LightGBM 是一个高效的梯度提升框架。它因其速度和性能而受到关注,尤其是在处理大型复杂数据集时。由微软开发的这个强大算法,在处理大量数据方面,比传统方法具有显著的易用性。
在这篇文章中,我们将使用 Ames Housing 数据集来试验 LightGBM 框架。特别是,我们将重点介绍其多功能提升策略——梯度提升决策树 (GBDT) 和基于梯度的单边采样 (GOSS)。这些策略提供了独特的优势。通过这篇文章,我们将比较它们的性能和特点。
我们首先设置 LightGBM,然后继续在理论和实践环境中研究它的应用。
通过我的书《进阶数据科学》启动您的项目。它提供了带有可运行代码的自学教程。
让我们开始吧。

LightGBM
照片来自 Marcus Dall Col。部分权利保留。
概述
本文分为四个部分;它们是:
- LightGBM 简介与初始设置
- 在 Ames 数据集上测试 LightGBM 的 GBDT 和 GOSS
- 精细调整 LightGBM 的树生长:聚焦叶子生长策略
- 比较 LightGBM 的 GBDT 和 GOSS 模型中的特征重要性
LightGBM 简介与初始设置
LightGBM (Light Gradient Boosting Machine) 由微软开发。它是一个机器学习框架,提供了构建、训练和部署机器学习模型所需的组件和实用工具。这些模型基于决策树算法,并以梯度提升为核心。该框架是开源的,您可以使用以下命令在您的系统上安装它
|
1 |
pip install lightgbm |
此命令将下载并安装 LightGBM 包及其必要的依赖项。
虽然 LightGBM、XGBoost 和 Gradient Boosting Regressor (GBR) 都基于梯度提升的原理,但由于其默认行为和一系列增强其功能的可选参数,LightGBM 的多个关键区别使其脱颖而出
- Exclusive Feature Bundling (EFB)(专属特征捆绑):作为一项默认功能,LightGBM 采用 EFB 来减少特征数量,这对于高维稀疏数据特别有用。此过程是自动的,有助于在没有大量手动干预的情况下有效管理数据维度。
- Gradient-Based One-Side Sampling (GOSS)(基于梯度的单边采样):这是一个可启用的可选参数,GOSS 保留具有大梯度的实例。梯度表示如果模型对该实例的预测发生轻微变化,损失函数将如何变化。大梯度意味着当前模型对该数据点的预测值远未达到实际目标值。具有大梯度的实例被认为对训练更重要,因为它们代表了模型需要显著改进的区域。在 GOSS 算法中,具有大梯度的实例通常被称为“欠训练”,因为它们表示模型性能较差且在训练过程中需要更多关注的区域。GOSS 算法在采样过程中特别保留所有具有大梯度的实例,确保这些关键数据点始终包含在训练子集中。另一方面,具有小梯度的实例被认为“训练良好”,因为模型对这些点的预测值更接近实际值,从而产生较小的误差。
- Leaf-wise Tree Growth(叶子生长):而 GBR 和 XGBoost 通常按层生长树,LightGBM 的默认树生长策略是按叶子生长。与按层生长(在移动到下一层之前,给定深度的所有节点都被分裂)不同,LightGBM 通过选择分裂后导致损失函数减小最大的叶子来生长树。这种方法可能导致非对称、不规则且更深的树,这些树比按层生长的平衡树更具表现力且更有效。
这些是 LightGBM 与传统 GBR 和 XGBoost 区分开的几个特征。有了这些独特的优势,我们就可以深入到探索的实证部分了。
想开始学习进阶数据科学吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
在 Ames 数据集上测试 LightGBM 的 GBDT 和 GOSS
在理解 LightGBM 的独特功能的基础上,本节将从理论转向实践。我们将利用 Ames Housing 数据集来严格测试 LightGBM 框架中的两个特定提升策略:传统的梯度提升决策树 (GBDT) 和创新的基于梯度的单边采样 (GOSS)。我们的目标是探索这些技术并对它们的有效性进行比较分析。
在我们深入模型构建之前,正确准备数据集至关重要。这包括加载数据并确保所有分类特征都得到正确处理,充分利用 LightGBM 处理分类变量的能力。与 XGBoost 一样,LightGBM 可以原生处理缺失值和分类数据,从而简化预处理步骤并带来更稳健的模型。这种能力至关重要,因为它直接影响模型训练过程的准确性和效率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 导入运行 LightGBM 的库 import pandas as pd import lightgbm as lgb from sklearn.model_selection import cross_val_score # 加载 Ames Housing 数据集 data = pd.read_csv('Ames.csv') X = data.drop('SalePrice', axis=1) y = data['SalePrice'] # 将分类列转换为 'category' 数据类型 categorical_cols = X.select_dtypes(include=['object']).columns X[categorical_cols] = X[categorical_cols] = X[categorical_cols].apply(lambda x: x.astype('category')) # 定义默认 GBDT 模型 gbdt_model = lgb.LGBMRegressor() gbdt_scores = cross_val_score(gbdt_model, X, y, cv=5) print(f"默认 Light GBM (含 GBDT) 的平均 R² 分数: {gbdt_scores.mean():.4f}") # 定义 GOSS 模型 goss_model = lgb.LGBMRegressor(boosting_type='goss') goss_scores = cross_val_score(goss_model, X, y, cv=5) print(f"Light GBM (含 GOSS) 的平均 R² 分数: {goss_scores.mean():.4f}") |
结果
|
1 2 |
默认 Light GBM (含 GBDT) 的平均 R² 分数: 0.9145 LightGBM (含 GOSS) 的平均 R² 分数: 0.9109 |
我们 5 折交叉验证实验的初步结果为两种模型的性能提供了有趣的见解。默认的 GBDT 模型达到了 0.9145 的平均 R² 分数,展示了强大的预测准确性。另一方面,GOSS 模型专门针对具有大梯度的实例,其平均 R² 分数略低,为 0.9109。
性能上的微小差异可能归因于 GOSS 优先处理某些数据点的方式,这在预测错误更集中的数据集中可能特别有利。然而,在像 Ames 这样相对同质的数据集中,GOSS 的优势可能无法完全发挥。
精细调整 LightGBM 的树生长:聚焦叶子生长策略
LightGBM 的一个显著特点是其能够创建叶子生长而非层级生长的决策树。这种叶子生长方法允许树通过优化损失减少来生长,可能导致更好的模型性能,但如果不经过适当调整,则存在过拟合的风险。在本节中,我们将探讨改变树叶数量的影响。
我们首先定义一系列实验,系统地测试 num_leaves 的不同设置如何影响两种 LightGBM 变体(传统梯度提升决策树 (GBDT) 和基于梯度的单边采样 (GOSS))的性能。这些实验对于确定我们特定数据集(Ames Housing 数据集)的模型的最优复杂度级别至关重要。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 试验叶子生长策略 import pandas as pd import lightgbm as lgb from sklearn.model_selection import cross_val_score # 加载 Ames Housing 数据集 data = pd.read_csv('Ames.csv') X = data.drop('SalePrice', axis=1) y = data['SalePrice'] # 将分类列转换为 'category' 数据类型 categorical_cols = X.select_dtypes(include=['object']).columns X[categorical_cols] = X[categorical_cols] = X[categorical_cols].apply(lambda x: x.astype('category')) # 定义要测试的叶子大小范围 leaf_sizes = [5, 10, 15, 31, 50, 100] # 结果存储 results = {} # 试验 GBDT 的不同叶子大小 results['GBDT'] = {} print("正在测试 GBDT 的不同 'num_leaves':") for leaf_size in leaf_sizes: model = lgb.LGBMRegressor(boosting_type='gbdt', num_leaves=leaf_size) scores = cross_val_score(model, X, y, cv=5, scoring='r2') results['GBDT'][leaf_size] = scores.mean() print(f"num_leaves = {leaf_size}: 平均 R² 分数 = {scores.mean():.4f}") # 试验 GOSS 的不同叶子大小 results['GOSS'] = {} print("\n正在测试 GOSS 的不同 'num_leaves':") for leaf_size in leaf_sizes: model = lgb.LGBMRegressor(boosting_type='goss', num_leaves=leaf_size) scores = cross_val_score(model, X, y, cv=5, scoring='r2') results['GOSS'][leaf_size] = scores.mean() print(f"num_leaves = {leaf_size}: 平均 R² 分数 = {scores.mean():.4f}") |
结果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
正在测试 GBDT 的不同 'num_leaves' num_leaves = 5: 平均 R² 分数 = 0.9150 num_leaves = 10: 平均 R² 分数 = 0.9193 num_leaves = 15: 平均 R² 分数 = 0.9158 num_leaves = 31: 平均 R² 分数 = 0.9145 num_leaves = 50: 平均 R² 分数 = 0.9111 num_leaves = 100: 平均 R² 分数 = 0.9101 正在测试 GOSS 的不同 'num_leaves' num_leaves = 5: 平均 R² 分数 = 0.9151 num_leaves = 10: 平均 R² 分数 = 0.9168 num_leaves = 15: 平均 R² 分数 = 0.9130 num_leaves = 31: 平均 R² 分数 = 0.9109 num_leaves = 50: 平均 R² 分数 = 0.9117 num_leaves = 100: 平均 R² 分数 = 0.9124 |
我们交叉验证实验的结果为 num_leaves 参数如何影响 GBDT 和 GOSS 模型的性能提供了富有启发性的数据。两种模型在 num_leaves 设置为 10 时表现最佳,均达到最高的 R² 分数。这表明适度的复杂性足以捕捉 Ames Housing 数据集中的潜在模式,而不会过拟合。考虑到 LightGBM 中 num_leaves 的默认设置为 31,这一发现尤其有趣。
对于 GBDT,增加叶子数量超过 10 会导致性能下降,这表明过多的复杂性会损害模型的泛化能力。相比之下,GOSS 对较高的叶子数量表现出稍强的容忍度,尽管改进趋于平缓,表明增加复杂性没有进一步的提升。
这项实验强调了调整 LightGBM 中 num_leaves 参数的重要性。通过仔细选择此参数,我们可以有效地平衡模型准确性和复杂性,确保在不同数据场景下都能获得稳健的性能。进一步尝试将 num_leaves 与其他参数结合进行实验,可能可以解锁更好的性能和稳定性。
比较 LightGBM 的 GBDT 和 GOSS 模型中的特征重要性
在对 num_leaves 参数进行精细调整并评估 GBDT 和 GOSS 模型的基本性能后,我们现在将重点转移到理解这些模型中各个特征的影响。在本节中,我们将通过可视化来探索每种提升策略最重要的特征。
以下是实现此目的的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
# 导入用于比较 GBDT 和 GOSS 之间特征重要性的库 import pandas as pd import numpy as np import lightgbm as lgb from sklearn.model_selection import KFold import matplotlib.pyplot as plt import seaborn as sns # 准备数据 data = pd.read_csv('Ames.csv') X = data.drop('SalePrice', axis=1) y = data['SalePrice'] categorical_cols = X.select_dtypes(include=['object']).columns X[categorical_cols] = X[categorical_cols] = X[categorical_cols].apply(lambda x: x.astype('category')) # 设置 K 折交叉验证 kf = KFold(n_splits=5) gbdt_feature_importances = [] goss_feature_importances = [] # 遍历每个折叠 for train_index, test_index in kf.split(X): X_train, X_test = X.iloc[train_index], X.iloc[test_index] y_train, y_test = y.iloc[train_index], y.iloc[test_index] # 使用最优 num_leaves 训练 GBDT 模型 gbdt_model = lgb.LGBMRegressor(boosting_type='gbdt', num_leaves=10) gbdt_model.fit(X_train, y_train) gbdt_feature_importances.append(gbdt_model.feature_importances_) # 使用最优 num_leaves 训练 GOSS 模型 goss_model = lgb.LGBMRegressor(boosting_type='goss', num_leaves=10) goss_model.fit(X_train, y_train) goss_feature_importances.append(goss_model.feature_importances_) # 平均所有折叠的特征重要性 avg_gbdt_feature_importance = np.mean(gbdt_feature_importances, axis=0) avg_goss_feature_importance = np.mean(goss_feature_importances, axis=0) # 转换为 DataFrame feat_importances_gbdt = pd.DataFrame({'Feature': X.columns, 'Importance': avg_gbdt_feature_importance}) feat_importances_goss = pd.DataFrame({'Feature': X.columns, 'Importance': avg_goss_feature_importance}) # 对前 10 个特征进行排序 top_gbdt_features = feat_importances_gbdt.sort_values(by='Importance', ascending=False).head(10) top_goss_features = feat_importances_goss.sort_values(by='Importance', ascending=False).head(10) # 绘图 plt.figure(figsize=(16, 12)) plt.subplot(1, 2, 1) sns.barplot(data=top_gbdt_features, y='Feature', x='Importance', orient='h', palette='viridis') plt.title('LightGBM GBDT 前 10 个特征', fontsize=18) plt.xlabel('重要性', fontsize=16) plt.ylabel('特征', fontsize=16) plt.xticks(fontsize=13) plt.yticks(fontsize=14) plt.subplot(1, 2, 2) sns.barplot(data=top_goss_features, y='Feature', x='Importance', orient='h', palette='viridis') plt.title('LightGBM GOSS 前 10 个特征', fontsize=18) plt.xlabel('重要性', fontsize=16) plt.ylabel('特征', fontsize=16) plt.xticks(fontsize=13) plt.yticks(fontsize=14) plt.tight_layout() plt.show() |
使用相同的 Ames Housing 数据集,我们应用了 k 折交叉验证方法,以保持与我们先前实验的一致性。然而,这次,我们专注于从模型中提取和分析特征重要性。特征重要性,它指示了每个特征在构建提升决策树中的有用性,对于解释机器学习模型的行为至关重要。它有助于理解哪些特征对模型的预测能力贡献最大,从而深入了解潜在数据和模型的决策过程。
以下是我们执行特征重要性提取的方式
- 模型训练:每个模型(GBDT 和 GOSS)都在数据的不同折叠上进行训练,并将最优
num_leaves参数设置为 10。 - 重要性提取:训练后,提取每个模型的特征重要性。这种重要性反映了特征在树中进行关键决策分裂的次数。
- 跨折平均:对所有折叠的重要性进行平均,以确保我们的结果稳定且能代表模型在不同数据子集上的性能。
以下可视化简洁地呈现了 GBDT 和 GOSS 模型之间在特征重要性上的这些差异
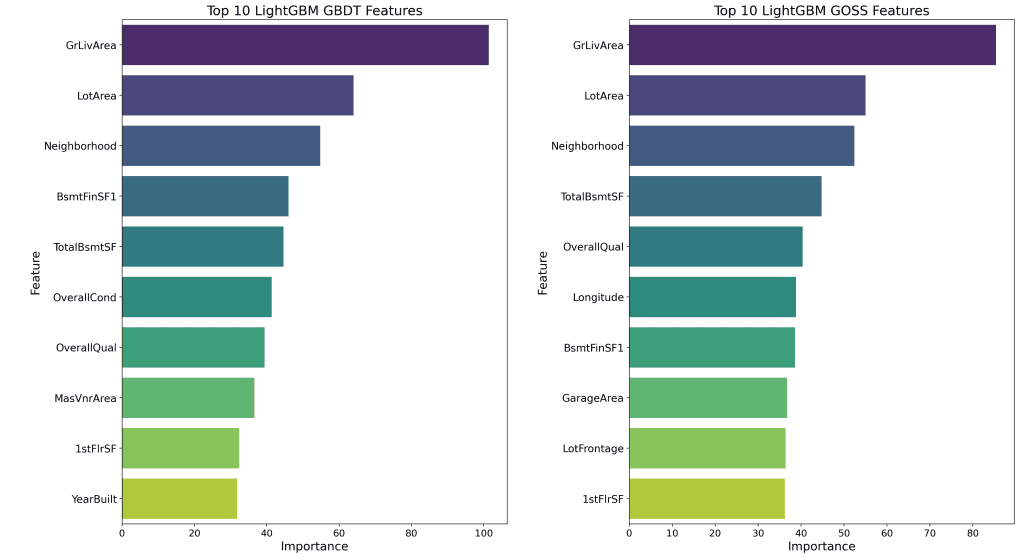
分析揭示了每个模型在特征优先排序方面有趣的模式。GBDT 和 GOSS 模型都强烈偏向“GrLivArea”和“LotArea”,突显了物业大小在确定房价中的基本作用。此外,两个模型都高度评价了“Neighborhood”,强调了地点在住房市场中的重要性。
然而,从第四个特征开始,模型在优先排序上开始出现分歧。GBDT 模型偏爱“BsmtFinSF1”,这表明了完成的地下室的价值。另一方面,GOSS 模型优先考虑具有较大梯度的实例以纠正预测错误,它更强调“OverallQual”。
随着我们结束本次分析,很明显,GBDT 和 GOSS 模型之间在特征重要性上的差异为我们提供了关于每个模型如何看待不同特征在预测房价方面的相关性的宝贵见解。
进一步阅读
教程
Ames 住房数据集和数据字典
总结
这篇博客文章向您介绍了 LightGBM 的功能,重点介绍了其独特的特性和在 Ames Housing 数据集上的实际应用。从初始设置和 GBDT 与 GOSS 提升策略的比较,到对特征重要性的深入分析,我们揭示了宝贵的见解,这些见解不仅展示了 LightGBM 的效率,还展示了它对复杂数据集的适应性。
具体来说,你学到了:
- 模型变体探索:比较默认 GBDT 和 GOSS 模型,让我们了解了根据数据特征如何利用不同的提升策略。
- 如何试验叶子生长策略:调整
num_leaves参数会影响模型性能,最优设置可在复杂性和准确性之间取得平衡。 - 如何可视化特征重要性:理解和可视化模型中最具影响力的特征,可以显著影响您如何解释结果和做出决策。这个过程不仅阐明了模型的内部工作原理,还通过识别哪些变量对结果影响最大,有助于提高模型的透明度和可信度。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。


 Ensemble")




暂无评论。