Transformer模型以其强大的架构彻底改变了自然语言处理(NLP)。虽然最初的Transformer论文引入了完整的编码器-解码器模型,但为了满足不同的需求,这种架构的变体也应运而生。在本文中,我们将探讨不同类型的Transformer模型及其应用。
让我们开始吧。

Transformer 模型中的编码器和解码器
照片作者:Stephan Streuders。部分权利保留。
概述
本文分为三个部分;它们是:
- 完整 Transformer 模型:编码器-解码器架构
- 仅编码器模型
- 仅解码器模型
完整 Transformer 模型:编码器-解码器架构
原始Transformer架构在“Attention is All You Need”一文中提出,它结合了专门用于序列到序列(seq2seq)任务(如机器翻译)的编码器和解码器。架构如下所示。
来自“Attention is All You Need”论文的Transformer架构
编码器将输入序列(例如,源语言的句子)处理成上下文表示。它由一系列相同的层组成,每层包含一个自注意力子层和一个前馈子层。
解码器遵循类似的结构,处理目标序列(例如,目标语言的部分句子)。每个解码器层包含三个子层:自注意力、交叉注意力和前馈。交叉注意力子层是解码器特有的,它将编码器的上下文与目标序列相结合以生成输出。
在完整的Transformer模型中,编码器和解码器是连接在一起的,但是必须先由编码器处理整个输入序列,然后解码器才能开始生成输出。编码器使每个token能够关注输入序列中的所有其他token,从而创建丰富的上下文表示。
Transformer的标志性特征是其注意力层。注意力输出是值序列$V$的加权和,其中权重是通过将查询$Q$与键序列$K$进行注意力计算而得到的注意力分数。虽然查询和键序列的长度可能不同,但值序列必须与键序列长度匹配。结果是一个形状为$(L_Q, L_K)$的矩阵$A$,其中$A_{i,j}$表示第$i$个查询元素与第$j$个键元素之间的注意力分数。
编码器和解码器都使用自注意力,其中查询、键和值序列在进行线性变换之前是相同的。但是,解码器的自注意力是因果的,当$i < j$时,会阻止查询元素$i$与键元素$j$之间的注意力。这种设计反映了序列生成的自回归性质:token不应了解未来的token。
因果注意力是通过使用一个下三角矩阵(值为1)作为掩码来实现的。
|
1 2 3 4 5 |
import torch seq_len = 4 causal_mask = torch.tril(torch.ones(seq_len, seq_len)) print(causal_mask) |
如果打印掩码,它将如下所示:
|
1 2 3 4 |
tensor([[1., 0., 0., 0.], [1., 1., 0., 0.], [1., 1., 1., 0.], [1., 1., 1., 1.]]) |
注意力分数将乘以掩码来计算注意力输出。在大多数实现中,掩码实现为$-\infty$或$0$而不是$0$或$1$,并且在计算softmax分数之前将其添加到矩阵中。这种方法使用更快的加法而不是更慢的乘法。
Transformer模型中的解码器也使用交叉注意力。它从解码器中的前一层获取查询序列,而键和值序列来自编码器的输出。这就是解码器如何利用编码器的输出来生成最终输出。
完整的Transformer架构特别适合输入和输出序列长度可能不同且输出取决于整个输入上下文的任务。例如,机器翻译,其中输入是源语言的句子,输出是目标语言的句子;以及文本摘要,其中输入是一篇长文章,输出是总结文章的段落。
仅编码器模型
虽然强大,但编码器-解码器架构计算量大,并引入延迟,因为解码器必须等待编码器完成其处理。仅编码器模型通过移除解码器来简化这一点。BERT模型就是一个例子,如下所示。
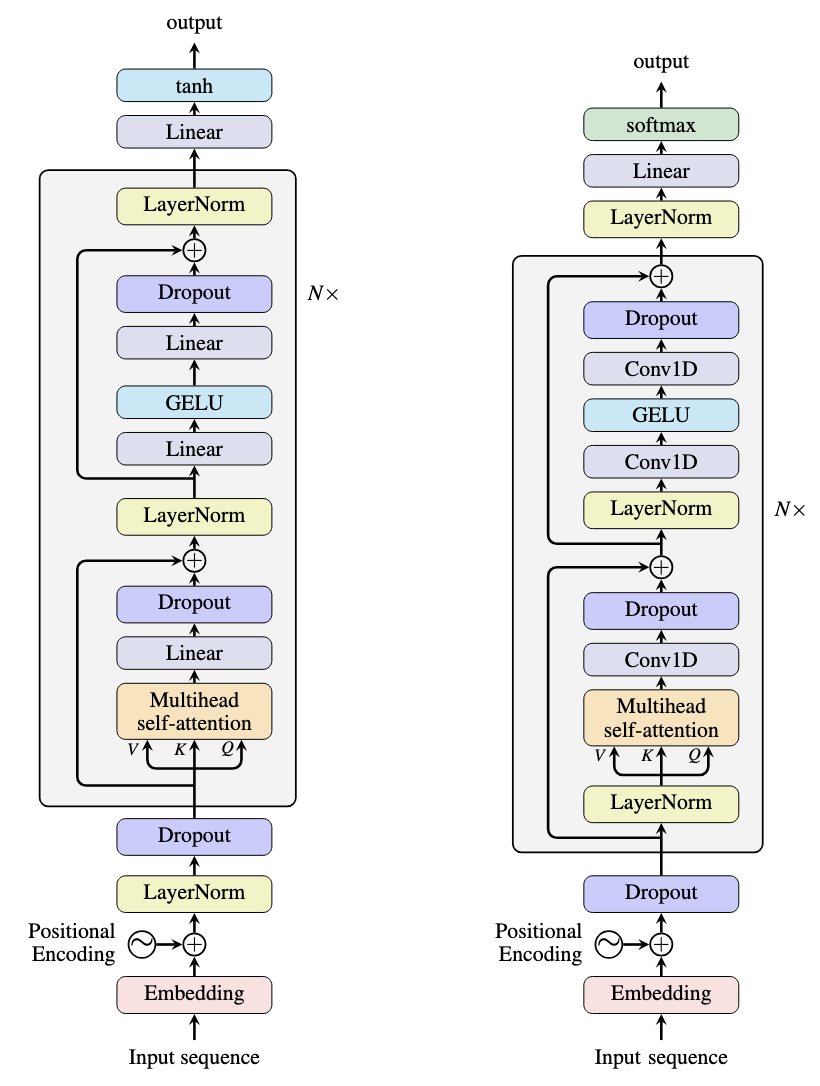
BERT架构(左)和GPT-2架构(右)
BERT(Bidirectional Encoder Representations from Transformers)是最流行的仅编码器模型之一。它一次处理整个输入序列,产生上下文表示。由于输入和输出都是序列,因此通常会添加特定于任务的模型头以用于下游应用程序。
例如,“NER头”可以标记token为命名实体,而“情感分析头”则处理整个序列以产生单一的情感分数。下面是如何创建BERT模型:
|
1 2 3 4 5 |
from transformers import BertModel, BertConfig config = BertConfig() model = BertModel(config=config) print(model) |
此代码未加载预训练权重,但您可以查看模型架构,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(30522, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0-11): 12 x BertLayer( (attention): BertAttention( (self): BertSdpaSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ) ) |
该模型有一个“embeddings”层,用于将输入token ID转换为维度为768的向量空间。该模型在最后还有一个“pooler”层,用于在将输出馈送到特定任务模型头之前进行转换。BERT模型的主体是BertEncoder模块,它是由12个架构相同的BertLayer模块堆叠而成。每个BertLayer中有多个线性层、LayerNorm和Dropout层。然而,只有一个BertAttention模块,其中实现了多头自注意力。
BERT等仅编码器模型使用Transformer架构的编码器部分。它们通常使用掩码语言模型进行训练,其中输入序列中的随机token被替换为特殊token,然后训练基础模型来猜测原始token是什么。这使得模型能够看到整个序列来理解上下文,以便执行预测。
仅解码器模型
得益于OpenAI的GPT(Generative Pre-trained Transformer)模型所展现出的能力,仅解码器模型如今越来越普遍。虽然像GPT-3.5和GPT-4这样的后期版本过于庞大,无法放入单个计算机中,并且不是开源的,但像GPT-2这样的早期版本是开源且足够小的,可以进行处理。您可以使用Hugging Face Transformers库来实例化一个,如下所示:
|
1 2 3 4 5 |
from transformers import GPT2LMHeadModel, GPT2Config config = GPT2Config() model = GPT2LMHeadModel(config=config) print(model) |
或者,如果您想加载预训练权重,可以这样做:
|
1 2 3 4 |
from transformers import GPT2LMHeadModel model = GPT2LMHeadModel.from_pretrained("gpt2") print(model) |
代码会将模型架构打印到屏幕上。输出如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
GPT2LMHeadModel( (transformer): GPT2Model( (wte): Embedding(50257, 768) (wpe): Embedding(1024, 768) (drop): Dropout(p=0.1, inplace=False) (h): ModuleList( (0-11): 12 x GPT2Block( (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (attn): GPT2Attention( (c_attn): Conv1D(nf=2304, nx=768) (c_proj): Conv1D(nf=768, nx=768) (attn_dropout): Dropout(p=0.1, inplace=False) (resid_dropout): Dropout(p=0.1, inplace=False) ) (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (mlp): GPT2MLP( (c_fc): Conv1D(nf=3072, nx=768) (c_proj): Conv1D(nf=768, nx=3072) (act): NewGELUActivation() (dropout): Dropout(p=0.1, inplace=False) ) ) ) (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) ) (lm_head): Linear(in_features=768, out_features=50257, bias=False) ) |
您可能会注意到模型注意力子层中使用了Conv1D层。这实际上只是一个线性投影层,因为nx与输入维度大小相同。
该架构在上图也有说明。比较两者,您会发现GPT-2和BERT非常相似,只是LayerNorm的位置不同。BERT模型使用后置归一化,而GPT-2使用前置归一化。如上所述,nn.Linear层和nn.Conv1D层的用法在功能上是等效的。
将GPT-2的架构与Transformer的解码器进行比较,您会注意到缺少交叉注意力子层。这是因为模型中没有编码器,因此没有编码器输出,也不需要交叉注意力。
为什么GPT-2是仅解码器模型,即使它与BERT模型如此相似?
答案在于模型的训练方式。GPT-2使用下一个token预测进行训练,这意味着模型被训练来预测序列中的下一个token。训练始终使用因果掩码,而BERT训练中使用的掩码是随机的。因此,BERT期望看到完整的序列上下文,并且所有任务都基于此假设。然而,GPT-2只期望看到部分句子,并且不对未来进行任何假设。
这种训练上的差异可能看起来很微妙,但这是两种模型及其能力之间的关键区别。这也区分了仅编码器模型和仅解码器模型,无论它们的架构如何。这解释了为什么BERT可以用于NER,因为您需要看到整个句子来理解语法结构并确定一个token是否是命名实体。类似地,GPT-2可用于文本生成,因为它擅长补全部分句子。
进一步阅读
以下是一些关于该主题的进一步阅读材料:
- Attention is All You Need (原始Transformer论文)
- BERT:用于语言理解的深度双向 Transformer 预训练
- Language Models are Unsupervised Multitask Learners (GPT-2论文)
- Language Models are Few-Shot Learners (GPT-3论文)
- Transformer库中的BERT
- Transformer库中的GPT-2
总结
在本文中,您探索了不同类型的Transformer模型及其应用。您了解到:
- 完整的Transformer模型结合了编码器和解码器以用于seq2seq任务
- 仅编码器模型使用双向注意力来进行理解任务
- 仅解码器模型使用因果注意力来进行生成任务
- 每种架构都针对特定的用例进行了优化
- 训练方法,特别是注意力模式,区分了仅编码器和仅解码器模型
理解这些差异对于为您的NLP任务选择合适的模型架构至关重要。






暂无评论。