动态分类器选择是一种用于分类预测建模的集成学习算法。
该技术涉及在训练数据集上拟合多个机器学习模型,然后根据要预测的示例的具体细节,选择在进行预测时预计表现最佳的模型。
这可以通过使用k-近邻模型来定位训练数据集中最接近要预测的新示例的示例,在邻域上评估池中的所有模型,并使用在邻域上表现最佳的模型来预测新示例来实现。
因此,动态分类器选择通常可以比池中的任何单个模型表现更好,并且为平均多个模型的预测提供了替代方案,就像其他集成算法中的情况一样。
在本教程中,您将了解如何在Python中开发动态分类器选择集成。
完成本教程后,您将了解:
- 动态分类器选择算法为每个新示例选择一个模型来进行预测。
- 如何使用scikit-learn API为分类任务开发和评估动态分类器选择模型。
- 如何探索动态分类器选择模型的超参数对分类准确性的影响。
开始您的项目,阅读我的新书Python集成学习算法,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何在Python中开发动态分类器选择
照片由Jean and Fred拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 动态分类器选择
- 使用Scikit-Learn进行动态分类器选择
- DCS与总体局部准确度 (OLA)
- DCS与局部类别准确度 (LCA)
- DCS的超参数调整
- 探索k-近邻中的k
- 探索分类器池的算法
动态分类器选择
多分类器系统是指使用多个模型来解决分类预测建模问题的机器学习算法领域。
这包括诸如一对多、一对一和输出误差纠正码等熟悉的技术。它还包括更通用的技术,这些技术动态地选择一个模型来为需要预测的每个新示例进行预测。
目前有几种方法用于构建MCS [...] 最有前途的MCS方法之一是动态选择(DS),其中基础分类器是根据每个新的样本进行即时选择的。
— 动态分类器选择:近期进展与观点,2018年。
有关更多此类多分类器系统,请参阅教程
这些方法通常被称为:动态分类器选择,或简称DCS。
- 动态分类器选择:根据输入的具体细节,从多个训练模型中选择一个模型进行预测的算法。
鉴于DCS使用了多个模型,它被认为是一种集成学习技术。
动态分类器选择算法通常涉及以某种方式划分输入特征空间,并为每个分区分配特定的模型负责进行预测。有各种不同的DCS算法,研究工作主要集中在如何评估和分配分类器到输入空间的特定区域。
在训练了多个个体学习器之后,DCS为每个测试实例动态地选择一个学习器。 [...] DCS通过使用一个学习器进行预测。
— 第93页,集成方法:基础与算法,2012年。
一种早期流行的方法是首先在训练数据集上拟合一小组多样化的分类模型。当需要预测时,首先使用k-近邻(kNN)算法从与该示例匹配的训练数据集中找到k个最相似的示例。然后,在k个训练示例的邻域上评估模型中先前拟合的每个分类器,并选择表现最佳的分类器来预测新示例。
这种方法被称为“动态分类器选择局部准确度”或简称DCS-LA,由Kevin Woods等人于1997年题为“组合多个分类器使用局部准确度估计”的论文描述。
基本思想是估计每个分类器在未知测试样本周围的特征空间的局部区域的准确性,然后使用最局部准确的分类器的决策。
— 使用局部准确度估计组合多个分类器,1997年。
作者描述了两种为给定输入示例选择单个分类器模型进行预测的方法,它们是
- 局部准确度,通常称为LA或总体局部准确度(OLA)。
- 类别准确度,通常称为CA或局部类别准确度(LCA)。
局部准确度(OLA)涉及评估每个模型在k个训练示例的邻域上的分类准确性。然后选择在该邻域上表现最佳的模型来预测新示例。
每个分类器的OLA计算为局部区域中样本的正确识别百分比。
— 动态选择分类器——全面综述,2014年。
类别准确度(LCA)涉及使用每个模型为新示例做出预测,并记录预测的类别。然后,评估每个模型在k个训练示例邻域上的准确性,并选择在它对新示例预测的类别方面具有最佳技能的模型,并返回其预测。
LCA估计为每个基础分类器在局部区域内的正确分类百分比,但仅考虑那些分类器给出的类别与它为未知模式给出的类别相同的示例。
— 动态选择分类器——全面综述,2014年。
在这两种情况下,如果所有拟合模型都对新的输入示例做出相同的预测,则直接返回该预测。
现在我们熟悉了DCS和DCS-LA算法,让我们看看如何将其用于我们自己的分类预测建模项目。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用Scikit-Learn进行动态分类器选择
动态集成选择库(DESlib)是一个开源Python库,它实现了许多不同的动态分类器选择算法。
DESlib是一个易于使用的集成学习库,专注于实现动态分类器和集成选择的最新技术。
首先,我们可以使用pip包管理器安装DESlib库。
|
1 |
sudo pip install deslib |
安装后,我们可以通过加载库并打印已安装的版本来确认库已正确安装并准备就绪。
|
1 2 3 |
# 检查deslib版本 import deslib print(deslib.__version__) |
运行脚本将打印您已安装的DESlib库的版本。
您的版本应相同或更高。如果不是,您必须升级您的DESlib库版本。
|
1 |
0.3 |
DESlib通过OLA和LCA类分别提供了DCS-LA算法的实现,包括每种分类器选择技术。
每个类都可以直接用作scikit-learn模型,从而允许直接使用完整的scikit-learn数据准备、建模管道和模型评估技术。
这两个类都使用k-近邻算法来选择邻居,默认值为k=7。
默认情况下,使用装袋决策树的装袋聚合(bagging)集成作为分类器模型池,尽管可以通过设置“pool_classifiers”为模型列表来更改。
我们可以使用make_classification()函数创建一个具有10,000个示例和20个输入特征的合成二元分类问题。
|
1 2 3 4 5 6 |
# 合成二元分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(10000, 20) (10000,) |
现在我们熟悉了DESlib API,让我们看看如何使用每个DCS-LA算法。
DCS与总体局部准确度 (OLA)
我们可以使用总体局部准确度在合成数据集上评估DCS-LA模型。
在这种情况下,我们将使用默认的模型超参数,包括装袋决策树作为分类器模型池,以及k=7用于在进行预测时选择局部邻域。
我们将使用重复分层 k 折交叉验证来评估模型,重复三次,折数为 10。我们将报告模型在所有重复和折中的平均准确率和标准差。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用总体局部准确度评估动态分类器选择DCS-LA from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from deslib.dcs.ola import OLA # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = OLA() # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('平均准确度: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例报告了模型的平均准确度和标准差。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性,或者数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到,具有OLA和默认超参数的DCS-LA的分类准确度约为88.3%。
|
1 |
平均准确度: 0.883 (0.012) |
我们还可以将DCS-LA模型与OLA一起用作最终模型,并进行分类预测。
首先,模型在所有可用数据上进行拟合,然后可以调用predict()函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 使用总体局部准确度用DCS-LA进行预测 from sklearn.datasets import make_classification from deslib.dcs.ola import OLA # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = OLA() # 在整个数据集上拟合模型 model.fit(X, y) # 进行单次预测 row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808] yhat = model.predict([row]) print('预测类别: %d' % yhat[0]) |
运行示例将DCS-LA与OLA模型拟合到整个数据集上,然后用于预测新数据行,就像我们在应用程序中使用模型一样。
|
1 |
预测类别:0 |
现在我们熟悉了使用DCS-LA与OLA,让我们看看LCA方法。
DCS与局部类别准确度 (LCA)
我们可以使用局部类别准确度在合成数据集上评估DCS-LA模型。
在这种情况下,我们将使用默认的模型超参数,包括装袋决策树作为分类器模型池,以及k=7用于在进行预测时选择局部邻域。
我们将使用重复分层 k 折交叉验证来评估模型,重复三次,折数为 10。我们将报告模型在所有重复和折中的平均准确率和标准差。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用局部类别准确度评估动态分类器选择DCS-LA from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from deslib.dcs.lca import LCA # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = LCA() # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('平均准确度: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例报告了模型的平均准确度和标准差。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性,或者数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到,具有LCA和默认超参数的DCS-LA的分类准确度约为92.2%。
|
1 |
平均准确度: 0.922 (0.007) |
我们还可以将DCS-LA模型与LCA一起用作最终模型,并进行分类预测。
首先,模型在所有可用数据上进行拟合,然后可以调用predict()函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 使用局部类别准确度用DCS-LA进行预测 from sklearn.datasets import make_classification from deslib.dcs.lca import LCA # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = LCA() # 在整个数据集上拟合模型 model.fit(X, y) # 进行单次预测 row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808] yhat = model.predict([row]) print('预测类别: %d' % yhat[0]) |
运行示例将DCS-LA与LCA模型拟合到整个数据集上,然后用于预测新数据行,就像我们在应用程序中使用模型一样。
|
1 |
预测类别:0 |
现在我们熟悉了使用scikit-learn API来评估和使用DCS-LA模型,让我们来看看配置模型。
DCS的超参数调整
在本节中,我们将仔细研究一些您应该考虑为DCS-LA模型调整的超参数,以及它们对模型性能的影响。
DCS-LA有许多超参数可以研究,尽管在这种情况下,我们将研究k-近邻模型中用于模型局部评估的k值,以及如何使用自定义分类器池。
我们将以DCS-LA与OLA为基础进行这些实验,尽管具体方法的选择是任意的。
探索k-近邻中的k
k-近邻算法的配置对DCS-LA模型至关重要,因为它定义了每个分类器被考虑用于选择的邻域范围。
k值控制着邻域的大小,将其设置为适合您数据集的值很重要,特别是特征空间中样本的密度。过小的值意味着相关示例可能被排除在邻域之外,而过大的值可能意味着信号被太多示例淹没了。
下面的示例探讨了DCS-LA与OLA的分类准确度,k值从2到21。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 探索DCS-LA与总体局部准确度中knn的k值 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from deslib.dcs.ola import OLA from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() for n in range(2,22): models[str(n)] = OLA(k=n) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告每个配置的邻域大小的平均准确度。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性,或者数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到准确度随着邻域大小的增加而增加,可能到k=13或k=14,此时似乎趋于平稳。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>2 0.873 (0.009) >3 0.874 (0.013) >4 0.880 (0.009) >5 0.881 (0.009) >6 0.883 (0.010) >7 0.883 (0.011) >8 0.884 (0.012) >9 0.883 (0.010) >10 0.886 (0.012) >11 0.886 (0.011) >12 0.885 (0.010) >13 0.888 (0.010) >14 0.886 (0.009) >15 0.889 (0.010) >16 0.885 (0.012) >17 0.888 (0.009) >18 0.886 (0.010) >19 0.889 (0.012) >20 0.889 (0.011) >21 0.886 (0.011) |
为每个配置的邻域大小的准确度分数分布创建了箱线图。
我们可以看到模型性能和k值增加然后达到平台期的总体趋势。
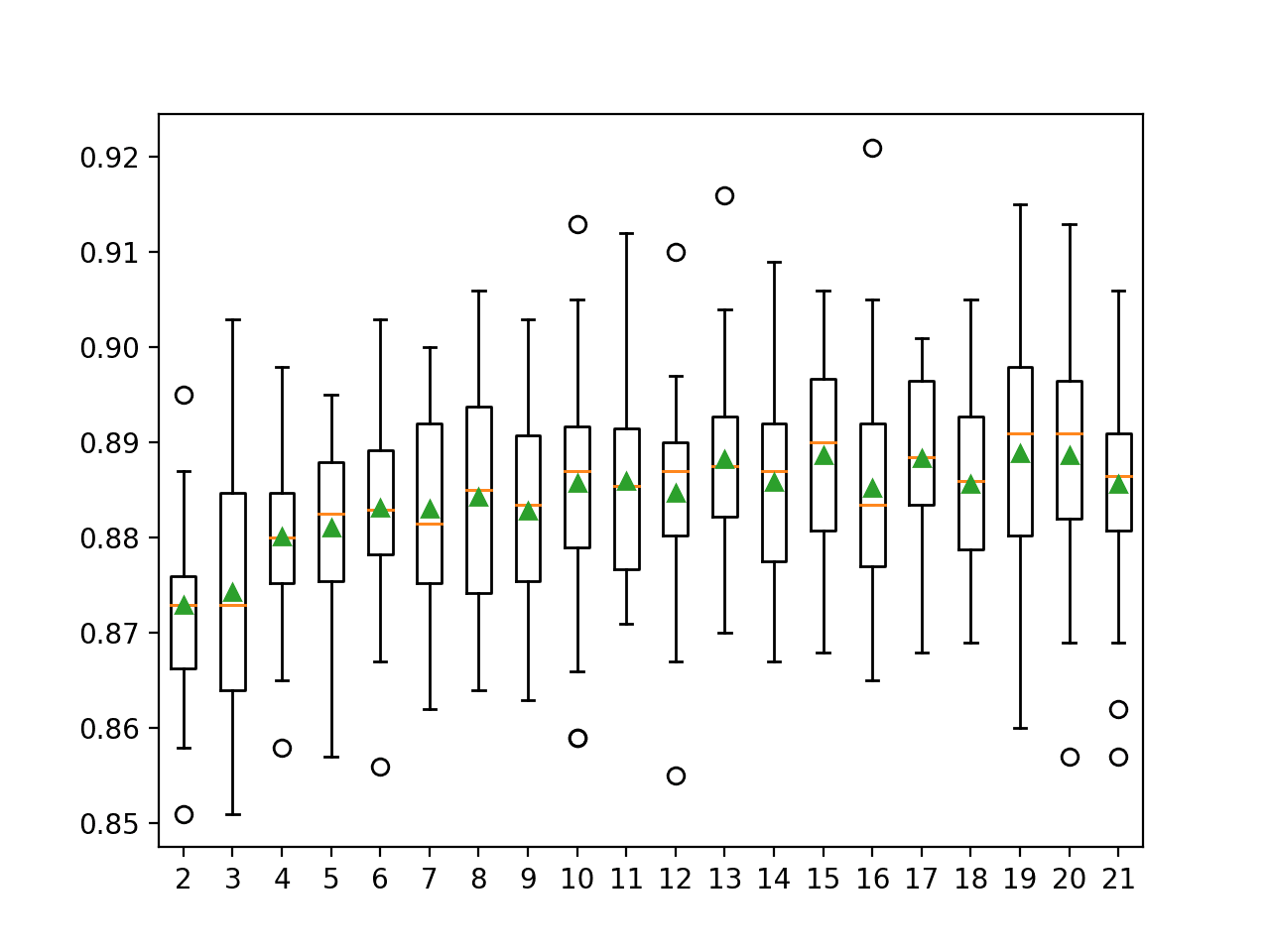
DCS-LA与OLA的k值准确度分布箱线图
探索分类器池的算法
DCS-LA的池中使用的算法选择是另一个重要的超参数。
默认情况下,使用装袋决策树,因为它已被证明在各种分类任务上是一种有效的方法。尽管如此,仍然可以考虑自定义分类器池。
这首先需要定义要使用的分类器模型列表,并在训练数据集上拟合每个模型。不幸的是,这意味着scikit-learn中的自动k折交叉验证模型评估方法在这种情况下不能使用。相反,我们将使用一个训练-测试分割,以便我们可以手动在训练数据集上拟合分类器池。
然后,可以通过“pool_classifiers”参数将拟合的分类器列表指定给OLA(或LCA)类。在这种情况下,我们将使用一个包含逻辑回归、决策树和朴素贝叶斯分类器的池。
在合成数据集上使用自定义分类器池评估DCS-LA与OLA的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 使用OLA和自定义算法池评估DCS-LA from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from deslib.dcs.ola import OLA from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.naive_bayes import GaussianNB X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 将数据集分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=1) # 定义要在池中使用的分类器 classifiers = [ LogisticRegression(), DecisionTreeClassifier(), GaussianNB()] # 在训练集上拟合每个分类器 for c in classifiers: c.fit(X_train, y_train) # 定义DCS-LA模型 model = OLA(pool_classifiers=classifiers) # 拟合模型 model.fit(X_train, y_train) # 对测试集进行预测 yhat = model.predict(X_test) # 评估预测 score = accuracy_score(y_test, yhat) print('准确度: %.3f' % (score)) |
运行示例首先报告带有自定义分类器池的模型平均准确度。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性,或者数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型实现了约91.2%的准确度。
|
1 |
准确度: 0.913 |
为了采用DCS模型,它必须优于任何贡献模型。否则,我们将仅使用表现更好的贡献模型。
我们可以通过评估每个贡献分类器在测试集上的表现来检查这一点。
|
1 2 3 4 5 6 |
... # 评估贡献模型 for c in classifiers: yhat = c.predict(X_test) score = accuracy_score(y_test, yhat) print('>%s: %.3f' % (c.__class__.__name__, score)) |
上面列出了带有自定义分类器池的DCS-LA的更新示例,这些分类器也单独进行评估。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 使用OLA和自定义算法池评估DCS-LA from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from deslib.dcs.ola import OLA from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.naive_bayes import GaussianNB # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 将数据集分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=1) # 定义要在池中使用的分类器 classifiers = [ LogisticRegression(), DecisionTreeClassifier(), GaussianNB()] # 在训练集上拟合每个分类器 for c in classifiers: c.fit(X_train, y_train) # 定义DCS-LA模型 model = OLA(pool_classifiers=classifiers) # 拟合模型 model.fit(X_train, y_train) # 对测试集进行预测 yhat = model.predict(X_test) # 评估预测 score = accuracy_score(y_test, yhat) print('准确度: %.3f' % (score)) # 评估贡献模型 for c in classifiers: yhat = c.predict(X_test) score = accuracy_score(y_test, yhat) print('>%s: %.3f' % (c.__class__.__name__, score)) |
运行示例首先报告带有自定义分类器池的模型平均准确度以及每个贡献模型的准确度。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性,或者数值精度的差异。考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到,DCS-LA再次实现了约91.3%的准确度,这优于任何贡献模型。
|
1 2 3 4 |
准确度: 0.913 >LogisticRegression: 0.878 >DecisionTreeClassifier: 0.884 >GaussianNB: 0.873 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
论文
- 使用局部准确度估计组合多个分类器, 1997.
- 动态选择分类器——全面综述, 2014.
- 动态分类器选择:近期进展与观点, 2018.
书籍
- 集成方法:基础和算法, 2012.
API
总结
在本教程中,您了解了如何在Python中开发动态分类器选择集成。
具体来说,你学到了:
- 动态分类器选择算法为每个新示例选择一个模型来进行预测。
- 如何使用scikit-learn API为分类任务开发和评估动态分类器选择模型。
- 如何探索动态分类器选择模型的超参数对分类准确性的影响。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……
 for Classification in Python")





非常有信息量的文章。我在这方面有几个疑问。可以使用池中的任何分类器,还是只能使用特定类型的分类器?另外,能否不使用k折交叉验证,而是使用循环提取每个折,并将分类器池应用于每个训练折?
提前感谢。
是的,我认为您可以使用任何分类器,请参阅“探索分类器池的算法”部分。
我们确实使用k折交叉验证来评估模型。无需提取分类器。
Jason,
您提到
“不幸的是,这意味着scikit-learn中的自动k折交叉验证模型评估方法在这种情况下不能使用。相反,我们将使用一个训练-测试分割,以便我们可以手动在训练数据集上拟合分类器池。”
是的,当使用自定义池时,我们不能使用CV,所有其他示例都使用CV。
这偏离主题了。您是如何写博客的?您使用 Jupyter 吗?
不行。
我使用文本编辑器来编写文字和代码,然后将它们全部放入 WordPress 博客中。
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/what-software-do-you-use-to-run-your-website
又一篇写得很好的文章!然而,我仍然有一些挥之不去的问题
1、模型如何进行特征选择?在运行模型之前,我需要预先选择重要的特征吗?
2、模型使用哪个特征空间来确定 K-最近邻?模型是否使用所有提供的特征?您可以手动选择 K-最近邻的特征吗?
2、我对模型的解释是它是非参数的,并且您需要每次都重新运行模型才能获得新预测,我说的对吗?
感谢您的时间。
谢谢。
您必须在建模之前准备好数据,包括特征选择。
它将数据按原样用于 k-nn。
与任何模型一样,您可以在训练后保存它,然后随时加载并进行预测。
非常感谢您精彩的博客!
谢谢!不客气。
很棒的课程。谢谢你的努力!
不客气!
嗨,Jason,
感谢这篇非常有趣的帖子。
我已经成功安装了 DESlib 库,但当我尝试使用 OLA() 模型进行单个预测时,它会引发此错误
NameError: name ‘_warn_for_nonsequence’ is not defined
我曾尝试搜索此错误,但徒劳无功。
欢迎任何建议
抱歉,我以前没见过这个错误。
请问可以使用动态集成方法进行回归吗?还是仅限于分类任务?
你好 EMD…以下资源是与您感兴趣的主题相关的绝佳起点
https://dl.acm.org/doi/10.1145/2379776.2379786