经验分布函数提供了一种为不符合标准概率分布的数据样本建模和采样累积概率的方法。
因此,它有时被称为经验累积分布函数,简称 ECDF。
在本教程中,您将了解经验概率分布函数。
完成本教程后,您将了解:
- 某些数据样本无法使用标准分布进行汇总。
- 经验分布函数提供了一种为数据样本建模累积概率的方法。
- 如何使用 statsmodels 库来建模和采样经验累积分布函数。
通过我的新书 机器学习概率 快速启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何在 Python 中使用经验分布函数
照片由 Gigi Griffis 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 经验分布函数
- 双峰数据分布
- 采样经验分布
经验分布函数
通常,数据样本的观测值分布符合已知的概率分布。
例如,人类的身高符合正态(高斯)概率分布。
但这并非总是如此。有时,收集的数据样本中的观测值不符合任何已知概率分布,并且无法通过数据变换或分布函数的参数化轻松地强制其符合现有分布。
相反,必须使用经验概率分布。
我们可能需要采样的概率分布函数主要有两种类型:
- 概率密度函数 (PDF)。
- 累积分布函数 (CDF)。
PDF 返回观察值的预期概率。对于离散数据,PDF 被称为概率质量函数 (PMF)。CDF 返回观察值小于或等于给定值的预期概率。
可以使用非参数密度估计方法(例如 核密度估计 (KDE))来拟合和使用经验概率密度函数进行数据采样。
经验累积分布函数称为经验分布函数,简称 EDF。它也称为经验累积分布函数,简称 ECDF。
EDF 的计算方法是:对数据样本中的所有唯一观测值进行排序,然后将每个观测值的累积概率计算为小于或等于该观测值的观测值数量除以总观测值数量。
如下
- EDF(x) = 小于或等于 x 的观测值数量 / n
与其他累积分布函数一样,随着域中观测值从最小到最大的枚举,概率的总和将从 0.0 进行到 1.0。
为了使经验分布函数具体化,让我们来看一个明显不符合已知概率分布的数据集示例。
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
双峰数据分布
我们可以定义一个明显不符合标准概率分布函数的数集。
一个常见的例子是当数据有两个峰值(双峰分布)或多个峰值(多峰分布)时。
我们可以通过组合来自两个不同正态分布的样本来构建双峰分布。具体来说,300 个均值为 20、标准差为 5(较小的峰值),以及 700 个均值为 40、标准差为 5(较大的峰值)。
选择的均值彼此靠近,以确保分布在组合样本中重叠。
下面列出了创建具有双峰概率分布的样本并绘制直方图的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 双峰数据集的示例 from matplotlib import pyplot from numpy.random import normal from numpy import hstack # 生成样本 sample1 = normal(loc=20, scale=5, size=300) sample2 = normal(loc=40, scale=5, size=700) sample = hstack((sample1, sample2)) # 绘制直方图 pyplot.hist(sample, bins=50) pyplot.show() |
运行示例,创建数据集并绘制直方图。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
我们有少于 20 的均值样本,而有 40 的均值样本,这在直方图中可以看到,40 附近的样本密度比 20 附近的样本密度更大。
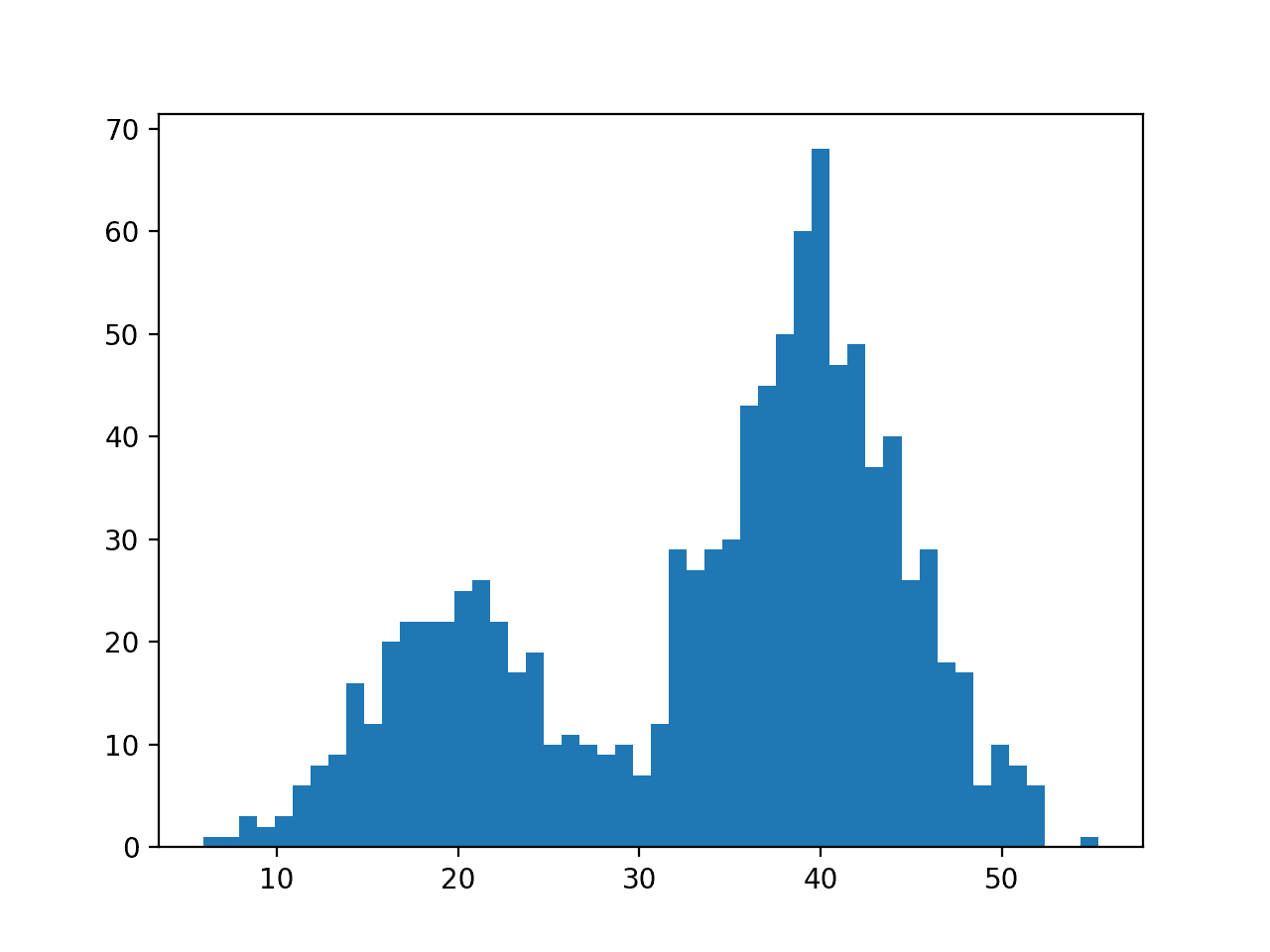
具有双峰概率分布的数据样本的直方图
根据设计,具有此分布的数据不适合常见的概率分布。
下面是此数据集的概率密度函数 (PDF) 的图。
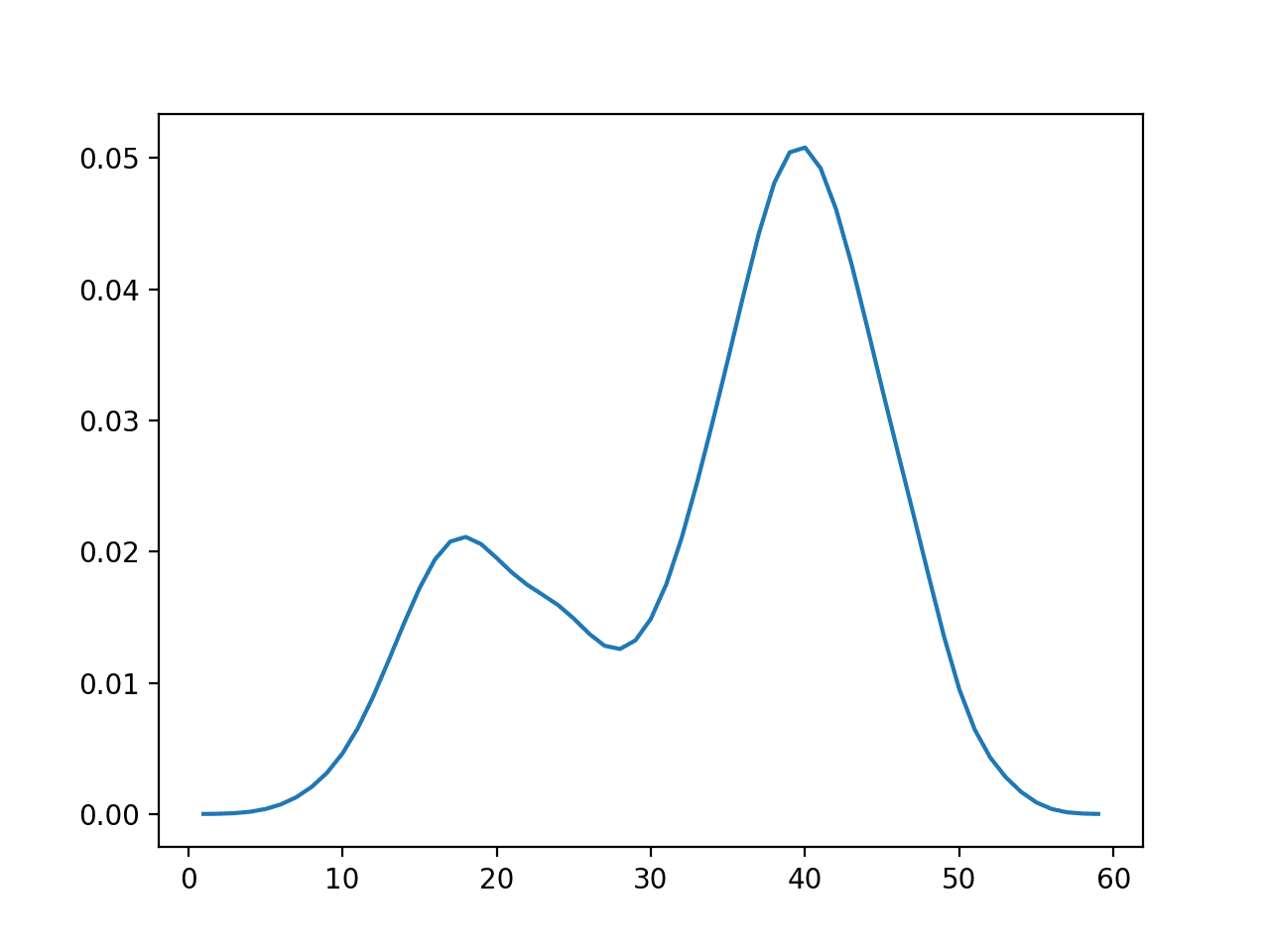
双峰数据集的经验概率密度函数
这是使用经验分布函数的一个好例子。
计算经验分布函数
可以在 Python 中为数据样本拟合经验分布函数。
statsmodels Python 库提供了 ECDF 类,用于拟合经验累积分布函数并计算来自域的特定观测值的累积概率。
通过调用 ECDF() 并传入原始数据集来拟合分布。
|
1 2 3 |
... # 拟合 cdf ecdf = ECDF(sample) |
拟合后,可以调用该函数来计算给定观测值的累积概率。
|
1 2 3 4 5 |
... # 获取值的累积概率 print('P(x<20): %.3f' % ecdf(20)) print('P(x<40): %.3f' % ecdf(40)) print('P(x<60): %.3f' % ecdf(60)) |
该类还提供了数据中唯一观测值的有序列表(.x 属性)及其相关的概率(.y 属性)。我们可以访问这些属性并直接绘制 CDF 函数。
|
1 2 3 4 |
... # 绘制 cdf pyplot.plot(ecdf.x, ecdf.y) pyplot.show() |
将这些结合起来,用于拟合双峰数据集的经验分布函数的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 为双峰数据集拟合经验 CDF from matplotlib import pyplot from numpy.random import normal from numpy import hstack from statsmodels.distributions.empirical_distribution import ECDF # 生成样本 sample1 = normal(loc=20, scale=5, size=300) sample2 = normal(loc=40, scale=5, size=700) sample = hstack((sample1, sample2)) # 拟合 cdf ecdf = ECDF(sample) # 获取值的累积概率 print('P(x<20): %.3f' % ecdf(20)) print('P(x<40): %.3f' % ecdf(40)) print('P(x<60): %.3f' % ecdf(60)) # 绘制 cdf pyplot.plot(ecdf.x, ecdf.y) pyplot.show() |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。考虑运行几次示例并比较平均结果。
运行示例,将经验 CDF 拟合到数据集,然后打印观察三个值的累积概率。
|
1 2 3 |
P(x<20): 0.149 P(x<40): 0.654 P(x<60): 1.000 |
然后计算整个域的累积概率,并显示为折线图。
在这里,我们可以看到大多数累积分布函数中常见的 S 形曲线,此处在双峰分布的两个峰值的均值周围有隆起。
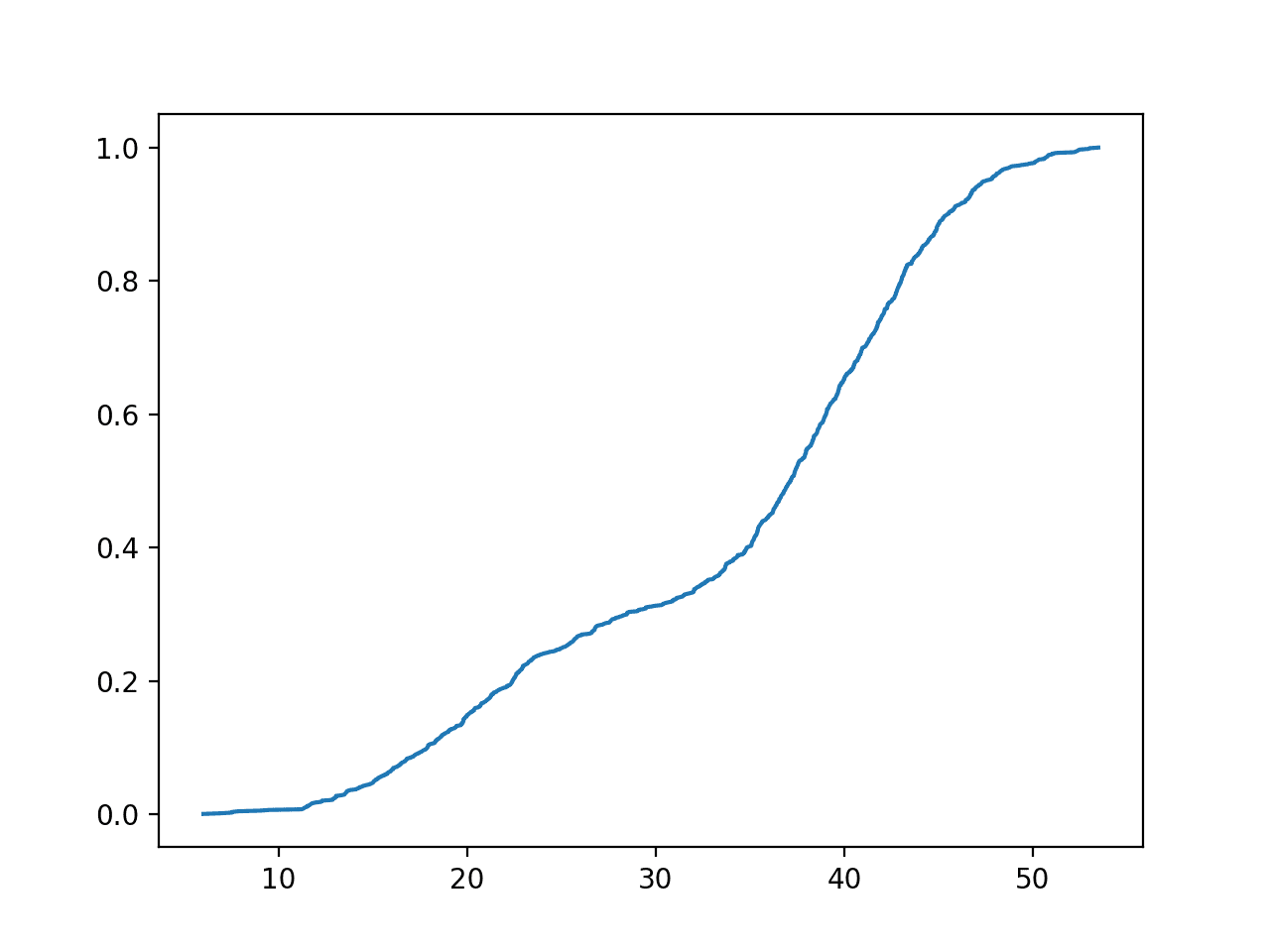
双峰数据集的经验累积分布函数
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
API
文章
总结
在本教程中,您了解了经验概率分布函数。
具体来说,你学到了:
- 某些数据样本无法使用标准分布进行汇总。
- 经验分布函数提供了一种为数据样本建模累积概率的方法。
- 如何使用 statsmodels 库来建模和采样经验累积分布函数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






 Test Functions for Function Optimization")
Jason,很棒!
谢谢!
标题为“双峰数据样本的经验概率密度函数”的图。您确定那是经验的,而不是真实的混合分布吗?
我相信我使用了 KDE 来估计原始观测值的 PDF。
我几年前制作了这两个关于如何使用 scipy 拟合分布的示例。它们非常简单,有些人可能会觉得有用
核密度:https://glowingpython.blogspot.com/2012/08/kernel-density-estimation-with-scipy.html
参数分布:https://glowingpython.blogspot.com/2012/07/distribution-fitting-with-scipy.html
感谢分享。
再次感谢 Jason,
我想知道您是否制作了另一个示例来探索峰值数量……
我看到这个例子只处理一个非常特殊的双峰情况……
谢谢你
相同的例子可以适用于多个峰值。
嗨,Jason!
ECDF 是否可以作为训练特征,就像使用滚动窗口统计量(如均值等)进行模型训练和预测一样?是否存在“数据泄露”的可能性?
谢谢
也许,如果它仅使用训练数据进行准备,就不会发生泄露。
试试你的想法,看看效果。
好文章。谢谢。我学会了您简单的解释和好的例子。
然而,在第二个代码框中调用 ECDF 类时,从 statsmodels 包中缺少导入此类的行。
具体是哪个例子?
您好,我想找到多类数据集的类别经验分布。
这将是一个多项分布。
https://machinelearning.org.cn/discrete-probability-distributions-for-machine-learning/
如果我们输入 ecdf (20),我们会得到相应的 ECDF。如何通过输入 ECDF 来获取相应的数字?
嗨 Sohaib……以下讨论可能很有帮助
https://stackoverflow.com/questions/44132543/python-inverse-empirical-cumulative-distribution-function-ecdf
如果我们想找到 p(x>20),该怎么做?
嗨 L_R……以下讨论有助于澄清
https://stackoverflow.com/questions/44132543/python-inverse-empirical-cumulative-distribution-function-ecdf
如何从拟合的 ECDF 图或 KDE 图中提取百分位数或分位数?我想知道 ECDF 或 KDE 图中 50% 和 90% 的 x 值。我在网上找到的解决方案说对数据进行排序并使用某个百分位函数查找分位数,但是从 ECDF 创建密度函数以使分布尽可能接近实际样本有什么用,如果我们无法从中提取分位数/百分位数?关于如何从 ECDF 和 KDE 中提取百分位数值有什么想法吗?
嗨 AJAY……以下内容可能对您有帮助
https://statsmodels.cn/dev/generated/statsmodels.distributions.empirical_distribution.ECDF.html