文本摘要的任务是从大型文本文档中创建简短、准确和流畅的摘要。
最近,深度学习方法已被证明在文本摘要的抽象方法中有效。
在这篇文章中,您将发现三种不同的模型,它们都基于为机器翻译中的序列到序列预测而开发的有效编码器-解码器架构。
阅读本文后,你将了解:
- Facebook AI Research 模型,它使用带卷积神经网络编码器的编码器-解码器模型。
- IBM Watson 模型,它使用带指向和分层注意力的编码器-解码器模型。
- 斯坦福/谷歌模型,它使用带指向和覆盖的编码器-解码器模型。
通过我的新书《自然语言处理深度学习》启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

用于文本摘要的编码器-解码器深度学习模型
图片由 Hiếu Bùi 提供,保留部分权利。
模型概述
我们将研究三种不同的文本摘要模型,这些模型以其作者在撰写本文时所属的组织命名。
- Facebook 模型
- IBM 模型
- Google 模型
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Facebook 模型
Facebook AI Research (FAIR) 的 Alexander Rush 等人在其 2015 年论文《用于抽象句子摘要的神经注意力模型》中描述了这种方法。
该模型专门为句子摘要而开发。
给定输入句子,目标是生成一个精简的摘要。[…] 摘要器以 x 作为输入并输出长度 N < M 的缩短句子 y。我们将假设摘要中的词也来自相同的词汇表。
这比,比方说,完整文档摘要更简单。
该方法遵循用于神经机器翻译的通用方法,包括编码器和解码器。探索了三种不同的编码:
- 词袋编码器。输入句子使用词袋模型进行编码,丢弃词序信息。
- 卷积编码器。使用词嵌入表示,然后是跨词的时间延迟卷积层和池化层。
- 基于注意力的编码器。使用词嵌入表示,并对上下文向量使用简单的注意力机制,提供输入句子和输出摘要之间的一种软对齐。
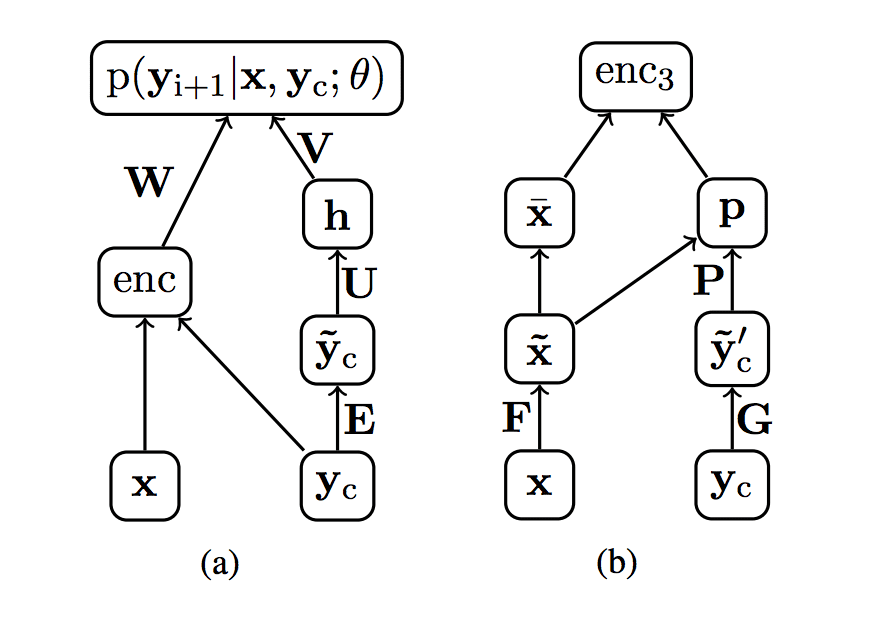
编码器和解码器元素的网络图
摘自《用于抽象句子摘要的神经注意力模型》。
然后,在文本摘要的生成中使用束搜索,这与机器翻译中使用的方法类似。
该模型在标准 DUC-2014 数据集上进行了评估,该数据集涉及为 500 篇新闻文章生成约 14 个单词的摘要。
此任务的数据包括来自《纽约时报》和美联社新闻服务的 500 篇新闻文章,每篇文章都配有 4 种不同的人工生成参考摘要(实际上不是标题),上限为 75 字节。
该模型还在约 950 万篇新闻文章的 Gigaword 数据集上进行了评估,其中给定新闻文章的第一句生成标题。
使用 ROUGE-1、ROUGE-2 和 ROUGE-L 衡量标准报告了这两个问题的结果,并且经过调整的系统在 DUC-2004 数据集上实现了最先进的结果。
与几个强基线相比,该模型在 DUC-2004 共享任务中显示出显著的性能提升。
IBM 模型
IBM Watson 的 Ramesh Nallapati 等人在其 2016 年论文《使用序列到序列 RNN 及其他方法进行抽象文本摘要》中描述了这种方法。
该方法基于带注意力的编码器-解码器循环神经网络,为机器翻译而开发。
我们的基线模型对应于 Bahdanau 等人(2014)使用的神经机器翻译模型。编码器由一个双向 GRU-RNN(Chung 等人,2014)组成,而解码器由一个单向 GRU-RNN 组成,其隐藏状态大小与编码器相同,并对源隐藏状态应用注意力机制,以及一个对目标词汇表的 soft-max 层以生成词语。
除了标记词性(POS)和离散化 TF 和 IDF 特征的嵌入之外,还使用了输入词的词嵌入。这种更丰富的输入表示旨在使模型在识别源文本中的关键概念和实体方面具有更好的性能。
该模型还使用学习开关机制来决定是生成输出词还是指向输入序列中的词,旨在处理稀有词和低频词。
……解码器配备了一个“开关”,用于在每个时间步决定是使用生成器还是指针。如果开关打开,解码器以正常方式从其目标词汇表中生成一个词。但是,如果开关关闭,解码器将生成一个指向源中某个词位置的指针。
最后,该模型是分层的,因为注意力机制在编码输入数据的词级别和句子级别都起作用。
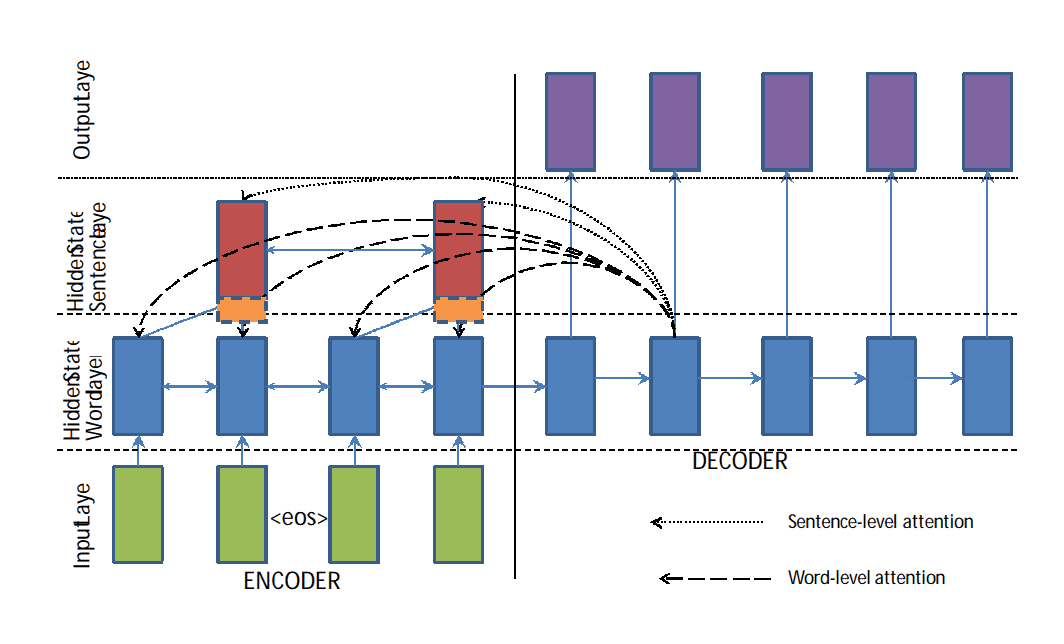
带有分层注意力的分层编码器。
摘自《使用序列到序列 RNN 及其他方法进行抽象文本摘要》。
总共有 6 种方法变体在 DUC-2003/2004 数据集和 Gigaword 数据集上进行了评估,这两个数据集都用于评估 Facebook 模型。
该模型还在来自 CNN 和 Daily Mail 网站的新新闻文章语料库上进行了评估。
与 Facebook 方法及其他方法相比,IBM 方法在标准数据集上取得了令人印象深刻的结果。
……我们应用注意力编码器-解码器进行抽象摘要任务,取得了非常有前景的结果,在两个不同的数据集上显著优于最先进的结果。
Google 模型
Stanford 的 Abigail See 等人在其 2017 年论文《言简意赅:使用指针-生成器网络的摘要》中描述了这种方法。
一个更好的名称可能是“斯坦福模型”,但我试图将这项工作与合著者 Peter Liu(Google Brain)2016 年在 Google Research Blog 上发表的题为“使用 TensorFlow 进行文本摘要”的帖子联系起来。
在他们的博客文章中,Google Brain 的 Peter Liu 等人介绍了一个 TensorFlow 模型,该模型直接将用于机器翻译的编码器-解码器模型应用于为 Gigaword 数据集生成短句摘要。他们声称该模型取得了优于最先进水平的结果,尽管除了代码随附的文本文档之外,没有提供正式的结果报告。
在他们的论文中,Abigail See 等人描述了抽象文本摘要深度学习方法的两个主要缺点:它们会产生事实错误并重复自身。
尽管这些系统很有前景,但它们表现出一些不良行为,例如不准确地再现事实细节,无法处理词汇外(OOV)词,以及重复自身。
他们的方法设计用于摘要多个句子而不是单个句子,并应用于用于演示 IBM 模型的 CNN/Daily Mail 数据集。该数据集中的文章平均包含约 39 个句子。
使用带有词嵌入的基线编码器-解码器模型,用于输入的双向 LSTM 和注意力机制。探索了一种扩展,该扩展使用指向输入数据中的词来处理词汇外词,类似于 IBM 模型中使用的方法。最后,使用覆盖机制来帮助减少输出中的重复。
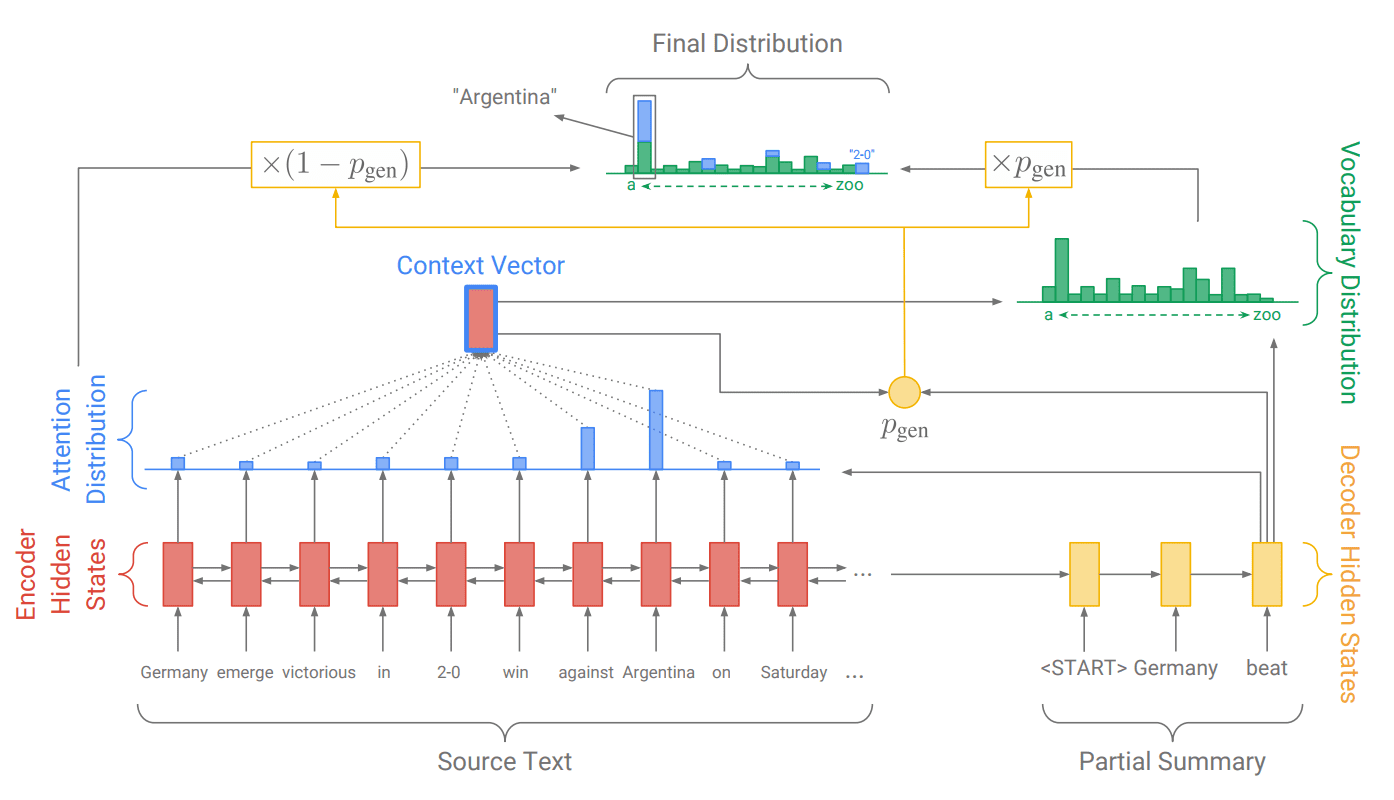
用于文本摘要的指针-生成器模型
摘自《言简意赅:使用指针-生成器网络的摘要》。
使用 ROUGE 和 METEOR 分数报告了结果,显示与抽象方法相比最先进的性能,以及与提取模型相媲美的分数。
我们的带覆盖的指针-生成器模型进一步提高了 ROUGE 和 METEOR 分数,令人信服地超越了最好的 [相比] 抽象模型……
结果确实表明,基线 seq-to-seq 模型(带注意力的编码器-解码器)可以使用,但未能产生有竞争力的结果,这表明了他们对该方法的扩展的好处。
我们发现我们的基线模型在 ROUGE 和 METEOR 方面表现不佳,事实上,更大的词汇量(150k)似乎并没有帮助。……事实细节经常被错误地再现,通常用更常见的替代词替换不常见的(但在词汇表中)词。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- 用于抽象句子摘要的神经注意力模型(查看代码),2015 年。
- 使用序列到序列 RNN 的抽象文本摘要及其他, 2016.
- 言简意赅:使用指针-生成器网络的摘要(查看代码),2017 年。
- 使用 TensorFlow 进行文本摘要(查看代码),2016 年
- 驯服循环神经网络以实现更好的摘要, 2017.
总结
在这篇文章中,您了解了用于文本摘要的深度学习模型。
具体来说,你学到了:
- Facebook AI Research 模型,它使用带卷积神经网络编码器的编码器-解码器模型。
- IBM Watson 模型,它使用带指向和分层注意力的编码器-解码器模型。
- 斯坦福/谷歌模型,它使用带指向和覆盖的编码器-解码器模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。





")
如果能更详细地解释指针网络就更好了。
感谢您的建议,也许您可以查看论文以获取更多信息?
你能解释一下 BERT 吗,以及如何使用 BERT 嵌入来构建这样的网络,而不是 word2vec、glove 这种固定嵌入。
谢谢,
感谢您的建议。
我可以在 pytorch 预训练的 bert 模型中将嵌入维度大小从 768 更改为 300 吗?
如果可以,如何更改?
如果不能,还有其他方法吗?
请回答这个问题,因为我因为这个问题而卡在我的项目中。提前致谢!
抱歉,目前我没有 pytorch 的教程。
也许可以尝试将您的问题发布到 stackoverflow?
你好,请问你能制作一个关于 BERT 的教程吗。
谢谢
感谢您的建议。
“探索了三种不同的解码器:”应改为“探索了三种不同的编码器:”
谢谢,已修正。