差分是一种流行且广泛使用的时间序列数据转换方法。
在本教程中,您将了解如何将差分运算应用于您的 Python 时间序列数据。
完成本教程后,您将了解:
- 关于差分运算,包括滞后差分和差分阶数的配置。
- 如何开发差分运算的手动实现。
- 如何使用内置的 Pandas 差分函数。
通过我的新书 Python 时间序列预测入门 开启您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。

如何使用 Python 差分时间序列数据集
图片由 Marcus 提供,保留部分权利。
为何对时间序列数据进行差分?
差分是一种转换时间序列数据集的方法。
它可以用于消除序列对时间的依赖,即所谓的时序依赖。这包括趋势和季节性等结构。
差分可以通过消除时间序列水平的变化来帮助稳定时间序列的均值,从而消除(或减少)趋势和季节性。
— 第 215 页,《预测:原理与实践》
差分是通过将当前观测值减去前一个观测值来执行的。
|
1 |
difference(t) = observation(t) - observation(t-1) |
这样,就可以计算出一系列差值。
滞后差分
连续观测值之间的差值称为滞后 1 差分。
滞后差分可以根据特定的时序结构进行调整。
对于具有季节性成分的时间序列,滞后可能等于季节性的周期(宽度)。
差分阶数
在进行差分运算后,仍然可能存在时序结构,例如非线性趋势的情况。
因此,可以重复进行差分过程,直到消除所有时序依赖。
进行差分的次数称为差分阶数。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
洗发水销售数据集
此数据集描述了三年期间每月洗发水销售数量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) series.plot() pyplot.show() |
运行该示例将创建图表,显示数据中存在明显的线性趋势。
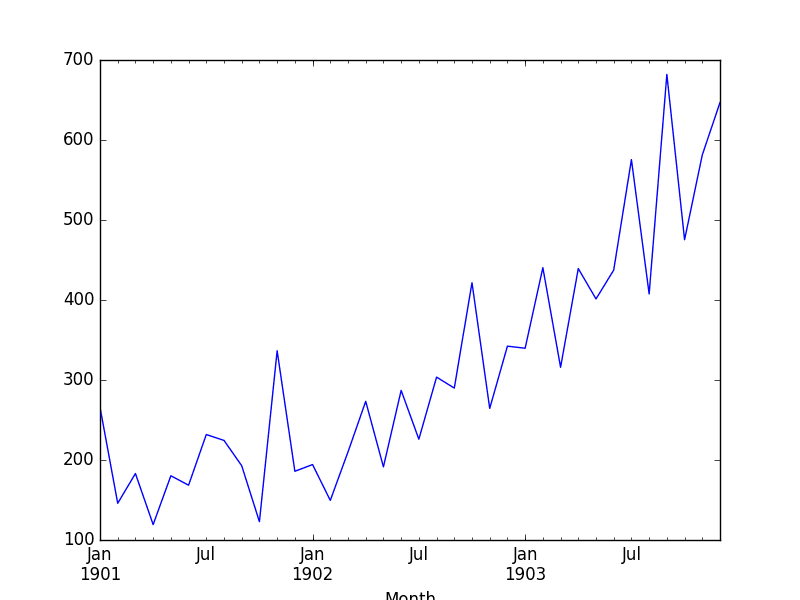
洗发水销售数据集图
手动差分
我们可以手动对数据集进行差分。
这涉及到开发一个新函数来创建差分数据集。该函数将遍历提供的序列,并以指定的间隔或滞后来计算差分值。
下面名为 difference() 的函数实现了这一过程。
|
1 2 3 4 5 6 7 |
# 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) |
我们可以看到,该函数会谨慎地从指定间隔之后开始生成差分数据集,以确保能够实际计算出差分值。定义了一个默认的间隔或滞后值为 1。这是一个合理的默认值。
进一步的改进是还可以指定差分的阶数或次数。
下面的示例将手动 difference() 函数应用于洗发水销售数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from pandas import read_csv from pandas import datetime from pandas import Series from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) X = series.values diff = difference(X) pyplot.plot(diff) pyplot.show() |
运行该示例将创建差分数据集并绘制结果。
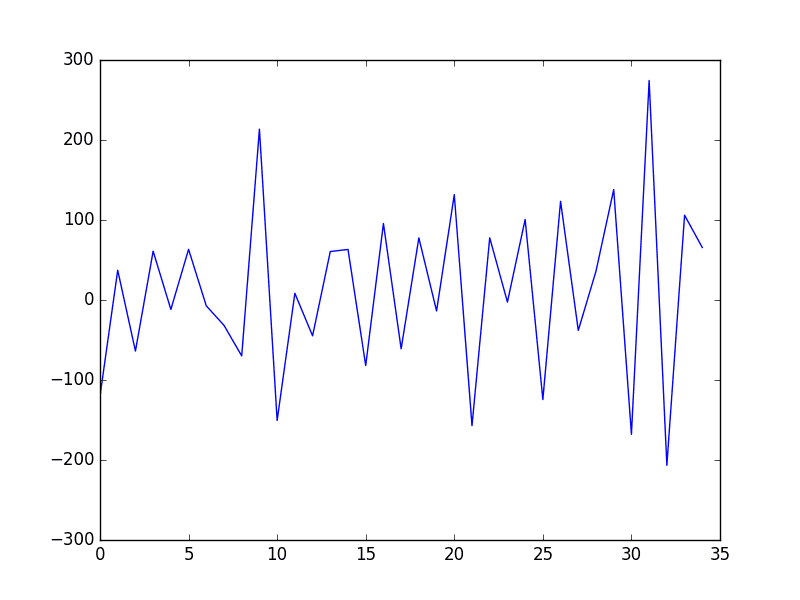
手动差分的洗发水销售数据集
自动差分
Pandas 库提供了一个函数来自动计算数据集的差分。
这个 diff() 函数在 Series 和 DataFrame 对象上都可用。
与上一节中手动定义的差分函数一样,它接受一个参数来指定间隔或滞后,在本例中称为 periods。
下面的示例演示了如何在 Pandas Series 对象上使用内置的差分函数。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) diff = series.diff() pyplot.plot(diff) pyplot.show() |
与上一节一样,运行该示例将绘制差分数据集。
使用 Pandas 函数的一个好处是,除了代码量更少之外,它还能保留差分序列的日期时间信息。
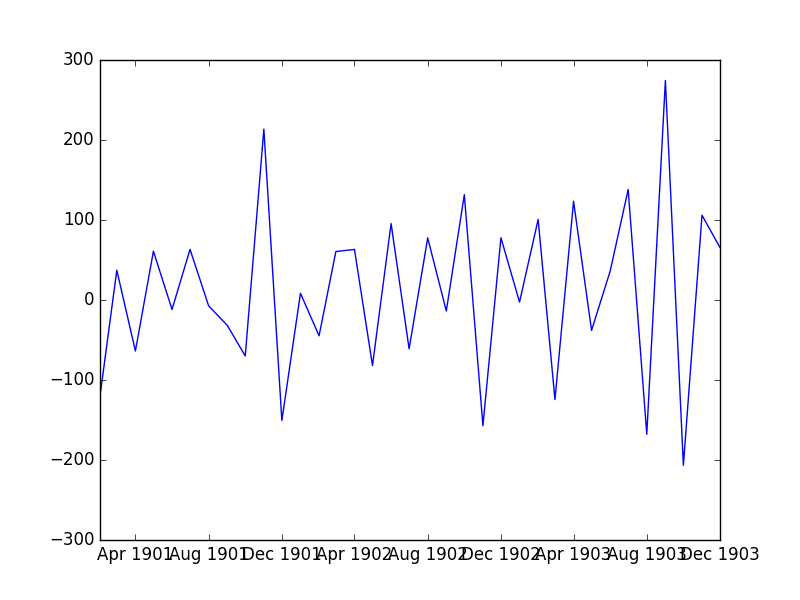
自动差分的洗发水销售数据集
总结
在本教程中,您了解了如何使用 Python 将差分运算应用于时间序列数据。
具体来说,你学到了:
- 关于差分运算,包括滞后和阶数的配置。
- 如何手动实现差分转换。
- 如何使用 Pandas 的内置差分转换实现。
您对差分或本文有任何疑问吗?
请在下面的评论中提出您的问题。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






你好,这是一项近期关于时间序列的工作,它为时间序列提供了一种符号表示。
https://arxiv.org/ftp/arxiv/papers/1611/1611.01698.pdf
感谢分享。
有个问题。如果差值为负数怎么办?
有些差值为正,有些为负。
您好,将负差值设为零的最 Pythonic 方法是什么?例如,我有一些 t+1 的预订和一个预测。
我的方法是先让它工作,然后再让它变得可读。
差分函数是否只用于消除趋势和季节性等结构?
或者它们也可以用于从数据集中构建趋势特征?
有哪些其他技术可以以建设性的方式使用趋势和季节性进行时间序列预测?
您可以使用转换后的变量和提取的结构作为特征,但要检查它们是否能提高模型的技能。
请参阅这篇关于时间序列预测特征工程的文章。
https://machinelearning.org.cn/basic-feature-engineering-time-series-data-python/
感谢您发布这些文章,Brownlee 博士!我喜欢海滩的照片。
谢谢你,Chris。
您好,我经常登录您的新内容“如何使用 Python 对时间序列数据集进行差分 - 机器学习精通”。您的幽默风格很棒,继续保持!您也可以看看我们关于代理列表的网站。
谢谢。
感谢您提供有价值的见解。您能解释一下如何进行第三次或第二次差分吗?
您将差分运算应用于已差分的序列。
对于“value = int(dataset[i])-int(dataset[i-interval])”
为什么显示“TypeError: only length-1 arrays can be converted to Python scalars”
提前感谢!
也许可以确保您已复制了示例中的所有代码?
Jason 您好,感谢您的发布,但我很好奇在使用 diff() 函数后如何处理 NAs?我猜数据应该被删除?还是应该进行插补?
已删除。
我尝试运行您的代码,但收到了这个消息
(data_string, format))
ValueError: 时间数据“190Sales of shampoo over a three year period”与格式“%Y-%m”不匹配
提前感谢!
看起来您可能没有删除文件页脚或以其他格式下载数据。
这是数据文件的直接链接,可供使用。
https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
您是对仅输出数据进行差分,还是也对具有时间依赖性的特征进行差分?
输入和输出都包括。
在进行了残差预测后,如何进行差分反转以恢复包含被差分掉的趋势和季节性的预测?
好问题,我在本文中展示了如何做到。
https://machinelearning.org.cn/remove-trends-seasonality-difference-transform-python/
复制粘贴?
https://www.m-asim.com/2018/10/12/how-to-difference-a-time-series-dataset-with-python/
顺便说一句,感谢您提供如此精彩的内容!
这很遗憾。我会让他把它删除。谷歌也会严厉处罚他。
这样做,我的第一个观测值将没有值,我的意思是 Yt-Yt-1 将是我的第一个值,我将少一个观测值?
是的。
如何进行差分反转?
将值加回来。
如何做到这一点?
本教程中有一个关于差分和逆差分的示例。
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
Jason 您好!一如既往的精彩教程。
我需要知道,如果数据是通过一阶差分得到的,如何获得未见数据的预测值?
详情
我正在进行单变量 ARIMA 预测,每天三次。数据不均匀,因此以每小时的速率通过前向填充进行了插值。我使用了一阶差分进行了预测。为了比较测试数据和预测,我将预测和测试数据进行了反转(积分)。
现在的问题是,当我没有测试数据但有未见数据的预测时,我该怎么做?如何将预测值还原为正常值,然后还原不同的预测值?
ARIMA 会通过 d 参数为您处理差分和逆差分。
否则,您可以手动进行,这里有代码可以实现:
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
能否请您告诉我如何在图中提取预测值?我得到了预测值,但无法使用 ARIMA 模型在 Python 中提取预测值。
predictions_ARIMA_diff=pd.Series(results_ARIMA.fittedvalues, copy=True)
print(predictions_ARIMA_diff.head())
predictions_ARIMA_diff_cumsum=predictions_ARIMA_diff.cumsum()
print(predictions_ARIMA_diff_cumsum.head())
predictions_ARIMA_log=pd.Series(ts_log[0],index=ts_log.index)
predictions_ARIMA_log=predictions_ARIMA_log.add(predictions_ARIMA_diff_cumsum, fill_value=0)
predictions_ARIMA_log.head()
#接下来 - 对上面的序列取指数(反对数),这将是预测值?—?时间序列预测模型。
##现在将预测值与原始值一起绘制。
#计算 RMSE
predictions_ARIMA=np.exp(predictions_ARIMA_log)
plt.plot(ts)
plt.plot(predictions_ARIMA)
plt.title(‘RMSE: %.4f’% np.sqrt(sum((predictions_ARIMA-ts)**2)/len(ts)))
#未来预测
#预测 5 年。我们有 144 个数据点 + 未来 5 年的 60 个数据点。即预测 204 个数据点。
results_ARIMA.plot_predict(1,204)
您可以使用 matplotlib 绘制预测,例如 plot() 函数。
嗨,Jason,
在方程中,是否可以进行差分的同时加入变量(因变量或自变量)的滞后?
谢谢
当然可以。
关于时间序列的精彩 Python 教程。
谢谢!很高兴对您有帮助。
无法运行
# 创建差分序列
def difference(dataset, interval=1)
diff = list()
for i in range(interval, len(dataset))
value = dataset[i] – dataset[i – interval]
diff.append(value)
return Series(diff)
错误发生在
value = dataset[i] – dataset[i – interval]
TypeError: unsupported operand type(s) for -: ‘str’ and ‘str’
很抱歉听到这个消息,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
刚刚读了错误信息。显然
dataset是一个字符串数组,而它应该是浮点数/整数。Jason 您好,感谢您提供非常有信息量的教程。我是一名博士生,我正在使用海洋数据的时序列来创建一个多元线性回归模型(statsmodels GLSAR,因为存在残差自相关)。我使用该模型来预测过去(而不是未来)的值,但这些是针对单个数据点而不是连续时间序列。
然而,我使用的因变量不是平稳的(显示季节性),而自变量则显示趋势、季节性和平稳性的混合。
我有几个问题
1) 如果我想消除平稳性,我想我应该使用差分和去除趋势的组合(如果适用),然后创建我的模型。然后我如何将此模型应用于我的预测?是否相同,还是我需要以某种方式添加趋势/差分回去才能使用它进行预测?
2) 我正在使用一个算法来查找 R 平方值最高的自变量组合。机器学习在我的专业领域越来越受欢迎,我想尝试一下。您认为这合适吗?我有 13 年的每日两次数据用于训练。
希望这很清楚,我很乐意回答任何问题。
是的,进行差分以消除趋势,进行季节性差分以消除季节性。就像您在训练集中传播差分一样,您也可以在测试集中传播差分。然后在预测值上进行逆差分以恢复到原始尺度。
我建议测试一系列方法,并使用受控实验来发现最有效的方法。
Jason 您好,感谢您提供这个出色的教程。
我想知道如何对时间序列日期属性进行差分以获得一系列时长?
抱歉,我不明白您的问题。您能详细说明一下吗?
我有一个数据,其中有两个索引,id 和 date。每个 id 都有一个日期序列,我想提取每个 id 的日期之间的差值。
太好了。听起来您需要开发一些自定义代码。
您有什么建议?
开发自定义代码以满足您项目的需求。工程,而不是机器学习。
抱歉,我没有能力为您进行工程。如果这很有挑战性,您可以尝试将您的问题发布到 stackoverflow 或聘请一位工程师?
嘿 Jason,我喜欢您的教程!我想问一下,如果我们进行差分,该如何绘制趋势线?我一直在网上到处找,但找不到方法?
谢谢!
如果您绘制原始数据(在差分之前),您应该能够看到存在的趋势。
如果我使用内置差分 —- diff = series.diff()
我该如何进行逆差分?
此外,是否可以在多元数据中使用内置差分?如何做到?
您可以在这里看到差分和逆差分的示例。
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
在对时间序列进行差分时,‘对数差分’和‘一阶差分’之间的区别是什么?我正在尝试使用 ACF/PACF 和平稳/转换后的数据来估计我的 ARIMA 参数,但我一直遇到这两种‘差分’,而且我无法分辨它们是否可以互换使用。此外,如果存在差异,我们如何在代码中使用 Pandas 进行对数差分?
附注:Jason,您的网站在我的学术生涯中帮助了我,现在也在我作为实习生希望很快获得全职工作的早期职业生涯中帮助了我——我想感谢您所做的一切努力。
我没有听说过这些术语,抱歉。
您可以对数据进行对数处理,您可以对数据进行差分,也可以以不同的阶数同时进行。
嗨,Jason,
感谢您的教程。我有一个问题。差分后,我得到一个平稳序列,我打算通过 ADF 测试来确认。这是我的代码——
from pandas import read_csv
from statsmodels.tsa.stattools import adfuller
series = read_csv(‘D:/Management Books/BSE Index Daily Closing.csv’, header=0, index_col=0, squeeze=True)
X = series.values
diff = series.diff()
X = diff(X)
result = adfuller(X)
print(‘ADF统计量:%f’ % result[0])
print(‘p值:%f’ % result[1])
print(‘Critical Values:’)
for key, value in result[4].items()
print(‘\t%s: %.3f’ % (key, value))
当我运行它时,我收到一个错误,如
TypeError Traceback (most recent call last)
in
4 X = series.values
5 diff = series.diff()
—> 6 X = diff(X)
7 result = adfuller(X)
8 print(‘ADF Statistic: %f’ % result[0])
TypeError: ‘Series’ object is not callable
请告诉我如何纠正错误。
不客气。
也许可以尝试在差分后从序列中提取 numpy 数组?
嗨,Jason,
非常感谢您的帮助。成功了! bingo!!!!
干得好,我很高兴听到这个!
嗨 Jason
我们如何将数值转换回原始尺度,以便能够将预测与实际值进行比较?
您可以调用 inverse_transform(),请参阅此教程了解更多信息
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
嗨,Jason,
我非常喜欢您的教程,它们总是非常清晰。我正在处理时间序列数据(按年份)。刚开始处理单变量时间序列(以百万为单位),有趋势但没有季节性,并应用了ARIMA模型。关于此模型有几个问题。
1. 我在没有进行任何特征工程和缩放的情况下应用了我的模型,因为它是单变量的,并且我得到了预期的预测值。这样正确吗?还是我需要在应用模型之前使用 diff() 函数使数据平稳?
2. 然后,通过调整ARIMA(p,d,q)参数,我根据MAPE指标得到了最终值,例如(1,2,0)。这样正确吗?
在这里,我就可以识别出 p(偏自相关)、d(差分值)的最佳值
和 q(自相关)。
3. 那么 Dicky fuller 检验和滚动平均的目的是什么?
4. 如果第三个参数 q=0,那么它是否可以称为ARIMA模型?
(如果我给 q 任何值,它会要求我使数据平稳。所以我将其设为零)。
5. 我可以使用 df.diff().diff() 吗?如果可以,我能称之为二阶差分吗?这有意义吗?
(这样 p 值才会小于 0.5)
请回答我的问题。期待您的宝贵回复。
(1, 2) ARIMA 中的 I 会进行差分,因此它应该通过找出正确的参数 (p,d,q) 来使数据平稳。如果您不同意拟合结果,您可以随时覆盖它。
(3) Dicky-Fuller 检验用于检查序列是否平稳。滚动平均只是移动平均的另一种说法。
(4) q 是 MA 参数,d=0 表示平稳
(5) 是的,这种情况就是 d=2
非常感谢您的回复。
嗨,Jason,
感谢这个精彩的教程!阅读后我有一个问题:如果通过将当前观测值减去前一个观测值而得到的差分数据具有季节性,那么原始数据是否也具有季节性?
嗨 JK… 以下信息可能有助于阐明
https://machinelearning.org.cn/time-series-seasonality-with-python/
https://machinelearning.org.cn/remove-trends-seasonality-difference-transform-python/
我有一个问题。如果我们拥有的数据是每年的(从 2009 年到 2020 年)。显然我们没有季节性,但根据 ADF 检验,它是非平稳数据。差分会使数据平稳还是没有任何区别?
嗨 SNA…我们建议您尝试差分和不差分,并比较结果。