在进行数据科学项目时,数据通常是表格结构的。您可以使用 R 中内置的数据表来处理此类数据。您也可以使用著名的 dplyr 库来利用其丰富的工具集。在这篇文章中,您将学习 dplyr 如何帮助您探索和操作表格数据。具体来说,您将学习:
- 如何处理数据框
- 如何对数据框执行一些常见操作
让我们开始吧。

使用 R 中的 dplyr 探索数据。
图片来源:Airam Dato-on。保留部分权利。
概述
这篇文章分为两部分:
- dplyr 入门
- 探索数据集
dplyr 入门
R 中的 dplyr 库可以使用 R 命令行中的 `install.package("dplyr")` 命令安装。但通常安装 `tidyverse` 包会很有帮助,因为它是一些有用的数据科学包的集合。
|
1 |
install.package("tidyverse") |
在开始之前,您应该加载 dplyr 包,它将覆盖一些现有的 R 函数并添加新功能。
|
1 |
library(dplyr) |
dplyr 库是一个强大的数据操作库。该库对称为数据框的表格结构数据进行操作。要从头开始创建数据框,您可以使用以下语法:
|
1 2 3 4 5 |
df <- data.frame( name = c("Alice", "Bob", "Charlie"), age = c(25, 30, 35), occupation = c("Software Engineer", "Data Scientist", "Product Manager") ) |
它提供了用于操作数据框的函数,称为“动词”。操作单个数据框的行的动词包括:
filter()根据列值选择行slice()根据偏移量选择行arrange()根据列值对行进行排序
操作数据框列的动词包括:
select()选择列的子集。rename()更改列的名称。mutate()更改列的值并创建新列。relocate()重新排列列。
此外,您还可以像 SQL 中一样运行分组操作:
group_by()将表转换为分组表ungroup()将分组表展开为表summarize()将组折叠成单行。
探索数据集
让我们查看一个数据集,看看 dplyr 如何帮助我们理解数据。
您将要探索的数据集是波士顿房价数据集。您可以从互联网加载此数据集:
|
1 2 3 |
boston_url <- 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' Boston <- read.table(boston_url, col.name=c("crim","zn","indus","chas","nox","rm","age","dis","rad","tax","ptratio","black","lstat","medv")) as_tibble(Boston) |
在 R 中,此数据集也可以从 MASS 库中以 `Boston` 的形式获得。
|
1 2 |
library(MASS) as_tibble(Boston) |
在这两种情况下,`as_tibble()` 函数用于将数据框封装成“tibble”,这使得大型表格能够很好地显示。两者的输出都将如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 一个 tibble:506 × 14 crim zn indus chas nox rm age dis rad tax ptratio black lstat medv <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> 1 0.00632 18 2.31 0 0.538 6.58 65.2 4.09 1 296 15.3 397. 4.98 24 2 0.0273 0 7.07 0 0.469 6.42 78.9 4.97 2 242 17.8 397. 9.14 21.6 3 0.0273 0 7.07 0 0.469 7.18 61.1 4.97 2 242 17.8 393. 4.03 34.7 4 0.0324 0 2.18 0 0.458 7.00 45.8 6.06 3 222 18.7 395. 2.94 33.4 5 0.0690 0 2.18 0 0.458 7.15 54.2 6.06 3 222 18.7 397. 5.33 36.2 6 0.0298 0 2.18 0 0.458 6.43 58.7 6.06 3 222 18.7 394. 5.21 28.7 7 0.0883 12.5 7.87 0 0.524 6.01 66.6 5.56 5 311 15.2 396. 12.4 22.9 8 0.145 12.5 7.87 0 0.524 6.17 96.1 5.95 5 311 15.2 397. 19.2 27.1 9 0.211 12.5 7.87 0 0.524 5.63 100 6.08 5 311 15.2 387. 29.9 16.5 10 0.170 12.5 7.87 0 0.524 6.00 85.9 6.59 5 311 15.2 387. 17.1 18.9 # ℹ 还有 496 行 # ℹ 使用 `print(n = ...)` 查看更多行 |
从中,您可以获得有关此数据集的一些基本信息:有 506 行和 14 列。显示了每列的名称及其数据类型(在本例中它们是双精度或整数)。您还可以看到数据的前 10 行。
然而,您可能会觉得这个输出仍然相当混乱。如果您只对列的子集感兴趣,可以使用 `select()` 函数,它以 SQL 中相同的操作命名:
|
1 |
select(Boston, c(crim, medv)) |> as_tibble() |
上面的是获取数据框 `Boston` 并仅选择 `crim` 和 `medv` 列,然后将其显示为 tibble(这样我们就可以确定结果将具有与以前相同的行数)。运算符 `|>` 是 R 中一个特殊的运算符,表示左侧的输出由右侧的函数处理。这等效于以下内容:
|
1 |
as_tibble(select(Boston, c(crim, medv))) |
但您发现它有用可能是因为它有助于您检验假设。这是一个房地产市场数据集。`crim` 列是犯罪率,`medv` 是房屋中值。您可能想知道犯罪率是否可以预测房屋价值。但直观地看,它们应该呈负相关。因此,让我们绘制房屋价值与犯罪率倒数的关系图:
|
1 |
Boston |> mutate( invcrim = 1/crim ) |> select(c(invcrim, medv)) |> plot() |
这里您使用了多个 `|>` 运算符来连接多个操作。`mutate()` 函数可以帮助您定义一个新列(或修改现有列)。`plot()` 函数需要一个包含两列的数据框,它将生成一个散点图。此代码行将生成如下所示的图:
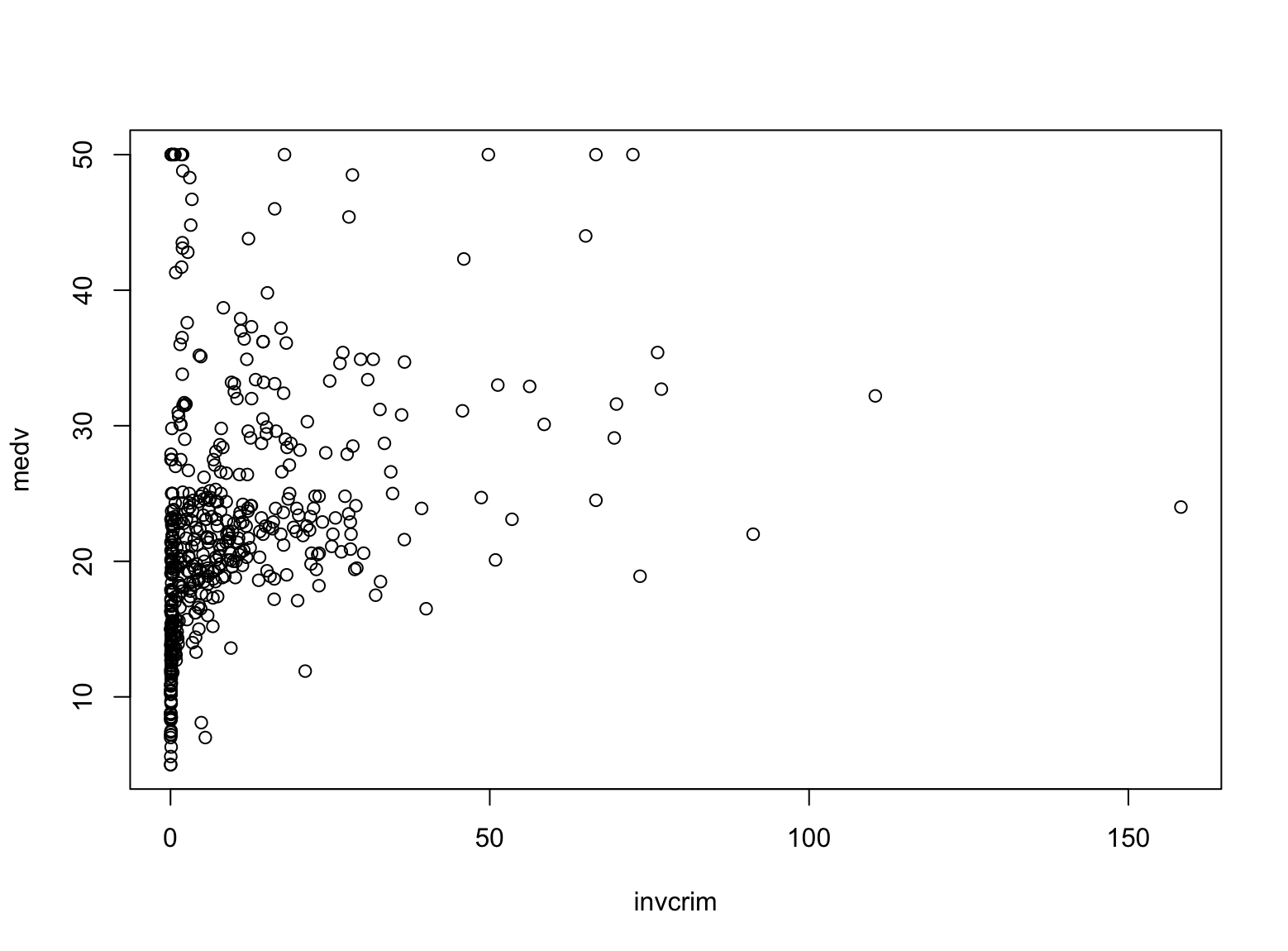
这似乎没有趋势。因此,您可能还想看看数据的某个部分是否能显示出趋势。例如,如果您只取 `age` 列大于 50 的子集。这正是 `filter()` 函数可以帮助的地方:
|
1 |
Boston |> filter(age > 50) |> select(c(crim, medv)) |> plot() |
这些是 dplyr 提供的方便工具。在这个特定的数据集中,趋势并非如此随意就能发现。您应该寻找更高级的技术,但这些都是很好的起点。
除了可视化探索数据,您还可以对数据进行数值探索。处理数据框最简单的方法是使用 `summary()` 函数。
|
1 |
summary(Boston) |
这适用于所有数值列。您应该会看到每列的基本统计数据,包括最大值、最小值、中位数、平均值等等。然而,有时您想查看不同列之间的相关性。例如,此数据集中的 `chas` 列表示位置是否靠近查尔斯河。它的值为 0 或 1。您可以使用 `group_by()` 来判断房屋价值与此类指标变量的关系:
|
1 |
group_by(boston, chas) |> summarize(avg=mean(medv), sd=sd(medv)) |
`group_by()` 函数将数据框提升为组,其中每个组是 `chas` 列中具有相同值的行子集。然后 `summarize()` 函数创建一个新列,其值由每个组计算得出。
上述输出如下:
|
1 2 3 4 5 |
# 一个 tibble:2 × 3 chas avg sd <int> <dbl> <dbl> 1 0 22.1 8.83 2 1 28.4 11.8 |
事实上,`summarize()` 函数可以在没有 `group_by()` 的情况下使用,但这将应用于整个数据框;因此输出将只有一行。
进一步阅读
本节为您提供了进一步学习上述材料的一些链接:
在线资料
- 使用 dplyr 进行数据转换备忘单
- tidyverse 的dplyr 简介
- 波士顿房价数据集
书籍
- Thomas Mailund 的《R 4 初级数据科学》第二版
总结
dplyr 库是一个强大的数据操作包。在这篇文章中,您了解了如何使用它来筛选、选择和汇总数据,以及这些工具如何帮助您探索数据集。具体来说,您学习了:
- 使用 tibble 作为呈现缩写数据框的不同方式
图片来源:Airam Dato-on。保留部分权利。
已缩写的数据框
- 如何按行和列操作表格数据
- 如何对数据框执行分组操作并计算聚合值






暂无评论。