文本摘要是自然语言处理中的一个问题,旨在为源文档创建简短、准确和流畅的摘要。
为机器翻译开发的编码器-解码器循环神经网络架构在文本摘要问题上已被证明是有效的。
考虑到 Keras 深度学习库为了使其简洁、简单易用而牺牲了一些灵活性,在该库中应用此架构可能很困难。
在本教程中,您将了解如何在 Keras 中实现用于文本摘要的编码器-解码器架构。
完成本教程后,您将了解:
- 如何使用编码器-解码器循环神经网络架构解决文本摘要问题。
- 如何为该问题实现不同的编码器和解码器。
- 您可以使用三种模型在 Keras 中实现用于文本摘要的架构。
通过我的新书《自然语言处理深度学习》启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧。

Keras 中用于文本摘要的编码器-解码器模型
图片由 Diogo Freire 提供,保留部分权利。
教程概述
本教程分为5个部分,它们是:
- 编码器-解码器架构
- 文本摘要编码器
- 文本摘要解码器
- 阅读源文本
- 实现模型
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
编码器-解码器架构
编码器-解码器架构是一种用于序列预测问题的循环神经网络组织方式,这些问题具有可变数量的输入、输出,或同时具有输入和输出。
该架构包含两个组件:一个编码器和一个解码器。
- 编码器:编码器读取整个输入序列并将其编码为内部表示,通常是一个固定长度的向量,称为上下文向量。
- 解码器:解码器从编码器读取编码后的输入序列并生成输出序列。
有关编码器-解码器架构的更多信息,请参阅这篇文章
编码器和解码器子模型是同时训练的。
这相当了不起,因为传统上,具有挑战性的自然语言问题需要开发单独的模型,这些模型后来被串联成一个管道,导致在序列生成过程中错误积累。
整个编码输入被用作生成输出中每个步骤的上下文。尽管这有效,但输入的固定长度编码限制了可以生成的输出序列的长度。
编码器-解码器架构的一个扩展是提供更具表现力的编码输入序列形式,并允许解码器学习在生成输出序列的每个步骤时关注编码输入中的哪些部分。
这种架构的扩展被称为注意力机制。
有关编码器-解码器架构中注意力的更多信息,请参阅这篇文章
带有注意力机制的编码器-解码器架构在生成可变长度输出序列的自然语言处理问题套件中很受欢迎,例如文本摘要。
该架构在文本摘要中的应用如下
- 编码器:编码器负责读取源文档并将其编码为内部表示。
- 解码器:解码器是一个语言模型,负责使用源文档的编码表示生成输出摘要中的每个单词。
文本摘要编码器
编码器是模型复杂性所在的地方,因为它负责捕获源文档的含义。
可以使用不同类型的编码器,尽管更常见的是使用双向循环神经网络,例如 LSTM。在编码器中使用循环神经网络的情况下,词嵌入用于提供单词的分布式表示。
Alexander Rush 等人使用了一个简单的词袋编码器,它忽略了词序,以及卷积编码器,它明确地尝试捕获 N-gram。
我们最基本的模型简单地使用输入句子的词袋,将其嵌入到 H 大小,同时忽略原始顺序的属性或相邻词之间的关系。[...] 为了解决词袋的一些建模问题,我们还考虑对输入句子使用深度卷积编码器。
— 用于抽象句子摘要的神经注意力模型,2015 年。
Konstantin Lopyrev 使用由 4 个 LSTM 循环神经网络组成的深度堆栈作为编码器。
编码器将新闻文章的文本逐字作为输入。每个单词首先通过一个嵌入层,将单词转换为分布式表示。然后使用多层神经网络组合该分布式表示。
— 使用循环神经网络生成新闻标题,2015 年。
Abigail See 等人使用单层双向 LSTM 作为编码器。
文章的标记 w(i) 逐一输入编码器(单层双向 LSTM),生成一系列编码器隐藏状态 h(i)。
— 言简意赅:使用指针生成器网络的摘要,2017 年。
Ramesh Nallapati 等人在其编码器中使用双向 GRU 循环神经网络,并结合了输入序列中每个单词的附加信息。
编码器由一个双向 GRU-RNN 组成……
— 使用序列到序列 RNN 的抽象文本摘要及其他,2016 年。
文本摘要解码器
解码器必须根据两个信息源生成输出序列中的每个单词
- 上下文向量:编码器提供的源文档的编码表示。
- 已生成序列:已生成作为摘要的单词或单词序列。
上下文向量可以是简单编码器-解码器架构中的固定长度编码,也可以是通过注意力机制过滤的更具表现力的形式。
生成的序列只进行了少量预处理,例如通过词嵌入对每个生成的单词进行分布式表示。
在每个步骤 t,解码器(单层单向 LSTM)接收前一个单词的词嵌入(训练时,这是参考摘要的前一个单词;测试时是解码器发出的前一个单词)。
— 言简意赅:使用指针生成器网络的摘要,2017 年。
Alexander Rush 等人在图中清晰地展示了这一点,其中 x 是源文档,enc 是提供源文档内部表示的编码器,yc 是之前生成的单词序列。
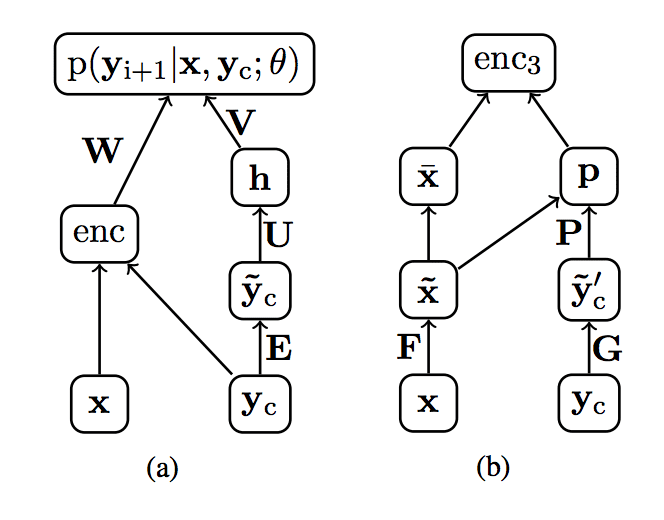
文本摘要解码器输入示例。
摘自《用于抽象句子摘要的神经注意力模型》,2015 年。
一次生成一个单词需要模型一直运行,直到生成最大数量的摘要单词或达到特殊的序列结束标记。
必须通过向模型提供特殊的序列开始标记来启动该过程,以便生成第一个单词。
解码器将输入文本的最后一个单词输入后生成的隐藏层作为输入。首先,将一个序列结束符号作为输入,再次使用嵌入层将符号转换为分布式表示。[...]。生成每个单词后,将相同的单词作为输入,以生成下一个单词。
— 使用循环神经网络生成新闻标题,2015 年。
Ramesh Nallapati 等人使用 GRU 循环神经网络生成输出序列。
……解码器由一个单向 GRU-RNN 组成,其隐藏状态大小与编码器相同。
阅读源文本
根据要解决的特定文本摘要问题,此架构的应用具有灵活性。
大多数研究集中在编码器中的一个或几个源句子,但这并非必须如此。
例如,编码器可以配置为以不同大小的块读取和编码源文档
- 句子。
- 段落。
- 页面。
- 文档。
同样,解码器可以配置为总结每个块,或聚合编码块并输出更广泛的摘要。
在这方面已开展了一些工作,Alexander Rush 等人使用了一个分层编码器模型,在单词和句子级别都具有注意力机制。
该模型旨在通过在源端使用两个双向 RNN 来捕获两个重要级别,一个在单词级别,另一个在句子级别。注意力机制同时在两个级别上运行。
— 用于抽象句子摘要的神经注意力模型,2015 年。
实现模型
在本节中,我们将介绍如何在 Keras 深度学习库中实现用于文本摘要的编码器-解码器架构。
通用模型
该模型的一个简单实现包括一个编码器,其输入是嵌入层,后跟一个 LSTM 隐藏层,该层生成源文档的固定长度表示。
解码器读取该表示和最后一个生成的单词的嵌入,并使用这些输入来生成输出摘要中的每个单词。
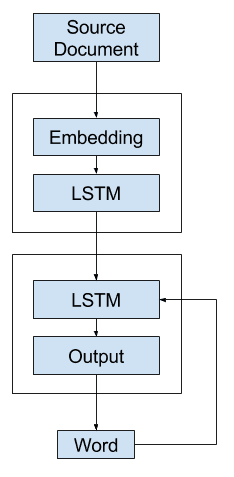
Keras 中的通用文本摘要模型
存在一个问题。
Keras 不允许模型输出自动作为模型输入的递归循环。
这意味着上面描述的模型不能直接在 Keras 中实现(但在更灵活的平台如 TensorFlow 中可能可以)。
相反,我们将研究可以在 Keras 中实现该模型的三个变体。
替代方案 1:一次性模型
第一个替代模型是一次性生成整个输出序列。
也就是说,解码器仅使用上下文向量来生成输出序列。
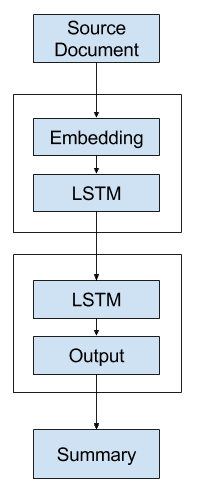
替代方案 1 – 一次性文本摘要模型
以下是使用函数式 API 在 Keras 中实现此方法的一些示例代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # 编码器输入模型 inputs = Input(shape=(src_txt_length,)) encoder1 = Embedding(vocab_size, 128)(inputs) encoder2 = LSTM(128)(encoder1) encoder3 = RepeatVector(sum_txt_length)(encoder2) # 解码器输出模型 decoder1 = LSTM(128, return_sequences=True)(encoder3) outputs = TimeDistributed(Dense(vocab_size, activation='softmax'))(decoder1) # 连接起来 model = Model(inputs=inputs, outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
这个模型给解码器带来了沉重的负担。
解码器很可能没有足够的上下文来生成连贯的输出序列,因为它必须选择单词及其顺序。
替代方案 2:递归模型 A
第二个替代模型是开发一个生成单个单词预测并递归调用它的模型。
也就是说,解码器使用上下文向量和到目前为止生成的所有单词的分布式表示作为输入,以生成下一个单词。
可以使用语言模型来解释到目前为止生成的单词序列,以提供第二个上下文向量,将其与源文档的表示结合起来,从而生成序列中的下一个单词。
通过递归调用模型并附加先前生成的单词(或者更具体地说,在训练期间预期的先前单词)来构建摘要。
上下文向量可以集中或相加,为解码器提供更广泛的上下文,以便解释和输出下一个单词。
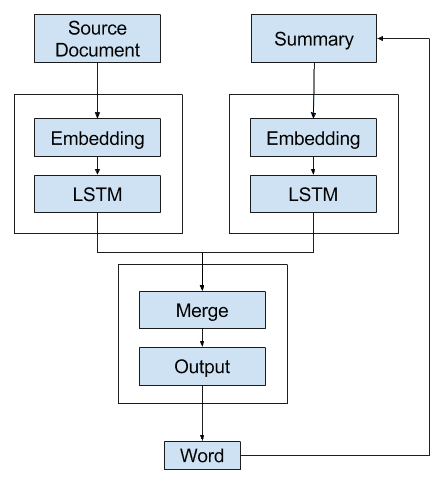
替代方案 2 – 递归文本摘要模型 A
以下是使用函数式 API 在 Keras 中实现此方法的一些示例代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # 源文本输入模型 inputs1 = Input(shape=(src_txt_length,)) am1 = Embedding(vocab_size, 128)(inputs1) am2 = LSTM(128)(am1) # 摘要输入模型 inputs2 = Input(shape=(sum_txt_length,)) sm1 = = Embedding(vocab_size, 128)(inputs2) sm2 = LSTM(128)(sm1) # 解码器输出模型 decoder1 = concatenate([am2, sm2]) outputs = Dense(vocab_size, activation='softmax')(decoder1) # 连接 [文章, 摘要] [单词] model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
这更好,因为解码器有机会使用先前生成的单词和源文档作为上下文来生成下一个单词。
它确实给合并操作和解码器带来了负担,需要解释它在生成输出序列中的位置。
替代方案 3:递归模型 B
在这第三个替代方案中,编码器生成源文档的上下文向量表示。
此文档在生成的输出序列的每个步骤中都被馈送到解码器。这允许解码器建立与用于生成输出序列中单词的内部状态相同的内部状态,以便它准备好生成序列中的下一个单词。
然后,通过一次又一次地为输出序列中的每个单词调用模型来重复此过程,直到生成最大长度或序列结束标记。
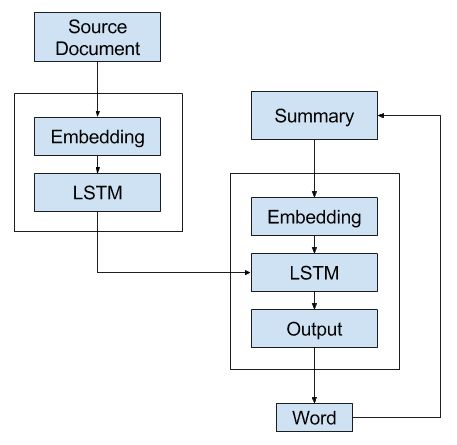
替代方案 3 – 递归文本摘要模型 B
以下是使用函数式 API 在 Keras 中实现此方法的一些示例代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
vocab_size = ... src_txt_length = ... sum_txt_length = ... # 文章输入模型 inputs1 = Input(shape=(src_txt_length,)) article1 = Embedding(vocab_size, 128)(inputs1) article2 = LSTM(128)(article1) article3 = RepeatVector(sum_txt_length)(article2) # 摘要输入模型 inputs2 = Input(shape=(sum_txt_length,)) summ1 = Embedding(vocab_size, 128)(inputs2) # 解码器模型 decoder1 = concatenate([article3, summ1]) decoder2 = LSTM(128)(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) # 连接 [文章, 摘要] [单词] model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') |
您还有其他替代实现思路吗?
在下面的评论中告诉我。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
论文
- 用于抽象句子摘要的神经注意力模型, 2015.
- 使用循环神经网络生成新闻标题, 2015.
- 使用序列到序列 RNN 的抽象文本摘要及其他, 2016.
- 直奔主题:使用指针生成器网络的摘要, 2017.
相关
总结
在本教程中,您学习了如何在 Keras 深度学习库中实现用于文本摘要的编码器-解码器架构。
具体来说,你学到了:
- 如何使用编码器-解码器循环神经网络架构解决文本摘要问题。
- 如何为该问题实现不同的编码器和解码器。
- 您可以使用三种模型在 Keras 中实现文本摘要架构。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






关于递归模型 A,这里有一个 5 个月前提出的类似方法(带共享嵌入):https://github.com/oswaldoludwig/Seq2seq-Chatbot-for-Keras
该模型的优点可以在这篇论文的 3.1 节中看到:https://www.researchgate.net/publication/321347271_End-to-end_Adversarial_Learning_for_Generative_Conversational_Agents
感谢提供的链接。
不客气!
对于递归模型 A,您可以引用 Zenodo 文档:https://zenodo.org/record/825303#.Wit0jc_TXqA
或 ArXiv 论文:https://arxiv.org/abs/1711.10122
提前感谢,
奥斯瓦尔多·路德维希
太棒了!
我提供了一个通用库,其中包含我聊天机器人背后的 seq2seq 模型:https://github.com/oswaldoludwig/Parallel-Seq2Seq 。我将这个模型称为并行 Seq2Seq,并在该仓库的 readme 文件中解释了其优点。
感谢分享。
先生,您能举个例子解释一下吗?
解释什么?
请用一个例子解释整个过程。您也没有提及推理过程。
抱歉,我不太明白,您想让我解释什么?
先生,您能解释一下如何使用预训练的词嵌入,例如 Glove,而不是独热向量作为编码器输入和解码器输入吗?
请看这个教程
https://machinelearning.org.cn/use-word-embedding-layers-deep-learning-keras/
如果您能提供一些在简单分类问题中使用自动编码器的示例,那就太好了。使用编码器/解码器预训练(输入 = 输出“无监督预训练”)以在中间获得高抽象级别的信息,然后将此网络分成两半,并使用编码器馈送一个带有 softmax(例如)的密集神经网络,并执行有监督的“后训练”。您认为这在 keras 中可能吗?
感谢您的建议。
通常,深度多层感知机在分类任务中表现优于自动编码器。
像这样的 Keras 示例会很棒:https://www.mathworks.com/help/nnet/examples/training-a-deep-neural-network-for-digit-classification.html
这是解决该问题的一个 CNN 示例
使用卷积神经网络和 Python Keras 进行手写数字识别
请提供 Keras 中用于文本摘要的编码器-解码器模型的代码链接
感谢您的建议。
这在以下情况下效果如何?
1) 杂乱的数据。例如,假设我想总结一段我错过的聊天对话。
2) 长内容。它能总结一本书吗?
这在工业界实际使用,还是仅仅是学术界的?
好问题,但很难回答。我建议您深入研究一些论文以查看示例,或者在您自己的数据上运行一些实验。
嗨,Jason,
感谢您的文章。
我尝试将第一种方法与您关于准备新闻文章以进行文本摘要的文章中的数据集结合使用(https://machinelearning.org.cn/prepare-news-articles-text-summarization/)。
不幸的是,我无法让编码器-解码器架构工作,也许您能提供一些帮助。
在准备文章的代码之后,我添加了以下代码
X, y = [' '.join(t['story']) for t in stories], [' '.join(t['highlights']) for t in stories]
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
MAX_SEQUENCE_LENGTH = 1000
tokenizer = Tokenizer()
total = X + y
tokenizer.fit_on_texts(total)
sequences_X = tokenizer.texts_to_sequences(X)
sequences_y = tokenizer.texts_to_sequences(y)
word_index = tokenizer.word_index
data = pad_sequences(sequences_X, maxlen=MAX_SEQUENCE_LENGTH)
labels = pad_sequences(sequences_y, maxlen=100) # test with maxlen=100
# 训练/测试划分
TEST_SIZE = 5
X_train, y_train, X_test, y_test = data[:-TEST_SIZE], labels[:-TEST_SIZE], data[-TEST_SIZE:], labels[-TEST_SIZE:]
# 创建模型
# 编码器输入模型
inputs = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
encoder1 = Embedding(len(word_index) + 1, 128, input_length=MAX_SEQUENCE_LENGTH)(inputs)
encoder2 = LSTM(128)(encoder1)
encoder3 = RepeatVector(2)(encoder2)
# 解码器输出模型
decoder1 = LSTM(128, return_sequences=True)(encoder3)
outputs = TimeDistributed(Dense(len(word_index) + 1, activation='softmax'))(decoder1)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')
batch_size = 32
epochs = 4
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=batch_size, verbose=1)
我收到的错误是:检查目标时出错:期望 time_distributed_2 具有 3 个维度,但得到的数组形状为 (3000, 100)
先谢谢您了。
抱歉,我无法为您调试代码。
嗨,丹尼尔,
我也有同样的问题。你解决了吗?
谢谢。
嘿,你的代码成功了吗?我在拟合时遇到了问题。
我也有同样的问题。有人解决了吗?
谢谢!
嘿,丹尼尔,你调试好了吗?
你好 Jason,
请问我们是否可以使用 conv2dlstm 进行语言建模
我建议使用 LSTM 进行语言模型。
我有一个基本问题,解码器最终输出的是一个向量对吗?我们如何将其转换为英文单词?例如,我们是否计算与词汇表中单词的余弦相似度?...谢谢
您可以输出一个独热编码向量,并将其映射到一个整数,然后映射到您词汇表中的一个单词。
感谢您的帮助,现在所有三个模型都对我有效,也感谢您关于如何生成神经语言模型的文章。我正在获得一些输出单词,但这与摘要相去甚远。
但是,我还有一个更基本的问题。在您的第二个和第三个模型中,有两个输入:文章和摘要。现在,在训练模型时,这很好。但是当预测输出或生成摘要时,摘要是未知的。那么我们如何输入第二个输入呢,应该用零代替单词索引吗?请指教。
是的,从零开始,然后逐字构建摘要以输出后面的单词。
嗨,Jason,
感谢您在这里分享的所有知识和书籍。
我有两个问题:一个是关于预测和何时保存模型。第二个是关于填充值。
递归模型 A 在训练期间有效(我看到单词正在添加)。但是,预测有点挑战。当我预测第一个单词时,我什么也得不到。我正在加载一个由 numpy.zeros 组成的当前摘要和源文档,并期望预测第一个单词以更新当前摘要。在我看来,这是预测的第一次迭代。我希望到目前为止我没有错。
起初我以为模型权重可能有问题,所以我为每个单词保存了训练期间的模型。我正在加载在训练的最后一步保存的模型。model.save(“model.h5”),model_load…所以我没有丢失权重。模型摘要正确地打印了架构,但结果是没有预测到任何单词。我假设训练的模型没有正确保存是正确的吗?
第二个问题:序列用 0 值“post”填充。在训练期间,模型最后会得到这些 0 值并预测 0 值。当它得到这些零时,模型及其权重会发生什么变化?它会丢失权重和训练吗?
再次感谢,并继续努力工作,
乔
模型将预测必须映射到单词的整数。
如果模型预测的都是零,那么可能模型需要进一步调整?
您可以使用遮罩层来跳过/忽略填充值。
@Anirban,您介意分享您在上面文章中成功运行的 3 个模型的工作示例代码吗?
嗨,Jason,您能否在一个小型文本数据集上提供其中一种架构的示例运行代码。我将不胜感激。
我希望将来能给出一些例子。
先生,我的摘要形状为 (3000,100,12000),即 3000 -> 示例,100 -> 摘要的最大长度,12000 -> 词汇量。现在我需要将此形状转换为分类值以使用 keras to_categorical 来查找损失。但是我遇到了内存错误。我有 8 GB 内存。请提供适当的解决方案。
是否有必要将摘要转换为分类值,或者我们不能也对摘要使用嵌入吗?如果可以,那么损失应该是什么,因为对于分类交叉熵损失,我们需要将我们的摘要转换为独热编码。
许多人面临这个问题。请提出解决方案。
当使用嵌入层作为输入时,您必须提供整数序列,其中每个整数映射到词汇表中的一个单词。
我的博客上有很多例子。
如果您内存不足,请尝试使用渐进加载。我有一个关于图片标注的例子。
是的,先生,但主要问题在于将目标摘要转换为分类数据,因为我的 num_classes 是 12000。
我还有另一个疑问。
在训练模型时,我遇到了一个未知问题,我的训练和验证损失持续下降,但准确率在一段时间后变得恒定。
请回答第二个问题。我真的被这个问题困住了。无法理解这个问题背后的逻辑。
是的,输出将是独热编码。12K 的输出词汇量非常小。
准确率对于文本数据来说是一个糟糕的指标。忽略它。
这意味着对于文本数据,我应该只关注损失的减少,因为在我的情况下,训练和验证损失都在持续下降,但训练和验证准确率停留在大约 0.50 的一个点上。
是的,关注损失。不要测量文本问题的准确性。
嗨,先生,我只是想知道抽象文本摘要背后的逻辑是什么,我们的模型如何能够总结测试数据,因为通常在分类的情况下,我们有一条曲线可以概括我们的数据,但在文本的情况下,泛化是不可能的,因为每个测试数据都是新的并且与训练数据不同。
好问题。模型学习文本中的概念以及如何简洁地描述这些概念。
那么,在这种情况下,我们的摘要与测试数据的黄金摘要匹配的可能性非常小。那我们为什么要使用 Bleu 或 Rouge 矩阵来评估我们的模型呢?
对于所有方法,我都收到以下错误
检查目标时出错:期望 time_distributed_38 具有 3 个维度,但得到的数组形状为 (222, 811)
我如何解决这个问题?
要么更改您的数据以满足模型的预期,要么更改模型以满足数据的预期。
你好,杰森。
谢谢你的回答。我是初学者,正在尝试学习如何总结文本。
我写了一个简单的例子,如下所示。但它存在形状问题。
您能告诉我在此示例中,我应该如何以及在哪里更改数据或模型吗?
谢谢
# 模块
import os
import numpy as np
from keras import *
from keras.layers import *
来自 keras.models import Sequential
from keras.preprocessing.text import Tokenizer, one_hot
from keras.preprocessing.sequence import pad_sequences
src_txt = [“I read a nice book yesterday”, “I have been living in canada for a long time”, “I study computer science this year in frence”]
sum_txt = [“I read a book”, “I have been in canada”, “I study computer science”]
vocab_size = len(set((” “.join(src_txt)).split() + (” “.join(sum_txt)).split()))
print(“词汇量:” + str(vocab_size))
src_txt_length = max([len(item) for item in src_txt])
print(“源文本长度:” + str(src_txt_length))
sum_txt_length = max([len(item) for item in sum_txt])
print(“摘要文本长度:” + str(sum_txt_length))
# 整数编码文档
encoded_articles = [one_hot(d, vocab_size) for d in src_txt]
encoded_summaries = [one_hot(d, vocab_size) for d in sum_txt]
# 将文档填充到最大长度为 4 个单词
padded_articles = pad_sequences(encoded_articles, maxlen=10, padding=’post’)
padded_summaries = pad_sequences(encoded_summaries, maxlen=5, padding=’post’)
print(“填充文章:{}”.format(padded_articles.shape))
print(“填充摘要:{}”.format(padded_summaries.shape))
# 编码器输入模型
inputs = Input(shape=(src_txt_length,))
encoder1 = Embedding(vocab_size, 128)(inputs)
encoder2 = LSTM(128)(encoder1)
encoder3 = RepeatVector(sum_txt_length)(encoder2)
# 解码器输出模型
decoder1 = LSTM(128, return_sequences=True)(encoder3)
outputs = TimeDistributed(Dense(vocab_size, activation=’softmax’))(decoder1)
# 连接起来
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’)
# 拟合模型
model.fit(padded_articles, padded_summaries, epochs=10, batch_size=32)
#model.fit(padded_articles, padded_summaries)
—————————————————————————
ValueError 回溯 (最近一次调用)
in ()
1 # 拟合模型
—-> 2 model.fit(padded_articles, padded_summaries, epochs=10, batch_size=32)
3 #model.fit(padded_articles, padded_summaries)
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, **kwargs)
1579 class_weight=class_weight,
1580 check_batch_axis=False,
-> 1581 batch_size=batch_size)
1582 # 准备验证数据。
1583 do_validation = False
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in _standardize_user_data(self, x, y, sample_weight, class_weight, check_batch_axis, batch_size)
1412 self._feed_input_shapes,
1413 check_batch_axis=False,
-> 1414 exception_prefix=’input’)
1415 y = _standardize_input_data(y, self._feed_output_names,
1416 output_shapes,
C:\Users\diyakopalizi\AppData\Local\Continuum\Anaconda3\lib\site-packages\keras\engine\training.py in _standardize_input_data(data, names, shapes, check_batch_axis, exception_prefix)
151 ‘ to have shape ‘ + str(shapes[i]) +
152 ‘ but got array with shape ‘ +
–> 153 str(array.shape))
154 return arrays
155
ValueError: Error when checking input: expected input_23 to have shape (None, 44) but got array with shape (3, 10)
抱歉,我没有能力为您调试代码。也许可以发布到 stackoverflow?
你解决了吗?
好的,谢谢。
我在这里学到了很多。
不客气,很高兴听到这个消息。
你好 jason!
我想只使用 tensorflow 实现分层 LSTM 文本摘要器。我是一个初学者,我获得了数据集 https://github.com/SignalMedia/Signal-1M-Tools/blob/master/README.md,但我无法使用此数据集,因为它太大了,我的笔记本电脑无法处理,您能告诉我如何预处理这些数据以便我可以对其进行标记并使用预训练的 glove 模型作为嵌入吗?
是的,我有很多关于如何准备文本数据进行建模的资料。
一个好的起点是这里
https://machinelearning.org.cn/start-here/#nlp
嗨,Jason,感谢您的帖子,它对解决问题非常有帮助。
我不明白的是网络的训练过程。我的意思是,我们没有文档的摘要(在测试集中),所以我假设,一开始,我们以零序列作为摘要输入。
然后,在训练阶段,我猜测我们需要循环摘要中的所有单词,并将这些单词设置为输出。因此,就迭代次数而言,我们需要为摘要中的每个单词,为数据集中的每个条目执行“训练”操作,并重复该过程几次。
某种程度上,这个过程在我脑海中并不十分清楚。您能给我一些资源来理解训练过程吗?
谢谢你
训练数据集必须包含完整的文档和摘要——例如,模型可以从中学习的东西。
您能更详细地描述训练过程吗?
也许重新阅读上面的帖子和引用的论文?
也请阅读这些帖子
https://machinelearning.org.cn/?s=text+summarization&post_type=post&submit=Search
嗨,Jason
替代方案 2 中合并层的作用是什么?它是否用于使 Dense 层同时了解输入和输出?
将文档的表示和到目前为止生成的文本合并为单个表示,作为预测下一个单词的基础。
嗨,感谢您与我们分享这些。您能为我解释一下为什么我们使用 vocab_size 变量吗?以及这如何参与到自动编码器架构中?如果我们有一个文本作为示例,vocab_size 将代表文本中唯一标记的数量吗?提前感谢。
词汇量大小是我们希望建模的单词数量。
此示例中没有自动编码器。
嗨,Jason,我不明白解码器使用的损失函数是什么。我知道在语言翻译中,我们有 (x, y) 的标记训练数据(源语言句子,目标语言翻译)。但是,在文本摘要中,我们是否真的有 (源句子,目标摘要) 的标记训练数据?我知道您的代码使用 categorical_crossentropy 损失函数,但是损失是针对哪个标签计算的?
是的,您需要源文本和目标文本来训练模型。
当我实现(递归模型 B)时,我遇到了摘要输入层的问题。
如何让 keras 将输出单词推送到摘要层输入中。
打印错误:检查模型输入时:期望看到 2 个数组,但得到了 1 个数组的以下列表
我当前的 .fit 实现
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
模型实现
# 摘要
inputs_summary = Input(shape=(count_output,))
layer_summary = Embedding(vocab_size, embed_size)(inputs_summary)
# 编码器
input_comm = Input(shape=(input_size,))
layer_comm = Embedding(vocab_size, embed_size)(input_comm)
……
# 解码器
decoder1 = concatenate([layer_comm, layer_titles])
……
model = Model(inputs=[input_comm, inputs_summary], outputs=[layer_out])
你可以用一个 for 循环自己完成。
杰森,您好!
我希望你能弄清楚以下问题
在递归模型 A 和 B 中,我注意到你使用了两个嵌入层,每个输入一个
输入1(源)
嵌入1…
输入2(摘要)
嵌入2….
我知道一个嵌入层是由训练过的 word2vec 或 glove 模型的信息(形状和权重)组成的——我已经用源训练了一个 word2vec 模型——我不知道的是,在你的代码中,Embedding1 和 Embedding2 层是否相同,或者我是否也必须为摘要训练一个 word2vec 模型来创建 Embedding2 层
相同,或者我是否必须创建一个 word2vec 模型
我知道这些是由 word2vec 模型的权重形状组成的。我不知道的是以下内容
如果这对于特定问题有意义,它们可以是相同的。
在第三个模型中,“article3”层在每个时间步输出隐藏状态,这些隐藏状态将与嵌入层的输出连接起来?“article3”的张量形状是什么?
谢谢你
你可以按如下方式打印各层的形状
嗨,Jason,
有没有一种方法可以在训练时没有目标摘要的情况下训练模型来总结文本?
对于监督学习模型来说不行。
对于备选3模型,inputs1 和 inputs2 会是什么?代码没有执行你在图中描述的操作。
模型3的代码如何管理图中描述的循环?请提供更多细节。
你需要自己编写循环代码。
这张图是否清楚?具体哪个部分令人困惑?
根据我的理解,inputs2 应该是输出词。我不明白你如何将输出词再次反馈给网络。
谢谢,
R
也许可以先尝试这个教程来熟悉架构。
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
嗨,Jason,
解码器是输出有意义的句子摘要还是词袋?
它输出一个可读的摘要。
你不能使用你之前写的另一篇文章中类似的编码器-解码器架构吗?但是你也许可以添加一个嵌入层。
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
当然可以。
我不理解 RepeatVector 的用法,请解释一下
它将一个层的输出(例如一个向量)重复多次作为后续层的输入。
这有帮助吗?
你好 Jason,你能帮我一下吗?我的理解是,你开发了这三个模型(备选1、2和3)是因为你提到的问题:“Keras 不允许模型输出自动作为模型输入的递归循环。”
然而,我不知道你为什么会写出那句话。这不正是你在文章“如何开发一个词级神经语言模型并用它来生成文本”中为语言模型文本生成所实现循环吗?文章链接如下:
https://machinelearning.org.cn/how-to-develop-a-word-level-neural-language-model-in-keras/?
在那篇文章中,作为文本生成的一部分,你创建了:(1) 对 N 个要生成的词进行循环;(b) 调用 model.predict() 生成下一个词;(c) 将生成的词添加到已生成词的窗口中;(d) 使用生成的词作为下一次调用 model.predict() 的输入。
你能解释一下区别吗?
是的,Keras 不会自动完成,我们必须编写一个循环来完成。
为什么模型通常是在“未嵌入”的输出上进行拟合?
我看到很多代码(几乎所有)都将输入通过“Embedding”层(以函数式 API 风格的代码)传递,然后模型以“outputs”作为真实输出序列进行拟合。
这意味着,我们正在将嵌入的输入与真实输出进行映射(从真实意义上训练网络的参数)..这看起来有点奇怪。
这是否意味着 Dense 层负责处理未嵌入的部分?
这与“units”参数设置为嵌入特征的数量这一事实相符!
此外,LSTM 的“units”参数是如何选择的?
它是否设置为填充序列的长度(输入和输出序列都一样)
我不明白,抱歉?
关于单元的数量,这会有帮助
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
嗨,Jason,
我有一个安全数据集,我想使用 ANN 或 LSTMN 来预测网站是否恶意。
IP 国家 操作系统 域名 攻击 信号 威胁
0.0.0.0.0 美国 Windows 某个域名.net 计算机服务器 899238erdjshgh90ds 是
编码这些列的最佳方法是什么?你有什么可以推荐的教程链接吗?你认为 ANN 或 LSTMN 哪个更适合预测/分类结果,例如威胁是或否?
非常感谢。
听起来是个很棒的项目。
我建议测试一系列表示法,以发现哪种效果最好。
也许词嵌入会是一个有用的方法?
先生,由于词嵌入已经是固定长度的向量,我可以直接将它们与解码器一起使用吗?然而,编码器会将它们转换为固定长度的向量。
你最终会得到一个嵌入序列,这个序列也必须是固定长度的。
嗨,Jason,
现在,我正在研究文本到图像项目,我想训练我的数据集的标题(文本)和图像以获得 pickle 文件。我仍在寻找这个问题的解决方案,但目前一无所获。所以我想请你帮我获得 Text2Image 编码器-解码器?你对此有什么想法吗?
提前感谢。
我见过一些关于使用 GAN 进行文本到图像任务的有趣论文。
我建议通过 Google 学术搜索查阅该主题的一些最新研究。
是的,我明白了,我研究了 Stack-GAN 算法,但是已经有一个文本和图像编码器文件(char-CNN-RNN text embeddings.pickle),我想用我自己的数据集从头开始训练它。你能告诉我如何预处理这个文件吗?
期待您的回复!
抱歉,我没有 Stack GAN 的教程。
您有上述3个模型的任何可用代码吗?如果有的话会很有帮助。
抱歉,我没有。
嗨,Jason,
感谢这篇精彩的文章。我有一个关于模型2——“备选2:递归模型 A”的问题。因为它同时使用了已生成的摘要信息和编码器生成的表示,所以它是否遵循“教师强制策略”?
是的,它使用了教师强制。
感谢您的回答,Jason。
我对文本摘要模型中开始和结束标记的作用有点好奇。
这些标记如何帮助解码器?
它们帮助模型了解如何开始和结束一个输出序列。
也许这个图片字幕的例子会更清楚
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
嗨,Jason,
谢谢你的帖子!它非常有见地。我喜欢你描述每种结构的优缺点。
对于递归模型 B,你能帮助我理解如何准备数据吗?
考虑到其结构,我有点困惑输入应该是什么样子。以下是我的想法
假设
src_txt_length = 8
sum_txt_length = 4
那么传统的文本准备方法最终会得到这样的结果(我为每一行给出了第一个值作为示例)
文本的填充序列
[w1, w2, w3, w4, w5, 0, 0, 0]
摘要的填充序列
[s1, s2, 0, 0, 0]
显然,上述内容不能直接用于递归 B 的结构(也许我错了)。
我认为我们需要更进一步,得到这样的结果
输入 1
[[w1, w2, w3, w4,w5, 0, 0, 0], [w1, w2, w3, w4, w5, 0, 0, 0], [w1, w2, w3, w4, w5, 0, 0, 0]]
输入 2
[[0,0,0,0,0], [s1,0,0,0,0], [s1,s2,0,0,0]]
标签
[[s1 的独热编码向量], [s2 的独热编码向量],[0 的独热编码向量]]
这样,批量大小 = 1 的训练,例如,将使用
[w1, w2, w3, w4,w5, 0, 0, 0] 和 [0,0,0,0,0] 来推断一个向量,该向量将针对 s1 的独热编码向量进行优化
我的思路正确吗?如果您能给我指明正确的方向,我将不胜感激!
提前感谢!
也许可以模拟一些测试示例,然后尝试将其输入模型?
嗨,Jason,
是的,我确实构建了测试示例,模型拟合没有错误。
然而,我上面提到的转换过程相当繁琐。所以我想知道你是否有其他关于如何为这种结构准备数据的想法。
抱歉,我无法准备定制的示例——我没有这个能力。
感谢您的这份指南。
用于拟合模型的训练数据和目标数据是什么?
我构建了一个具有以下结构的模型
模型:“model_1”
__________________________________________________________________________________________________
层(类型)输出形状参数 # 连接到
==================================================================================================
input_3 (InputLayer) [(None, 5000)] 0
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 5000, 128) 796928 input_3[0][0]
__________________________________________________________________________________________________
lstm_2 (LSTM) (None, 64) 49408 embedding_2[0][0]
__________________________________________________________________________________________________
input_4 (InputLayer) [(None, 30)] 0
__________________________________________________________________________________________________
repeat_vector_1 (RepeatVector) (None, 30, 64) 0 lstm_2[0][0]
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, 30, 128) 796928 input_4[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 30, 192) 0 repeat_vector_1[0][0]
embedding_3[0][0]
__________________________________________________________________________________________________
lstm_3 (LSTM) (None, 128) 164352 concatenate_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 6226) 803154 lstm_3[0][0]
==================================================================================================
总参数:2,610,770
可训练参数:2,610,770
不可训练参数: 0
当我尝试
model.fit([texts, summaries], validation_split = 0.1, epochs=epochs, batch_size=batch_size, verbose=1, callbacks=[LossHistory()])
处理第一个批次时,我得到了 IndexError: list index out of range 错误,可能是因为缺少目标数据
我们不能在第一个解释的通用模型中使用教师强制方法吗?这将规避递归循环的障碍。
当然,你可以以任何你喜欢的方式训练模型。
递归模型 B 可以非常简单地实现。
https://imgur.com/mxFXG38
太棒了!
你有没有在任何数据集上使用过这个模型?
嗨 Jason – 感谢您的这篇文章,它很棒!我只是对示例代码中 inputs1、inputs2 和 outputs 的含义有一个疑问。我的理解如下;
inputs1:整个源序列 [例如:一个包含 300 个单词的段落(分词后)]
inputs2:从技术上讲,这应该是一个单词 [上一个时间步预测的单词]。
outputs:这应该是整个摘要。但是我们需要 TimeDistributed 来逐词获取摘要吗?
我的理解正确吗?或者对于 inputs2,它会是到上一步为止的 *所有* 单词序列,而不仅仅是一个单词吗?提前感谢!
是的,或者 inputs2 将是迄今为止生成的整个序列。
非常感谢您的这篇非常有用的帖子。
如果您能为备选3:递归模型 A 和 B 提供一些代码,包括 (1) 拟合 (2) 预测,我将不胜感激。
特别是对于拟合,令人困惑的部分是如何生成 inputs2。似乎输出只是一个单一的预测(即,Dense 层形状 = (词汇量大小))
对于预测,模型是如何调用的,特别是当 inputs2 未知且模型再次预测 1 个输出时。
最初,我以为这样的方法会奏效
用于拟合模型
outputs = ['this' , 'is' , 'a' , 'summary']
inputs2_during_fitting = ['开始总结', 'this' , 'is' , 'a']
但我很困惑这会如何工作,因为模型每次被调用时只吐出一个预测/单词。
所以它不能一次训练整个序列。
为了预测第一个单词,我想我会像这样传递给模型。
outputs = ['this' , 'is' , 'a' , 'summary']
inputs2_during_prediction = ['开始总结', '未知', '未知', '未知']
但是模型如何知道我正在请求第一个输出词而不是第二个输出词呢?
谢谢!
感谢您的建议,我将来可能会涵盖它。
嘿 Jason,关于递归模型 B,我不太理解工作流程,图片中看起来像一个循环,我已经像上面的例子那样实现了,那么它是否循环呢?
我们正在循环一个输入序列。
也许从这里开始
https://machinelearning.org.cn/models-sequence-prediction-recurrent-neural-networks/
嗨 Jason,感谢您的精彩文章。我有一个关于第三种架构的问题。最终,如果我们想使用源文档的内部表示,我们应该使用 article2 层的输出吗?
也许可以尝试一下,看看什么有效?
嗨 Jason,我使用您的另一篇文章准备了我的数据,如何在这里使用这些 pkl 文件
我不知道你的数据是什么,也不知道如何加载它。
嗨,Jason,
根据带注意力机制的编码器-解码器模型,解码器逐个时间步处理输入。第一次时间步预测将编码器的最后状态作为初始状态,并输出解码器输出和隐藏状态,该隐藏状态作为下一个时间步的初始状态。
这种迭代过程如何在 TensorFlow 中使用带注意力机制的编码器-解码器架构捕获?我们是否为解码器的每个时间步应用循环?解码器的嵌入向量又如何呢?是在循环外部计算并访问,还是在循环内部计算?
我问这个的原因是,我没有在您的解码器架构中看到任何循环和反馈
好问题,我经常使用基于自动编码器的架构,因为它快速有效
https://machinelearning.org.cn/lstm-autoencoders/
你可以在这里看到另一种类型
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
模型:“model_4”
_________________________________________________________________
层(类型) 输出形状 参数 #
=================================================================
input_5 (InputLayer) [(None, 5000)] 0
_________________________________________________________________
embedding_4 (Embedding) (None, 5000, 128) 799488
_________________________________________________________________
lstm_8 (LSTM) (None, 128) 131584
_________________________________________________________________
repeat_vector_4 (RepeatVecto (None, 125, 128) 0
_________________________________________________________________
lstm_9 (LSTM) (None, 125, 128) 131584
_________________________________________________________________
time_distributed_4 (TimeDist (None, 125, 6246) 805734
=================================================================
总参数:1,868,390
可训练参数:1,868,390
不可训练参数: 0
___________________________
如何拟合我的数据?
嗨,Jason,
我尝试使用您介绍的最后一个架构与 CNN 新闻数据集,一切都与此非常相似,但是当我尝试训练模型时它给我一个错误,我无法在任何地方找到这个错误,
“ValueError: Layer model_7 expects 2 input(s), but it received 1 input tensors. Inputs received: []”
很抱歉听到这个消息,也许这些建议中的一个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你能分享代码给我们吗
谢谢,也许以后会。
嗨,Jason,
我认为如果我们假设源和摘要具有不同的词汇量大小,那么 Dense 层应该像这样:outputs = Dense(summary_vocab_size, activation=’softmax’)(decoder2)
是的,你说得对。
那么请在代码中编辑一下,以免人们混淆。
你好 Jason,我有一个关于这个教程的问题。你为编码器(即原始文本)设置了一个嵌入层,为解码器(摘要)设置了另一个嵌入层。我推断这两个嵌入模型是独立的。这意味着对于同一个词,这两个模型将生成两个不同的嵌入。我们为什么对此没有意见?
简单来说,数据上的训练会使其奏效。两个嵌入可能会产生不同的结果,这不是问题,因为文本和摘要可能拥有不同的词汇集。重要的是接收嵌入输出的 LSTM 层。经过训练后,它会知道如何使用它们。
谢谢你,Adrian!
嗨,Jason,
我使用了一个编码器-解码器模型来生成新闻摘要,但预测的序列是这样的
实际:[['startseq 截至周四,Facebook 允许用户编辑评论而不是重新输入,每条评论都将在下拉菜单中显示其编辑历史记录,以便为用户提供上下文,编辑功能将在接下来的几天内逐步向用户推出 endseq']]
预测:['startseq the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the']
如你所见,它生成了大量的“the”,你遇到过这样的问题吗?
你有什么建议吗?