差分进化是一种用于非线性、不可微连续空间函数全局优化的启发式方法。
差分进化算法属于更广泛的进化计算算法家族。与其他流行的直接搜索方法(如遗传算法和进化策略)类似,差分进化算法从候选解的初始种群开始。这些候选解通过引入种群变异并保留能产生较低目标函数值的最优候选解来迭代改进。
差分进化算法相较于上述流行方法具有优势,因为它能够处理非线性、不可微的多维目标函数,同时只需要很少的控制参数来引导最小化过程。这些特性使得该算法更易于使用且更实用。
在本教程中,您将了解用于全局优化的差分进化算法。
完成本教程后,您将了解:
- 差分进化是一种用于非线性、不可微连续空间函数全局优化的启发式方法。
- 如何从零开始在 Python 中实现差分进化算法。
- 如何将差分进化算法应用于实值二维目标函数。
通过我的新书 机器学习优化 开启您的项目,书中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。- 2021年6月:修复了代码中的变异操作,使其与描述匹配。
教程概述
本教程分为三个部分;它们是:
- 差分进化
- 差分进化算法(从零开始)
- 球函数上的差分进化算法
差分进化
差分进化是一种用于非线性、不可微连续空间函数全局优化的启发式方法。
为了使最小化算法被认为实用,它需要满足五个不同的要求:
(1) 能够处理不可微、非线性、多模态成本函数。
(2) 可并行化,以应对计算密集型成本函数。
(3) 易于使用,即很少的控制变量来引导最小化。这些变量应
且稳定且易于选择。
(4) 良好的收敛性,即在
连续独立试验中一致收敛到全局最小值。
— A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces, 1997.
差分进化算法的优势在于它被设计用于满足上述所有要求。
差分进化 (DE) 可以说是近年来最强大、最通用的连续参数空间进化优化器之一。
— Recent advances in differential evolution: An updated survey, 2016.
该算法首先随机初始化实值决策向量(也称为基因组或染色体)种群。这些代表多维优化问题的候选解。
在每次迭代中,算法会引入种群变异以生成新的候选解。变异过程将两个种群向量的加权差添加到第三个向量上,生成一个变异向量。变异向量的参数在称为交叉的过程中与另一个预定向量(目标向量)的参数混合,目的是增加扰动参数向量的多样性。由此产生的向量称为试探向量。
DE 通过将两个种群向量的加权差添加到第三个向量来生成新的参数向量。称此操作为变异。
为了增加扰动参数向量的多样性,引入了交叉。
— A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces, 1997.
这些变异根据变异策略生成,该策略遵循一般的命名约定 DE/x/y/z,其中 DE 代表差分进化,x 表示要变异的向量,y 表示用于 x 变异的差向量数量,z 表示所使用的交叉类型。例如,流行的策略
- DE/rand/1/bin
- DE/best/2/bin
指定向量 x 可以从种群中随机选择 (rand),或者选择成本最低的向量 (best);考虑的差向量数量为 1 或 2;并且交叉根据独立的二项式 (bin) 实验进行。特别是 DE/best/2/bin 策略,在种群规模足够大的情况下,对于改善种群多样性似乎非常有益。
如果种群向量数量 NP 足够大,使用两个差向量似乎可以改善种群多样性。
— A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces, 1997.
最后的选择操作用试探向量(其后代)替换目标向量(其父代),前提是试探向量产生更低的目标函数值。因此,更优的后代现在成为新生成的种群的成员,并随后参与进一步种群成员的变异。这些迭代继续进行,直到达到终止标准。
迭代将继续,直到满足终止条件(例如,最大函数评估次数耗尽)。
— Recent advances in differential evolution: An updated survey, 2016.
差分进化算法需要很少的参数即可运行,即种群大小 NP、一个 [0, 2] 范围内的实数且恒定的尺度因子 F,它在变异过程中为差分变化加权,以及一个通过实验确定的交叉率 CR ∈ [0, 1]。这使得该算法易于使用且更实用。
此外,经典 DE 只需要很少的控制参数(精确地说,3 个:尺度因子、交叉率和种群大小)——这一特性使其对实践者来说易于使用。
— Recent advances in differential evolution: An updated survey, 2016.
上述经典差分进化算法已进一步发展出各种变体,
您可以在 Recent advances in differential evolution – An updated survey, 2016 中阅读。
既然我们已经熟悉了差分进化算法,那么我们就来看看如何从零开始实现它。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
差分进化算法(从零开始)
在本节中,我们将探讨如何从零开始实现差分进化算法。
差分进化算法首先生成候选解的初始种群。为此,我们将使用 rand() 函数生成一个数组,其中包含从 [0, 1) 上的均匀分布采样的随机值。
然后,我们将对这些值进行缩放,以将它们的分布范围更改为 (下界, 上界),其中界限以二维数组的形式指定,每个维度对应一个输入变量。
|
1 2 3 |
... # 随机初始化指定边界内的候选解种群 pop = bounds[:, 0] + (rand(pop_size, len(bounds)) * (bounds[:, 1] - bounds[:, 0])) |
目标函数也将在此边界范围内进行评估。因此,可以选择的目标函数和每个输入变量的边界可以定义如下:
|
1 2 3 4 5 6 |
# 定义目标函数 def obj(x): return 0 # 定义下界和上界 bounds = asarray([-5.0, 5.0]) |
我们可以通过将候选解的初始种群作为输入参数传递给目标函数来评估它。
|
1 2 3 |
... # 评估候选解的初始种群 obj_all = [obj(ind) for ind in pop] |
随着种群演变并收敛到最优解,我们将用更好的值替换 obj_all 中的值。
然后,我们可以遍历算法预定的迭代次数,例如 100 或 1,000 次(由参数 iter 指定),以及所有候选解。
|
1 2 3 4 5 6 |
... # 运行算法迭代 for i in range(iter): # 遍历所有候选解 for j in range(pop_size): ... |
算法迭代的第一步是执行变异过程。为此,从种群中随机选择三个非当前候选解 a、b 和 c,并通过计算:a + F * (b – c) 来生成变异向量。请记住,F ∈ [0, 2] 表示变异尺度因子。
|
1 2 3 4 |
... # 选择三个非当前候选解 a、b 和 c candidates = [candidate for candidate in range(pop_size) if candidate != j] a, b, c = pop[choice(candidates, 3, replace=False)] |
变异过程由 mutation 函数执行,我们将 a、b、c 和 F 作为输入参数传递给它。
|
1 2 3 4 5 6 7 |
# 定义变异操作 def mutation(x, F): return x[0] + F * (x[1] - x[2]) ... # 执行变异 mutated = mutation([a, b, c], F) ... |
由于我们在有界值的范围内操作,我们需要检查新变异的向量是否也位于指定的边界内,如果不是,则根据需要将其值裁剪到上限或下限。此检查由 check_bounds 函数执行。
|
1 2 3 4 |
# 定义边界检查操作 def check_bounds(mutated, bounds): mutated_bound = [clip(mutated[i], bounds[i, 0], bounds[i, 1]) for i in range(len(bounds))] return mutated_bound |
下一步执行交叉,其中当前(目标)向量的特定值被替换为变异向量中的相应值,以创建试探向量。替换哪些值由为每个输入变量生成的统一随机值是否小于交叉率决定。如果是,则将变异向量中的相应值复制到目标向量。
交叉过程由 crossover() 函数实现,该函数接收变异向量和目标向量,以及交叉率 cr ∈ [0, 1] 和输入变量的数量作为输入。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 定义交叉操作 def crossover(mutated, target, dims, cr): # 为每个维度生成一个统一的随机值 p = rand(dims) # 通过二项式交叉生成试探向量 trial = [mutated[i] if p[i] < cr else target[i] for i in range(dims)] return trial ... # 执行交叉 trial = crossover(mutated, pop[j], len(bounds), cr) ... |
最后的选择步骤用试探向量替换目标向量,前提是试探向量产生更低的目标函数值。为此,我们评估这两个向量的目标函数,然后执行选择,如果试探向量是最优的,则将新的目标函数值存储在 obj_all 中。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 计算目标向量的目标函数值 obj_target = obj(pop[j]) # 计算试探向量的目标函数值 obj_trial = obj(trial) # 执行选择 if obj_trial < obj_target: # 用试探向量替换目标向量 pop[j] = trial # 存储新的目标函数值 obj_all[j] = obj_trial |
我们可以将所有步骤整合到一个 differential_evolution() 函数中,该函数接收种群大小、每个输入变量的边界、总迭代次数、变异尺度因子和交叉率作为输入参数,并返回找到的最佳解决方案及其评估值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
def differential_evolution(pop_size, bounds, iter, F, cr): # 随机初始化指定边界内的候选解种群 pop = bounds[:, 0] + (rand(pop_size, len(bounds)) * (bounds[:, 1] - bounds[:, 0])) # 评估候选解的初始种群 obj_all = [obj(ind) for ind in pop] # 查找初始种群中表现最佳的向量 best_vector = pop[argmin(obj_all)] best_obj = min(obj_all) prev_obj = best_obj # 运行算法迭代 for i in range(iter): # 遍历所有候选解 for j in range(pop_size): # 选择三个非当前候选解 a、b 和 c candidates = [candidate for candidate in range(pop_size) if candidate != j] a, b, c = pop[choice(candidates, 3, replace=False)] # 执行变异 mutated = mutation([a, b, c], F) # 检查变异后的下界和上界是否得以保留 mutated = check_bounds(mutated, bounds) # 执行交叉 trial = crossover(mutated, pop[j], len(bounds), cr) # 计算目标向量的目标函数值 obj_target = obj(pop[j]) # 计算试探向量的目标函数值 obj_trial = obj(trial) # 执行选择 if obj_trial < obj_target: # 用试探向量替换目标向量 pop[j] = trial # 存储新的目标函数值 obj_all[j] = obj_trial # 查找每次迭代中表现最佳的向量 best_obj = min(obj_all) # 存储最低的目标函数值 if best_obj < prev_obj: best_vector = pop[argmin(obj_all)] prev_obj = best_obj # 报告每次迭代的进度 print('Iteration: %d f([%s]) = %.5f' % (i, around(best_vector, decimals=5), best_obj)) return [best_vector, best_obj] |
既然我们已经实现了差分进化算法,让我们来看看如何使用它来优化目标函数。
球函数上的差分进化算法
在本节中,我们将把差分进化算法应用于一个目标函数。
我们将使用一个简单的二维球函数,指定在 [-5, 5] 的边界内。球函数是连续的、凸的和单峰的,其特征是在 f(0, 0) = 0.0 处有一个全局最小值。
|
1 2 3 |
# 定义目标函数 def obj(x): return x[0]**2.0 + x[1]**2.0 |
我们将使用基于 DE/rand/1/bin 策略的差分进化算法来最小化此目标函数。
为此,我们必须为算法参数定义值,特别是种群大小、迭代次数、变异尺度因子和交叉率。我们将这些值经验性地设置为 10、100、0.5 和 0.7。
|
1 2 3 4 5 6 7 8 9 |
... # 定义种群大小 pop_size = 10 # 定义迭代次数 iter = 100 # 定义变异尺度因子 F = 0.5 # 定义重组交叉率 cr = 0.7 |
我们还定义了每个输入变量的边界。
|
1 2 3 |
... # 定义每个维度的下界和上界 bounds = asarray([(-5.0, 5.0), (-5.0, 5.0)]) |
接下来,我们执行搜索并报告结果。
|
1 2 3 |
... # 执行差分进化 solution = differential_evolution(pop_size, bounds, iter, F, cr) |
将所有这些结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
# 二维球目标函数的差分进化搜索 from numpy.random import rand from numpy.random import choice from numpy import asarray 从 numpy 导入 clip from numpy import argmin from numpy import min from numpy import around # 定义目标函数 def obj(x): return x[0]**2.0 + x[1]**2.0 # 定义变异操作 def mutation(x, F): return x[0] + F * (x[1] - x[2]) # 定义边界检查操作 def check_bounds(mutated, bounds): mutated_bound = [clip(mutated[i], bounds[i, 0], bounds[i, 1]) for i in range(len(bounds))] return mutated_bound # 定义交叉操作 def crossover(mutated, target, dims, cr): # 为每个维度生成一个统一的随机值 p = rand(dims) # 通过二项式交叉生成试探向量 trial = [mutated[i] if p[i] < cr else target[i] for i in range(dims)] return trial def differential_evolution(pop_size, bounds, iter, F, cr): # 随机初始化指定边界内的候选解种群 pop = bounds[:, 0] + (rand(pop_size, len(bounds)) * (bounds[:, 1] - bounds[:, 0])) # 评估候选解的初始种群 obj_all = [obj(ind) for ind in pop] # 查找初始种群中表现最佳的向量 best_vector = pop[argmin(obj_all)] best_obj = min(obj_all) prev_obj = best_obj # 运行算法迭代 for i in range(iter): # 遍历所有候选解 for j in range(pop_size): # 选择三个非当前候选解 a、b 和 c candidates = [candidate for candidate in range(pop_size) if candidate != j] a, b, c = pop[choice(candidates, 3, replace=False)] # 执行变异 mutated = mutation([a, b, c], F) # 检查变异后的下界和上界是否得以保留 mutated = check_bounds(mutated, bounds) # 执行交叉 trial = crossover(mutated, pop[j], len(bounds), cr) # 计算目标向量的目标函数值 obj_target = obj(pop[j]) # 计算试探向量的目标函数值 obj_trial = obj(trial) # 执行选择 if obj_trial < obj_target: # 用试探向量替换目标向量 pop[j] = trial # 存储新的目标函数值 obj_all[j] = obj_trial # 查找每次迭代中表现最佳的向量 best_obj = min(obj_all) # 存储最低的目标函数值 if best_obj < prev_obj: best_vector = pop[argmin(obj_all)] prev_obj = best_obj # 报告每次迭代的进度 print('Iteration: %d f([%s]) = %.5f' % (i, around(best_vector, decimals=5), best_obj)) return [best_vector, best_obj] # 定义种群大小 pop_size = 10 # 定义每个维度的下界和上界 bounds = asarray([(-5.0, 5.0), (-5.0, 5.0)]) # 定义迭代次数 iter = 100 # 定义变异尺度因子 F = 0.5 # 定义重组交叉率 cr = 0.7 # 执行差分进化 solution = differential_evolution(pop_size, bounds, iter, F, cr) print('\nSolution: f([%s]) = %.5f' % (around(solution[0], decimals=5), solution[1])) |
运行示例会报告搜索进度,包括迭代次数以及每次检测到改进时的目标函数响应。
在搜索结束时,找到最佳解决方案并报告其评估结果。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到算法在约 33 次改进(100 次迭代中)后收敛到非常接近 f(0.0, 0.0) = 0.0 的值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
迭代:1 f([[ 0.89709 -0.45082]]) = 1.00800 迭代:2 f([[-0.5382 0.29676]]) = 0.37773 迭代:3 f([[ 0.41884 -0.21613]]) = 0.22214 迭代:4 f([[0.34737 0.29676]]) = 0.20873 迭代:5 f([[ 0.20692 -0.1747 ]]) = 0.07334 迭代:7 f([[-0.23154 -0.00557]]) = 0.05364 迭代:8 f([[ 0.11956 -0.02632]]) = 0.01499 迭代:11 f([[ 0.01535 -0.02632]]) = 0.00093 迭代:15 f([[0.01918 0.01603]]) = 0.00062 迭代:18 f([[0.01706 0.00775]]) = 0.00035 迭代:20 f([[0.00467 0.01275]]) = 0.00018 迭代:21 f([[ 0.00288 -0.00175]]) = 0.00001 迭代:27 f([[ 0.00286 -0.00175]]) = 0.00001 迭代:30 f([[-0.00059 0.00044]]) = 0.00000 迭代:37 f([[-1.5e-04 8.0e-05]]) = 0.00000 迭代:41 f([[-1.e-04 -8.e-05]]) = 0.00000 迭代:43 f([[-4.e-05 6.e-05]]) = 0.00000 迭代:48 f([[-2.e-05 6.e-05]]) = 0.00000 迭代:49 f([[-6.e-05 0.e+00]]) = 0.00000 迭代:50 f([[-4.e-05 1.e-05]]) = 0.00000 迭代:51 f([[1.e-05 1.e-05]]) = 0.00000 迭代:55 f([[1.e-05 0.e+00]]) = 0.00000 迭代:64 f([[-0. -0.]]) = 0.00000 迭代:68 f([[ 0. -0.]]) = 0.00000 迭代:72 f([[-0. 0.]]) = 0.00000 迭代:77 f([[-0. 0.]]) = 0.00000 迭代:79 f([[0. 0.]]) = 0.00000 迭代:84 f([[ 0. -0.]]) = 0.00000 迭代:86 f([[-0. -0.]]) = 0.00000 迭代:87 f([[-0. -0.]]) = 0.00000 迭代:95 f([[-0. 0.]]) = 0.00000 迭代:98 f([[-0. 0.]]) = 0.00000 解决方案:f([[-0. 0.]]) = 0.00000 |
通过稍微修改 differential_evolution() 函数来跟踪目标函数值并将其作为列表 obj_iter 返回,我们可以绘制每次改进时返回的目标函数值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
def differential_evolution(pop_size, bounds, iter, F, cr): # 随机初始化指定边界内的候选解种群 pop = bounds[:, 0] + (rand(pop_size, len(bounds)) * (bounds[:, 1] - bounds[:, 0])) # 评估候选解的初始种群 obj_all = [obj(ind) for ind in pop] # 查找初始种群中表现最佳的向量 best_vector = pop[argmin(obj_all)] best_obj = min(obj_all) prev_obj = best_obj # 初始化用于存储每次迭代目标函数值的列表 obj_iter = list() # 运行算法迭代 for i in range(iter): # 遍历所有候选解 for j in range(pop_size): # 选择三个非当前候选解 a、b 和 c candidates = [candidate for candidate in range(pop_size) if candidate != j] a, b, c = pop[choice(candidates, 3, replace=False)] # 执行变异 mutated = mutation([a, b, c], F) # 检查变异后的下界和上界是否得以保留 mutated = check_bounds(mutated, bounds) # 执行交叉 trial = crossover(mutated, pop[j], len(bounds), cr) # 计算目标向量的目标函数值 obj_target = obj(pop[j]) # 计算试探向量的目标函数值 obj_trial = obj(trial) # 执行选择 if obj_trial < obj_target: # 用试探向量替换目标向量 pop[j] = trial # 存储新的目标函数值 obj_all[j] = obj_trial # 查找每次迭代中表现最佳的向量 best_obj = min(obj_all) # 存储最低的目标函数值 if best_obj < prev_obj: best_vector = pop[argmin(obj_all)] prev_obj = best_obj obj_iter.append(best_obj) # 报告每次迭代的进度 print('Iteration: %d f([%s]) = %.5f' % (i, around(best_vector, decimals=5), best_obj)) return [best_vector, best_obj, obj_iter] |
然后,我们可以创建这些目标函数值的折线图,以查看搜索过程中每次改进的相对变化。
|
1 2 3 4 5 6 7 8 9 10 |
from matplotlib import pyplot ... # 执行差分进化 solution = differential_evolution(pop_size, bounds, iter, F, cr) ... # 最佳目标函数值的折线图 pyplot.plot(solution[2], '.-') pyplot.xlabel('Improvement Number') pyplot.ylabel('Evaluation f(x)') pyplot.show() |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
# 二维球目标函数的差分进化搜索 from numpy.random import rand from numpy.random import choice from numpy import asarray 从 numpy 导入 clip from numpy import argmin from numpy import min from numpy import around from matplotlib import pyplot # 定义目标函数 def obj(x): return x[0]**2.0 + x[1]**2.0 # 定义变异操作 def mutation(x, F): return x[0] + F * (x[1] - x[2]) # 定义边界检查操作 def check_bounds(mutated, bounds): mutated_bound = [clip(mutated[i], bounds[i, 0], bounds[i, 1]) for i in range(len(bounds))] return mutated_bound # 定义交叉操作 def crossover(mutated, target, dims, cr): # 为每个维度生成一个统一的随机值 p = rand(dims) # 通过二项式交叉生成试探向量 trial = [mutated[i] if p[i] < cr else target[i] for i in range(dims)] return trial def differential_evolution(pop_size, bounds, iter, F, cr): # 随机初始化指定边界内的候选解种群 pop = bounds[:, 0] + (rand(pop_size, len(bounds)) * (bounds[:, 1] - bounds[:, 0])) # 评估候选解的初始种群 obj_all = [obj(ind) for ind in pop] # 查找初始种群中表现最佳的向量 best_vector = pop[argmin(obj_all)] best_obj = min(obj_all) prev_obj = best_obj # 初始化用于存储每次迭代目标函数值的列表 obj_iter = list() # 运行算法迭代 for i in range(iter): # 遍历所有候选解 for j in range(pop_size): # 选择三个非当前候选解 a、b 和 c candidates = [candidate for candidate in range(pop_size) if candidate != j] a, b, c = pop[choice(candidates, 3, replace=False)] # 执行变异 mutated = mutation([a, b, c], F) # 检查变异后的下界和上界是否得以保留 mutated = check_bounds(mutated, bounds) # 执行交叉 trial = crossover(mutated, pop[j], len(bounds), cr) # 计算目标向量的目标函数值 obj_target = obj(pop[j]) # 计算试探向量的目标函数值 obj_trial = obj(trial) # 执行选择 if obj_trial < obj_target: # 用试探向量替换目标向量 pop[j] = trial # 存储新的目标函数值 obj_all[j] = obj_trial # 查找每次迭代中表现最佳的向量 best_obj = min(obj_all) # 存储最低的目标函数值 if best_obj < prev_obj: best_vector = pop[argmin(obj_all)] prev_obj = best_obj obj_iter.append(best_obj) # 报告每次迭代的进度 print('Iteration: %d f([%s]) = %.5f' % (i, around(best_vector, decimals=5), best_obj)) return [best_vector, best_obj, obj_iter] # 定义种群大小 pop_size = 10 # 定义每个维度的下界和上界 bounds = asarray([(-5.0, 5.0), (-5.0, 5.0)]) # 定义迭代次数 iter = 100 # 定义变异尺度因子 F = 0.5 # 定义重组交叉率 cr = 0.7 # 执行差分进化 solution = differential_evolution(pop_size, bounds, iter, F, cr) print('\nSolution: f([%s]) = %.5f' % (around(solution[0], decimals=5), solution[1])) # 最佳目标函数值的折线图 pyplot.plot(solution[2], '.-') pyplot.xlabel('Improvement Number') pyplot.ylabel('Evaluation f(x)') pyplot.show() |
运行此示例将创建一个线图。
折线图显示了每次改进的目标函数评估值,初期变化较大,搜索后期变化非常小,因为算法已收敛到最优值。
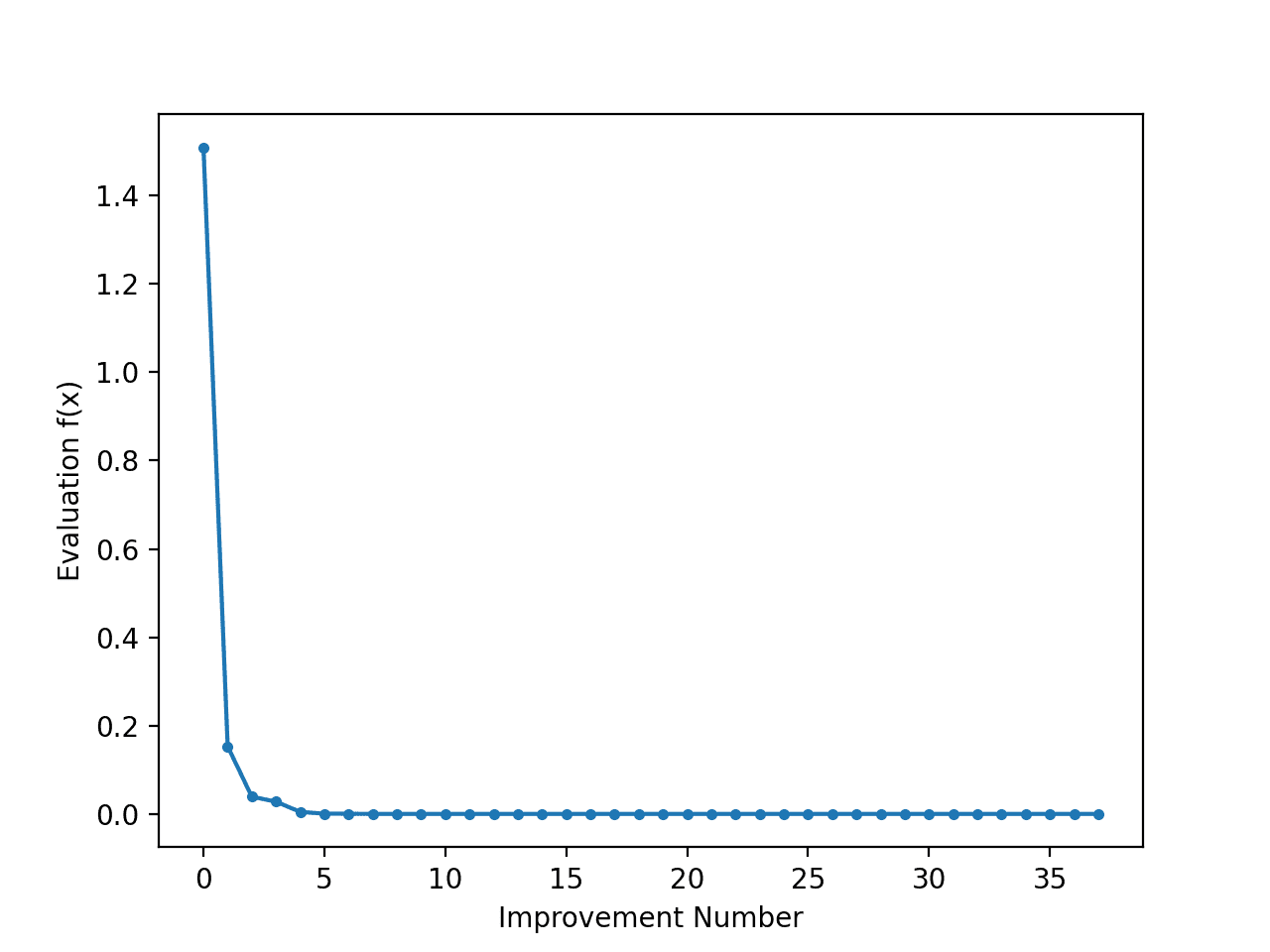
差分进化搜索过程中每次改进的目标函数评估值折线图
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces, 1997.
- Recent advances in differential evolution: An updated survey, 2016.
书籍
- 优化算法, 2019.
文章
总结
在本教程中,您了解了差分进化算法。
具体来说,你学到了:
- 差分进化是一种用于非线性、不可微连续空间函数全局优化的启发式方法。
- 如何从零开始在 Python 中实现差分进化算法。
- 如何将差分进化算法应用于实值二维目标函数。







你好,我正在收到一个关于 pyplot.plot(solution[2], ‘.-‘) 的 list index out of range 错误。
有什么想法吗?
很抱歉听到这个消息,也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
感谢教程。我看到了差分进化和遗传算法在全局优化方面的巨大潜力!
我没有太多时间玩这个差分进化代码教程,但我已经玩过 scipy API:differential_evolution()。所以我认为这个教程只是在讲如何构建自己的(从零开始的)算法。对吗?
无论如何,我更关注你之前的:遗传算法(从零开始):https://machinelearning.org.cn/simple-genetic-algorithm-from-scratch-in-python/
所以,我看到的第一个问题是,这两个(遗传算法和差分进化代码)在过程上非常非常相似,如果不是完全相同的话。
我唯一看到的是,遗传算法中的变异过程是在变量的二进制版本上执行的,而在这里的 DE 中则不是。我还看到了 DE/x/y/z 的策略模式……我说对了吗?
第二个问题是由于这个过程(遗传 & 差分进化)都专注于获得全局最优……而且速度很快、稳定且高效地收敛到全局最优……以至于我认为有人必须利用它们来“替换”反向传播或随机梯度下降,以获得更新 ML/DL 模型权重的新选择,我说对了吗?
谢谢
新解的创建方式和使用的表示法是主要区别。
是的,但通常来说,反向传播/SGD 是神经网络的更好解决方案。
你好,
文本说变异是 a + F * (b – c),但代码写的是
def mutation(x, F)
return x[0] + F * x[1] – x[2]
祝好
谢谢。
尊敬的Jason博士,
另一种方法是转到“完整代码”。在代码的顶部,有一个看起来像“”的图标,它会打开纯代码。按 CTRL+A 然后 CTRL+C 复制代码。
然后打开一个 DOS 窗口并输入 python 在 DOS 下运行 python 解释器。
粘贴代码,并在最后一行 pyplot.show() 的末尾按 Enter 键。
我试过了,代码可以正常工作。
或者,运行一个解释器,如“Spyder”,而不是 Idle IDE。
粘贴代码 = Ctrl+V。
它有效。
谢谢你,
悉尼的安东尼。
尊敬的Jason博士,
该图标用于在纯代码和带行号的代码之间切换。
不知道为什么它们在用引号括起来时消失了。
所以,通过点击图标可以在纯代码和带行号的代码之间切换。
谢谢你,
悉尼的Anthony
抱歉,我指的是那个看起来像的图标,它在纯代码和带行号的代码之间切换。它消失了。
谢谢你,
悉尼的Anthony
图标是 gt(大于号)和 lt(小于号)的组合。图标的图像是 lt gt。
出于无法解释的原因,实际的 gt 和 lt 符号没有显示。这些符号的使用看起来是在纯代码和带行号代码之间切换。
谢谢你,
悉尼的Anthony
感谢分享。
尊敬的Jason博士,
在你的教程中,你有一个目标函数
如果我有一组数据,但不知道目标函数怎么办?如何从原始数据中确定目标函数?
谢谢你,
悉尼的Anthony
在机器学习中,目标函数通常是损失函数,例如,最小化模型在训练数据集上进行预测时的损失。
尊敬的Jason博士,
如何提取损失函数以用于此差分进化算法?
谢谢你,
悉尼的Anthony
你说的“提取损失函数”是什么意思?
通常,你在机器学习中定义一个你想最小化的损失函数,通常是模型对训练数据集的误差函数。
尊敬的Jason博士,
我想能够使用 xgboost、keras 的 ML 函数中的损失函数,并将其插入差分进化算法中,以防 xgboost 和 keras 中的 ML 算法的成本函数具有不可微函数。
这就是为什么我想能够从 xgboost 和 keras 中提取成本函数并将其插入差分进化算法中。
谢谢你,
悉尼的Anthony
是的,正如我所说,这是预测值与训练数据集中的预期值之间的损失。
您可能需要编写自定义代码才能将任意优化算法与 GBDT 或神经网络一起使用。
尊敬的Jason博士,
谢谢你的回复。
三种提问方式相同——如果使用 Keras、XGBoost 和 Torch 等软件包,它们有自己的优化技术,就不需要担心使用差分进化了。
* 所以我可以得出结论,当使用 Keras、XGBoost 和 Torch 等机器学习算法时,真的没有必要使用差分进化吗?
* 换句话说,本教程中的差分进化算法以及 https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html 中的算法是针对已知但不可微分的函数吗?
* 换句话说,使用差分进化来处理已知的软件包 Keras、XGBoostr 和 Torch 等是没有意义的。
一直很欣赏你的回答,
谢谢你,
悉尼的Anthony
并非没有意义,但你需要一个充分的理由。每种算法使用的传统方法都是最知名的。
尊敬的Jason博士,
谢谢你的回复。
悉尼的Anthony
不客气。
如果我想同时优化多个输出,该怎么做?
如果你想用 DE 解决多目标优化问题,有几种方法可以做到:(论文)。本质上,引用论文中的话,“*在评估目标函数之前,该方法根据目标的相对重要性为其乘以权重。然后通过对加权目标求和来形成一个新的目标函数。因此,它将多目标转换为单目标。*”
假设我的目标函数是相对的——我能看出 x 比 y 差,但我无法用标量给它们评分——需要进行哪些调整才能使其正常工作?或者是否有其他进化算法我应该尝试?
这很难,但我会试着问自己,为什么我会说 x 比 y 差?如果你能给出逻辑,你就可以得出一个标量度量。
假设你正在学习下棋,你通过让玩家互相玩几局来比较他们。你可以说“X 在 10 场比赛中赢了 Y,所以 X 更好”,但给他们一个标量值是没有意义的——尤其是因为这种排序不一定具有传递性(排序 X > Y、Y > Z、Z > X 是可能的)。每一代你可能都会让整个种群与整个种群进行比赛——在这种方案中,胜利得 1 分,失败得 -1 分。问题是,这在每一代都需要 population_size^2 * k 场比赛。
在现实世界的比赛中,棋手会获得 ELO 评分,这代表了他们获胜可能性的估计。我对此进行了一些实验,但由于不适的基因组会被淘汰,平均 ELO 不断上升,而将其标准化几乎使整个方案变得无用。我还怀疑模拟种群的相对较小的规模也起到了作用。也许这是可能的,但它非常不简单,以至于我怀疑它是否值得。
这个问题也很棘手,因为没有可衡量的目标,所以很难比较不同的实验,也很难评估你的解决方案(除了局部收敛,这可能是“红皇后”问题)。
每个模型都有一些假设。如果这些假设被违反,你就不能期望模型能够正常工作。我认为这里就是这种情况。如果 X>Y,Y>Z,Z>X,那么为什么我不能声称 Y>X?这表明你可能遇到问题。
如果我正确理解了你——你假设 X > Y,这与你声称 Y > X 相矛盾。
想象一下石头剪刀布。
X 总是玩石头
Y 总是玩剪刀
Z 总是玩布
X > Z > Y > X
这表明通过标量对这种关系进行排序是行不通的。
请注意,石头剪刀布是一个无趣的游戏——在不知道对手的情况下,所有策略的适合度都相同,但在各种游戏中也可能发生同样的情况。
嘿 Jason,我如何将这个改编成多于 2 个 X,比如如果我的 X 有 X1,X2…Xn?例如 [1,2,3,4]
如果你能帮我解决这个问题,那就太好了!?
嗨 Agrover112……请指明您希望修改的代码部分以及原因。
你好,非常感谢您对算法的清晰准确的实现。
我只是注意到您不必在内循环中为每个个体计算“obj_target”(obj_target = obj(pop[j]),因为它与“obj_all[j]”相同。虽然这是一个小问题,但当我们在评估大型模型时,例如在我研究中的大型 CNN,它的成本会非常高。
再次感谢
你好 Hadi……不用谢!感谢你更新你的进展!