用于循环神经网络的编码器-解码器架构是标准的神经机器翻译方法,它与传统的统计机器翻译方法相媲美,甚至在某些情况下表现更优。
这种架构非常新颖,直到2014年才首次提出,但已被谷歌翻译服务采纳为核心技术。
在这篇文章中,您将了解神经机器翻译中编码器-解码器模型的两个开创性示例。
阅读本文后,你将了解:
- 编码器-解码器循环神经网络架构是谷歌翻译服务的核心技术。
- 所谓的“Sutskever 模型”用于直接端到端机器翻译。
- 所谓的“Cho 模型”通过GRU单元和注意力机制扩展了该架构。
通过我的新书《深度学习与自然语言处理》启动您的项目,包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

用于神经机器翻译的编码器-解码器循环神经网络模型
图片由Fabio Pani提供,保留部分权利。
NMT 的编码器-解码器架构
带循环神经网络的编码器-解码器架构已成为神经机器翻译 (NMT) 和一般序列到序列 (seq2seq) 预测的有效且标准的方法。
该方法的主要优点是能够直接在源句子和目标句子上训练一个单一的端到端模型,并且能够处理可变长度的文本输入和输出序列。
作为该方法成功的证据,该架构是谷歌翻译服务的核心。
我们的模型遵循带有注意力机制的常见序列到序列学习框架。它包含三个组件:一个编码器网络、一个解码器网络和一个注意力网络。
— 谷歌神经机器翻译系统:弥合人与机器翻译之间的差距,2016年
在这篇文章中,我们将仔细研究两个不同的研究项目,它们在2014年同时开发了相同的编码器-解码器架构,并取得了让该方法备受关注的成果。它们是:
- Sutskever NMT 模型
- Cho NMT 模型
有关该架构的更多信息,请参阅该文章
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Sutskever NMT 模型
在本节中,我们将介绍由Ilya Sutskever等人开发的神经机器翻译模型,如他们2014年论文“使用神经网络进行序列到序列学习”所述。我们将它称为“Sutskever NMT 模型”,因为没有更好的名称。
这是一篇重要的论文,因为它最早引入了用于机器翻译以及更一般的序列到序列学习的编码器-解码器模型之一。
它是机器翻译领域的一个重要模型,因为它是第一个在大型翻译任务上优于基准统计机器学习模型的神经机器翻译系统之一。
问题
该模型应用于英语到法语的翻译,特别是WMT 2014 翻译任务。
翻译任务一次处理一个句子,在训练期间,输出序列的末尾添加了一个序列结束(<EOS>)标记,以表示翻译序列的结束。这使得模型能够预测可变长度的输出序列。
请注意,我们要求每个句子以特殊的句子结束符号“<EOS>”结尾,这使得模型能够定义所有可能长度序列的分布。
该模型在数据集的1200万个句子中的一个子集上进行训练,该子集包含3.48亿法语单词和3.04亿英语单词。选择这个集合是因为它已经预先分词。
源词汇表减少到最常用的16万个源英语单词和8万个最常用的目标法语单词。所有词汇表外的单词都被替换为“UNK”标记。
模型
开发了一种编码器-解码器架构,其中输入序列被完整读取并编码为固定长度的内部表示。
然后,解码器网络使用此内部表示输出单词,直到达到序列结束标记。LSTM 网络用于编码器和解码器。
其思想是使用一个 LSTM 一次读取一个时间步的输入序列,以获得大型固定维度的向量表示,然后使用另一个 LSTM 从该向量中提取输出序列。
最终模型是5个深度学习模型的集合。在翻译推断期间使用了从左到右的束搜索。
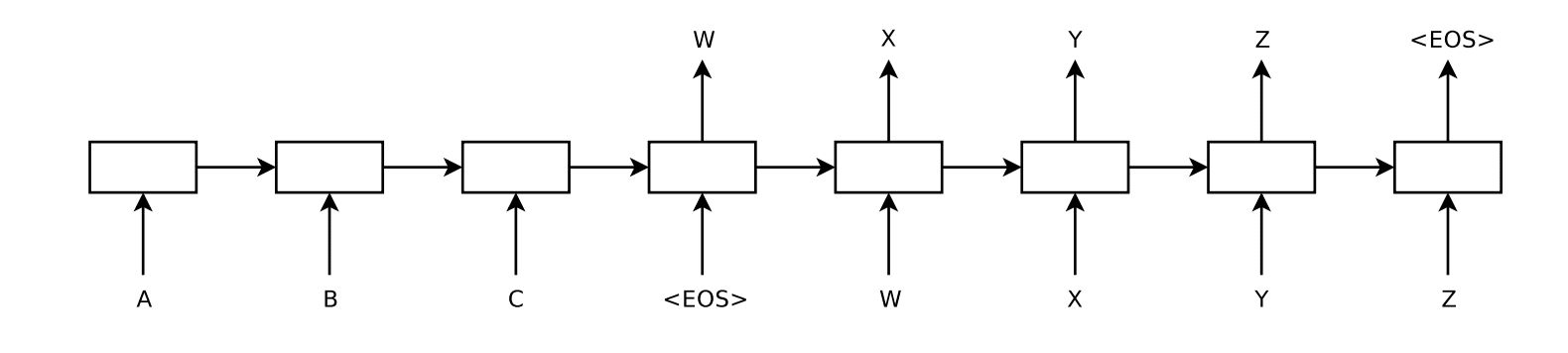
Sutskever 编码器-解码器模型用于文本翻译的示意图
摘自《使用神经网络进行序列到序列学习》,2014年。
模型配置
- 输入序列被反转。
- 使用一个1000维的词嵌入层来表示输入单词。
- 输出层使用Softmax。
- 输入和输出模型有4层,每层有1,000个单元。
- 该模型经过7.5个epoch的训练,并进行了一些学习率衰减。
- 训练期间使用128个序列的批量大小。
- 训练期间使用梯度裁剪以减轻梯度爆炸的可能性。
- 批量由长度大致相同的句子组成,以加快计算速度。
该模型在8个GPU机器上训练,每个层在不同的GPU上运行。训练耗时10天。
最终的实现以每秒6,300个单词(英语和法语)的速度,迷你批次大小为128。使用此实现进行训练大约需要十天。
结果
该系统获得了34.81的 BLEU 分数,与使用统计机器翻译系统开发的基准分数33.30相比,这是一个不错的成绩。重要的是,这是第一个神经机器翻译系统在大规模问题上优于基于短语的统计机器翻译基准的例子。
... 我们获得了34.81的BLEU分数[...] 这是大型神经网络直接翻译所取得的迄今为止最好的结果。作为比较,SMT 基线在此数据集上的BLEU分数为33.30。
最终模型被用于重新评估最佳翻译列表,并将分数提高到36.5,使其接近当时37.0的最佳结果。
您可以在此处观看与该论文相关的演讲视频。
Cho NMT 模型
在本节中,我们将介绍由Kyunghyun Cho等人于2014年发表的题为“使用RNN编码器-解码器学习短语表示以进行统计机器翻译”的论文中描述的神经机器翻译系统。我们将它称为“Cho NMT 模型”,因为没有更好的名称。
重要的是,Cho 模型仅用于评估候选翻译,而不像上面的 Sutskever 模型那样直接用于翻译。尽管为了更好地诊断和改进模型而对该工作进行的扩展确实直接且单独地将其用于翻译。
问题
如上所述,该问题是WMT 2014研讨会上的英语到法语翻译任务。
源词汇表和目标词汇表限制为最常用的15,000个法语和英语单词,覆盖了数据集的93%,词汇表外的单词被“UNK”替换。
模型
该模型采用相同的双模型方法,在此明确命名为编码器-解码器架构。
... 称为 RNN 编码器-解码器,由两个循环神经网络 (RNN) 组成。一个 RNN 将符号序列编码成固定长度的向量表示,另一个将该表示解码成另一个符号序列。
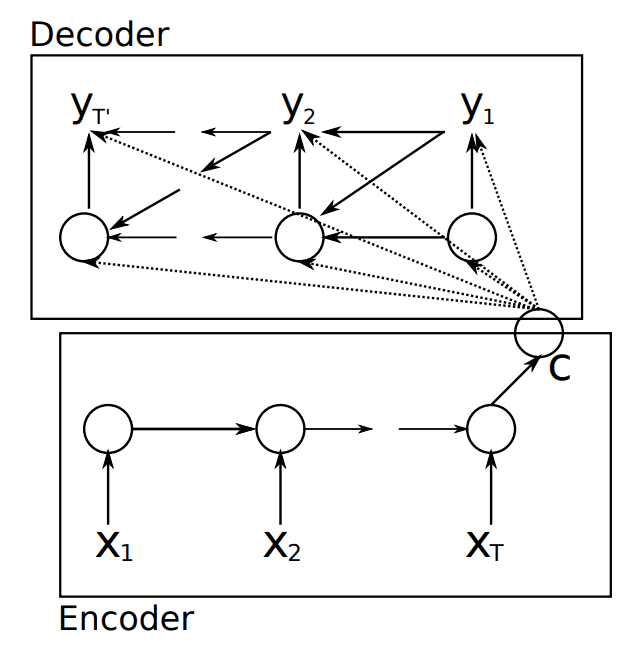
编码器-解码器架构的示意图。
摘自“使用RNN编码器-解码器学习短语表示以进行统计机器翻译”。
该实现不使用 LSTM 单元;相反,开发了一种更简单的循环神经网络单元,称为门控循环单元(GRU)。
...我们还提出了一种新型的隐藏单元,它受到了LSTM单元的启发,但在计算和实现上要简单得多。
模型配置
- 使用100维的词嵌入来表示输入单词。
- 编码器和解码器配置为1层,包含1000个 GRU 单元。
- 解码器后使用了500个 Maxout 单元,池化2个输入。
- 训练期间使用64个句子的批量大小。
该模型训练了大约2天。
扩展
在论文《神经机器翻译的特性:编码器-解码器方法》中,Cho等研究了他们模型的局限性。他们发现性能随着输入句子长度的增加和词汇表外单词数量的增加而迅速下降。
我们的分析表明,神经机器翻译的性能受到句子长度的显著影响。
他们提供了一个有用的图表,显示了模型性能随句子长度增加而逐渐下降,捕捉了随着难度增加而技能逐渐丧失的情况。
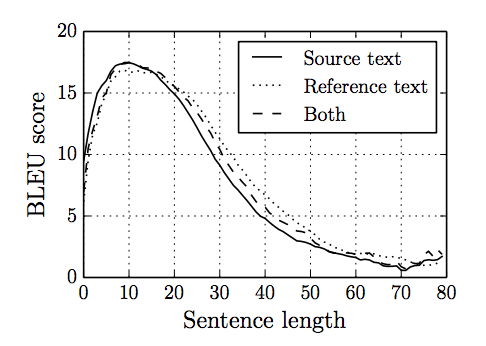
模型技能随句子长度增加而损失。
摘自《神经机器翻译的特性:编码器-解码器方法》。
为了解决未知词的问题,他们建议在训练期间大幅增加已知词汇的词汇量。
他们在后续论文《通过联合学习对齐和翻译的神经机器翻译》中解决了句子长度问题,其中他们提出了使用注意力机制。模型不再将输入句子编码为固定长度的向量,而是保留编码输入的更完整表示,并学习为解码器输出的每个单词关注输入的不同部分。
每次所提出的模型生成一个翻译词时,它会(软)搜索源句子中信息最相关的位置集。然后,该模型根据与这些源位置相关联的上下文向量以及所有先前生成的预测目标词来预测目标词。
论文中提供了丰富的技术细节;例如
- 使用了一个配置类似的模型,但带有双向层。
- 数据经过处理,词汇表中保留了30,000个最常用词。
- 模型首先用长度不超过20个单词的句子进行训练,然后用长度不超过50个单词的句子进行训练。
- 使用80个句子的批次大小,模型训练了4-6个 epoch。
- 在推断过程中使用束搜索来找到每个翻译最有可能的单词序列。
这次模型大约需要5天时间来训练。这个后续工作的代码也已提供。
与Sutskever一样,该模型取得了与经典基于短语的统计方法相当的结果。
也许更重要的是,所提出的方法取得了与现有基于短语的统计机器翻译相当的翻译性能。这是一个惊人的结果,考虑到所提出的架构,或者说整个神经机器翻译家族,直到今年才被提出。我们相信这里提出的架构是朝着更好的机器翻译和更好地理解自然语言迈出的有希望的一步。
Kyunghyun Cho 也是 Nvidia 开发者博客上关于神经机器翻译编码器-解码器架构主题的2015系列文章“GPU 神经机器翻译简介”的作者。该系列文章对该主题和模型提供了很好的介绍;请参阅第1部分、第2部分和第3部分。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 谷歌神经机器翻译系统:弥合人与机器翻译之间的差距, 2016.
- 使用神经网络进行序列到序列学习, 2014.
- 《使用神经网络进行序列到序列学习》的演示文稿, 2016.
- Ilya Sutskever 主页
- 使用 RNN 编码器-解码器学习短语表示进行统计机器翻译, 2014.
- 通过联合学习对齐和翻译的神经机器翻译, 2014.
- 神经机器翻译的特性:编码器-解码器方法, 2014.
- Kyunghyun Cho 主页
- GPU 神经机器翻译简介(第1部分、第2部分、第3部分),2015年。
总结
在这篇文章中,您发现了神经机器翻译中编码器-解码器模型的两个示例。
具体来说,你学到了:
- 编码器-解码器循环神经网络架构是谷歌翻译服务的核心技术。
- 所谓的“Sutskever 模型”用于直接端到端机器翻译。
- 所谓的“Cho 模型”通过 GRU 单元和注意力机制扩展了架构。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。






这篇文章很鼓舞人心!谢谢你,贾森。
谢谢,听到这个我很高兴。
真是太棒了,完美。
谢谢。
这种技术可以用于音译(专有名词)吗?还是音译会更简单?如果是,对于英语到阿拉伯语和反向音译,哪种序列到序列模型比较好?
我相信是的。
嗨,Jason,
我从您精彩的系列文章中学到了很多。感谢您提供了所有这些知识。我有一个小问题。我尝试了 LSTM 和 GRU 在音译任务上。GRU 的 BLEU 分数是0.08,而 LSTM 的是0.72。为什么会有如此巨大的差异?GRU 应该与 LSTM 表现相当。在这方面有什么见解或指示吗?
它们是不同的,因此不能并驾齐驱。
对于不同问题,不同算法会产生不同的结果。
对于像我这样的机器学习-深度学习新手来说,信息量非常大。
谢谢先生。
谢谢。
我们可以在编码器-解码器结构中使用双向 LSTM 作为解码器吗?
当然可以。
你好 Jason,我有两个问题
seq2seq 可以处理多长的序列,10个?100个?还是多达1000个?
我可以使用 seq2seq 作为特征提取器吗?当我将相同的序列输入编码器和解码器时,只使用编码器的输出来作为输出特征?
好问题,也许200-400个时间步的输入和输出。也许可以尝试一下看看什么有效。
我对NMT在软件工程中的应用很感兴趣。但我对各种编码器-解码器结构之间的区别有一些疑问。您能帮我吗?
我可以试试,你的问题是什么?
我感兴趣的是,将一份代表客户过去某个时间段内产品购买情况的文档,转化为一份代表未来某个时间段内极可能购买情况的文档。然后我将用它为客户创建推荐产品列表。您概述的技术能够提取过去购买行为中的潜在概率结构,然后合成未来的购买行为吗?
很难脱口而出,我建议探索一些原型,看看它是否可行。或者查阅文献,看看是否有类似的问题已经解决/处理过。
这真是一篇很棒的文章。我刚接触这个领域,您能给我一些资源来了解带注意力机制的编码器-解码器模型的基本实践见解吗?我将不胜感激……谢谢!
是的,也许这些教程会有帮助
https://machinelearning.org.cn/?s=encoder+decoder+attention&post_type=post&submit=Search
我想为我的语言 Afaan Oromo 和 Amharic 开发 NMT;我在 Spacy 方面遇到了困难,您能告诉我如何使用 RNN 开发基于网络的机器翻译系统吗?
抱歉,我不太了解如何开发用于机器翻译的网站。