
使用 Python 诊断和修复机器学习中的过拟合
作者 | Ideogram 提供图片
引言
过拟合是构建机器学习(ML)模型时遇到的最常见(如果不是最常见的话!)问题之一。本质上,当模型过度学习训练数据中的细微差别(甚至是噪声),而不是以一种允许更好地泛化到未来未见数据的方式捕捉潜在模式时,就会发生过拟合。诊断您的 ML 模型是否遇到此问题,对于有效解决它并确保模型在生产环境中部署后能够很好地泛化到新数据至关重要。
本文以教程形式,说明了如何使用 Python 诊断和修复过拟合。
设置
在诊断 ML 模型中的过拟合之前,我们需要数据来训练模型。让我们开始导入必要的包,并创建一个在训练回归模型之前容易过拟合的合成数据集。
加载包
|
1 2 3 4 5 6 7 |
import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures 来自 sklearn.linear_model 导入 LinearRegression from sklearn.pipeline import make_pipeline from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error |
数据集创建(主要遵循正弦模式并添加一些噪声)
|
1 2 3 4 5 6 7 8 |
def generate_data(n_samples=20, noise=0.2): np.random.seed(42) X = np.linspace(-3, 3, n_samples).reshape(-1, 1) y = np.sin(X) + noise * np.random.randn(n_samples, 1) return X, y X, y = generate_data() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) |
诊断过拟合
诊断过拟合有两种常用方法:
- 一种方法是将模型的预测或输出作为输入的函数进行可视化,并与实际数据进行比较。这可以通过图表完成,特别是对于低维数据,以查看模型是否过拟合了训练数据,而不是以一种更具泛化性的方式捕捉潜在模式。
- 对于更复杂的、更难可视化的模型,另一种方法是检查训练集和测试集或验证集之间的准确性(或错误)差异。较大的差距,即训练性能明显优于测试性能,是过拟合的有力指标。
由于我们将训练一个非常低复杂度的多项式回归模型来拟合我们之前创建的低维、随机生成的数据集,现在我们将定义一个函数,该函数训练一个多项式回归模型,并将其与训练和测试数据一起可视化,作为诊断过拟合的手段。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def train_and_view_model(degree): model = make_pipeline(PolynomialFeatures(degree), LinearRegression()) model.fit(X_train, y_train) X_plot = np.linspace(-3, 3, 100).reshape(-1, 1) y_pred = model.predict(X_plot) plt.scatter(X_train, y_train, color='blue', label='训练数据') plt.scatter(X_test, y_test, color='red', label='测试数据') plt.plot(X_plot, y_pred, color='green', label=f'多项式次数 {degree}') plt.legend() plt.title(f'多项式回归(次数 {degree})') plt.show() train_error = mean_squared_error(y_train, model.predict(X_train)) test_error = mean_squared_error(y_test, model.predict(X_test)) print(f'次数 {degree}: 训练 MSE = {train_error:.4f}, 测试 MSE = {test_error:.4f}') return train_error, test_error X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) |
让我们调用此函数来训练和可视化一个次数为 10 的多项式回归器。通常,次数越高,多项式曲线可以变得越复杂,因此它可以更紧密地拟合训练数据。因此,非常高的多项式次数可能会增加模型过拟合数据的风险,并且模型(曲线)也会表现出更不可预测的模式,我们很快就会看到。
|
1 2 |
overfit_degree = 10 train_and_view_model(overfit_degree) |
这是模型和数据的可视化结果
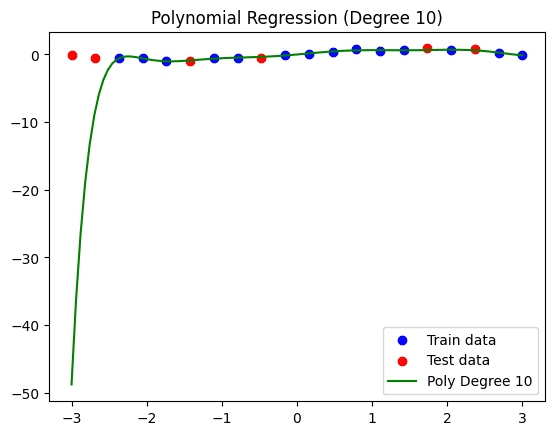
多项式回归模型(次数 = 10)。
请注意,我们之前定义的自定义函数还会打印训练数据和测试数据的错误,从而提供了另一种过拟合诊断方法。在此模型中,训练数据的均方误差(MSE)为 0.0052,而测试数据的误差高得多,为 406.1920,这主要是由于回归曲线左侧看到的剧烈模式。
修复过拟合
要在此示例中修复过拟合,我们将采用一种简单但通常有效的方法:简化模型。对于多项式回归模型,这需要降低曲线的次数。例如,让我们尝试一个次数为 3 的模型
|
1 2 |
reduced_degree = 3 train_and_view_model(reduced_degree) |
可视化结果
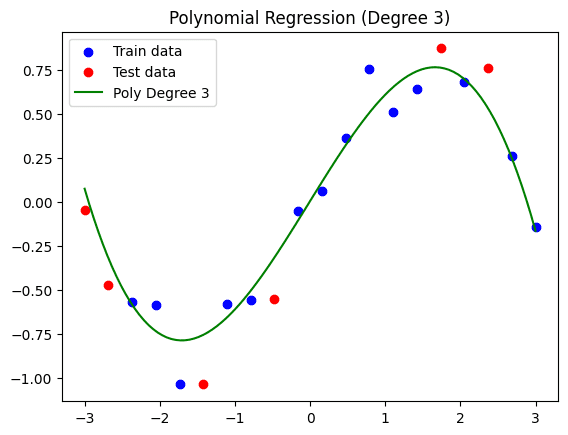
简化的多项式回归模型(次数 = 3)。
正如我们所见,虽然这条曲线不像之前的模型那样能完全紧密地拟合训练集,但我们可能在一定程度上克服了过拟合问题,从而得到了一个可能更好地泛化到未来不同数据的模型。结果的训练 MSE 为 0.0139,而测试 MSE 为 0.0394。这次,虽然误差之间仍然存在差异,但要小得多:这表明该模型更具泛化性。
结论
本文揭示了在 Python 中训练的经典机器学习模型中发现和解决过拟合问题所需的实用步骤。具体来说,我们通过将模型与数据一起可视化、计算产生的错误以及简化模型以使其更具泛化性,来说明了如何发现和修复多项式回归模型中的过拟合。






暂无评论。