编码器-解码器 LSTM 的入门介绍,用于
使用示例 Python 代码进行序列到序列预测。
编码器-解码器 LSTM 是一种循环神经网络,旨在解决序列到序列问题,有时称为 seq2seq。
序列到序列预测问题具有挑战性,因为输入和输出序列中的项目数量可以变化。例如,文本翻译和学习执行程序都是 seq2seq 问题的例子。
在这篇文章中,您将了解用于序列到序列预测的编码器-解码器 LSTM 架构。
完成这篇文章后,您将了解:
- 序列到序列预测的挑战。
- 编码器-解码器架构及其旨在解决的 LSTM 局限性。
- 如何在 Python 中使用 Keras 实现编码器-解码器 LSTM 模型架构。
通过我的新书《使用 Python 的长短期记忆网络》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。

编码器-解码器长短期记忆网络
图片由 slashvee 拍摄,保留部分权利。
序列到序列预测问题
序列预测通常涉及预测实值序列中的下一个值或为输入序列输出一个类别标签。
这通常被框定为从一个输入时间步长到一个输出时间步长(例如一对一)或从多个输入时间步长到一个输出时间步长(多对一)类型的序列预测问题。
有一种更具挑战性的序列预测问题,它将一个序列作为输入,并需要一个序列预测作为输出。这些被称为序列到序列预测问题,简称 seq2seq。
使这些问题具有挑战性的一个建模问题是,输入和输出序列的长度可能不同。鉴于存在多个输入时间步长和多个输出时间步长,这种形式的问题被称为多对多类型序列预测问题。
需要 LSTM 帮助进行序列预测吗?
参加我的免费7天电子邮件课程,了解6种不同的LSTM架构(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
编码器-解码器 LSTM 架构
一种对 seq2seq 预测问题非常有效的方法被称为编码器-解码器 LSTM。
该架构由两个模型组成:一个用于读取输入序列并将其编码成固定长度的向量,另一个用于解码固定长度的向量并输出预测序列。这些模型协同使用,因此该架构被称为编码器-解码器 LSTM,专门用于 seq2seq 问题。
……RNN 编码器-解码器,由两个循环神经网络 (RNN) 组成,它们充当编码器和解码器对。编码器将可变长度的源序列映射到固定长度的向量,解码器将向量表示映射回可变长度的目标序列。
— 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014。
编码器-解码器 LSTM 是为自然语言处理问题开发的,它在文本翻译(称为统计机器翻译)领域展现了最先进的性能。
这种架构的创新之处在于模型核心使用了固定大小的内部表示,输入序列被读取到该表示中,输出序列则从该表示中读取。因此,该方法可以被称为序列嵌入。
在该架构首次应用于英法翻译的其中一个应用中,对编码后的英文短语的内部表示进行了可视化。这些图揭示了为翻译任务所利用的短语的定性有意义的学习结构。
所提出的 RNN 编码器-解码器自然地生成了短语的连续空间表示。……从可视化中可以看出,RNN 编码器-解码器捕获了短语的语义和句法结构。
— 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014。
在翻译任务中,当输入序列被反转时,模型被发现更有效。此外,该模型被证明即使在非常长的输入序列上也有效。
我们能够在长句子上做得很好,因为我们在训练和测试集中反转了源句中的单词顺序,但没有反转目标句中的单词顺序。通过这样做,我们引入了许多短期依赖关系,这使得优化问题变得更加简单。……反转源句中单词的简单技巧是这项工作的主要技术贡献之一。
— 使用神经网络的序列到序列学习,2014年。
这种方法也已用于图像输入,其中卷积神经网络用作输入图像的特征提取器,然后由解码器 LSTM 读取。
……我们建议遵循这个优雅的方法,用深度卷积神经网络 (CNN) 替换编码器 RNN。……通过首先对其进行图像分类任务的预训练,并使用最后一个隐藏层作为生成句子的 RNN 解码器的输入,自然地将 CNN 用作图像“编码器”。
— 展示与讲述:一种神经图像字幕生成器,2014年。
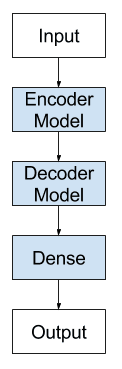
编码器-解码器 LSTM 模型架构
编码器-解码器 LSTM 的应用
以下列表重点介绍了编码器-解码器 LSTM 架构的一些有趣应用。
- 机器翻译,例如英法短语翻译。
- 学习执行,例如计算小程序的结果。
- 图像字幕,例如为图像生成文本描述。
- 对话建模,例如生成文本问题的答案。
- 运动分类,例如从手势序列生成命令序列。
在 Keras 中实现编码器-解码器 LSTM
编码器-解码器 LSTM 可以直接在 Keras 深度学习库中实现。
我们可以将模型视为由两个关键部分组成:编码器和解码器。
首先,输入序列一次一个编码字符地呈现给网络。我们需要一个编码层来学习输入序列中步骤之间的关系并形成这些关系的内部表示。
可以使用一个或多个 LSTM 层来实现编码器模型。该模型的输出是一个固定大小的向量,代表输入序列的内部表示。该层中存储单元的数量定义了此固定大小向量的长度。
|
1 2 |
model = Sequential() 模型.add(LSTM(..., input_shape=(...))) |
解码器必须将输入序列学习到的内部表示转换为正确的输出序列。
一个或多个 LSTM 层也可以用于实现解码器模型。该模型从编码器模型中读取固定大小的输出。
与普通 LSTM 一样,密集层用作网络的输出。通过将密集层包装在 TimeDistributed 包装器中,可以使用相同的权重来输出输出序列中的每个时间步。
|
1 2 |
模型.add(LSTM(..., return_sequences=True)) 模型.add(TimeDistributed(Dense(...))) |
不过,有一个问题。
我们必须将编码器连接到解码器,但它们不匹配。
也就是说,编码器将产生一个二维输出矩阵,其长度由层中存储单元的数量定义。解码器是一个 LSTM 层,它期望一个 [样本、时间步长、特征] 的三维输入,以便产生某个不同长度的解码序列,该长度由问题定义。
如果您尝试将这些部分强制组合在一起,您将收到一个错误,指示解码器的输出是二维的,并且需要三维输入到解码器。
我们可以使用 RepeatVector 层来解决这个问题。这个层只是简单地将提供的二维输入重复多次以创建三维输出。
RepeatVector 层可以像适配器一样使用,将网络的编码器和解码器部分连接起来。我们可以配置 RepeatVector 以便在输出序列的每个时间步重复固定长度的向量一次。
|
1 |
模型.add(RepeatVector(...)) |
综上所述,我们有
|
1 2 3 4 5 |
model = Sequential() 模型.add(LSTM(..., input_shape=(...))) 模型.add(RepeatVector(...)) 模型.add(LSTM(..., return_sequences=True)) 模型.add(TimeDistributed(Dense(...))) |
总而言之,RepeatVector 用作适配器,将编码器的固定大小的二维输出与解码器所需的长度不同且为三维的输入进行匹配。TimeDistributed 包装器允许将相同的输出层重用于输出序列中的每个元素。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
论文
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014.
- 使用神经网络进行序列到序列学习, 2014.
- 展示与讲述:一个神经图像字幕生成器, 2014.
- 学习执行, 2015.
- 一个神经对话模型, 2015.
Keras API
文章
总结
在这篇文章中,您了解了用于序列到序列预测的编码器-解码器 LSTM 架构。
具体来说,你学到了:
- 序列到序列预测的挑战。
- 编码器-解码器架构及其旨在解决的 LSTM 局限性。
- 如何在 Python 中使用 Keras 实现编码器-解码器 LSTM 模型架构。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






嗨 Jason
应用 model.add(TimeDistributed(Dense(…))) 后,我们将收到什么样的输出?
此致
很好的问题!
您将从 Dense 中获得包装器在每个时间步收到的输出。
非常感谢
那意味着我们也会收到固定长度的输出吗?
给定大小相同但含义不同的输入序列?
例如:
我喜欢这个——input_1
和
我买了车——input_2
在任何情况下都会变成两个长度相同的序列吗?
不,输入和输出序列的长度可以不同。
RepeatVector 允许您指定输出向量的固定长度,例如,重复输入序列的固定长度编码的次数。
嗨,Jason,我很高兴阅读您的帖子。
一个问题:实现 seq2seq 的常见方法是将编码器的输出用作解码器内部状态的初始值。然后,解码器输出的每个令牌都会作为输入反馈给解码器。
在您的方法中,您反其道而行之,将编码器的输出在每个时间步都作为输入。
我想知道您是否尝试过两种方法,如果尝试过——哪种方法对您来说效果更好?
谢谢
谢谢 Yoel。好问题!
我尝试过另一种方法,但不得不在 Keras 中巧妙地实现(例如,它不自然)。在使用注意力时也需要这种方法。我希望将来能更详细地介绍这一点。
至于哪个更好,我不确定。根据我的经验,上述简单方法可以帮助您在 seq2seq 应用程序中走得很远。
Jason 的出色描述。我想知道你是否有使用 Keras 进行图分析的例子。
此致
M.B.
抱歉,我没有。
你好,谢谢你的精彩博客。我有一个问题。
我想知道这个例子是不是编码器-解码器的简化版本?因为我在你的代码中没有找到解码器的移位输出向量。
谢谢你
这是一个简化版本。有关更复杂的版本,请参见此处
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
嗨,Jason,感谢您的精彩帖子。
我很好奇为什么你没有为编码器使用“return_sequences=true”,而是重复最后一个值多次?
谢谢。
它不会对输出序列的长度提供细粒度的控制。
不过,如果您有任何想法,请尝试一下,告诉我进展如何。
详细说明一下——如果使用 return_sequences = true,那么我们将从每个编码器时间步长获得输出,该时间步长仅包含编码器迄今为止所见内容的局部编码。在所有输出序列中使用最终编码状态的优势在于对整个输入序列具有完全编码状态。
听起来不错!
有没有一个简单的github示例来演示这个代码的实际应用?
我的博客上有代码,请尝试搜索功能。
嗨 Jason,感谢您如此直观的帖子。一个小问题,如果我们将自动编码器用于特征提取,y_train 会是什么?是序列 {x1, x2, x3..xT} 还是 {xT+1, xT+2,…xT+f} 还是仅仅 {xT+1}?
如果您对输入变量进行特征提取,y 变量将不会受到影响。
我的错,我没有正确地提出问题。我的问题是,如果使用单独的自动编码器块进行特征提取,并且编码器的输出然后馈送到另一个神经网络以预测另一个输出变量 y,那么自动编码器块的训练输出是什么,它是 {x1,x2,x3…xT} 还是 {xT+1, xT+2,…xT+f} 还是仅仅 {xT+1},其中 xT 是输入特征向量。我希望现在我已经说清楚了。
这完全取决于您。
我可能会让前端模型总结每个时间步(如果特征很多),或者总结样本或子集(如果特征很少)。
嗨,Jason,
假设我必须训练一个总结文本数据的网络。我收集了一个文本-摘要对的数据集。但我对训练有点困惑。源文本包含“M”个单词,而摘要文本包含“N”个单词(M > N)。如何进行训练?
我有一系列关于这个主题的帖子,例如
https://machinelearning.org.cn/?s=text+summarization&submit=Search
是啊。我几乎读完了所有这些。干得好。<3。
但我仍然对训练感到怀疑。
正如这篇帖子中提到的 (https://machinelearning.org.cn/encoder-decoder-models-text-summarization-keras/),在创建模型之前,源文本长度和摘要文本长度是否必须固定?训练数据集没有固定长度的源-摘要对。
任何朝着正确方向的推动都将非常有帮助。
是的,您必须选择它们的长度,然后将所有数据填充到这些长度。
嗨,Jason,您的博客帖子真的很棒。我正在尝试预测时间序列,但也想进行降维以从我的信号中学习最重要的特征。代码看起来像
输入维度=1
时间步=256
样本=17248
批大小=539
维度=64
inputs = Input(shape=(时间步长, input_dim))
编码 = LSTM(n_dimensions, activation=’relu’, return_sequences=False, name=”encoder”)(inputs)
decoded = RepeatVector(时间步长)(encoded)
解码 = LSTM(input_dim,activation=’linear’, return_sequences=True, name=’decoder’)(decoded)
自动编码器 = Model(inputs,decoded)
encoder = Model(inputs, encoded)
如果我想用我的数据进行降维,我必须用哪个进行预测?用 auteoncoder.predict 还是 encoder.predict?
抱歉,我无法调试您的代码,也许可以把您的代码和错误发布到 stackoverflow?
嗨 Jason
尝试了一下你的编码器代码。它看起来像下面这样
model = Sequential()
model.add(LSTM(200, input_shape=(n_lag, numberOfBrands)))
model.add(RepeatVector(n_lag))
model.add(LSTM(100, return_sequences=True))
model.add(TimeDistributed(Dense(numberOfBrands)))
model.compile(loss=’mean_squared_error’, optimizer=’adam’,metrics=[‘mae’])
之后当我执行以下行时
history = model.fit(train_X, train_y, epochs=200, batch_size=5, verbose=2),我收到以下错误
检查目标时出错:expected time_distributed_5 有 3 个维度,但得到的数组形状为 (207, 30)
我知道为什么。它抱怨 train_y,其形状为 207,30!这里重塑 Y 以适应 3D 输出的诀窍是什么?
谢谢
这看起来您的数据与模型预期不符。您可以重塑数据,也可以更改模型的输入预期。
有关为 LSTM 准备数据的更多帮助,请参阅此处
https://machinelearning.org.cn/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
确实,问题出在形状上。特别是 RepeatVector 层。确定 RepeatVector 层参数的规则是什么?在我的模型中,我传递了时间滞后,这显然是不正确的。
输出时间步长数。
好的,所以对我来说显然是 1,因为我试图为一个时间步长(即 t)输出“numberOfBrands”个值。数据整形才是真正的挑战部分 :)。
非常感谢。您真的很有帮助
嗨,Jason,感谢您的精彩帖子!我只是有一个问题,我正在尝试构建一个编码器-解码器 LSTM,它以 (4800, 15, 39) 维度的窗口作为输入,给我一个编码向量,我对其应用 RepeatVector(15),最后使用重复的编码向量输出输入的预测,这与您在这篇帖子中做的事情类似。但是,我阅读了您的另一篇帖子 (https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/),我无法弄清楚这两种技术之间的区别,以及哪种技术在我的情况下是有效的。
非常感谢,我是您博客的忠实粉丝。
干得好,克里斯蒂安。
好问题。
RepeatVector 方法不是“真正的”编码器-解码器,但它模拟了行为,并且根据我的经验,提供了相似的技能。它更像是一种自动编码器模型。
您链接的教程是 2014/2015/等论文中描述的“真正的”自动编码器,但在 Keras 中实现起来非常痛苦。
主要区别在于使用来自编码器的内部状态作为解码器状态的种子。
如果您担心,也许可以尝试两种方法,并使用效果更好的一种。
你好 Jason,感谢您的及时回复。
我假设您是指我链接的另一个教程是一个“真正的”编码器解码器*,因为您说使用 RepeatVector 更像一个自动编码器模型。我说的对吗?
至于模型之间的差异,编码器-解码器 LSTM 模型使用内部状态和编码向量来预测第一个输出向量,然后使用该预测向量来预测下一个向量,依此类推。但自动编码器技术仅使用预测向量。
如果确实如此,第二种方法(RepeatVector)如何仅通过查看编码向量就能预测时间序列?
我已经实现了这种技术,并且它给出了非常好的结果,所以我认为我不会再为编码器-解码器的实现而烦恼了,因为它给我带来了很多麻烦。
再次感谢!
正确。
它开发了输入序列的压缩表示,由解码器解释。
嗨,Jason,我也用这个模型进行预测,我也得到了很好的结果。但我困惑的是,我是否应该使用另一个真正的编码器-解码器,因为:我用一个大数据的一部分(例如 AAA)训练它,我只是想让模型能够预测这小部分,因此我使用了子序列。然后当我预测所有数据时,它应该只预测之前相同的部分,而不是数据的其余部分。假设它应该只预测 AAA 而不是整个数据 AAABBB。最后应该看起来像 AAA AAA。
抱歉,我不太明白。您能用一句话总结一下输入/输出吗?
我尝试用一个例子来解释:训练输入:AAA,预测输入:AAA-BBB,预测输出:AAA-BBB(但我预期只有 AAA-AAA)。所以模型不应该预测正确。这是否与有状态和重置状态有关?或者使用一个子模型进行训练,一个子模型进行预测?
也许是您对问题的框架?
也许是所选的模型?
也许是所选的配置?
…
我知道有很多尝试和修复,很多可能的地方……我用随机数据反向测试了模型,并达到了我预期的输入/输出。我已经选择了不同的框架,但还没有尝试有状态和重置状态,你认为值得尝试吗?
是的,如果测试模式便宜/快速的话。
我还阅读了您的帖子 https://machinelearning.org.cn/define-encoder-decoder-sequence-sequence-model-neural-machine-translation-keras/#comment-438058 也许这能解决我的问题?
嗨,Christian,您能分享一下您用来实现这些技术的代码吗?电子邮件 (gwkibirige@gmail.com)
您在 R Keras 中有类似的示例吗?因为我不理解 TimeDistributed。谢谢
抱歉,我没有 Keras in R 的示例。
这里有更多关于 TimeDistributed 的内容
https://machinelearning.org.cn/timedistributed-layer-for-long-short-term-memory-networks-in-python/
亲爱的 Jason,
感谢您的精彩帖子。您是否有关于生成式(变分)LSTM 自动编码器的文章,以便能够捕获潜在向量,然后根据训练集样本生成新的时间序列?
祝好
我相信我有一篇关于 LSTM 自动编码器的精彩帖子。但不是变分自动编码器。
你到底需要什么帮助?
非常感谢
不客气。
一个可能很明显的小问题 😀
你说 1 表示单位大小。它表示该层中 LSTM 单元的数量吗?
据我所知,输入层中 LSTM 单元的数量取决于输入序列中的时间戳数量。我说的对吗?
如果真是这样,那 1 到底意味着什么?
输入定义了每个样本预期的时间步数和特征数。
LSTM 第一个隐藏层中的单元数与输入无关。
Keras 使用第一个隐藏层上的 input_shape 参数定义输入,也许这就是你困惑的原因?
Jason,
您能提供一个如何为 LSTM 自动编码器整形多元时间序列数据的示例吗?我一直在尝试这样做,但失败得很惨。谢谢。
也许这个教程会有帮助
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
嗨,Jason,喜欢你的博客。
我正在努力理解关于图像字幕的 Show and Tell 论文 (https://arxiv.org/pdf/1411.4555.pdf)。
(输入图像被编码成向量并作为输入发送到 LSTM 模型)
他们在那里提到
在 LSTM 训练部分下,“我们经验性地验证了在每个时间步将图像作为额外输入会导致较差的结果,因为网络可以明确地利用图像中的噪声并且更容易过拟合”。
您能解释一下这意味着什么吗?他们是否删除了 timedistributed 层,或者有其他解释。
这可能意味着他们尝试在生成每个输出词时提供图像,但这没有帮助。
嗨,Jason,
——请问,当损失 = nan 时是什么意思!
——我们如何选择参数“n_steps_in”和“n_features”?
“n_steps_in”是指序列中的周期(季节性成分)吗?
这表明您的程序存在问题,也许可以尝试缩放数据或更改模型配置。
您必须通过实验来发现能够为您的程序带来最佳性能的特征/步数。
你好,
对于像抽象文本摘要这样的应用,我们使用 GloVe 等工具在预处理期间查找两个术语之间的相对依赖关系,那么编码期间的固定长度向量到底会描述什么?
另外,您能解释一下注意力在上述问题中的应用吗?
谢谢。
该向量描述了一个单词,也许可以阅读这篇文章
https://machinelearning.org.cn/what-are-word-embeddings/
我有许多关于注意力的帖子可能会有所帮助
https://machinelearning.org.cn/?s=attention&post_type=post&submit=Search
嗨
假设我们想以一种事先不知道输出序列长度的方式使用 seq2seq。事实上,我们希望解码器运行的方式是,解码中的先前步骤会告诉解码器是否生成输出信号或终止。换句话说,解码器使用解码过程本身(以及输入和中间状态)来知道何时停止输出任何内容。这在 seq2seq 模型中是否可行?或者,我们是否必须事先指定解码器将执行的迭代次数?
您的 LSTM 书中涵盖了这些内容吗?
您可以使用动态 RNN 并根据需要处理可变数量的输入/输出时间步。
我没有太多例子,但这里有一个
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
你好 jason,
我的数据由 3 列组成:2 个特征和一个随时间连续的序列。我的目标是:给定 2 个特征的值和我的序列的 21 个时间步长,——> 预测序列中接下来的 7 个时间步长。
只想确认在这种情况下,编码器-解码器 LSTM 是我的首选吗?
如果输入和输出步数不匹配,那么编码器-解码器可能是一个很好的起点。
为什么要使用重复向量?编码器-解码器不是用解码器前一个时间步的输出训练的吗?还是用教师强制?
我们正在为编码器-解码器使用基于自动编码器的架构,我发现这种架构同样有效且简单得多。
另请参阅此
https://machinelearning.org.cn/lstm-autoencoders/
还有这个。
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
嗨,Jason,
我已经在 Keras 中训练了日期机器翻译模型,它按预期工作如下
=====================预测代码====================
示例 = [‘1979年5月3日’, ‘09年4月5日’, ‘2016年8月21日’, ‘2007年7月10日星期二’, ‘2018年5月9日星期六’, ‘2001年3月3日’, ‘2001年3月3日’, ‘2001年3月1日’]
对于EXAMPLES中的每个例子
source = string_to_int(example, Tx, human_vocab)
source = np.array(list(map(lambda x: to_categorical(x, num_classes=len(human_vocab)), source))).swapaxes(0,1)
prediction = model.predict([source, s0, c0])
prediction = np.argmax(prediction, axis = -1)
output = [inv_machine_vocab[int(i)] for i in prediction]
print(“source:”, example)
print(“output:”, ”.join(output),”\n”)
==============输出============
来源:1979年5月3日
输出:1979-05-03
来源:09年4月5日
输出:2009-05-05
==============================
但保存和重用模型的效果非常差,如下所示
================ 保存模型======
model.save(“models/my_model.h5”)
========加载已训练模型========
test_model = load_model(“models/my_model.h5”)
这表现很差
==========test_model 预测=========
来源:1979年5月3日
输出:2222222222
来源:09年4月5日
输出:2222222222
===============================
请帮助
干得好!
也许确认您正在保存模型(权重和架构)以及任何数据准备对象。
是的,我保存了模型
model.save(“models/my_model.h5”)
这可能会保存完整的模型(权重和架构)
是的,会的。
当我重新加载模型时,它的性能非常差。
model = load_model(“models/my_model.h5”)
以下是模型的预测结果——
来源:1979年5月3日
输出:2222222222
来源:09年4月5日
输出:2222222222
为什么重新加载的模型没有按预期工作?
哎哟。
确保您还保存了用于数据的所有数据准备方法,以便您可以将它们应用于新数据。
https://machinelearning.org.cn/how-to-save-and-load-models-and-data-preparation-in-scikit-learn-for-later-use/
你好,
我有一个请求给您,请写一篇关于指针网络(https://arxiv.org/pdf/1506.03134.pdf)的教程,及其在 Python 中的实现,包括可变输入长度和必要时添加更多参数的实用程序。
提前感谢
特别是对于凸包问题。
感谢您的建议!
你好 Jason,
感谢您的文章,我正在从您的网站和书籍中学习。
如果您不介意,我有 3 个问题
1- 当提到“序列到序列 LSTM”时,它总是指“编码器-解码器 LSTM 模型”吗?也就是说,Seq2Seq = 编码器-解码器?
2- 除了输入/输出形状之外,模型配置中还有其他内容表明此模型是编码器-解码器模型吗?
3- 您能为带有注意力的 LSTM 进行时间序列预测推荐任何参考资料吗?
提前感谢
Sarah
不客气。
不,任何可以支持 seq2seq 的模型。最常见的是编码器-解码器。
是的,该架构表明是编码器-解码器。
抱歉,我没有关于此主题的教程。
谢谢杰森,
您能帮我确切地知道架构中哪些地方表明是编码器-解码器吗?
编码器-解码器架构有两个模型,一个编码器模型和一个解码器模型,它们之间通过一个瓶颈层隔开,该瓶颈层是编码器的输出。
上述教程给出了一个例子。
嗨,Jason,
我仍然不明白 RepeatVector 的用法。如果你将参数“return_sequence = True”传递给编码器的 LSTM 层,你会得到一个 3D 张量输出,它将与解码器输入兼容 [样本,时间步长,特征]。
在我看来,使用 RepeatVector 只会重复你的最后一个状态 X 次以适应所需的形状。
还是我错过了什么?
谢谢!
重要细节:我正在使用固定时间步长(1500),这会是我不需要 RepeatVector 来解释输入和输出长度之间潜在差异的原因吗?
那是很多时间步!通常我们把时间步限制在200-400。
是的,编码器-解码器模型旨在解决输入和输出序列长度不同的 seq2seq 问题。如果您的数据不属于这种情况,那么该模型可能不适用。
其思想是为输出序列中所需的每一步重复编码的输入序列(其长度可能不同)。
嗨,Jason,
非常感谢这篇文章。
我正在处理一个 N 个时间步的信号,我想知道在一个去噪问题中(输入序列和输出序列具有相同的时间步数 = N),我是否可以使用参数“return_sequence = True”来代替 RepeatVector 层。自动编码器的架构如下所示
auto_encoder_lstm = Sequential()
auto_encoder_lstm.add((LSTM(64, return_sequences=True) , input_shape=(N,1))
auto_encoder_lstm.add(LSTM(64, return_sequences=True)))
auto_encoder_lstm.add(TimeDistributed(Dense(1))
auto_encoder_lstm.compile(optimizer=optimizers.RMSprop(lr=0.0001) , loss=’mse’)
我的代码是否正确,还是我应该使用 RepeatVector?
非常感谢。
不客气。
不,我认为您所描述的不适用于 seq2seq 模型。
谢谢您的回复。但是,原因是什么呢?
实际上,我的模型以大小为 (N,1) 的噪声信号作为输入,并尝试使用 MSE 作为损失函数重构相同长度的原始信号作为输出。我测试了 BLSTM 模型,它在各种信噪比 (SNR) 值下都能提供最佳的去噪效果。
您能澄清一下您的回复吗?谢谢。
当然,您的模型架构没有解耦编码器和解码器子模型,因此不允许可变长度的输入和输出序列。相反,您的模型的输出受到输入长度的特定约束——这正是编码器-解码器模型为 seq2seq 问题所克服的问题。
非常感谢
不客气。
嗨,Jason,
我还有一个问题,如果我的模型不正确,我的去噪双向 LSTM 自动编码器的正确架构是什么?
(是否可以在 https://machinelearning.org.cn/lstm-autoencoders/ 中提出的架构中用双向 LSTM 替换标准 LSTM)
非常感谢。
抱歉,我没有去噪 LSTM 自动编码器的示例,但链接中的示例是一个很好的起点。
好的,非常感谢。
不客气。
谢谢,Jason 的精彩文章,我只有一个疑问
为什么我们需要使用 RepeatVector,如果我们在 lstm 中使用 return_sequences=True,因为据我所知,“return_sequences=True”的 lstm 将只返回 3D 输出,维度为 (#BatchSize, #TimeStamps, #noOfunits)。
期待您的回复
为了控制输出序列的长度。
抱歉,我没明白,您能详细说明一下吗。
在文章中,您写道
“编码器将生成一个二维输出矩阵,其长度由层中存储单元的数量定义。解码器是一个 LSTM 层,它期望一个 [样本、时间步长、特征] 的三维输入”
但我认为编码器将生成一个三维矩阵(#BatchSize、#TimeStamps、#noOfunits),而不是二维矩阵。
也许这里的编码器-解码器示例能让你更清楚。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
你好 Jason,感谢你的出色工作,我通过你的博客学习了机器学习。所以我欠你一份人情。
我在回归的 LSTM 自动编码器上遇到了一个问题,我将输入和输出数据缩放到 0 到 1 的范围,在第一次训练过程结束时,当我绘制模型中间向量(编码器输出和解码器模型输入向量)时,我看到数据的范围在 0 到 8 之间。我绘制了编码器中的一些其他层,又看到了这个范围。这降低了模型的性能。我尝试在每一层之后使用 BatchNormalization 层,但这不起作用!(我在某个地方读到你说不要将 BatchNormalization 用于 LSTM)。那么我该怎么办?
再次感谢
为你的进步喝彩!
也许你可以探索其他方法,例如这里列出的一些方法。
https://machinelearning.org.cn/start-here/#better
LayerNormalization 在这里有效吗?
你可以试试,但我认为这里没有任何好处。
在文本中,它说“也就是说,编码器将产生一个二维输出矩阵”,然而,由于编码器的输出是 LSTM 的输出,我认为 LSTM,因此编码器应该产生一个一维矩阵。
也许这句话有错误,如果我弄错了,有人能告诉我为什么吗?
因为 return_sequence=True 将返回整个序列(每个时间步一个),并且有多个 LSTM 单元。因此它是二维的。
在 LSTM(...) 中,如果你没有指定 return_state 参数,这是否意味着解码器将没有任何初始隐藏/细胞状态?