为您的机器学习问题设定性能基线非常重要。
它将为您提供一个参考点,您可以将所有其他模型与之进行比较。
在本文中,您将了解如何使用Weka为机器学习问题开发性能基线。
阅读本文后,您将了解
- 确立机器学习问题性能基线的重要性。
- 如何使用零规则方法计算回归问题的基线性能。
- 如何使用零规则方法计算分类问题的基线性能。
启动您的项目,阅读我的新书《Weka机器学习精通》,其中包含分步教程和所有示例的清晰屏幕截图。
让我们开始吧。

如何在 Weka 中为机器学习模型估算基线性能
照片由 Peter Stevens 拍摄,保留部分权利。
基线结果的重要性
您事先无法知道哪种算法最适合您的问题,因此您必须尝试一系列算法,看看哪种效果最好,然后专注于它。
因此,在处理机器学习问题时,建立性能基线至关重要。
基线提供了与其他机器学习算法进行比较的参考点。
您可以了解相对于基线的绝对性能提升,以及显示您相对进步的提升率。
没有基线,您就不知道您在问题上做得有多好。您没有参考点来考虑您是否以及持续地增加价值。基线定义了所有其他机器学习算法必须跨越的障碍,才能在问题上展示“技能”。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
零规则基线性能
分类和回归问题的基线都称为零规则算法。也称为ZeroR或0-R。
让我们通过一些例子更仔细地了解零规则算法如何在分类和回归问题中使用。
回归问题的基线性能
对于预测数值的回归预测建模问题,零规则算法会预测训练数据集的均值。
例如,让我们在波士顿房价预测问题上演示零规则算法。您可以从Weka数据集网页下载波士顿房价预测数据集的ARFF文件。它位于datasets-numeric.jar包中的housing.arff文件中。
- 启动Weka GUI Chooser。
- 单击“Explorer”按钮打开Weka Explorer界面。
- 加载波士顿房价数据集housing.arff文件。
- 单击“Classify”选项卡以打开分类选项卡。
- 选择ZeroR算法(默认应选中它)。
- 选择“Cross-validation”测试选项(默认应选中它)。
- 单击“Start”按钮以在数据集上评估算法。
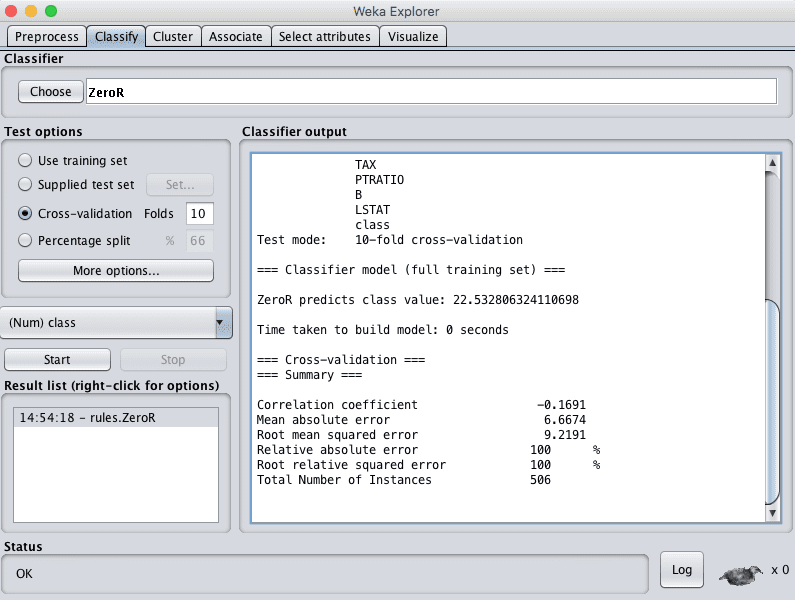
Weka回归问题的基线性能
ZeroR算法预测的波士顿平均房价为22.5(千美元),RMSE为9.21。
任何机器学习算法要想证明其在此问题上具有技能,都必须实现比此值更好的RMSE。
分类问题的基线性能
对于预测分类值的分类预测建模问题,零规则算法会预测训练数据集中观察次数最多的类值。
例如,让我们在Pima印第安人糖尿病发病率问题上演示零规则算法。该数据集应位于Weka安装的data/目录中。如果没有,您可以从Weka下载网页下载针对“其他平台”的默认Weka安装(.zip扩展名),解压缩并找到diabetes.arff文件。
- 启动Weka GUI Chooser。
- 单击“Explorer”按钮打开Weka Explorer界面。
- 加载Pima印第安人数据集diabetes.arff文件。
- 单击“Classify”选项卡以打开分类选项卡。
- 选择ZeroR算法(默认应选中它)。
- 选择“Cross-validation”测试选项(默认应选中它)。
- 单击“Start”按钮以在数据集上评估算法。
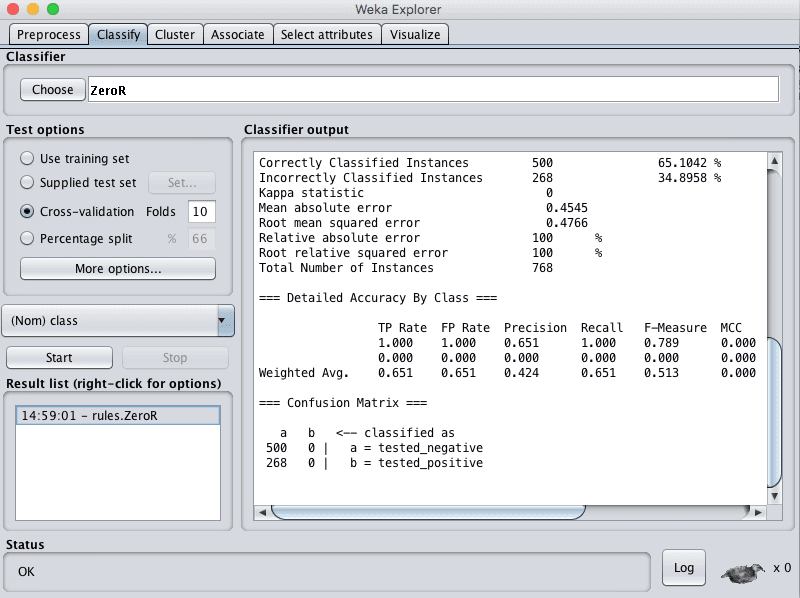
Weka分类问题的基线性能
ZeroR算法将所有实例都预测为tested_negative值,因为它是多数类,准确率为65.1%。
任何机器学习算法要想证明其在此问题上具有技能,都必须实现比此值更好的准确率。
总结
在本文中,您已经了解了如何使用Weka为您的机器学习问题计算基线性能。
具体来说,你学到了:
- 计算问题基线性能的重要性。
- 如何使用零规则算法计算回归问题的基线性能。
- 如何使用零规则算法计算分类问题的基线性能。
您对计算性能基线或本文有任何疑问吗?在评论区提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。





分类器是否必须始终是ZeroR?其他参考点,例如NaiveBayes呢?
基线应该选择哪个测试选项?是否必须始终是交叉验证?
很好的问题。我喜欢使用ZeroR,但您可以根据自己的喜好设定基线。
我建议使用与您评估问题上所有方法相同的测试框架/测试选项。
非常感谢Jason Brownlee博士
我的问题是,我可以在我的研究中使用ZeroR算法来预测破产吗?
它相比于其他算法有什么好处?
谢谢
ZeroR是一个基线方法,所有其他方法都可以与之进行比较。
我感到困惑。如果我在这里按照您的指导:https://machinelearning.org.cn/dont-use-random-guessing-as-your-baseline-classifier/
……那么我的基线性能或ZeroR将是54.6%,使用以下计算
P(类为否) * P(你猜否) + P(类为是) * P(你猜是) = =0.651*0.651+0.349*0.349 = 0.546。
我这里错过了什么?
-谢谢-
零规则不是随机猜测。
该方程用于随机猜测。
零规则将猜测分类的众数,回归的均值。
嗨Jason,有没有办法查看Weka根据我们在weka界面中的选择或操作生成的程序?
谢谢
如果您是Java程序员,可以使用API开发程序。
嗨Jason,另一个问题,我看到了运行数据集 against ZeroR算法的这些响应,但不确定它根据什么确切的数据得出这些预测
ZeroR预测类值:yes
ZeroR预测类值:FALSE
-对于什么数据类值是false?
ZeroR预测类值:sunny
-什么时候是晴天?
ZeroR预测类值:22.532806324110698
也许仔细检查您正在使用的数据文件?
嗨。感谢您提供的ZeroR精彩指南。
我在解释我的ZeroR结果时遇到了麻烦。
我对我的回归数据集运行了ZeroR,我得到-0的相关系数,这是什么意思?这是一个错误吗?我得到了85029231.6432的RMSE – 这也太高了,对吧?这是什么意思?
这表明变量之间没有相关性。
也许可以尝试其他算法?
我可以使用WEKA获得具有许多缺失值的基线结果吗?我已经在WEKA中尝试过,并获得了结果。我只想知道我在这里是否犯了错误,或者我是否需要处理缺失值以获得适当的基线性能?
谢谢
San
是的,使用均值或中位数(如果需要)进行插补,并使用ZeroR计算基线。
我尝试运行Weka分类器,所有分类器都产生与基线分类器相同的结果。在这种情况下,哪种分类器更好?
这可能是因为模型需要进一步调整其配置。
您可能需要尝试另一种模型。
这可能意味着您的问题是不可预测的。
当您运行ZeroR模型并正确分类68%时,然后您运行J48进行分类树,准确率只有67%,您接下来会怎么做?
嗨Brandi…您可能需要考虑深度学习模型来比较性能
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/