通过观察神经网络和深度学习模型在训练过程中随时间变化的性能,您可以学到很多东西。
Keras 是一个强大的 Python 库,它为创建深度学习模型提供了清晰的界面,并封装了更底层的 TensorFlow 和 Theano 后端。
在这篇文章中,您将了解如何使用 Python 和 Keras 审查和可视化深度学习模型在训练过程中随时间变化的性能。
使用我的新书 《Python 深度学习》启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2017 年 3 月更新: 已更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 2018年3月更新:添加了下载数据集的备用链接
- 2019 年 9 月更新:更新至 Keras 2.2.5 API
- 2019 年 10 月更新:已更新至 Keras 2.3.0 API
- 2022 年 7 月更新:更新至 TensorFlow 2.x API

在 Keras 中显示深度学习模型训练历史
图片由 Gordon Robertson 提供,部分权利保留。
访问 Keras 中的模型训练历史
Keras 提供了在训练深度学习模型时注册回调的能力。
在训练所有深度学习模型时注册的默认回调之一是 History 回调。它记录每个 epoch 的训练指标。这包括损失和准确度(对于分类问题),如果设置了验证数据集,还包括验证数据集的损失和准确度。
History 对象是从用于训练模型的 fit() 函数调用返回的。指标存储在返回对象的 history 成员中的字典中。
例如,在模型训练后,您可以使用以下代码片段列出 history 对象中收集的指标
|
1 2 3 |
... # 列出历史中的所有数据 print(history.history.keys()) |
例如,对于在分类问题上使用验证数据集训练的模型,这可能会产生以下列表
|
1 |
['accuracy', 'loss', 'val_accuracy', 'val_loss'] |
您可以使用 history 对象中收集的数据创建图表。
这些图表可以提供有关模型训练有用信息的指示,例如
- 其在 epoch 上的收敛速度(斜率)
- 模型是否可能已经收敛(线的平坦部分)
- 模型是否可能对训练数据过度学习(验证线的拐点)
- 等等
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
在 Keras 中可视化模型训练历史
您可以从收集到的历史数据创建图表。
在下面的示例中,创建了一个小型网络来模拟 Pima Indians 糖尿病发病二元分类问题。这是一个来自 UCI 机器学习存储库的小型数据集。您可以下载数据集并将其保存为 pima-indians-diabetes.csv 在您当前的工作目录中(更新:从此处下载)。
该示例收集了从模型训练返回的历史记录,并创建了两个图表
- 训练 epoch 上训练集和验证集准确度的图表
- 训练 epoch 上训练集和验证集损失的图表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 可视化训练历史 from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense import matplotlib.pyplot as plt import numpy as np # 加载皮马印第安人糖尿病数据集 dataset = np.loadtxt("pima-indians-diabetes.csv", delimiter=",") # 分割为输入 (X) 和输出 (Y) 变量 X = dataset[:,0:8] Y = dataset[:,8] # 创建模型 model = Sequential() model.add(Dense(12, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0) # 列出历史中的所有数据 print(history.history.keys()) # 总结准确度历史 plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.title('模型准确度') plt.ylabel('准确度') plt.xlabel('epoch') plt.legend(['训练', '测试'], loc='左上') plt.show() # 总结损失历史 plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.title('模型损失') plt.ylabel('损失') plt.xlabel('epoch') plt.legend(['训练', '测试'], loc='左上') plt.show() |
图表如下。验证数据集的历史记录按照惯例标记为测试,因为它确实是模型的测试数据集。
从准确度图表中可以看出,模型可能可以再多训练一点,因为在最后几个 epoch 中,两个数据集的准确度趋势仍在上升。您还可以看到模型尚未过度学习训练数据集,在两个数据集上都表现出可比的技能。
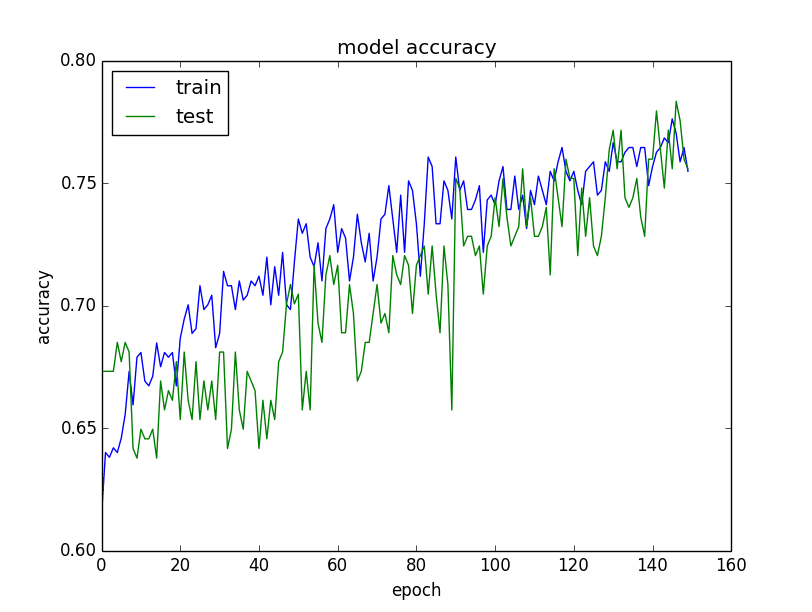
模型在训练集和验证集上的准确度图
从损失图表中可以看出,模型在训练集和验证集(标记为测试)上表现相当。如果这些平行图开始持续偏离,这可能是提前停止训练的信号。

总结
在这篇文章中,您了解了在训练深度学习模型时收集和审查指标的重要性。
您了解了 Keras 中的 History 回调,以及它总是从 fit() 函数调用中返回以训练您的模型。您学习了如何从训练期间收集的历史数据创建图表。
您对模型训练历史或这篇文章有任何疑问吗?请在评论中提出您的问题,我将尽力回答。






谢谢 Jason!
不客气,Marcel。
你好,你知道如何在 keras 中使用 Callback 绘制图片吗?
太棒了。是否也可以绘制每个 epoch 中每个样本的准确度和损失?
例如:1 个 epoch,60,000 张 MNIST 图像 => 在该 epoch 中绘制 60,000 个准确度/损失?
这些图表可以汇总显示,如果您愿意,可以计算每个单独样本的损失和准确度,但这会是大量数据。希望我回答了您的问题。
嗨,Jason,
我非常希望能得到一些指导,确切地知道如何获得每个单独样本更细粒度的损失和准确度。我的数据集没有那么大,所以数据量不会是难以克服的。
谢谢!
Zorana
你好 Zorana……请详细说明“细粒度”是什么意思。以下内容可能与提高准确度有关
https://machinelearning.org.cn/improve-model-accuracy-with-data-pre-processing/
你好,我正在寻找类似的东西。你找到办法了吗?
提前感谢。
history = model.fit(X,y, validation_split=0.33, epochs=150, batch_size=60000)
d=history.history
你好 Randy,
希望下面的代码有所帮助,请告诉我
plt.plot(range(epochs), d.get(“loss”))
plt.ylabel(‘RMSE 损失’)
plt.xlabel(‘epoch’);
loss=d.get(“loss”)
for i in range(len(loss))
if i%25 == 1
print(f’epoch: {i:3} loss: {loss[i]:10.8f}’)
嗨,Jason,
感谢您的精彩文章!
对于准确度图表,当它开始过度学习时,指标是什么?发生这种情况时,图表会是什么样子?
提前感谢
你好 Alvin,好问题。
如果模型过拟合,图表将显示在训练数据上表现出色,而在测试数据上表现不佳。
你好!我目前正在为我的研究训练 CNN。数据集是稀疏的。我正在使用 Conv->Conv->Pool->conv->dropout->gap->dense 层。
对于许多不同的架构组合,模型似乎都会过拟合,无论我怎么做。有没有一种系统的方法来解决这个问题?
是的,尝试增加正则化。
我这里列出了一些可以尝试的技术
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
Jason,
很棒的教程,非常清晰地阐述了 keras 中每个网络的工作原理。
我有一个小问题
keras 是否支持这种数据集来实现自动编码器而不是 FFN?
谢谢..
致敬
Sunny
你好 Suny,
Keras 确实支持自动编码器,但我通常不使用它们,因为它们已经被大型 MLP 和 LSTMs 和 CNNs 等专门方法超越,这些方法可以在训练时学习特征。
你好 Jason(和所有人)。
当应用 dropout 时,我想知道损失和准确度值是如何计算的。在每个 epoch 之后,程序仍然会丢弃神经元/权重来计算损失和准确度,还是使用整个网络?
好问题,
Dropout 只在训练(反向传播)期间应用,而不是在进行预测(前向传播)时应用。
嗨,Jason,
感谢所有精彩的教程!
我希望能够绘制有状态 LSTM 的历史记录。我尝试了类似下面的方法,但在此情况下它失败了,因为我要求 Python 字典做它们不喜欢的事情(我是 Python 新手)。我还尝试了其他方法,但都因与 Python 相关的原因失败了。
重印您的有状态教程中的 .fit() 代码(并添加了一个失败的捕获历史尝试)
my_history = {}
for i in range(100)
history = model.fit(trainX, trainY, nb_epoch=1, batch_size=batch_size, verbose=2, shuffle=False)
my_history.update(history)
model.reset_states()
我这里做错了什么?谢谢!
Bo,这个想法很有趣。
考虑使用列表并将历史对象附加到列表中。另外,考虑在每次迭代中创建一个全新的模型,以尝试保持所有比较的公平性。
告诉我你的进展和发现!
如何显示 keras 中使用的神经网络?有没有简单的方法来绘制网络
这可能对 nagendra 有帮助
https://keras.org.cn/visualization/
嗨,Jason,
我希望在训练期间可视化每个 epoch 的损失和准确度图表。
我正在考虑通过编写回调来实现,但不确定具体如何以及是否可以做到。
你有什么建议?
谢谢
你好 Aviel,Keras 并非原生设计用于此。
也许可以使用回调将数据发布到文件/数据库,并使用单独的进程进行绘图?
我建议尝试一下这种粗糙的方法,看看效果如何。
你好,
首先,非常感谢您的教程!
我有一个小问题。我希望绘制图表,但我的计算资源**不在**本地。有没有办法通过回调或其他方式将每个错误值存储在 CSV 文件中,然后稍后绘制?或者有没有办法,我不知道,保存历史对象,也许将其 pickle 化,然后使用 rsync 或 dropbox 等标准工具发送到我的本地计算机?
您对这些远程绘图实验有什么建议?我只需要获取数据,以便我可以绘制错误/损失与 epoch 的关系。
(另外,我可以绘制与迭代而不是 epoch 的关系吗?只是好奇)
你好 Charlie,
您可以将历史记录存储在数组中,然后创建并保存图表作为文件,而无需显示。
你好,
我有一个非常简单的问题,希望您不介意我问。我想用 plt.savefig("figure") 保存损失函数图,但我得到了“模块不可调用”的错误,如果我注释掉 plt.savefig("figure"),一切都运行正常。您知道这是为什么吗?
非常感谢!
确保您已正确安装和配置 matplotlib。
你好,
我解决了错误,谢谢!但是,我还有另一个问题,我正在对参数(epoch 和 batch size)进行网格搜索,并且对于每个组合,我都会绘制损失函数。但是,对于每个组合,它只是在同一个图中将每个结果显示在另一个结果的顶部!你知道为什么会这样吗?
抱歉,我没有在网格搜索中捕获历史的经验。
我建议您编写自己的 for 循环/网格搜索,这样您会有更大的灵活性。
你好,
做得很好。
快速提问。我目前在没有 Keras 的情况下使用 tensorflow,并绘制 CNN 的损失和准确度。我正在使用带有 Adam 优化器的交叉熵,并将交叉熵值用作损失。这是对的吗?
另外,如果损失在 200-300 范围内,我是否应该绘制它的对数值?因为我看到的所有图表中,损失都在 0-1 之间。
谢谢
戴夫
你好,感谢您提供所有精彩的信息。如果您能就 Keras 模型是管道的一部分时如何访问训练历史提供任何建议,不胜感激。
谢谢你,
Caleb
抱歉,我自己没做过。您可能需要扩展 sklearn 封装器并手动捕获此信息。
嗨,Jason,
我正在运行您书中的这个例子,但是我使用了交叉验证,特别是 StratifiedKFold。所以当我拟合模型时,我没有传递 `validation_split` 或 `validation_data`,因此我的模型历史只有 ['acc', 'loss'] 键。我正在使用 model.evaluate()。我如何可视化测试?
你可以保留一个验证测试,或者你可以收集每个模型在每个交叉验证折叠上评估的历史。
嗨,Jason!
我有两个问题
1) 当将 verbose 设置为 2 时,我期望在每个 epoch 期间打印,包括进度条,但我只看到训练和验证损失(没有看到准确度或进度条)
2) 当运行到达绘图部分时,我收到一个错误
plt.plot(history.history['acc'])
KeyError: 'acc'
忽略的异常: <bound method BaseSession.__del__ of >
回溯(最近一次调用)
文件 "C:\ProgramData\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", 第 582 行,在 __del__ 中
UnboundLocalError: 局部变量 'status' 在赋值前被引用
谢谢!
没错,如果你想要进度条,请将 verbose=1。
你必须将准确度指标添加到 fit 函数中。错误表明没有这样做。在此处了解更多关于指标的信息
https://keras.org.cn/metrics/
你好 Jason,非常感谢,我还有几个问题
a. 如何使用历史对象绘制 ROC 曲线?
b. 如何在每个 epoch 后保存最佳模型?(仅当验证集上的准确度提高时,才用新模型覆盖我的模型)
谢谢,
Nir
我没有使用 Keras 结果绘制 ROC 曲线的示例。
这篇文章将帮助您在训练期间保存模型
https://machinelearning.org.cn/check-point-deep-learning-models-keras/
我在这里找到了生成 ROC/AUC 的解决方案
忘记对 Jason 说声非常感谢,你总是让人惊叹,永远走在前沿但又务实。
很高兴听到这个消息。
我遇到了同样的“keyerror ‘acc’”问题。我已经在模型评估中添加了准确度指标,但仍然遇到相同的错误。请帮忙
将 'acc' 改为 'accuracy',我相信这是 Keras 新版本中的一个更改。
您能告诉我如何保留 classifier.fit_generator() 函数的历史记录吗?
你好 jason!
我希望在 tflearn 中访问模型训练历史以绘制图表。
我们如何在 tflearn 中做到这一点?
抱歉,我没有例子。
你好 Jeson,我正在使用超过 100 GB 的数据集来构建模型。我正在使用 HDF5 数据库进行数据加载。所以对于这种配置,我手动迭代训练过程。因此,由于我使用手动迭代,历史文件没有附加模型信息,而是每个 epoch 之后都创建了历史文件。如何像正常过程一样更新历史文件以追加。
我可以在每个 epoch 后手动附加模型信息吗?因为模型优化需要历史文件信息。
我建议您在训练过程中将性能保存到文件中。只需将每个 epoch 的分数附加到文件中。
你好 Jason,我写了一个 LSTM 模型来训练我的脑部 MRI 切片。对于我的数据集,每个患者有 50 个切片,n 个患者被分成训练集和验证集。我的 LSTM 模型设计如下
model = Sequential()
model.add(LSTM(128, input_shape = (max_timesteps, num_clusters), activation='tanh', recurrent_activation='elu', return_sequences = False, stateful = False, name='lstm_layer'))
model.add(Dropout(0.5, name = 'dropout_layer'))
model.add(Dense(out_category, activation = 'softmax', name='dense_layer'))
optimizer = optimizers.RMSprop(lr=lrate)
model.compile(loss = 'categorical_crossentropy', optimizer = optimizer, metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_vald, y_vald), epochs = epoch_num, batch_size = batch_size, shuffle = True)
首先,我使用微调后的 GoogLeNet 的 GlobalAveragePooling 层提取每个切片的特征。
其次,使用训练集中的 n1*50*2048 特征和验证集中的 n2*50*2048 特征来训练我的 LSTM 模型。
然而,训练过程非常奇怪。训练和验证的准确度在 Epoch 46 突然下降。您能给我一些关于这个结果的建议吗?Epoch 40 到 50 的过程如下
Epoch 40/70
407/407 [==============================] – 25s – loss: 8.6558e-05 – acc: 1.0000 – val_loss: 1.3870 – val_acc: 0.8512
Epoch 41/70
407/407 [==============================] – 25s – loss: 1.7462e-06 – acc: 1.0000 – val_loss: 1.2368 – val_acc: 0.8595
Epoch 42/70
407/407 [==============================] – 25s – loss: 4.5732e-06 – acc: 1.0000 – val_loss: 1.1689 – val_acc: 0.8760
Epoch 43/70
407/407 [==============================] – 25s – loss: 6.2214e-07 – acc: 1.0000 – val_loss: 1.2545 – val_acc: 0.8760
Epoch 44/70
407/407 [==============================] – 25s – loss: 2.5658e-07 – acc: 1.0000 – val_loss: 1.2440 – val_acc: 0.8595
Epoch 45/70
407/407 [==============================] – 25s – loss: 6.2594e-07 – acc: 1.0000 – val_loss: 1.2281 – val_acc: 0.8678
Epoch 46/70
407/407 [==============================] – 25s – loss: 3.3054e-07 – acc: 0.5676 – val_loss: 1.1921e-07 – val_acc: 0.5372
Epoch 47/70
407/407 [==============================] – 25s – loss: 1.1921e-07 – acc: 0.5061 – val_loss: 1.1921e-07 – val_acc: 0.5372
Epoch 48/70
407/407 [==============================] – 25s – loss: 1.1921e-07 – acc: 0.5061 – val_loss: 1.1921e-07 – val_acc: 0.5372
Epoch 49/70
407/407 [==============================] – 25s – loss: 1.1921e-07 – acc: 0.5061 – val_loss: 1.1921e-07 – val_acc: 0.5372
Epoch 50/70
407/407 [==============================] – 25s – loss: 1.1921e-07 – acc: 0.5061 – val_loss: 1.1921e-07 – val_acc: 0.5372
这篇文章可能会给你一些启发
https://machinelearning.org.cn/improve-deep-learning-performance/
你好教授,
您在使用 Tensorboard 回调来绘制准确度方面的经验如何?
我目前正在尝试使用它,但由于某种原因,它在实现时降低了我的准确度。当我注释掉回调时,准确度提高了 30%。这是怎么回事?我应该坚持使用您的方法而不是使用 Tensorboard 吗?
抱歉,Jared,我还没用过 TensorBoard。
我们如何查看损失、准确度、验证损失和验证准确度是如何计算的内部机制?
抱歉,我不确定你是什么意思。如果你愿意,可以根据模型做出的预测手动计算这些东西。
你好,
谢谢你,
我如何才能在训练期间显示这些图表?这样我就可以在线查看网络进度。
也许你可以创建一个自定义回调,动态更新图表。
感谢您的精彩教程。我有两个问题需要您澄清
1. 如何避免编译函数返回的历史对象被打印出来。
2. 我如何将 tensorflow 更改为使用 theano。
非常感谢。
抱歉,我不理解您的第一个问题,请您重新表述一下好吗?
您可以通过编辑 ~/.keras/keras.json 中的 Keras 配置文件来更改后端。
你好 Jason 博士,这对我可视化我的模型有很大帮助,但你能告诉我如何选择验证拆分值和批处理大小吗?
在你的特定数据集上使用试错法。
不好意思,您说的试错法是什么意思?我是 ML 和 DL 的新手。
抱歉,我的意思是使用实验来看看哪种方法对您的问题最有效。这是一种原始的搜索过程。
为什么 Val_acc 比实际的训练准确度更高?这意味着过拟合还是什么?
乍一看,这很不寻常,可能是欠拟合的迹象(例如,模型不稳定)。
为什么你在图表中写了“测试”,尽管你把它用作验证?
好发现。
嗨,太完美了,谢谢
但如果我想把它保存到 *.png 文件中,我该怎么做呢?
我用了 plt.savefig('iman.png')
但它不起作用
你能帮我吗,jason?
是的,我也会推荐这个方法。
为什么不起作用?
如何对 tflearn 做同样的事情,我到处找了,找不到类似的东西。我的 tflearn 中的 model.fit 没有返回任何东西,所以我得到了这个错误
my_history.update(history)
TypeError: 'NoneType' object is not iterable
如果您能提供解决方案,将非常有帮助。谢谢!
抱歉,我目前不使用 tflearn。我无法给您好的建议。
你好 Jason,很棒的文章!
我有一个问题。我正在训练一个 CNN 超过 5 个 epoch,并获得了 0.9995 的测试准确度,并绘制了训练和验证准确度图,如您所示。训练准确度在 5 个 epoch 中从 0 增加到 0.9995,但验证准确度似乎几乎稳定在 1.0(>0.9996)。这正常吗?我搞不清楚这里发生了什么。
(我使用了 100,000 张图像,其中 20% 用于测试。在 80% 用于训练的图像中,20% 分割用于验证,其余用于训练)
提前感谢!
有趣,也许验证样本太小了?也许你的模型非常有效?
也许多重复几次实验看看结果是否保持不变?
是的,结果保持不变。可能是验证样本太小了。我正在训练 64000 张图像并在 16000 张图像上进行验证。所以,这可能是原因,或者我的模型非常有效?
另外,我注意到当我从模型中移除一个 dropout 实现(2 个中的一个)时,训练准确度会高于验证准确度图表。
也许探索模型的其他配置和测试工具会比较好?
你好 Jason,感谢你的精彩帖子。
我想问你一个关于如何解释这些结果的问题。
https://ibb.co/hYyYvG
https://ibb.co/dR3DUb
我正在使用 Keras 构建网络。
我有 2 层,每层有 128 个单元,最后一层有 2 个单元。
我正在使用 L2 正则化。我使用 Adam 优化器。
在拟合时,我使用了 100 个 epoch,批处理大小 32,验证拆分 0.3。
我的数据包含 15000 行,5 个特征加上输出。
我不确定我是否过拟合。
而且我无法弄清楚为什么我的验证数据有如此多的波动。我尝试了很多不同的方法,但波动从未消失。
通常,我知道训练数据和验证数据之间不应有很大的差距/差异。但我对准确度不确定。我们是否应该总是获得稍好的验证数据准确度?否则,是过拟合的迹象吗?
您能详细说明一下吗?
谢谢!
也许这篇文章将有助于诊断您的图表
https://machinelearning.org.cn/diagnose-overfitting-underfitting-lstm-models/
嗨,杰森,
谢谢,
关于物体检测问题(例如运行 ssd_keras 进行物体检测)的损失和准确度呢,是否可以遵循相同的步骤?
抱歉,我不明白,您能重新表述一下或者提供更多上下文吗?
Jason,
我还希望获得训练期间产生的平均误差,这样一旦我在验证集上运行模型,我就可以将每个步骤中产生的误差与我得到的这个平均值进行比较。如何获得整个训练数据的平均 RMSE 值?
抱歉,我不确定我是否理解。也许您可以提供更多上下文?
您好。
谢谢。我想知道:为什么训练损失一开始不如验证损失好?是因为使用了 dropout 吗?
有可能是。
如果是模型在训练集和验证集上的损失图
如果图中包含 ^;你为什么将训练集和测试集作为图例添加到图中。这难道没有误导性吗?
这里我将“测试”称为一个通用的样本外数据集。
这有帮助吗?
你好,对不起,我无法在图中显示测试,我不知道为什么……你能帮我吗?
你好 Manel……你是否收到了我们可能可以帮助你的错误或错误?
你好,Jason!
在 Keras 历史记录中,我如何绘制训练期间的准确度与批次大小的关系?
使用回调
我不建议使用回调来创建图表。
收集平均准确度分数数组和批次大小数组,然后使用 matplotlib 创建图表。
正如您的示例所示,只有训练和验证损失以及准确度。我能否问一下如何绘制训练、验证和测试的损失和准确度?
*显示
您可以绘制每个训练 epoch(即随时间)在训练集和测试集上的损失。
嗨,Jason,
在回归模型中,如何研究历史呢?如何可视化训练集和验证集中的损失?在我的例子中,当我执行
print(history.history.keys())
我只得到两个值
dict_keys(['mean_absolute_error', 'loss'])
所以我无法绘制验证集损失。我已经用以下代码拟合和评估了模型
history = model.fit(X_train, Y_train, epochs=50, batch_size=30)
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=12)
看起来不错。
在回归中,我们可以将指标添加到编译步骤,以获取验证损失,对吗?
model.compile(….,, loss=”mean_absolute_error”, metrics=[“”mean_squared_error”])
然后
history.history.keys()
会给出
val_loss, loss, mean_sqaured_error, val_mean_sqaured_error
(损失是 MAE)
然后我们可以绘制它们。
嗨,Jason,
这是一篇介绍 Keras 历史的好文章。我有一个问题,如果这个历史是否也适用于多步时间序列预测。例如,使用过去两小时的数据预测未来两小时 f(x(n-1), x(n))= x(n+1), x(n+2)
y 有两个值,但 history['loss_val'] 只有一个值。如果这个 history['loss_val'] 是两小时预测的损失之和?
我查阅了 Keras 网站,但没有找到答案。提前感谢。
好问题。
它可能是向量输出的平均或总损失?只是猜测。
我们可以为测试绘制相同的图吗?也就是 model.evaluate()
不,只有训练期间的历史记录。
嗨 Jason
你的教程真是太棒了。感谢你的努力。
我正在尝试为我的模型绘制模型损失和准确性。在 history 变量中,'loss' 和 'val_loss' 存在。但是当我尝试访问 'acc' 或 'val_acc' 时,它会引发一个键错误。我打印了所有键。请查看下面的输出
val_loss
val_dense_3_loss_1
val_dense_3_loss_2
……
val_dense_3_loss_14
val_dense_3_loss_15
val_dense_3_acc_1
val_dense_3_acc_2
.....
val_dense_3_acc_14
val_dense_3_acc_15
loss
dense_3_loss_1
dense_3_loss_2
……
dense_3_loss_14
dense_3_loss_15
dense_3_acc_1
dense_3_acc_2
……
dense_3_acc_14
dense_3_acc_15
我错过了什么?
编译模型时必须添加 metrics=['accuracy']。
谢谢你的回复。
是的,我已经添加了。请查看下面的实现
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
history = model.fit(inputs, outputs, validation_split=0.2, epochs=epochs, batch_size=batch_size)
有一件事,我从 history.history.keys() 中获取 dense_3_acc_n。如果我取 dense_3_acc_1 到 dense_3_acc_n 的平均值,我将得到平均准确性。它会计算实际准确性吗?
我建议关注 'acc' 和 'val_acc' 键。
嗨,Jason,你能告诉我如何通过加载保存的模型(使用 model.save('filename') 命令的 hdf5 格式)来绘制这些图表吗?因为当我尝试用保存的模型绘制时,它给我一个错误“history is not defined”
您只能通过调用 fit() 并使用数据来训练模型来获取图表。
嗨,谢谢回复。你能告诉我如何绘制测试准确性和损失以及训练和验证吗?
是的,上面的教程向您展示了如何操作。
嗨,但这适用于训练和验证,而不是实际测试数据?我想在一个图中绘制所有三个验证、训练和测试。
您可以手动运行训练循环,在每个数据集上进行评估,存储结果,然后在最后将它们全部绘制出来。
谢谢。
不客气。
谢谢你。我有一个疑问。我的模型类型是 'keras.callbacks.history'。如何检查模型是否欠拟合或过拟合。
我在这里有一些建议
https://machinelearning.org.cn/diagnose-overfitting-underfitting-lstm-models/
谢谢你,Jason!
我以前不理解 Keras,但多亏了你,我开始理解它了。
很高兴听到这个消息。
嗨,Jason,
很棒的教程。我想知道训练周期结束后,绘图需要多长时间才能显示?我尝试了一下,但绘图需要很长时间才能显示,而且我只做了 2 个周期来加快过程,尽管我使用的是我自己的神经网络,而不是上面显示的示例。
非常感谢!
Marco
图表应该立即显示。
确保您从命令行运行代码,方法如下
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
嗨,Jason,
谢谢,我成功解决了这个问题,事实证明(至少对我来说)Matplotlib 图表在终端中运行脚本时不会打开。我在控制台/shell 中运行代码,它运行良好。再次感谢。
很高兴听到你的进步。
终端/控制台/shell 对我来说都是一回事。
当你提到“终端”时,你到底是什么意思?
感谢您的文章!
我创建了一个 Python 包,只需一行代码即可绘制准确性和损失。
https://pypi.ac.cn/project/keras-hist-graph/
使用 `pip install keras-hist-graph` 安装
然后使用
from keras_hist_graph import plot_history
history = model.fit(x, y, ...)
plot_history(history)
太棒了,谢谢分享!
亲爱的 Jason,
非常感谢您提供的所有优秀教程!它们在把我引入机器学习世界方面帮了大忙。
我有以下问题
在 Keras 中,有没有办法绘制训练和验证损失与数据集大小(而不是 epoch)的图?
假设我有一个包含 N 个训练样本的数据集。我想知道使用 20% 的数据集,然后是 40%...,然后是 100% 的训练和验证损失,并将所有这些点上的结果绘制在图表上。
我可以编写一个循环过程,相应地分割数据集大小并在每个分割中拟合模型,但是,每个分割点上训练和验证损失的最终数字应该是多少?使用训练损失相对于 epoch 数量的平均值还是最后一个 epoch 报告的损失是否正确?
我看到 Scikit learn 有一个用于创建学习曲线的示例脚本(https://scikit-learn.cn/stable/auto_examples/model_selection/plot_learning_curve.html),但不太明白如何将 Keras Sequential Model 与此结合使用。
提前感谢!
您可以运行一个实验,并总结训练集大小和误差之间的关系。在每个大小的数据集上拟合模型,存储分数,然后绘制分数。
是的,你必须写一个 for 循环。
你好,Jason。
感谢您的教程。
我可以在一个不是分类问题的问题中绘制历史记录吗?
或者换句话说,一个我不使用 *_crossentropy 的网络?
谢谢
是的。任何在训练期间跟踪的指标都可以绘制出来。
嗨,Jason,
我从您的博客中学到了很多东西。它真的很棒。
我有一个关于在 Keras 中拟合模型时 history 对象的疑问。
在上面的例子中,您使用一个简单的神经网络,其中包含多个隐藏的密集层。由于 fit 方法只调用一次,所以 history 对象只实例化一次,一切都很好。
但是,我不确定如何在模型的 LSTM 层中使用 history 对象。当 stateful=True 时,我们会在循环中运行 epoch,因此 fit 在每次循环中都会被调用。在这种情况下,您如何使用 history 对象。
您是否必须显式地跟踪它每次实例化...例如通过字典?
好问题。
如果您手动运行 epoch,您也可以手动在训练/测试集上评估模型,并将结果存储在您自己的列表/列表历史对象中。
这能和 gridsearchCV 结合使用吗(如果可以,如何编码?)
不,我想它们会相互矛盾。例如,评估模型性能(交叉验证)和回顾学习动态(学习曲线)。
感谢这篇入门文章。
我厌倦了为每个想要了解的指标添加新的节。我将此通用化,以绘制 model.compile(metrics=[m,...]) 中存在的所有键。
感谢分享。
感谢这篇很棒的文章!
通常,准确性或损失足以评估模型(确定它是否过拟合、欠拟合等)。但是,在某些情况下,是否必须同时使用两者才能得出关于模型性能的结论?如果不是,那么拥有两个本质上告诉我们相同事情的指标的意义何在?
此外,为什么(至少根据我自己的经验)损失与 epoch 的图表通常看起来比准确性与 epoch 的图表更平滑?
损失可能显示过拟合,但准确性可能没有显示效果。在这种情况下,我希望看到两者。
准确度比损失更离散,它会不那么平滑。
在建议的损失显示过拟合但准确度没有显示效果的情况下,您会如何决定下一步该做什么?
嗯,我宁愿使用一个不显示过拟合的模型(例如,拥有一个更稳定的模型)。我可能会添加正则化以减少过拟合损失。可能是权重正则化和早期停止。
这可能已经很晚了。您可以使用其他性能指标,例如召回率、精确率和 F1 分数,这些指标也通过包含 keras.metrics 套件生成。您可以执行类似 metrics=['accuracy',tf.keras.metrics.Precision(), tf.keras.metrics.Recall(),tf.keras.metrics.TruePositives(),tf.keras.metrics.TrueNegatives(),tf.keras.metrics.FalsePositives(),tf.keras.metrics.FalseNegatives()]),
]。此外,您可以通过获取混淆矩阵并计算其他指标(例如 G 分数、误报率和马修斯相关系数)来扩展您的评估标准。
感谢分享。
我注意到你在这里交替使用验证和测试。这有效吗?验证和测试难道不应该不同吗?
提前感谢
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
嗨,Jason,
我做了一个测试,使用不同的批量大小:32、64、128、256、512、1024 和 2048。我为每个批量大小训练了 5 个模型,总共得到 35 个模型。我使用 Keras history 保存了每个模型的“loss”和“val_loss”,并选择了验证损失中的最小值对应的损失和验证损失,以避免过拟合。当我绘制损失时,批量大小为 1024 的 5 个模型大致得到了最小值,但是当我绘制验证损失时,没有最小值。我觉得这很奇怪,还是因为 Keras 计算损失和 val_loss 的方式造成的?
你说的“没有最小值”是什么意思?
好的,那是我的代码中的一个错误 :) 现在训练误差和验证误差都随着批量大小的减小而减小,在 1024 左右达到最小值。但现在我发现了另一个问题,这可能对您和其他人来说很明显。我使用两种方法计算和绘制训练误差和验证误差。首先,我使用 Keras history 保存损失和 val_loss,其次,我保存每个模型及其最佳权重,然后计算每个模型的 MSE。所有模型的 val_loss 和验证集的 MSE 都相同,但训练集的损失和 MSE 不同,尽管它们很接近。所以 Keras 必须以不同的方式计算损失和 val_loss,你知道是如何以及为什么吗?
干得不错。
我相信 val 损失是在训练期间对每个批次进行平均的。
您好 Jason,
如何使用 scikit_learn 或 k_fold 将数据集分割为训练、验证和测试?
您可以使用 train_test_split() 函数,在此处了解更多信息。
https://machinelearning.org.cn/evaluate-performance-machine-learning-algorithms-python-using-resampling/
嗨 Jason!我想知道如何通过 history.history 获取模型的 RMSE?
Keras 不支持 RMSE,您可以在此处添加它
https://machinelearning.org.cn/custom-metrics-deep-learning-keras-python/
你好,
我想知道在训练过程中如何获取每个 epoch 后的梯度信息?
我正在使用 TensorFlow。
谢谢
抱歉,我没有这方面的例子。
你好 Jason,
我运行这段代码,但是出现了这个问题:“ValueError: could not convert string to float: '”6′”
很抱歉听到这个消息,我这里有一些建议可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
电脑重启后,如何查看模型历史记录?
您必须将历史记录保存到文件才能将来查看。
嗨,Jason,感谢您的完美描述。????♀️
我有个问题
我拟合了我的模型,其中 y_train 是一个列表,当我像“loss”一样绘制历史记录时,它没有显示任何内容。
我不知道为什么。????
也许您可以从博客文章中的示例开始,并将其改编为您的具体问题?
非常感谢,我是您文章的忠实读者!!!它们太棒了。
谢谢!
我的图表只有 6 个 epoch,从第二个 epoch 开始看起来像一条直线,这正常吗?模型准确率是 99%。
这表明你正在处理的问题非常简单/容易。
在这种情况下,我如何放大图表以显示 epoch 之间的差异?如果我们要将这个图表用于论文,没人能从图表中看出差异。
也许只绘制感兴趣的区间,而不是所有数据?
感谢您的精彩文章,我有一个快速的问题
我想知道我的模型(图像分类)的最佳 epoch
1) 假设我有 epoch=4,我应该运行模型 3 次并考虑验证测试的最后准确率(在这种情况下,我将有 3 个值,持续 3 次),然后我选择最高的一个吗?
2) 当我更改 epoch 时,我应该重复实现模型还是直接使用新的 epoch 进行拟合?
提前感谢。
监控验证损失以选择最佳 epoch。
您可以使用检查点保存最佳验证 epoch 的模型。
https://machinelearning.org.cn/check-point-deep-learning-models-keras/
您可以选择将 epoch 编号用作新拟合的固定训练 epoch 数量,也许可以对多次运行的所选 epoch 数量取平均值。
我有一个超过 100 万条记录的数据集。从标签列来看,只有 200 个异常类别,其余都是正常的。使用 sklearn.model_selection.train_test_split 分割此数据集是否最佳?训练集和测试集中都有 100 条异常记录是否更好?
不,请看这篇文章
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
嗨,Jason,感谢这些很棒的教程。我用数据运行了上面的代码,一切都很顺利。现在,我正在用不同的数据运行代码,我的问题是
我正在使用 model.fit 训练数据集(仅训练数据,没有 validation_split),并绘制损失值。然后我在相同的训练数据(没有“test_data”作为验证)上运行 model.evaluate,我得到的损失(一个标量数字)与 model.fit 中最后一个 epoch 的损失值不同(通常更低)。这正常吗?根据我对这些教程的理解,我期望它们都是相同的,因为这两个命令(fit() 和 evaluate())中使用的数据始终相同。我对这两个命令有什么理解不对的地方吗?
训练期间看到的损失可能是在 epoch 内的批次上平均的。
也许检查代码或在 Keras 用户组上提问?
嗨,布朗利先生,我是一名计算机科学专业的学生,正在做我的毕业项目,我遇到了一些问题。我有大约 4k 张图片,分为 16 个类别,使用基本的网络结构进行训练;卷积层从 32 个滤波器开始,每个后续卷积层都加倍,每个卷积层的内核大小为 3x3,dropout 层从 0.1 开始,每次增加 0.02-0.05。每个类别大约有 250-350 张图片。
我使用 keras 图像增强和 fit_generator 来实现每个 epoch 500 张图片,总共 200 个 epoch,总共 10 万个训练样本,以确保我的网络泛化良好,我还在验证集上使用增强。训练损失接近 0.2,准确度在 10 万个样本后达到 91-92%,但验证准确度仅达到 30%,手动测试新图片也导致糟糕的结果。
这些类别本质上是北美动物,例如鹿、麋鹿、驼鹿、熊、郊狼等,以及一些其他随机事物,因此提取的特征总是会有些相似,但 30% 似乎低得令人难以置信。您有什么建议?
这是基本结构
输入(128,128,3)->顺序->卷积->LR->dropout->卷积->零填充->LR->dropout->BN->卷积->LR->dropout->BN->卷积->LR->dropout->卷积->LR->dropout->展平->密集(16)
这听起来模型可能过拟合了。
这将帮助您诊断问题
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
然后,这里的教程将帮助您纠正它。
https://machinelearning.org.cn/start-here/#better
告诉我进展如何。
感谢您的输入,我决定改用 Resnet 架构,我遇到了类似的问题,即我的 val_acc 几乎总是只有我的常规 acc 的一半。阅读了您的“7 天迷你课程”以及您提供的第一个链接后,我得出的结论是,我没有足够的数据来很好地泛化。
这让我感到有些困惑,我不确定该怎么做,我从 Google/Bing/Yahoo 抓取的约 10 万张图片中手动选择了 4k 张图片,我无法再找到有意义的数据量。话虽如此,我看到了您提到在输入层使用噪声,并想知道您建议高斯噪声值的硬限制是多少,在您的示例中,您有一个 0.1 的值,这是您推荐的最大值吗?
与上述相关,引入我不在乎的类别是否允许更好的泛化?一个例子是,如果我有 10 个与动物相关的类别,并且训练导致了所讨论的问题,那么添加另外 10 个与日常随机对象相关的类别是否能让我的模型更好地拟合数据,或者甚至是一个由不属于前 10 个类别的随机图片填充的单个类别?
最后,关于上一段,是否可能过拟合特定类别?目前我的分布几乎是均匀的,就像我说的那样,每个类别大约有 250-350 张图片用于训练,其中 10% 用于测试,一个包含 2k 图片的类别会导致过拟合问题吗?
感谢您所有的时间,不幸的是我的毕业设计导师不了解这个领域,所以我边学边做,您的网站非常有帮助。
您可以忽略我的最后一个问题,我实际上在您的网站上找到了答案:https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/。
我仍然希望您对第二段和第三段提供一些意见。
这些方法可能不适用于多类别计算机视觉问题。
如果数据不足,主要有两条途径。
尝试数据增强以扩展数据集
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
最佳实践
https://machinelearning.org.cn/best-practices-for-preparing-and-augmenting-image-data-for-convolutional-neural-networks/
并尝试正则化方法以减少过拟合。
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
使用混淆矩阵查看模型在不同类别上的表现
https://machinelearning.org.cn/confusion-matrix-machine-learning/
主题:评估模型并绘制训练历史记录
在训练周期中,训练集和测试集上的准确度图是否必须收敛(例如线条的平台期)?
这些图只是帮助你理解正在发生的事情的工具。
它们不是必需的。
我们输入一张大小为 28*28*1 的图像:我如何查看每个操作后的像素值,即应用第一个内核 -> 最大池化 -> 第二个内核 -> 最大池化 -> 展平 -> fc1 -> fc2?我想保存并打印每个阶段的像素值。
您也可以将每一层用作输出层,以查看每个点的输出。
我在这里给出了一个例子
https://machinelearning.org.cn/how-to-visualize-filters-and-feature-maps-in-convolutional-neural-networks/
我的预测中没有假阳性和假阴性,所以准确度应该达到 100%,但它显示 99.997,这正常吗?
历史记录是每个 epoch 中所有批次的性能平均值。
相反,您可以使用 model.evaluate() 来估计模型在保留数据集上的性能。
你好 Jason,
有没有办法记录模型拟合数据所需的时间?
Vishnu
是的,在进行预测之前记录时间,然后再次记录时间并计算差异。
嗨,Jason,非常不错的教程。
我想问一下,有没有办法获取每次迭代的权重和偏差?
谢谢。
是的,您可以手动逐步完成 epoch,并在每次循环中调用 model.get_weights()。
或者设置一个检查点回调,在每个 epoch 结束时将权重保存到文件。
嗨,Jason,
我正在尝试获取一个准确度图,但它不是我预期的样子,我无法弄清楚我哪里出错了。
下面是我的代码。
# 可视化训练历史
来自 keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# 加载皮马印第安人糖尿病数据集
dataset = numpy.loadtxt("pima-indians-diabetess1.csv", delimiter=",")
# 分割为输入 (X) 和输出 (Y) 变量
X = dataset[:,0:7]
Y = dataset[:,7]
# 创建模型
model = Sequential()
model.add(Dense(50, input_dim=7, activation='relu'))
model.add(Dense(48, activation='relu'))
model.add(Dense(30, kernel_initializer='uniform', activation='relu'))
model.add(Dense(28, kernel_initializer='uniform', activation='relu'))
model.add(Dense(26, kernel_initializer='uniform', activation='relu'))
model.add(Dense(20, kernel_initializer='uniform', activation='relu'))
model.add(Dense(18, kernel_initializer='uniform', activation='relu'))
model.add(Dense(16, kernel_initializer='uniform', activation='relu'))
model.add(Dense(10, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, activation=’sigmoid’))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
# 拟合模型
history = model.fit(X, Y, validation_split=0.25, epochs=150, batch_size=32, verbose=0)
# 列出历史中的所有数据
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()
下面是我的准确度图的快照链接
https://drive.google.com/file/d/1GJJy4frCOpgc5-Z2LIoniUYDNR40MQ5j/view?usp=sharing
我相信从 Keras 2.3 开始,您必须使用 'accuracy' 而不是 'acc'。
此外,您的平面图表明模型学习不多——看起来层数太多了!
作为一名机器学习初学者,我想知道即使我使用从图像而非 CSV 文件构建的数据集,是否可以使用“validation_split”属性——我使用 fit_generator 而非 fit 进行训练。
另外,非常感谢本文中的解释和提示!
是的,你可以。
我为 UNSWNB 数据集测试它,它给我错误消息
'DataFrame' object has no attribute 'values'
也许将您的代码和错误发布到 stackoverflow?
嗨,Jason!
我正在编写一个预测能源消耗的代码
我尝试使用 print(history.history.keys()),但它对我不起作用!我收到一个 KeyError: 'val_mean_absolute_percentage_error'
你能帮我吗?
这是我的代码
from __future__ import print_function
from sklearn.metrics import mean_absolute_error
import math
import numpy as np
import matplotlib.pyplot as plt
from pandas import read_csv
来自 keras.models import Sequential
from keras.layers import Dense, LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
# 将值数组转换为数据集矩阵
def create_dataset(dataset, look_back=1)
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1)
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# 设置随机种子以保证结果可复现
np.random.seed(7)
# 加载数据集
dataframe = read_csv('OND_Q4.csv', usecols=[7], engine='python', header=3) #wind-SPEED
dataset = dataframe.values
print(dataframe.head)
dataset = dataset.astype(‘float32′)
# 规范化数据集
scaler = MinMaxScaler(feature_range=(0, 1))
数据集 = scaler.fit_transform(数据集)
# 拆分为训练集和测试集
train_size = int(len(dataset) * 0.7) # 使用 70% 的数据进行训练
test_size = len(dataset) – train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# 重塑为 X=t 和 Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 重塑输入为 [样本,时间步,特征]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# 创建并拟合 LSTM 网络
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
##########################################################################################################################################
# 编译模型
model.compile(loss='mean_squared_error', optimizer='adam',metrics=['mape'])
history=model.fit(trainX, trainY, epochs=5, batch_size=1, verbose=2)
# 列出历史中的所有数据
print(history.history.keys())
train_MAPE = history.history['mape']
valid_MAPE = history.history['val_mean_absolute_percentage_error']
train_MSE = history.history['loss']
valid_MSE = history.history['val_loss']
谢谢你
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
在 582 个样本上进行训练,在 146 个样本上进行验证
第 1/200 纪元
—————————————————————————
KeyError 回溯(最近的调用在最后)
in
----> 1 model.fit(X_train, y_train, epochs=200, validation_data=(X_test, y_test), callbacks=[mcp_save], batch_size=128)
~\AppData\Roaming\Python\Python36\site-packages\keras\models.py 中的 fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, **kwargs)
865 class_weight=class_weight,
866 sample_weight=sample_weight,
--> 867 initial_epoch=initial_epoch)
868
869 def evaluate(self, x, y, batch_size=32, verbose=1,
~\AppData\Roaming\Python\Python36\site-packages\keras\engine\training.py 中的 fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs)
1596 initial_epoch=initial_epoch,
1597 steps_per_epoch=steps_per_epoch,
-> 1598 validation_steps=validation_steps)
1599
1600 def evaluate(self, x, y,
~\AppData\Roaming\Python\Python36\site-packages\keras\engine\training.py 中的 _fit_loop(self, f, ins, out_labels, batch_size, epochs, verbose, callbacks, val_f, val_ins, shuffle, callback_metrics, initial_epoch, steps_per_epoch, validation_steps)
1170 if isinstance(ins[-1], float)
1171 # 不切片训练阶段标志。
-> 1172 ins_batch = _slice_arrays(ins[:-1], batch_ids) + [ins[-1]]
1173 else
1174 ins_batch = _slice_arrays(ins, batch_ids)
~\AppData\Roaming\Python\Python36\site-packages\keras\engine\training.py 中的 _slice_arrays(arrays, start, stop)
404 if hasattr(start, 'shape')
405 start = start.tolist()
--> 406 return [None if x is None else x[start] for x in arrays]
407 else
408 return [None if x is None else x[start:stop] for x in arrays]
~\AppData\Roaming\Python\Python36\site-packages\keras\engine\training.py 中的 (.0)
404 if hasattr(start, 'shape')
405 start = start.tolist()
--> 406 return [None if x is None else x[start] for x in arrays]
407 else
408 return [None if x is None else x[start:stop] for x in arrays]
~\Anaconda3\envs\tensorflow1\lib\site-packages\pandas\core\frame.py 中的 __getitem__(self, key)
2999 if is_iterator(key)
3000 key = list(key)
--> 3001 indexer = self.loc._convert_to_indexer(key, axis=1, raise_missing=False)
3002
3003 # take() 不接受布尔索引器
~\Anaconda3\envs\tensorflow1\lib\site-packages\pandas\core\indexing.py 中的 _convert_to_indexer(self, obj, axis, is_setter, raise_missing)
1283 # 设置时,不允许缺少键,即使使用 .loc
1284 kwargs = {"raise_missing": True if is_setter else raise_missing}
-> 1285 return self._get_listlike_indexer(obj, axis, **kwargs)[1]
1286 else
1287 try
~\Anaconda3\envs\tensorflow1\lib\site-packages\pandas\core\indexing.py 中的 _get_listlike_indexer(self, key, axis, raise_missing)
1090
1091 self._validate_read_indexer(
-> 1092 keyarr, indexer, o._get_axis_number(axis), raise_missing=raise_missing
1093 )
1094 return keyarr, indexer
~\Anaconda3\envs\tensorflow1\lib\site-packages\pandas\core\indexing.py 中的 _validate_read_indexer(self, key, indexer, axis, raise_missing)
1175 raise KeyError(
1176 "None of [{key}] are in the [{axis}]".format(
-> 1177 key=key, axis=self.obj._get_axis_name(axis)
1178 )
1179 )
KeyError: "None of [Int64Index([148, 425, 97, 486, 306, 454, 483, 485, 79, 246,\n ...\n 101, 469, 172, 401, 176, 470, 374, 66, 200, 308],\n dtype='int64', length=128)] are in the [columns]"
你好 jason,
你能帮我摆脱这个错误吗?我搜了很多网站,但都没有帮到我。我希望你能帮我。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
history.history.keys() 现在返回 ['acc', 'loss', 'val_acc', 'val_loss']...
'accuracy' 缩短为 'acc'
不,您需要将 Keras 版本更新到 2.3.1。
大家好,
我是一名机器学习初学者。在做项目时,我遇到了一个我不清楚的问题。
我的问题是,在 model.fit() 函数完成后的最后一个 epoch 中显示的损失值与我从 model.evaluate() 函数中得到的损失值不同。然而,这两个提供者之间的 val_loss 值显示出绝对一致性。
请查看下面的结果,帮助我解决问题。
——
"model.compile(loss='mse', optimizer=adadel, metrics=['mse','mae'])
history = model.fit(x, y, nb_epoch=10, batch_size=32, validation_data=(x_test, y_test))"
第 10/10 纪元
8/8 [==============================] - 0s 1ms/step - loss: 0.2280 - mse: 0.2280 - mae: 0.3640 - val_loss: 0.1704 - val_mse: 0.1704 - val_mae: 0.317
——
evaluation = model.evaluate(x, y)
8/8 [==============================] - 0s 250us/step
评估:[0.1698070764541626, 0.1698070764541626, 0.3129541277885437]
-----------------------------
最后一个 epoch 中“loss”的损失值为 0.2280,而 evaluate(x,y) 的值为 0.1698……
是的,这是对批次平均性能的估计或平均值。
我建议关注 evaluate() 函数的结果。
非常感谢您的帮助,Jason Brownlee!
您能否帮助我解决一个后续问题,例如:
我想通过绘制“损失值”和“验证损失值”(从 fit() 函数获得)随 epoch 的变化来评估模型的训练熟练程度,但 evaluate() 函数是我们应该关注的。
那么您能推荐我应该如何进行评估吗?
历史记录由对 fit() 的调用返回,您无法从对 evaluate() 的调用中获取此信息。
非常感谢您的回复。
正如我在一些论坛上看到的例子,他们绘制了“损失值”和“验证损失值”(从 fit() 函数获得)随 epoch 的变化,并使用该图来评估模型的性能。
这是否是评估模型的足够标准?
它只是一个诊断工具。模型通过选择基于项目需求的指标来评估,并设计一个测试工具来以它将在操作中用于新数据预测的方式评估模型。通常是重复的 k 折交叉验证。
嗯,我明白了问题。
非常感谢您的帮助!
不客气。
嗨,Jason,
我正在运行这个示例,但我使用的是交叉验证(StratifiedKFold)并且我使用了 k-fold = 10。我如何收集每个交叉验证折叠中评估的每个模型的历史记录?我该怎么做?
我的模型历史记录只有键 ['acc', 'loss'],但我不知道这些键属于哪个折叠或模型??
如果您手动使用 for 循环运行折叠,则可以。
非常感谢您,Jason,
但是否有可能在同一张图上获取所有 k 折交叉验证的训练过程?
是的,我相信我的博客上有一些例子。我想对于图像分类,您可以使用博客搜索。
嗨,Jason,
您的博客帮助我轻松学习了机器学习。为此感谢您。我尝试获取一些其他数据集的准确度……我将我的代码和图表附在下面的链接中。请查看并评论它是否正常……此外,我添加了许多层只是为了获得良好的准确度(因此我得到了平坦的线条)。您提出的任何建议都会有所帮助。
此致
https://drive.google.com/folderview?id=12WRXmBU2QDjIc8p6LEHm5t8CPoOmPcRk
谢谢,很高兴听到这个。
抱歉,我没有能力审查/调试您的代码
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
谢谢,我的问题是,在训练我的模型之后,我将其保存到磁盘 model.save('...')
然后我运行 load_model('...') 来绘制一些函数
但如果我运行 print(model.history),我得到这个错误“对象没有历史属性”
我的拟合看起来是这样的
history=model.fit(X_train, Y_train, nb_epoch=5, batch_size=16, callbacks=[history])
如果我想稍后使用它,我应该将历史记录保存在列表中吗?
模型没有名为 history 的属性,并且 history 不会被保存。
您必须拟合模型,并且 fit() 函数将返回一个名为 history 的字典。
你好,Jason。
我一直在阅读您的《深度学习与 Python》一书(顺便说一句,这是一本很棒的书),我刚刚读完专门介绍从 Keras 训练中读取历史记录的章节(本页面似乎就是基于此的)。
令我沮丧的是,下一章使用了带有 cross_val_score 和 StatifiedKFold 的 sklearn KerasClassifier,这使得我无法直接将此历史代码与该示例中的声纳数据集一起使用。
我接着编写了自己的 Keras 回调类,以便在 k 折交叉验证的上下文中手动构建历史记录(这实质上意味着同一图表上的一堆历史记录线……每个 K 折分割对应一条)。
我相当成功地实现了这个目标,但图表给我带来了一些非常有趣的结果,我想向您请教。
准确度图表像您此页面上的示例一样增加,但随后它实际上达到了 1!并趋于平稳(因为它达到了上限,准确度不能大于 1)。
我的困惑由此开始。如果整个 epoch 都训练到了 1 的分数……为什么 cross_val_score 返回的基线分数约为 0.8 呢?
我的第一直觉是存在我没有计算的单独验证分数(训练集得到 1 分,但验证得到较低分数)……但我尝试了 Keras 回调上的 on_test 函数,它们根本没有执行,所以我排除了这一点。
我还排除了我的代码中的错误(没有舍入错误等……),因为我确认 on_train_batch_end 回调中的 logs['accuracy'] 在整个 epoch 的所有批次中都返回 1。
如果您需要更多详细信息,或者想和我一起查看代码,请随时给我发电子邮件。现在,我只想知道为什么总分不是 1.0,因为整个 epoch 都训练到了 1。
谢谢,你做得很好!
是的,要使用 history,需要直接使用 Keras API。
是的,准确率不能高于 1,即 100%。
抱歉,我不明白这个问题。你说的“基线分数”是什么意思?
好的,所以一般的流程是这样的
– estimators = []
– estimators.append((‘mlp’, KerasClassifier(…)))
– pipeline = Pipeline(estimators)
– kfold = StratifiedKFold(…)
– results = cross_val_score(pipeline,… , fit_params={…myCallbackhere…})
– print(“Baseline: %.2f%% (%.2f%%)” % (results.mean() * 100, results.std() * 100))
这是 cross_val_score 函数返回的基线分数(通常返回约 80-85%,带标准差)
请参阅《Python 深度学习》第 15.2 章,该章首先创建了一个基线,然后深入探讨了 Dropout 正则化。
好的,我想你是在问为什么我们在训练集上表现良好,而在测试集或跨测试集的摘要上表现不佳。
原因在于模型过度拟合了训练集,导致泛化性能更差——即在测试集上表现更差。
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
这有帮助吗?
问题是,据我所知,根本没有进行测试,只有训练(on_train 的回调函数触发了,但 for this code 的 on_test 根本没有执行)
也许一个非常简单的例子可以更好地说明我所看到的情况
—— 以我之前的评论中的代码为例,我向其中添加了以下内容
—— print(results)
—— print(history.getScores()) # history 是我创建的 keras 回调类。
我还将训练设置为以下内容
—— epochs = 2
—— n_splits = 3
—— batch_size=1000
这将允许我们看到一个简单的 2x3 网格,其中包含 keras 回调中 on_train > log['accuracy'] 返回的所有原始分数。
输出如下:
—— print(results) 的输出
— [0.55714285 0.52173913 0.60869563]
—— print(history…) 的输出
— 0 1 2
— 0 0.411932 0.370432 0.589976
— 1 0.461256 0.380024 0.625300
这个 pandas 数据框中的每一列对应于那 3 个 n_splits 中的一个,并且有 2 行,因为有 2 个 epochs
结果似乎也对应于 n_splits …
—— 所以直观上,我希望结果中的第一个值是历史数据框中第一列的平均值……但这并非如此
我想知道为什么我不能使用 keras 回调来重现 cross_val_score 返回的分数……我应该能做到,对吧?
据我所知,历史记录中的分数是跨批次平均的,而不是数据集的真实分数。
嗨 Jason
你最新的评论没有回复按钮,所以在这里回复
这些分数不会自动平均(每个批次都会触发对 on_train 的单独调用)
这就是为什么我将 batch_size 设置为 1000,在一个只有大约 200 条记录的数据集上,这导致每个 epoch 一个批次。单个数字的平均值就是它本身,所以我不认为这是问题所在。
说得有理。
太棒了……我遇到困难时总是参考你的文章……请告诉我如何加载“history”并重新使用模型进行绘图和后续预测……
我正在使用 pickle 倾倒历史记录,如下所述
pickle.dump(H.history, open(filename, 'wb'))
并想加载,如下所述
Hist_later = pickle.load(filename)
请帮忙……
好的,我想我明白了……完成了……
当我将“H.history”存储到 Hist_later 时
那么我应该绘制
“plt.plot(np.arange(0, N), Hist_later [“loss”], label=”train_loss”)”
而不是
“plt.plot(np.arange(0, N), Hist_later.history[“loss”], label=”train_loss”)”
我很高兴听到您解决了您的问题。
抱歉,我没有保存历史记录的示例。
我相信你可以像你建议的那样使用 pickle 来保存和加载历史对象。
您好,先生!打扰您很抱歉,但是您的博客非常棒,内容本身就非常有帮助,评论区就像一个额外福利。所以我希望我没有提出太多问题,因为我不想滥用您的好意。
我的疑问是:我如何正确评估模型并检测过拟合或欠拟合?我阅读了您关于“诊断过拟合”的另一篇文章,但是回到这个更简单的训练示例,我有一些疑问。
我总是将数据集在一开始就分成训练/测试(以免任何类型的预处理对数据造成偏差)。如果我进行某种模型评估,我会将训练集分成训练集和评估集。
最后,在我“发现”最佳模型后,我将所有训练数据(不进行验证拆分)进行拟合,并使用最初的测试集来评估性能。这是正确的吗?
我该如何评估整体性能?我用训练数据调用 model.evaluate,然后用测试数据调用。但是,我在训练数据上获得了 100% 的准确率,在测试数据上获得了 67% 的准确率。我假设我的模型过拟合了。但是,无论我做任何更改,我总是在训练数据上获得 100% 的准确率。这正常吗?
谢谢。
这将有助于检测过拟合/欠拟合
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
嗨,Jason,
感谢这篇教程。
我想通过在一个图表中绘制两个模型的训练准确率来比较它们。如何实现呢?
也许将每个模型的训练准确率向量存储到文件中,然后编写第二个程序来加载每个文件并将其绘制成线图。
嗨 Jason
感谢教程。
训练时我忘记存储模型历史记录,像这样
history = model.fit( trainX, trainY, …)。
现在我需要模型的准确率和损失来绘制图表。我如何获取这些准确率和损失?还是我必须重新训练模型?
你将不得不重新训练你的模型。
非常感谢
不客气!
你知道如果使用管道如何生成这些图表吗?我遇到了错误:AttributeError: 'Pipeline' object has no attribute 'history'
您必须直接使用 Keras API。
Jason,
感谢您分享您的知识,您的文章总是很有帮助。我正在构建一个回归模型。训练期间损失函数波动是正常的吗?我对此有点担心,因为我期望损失值收敛。有没有推荐的解决方法?
谢谢!
是的。它应该呈下降趋势。
您好,感谢您的快速回复。不幸的是,我不太确定是否理解您的回复。它应该呈下降趋势是指只要它下降,波动就是正常的吗?还是收敛是应该确保的条件?
如果损失呈下降趋势,这可能表明模型正在收敛。
你好,Jason。我想知道,如何绘制不同 epoch 的历史记录?例如,我训练 LSTM 模型 10 个 epoch,然后再次用 5 个 epoch 重新训练,不同 epoch 是否可能具有相同的损失曲线图?如果可能,我该如何操作?请您建议一下,谢谢!
您可以为每次运行创建一个折线图,或者简单地保存历史记录并在将来创建任何您喜欢的图表。
也许我不明白你遇到的具体问题?
因为我尝试在训练期间更改优化器,并且我希望在训练期间结合优化器能够绘制图表。
你好,Jason。我想知道,如何绘制不同 epoch 的损失函数?例如,我用 Adam 优化器训练 LSTM 模型 10 个 epoch,然后在 10 个 epoch 后,我尝试更改为 SGD 优化器并训练 5 个 epoch。那么,如何在同一个损失函数线图上绘制 15 个 epoch(10 个用 Adam,5 个用 SGD)的损失函数?请您解释一下,谢谢。
收集或存储每次运行的绘图,然后将数组连接起来并绘制线。
你可以绘制任何你想要的东西。
很棒的教程。
我训练了一个 CNN 模型,epochs=200。
我想获取在验证准确率最高时该模型的权重。
我知道代码 model.fit(verbose=1) 会显示每个 epoch 的值。
我该怎么做?
您可以使用提前停止或检查点。
也许从这里开始
https://machinelearning.org.cn/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
有人能帮我找到图表中的验证准确率吗?
上面的教程向您展示了如何从训练历史记录中创建折线图。
你好 Jason,
首先祝贺您的工作,它帮助很大,但我有一个问题。
在我的准确率图(以及损失图)中,两个数据集的趋势方向相反。我尝试更改层数、层中的神经元数量、批次大小和 epoch 数量,但都没有改变。
您对这个问题有什么想法吗?
非常感谢!!
是的,损失会下降,准确率会上升,这是正常的。
嗨,Jason,我们在这里谈话时你向我推荐了这篇文章:https://machinelearning.org.cn/difference-test-validation-datasets/#comment-594088
我正在按照本文中提到的方法进行操作。正如你在这里提到的 https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset/,通常不建议将测试集用作验证集。但是由于我正在手动逐个更改超参数并对每个组合运行整个模型,我不需要使用验证集来调整它们或检测提前停止。那么我可以使用验证准确率作为测试准确率吗,因为验证集是一个未用于训练模型的保留数据集?
提前感谢!
我不推荐这种方法,因为你最终可能会使模型过度拟合你的数据集。
理想情况下,您应该保留一些数据,在模型选择/超参数调整期间不触及这些数据,以进行最终的模型评估。
对所有算法和调整重复使用所有数据可能会导致您找到一个只在您的特定示例上表现良好的模型和配置。
哦,现在我明白了。
非常感谢!
不客气。
最好的网站之一,我得到了很好的虚拟指导。
非常感谢您以如此美妙的方式分享知识。
感谢您的美言!
我如何为 3 个不同的模型在同一图上绘制图表?例如,我想在同一图上绘制 DenseNet、EfficientNet 和 ResNet 的准确率与 epoch 数量的图表。
我该怎么做?
将数据保存到文件,加载每个轨迹并将其添加到单个图中。
我喜欢你的博客,它太有帮助了!非常感谢
不客气!
谢谢你!觉得它真的很有帮助!!
不客气!
如何在 Python 中计算模型的执行时间?我们根据什么来计算模型执行时间?
您可以使用 timeit
https://docs.pythonlang.cn/3/library/timeit.html
我固定了 epoch、batch size 和所有参数。每次训练模型时,我都会得到不同的准确率、损失、验证准确率和验证损失。但我使用的所有参数都相同。你能帮我解答这个疑问吗?
是的,请看这个
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
当我使用迁移学习时,它比从头开始开发的模型花费更多的时间。为什么会出现这种情况?现有模型不是已经训练好了吗?
这听起来不对。
也许再次检查你的代码。
除了损失、准确率、验证损失、验证准确率之外,我们还能在历史记录中添加更多变量吗?我们能添加更多指标吗?这个损失是如何计算的?
是的,你可以指定任意多的内置函数或自定义函数。
Brownlee 博士,
先生,请教一个简短的问题。在教程中,您在调用“history”之前对 X 和 y 运行了 .fit(),并让 Python 使用该数据输出训练和验证图。有没有办法对交叉验证(在本例中为 cross_val_score)执行此操作,以便输出按折叠绘制或作为所有折叠的聚合?
您可以看到历史记录中有一个键“val_loss”,它为您提供验证指标。如果您想添加更多指标,或制作一些定制指标,您可以从文档中查看:https://tensorflowcn.cn/guide/keras/train_and_evaluate#custom_metrics
谢谢,Adrian!如果我可以再问一个问题:假设我正在运行 10 折交叉验证,并希望为每个单独的折叠输出准确率和/或损失与 epoch 的图表。这可能吗?我卡住的地方是弄清楚将绘图命令放在哪里,因为在我看来,我必须在 cross_val_score 内部调用绘图函数,而且我不确定如何实现这一点。
不阅读您的代码,但我可以概述您可能做的事情:您在循环中执行 10 折交叉验证,每次迭代一个折叠。然后您需要记住您所处的迭代,并将指标记住到一个单独的数组中。完成所有交叉验证后,将这 10 个数组绘制成 10 条曲线。
你好。我正在寻找一种方法来访问用 Python 训练的模型中的数据。例如,我可以从用 faster rcnn 训练的模型末尾获得的推理图中访问我训练的数据吗?
谢谢,但我尝试这个例子时出现错误
plt.plot(history.history['val_accuracy'])
KeyError: 'val_accuracy'
这意味着您没有进行验证,或者您没有在验证中保留准确率分数。
示例中是否缺少一行代码,因为我觉得我完全按照示例操作,但在 plt.plot(history.history['val_accuracy]) 处出现了相同的错误
KeyError: 'val_accuracy'
嗨,ML_New_Learner……你是不是把“val_accuracy”末尾的单引号'漏掉了?
嗨,Adrian。你知道我的问题吗?谢谢。
你是在说取回你用来训练模型的数据吗?我认为这不可能,因为模型不会记住它。
谢谢你的回复。
嗨,Jason,
感谢您为制作这些精彩教程所做的辛勤工作。我有一个问题,在我的模型中,模型在测试集上的表现要好得多,即 0.94,而在训练集上的表现却很差,只有 0.78(在微调超参数、打乱交叉验证 [StratifiedKFold 和 StratifiedShuffleSplit] 并考虑类别不平衡之后)。
我的数据集严重不平衡,并且是一种高维数据,不应使用 SMOTE 及其变体(尽管我测试了 SMOTE 和 ADASYN 以检查其有效性)。
为了解决不平衡问题,我测试了 1) class_weight = “balanced” 参数调优 2) 手动类权重调优和 3) 样本权重。唯一能提高测试集性能的解决方案是设置样本权重调优。在这里,此分类问题的性能要好得多,但我担心训练集上的糟糕表现与测试集上提高的性能之间的差异。
您能提出一个解决方案吗?
提前感谢,
嗨,Dash……以下讨论可能会引起您的兴趣
https://www.researchgate.net/post/When_can_Validation_Accuracy_be_greater_than_Training_Accuracy_for_Deep_Learning_Models
谢谢
詹姆斯你好,你的帖子对我很有用!
我该如何绘制 RNA 权重图,以便查看哪种配置是最好的
嗨,Paublo……非常欢迎!请澄清“绘制 RNA 权重”的含义,以便我们更好地协助您。
你好,当我从 fit 中创建 history,例如 history = model.fit(...) 时,它真的拟合模型还是只是创建 history?
此致
嗨,Kong……以下资源可能会增加清晰度
https://towardsdatascience.com/fit-vs-predict-vs-fit-predict-in-python-scikit-learn-f15a34a8d39f
你可以检查你的 history.history 字典中包含哪些序列。
print(history.history.keys())
在我的例子中,键是“val_acc”。我的猜测是它在较新版本中被重命名了。
非常感谢!!你不知道我为了寻找这样的解决方案付出了多少努力。
你好,
感谢这篇精彩的文章。
在你的代码中,你绘制了训练准确率和 val_accuracy。
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
然而,图例显示为 Train 和 Test。
图例不应该显示 Train 和 Validation 吗,而不是 Test?
彼得
感谢您的反馈,Peter!