确定您的长短期记忆(LSTM)模型在序列预测问题上的表现是否良好可能很困难。
您可能会获得良好的模型技能得分,但了解您的模型是否适合您的数据,或者它是否欠拟合或过拟合并且可以通过不同的配置做得更好,这一点很重要。
在本教程中,您将了解如何在序列预测问题上诊断 LSTM 模型的拟合情况。
完成本教程后,您将了解:
- 如何收集和绘制 LSTM 模型的训练历史。
- 如何诊断欠拟合、拟合良好和过拟合模型。
- 如何通过平均多次模型运行来开发更鲁棒的诊断。
通过我的新书 《Python 长短期记忆网络》 开启您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2020年1月更新:更新了Keras 2.3和TensorFlow 2.0的API。
教程概述
本教程分为6个部分;它们是
- Keras 中的训练历史
- 诊断图
- 欠拟合示例
- 拟合良好的示例
- 过拟合示例
- 多次运行示例
1. Keras 中的训练历史
通过查看模型随时间推移的表现,您可以深入了解模型的行为。
LSTM 模型通过调用 `fit()` 函数进行训练。此函数返回一个名为 `history` 的变量,其中包含在模型编译期间指定的损失和任何其他指标的跟踪。这些分数在每个 epoch 结束时记录。
|
1 2 |
... history = model.fit(...) |
例如,如果您的模型已编译为优化对数损失(`binary_crossentropy`)并在每个 epoch 衡量准确性,那么对数损失和准确性将在每个训练 epoch 的历史跟踪中计算和记录。
每个分数都可以通过调用 `fit()` 返回的历史对象中的键来访问。默认情况下,在拟合模型时优化的损失称为“loss”,准确性称为“acc”。
|
1 2 3 4 5 |
... model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(X, Y, epochs=100) print(history.history['loss']) print(history.history['accuracy']) |
Keras 还允许您在拟合模型时指定单独的验证数据集,该数据集也可以使用相同的损失和指标进行评估。
这可以通过在 `fit()` 上设置 `validation_split` 参数来完成,以使用一部分训练数据作为验证数据集。
|
1 2 |
... history = model.fit(X, Y, epochs=100, validation_split=0.33) |
这也可以通过设置 `validation_data` 参数并传入 X 和 y 数据集的元组来完成。
|
1 2 |
... history = model.fit(X, Y, epochs=100, validation_data=(valX, valY)) |
在验证数据集上评估的指标使用相同的名称进行键控,并带有“val_”前缀。
|
1 2 3 4 5 6 7 |
... model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(X, Y, epochs=100, validation_split=0.33) print(history.history['loss']) print(history.history['accuracy']) print(history.history['val_loss']) print(history.history['val_accuracy']) |
2. 诊断图
LSTM 模型的训练历史可用于诊断模型的行为。
您可以使用 Matplotlib 库绘制模型的性能。例如,您可以按如下方式绘制训练损失与测试损失的比较:
|
1 2 3 4 5 6 7 8 9 10 |
from matplotlib import pyplot ... history = model.fit(X, Y, epochs=100, validation_data=(valX, valY)) pyplot.plot(history.history['loss']) pyplot.plot(history.history['val_loss']) pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.legend(['train', 'validation'], loc='upper right') pyplot.show() |
创建和查看这些图有助于了解可能需要尝试的新配置,以获得更好的模型性能。
接下来,我们将看一些示例。我们将考虑在训练集和验证集上的模型技能(以最小化的损失衡量)。您可以使用对您的问题有意义的任何指标。
3. 欠拟合示例
欠拟合模型是指在训练数据集上表现良好,但在测试数据集上表现差的模型。
这可以从图中诊断出来:训练损失低于验证损失,并且验证损失的趋势表明可能进一步改进。
下面提供了一个小的、人为设计的欠拟合 LSTM 模型示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from matplotlib import pyplot from numpy import array # 返回训练数据 def get_train(): seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 返回验证数据 def get_val(): seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 定义模型 model = Sequential() model.add(LSTM(10, input_shape=(1,1))) model.add(Dense(1, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer='adam') # 拟合模型 X,y = get_train() valX, valY = get_val() history = model.fit(X, y, epochs=100, validation_data=(valX, valY), shuffle=False) # 绘制训练和验证损失 pyplot.plot(history.history['loss']) pyplot.plot(history.history['val_loss']) pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.legend(['train', 'validation'], loc='upper right') pyplot.show() |
运行此示例将生成训练和验证损失的图,显示了欠拟合模型的特征。在这种情况下,可以通过增加训练 epoch 的数量来提高性能。
在这种情况下,可以通过增加训练 epoch 的数量来提高性能。
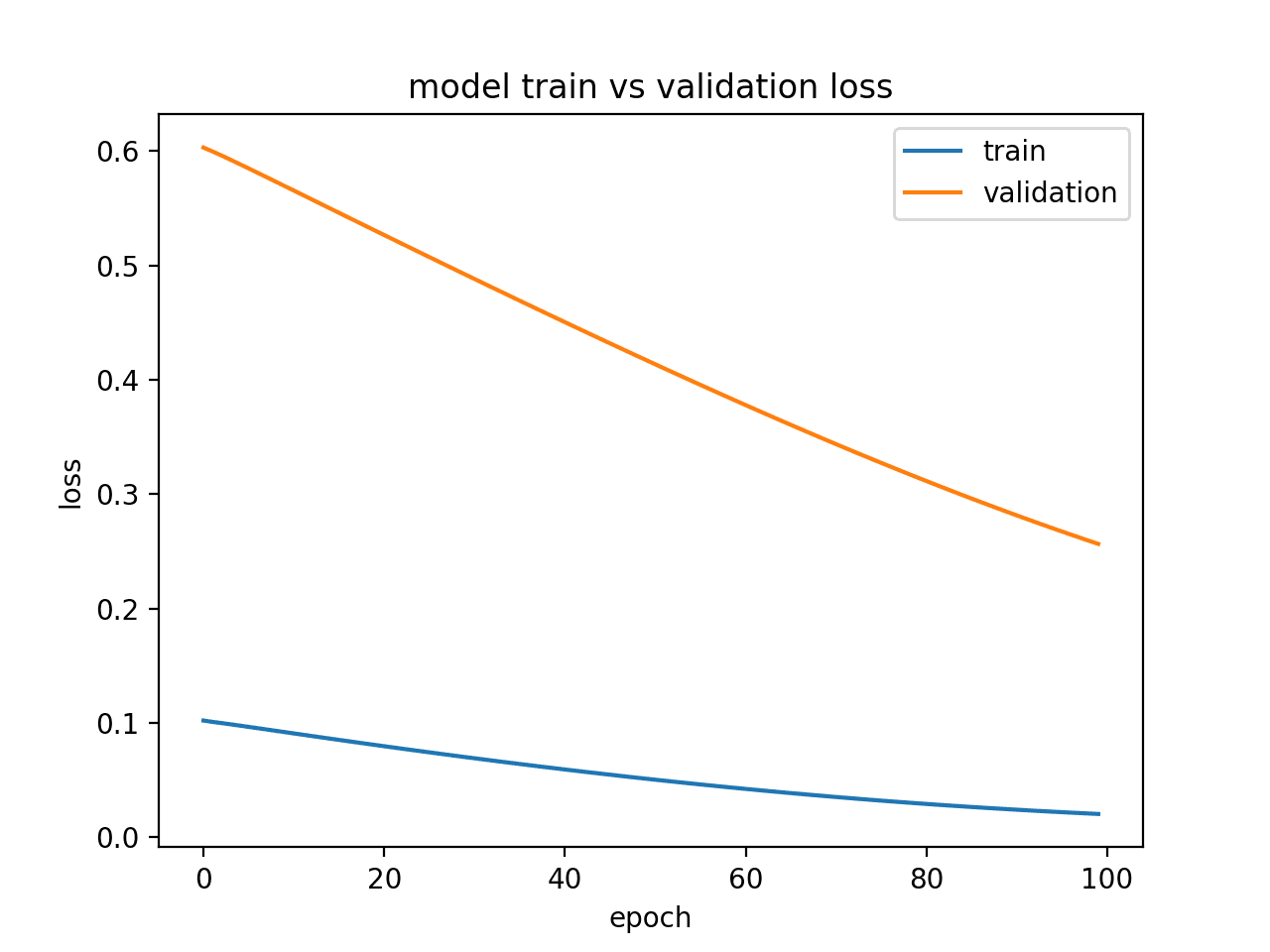
显示欠拟合模型的诊断折线图
或者,如果训练集的模型性能优于验证集,并且性能已趋于平稳,则模型可能欠拟合。下面是一个欠拟合模型的示例。
下面是一个具有不足的内存单元的欠拟合模型的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from matplotlib import pyplot from numpy import array # 返回训练数据 def get_train(): seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((5, 1, 1)) 返回 X, y # 返回验证数据 def get_val(): seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 定义模型 model = Sequential() model.add(LSTM(1, input_shape=(1,1))) model.add(Dense(1, activation='linear')) # 编译模型 model.compile(loss='mae', optimizer='sgd') # 拟合模型 X,y = get_train() valX, valY = get_val() history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False) # 绘制训练和验证损失 pyplot.plot(history.history['loss']) pyplot.plot(history.history['val_loss']) pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.legend(['train', 'validation'], loc='upper right') pyplot.show() |
运行此示例显示了欠拟合模型的特征,该模型似乎资源不足。
在这种情况下,可以通过增加模型的容量来提高性能,例如隐藏层中的内存单元数量或隐藏层数量。
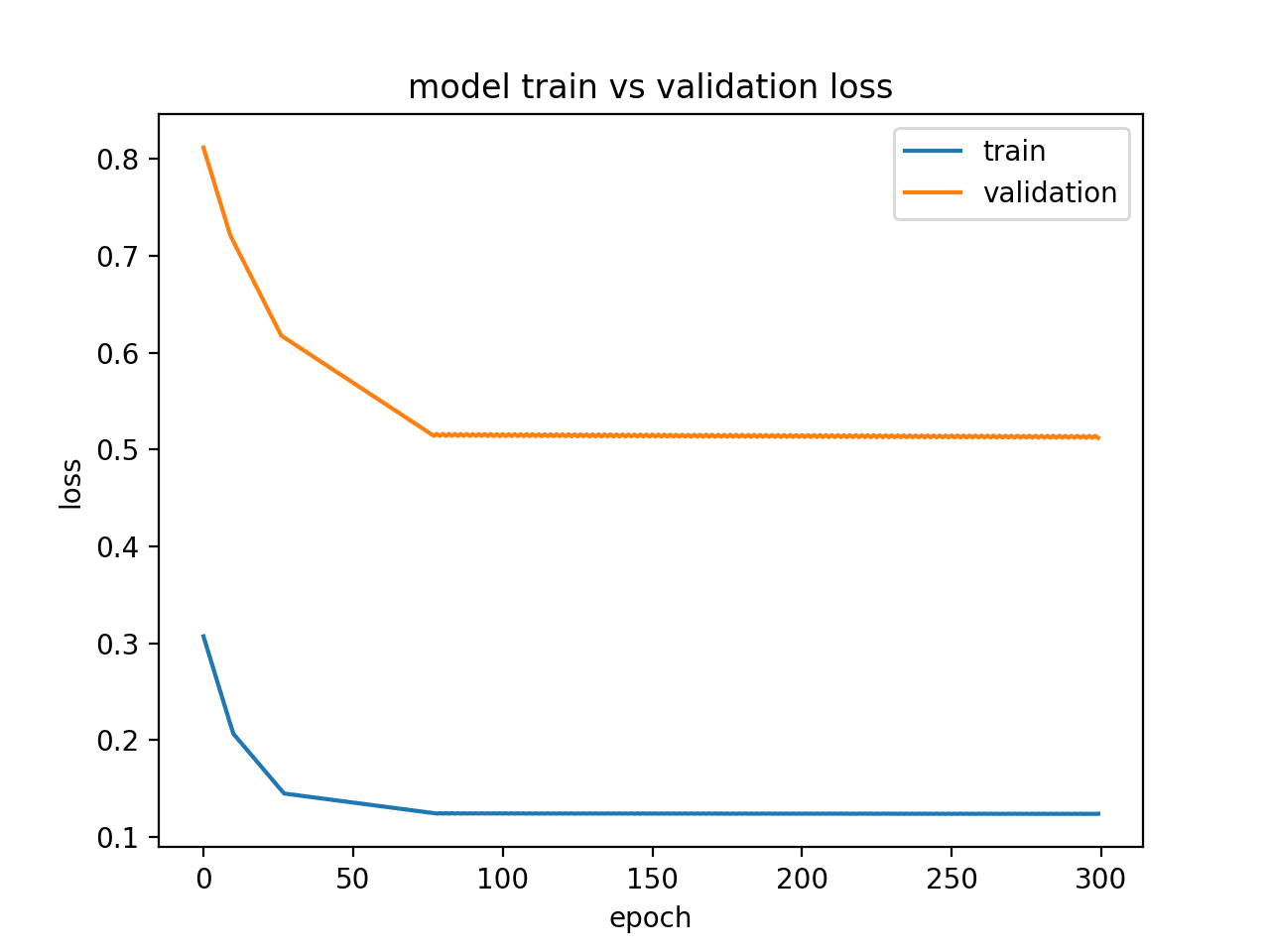
通过状态显示欠拟合模型的诊断折线图
4. 拟合良好的示例
拟合良好是指模型在训练集和验证集上表现都很好的情况。
这可以从图中诊断出来:训练损失和验证损失都下降并稳定在相似的点。
下面的小示例演示了一个拟合良好的 LSTM 模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from matplotlib import pyplot from numpy import array # 返回训练数据 def get_train(): seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((5, 1, 1)) 返回 X, y # 返回验证数据 def get_val(): seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 定义模型 model = Sequential() model.add(LSTM(10, input_shape=(1,1))) model.add(Dense(1, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer='adam') # 拟合模型 X,y = get_train() valX, valY = get_val() history = model.fit(X, y, epochs=800, validation_data=(valX, valY), shuffle=False) # 绘制训练和验证损失 pyplot.plot(history.history['loss']) pyplot.plot(history.history['val_loss']) pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.legend(['train', 'validation'], loc='upper right') pyplot.show() |
运行该示例会创建一个折线图,显示训练和验证损失的收敛。
理想情况下,我们希望看到类似这样的模型性能,尽管对于具有大量数据的挑战性问题,这可能无法实现。
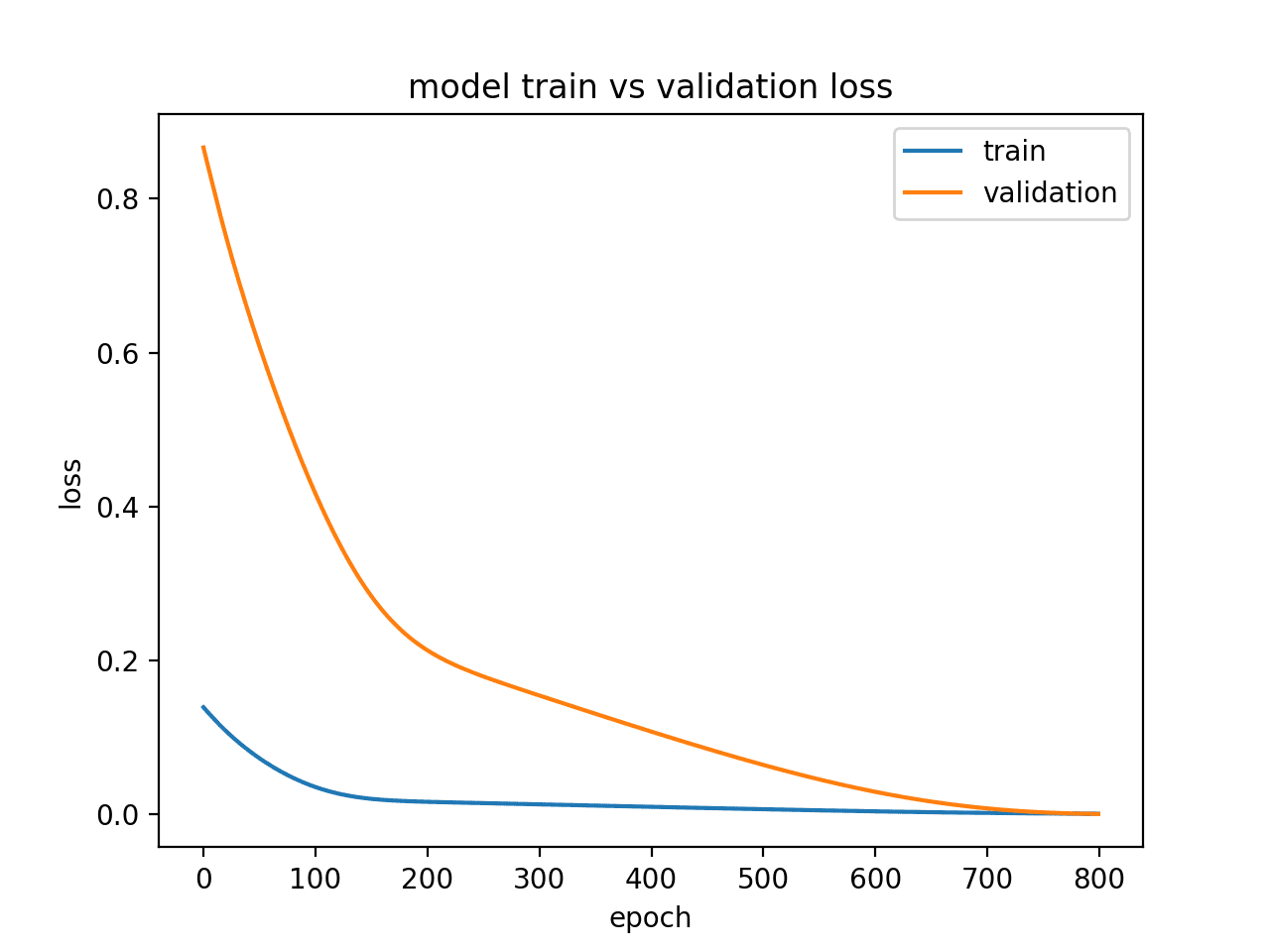
显示模型拟合良好的诊断折线图
5. 过拟合示例
过拟合模型是指训练集的性能良好并持续改进,而验证集的性能则先提高到某个点然后开始下降。
这可以从图中诊断出来:训练损失向下倾斜,验证损失向下倾斜,达到一个拐点,然后再次向上倾斜。
下面的示例演示了一个过拟合的 LSTM 模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from matplotlib import pyplot from numpy import array # 返回训练数据 def get_train(): seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((5, 1, 1)) 返回 X, y # 返回验证数据 def get_val(): seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 定义模型 model = Sequential() model.add(LSTM(10, input_shape=(1,1))) model.add(Dense(1, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer='adam') # 拟合模型 X,y = get_train() valX, valY = get_val() history = model.fit(X, y, epochs=1200, validation_data=(valX, valY), shuffle=False) # 绘制训练和验证损失 pyplot.plot(history.history['loss'][500:]) pyplot.plot(history.history['val_loss'][500:]) pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.legend(['train', 'validation'], loc='upper right') pyplot.show() |
运行此示例会创建一个图,显示过拟合模型的验证损失的特征性拐点。
这可能表明训练 epoch 过多。
在这种情况下,可以在拐点处停止模型训练。或者,可以增加训练样本的数量。
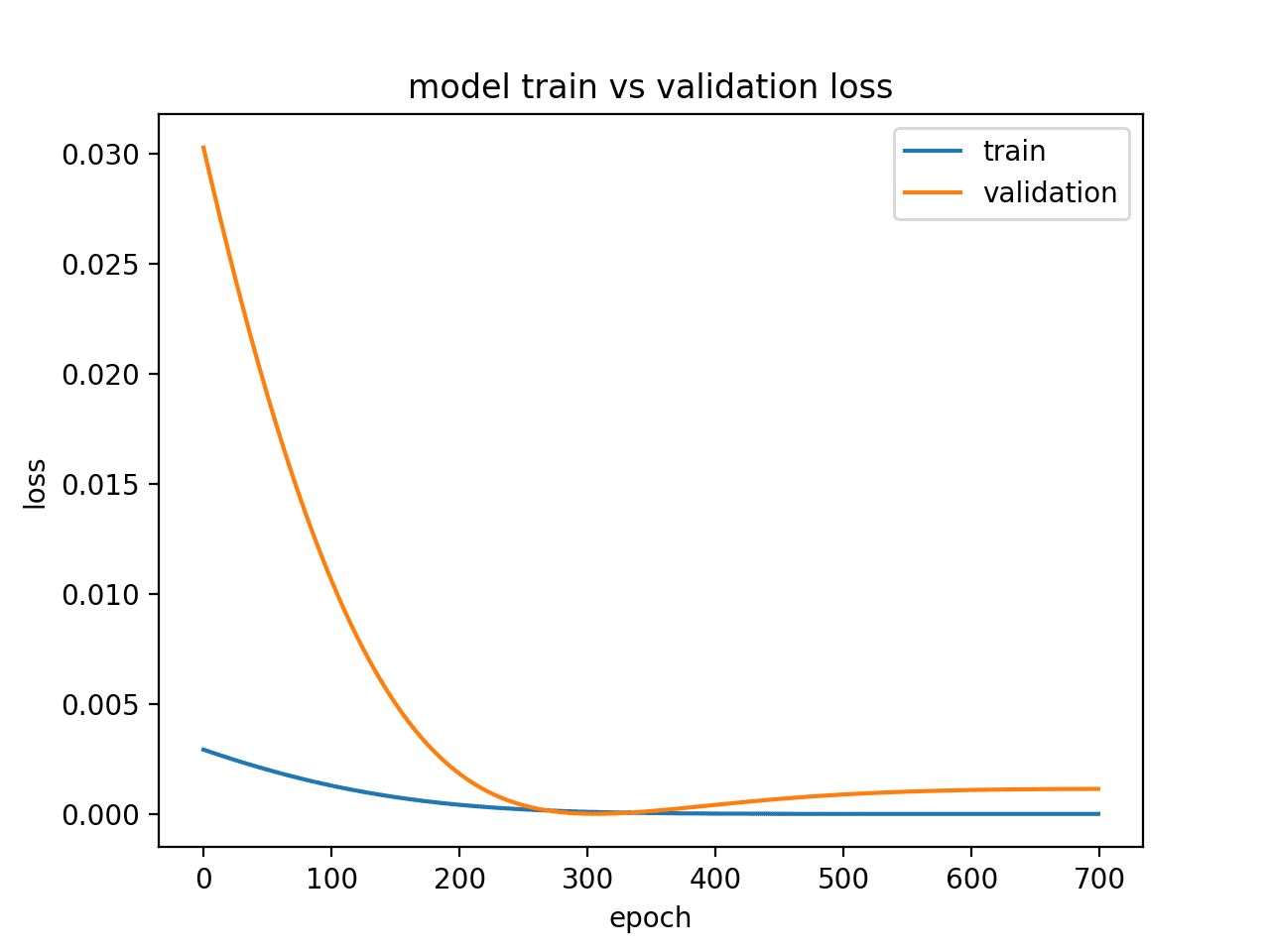
显示过拟合模型的诊断折线图
6. 多次运行示例
LSTM 是随机的,这意味着每次运行都会得到不同的诊断图。
重复进行诊断运行多次(例如 5、10 或 30 次)会很有用。然后可以绘制每次运行的训练和验证跟踪,以更稳健地了解模型随时间推移的行为。
下面的示例运行相同的实验多次,然后绘制每次运行的训练和验证损失的跟踪。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from matplotlib import pyplot from numpy import array from pandas import DataFrame # 返回训练数据 def get_train(): seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((5, 1, 1)) 返回 X, y # 返回验证数据 def get_val(): seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]] seq = array(seq) X, y = seq[:, 0], seq[:, 1] X = X.reshape((len(X), 1, 1)) 返回 X, y # 收集跨多次重复的数据 train = DataFrame() val = DataFrame() for i in range(5): # 定义模型 model = Sequential() model.add(LSTM(10, input_shape=(1,1))) model.add(Dense(1, activation='linear')) # 编译模型 model.compile(loss='mse', optimizer='adam') X,y = get_train() valX, valY = get_val() # 拟合模型 history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False) # 存储历史记录 train[str(i)] = history.history['loss'] val[str(i)] = history.history['val_loss'] # 绘制多次运行的训练和验证损失 pyplot.plot(train, color='blue', label='train') pyplot.plot(val, color='orange', label='validation') pyplot.title('model train vs validation loss') pyplot.ylabel('loss') pyplot.xlabel('epoch') pyplot.show() |
在生成的图中,我们可以看到欠拟合的总体趋势在 5 次运行中都保持着,并且更强烈地表明可能需要增加训练 epoch 的数量。
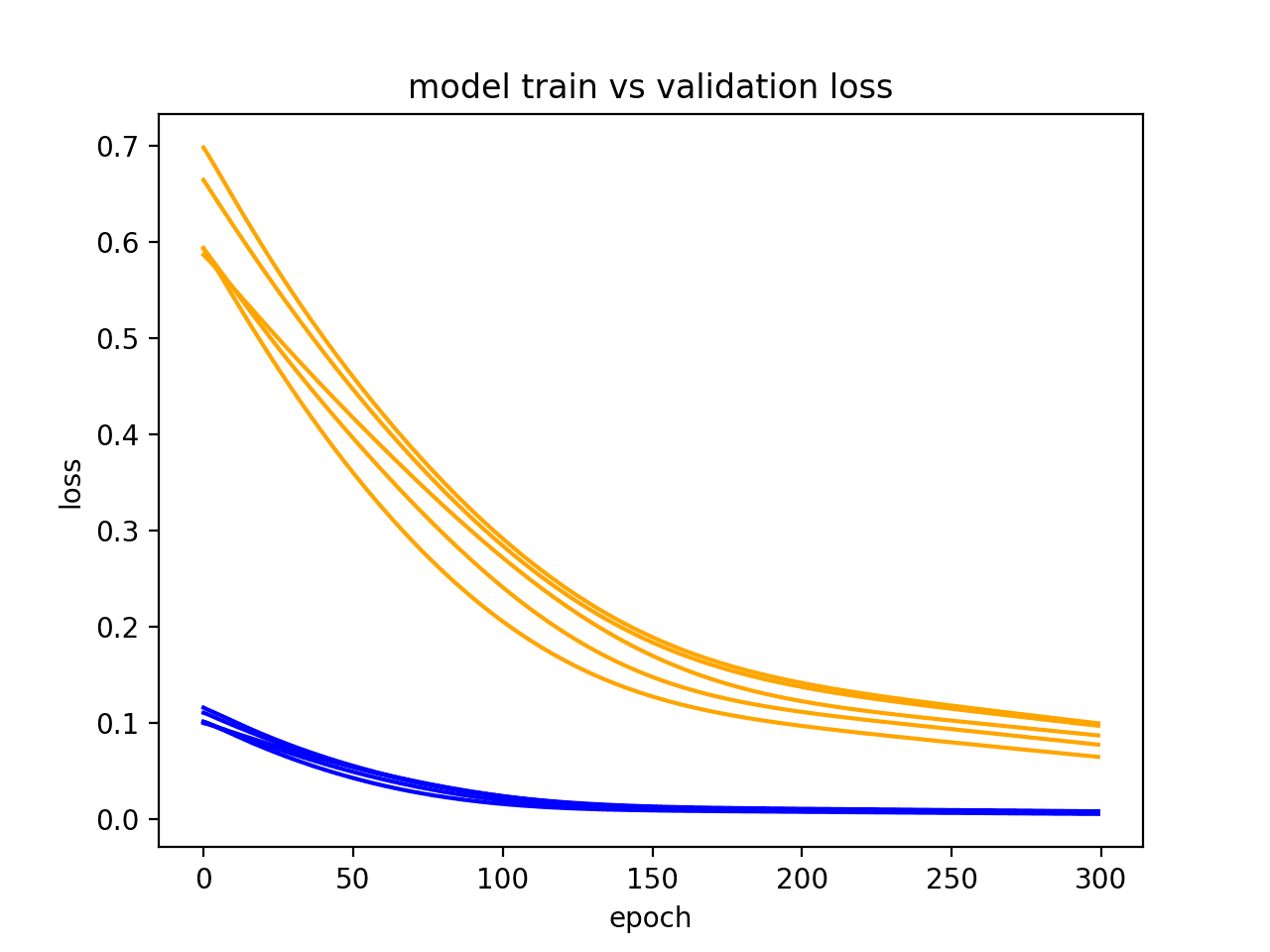
显示模型多次运行的诊断折线图
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
总结
在本教程中,您了解了如何诊断 LSTM 模型在序列预测问题上的拟合情况。
具体来说,你学到了:
- 如何收集和绘制 LSTM 模型的训练历史。
- 如何诊断欠拟合、拟合良好和过拟合模型。
- 如何通过平均多次模型运行来开发更鲁棒的诊断。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






非常有用的见解。感谢分享!
谢谢 Shiraz
提供了一些好信息,谢谢。您确定您的 x 轴单位是正确的吗?
是的,在一种情况下(过拟合示例),我截断了数据以便阅读。
嗨,Jason!
如果损失波动呢?第二个 epoch 之后,我出现了上下波动,即使有 25 个 epoch,验证集的损失仍然大于 0.5
您能给我一些关于发生这种情况的线索吗?
谢谢!
好问题。
我建议查看 10 到 100 个 epoch 的损失趋势,而不是非常短的时期。
感谢您发布关于如何诊断 LSTM 模型的这篇信息丰富的博文。我一定会尝试这个巧妙的技巧。请在接下来的帖子中继续分享更多有用的技巧和建议。
谢谢。我希望有所帮助。
您希望我写哪种类型的技巧?
嗨,James!有没有不使用验证集(当我使用 Dropout 层时)来检测过拟合的技巧?
(我是深度学习新手)
只过拟合训练集这个概念只有在有另一个数据集(例如测试集或验证集)的背景下才有意义。
另外,我的名字是 Jason,不是 James。
嗨,Jason,
可以使用测试数据集来检测对训练数据集的过拟合或欠拟合,而无需验证数据集吗?如何操作?这与使用验证数据集的方法不同吗?
非常感谢。顺便说一句,您的课程对学习机器学习非常有益。
也许可以,但是一个数据点(而不是每个 epoch 的评估)可能不足以做出诊断/声明模型行为。
嗨,Jason,
LSTM 的超参数调优非常有用——尤其是在时间序列方面。期待这方面的博文。
祝好,
Andrei
您具体想看什么?哪些参数?
我有几篇关于 LSTM 调优的帖子。
感谢您的帖子,Jason。
还有另一种情况,当验证损失低于训练损失时!这种情况表明时间序列高度非平稳,具有不断增长的均值(或方差),其中网络专注于恰好落在验证集中的信号的“肉”部分。
好建议,谢谢。
嗨,Jason!
感谢您提供如此有用的 LSTM 诊断方法。我正在进行人类活动识别。现在我的图看起来像这样 https://imgur.com/a/55p9b。您有什么建议吗?
我正在尝试对健身运动进行分类。
干得漂亮!
也许尝试在 epoch 10 左右提前停止?
在这种情况下,我的准确率将是
训练 21608 个样本,验证 5403 个样本
…
21608/21608 [==============================] – 802s – loss: 0.2115 – acc: 0.9304 – val_loss: 0.1949 – val_acc: 0.9337
Epoch 7/50
21608/21608 [==============================] – 849s – loss: 0.1803 – acc: 0.9424 – val_loss: 0.2132 – val_acc: 0.9249
Epoch 8/50
21608/21608 [==============================] – 786s – loss: 0.1632 – acc: 0.9473 – val_loss: 0.2222 – val_acc: 0.9297
Epoch 9/50
21608/21608 [==============================] – 852s – loss: 0.1405 – acc: 0.9558 – val_loss: 0.1563 – val_acc: 0.9460
Epoch 10/50
21608/21608 [==============================] – 799s – loss: 0.1267 – acc: 0.9590 – val_loss: 0.1453 – val_acc: 0.9606
Epoch 11/50
21608/21608 [==============================] – 805s – loss: 0.1147 – acc: 0.9632 – val_loss: 0.1490 – val_acc: 0.9567
Epoch 12/50
21608/21608 [==============================] – 788s – loss: 0.1069 – acc: 0.9645 – val_loss: 0.1176 – val_acc: 0.9626
Epoch 13/50
21608/21608 [==============================] – 838s – loss: 0.1028 – acc: 0.9667 – val_loss: 0.1279 – val_acc: 0.9578
Epoch 14/50
21608/21608 [==============================] – 808s – loss: 0.0889 – acc: 0.9707 – val_loss: 0.1183 – val_acc: 0.9648
Epoch 15/50
21608/21608 [==============================] – 785s – loss: 0.0843 – acc: 0.9729 – val_loss: 0.1000 – val_acc: 0.9706
50 个 epoch 后的准确率
第 50/50 轮
21608/21608 [==============================] – 793s – loss: 0.0177 – acc: 0.9950 – val_loss: 0.0772 – val_acc: 0.9832
我也没用 dropout 和 regularization。
我的一个类别(休息)比其他类别(运动)样本多得多 https://imgur.com/a/UxEPr。
混淆矩阵 – https://imgur.com/a/LYxUu。
我使用了以下模型
model = Sequential()
model.add(Bidirectional(LSTM(128), input_shape = (None,3)))
model.add(Dense(9, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’, optimizer=’rmsprop’, metrics=[‘accuracy’])
mcp = ModelCheckpoint(‘best_model_50_epochs.hd5’, monitor=”val_acc”,
save_best_only=True, save_weights_only=False)
history = model.fit(X_train,
y_train,
batch_size=32,
epochs=50,
validation_split=0.2,
callbacks=[mcp])
我也尝试了 dropout
model.add(Bidirectional(LSTM(128, dropout=0.5, recurrent_dropout=0.5), input_shape = (None,3)))
train_loss vs val_loss – https://imgur.com/a/k5TVU
50 个 epoch 的准确率
loss: 0.2269 – acc: 0.9244 – val_loss: 0.1574 – val_acc: 0.9558
嗨 Jason!当我有多个类别,其中一个类别占样本的 50% 时,您有什么建议来提高准确率?
(我上面展示了我的模型)
谢谢!
我这里有一些想法
https://machinelearning.org.cn/improve-deep-learning-performance/
激活函数、batch_size(我注意到它与测试集大小相关,但并非总是如此)、损失函数、隐藏层数量、内存单元数量、优化器类型、输入序列历史长度(https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/)
对于所有这些参数,我都会进行试错测试。想知道是否有更系统的方法来查找最佳参数。
我和 Andrei 做的事情差不多。我在电子表格中设计了几天的运行,然后开始执行,看看“问题是什么样的”。
https://machinelearning.org.cn/plan-run-machine-learning-experiments-systematically/
这里和引用的论文(例如,先测试什么,再测试什么,依此类推)中有一些非 LSTM 特定的方法可以系统地调整 mini-batch 梯度下降算法。
https://machinelearning.org.cn/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
谢谢 Jason!您的博客做得太棒了!
谢谢 Andrei!
嗨,Jason,
非常好的帖子,让我们知道如何诊断我们的程序!我一直在玩 RNN 一段时间了。我开始阅读您的以前的帖子。它们非常适合初学者入门!
现在我想进入更高级的水平,我希望您能分享我关于更令人兴奋的近期/最先进的模型(如 WaveNet、Deep Speech、使用 Keras 的 Attention 等)的见解/总结。
谢谢!
当然,您想知道什么?
嗨,Jason,
感谢您这篇非常有用的帖子,非常清晰。
我有一个问题。
当我们设置 fit() 中的 validation_data 时,它只是为了在 fit() 完成后查看模型的行为(这是我的猜测!),还是 Keras 在每个 epoch 的优化过程中使用此 validation_data 来更好地拟合 validation_data?(这是我希望的 :-)
我通常准备三个不相交的数据集:用于训练的训练数据,用于优化超参数的验证数据,以及最后用于测试模型的样本外数据。因此,如果 Keras 基于 validation_data 优化模型,那么我就不必自己优化了!
验证数据仅用于在训练期间了解模型在未见过的数据上的技能。
嗨,Jason,
为什么我进行回归时准确率值总是 0?损失值下降了。原因是什么?谢谢。
model.compile(optimizer=’adam’, loss=’mse’, metrics=[‘mean_squared_error’, ‘accuracy’])
我们无法为回归衡量准确率。它是正确标签预测的度量,而在回归中没有标签。
你好,
感谢您的有用帖子。
过拟合总是可以解决的吗?
换句话说,数据可训练的充要条件是什么?
也许我们有足够的数据,但由于数据不可训练,我们出现了过拟合。
这是一个开放性问题,并且特定于每个数据集。
我在这里列出了大量可供给定问题尝试的经验技巧
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
嗨,Jason,
感谢您这篇精彩实用的帖子。
我遇到了一个奇怪的问题,我的 LSTM 训练/验证损失图。如您所见 [1],验证损失在第一个(或前几个) epoch 后就开始增加,而训练损失持续下降,并最终变为零。我使用了 dropout 来处理这个严重的过拟合问题,然而,在最佳情况下,验证误差仍然与第一个 epoch 的值相同。我还尝试更改模型的各种参数,但在所有配置中,验证损失都呈现出这种增加的趋势。这真的是过拟合问题,还是我的实现或问题表述有问题?
[1] https://imgur.com/mZXh4lh
您可以探索具有更强表示能力的模型,也许是更多的神经元或更多的层?
我测试了多个层以及每层不同数量的神经元,但在许多测试中,我仍然看到几个 epoch 后验证损失呈现相同的增加趋势。
也许可以尝试更改更多其他方面,如优化算法、学习率、批大小等,请看这里
https://machinelearning.org.cn/improve-deep-learning-performance/
嗨,Jason。我为您帖子中的观点感到非常震惊。我面临一个困难的情况,在使用 LSTM 时,验证损失 >>
训练损失,所以我搜了一下。这里 https://github.com/karpathy/char-rnn/issues/160 和这里 https://www.reddit.com/r/MachineLearning/comments/3rmqxd/determing_if_rnn_model_is_underfitting_vs/ 他们建议这可能是过拟合。但在您的帖子中,这应该是欠拟合。我很困惑,您能解释一下吗?
你好 Cliff:我认为 Jason 的标题弄错了。在欠拟合的标题中,他解释的是过拟合。
我认为这篇关于该主题的教程更好
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
感谢这篇好文章,我想将其与其他技巧和窍门进行比较,以确保没有冲突。
– 这里你说
欠拟合:训练表现好,测试数据集表现差。
– 在其他技巧和窍门中,它说
过拟合:训练损失远低于验证损失
这两个技巧是否相同,只是诊断不同?因为表现好应该意味着损失低。
嗨,Jason,
我没有理解“3. 欠拟合”示例中的一些内容。本节第一个示例的图显示验证损失在减少,您也认为如果网络通过更多 epoch 进行更多训练,损失会进一步减少。网络如何在从未见过的数据序列上给出正确预测?特别是,如何在从 0.0 到 0.5 的序列上学习(get_train() 函数的数据)来改进对 0.5 到 0.9(get_val() 函数的数据)的预测?
我还想说的是,我一直在阅读您博客上的帖子一个月了,但这是我第一次评论,我想感谢您在这里持续发布内容,并使机器学习更容易访问。
好问题,在理想情况下,模型将从示例中泛化。
谢谢你的支持!
Jason,我不太明白,您能详细说明一下吗?谢谢!
嗨,Jason,
我测试了欠拟合示例 500 个 epoch,并在 model.compile 函数中提到了“metrics = [‘accuracy’]”,但当我拟合模型时,所有 500 个 epoch 的准确率指标都是 0。为什么在这种情况下准确率是 0%?
也许您的模型技能非常差?
您说的技能差是什么意思?我测试了这个博客示例(欠拟合第一个示例,500 个 epoch,其余代码与欠拟合第一个示例相同),并检查了准确率,结果是 0% 的准确率,但我期望有很好的准确率,因为在 500 个 epoch 时,训练损失和验证损失收敛了,正如本博客中所提到的,这也是一个拟合良好的示例。
抱歉引起混淆,模型技能是指模型做出高质量预测的能力。
我测试了这个博客的拟合良好示例,它也给了我 0% 的准确率。如果拟合良好的模型给出了 0% 的准确率,那么我们就没有什么可以调整其准确率的了,因为它已经拟合得很好了。然而,拟合良好的模型应该能提供高质量的预测。我认为您应该自己检查这个博客的拟合良好示例的准确率,并请就此提供一些评论以消除混淆。
我们正在处理的示例中没有准确率,这是一个人为设计的回归问题(不是分类),并且只评估损失。
您可以在这里了解更多关于为什么您不能使用准确率来评估回归的信息
https://machinelearning.org.cn/classification-versus-regression-in-machine-learning/
你好,
很棒的文章,谢谢!
两个简短的问题
1)您设计的代码方式,状态不会在每个 epoch 后重置,这是一个问题。是否有办法包含 model.state_reset,但只训练模型.fit 一个 epoch 在一个 for 循环中?基本上是
model.fit(X,y, epochs = 100, validation_data = (valx, valy), shuffle = FALSE, stateful = TRUE, state_reset= TRUE) 或者类似的?
2)如果那不可能,我该如何模仿相同的行为?会是这样的吗?
for i in range(epos)
model.fit(X,y, epos=1, stateful=true)
yhat_t = model.predict(train, …)
yhat_val = model.predict(val, …)
train_error = msqrt_error(y, yhat_t)
val_error = msqrt_error(y, yhat_val)
model.state_reset()
我只想绘制误差和准确率随 epoch 的发展情况。
谢谢!
要管理状态,您必须在循环中逐个手动执行 epoch。
这个也适用于 DecisionTreeClasfier 吗?
也许可以。
尊敬的布朗利博士,
我正在使用 CNN 层处理一个分类问题,但是我的训练和验证损失曲线很奇怪。训练损失非常快地下降到低水平并收敛,具有高准确率。我的验证曲线最终也收敛了,但速度慢得多,而且经过了更多的 epoch。因此,训练和验证损失之间存在巨大的差距,但在经过一定数量的 epoch 后,该差距会突然缩小。
我正在使用 Keras/Tensorflow 架构,该架构是 Conv + Batch Normalization + Convo + Batch Normalization + MaxPooling2D 重复 4 次,我的 CNN 用于将图像分类为大约 30 个类别之一。我在以下 stack exchange 上有更多详细信息
https://stats.stackexchange.com/questions/335890/how-do-i-interpret-my-validation-and-training-loss-curve-if-there-is-a-large-dif
您对这种情况可能存在的问题有什么见解吗?
也许模型欠拟合?探索更大的模型看看是否有区别。
你好,Jason。
感谢您的帖子。我正在使用 LSTM 进行机器翻译。现在我的图看起来像这样 https://imgur.com/a/i2dOB87。您有什么建议?
我正在尝试提高准确率。
我正在使用 4 层编码器和解码器。
这是基本实现。
………………………….
编码器
encoder1 = LSTM(lstm_units, return_state=True , return_sequences = True , name = ‘LSTM1’)
encoder2 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘LSTM2’)
encoder3 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘LSTM3’)
encoder4 = LSTM(lstm_units, return_state=True , name = ‘LSTM4’)
encoder_outputs4 , state_h4 , state_c4 = encoder4(encoder3(encoder2(encoder1(embedded_output))))
………………………………
解码器
decoder_lstm1 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘Dec_LSTM1’)
decoder_lstm2 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘Dec_LSTM2’)
decoder_lstm3 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘Dec_LSTM3’)
decoder_lstm4 = LSTM(lstm_units, return_sequences=True, return_state=True , name = ‘Dec_LSTM4′)
decoder_outputs4 , _, _ = decoder_lstm4(decoder_lstm3(decoder_lstm2(decoder_lstm1(embedded_Ar_output,
initial_state=encoder_states4))))
decoder_dense = Dense(output_vector_length, activation=’softmax’)
decoder_outputs = decoder_dense(decoder_outputs4)
*lstm_units : 500
*epochs : 200
………………………..
fit model 部分
#Compile Model
model.compile(loss=’mse’, optimizer=’adam’ , metrics=[‘acc’] )
#Train and fit model # Learning!
history = model.fit([dataset_encoder_input, dataset_decoder_input], target ,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
*batch_size = 512
干得漂亮,这里有一些可以尝试的通用想法
https://machinelearning.org.cn/improve-deep-learning-performance/
嗨,Jason,感谢您的网站,它太棒了…
一个问题,在 python 中(我是 python 新手)是否存在像 R 中的 Caret 这样的“包”,我可以通过几个步骤训练一个 LSTM 模型(或其他深度学习算法),找到参数或超参数(我给它一个向量),同时进行缩放(或预处理数据)和验证或交叉验证?
目标不是输入太多命令,而是组合查找最佳参数或超参数。
您是在问网格搜索 LSTM 吗?
如果是,这里有一个使用 Keras 模型进行网格搜索的示例,您可以进行改编
https://machinelearning.org.cn/grid-search-hyperparameters-deep-learning-models-python-keras/
嗨,Jason!
很棒的帖子和精彩的图。这些评估过拟合与欠拟合的方法是否也适用于 LSTM 以外的模型,例如前馈神经网络或 CNN?
是的。
谢谢!
嘿 Jason,首先感谢您的帖子,您的所有帖子都非常有帮助。但是,我对第 3 节(欠拟合模型)中的第二个图感到有些困惑。这难道不是过拟合吗?模型在训练误差上损失很低,但在验证集上损失很高,即泛化不好?您在这种情况下提出的建议是增加模型的容量,但这只会改善训练集的拟合,从而扩大验证集和训练集损失之间的差距吗?谢谢,Mike
注意这些线开始时就很遥远,并且一直保持遥远。这是我们寻找欠拟合时的信号。
亲爱的 Jason,
我正在使用 LSTM 预测一些时间序列数据。
这是我的模型和提前停止。
https://photos.app.goo.gl/WuPELturhc8Z4JbP9
这是运行 100 个 epoch 的结果。
https://photos.app.goo.gl/p1h4PQdC1CE6wJHq8
这看起来还好吗?我是否过拟合了?我想知道为什么开始时验证损失会小于训练损失?
非常感谢您的帮助,以及您提供的所有这些出色工作。
在我看来,这并不像过拟合。
嗨,Jason,
这是一篇非常有用的文章。在示例中,只预测了一个值。对于时间序列预测,可能需要预测多个值:t, t+1 … t+n。您知道 history[‘loss’] 和 history[‘val_loss’] 是如何计算的吗?或者是否有其他指标可以参考?
提前感谢。
我推荐这个教程
https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
非常感谢您的回复。
我之前读过您提到的教程。您的意思是创建自己的函数,如 evaluate_forecasts(…) 来计算每个 epoch 的 t+i rmse,然后绘制 rmse 与 epoch 的关系吗?
教程没有帮助吗?
嗨,Jason,
是的,您提到的教程有帮助,但我想确保我的理解是正确的。
我的问题是,对于时间序列预测 t+1 … t+n,如何绘制训练损失和验证损失。我想知道 history[‘loss’] 和 history[‘val_loss’] 是否仅用于 t+1,还是它们是 t+1 … t+n 的平均值?是否有其他指标用于此目的?
如果 history 中没有用于衡量 t+1 … t+n 的训练损失和验证损失的指标,我是否需要创建自己的函数,如 evaluate_forecasts(…) 来计算每个 epoch 的 t+i rmse?
提前感谢。
抱歉,现在我明白了。
在训练过程中,没有不同时间步长损失的概念,模型根据给定输入的输出向量计算损失。
如果您想在训练期间了解每个未来时间步长的误差,您可以逐个手动进行训练 epoch,计算误差,并在运行结束时绘制所有误差。
Jason 先生您好,很高兴读到您的文章,它给了我很大的帮助。在阅读了 MLT 和您之间的帖子后。我又有一个问题,如果“在训练过程中,没有不同时间步长损失的概念,模型根据给定输入的输出向量计算损失。”那么,为什么每个训练 Epoch 都有“loss: 0.0662”?抱歉,我想正确理解您。
损失是正在最小化的模型得分,它特定于问题类型,例如回归的 MSE 或分类的交叉熵。
嗨,Jason,
我正在尝试制作 LSTM 模型。
以下是我的模型代码和结果。
模型存在过拟合,但我不知道如何使该模型收敛。我借助这篇帖子更改了我的变量缩放,但结果仍然相同。
https://machinelearning.org.cn/improve-deep-learning-performance/
代码
model = Sequential()
model.add(LSTM(66, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dropout(.5))
model.add(Dense(1))
model.compile(loss=’mae’, optimizer=’Adam’)
# 拟合网络
history = model.fit(train_X, train_y, epochs=30, batch_size=66, validation_data=(test_X, test_y), verbose=2, shuffle=False)
结果。
https://drive.google.com/file/d/1Byos8d1wVAopqGydYLnpUDgkRqUCbPxS/view?usp=sharing
您能帮我理解我遗漏了什么吗?
我很乐意回答技术问题,但我不能帮您检查代码,抱歉。
嗨 Jason
如果我的训练损失和准确率曲线很好,而测试曲线却发散,我应该怎么想?
关于损失,请想象一个 X
从左上到右下是训练的
从左下到右上是测试的
谢谢,
g
我不确定我是否明白了,也许可以提供一张图?
你好 Jason,
感谢您提供的精彩教程和书籍(我和我的朋友购买了 NLP 套餐,非常有帮助)。
我理解“良好拟合”意味着验证误差很低,但可能等于或略高于训练误差。
我的困惑是:多大的差异才算可以,不算过拟合?
例如,如果最后一个 epoch 训练损失为 0.08,验证损失为 0.11,这是否表示过拟合?
这完全取决于具体问题。没有普遍适用的规则。
如果模型在训练集上的性能持续提高,而在测试集或验证集上的性能开始变差,那么就明显是过拟合了。
你好!首先,感谢您解释过拟合和欠拟合的概念。这非常有帮助,因为步骤解释得很详细。但如果可以的话,您有什么具体的来源(或在线期刊)可以说明您是如何判断模型是欠拟合/过拟合的吗?如果可以,您能否将其包含在帖子中?非常感谢,我期待您的回复!
手边没有,您具体在寻找什么?
哦!如果我说得令人困惑,我很抱歉。但我正在寻找任何期刊/书籍/论文,可以用来判断一个模型是否被认为是过拟合、欠拟合或拟合。如果您知道任何,请告诉我好吗?谢谢。
也许在这里搜索
http://scholar.google.com
嗨,Jason,
我正在尝试使用您的教程,使用我自己的时间序列数据来构建模型
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
我甚至无法让训练曲线低于 0.05。所以这不是过拟合或欠拟合的问题。我应该看什么?
一般来说,LSTM 在时间序列预测方面非常糟糕。也许可以从线性模型开始,然后尝试 MLP,然后是 CNN,最后是 LSTM。
我推荐这个过程
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
你好,Jason!
我正在从事用于分类目的的 EEG 数据集。该数据集包括 65000x14x320(样本 X EEG 通道 X 时间步)的原始 EEG 信号作为输入数据,并分为 11 类。时间步长不是固定的,而是从 130-320 不等。所以我选择了将它们全部零填充到 320。
由于数据是序列性的,我选择使用 Keras 中的 LSTM 来训练它们。尝试调整各种超参数但都无济于事。模型根本没有学习。准确率始终徘徊在 1/11 左右,即随机猜测的水平。
关于深度学习中处理 EEG 数据有什么建议吗?
一般来说,我建议在开始时遵循这个过程
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
我这里有一个使用 EEG 数据的示例
https://machinelearning.org.cn/how-to-predict-whether-eyes-are-open-or-closed-using-brain-waves/
此外,这些教程中的一些也将有所帮助
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好,杰森!
首先,您的教程一直很有帮助!
其次,我目前正在使用一个 ANN,其中我的验证损失比我的训练损失要好(我的指标是 mae)。我得出结论它是欠拟合。然而,无论我如何调整超参数都无法解决。我已经调整了从 epoch 到隐藏层和每层神经元数量的一切。有什么建议如何处理这个问题?
谢谢!
也有可能是验证数据集太小或者不能代表整体情况?
尝试更改它,使用一个大的验证集?
嗨 Jason
感谢这篇文章。
我们正在为评论分析开发一个原型模型,遇到了一个看似不寻常的问题。我正在使用 Keras(Tensorflow 层)LSTM 模型。
我们在生产中使用 tensorflow.js 框架。并开发了一个具有 UI 的部署和训练平台。
UI 包括来自模型的训练摘要图。
我们最近训练了一个模型,该模型应该可以对一个相当简单(但特定)的语义规则进行推理,这可能可以解释接下来发生的事情。
我们训练了一个模型,在看不见的测试数据上显示出 99% 的准确率!这个百分比是基于我们通过编程计算二进制分类器的预测来响应新预测的。我们没有读取模型的验证准确率或准确率。
为了所有意图和目的,与我们在新测试数据上的人类标签相比,该模型确实有 99% 的准确率。然后我们测量两个分数(0 和 1)的精度,并且接近每个分数的总体平均值(0 分精度为 99%,1 分精度为 98%)。
A) 这似乎很奇怪……即使正如我所说,我们正在独立测试结果
B) 摘要图显示,大约在 epoch 30 时,验证误差显著高于训练误差。我们训练到 epoch 100,有 81 个 LSTM 单元。
当我们训练到训练和验证误差收敛时,我们会得到一个明显准确率更低的模型
您对此有什么看法?
谢谢
Dan
哇,生产环境中的 tensorflow.js?为什么不是 Python 版本?
也许验证数据集很小,或者不能代表训练数据集,因此结果具有误导性?
另外,据我经验,损失是衡量过拟合的最佳指标,准确率对于过拟合的模型通常保持平坦。
嗨,Jason!
我正在尝试将此应用于与您的电力预测教程中的代码类似的示例。
但是当我尝试使用 validation_split 时,我在 history 中什么也得不到,它什么也没有。history.keys 是空的。
我的训练数据的形状是 (1.10.3),这可能是我的问题的原因吗?“第一个形状”是 1,所以它不能被分割?
感谢您出色的教程!
使用验证数据集进行时间序列处理很困难,因为我们通常使用前向验证。
您可能需要手动运行验证评估并构建自己的图。
你好,感谢分享。您能告诉我如何检测逻辑回归和 KNN 的过拟合吗?有很多关于如何避免过拟合的信息,但我找不到任何解释如何检测过拟合的适当信息?
是的,您可以计算模型在验证数据集上的性能,例如,学习点而不是学习曲线。
也许对多个折叠的结果进行平均。
有没有什么数值指标可以做到这一点,而不是看图?
可能有一些,但据我所知没有。
嗨,Jason,
我只是想知道网站上描述的图(用于诊断欠拟合和过拟合)是否也适用于其他机器学习模型,例如多层感知机……谢谢!
当然可以!
请看这篇文章
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
我训练了我的 LSTM 模型(单次),并在预测中观察到了一些好的结果。
请查看下面的链接,与损失和准确率相关
链接 1
https://i.imgur.com/YHzJGdl.png
在那之后,根据您的帖子,我尝试了我的 LSTM 模型进行多次运行,最多 5 次迭代。(LSTM 是随机的)
请查看多次运行的链接
https://i.imgur.com/r4YAgtu.jpg
问题
我能从多次运行的图片中理解什么?
我的模型不好吗?
如果不好,我该如何改进?能否分享一些博客文章来改进这种情况下的模型?
看起来有点过拟合,也许可以尝试正则化。
这里有一些想法
https://machinelearning.org.cn/start-here/#better
你好 Jason,
我使用了 2 个 Dropout 层,每个 Dropout 率为 10%,来正则化我的模型。由于我的模型只有 2200 个参数,使用 Dropout 只会留下有限的数据用于学习。
所以,在我避免使用 Dropout 后,我的损失和验证损失遵循一个模式。
请查看下面链接中的图片……
https://imgur.com/I2JxyXD
请评论我遵循的流程是否正确
我建议测试一系列干预措施,看看哪种最适合您的问题。
另外,您的链接不起作用。
你好,你能给我发短信吗?我有一个图,在尝试训练我的模型时我不喜欢,你能帮我吗?
也许这个教程会有帮助
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
我创建了一个使用 RNN 预测 CPU 使用率的模型。我使用了 Materna 的数据集。我的验证损失和训练损失分别为 0.0095 和 0.0057。这是图。我的模型足够好吗,还是表示高方差或高偏差?
好的表现是相对的。
也许可以与朴素模型或线性模型进行比较。
嘿 Jason,首先感谢您的帖子,您所有的帖子都非常有帮助。
我创建了一个关于学生与视频互动过程的 LSTM 模型。我使用了 l2 和 dropout 来减少过拟合,但是当我绘制验证损失和训练损失图时,我感到困惑。
请问您能帮我区分一下这个图吗?
这张图的照片链接……
非常感谢
https://imgur.com/Vj5fGrW
谢谢。
看起来拟合得“不错”。也许可以尝试其他配置来确认它不是欠拟合。
感谢 Jason 的帖子。
我有一些关于 LSTM 的问题
1. 目前,我正在使用 Tensorboard 来可视化每个 epoch 的准确率和损失(训练和验证)。Tensorboard 生成的图与您的代码相同吗?我开始怀疑是应该继续使用 Tensorboard 还是不使用。
2. 我的数据集相当大(约 470 万条数据),我打算实证测试 3、5、7、9 和 11 个序列长度(我将它们称为窗口)中哪一个性能更好。标签 0 或 1 将应用于每个窗口,并且由于标签 1 大部分时间分配给少量窗口,这很可能导致数据集不平衡。我已经进行了欠采样,并打算使用类别权重来平衡它们。
当我测试一个具有 7 个序列长度的窗口时,我无法在不牺牲召回率的情况下获得良好的准确率(我猜测这是由于数据集不平衡的性质和相关的权重)。准确率似乎卡在 ±60% 左右,而召回率几乎总是更低(当召回率超过 60% 时,准确率会降低)。
我检查了 Tensorboard,发现每个 epoch 的验证准确率和验证损失似乎有些奇怪的波动(一些互联网帖子认为这是因为我使用的 Keras 的 mini batch size,我使用的是 batch_size=2000)。然后我检查了混淆矩阵,结果更令人沮丧,我的模型预测了 53% 的时间是类别 0,47% 的时间是标签 1,从而导致召回率超过 50%(我认为这意味着我的模型低估了类别 0,高估了类别 1)。
自然而然地,这引出了这些问题:
2a. 理想的 batch_size 是多大?这会影响我的模型吗?
2b. 我了解到要创建一个深度学习模型,一个人应该从简单的开始。我从一个非常简单的架构 LSTM(32)-FC(16)-FC(2) 开始,最后一个层使用 softmax。我如何知道何时增加神经元或何时增加层?更重要的是,我如何知道即使我增加容量,我的模型也不会变得更好?
2c. 在我最后的实验中,我尝试使用 dropout 来提高模型的性能(尽管我不确定什么时候可以说我的模型是好的)。我注意到的一件事是,dropout 的放置(以及 dropout 的速率)对我的模型影响很大。它可能导致我的模型只预测类别 0(导致 94% 的准确率和 0% 的召回率)。有时,当我尝试与 L2 正则化结合使用时,也会发生这种情况。您对如何微调这种情况有什么见解或指南吗?
如果这些问题很长并占用了您大量时间,我非常抱歉。我期待您的回复。非常感谢您,Jason。
你好 Omar,恭喜你取得了进展!
也许应该抛开准确率,考虑到你对精确率/召回率的关注,可以考虑优化 F-measure (F1)。
抱歉,我对 tensorboard 不了解。
测试不同的 batch size 来找出最适合您的模型+数据的。
更多关于配置网络的信息(也就是说,没有可靠的规则)
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
不是马上就能知道的,抱歉。
谢谢你的回复。
考虑到使用 F1 的情况,Keras 是否支持通过评估每个 epoch 的 F1 分数来进行反向传播?
另外,我读了您的帖子(https://machinelearning.org.cn/use-dropout-lstm-networks-time-series-forecasting/),建议在 LSTM 中使用 dropout。有什么区别
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True, dropout=dropout))
和
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
model.add(Dropout(dropout))
谢谢。
不,您应该使用交叉熵损失进行拟合,可能带有类别权重,但通过 F-measure 分数来进行模型选择。
好问题。Dropout 在时间步之间 vs 序列结束后的 Dropout。
太好了,谢谢 Jason!
不客气。
亲爱的 Jason,抱歉再问您问题。您能看看这张图片吗?
https://imgur.com/JLMyYgD
我的一些 LSTM 模型显示了这种每 epoch 验证损失的图(我尝试了 50 个 epoch,使用 Keras 的早停,耐心值为 15)。根据我的理解,这张图显示我的总体验证损失正在下降(呈下降趋势)。您认为我需要更多的 epoch 吗?
非常感谢 Jason。
看起来学习还可以继续。也许可以尝试一下,并比较早停时的模型(通过检查点保存)与学习更多之后的模型?
我会试试的。目前,我已经尝试了 LSTM 单元、FC 神经元、L2 值和 Dropout 值的组合,每个组合运行 5 次,并生成了 100 个不同的模型(通过 Keras EarlyStopping 和 Restore Best Weight)(50 个 epoch 和 15 个耐心值)。我是否应该重新运行每个模型,使用更多的 epoch(例如 100 个 epoch)和更多的耐心?我打算尝试 7 种不同的序列长度,这样我将有 700 个模型。
谢谢你,Jason。
也许可以测试并比较结果?
嗨 Jason
感谢这篇文章。
我有一个问题。
我的训练准确率正在提高,但验证准确率最终会下降。
同样,训练损失最终会下降,但验证损失会增加。
你能告诉我原因吗?以及如何改进。
我有一些文本数据。我正在模型中使用 bilstm 层。
听起来你正在过拟合。
也许以下方法之一会有帮助
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
你好 Jason,我正在对从视频中提取的特征进行人类活动分类。
这是一个多类问题。基本上,我通过视频片段组织了 train_data,每个片段都有一个标签,并将数据分为 75% 的训练数据和 25% 的验证数据。
我正在使用 LSTM 进行训练,并带有 dropout。到目前为止,我的训练准确率可以达到 90%,epoch=60,但验证准确率保持在 38%。
观察结果:训练准确率持续提高,但验证准确率停止提高,并从 epoch 18 到训练结束(即 epoch 60)保持平稳。这在我看来不像欠拟合,因为训练准确率可以继续提高。但我也无法判断它是过拟合,因为验证准确率仍然是 38%。
我认为前进的方向是添加 dropout 来正则化过拟合,以便学习到的权重能够更好地减少验证损失。我是否朝着正确的方向前进?
您有什么建议可以帮助提高验证准确率,我还可以尝试什么来更好地缩小问题范围?
为你的进步喝彩!
或许可以尝试这里的一些建议
https://machinelearning.org.cn/improve-deep-learning-performance/
嗨!
所以,我将数据集分为三个部分:训练、验证和测试。
在 fit 时,我过去只使用训练数据,然后调用 model.evaluate 配合训练数据,最后调用 model.evaluate(以获得分数) 配合验证数据。最后,我用所有数据训练模型,然后用所有拟合好的模型调用 model.evaluate 配合测试数据。
我的问题是,在哪里应该使用 validation_data?我是否应该在之后使用 model.evaluate 配合与 validation_data 相同的数据?或者我是否应该只在测试数据上使用 model.evaluate,而不是在验证数据上?
我还有另一个问题是,当我用所有数据拟合模型时,我是否不应该使用 validation_data?我的疑问主要是,是否足够依赖验证数据,因为在验证集上进行改进后,仍然可能导致测试集上的过拟合或欠拟合。
提前感谢!
通常,验证数据用于在训练期间监控性能,并在模型开始过拟合时停止训练。
这可以通过早停回调来实现
https://machinelearning.org.cn/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
非常有帮助!!谢谢
谢谢,很高兴听到这个。
训练测试比验证测试高是什么样的问题?谢谢。您的博客非常有帮助
在这种情况下,训练损失 > 测试损失,那么测试集可能太小,不能代表问题。
嗨,博士。
如果我们多次用不同数据集(在一个周期内)拟合 LSTM 模型,您建议如何识别模型是否过拟合?
我们应该分析每个拟合的图,还是在这种情况下计算每个损失和验证损失的平均值比较可靠?
案例 1
for x,y in dataset
history = model.fit(x, y, epochs=nrEpochs, validation_split=0.33, …)
#在周期内绘制图
案例 2
loss = []
val_loss = []
for x,y in data
history = model.fit(x, y, epochs=nrEpochs, validation_split=0.33, …)
loss.append(history.history[‘loss’])
val_loss.append(history.history[‘val_loss’])
#在周期外绘制图。
谢谢,您的博客太棒了!
尝试构建学习曲线,如果不能,那么可以查看训练与验证/测试性能的点值。
太棒了 Jason
谢谢!
嗨,博士。
抱歉打扰。我的 LSTM 很快就获得了高准确率(99%)。但是,我认为这好得有点离谱。
我不认为模型过拟合得那么严重。我可以问一下您的意见吗?
“好”结果正常吗?
https://ibb.co/bNtGmr0
提前感谢!
好问题,我认为这将有所帮助
https://machinelearning.org.cn/faq/single-faq/what-does-it-mean-if-i-have-0-error-or-100-accuracy
嗨,Jason,
我有 500 个样本的多个场景。我想将它们分割成训练集和测试集。所有这些样本都应该保持在一起。只有顺序应该被混合和分割。
我原本以为 train_test_split 会起作用,但它会混合它们。
#导入数据集
dataset_train = pd.read_csv(‘Labeled_data.csv’)
#D 数组
n_samples = 500
init = 0
data = []
for i in range(n_samples,len(dataset_train),n_samples)
scenario = np.array(dataset_train)
padded_array = scenario[init:i,:]
data.append(padded_array)
init = i
data = np.stack(data)
dataset = np.load(‘dataset.npy’)
X_train, X_test, y_train, y_test = train_test_split(dataset[:,:,0:12], dataset[:,:,12:13],test_size = 0.2)
train_data = np.zeros((1,13))
for i in range (0,X_train.shape[0])
scenario = np.array(X_train[i,:,:])
label = np.array(y_train[i,:,:])
scen =np.concatenate((scenario, label), axis=1)
train_data = np.concatenate((train_data,scen),axis=0)
抱歉,我没有能力审查/调试您的代码。
也许随机分割样本?也许按顺序分割?您最了解您的数据。
先生,您好,
在所有这些例子中,训练集和验证集的损失值从不同的值开始,然后收敛(或不收敛)。但是,如果训练集和验证集的损失值从相同的值开始,然后发散,但之后又收敛,这是什么意思?
我在这里有一个例子:https://ibb.co/phzKTLm
谢谢,抱歉打扰。
在我看来很棒!一个良好的拟合。
布朗利博士您好,
我喜欢您的博客文章和您的书。多亏了您,我学到了很多。您在回复会员方面非常勤奋。
我还在学习中,在 StackOverflow 博客上有人告诉我,准确率在回归问题中没有意义。我注意到您在上面的 LSTM 中使用了准确率,而 LSTM 是一种 RNN。您能否为我澄清这一点,因为我现在对此感到认知失调。提前感谢,并继续保持出色的工作。
谢谢!
是的,准确率对于回归是无效的
https://machinelearning.org.cn/faq/single-faq/how-do-i-calculate-accuracy-for-regression
上面的模型是一个回归模型,不使用准确率。我们正在绘制损失。
帖子开头使用的那个示例是用于分类模型的。
你好 Jason,感谢您的教程。您能否进一步解释一下使用 validation_split(0.33) 和 validation_data=(valX, valY) 的区别?
我明白使用 split 时,会从训练数据中取一定比例用于验证。但是,我不太理解使用 validation_data=(valX, valY)。
谢谢!
是的,前者会自动从训练集中选择验证集,后者使用您已经提取或准备好的指定集合。
感谢您的宝贵帮助。
我还见过将 validation_data=(x_test, y_test) 的示例。这是正确的验证实现吗?您如何解释?
有时我那样做,这是为了让示例更简单,而不是一种好的实践。
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
精彩的教程,谢谢!我的问题是,如果我的验证和测试损失看起来像波浪(即,一起下降,就像小波浪一样),这意味着什么?
谢谢!
Luke
谢谢。
在建模之前,最好去除数据中的周期/季节性
https://machinelearning.org.cn/remove-trends-seasonality-difference-transform-python/
你好 Jason,当您展示欠拟合模型的示例时,您的图清楚地显示训练损失 < 验证损失。
然而,我进行了进一步的研究,似乎当训练损失 < 验证损失时,这是过拟合。
我感到很困惑,您能否对此进行澄清?
谢谢,
Matthew
在一般情况下,您是正确的。
在本例中,我们可以清楚地看到模型还有改进的空间。拟合过程尚未收敛,它是欠拟合的。
这种方法对于确定过拟合和欠拟合非常有用。
在本教程中,它用于 LSTM 模型。
它是否也用于确定线性回归 ANN 模型等其他神经网络模型的过拟合和欠拟合?
是的。
参见此
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
您的一些结论/建议是不正确的,您需要重写这篇帖子。例如,正如有人指出的那样,当验证损失大于训练损失时,这很可能是过拟合的迹象。而且它*绝对*不是欠拟合。
我见过验证损失在很长一段 epoch 中持续*低于*训练损失,但模型在预测测试集时效果很差。好吧,在 painstaking 地查看了数千行数据后,我终于找到了罪魁祸首。
结果发现训练集中有一些异常值,这迫使模型从这些异常值中学习。请记住,如果您的损失是 MSE,它会夸大训练集中的少数坏苹果。而验证集恰好没有这些异常值。
所以,即使当验证损失低于训练损失时,也不能说明什么。
我不同意——但我们可能在互相误解,而且一个小的测试/验证数据集可能会描绘出相互矛盾的画面。
请参见这篇关于学习曲线的更新帖子
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
你好 Brownlee 先生,非常感谢您这篇有价值的文章,它非常有帮助。
我只有一个注意事项,您说“欠拟合模型是指在训练数据集上表现良好,在测试数据集上表现差的模型。” 我认为恰恰相反,欠拟合模型在训练数据集上表现很差,对吗!
同意。欠拟合通常意味着在训练集上表现不佳
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
感谢您所有精彩的教程,我是一名机器学习新手,但通过您的课程,我进步得很快。
我需要您的帮助来构建我的验证数据集,以便与我的训练数据集进行比较。在这里,您的示例中,您有一个预定义的验证数据集,对吗?
但是一般来说,我能获得如何提供验证数据集的链接或来源吗,请?
我正在使用您的 LSTM 模型处理机场乘客数据,现在我需要优化我的模型和预测。
在此先感谢,
Ronak。
不客气!
序列数据集的验证数据很难。通常,训练集中的最后 n 个序列会被保留用于验证。
如何开发用于单类分类方法的 LSTM 模型?