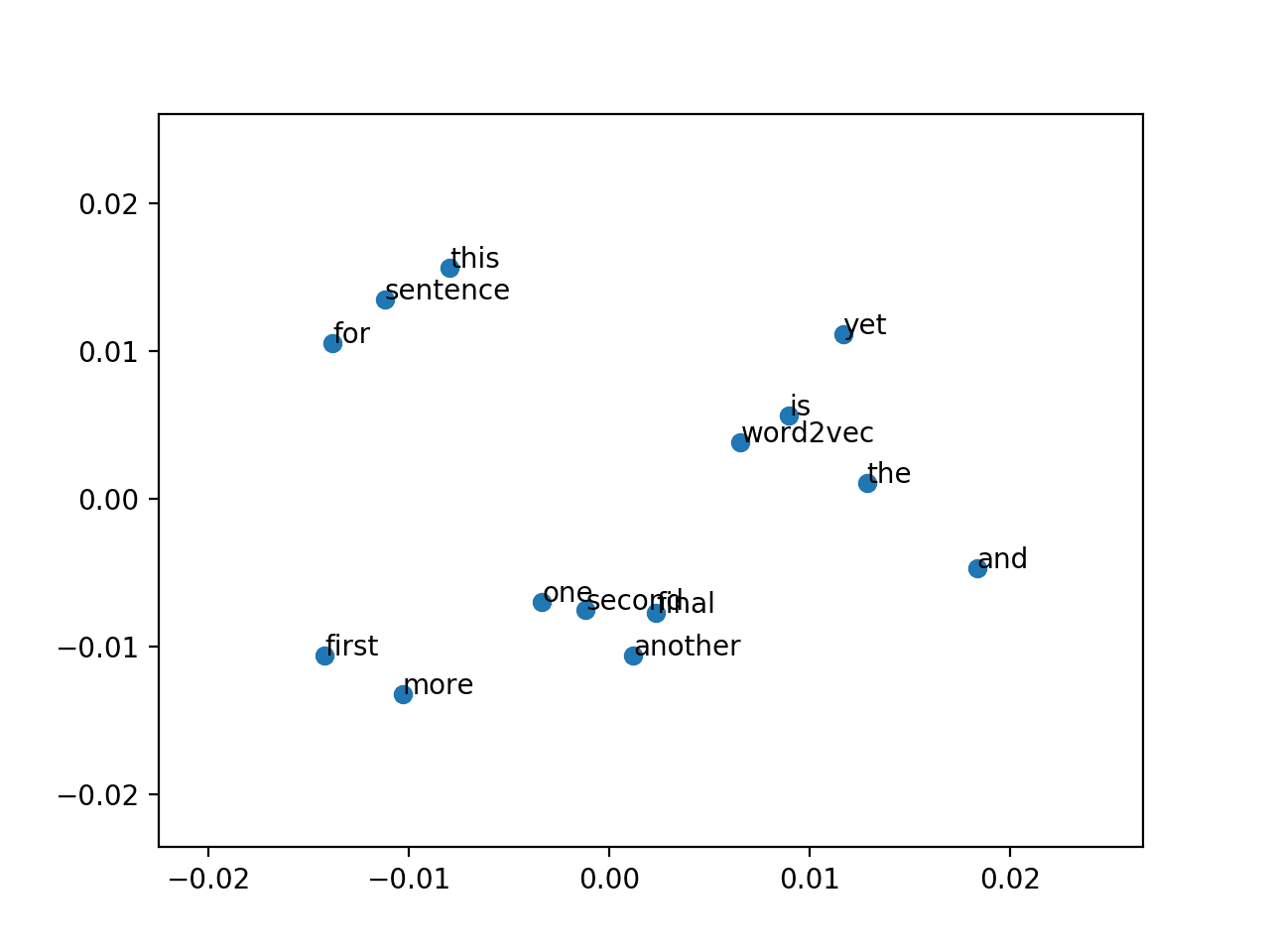
Word2Vec 模型的 PCA 投影散点图
加载 Google 的 Word2Vec 嵌入
训练您自己的词向量可能是解决给定 NLP 问题的最佳方法。
但这可能需要很长时间、一台具有大量内存和磁盘空间的快速计算机,以及可能一些微调输入数据和训练算法的专业知识。
另一种方法是直接使用现有的预训练词嵌入。
除了 word2vec 的论文和代码,Google 还在 Word2Vec Google Code Project 上发布了一个预训练的 word2vec 模型。
预训练模型不过是一个包含标记及其相关词向量的文件。预训练的 Google word2vec 模型是在 Google 新闻数据(约 1000 亿个词)上训练的;它包含 300 万个词和短语,并使用 300 维词向量进行拟合。
它是一个 1.53 GB 的文件。您可以从这里下载
解压后,二进制文件(GoogleNews-vectors-negative300.bin)大小为 3.4 GB。
Gensim 库提供了加载此文件的工具。具体来说,您可以调用 `KeyedVectors.load_word2vec_format()` 函数将此模型加载到内存中,例如
|
1 2 3 |
from gensim.models import KeyedVectors filename = 'GoogleNews-vectors-negative300.bin' model = KeyedVectors.load_word2vec_format(filename, binary=True) |
在我的现代工作站上,加载大约需要 43 秒。
另一件有趣的事情是你可以用单词做一些线性代数运算。
例如,在讲座和介绍性论文中描述的一个流行例子是
|
1 |
queen = (king - man) + woman |
也就是说,词语 queen 是给定从 king 中减去 man 的概念并加上 woman 这个词语后最接近的词语。king 中的“男性”被“女性”取代,从而得到 queen。一个非常酷的概念。
Gensim 在训练或加载的模型上的 `most_similar()` 函数中提供了一个执行这些类型操作的接口。
例如
|
1 2 |
result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
我们可以将所有这些放在一起,如下所示。
|
1 2 3 4 5 6 7 |
from gensim.models import KeyedVectors # 加载 google word2vec 模型 filename = 'GoogleNews-vectors-negative300.bin' model = KeyedVectors.load_word2vec_format(filename, binary=True) # 计算: (king - man) + woman = ? result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
运行该示例会加载 Google 预训练的 word2vec 模型,然后对这些单词的词向量执行 (king – man) + woman = ? 操作。
正如我们所预期的,答案是 queen。
|
1 |
[('queen', 0.7118192315101624)] |
有关您可以探索的更多有趣的算术示例,请参阅“进一步阅读”部分中的一些帖子。
加载 Stanford 的 GloVe 嵌入
斯坦福大学的研究人员也有自己的词嵌入算法,类似于 word2vec,称为全球词向量表示,简称 GloVe。
我不会在这里深入讨论 word2vec 和 GloVe 之间的区别,但一般来说,目前 NLP 从业者似乎更喜欢 GloVe,这基于其结果。
与 word2vec 类似,GloVe 研究人员也提供了预训练词向量,在这种情况下,有多种选择可供选择。
您可以下载 GloVe 预训练词向量,并使用 gensim 轻松加载。
第一步是将 GloVe 文件格式转换为 word2vec 文件格式。唯一的区别是添加了一个小的标题行。这可以通过调用 `glove2word2vec()` 函数来完成。例如
|
1 2 3 4 |
from gensim.scripts.glove2word2vec import glove2word2vec glove_input_file = 'glove.txt' word2vec_output_file = 'word2vec.txt' glove2word2vec(glove_input_file, word2vec_output_file) |
转换后,文件可以像上面一样加载,就像 word2vec 文件一样。
让我们用一个例子来具体说明。
您可以从 GloVe 网站下载最小的 GloVe 预训练模型。它是一个 822 兆字节的 zip 文件,包含 4 个不同的模型(50、100、200 和 300 维向量),这些模型在包含 60 亿个标记和 40 万个词汇的维基百科数据上进行训练。
直接下载链接在此
使用 100 维版本的模型,我们可以将文件转换为 word2vec 格式,如下所示
|
1 2 3 4 |
from gensim.scripts.glove2word2vec import glove2word2vec glove_input_file = 'glove.6B.100d.txt' word2vec_output_file = 'glove.6B.100d.txt.word2vec' glove2word2vec(glove_input_file, word2vec_output_file) |
您现在拥有一个 GloVe 模型的副本,采用 word2vec 格式,文件名为 `glove.6B.100d.txt.word2vec`。
现在我们可以加载它并执行与上一节相同的 (king – man) + woman = ? 测试。完整的代码列表如下。请注意,转换后的文件是 ASCII 格式,而不是二进制格式,因此加载时我们将 `binary=False` 设置为 `False`。
|
1 2 3 4 5 6 7 |
from gensim.models import KeyedVectors # 加载斯坦福 GloVe 模型 filename = 'glove.6B.100d.txt.word2vec' model = KeyedVectors.load_word2vec_format(filename, binary=False) # 计算: (king - man) + woman = ? result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
运行该示例会打印出相同的“queen”结果。
|
1 |
[('queen', 0.7698540687561035)] |
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
Gensim
- gensim Python 库
- models.word2vec gensim API
- models.keyedvectors gensim API
- scripts.glove2word2vec gensim API
文章
- 玩转 Word2vec, 2016
- 数字人文领域的向量空间模型, 2015
- Gensim Word2vec 教程, 2014
总结
在本教程中,您学习了如何使用 Gensim 在 Python 中开发和加载词嵌入层。
具体来说,你学到了:
- 如何根据文本数据训练您自己的 word2vec 词嵌入模型。
- 如何使用主成分分析 (PCA) 可视化训练好的词嵌入模型。
- 如何从 Google 和 Stanford 加载预训练的 word2vec 和 GloVe 词嵌入模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






感谢您精彩的教程,请问先生我可以下载这些教程的 pdf 吗
致敬
尝试一些 web2pdf 插件。
您有示例吗?
我很快就会发布一本关于这个主题的书。
嗨,Jason,
我开始阅读您的网站进行学习。它的写作水平使得像我这样的初学者也能轻松理解这些主题。感谢并赞赏您为此付出的真诚努力。
我想向您寻求帮助或建议,
我需要编写一个算法,将文本转换或提取为条件、参数和动作。
例如
算法输入:“如果 A 大于 100,则将 B 设置为 200”
算法输出
INPUT_VAR1 CONDITION INPUT1_VALUE1 ACTION OUTPUT_VAR1 OUTPUT1_VALUE1
—————————————————————————————————————–
A > 100 SET B 200
基本上,我正在寻找的是如何解释文本并从中提取文本中描述的动作、输入和输出。
听起来是一个有趣的项目。
也许编码器-解码器 LSTM 会很合适。
您可以从这里开始学习 LSTMs
https://machinelearning.org.cn/start-here/#lstm
您可以从这里开始学习 NLP 的深度学习
https://machinelearning.org.cn/start-here/#nlp
运行了示例,但不确定 25 x 4 向量代表什么或如何解读图表。
向量是单词的学习表示。
这个图可能提供对单词“自然”分组的洞察,也许在更大的数据集上会更清晰。
谢谢你,Jason。非常清晰、有趣且启发性强。
谢谢亚历山大。
感谢这篇很棒的教程
我有个问题。“GoogleNews-vectors-negative300.bin.gz”是用哪种算法实现的,是 skip-gram 还是 CBOW?
我不太确定,Rose,我相信细节都在 w2v 页面上。
https://code.google.com/archive/p/word2vec/
非常有条理,即使是初学者也能跟上。非常感谢。我非常欣赏你的工作!
谢谢。
嗨,Jason,
感谢你的详细解释!
对于“Word2Vec 模型 PCA 投影的散点图”这张图片,我的结果和你的不同。我不确定我的代码是否有任何问题。实际上,我是复制你的代码的。
这是我的
http://prntscr.com/gvg5jz
请您看一下并给出您的评论?
非常感谢!
该算法是随机的。
https://machinelearning.org.cn/randomness-in-machine-learning/
非常感谢,Jason!
很棒的教程,非常感谢!有一个问题,有没有类似于 GloVe 嵌入,但基于英语以外的其他语言的?
可能有,我不知道它们,抱歉。
你可以在几分钟内训练自己的向量——这是一个非常快速的算法。
感谢您的简单解释 🙂
很高兴它有帮助。
你好,
我正在尝试将我自己的语料库与上面提到的 GloVe 嵌入结合起来。我还没有真正找到一个解决方案/示例,可以利用 GloVe 6b 进行已知嵌入,然后“扩展”或训练我自己的词汇外(OOV)标记(这些通常是非语言词或机器生成的)。
任何帮助不胜感激。
谢谢
嗨,Rob,一种方法是将嵌入加载到 Embedding 层中,并在训练网络时用你的数据调整它们。
也许 Gensim 允许你更新现有向量,但我没有看到或尝试过这样做,抱歉。
@Rob Hamilton-Smith,我正在处理一个类似的问题,你如果找到了解决方案能帮我一下吗?
谢谢
感谢这篇精彩的教程(一如既往)。你打算写一篇关于使用 doc2vec 和/或 Fasttext 为完整文档进行词嵌入的帖子吗?
我特别感兴趣的是使用预训练词嵌入来表示文档(约500词)。这允许利用大型语料库。然而,众所周知,在分类任务中,简单平均法只与经典 BOW 一样好(甚至更糟)。显然,你可以通过首先对 word2vec 词典进行 PCA 变换来做得更好(论文“In Defense of Word Embedding for Generic Text Representation”),但到目前为止我还没有看到其他人使用这种技巧……
我希望将来能介绍 Fasttext。
当目标是模型技能时,我建议测试你能找到的每一个技巧!告诉我你进展如何。
这个教程对我帮助很大!!
非常感谢!
谢谢 Guy,我很高兴听到这个消息。
又一篇精彩的文章。我长期以来一直在努力掌握 word2vec 的窍门,这对我帮助很大。
很高兴听到这个消息!
尊敬的先生,
1) 我有一台 8GB 内存和 i5 处理器系统。使用该模型训练 Google News 语料库需要多长时间?
2) 在您描述的演示示例中,您使用的数据集是您自己输入的形式。如果我想使用任何语料库来训练模型,我该如何处理语料库?比如布朗语料库?
或者,如果我有任何任意语料库,我该如何处理它,以便以适合处理的形式将其输入到 word2vec 模型中?
我不知道训练 Google 语料库需要多长时间,抱歉,也许可以问问 Google 研究人员?
如果资源充足,您应该可以在一分钟内加载学习到的 Google 词向量。
要学习您自己的语料库,请根据您的应用程序需要对文本进行分词,并使用上面的 Gensim 代码。
向 Jason 致敬,他对一个非常复杂的话题进行了清晰而精确的解释。
谢谢!
嗨,Jason,
如何将 ngrams 纳入我的词汇表。gensim 是否提供了实现此功能的函数?
你可以用一两行 Python 代码从数据集中手动提取它们。
Gensim 中可能有这样的工具,但我不太了解。
非常感谢如此详细的解释
不客气。
嗨,Jason,您能就基于问答模型的语言建模提供一些想法吗?提前感谢。
感谢您的建议,我希望将来能涵盖它。
我有一个小问题,基于 glove 的词向量不提供 model.score 功能。
正确。
如何使用 word2vec(Google 预训练模型)将句子转换为向量。
每个单词都被转换成一个向量。
你好,我叫 Yazid,我只想知道如何用新词更新 GoogleNews 模型。
此致
你可以用你的新作品训练向量,并取你感兴趣的词的向量的并集。
谢谢,这么好的解释。
Jason,请问一个快速问题
假设我们正在自己预训练嵌入(不使用 glove/google)。
以下哪种会更好?
1) 使用 gensim 预训练,然后馈入 keras 嵌入层,trainable=False。
2) 作为神经网络嵌入层的一部分进行训练?
请指教。
这些将是预训练的词嵌入。
抱歉,我必须说,gensim 嵌入预训练实际上更糟。(在一个包含 1.5M 小文本的数据集的情况下。)
因此,作为神经网络的一部分的 Embedding 层中那些随机初始化的权重显示出更好的结果。
我的理由是
– 只有在使用 GloVe/Google 等模型时,使用预训练词嵌入才有意义。
– 只有在文本相对较大的数据集(即不是推文或小消息)上,使用预训练词嵌入才有意义。
请问您的意见是什么?
祝好!
不错。听起来合理。
非常棒的教程。请问,有没有办法获取用于训练模型的句子?我有一个 doc2vec 模型 M,我尝试用 M.documents 获取句子列表,就像使用 M.vector_size 获取向量大小一样。
另外,如果有一个 doc2vec 模型并想推断新向量,有没有办法使用带标签的句子?我在 gensim 页面上看到它写着
infer_vector(doc_words, alpha=0.1, min_alpha=0.0001, steps=5)¶
为给定批量训练后的文档推断向量。
文档应该是一个词(token)列表。
但我想使用带标签的句子。非常感谢!
我不确定我是否理解,抱歉。
您将拥有可以直接访问的模型训练数据吗?
我下载了一个在维基百科转储上训练的 doc2vec 模型。我想知道模型是否也存储了句子,如果是,我如何访问它们。非常感谢。
或许可以询问您下载模型的人?
如何为一个完整的评论句子生成词嵌入?我的意思是,在 word2vec 中,我们会为每个词获得 300 维的向量。
除了计算一个句子中所有词的向量平均值之外,还有没有什么好的技术可以实现句子向量的良好表示?
我相信有这样的方法。抱歉,目前我没有示例。
嗨,Jason,
过去几天我一直在处理使用 word2vec 和 glove 进行词嵌入的问题。
我阅读了许多帖子,但它们都很混乱。
昨天我偶然发现了这篇文章,哇!它对我帮助很大!
我还了解到你有一本书《深度学习与自然语言处理》。看起来很棒!
我很想购买它!
但我想直接联系你,了解这本书是否符合我的要求。
我从事的任务包括 Word2Vec、Doc2Vec、使用嵌入将一个文档映射到另一个文档进行推荐等。
我只需要基本理解,以便我能迈出下一步,并创建自己的想法/分析。
这本书涵盖了 word2vec 模型以及如何在深度学习中使用它们。它不包括 doc2vec。
每当我开始新话题时,我都会参考你的网站。
谢谢你
谢谢。
我可以用印尼语构建这个模型吗?
当然可以。
很棒的帖子。非常容易理解,信息量很大。
谢谢。
我有一个关于相似性的问题。如果我使用 w2vec 将单词转换为向量。我如何找到单词之间的相似性。
我知道我可以使用 most. Similar() 函数来查找特定单词的相似性,但是如何实现在文档中所有单词之间的相似性。
也许可以遍历所有单词,并手动计算与词汇表中所有其他单词的相似度(例如,编写两个 for 循环)。
你为什么会想要这个?
还有一个问题。
我可以使用 w2vec 将 unigrams 和 bigrams 转换为向量吗?
可能更容易分别学习一个二元模型和一个一元模型,如果仍然需要,则学习它们之间的映射(例如,一个模型)。
感谢 Jason 精彩的博客!
你知道关于二元嵌入的任何论文或实现吗?
手头没有,抱歉。
感谢您的回复!
不客气。
你好,Jason,我有一个关于词向量维度选择的问题。假设是 300 维,所有词的维度都一样吗?我们根据什么标准来选择这些维度?
是的,所有单词将具有相同的维度。
你好,
这可能是一个愚蠢的问题,但是您传递给 Word2Vec 进行训练的句子,它们是否包含所有句子(即训练、验证和测试)?
还有,当您为句子创建嵌入矩阵/字典时,它是否也应该包含测试句子的单词?
第三,在评估模型时,测试句子是否也会被转换为序列或整数?
谢谢
是的,句子被分割,然后编码以用于建模。
训练数据集应具有更广泛领域的代表性。这普遍适用,不限于自然语言处理。
感谢这篇精彩的教程。有没有办法撤销词嵌入转换?我正在将嵌入矩阵“X = model[model.wv.vocab]”馈送到一个自动编码器模型。我也会得到一个矩阵作为结果。我想通过应用逆向 word2vec 转换来解释该矩阵,以便我可以比较输入和输出结果。有什么想法吗?
当然,您可以针对给定的向量搜索最接近的一个或一组向量。
谢谢你的回复。但你能解释更多吗?
你的意思是这样的吗
for i in range(len(X))
inverted.append([argmax(decoded_tags[i, :])])
您可以使用欧几里得距离或点积等距离度量来找到最接近的向量。
你能提供一个例子吗?或者一个可以帮助我这样做的链接。
我很乐意帮忙,但我没有能力为您编写自定义代码,我在这里解释更多。
https://machinelearning.org.cn/faq/single-faq/can-you-change-the-code-in-the-tutorial-to-___
嗨,Jason,
这篇教程和其他的一样棒,但老实说,当我应用您的命令时
model = Word2Vec(sentences, min_count=1)
words = list(model.wv.vocab)
print(words)
当我使用您提供的数据集时,它运行良好,但是当我应用我自己的数据集时,其结构如下:一个名为 diseases 的文件夹,此文件夹中有 2 个子文件夹,分别是 blood cancer 和 breast cancer。在每个子文件夹中,例如 blood cancer,有许多 txt 文件,每个文件包含至少 20 个句子,不幸的是,当我应用您的命令 model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1) 和 words = list(model.wv.vocab)
print ('words' , words)
打印的单词如下:words [‘b’, ‘t’, ‘f’, ‘r’, ‘u’, ‘l’, ‘y’, ‘w’, ‘m’, ‘d’, ‘p’, ‘g’, ‘j’, ‘v’, ‘k’, ‘s’, ‘e’, ‘q’, ‘c’, ‘x’, ‘h’, ‘i’, ‘n’, ‘z’, ‘a’, ‘o’]
然而,我期望得到的是单词而不是字符。
我知道您没有能力为我编写自定义代码或检查每个人的命令,但请看一下我的几行命令,找出问题所在,因为我是一个初学者,我已经尝试查找但未能找到。
我在 Ubuntu 17.10 中使用 Keras 编写命令
breast= glob.glob(‘/home/mary/.config/spyder-py3/BinaryClassClassification/breastcancer/*.txt’)
blood=glob.glob(‘/home/mary/.config/spyder-py3/BinaryClassClassification/bloodcancer/*.txt’)
breast_samples_text = [load_file(file) for file in breast]
bloodـsamples_text= [load_file(file) for file in blood]
vocab_dic = breast_samples_text + blood_samples_text
model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1)
words = list(model.wv.vocab)
打印的单词是:words [‘b’, ‘t’, ‘f’, ‘r’, ‘u’, ‘l’, ‘y’, ‘w’, ‘m’, ‘d’, ‘p’, ‘g’, ‘j’, ‘v’, ‘k’, ‘s’, ‘e’, ‘q’, ‘c’, ‘x’, ‘h’, ‘i’, ‘n’, ‘z’, ‘a’, ‘o’]
急切等待您的答复,因为我非常需要它。
此致
Maryam
我相信你的数据格式不同。也许可以先关注数据加载,并确认内存中的数据与教程中的数据结构相同?
import re
from nltk.tokenize import TweetTokenizer, sent_tokenize
tokenizer_words = TweetTokenizer()
tokens_sentences = [tokenizer_words.tokenize(t) for t in
nltk.sent_tokenize(text)]
使用这段代码,你就能得到你想要的输出。我遇到了和你一样的问题
嗨,Jason,
我用这个命令修改了它,它给了我一个正确的输出::[
def load_file(file_name)
cleaned_txt = re.sub(“[^a-zA-Z]+”, ” “, open(file_name, ‘r’, encoding=”utf8”).read()).lower()
return cleaned_txt
def gen_vocab_dic(all_text)
voc = set()
for record in all_text
for word in record.split()
voc.add(word)
voc_dic = {}
index = 1 # 我们从1开始
for i in voc
voc_dic[i] = index
index = index + 1
return voc_dic,voc
breast= glob.glob('/home/mary/.config/spyder-py3/Dataset#2_BinaryClassClassification breasrcancer_disease/*.txt')
bloodcancer=glob.glob('/home/mary/.config/spyder-py3/Dataset#2_BinaryClassClassification/bloodcancer_disease/*.txt')
breast_samples_text = [load_file(file) for file in breast]
bloodـsamples_text= [load_file(file) for file in blood]
vocab_dic = gen_vocab_dic(breast_samples_text + blood_samples_text)
model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1)
words_list = list(model.wv.vocab)
print ('words_list' , words_list)== 'subcategory', 'disproportionally', 'alen' and etc.
但我不知道如何将每个类别的标签与每个单词关联起来?换句话说,如何标记属于每个类别的任何样本?
我已经提供了x_train或x_test,但我不知道如何提供y_dataset??
Jason,请帮我处理这种类型的数据集,因为我从未见过教word2vec处理这种数据集结构的教程。我的数据集结构如下:一个名为diseases的文件夹,该文件夹中有2个子文件夹,分别是血癌和乳腺癌。在每个子文件夹中,例如血癌,有许多txt文件,其中包含至少20个句子,正如我在上一篇文章中提到的。
等待回复,因为我需要它,很抱歉提出这个请求。
祝好
Maryam
抱歉,我不了解你的预测问题。或许你可以为我总结一下?
你如何决定使用多少个负面词?标准是什么?
你具体指的是什么?
嗨,Jason,
感谢您为我们提供了关于word2vec的最佳教程之一。但我认为您的教程存在以下局限性
当你通过word2vec创建模型时,如下所示
model = Word2Vec(sentences, size=100, window=5, workers=8, min_count=1)
您应该解释如何在通过word2vec模型嵌入单词后应用单词向量。例如,当我们使用Keras嵌入层时,
z = Embedding(vocab_dic_size, 100, input_length=seq_length, name="embedding")
我们可以这样应用。但我不知道如何使用您创建的word2vec模型来嵌入单词并给它们赋权重??
抱歉,我有点困惑,如果您能写一个使用 model = Word2Vec() 的实例,就像我上面用 keras embedding 层写的例子一样,那将是一个很好的指导,因为我已经搜索过它但没有理解。
很抱歉写了这么长的一段评论,但请考虑我是一个初学者,并且发现您的教程在清晰度方面是最好的。
我在此教程中展示了如何拟合模型并进行预测
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
你好。我是数据科学新手,通过您的帖子,我认为您是能指导我完成项目的最佳人选。我想创建一个包含所有与黄金市场相关的词汇的词典,为此我正在收集1000篇黄金新闻文章的文本。
在这种情况下,word2vec 可以使用吗,因为简单的单词分词无济于事。
或许你可以从所有文章中提取所有单词,然后看看所有文章中最常用的1000个单词是哪些?
嗨,Jason,
我喜欢你的文章。我为不同的文档表示构建了以下比较。您的反馈将不胜感激。
https://github.com/ahmed-mohamed-sn/DocumentRepresentations
抱歉,我没有能力审查和调试您的代码。
嗨,
这篇文章很有帮助。谢谢。
我需要训练一个RNN对身份证原始OCR输出中的姓名、地址、年龄、出生日期等进行分类。我希望这个分类器是通用的,并且适用于大多数类型的身份证。
由于姓名、地址等信息在预训练模型中不可用,我决定训练自己的词嵌入。我有大约50种身份证变体,并将通过修改其中的详细信息来生成训练数据。
我发现有人做了类似的事情——
“我们将单词文本哈希到一个大小为2^18的二进制向量中,该向量使用嵌入层嵌入到可训练的500维分布式表示中”
所以我理解了“词哈希”部分,但他们是如何将这些二进制特征向量嵌入到500维中的,我的意思是,你如何将那些2^18维的特征转换为500维。
您的帮助将不胜感激。如果您有其他替代方案,请建议。
或许这篇关于词嵌入的入门文章会有所帮助
https://machinelearning.org.cn/what-are-word-embeddings/
我被gensim Word2Vec的实际结果所困扰。我整理了问题并在此处提问:https://stackoverflow.com/questions/51233632/word2vec-gensim-multiple-languagess。是否有可能在多种语言上训练gensim并仍然获得正确的相似性结果?我的结果显示不能。
我还想问,当我们从gensim训练Word2Vec时,随机权重是保持不变还是每次训练模型时都会改变?
我不了解跨语言模型。听起来需要更深入的思考。
权重是通过在提供的数据集上进行训练学习的。
代码中的“alpha”是什么?
告诉我更多关于它的信息。
“alpha”被初始化为“0.025”。它的用途是什么?
我正在使用或多或少的相同步骤构建一个特定领域的word2vec模型。给定一个单词,我知道相似的单词应该是什么。我也没有数据集。我正在尝试基于非常小的变化来过拟合模型。当我绘制图表时,我看到我需要的单词被分组在一起。例如,单词a、b和c被分组在一个单独的簇中。所以我假设当我输入a时,我应该得到b和c作为相似的单词。然而,离问题中的簇更远的单词具有更好的分数并首先显示。我如何改变这种行为?任何帮助都将不胜感激。谢谢
模型有参数,尝试调整它们,看看它们是否能产生预期的效果?
也许你需要新的/不同的训练数据?
也许你的假设或评分有缺陷?
嗨,Jason,
感谢您精彩的教程。
我有一个关于向量维度的问题。我们可以可视化维度吗?请指导我。
你到底是什么意思?所有向量都具有相同的维度。
如果你是指可视化词向量,上面的教程展示了如何做。
你好,
word2vec 或 Glove 算法对非英语单词/语言(即俄语)有用吗?
是的,只要你有数据来训练它。
我正在尝试构建一个“文本分类器”,将其分为两个类别。我使用word2vec创建了模型,但如何使用该模型来预测其他数据。
其他模型如SVM、逻辑回归有“预测”功能,但word2vec没有。
有什么方法可以结合word2vec和SVM来使用吗?
word2vec 向量可以用作任何模型的输入,包括 SVM。抱歉,我没有一个可用的示例。
嗨,Jason,
如果将语料库之外的新词作为输入提供给使用一组语料库训练的模型,Word2Vec 会提供向量吗?
谢谢
不,新词无法映射。
我们可以将通过word2Vec算法创建的词向量作为输入提供给LDA模型训练吗?
请告诉我。
提前谢谢!!!
也许吧,抱歉我不知道。
如何为大型语料库准备输入?我有一个包含5万篇文章的csv文件(每行一篇文章)。正如https://rare-technologies.com/word2vec-tutorial/ 所述,将输入作为Python内置列表很方便,但当输入很大时会占用大量RAM。
也许可以逐步将文章加载到内存中以准备它们,而不是一次性加载所有文章。
是否可以定义自己的损失函数?
在Gensim中?或许可以。我建议查看API文档。
贾森先生,我正在做一个项目,该项目在社交媒体平台上进行情感分析并帮助检测网络欺凌,你能告诉我是否需要训练自己的词向量,或者在推特推文上预训练的GLoVe词向量就足够了?
我建议尝试两种方法,看看哪种方法最适合您的特定数据集。
非常感谢您的解释。
我有一个问题请教。一旦我们得到了模型,如何提取词列表的向量?
我上面的教程中展示了如何提取单词的向量。
嗨,
我想为一个标记语料库进行词嵌入,这个语料库不是英语,而是一种印度语言。如何使用 gensim 来做到这一点?
抱歉,我无法帮助你。
好帖子,伙计。我有一个问题,我们可以用训练过的word2vec模型检查整个新文档中的一个词,比如“java”吗?
抱歉,我不明白,你能详细说明一下吗?
你好 Jason 先生,我正在做一个情感分析项目(评论中方面及其极性的分类),我使用深度学习和 word embedding 的 skip-gram 模型,你能帮我一下吗,我需要一些关于这些方法的教程。
上面的教程有帮助吗?
你到底遇到了什么问题?
嗨,Jason,
我有这段代码
我得到了这种格式的数据
我只想对文件名中的数据应用 word2vec。
我该怎么做?
听起来像一个简单的编程问题,而不是一个机器学习问题?
也许将您的代码和错误发布到 stackoverflow?
嗨 Jason,感谢您的教程。
解释得很清楚。
我只想问您一件事,关于我的用例。
我有一个包含1.8k个句子的语料库,词汇量为2k个单词。
您认为这些足以用 Gensim 训练我自己的自定义嵌入吗,还是最好使用预训练模型?
因为我已经训练了它(使用 gensim Fast-text),然后将权重传递给 keras 嵌入层(trainable=True)和一个 Conv1D 层。
我得到了非常好的结果。
尽管我的语料库很小,这可能吗?因为通常这些嵌入都是在非常大的词汇量上训练的。
提前感谢您的回答
或许可以尝试一下,并将结果与使用 Keras 学习的嵌入进行比较?
Fast-text 预训练嵌入——> 89% 的准确率
Fast-text 使用我的语料库通过 gensim 训练学习嵌入——> 93% 的准确率
看来尽管我的语料库不够大,但从头开始学习嵌入会带来更好的结果。
所以谢谢,我发现 Fast-text 使用 n-gram 即使在词汇量较小的情况下也能给出更好的结果。
不错的发现,谢谢分享。
result = model.most_similar(positive=[‘man’,’woman’], negative=[‘beer’], topn=1)
print(result)
[(‘victim’, 0.7144894003868103)]
真的吗?? 🙂
这很令人惊讶(如果这是一个真实的结果)!
请记住,模型及其结果的好坏取决于用于训练它的数据。
你好,
这篇帖子提供了非常有用的信息,我用它在 Python 中使用 Keras 开发了一个模型。之后,我想在 Java 中使用这个模型。我知道如何在 Java 中加载模型,但加载 glove 预训练词向量时遇到了困难。Python 中使用的代码与上面提到的相同
from gensim.scripts.glove2word2vec import glove2word2vec
glove_input_file = ‘glove.840B.300d.txt’
word2vec_output_file = ‘glove.word2vec’
glove2word2vec(glove_input_file, word2vec_output_file)
from gensim.models import KeyedVectors
glove_w2vec = KeyedVectors.load_word2vec_format(‘glove.word2vec’, binary=False)
我也想在 Java 中重现同样的效果。我尝试使用 dl4j 入门页面。但我不断收到错误,例如 1. java.library.path 中没有 jnind4jcpu 2. java.library.path 中没有 jnind4jcpu。我无法在任何地方找到解决方案。如果您能帮助我解决这个问题,将非常有帮助。
或许可以在Python中加载它,然后以更方便Java读取的格式保存它?
如何使用已训练的Word2Vec模型计算句子中的“平均”单词
检索每个单词的向量并计算它们的平均值。
你好,
我看到这篇文章发布于2017年10月6日。
现在还最新吗?
也就是说,Gensim仍然是开发自己词嵌入的方法吗?
在博客的例子中,带分隔词的句子列表当然很小。您指出,当数据量很大时,可以使用迭代器。
这通常是常态,即大量数据。魔鬼藏在细节中,我在网上找不到将句子传递给word2vec模型构造函数作为迭代器构建的代码示例。
另一件可能有帮助的事情是,当嵌入计算需要数小时时,如何了解一些实际操作,因为每隔一段时间保存已经计算出的结果可能值得,以防“发生什么意外”,我说得对吗?
谢谢
是的。
还有 Keras 用于深度学习模型中的学习嵌入
https://machinelearning.org.cn/use-word-embedding-layers-deep-learning-keras/
很好的建议,谢谢。
嗨
我有一个关于基于W2V构建的图的问题。我不太清楚轴是什么?
它们是没有单位的,例如特征向量或数据的投影。
嗨,Jason,
首先,感谢您提供这个有用的教程。
我知道cbow和skip gram之间的区别。但是,我想问您在gensim中使用cbow和skip gram开发嵌入矩阵的区别。
您具体指什么?算法之间的区别?
我指的是使用cbow的word2vec和使用skip gram的word2vec之间的区别。
区别在于用于准备分布式表示的算法选择。
先生,如果预训练模型中不存在某个词,该怎么办?
它会抛出一个错误,说单词不在词汇表中。
您可以将未知词标记为“0”或未知。
嗨,Jason,是否有API可以将word2vec(使用gensim生成)与各种sklearn分类器(而不是带嵌入层的keras神经网络)如MultinomialNB、MLPClassifier等一起使用?
据我所知,没有。
嗨,Jason,感谢您提供如此精彩的教程。是否可以更新您的教程,添加一个可以在不将GloVe嵌入转换为Word2Vec的情况下将其可视化为2D的代码片段?
您可以直接提取向量并创建PCA投影。
顺便问一下,您有带负采样的skipgram教程吗?我读到它比GloVe好得多。
我想没有,抱歉。
首先,非常感谢您提供如此精彩的文章,然后我想根据相似性从上到下对词汇进行聚类,任何想法都将不胜感激。
抱歉,我没有关于聚类的教程。也许将来会有。
感谢您提供这篇精彩的文章。我的代码中收到了一些警告。而且在绘图时,我的语料库单词不可见。
在此行收到警告:
X = model[model.wv.vocab]
DeprecationWarning: 对已弃用的 `__getitem__` 的调用(此方法将在4.0.0中删除,请改用 self.wv.__getitem__())。
在绘图时:
RuntimeWarning: 当前字体中缺少字形 2414。
我需要怎么做才能解决它?
暂时可以忽略它们。
亲爱的杰森,非常感谢你精彩的解释。
我有一个疑问:如果我们用代码 model = Word2Vec(sentences, min_count=4) 和 model = Word2Vec(sentences, min_count=3) 运行,对于您所举的例子,它们会给出相同的向量表示结果吗?
不会,这是一种随机方法,每次运行时都会给出不同的向量。
我如何将我的数据集转换为相同的句子格式,我的意思是句子用列分隔,每个句子在[]中,并且句子单词被分词?
本教程将帮助您准备数据。
https://machinelearning.org.cn/clean-text-machine-learning-python/
我在您的一篇文章中读到如何打印预测标签和实际标签,但我忘了在哪一篇,您能给我看看那部分代码或那篇文章吗……拜托?
谢谢你
你是我的榜样
当然,您所说的标签具体指什么?
嵌入?类别标签?
我想看看分类错误发生在哪里……
您可以使用 `model.predict_classes()` 预测类别,然后打印其值。
也许这会有帮助。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
我在自己的数据集上训练了我自己的word2vec模型,我两次运行相同的代码,每次同一个词的向量都有不同的值,这是可以接受的还是不可以接受的?
例如,单词“country”第一次运行时值为
[-0.019637132 0.041940697 -0.06441503 0.0151868425 0.011437362 0.05516808 0.030604098 …]
第二次运行值为
[-0.026120335 0.032587618 0.12853415 0.026889715 -0.02893926 0.013117478 0.06197646 …]
是的,这是预料之中的。
为什么会这样呢?我正在寻找创建自己的word2vec模型,就像Glove和Google word2vec一样。但是,如果每次我在相同的数据集上运行代码而没有任何更改时,都会得到不同的单词向量,为什么他们会使其通用或普适呢?
我的意思是,如果谷歌和Glove多次运行他们的代码,并且他们得到了同一个词的不同向量,为什么他们还要让他们的模型通用呢?
看起来他们每次得到的词向量都相同,但我为我的词提取了错误的向量……有什么地方不对劲,
我严格遵循了你的方法(4. 训练word2vec嵌入),最后,我添加了这段代码来保存单词及其对应的向量
model.wv.save_word2vec_format(’embedding_word2vec_Mydata.txt’, binary=False)
每次我运行它,我都会得到同一个词的不同向量,我觉得我误解了一些东西……
抱歉问了这么长的问题,
谢谢,Jason教授
它们是随机算法,每次运行时都会给出不同的结果,但平均而言,其总体模式是相同的。
这些方法每次运行代码时,都会以略微不同的方式学习这些通用模式。
嗨,Jason,
你能帮我理解一下,什么时候使用Word2Vec,以及用于什么目的(我是说对于情感分析、文本分类等情况)。
我还想知道如何以最简单的方式将word2vec转换为doc2vec。
这对我将有很大的帮助。
谢谢。
Word2Vec 是一种词的分布式表示,当您的模型输入是词时,它非常有用。
我无法帮助您处理 doc2vec,抱歉,我还没有相关示例。
嗨,Jason,
您有关于如何在Glove模型上训练自己的词嵌入的示例吗?
谢谢
目前还没有。
我在一个包含200000个句子的语料库上训练了自己的word2vec模型,然后在一个包含100万个句子的语料库上训练它。我正在使用您的教程解决一个分类问题,令人惊讶的是,即使语料库大小变得非常大,我的深度模型的f1分数仍然保持不变。问题可能出在哪里?
干得好!
也许你训练的word2vec对模型没有增值作用?
你好,
如何使用创建的word2vec模型?我创建了一个word2vec模型,但我找不到使用该模型查找其他单词得分的语法。您能给我解释一下吗?
你说的“分数”是什么意思?word2vec会为每个词返回一个向量,而不是一个分数。
你有没有关于将 word2vec 与 SVM、LR 等机器学习模型结合使用的教程?
我想没有,恕我直言。
我需要源代码。我怎么下载代码?
看这里
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
你好,如果我只想绘制那些在所有句子中至少出现n次的单词,该怎么办?另外,如何使图表更大以便实际看到发生了什么?
您可以使用if语句来处理单词的频率计数。
您可以为matplotlib指定大小,或许可以查看API文档。
如果我把glove文件存到s3上,我该怎么做同样的操作呢?
或许可以试试看?
当你尝试使用传统方式读取对象时会遇到内存问题
file.get()[‘Body’].read()
将尝试某种方式进行流式读取,如果可能的话。
祝你好运!
你好杰森,如果您能提供一些用Python寻找医学术语之间语义相似性的例子,那对我将非常有帮助。我正在用NLP构建疾病预测器。例如,我想知道“fever”和“high temperature”或者“fever”和“raise in temperature”是否相同。这用普通的相似性度量是不可能的。请帮助我。热切期待您的回复。提前感谢。
为什么不从词向量之间的欧几里得距离开始呢?
或者如果你指的是因为你有一个词到多个词的情况,也许可以查阅关于词向量的文献,看看这种情况是如何处理的?抱歉,我不记得了。
像“of”这样的词在谷歌的模型中不存在,这正常吗?
超常见的连接词通常会被移除。它们作用不大。
好的,谢谢
亲爱的Jason
感谢这篇有趣的文章。你提到“我们不是从文件中加载大型文本文档或语料库,而是使用一个小的、内存中的预分词句子列表”。我通过加载文本文件(每行一个句子)的内容来运行你的代码,但在这种情况下,print(words) 的输出结果打印的是字母而不是单词。你有什么想法吗?
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
谢谢。我知道让你调试我们的代码不合理。因此,我会尽力找到错误,我相信我会的。
祝你好运!
感谢您的积极能量。在Stack Overflow的帮助下,我解决了这个错误!我的错误是在将文本文件内容加载到sentences变量之前使用了sentences = "" 而不是 sentences = []。
干得好!
嗨,Jason,
感谢您提供这个精彩的教程!
我如何使用您上面使用的以下数组来训练神经网络?
[ -4.61881841e-03 -4.88735968e-03 -3.19508743e-03 4.08568839e-03
-3.38211656e-03 1.93076557e-03 3.90265253e-03 -1.04349572e-03
4.14286414e-03 1.55219622e-03 3.85653134e-03 2.22428422e-03
-3.52565176e-03 2.82056746e-03 -2.11121864e-03 -1.38054823e-03
-1.12888147e-03 -2.87318649e-03 -7.99703528e-04 3.67874932e-03
2.68940022e-03 6.31021452e-04 -4.36326629e-03 2.38655557e-04
-1.94210222e-03 4.87691024e-03 -4.04118607e-03 -3.17813386e-03
4.94802603e-03 3.43150692e-03 -1.44031656e-03 4.25637932e-03
-1.15106850e-04 -3.73274647e-03 2.50349124e-03 4.28692997e-03
-3.57313151e-03 -7.24728088e-05 -3.46099050e-03 -3.39612062e-03
3.54845310e-03 1.56780297e-03 4.58260969e-04 2.52689526e-04
3.06256465e-03 2.37558200e-03 4.06933809e-03 2.94650183e-03
-2.96231941e-03 -4.47433954e-03 2.89590308e-03 -2.16034567e-03
-2.58548348e-03 -2.06163677e-04 1.72605237e-03 -2.27384618e-04
-3.70194600e-03 2.11557443e-03 2.03793868e-03 3.09839356e-03
-4.71800892e-03 2.32995977e-03 -6.70911541e-05 1.39375112e-03
-3.84263694e-03 -1.03898917e-03 4.13251948e-03 1.06330717e-03
1.38514000e-03 -1.18144893e-03 -2.60811858e-03 1.54952740e-03
2.49916781e-03 -1.95435272e-03 8.86975031e-05 1.89820060e-03
-3.41996481e-03 -4.08187555e-03 5.88635216e-04 4.13103355e-03
-3.25899688e-03 1.02130906e-03 -3.61028523e-03 4.17646067e-03
4.65870230e-03 3.64110398e-04 4.95479070e-03 -1.29743712e-03
-5.03367570e-04 -2.52546836e-03 3.31060472e-03 -3.12870182e-03
-1.14580349e-03 -4.34387522e-03 -4.62882593e-03 3.19007039e-03
2.88707414e-03 1.62976081e-04 -6.05802808e-04 -1.06368808e-03]
你什么意思?
你好
关于Gensim训练词的小疑问,有时如何处理这些机器学习词
,人工智能词如何处理空格?
请大家帮帮我
model.wv.most_similar(“Artificial intelligence”)
KeyError: “词语‘Artificial intelligence’不在词汇表中”
如何处理两个词,请帮助我
我们通常会移除空格,只对单词进行建模。
嗨,Jason,
我用你的代码尝试了gensim库、PCA降维和可视化。我稍微修改了一下,用歌德的德语剧本《浮士德I》喂给它,并可视化了一些有趣的词,比如Himmel(天堂)、Hölle(地狱)、Gott(上帝)、Teufel(魔鬼)等等,我很想知道我会看到什么样的邻居关系。首先,我惊讶地发现2D映射在每次运行时都会改变,甚至邻近的词也会改变。于是,我通过定义解算器来改变PCA命令:pca = PCA(n_components=2, svd_solver=’full’)。这使得邻居关系更加稳定,但并没有给出唯一的结果。实际上,我不太明白为什么会这样。
总的来说,我有点失望,因为我的期望,比如找到靠近地狱的魔鬼,并没有实现。显然,向量化背后的数学没有我希望的那么哲学。
无论如何,很棒的教程!谢谢!
不错的调查!
或许数据集太小,或者模型配置的选择需要调整,以在多次运行中提供更稳定的模型。
最好的东西总是免费的……
谢谢你,杰森博士。你解释事情的方式非常简单有效。
谢谢!
你能把这个教程转换成GenSim 4版本吗?
这里有一些需要更新的地方
#GenSim 3
#words = list(model.wv.vocab)
#GenSim 4
words = model.wv.index_to_key
#GenSim 3
#print(model[‘sentence’])
#GenSim 4
normed_vector = model.wv.get_vector(“sentence”, norm=True)
# GenSim 3
#X = model[model.wv.vocab]
# GenSim 4
X = model.wv.get_normed_vectors()
这里有一个例子
https://machinelearning.org.cn/develop-word-embeddings-python-gensim/
制作一个关于fasttext多语言情感分析的教程
感谢您的建议。
亲爱的 Jason,
我想知道是否可以从预训练模型Glove和Google中选择特定输入年份的结果?如果不能,我可以在我的数据(针对特定年份)上训练Glove吗?
可能不行。要训练您自己的嵌入,请看这个是否有帮助:https://machinelearning.org.cn/develop-word-embeddings-python-gensim/
但你需要一台非常强大的电脑才能做出与Glove媲美的模型
这篇文章是2017年的,但我希望还不算太晚,
非常感谢这篇精彩有用的文章 @Jason Brownlee!!!
嗨 Fede……内容仍然非常相关!