使用梯度提升等决策树集成方法的一个优点是,它们可以自动从训练好的预测模型中提供特征重要性估计。
在这篇文章中,您将了解如何使用 Python 中的 XGBoost 库估算预测建模问题的特征重要性。
阅读本文后,您将了解
- 如何使用梯度提升算法计算特征重要性。
- 如何在 Python 中绘制 XGBoost 模型计算的特征重要性。
- 如何使用 XGBoost 计算的特征重要性进行特征选择。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2017 年 1 月更新:已更新以反映 scikit-learn API 0.18.1 版本中的更改。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。
- 更新日期 2020 年 4 月:更新了 XGBoost 1.0.2 的示例。

在 Python 中使用 XGBoost 进行特征重要性和特征选择
图片来源:Keith Roper,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
梯度提升中的特征重要性
使用梯度提升的一个好处是,在构建完提升树后,检索每个属性的重要性分数相对简单。
通常,重要性提供一个分数,该分数表示每个特征在模型中构建提升决策树时的有用或有价值程度。属性在决策树中用于做出关键决策的次数越多,其相对重要性就越高。
这种重要性是针对数据集中每个属性明确计算的,从而可以对属性进行排名并相互比较。
对于单个决策树,重要性是根据每个属性分割点改进性能度量的量(通过节点负责的观测数量加权)计算的。性能度量可以是用于选择分割点的纯度(基尼指数)或其他更具体的误差函数。
然后将模型中所有决策树的特征重要性进行平均。
有关提升决策树中特征重要性如何计算的更多技术信息,请参阅《统计学习要素:数据挖掘、推断和预测》一书的第 10.13.1 节“预测变量的相对重要性”,第 367 页。
另请参阅 Matthew Drury 对 StackOverflow 问题“提升的相对变量重要性”的回答,他提供了非常详细和实用的答案。
手动绘制特征重要性
训练好的 XGBoost 模型会自动计算您的预测建模问题的特征重要性。
这些重要性分数可在训练模型的 feature_importances_ 成员变量中获取。例如,它们可以直接打印如下:
|
1 |
打印(模型.feature_importances_) |
我们可以直接在条形图中绘制这些分数,以直观地显示数据集中每个特征的相对重要性。例如:
|
1 2 3 |
# 绘图 pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_) pyplot.show() |
我们可以通过在 Pima Indians 糖尿病发病数据集上训练 XGBoost 模型并根据计算出的特征重要性创建条形图来演示这一点。
下载数据集并将其放置在您的当前工作目录中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 手动绘制特征重要性 从 numpy 导入 loadtxt from xgboost import XGBClassifier from matplotlib import pyplot # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] y = dataset[:,8] # 拟合模型,无训练数据 model = XGBClassifier() model.fit(X, y) # 特征重要性 打印(模型.feature_importances_) # 绘图 pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_) pyplot.show() |
注意:您的结果可能会有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑运行几次示例并比较平均结果。
运行此示例首先输出重要性分数。
|
1 |
[ 0.089701 0.17109634 0.08139535 0.04651163 0.10465116 0.2026578 0.1627907 0.14119601] |
我们还会得到一个相对重要性的条形图。
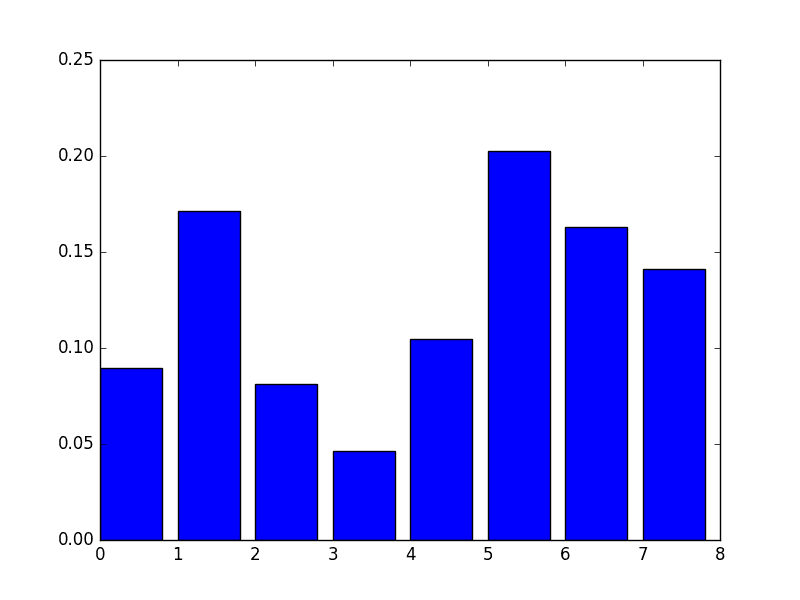
XGBoost 特征重要性的手动条形图
此图的一个缺点是特征按其输入索引而不是重要性排序。我们可以在绘制之前对特征进行排序。
幸运的是,有一个内置的绘图函数可以帮助我们。
使用内置的 XGBoost 特征重要性绘图
XGBoost 库提供了一个内置函数来按重要性排序绘制特征。
该函数名为 plot_importance(),可以如下使用:
|
1 2 3 |
# 绘制特征重要性 plot_importance(model) pyplot.show() |
例如,下面是使用内置 plot_importance() 函数绘制 Pima Indians 数据集特征重要性的完整代码列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 使用内置函数绘制特征重要性 从 numpy 导入 loadtxt from xgboost import XGBClassifier from xgboost import plot_importance from matplotlib import pyplot # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] y = dataset[:,8] # 拟合模型,无训练数据 model = XGBClassifier() model.fit(X, y) # 绘制特征重要性 plot_importance(model) pyplot.show() |
注意:您的结果可能会有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑运行几次示例并比较平均结果。
运行示例会给我们一个更有用的条形图。
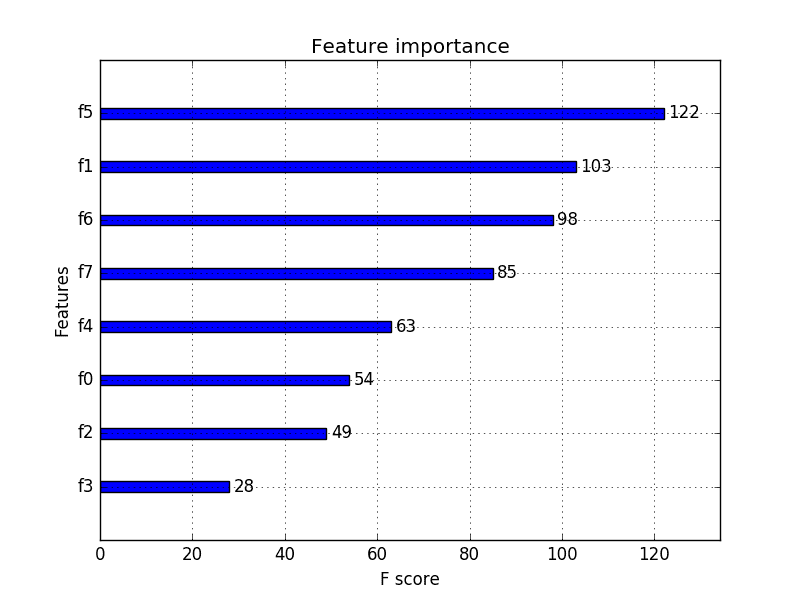
XGBoost 特征重要性条形图
您可以看到特征根据它们在输入数组 (X) 中的索引从 F0 到 F7 自动命名。
手动将这些索引映射到问题描述中的名称,我们可以看到图表显示 F5(身体质量指数)具有最高的重要性,而 F3(皮褶厚度)具有最低的重要性。
使用 XGBoost 特征重要性分数进行特征选择
特征重要性分数可用于 scikit-learn 中的特征选择。
这是通过 SelectFromModel 类完成的,该类接受一个模型并将数据集转换为具有选定特征的子集。
此类别可以接受预训练模型,例如在整个训练数据集上训练的模型。然后它可以使用阈值来决定选择哪些特征。当您在 SelectFromModel 实例上调用 transform() 方法时,将使用此阈值在训练数据集和测试数据集上一致地选择相同的特征。
在下面的示例中,我们首先分别在整个训练数据集和测试数据集上训练并评估一个 XGBoost 模型。
然后,我们使用从训练数据集计算的特征重要性,将模型封装在 SelectFromModel 实例中。我们使用它在训练数据集上选择特征,从选定的特征子集训练一个模型,然后在测试集上评估该模型,遵循相同的特征选择方案。
例如:
|
1 2 3 4 5 6 7 8 9 |
# 使用阈值选择特征 selection = SelectFromModel(model, threshold=thresh, prefit=True) select_X_train = selection.transform(X_train) # 训练模型 selection_model = XGBClassifier() selection_model.fit(select_X_train, y_train) # 评估模型 select_X_test = selection.transform(X_test) y_pred = selection_model.predict(select_X_test) |
为了兴趣,我们可以测试多个阈值来选择特征的重要性。具体来说,每个输入变量的特征重要性,这实质上允许我们通过重要性测试每个特征子集,从所有特征开始,到包含最重要特征的子集结束。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 使用特征重要性进行特征选择 从 numpy 导入 loadtxt from numpy import sort from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.feature_selection import SelectFromModel # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] Y = dataset[:,8] # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7) # 在所有训练数据上拟合模型 model = XGBClassifier() model.fit(X_train, y_train) # 对测试数据进行预测并评估 y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0)) # 使用每个重要性作为阈值拟合模型 thresholds = sort(model.feature_importances_) for thresh in thresholds: # 使用阈值选择特征 selection = SelectFromModel(model, threshold=thresh, prefit=True) select_X_train = selection.transform(X_train) # 训练模型 selection_model = XGBClassifier() selection_model.fit(select_X_train, y_train) # 评估模型 select_X_test = selection.transform(X_test) y_pred = selection_model.predict(select_X_test) predictions = [round(value) for value in y_pred] accuracy = accuracy_score(y_test, predictions) print("Thresh=%.3f, n=%d, Accuracy: %.2f%%" % (thresh, select_X_train.shape[1], accuracy*100.0)) |
注意:如果您使用 XGBoost 1.0.2(可能还有其他版本),XGBClassifier 类中存在一个 bug,导致错误:
|
1 |
KeyError: 'weight' |
这可以通过使用自定义的 *XGBClassifier* 类来修复,该类返回 *coef_* 属性的 *None*。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 使用特征重要性进行特征选择,修复 xgboost 1.0.2 的 bug 从 numpy 导入 loadtxt from numpy import sort from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.feature_selection import SelectFromModel # 定义自定义类以修复 xgboost 1.0.2 中的 bug class MyXGBClassifier(XGBClassifier): @property def coef_(self): return None # 加载数据 dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",") # 将数据拆分为 X 和 y X = dataset[:,0:8] Y = dataset[:,8] # 将数据拆分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=7) # 在所有训练数据上拟合模型 model = MyXGBClassifier() model.fit(X_train, y_train) # 对测试数据进行预测并评估 predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" % (accuracy * 100.0)) # 使用每个重要性作为阈值拟合模型 thresholds = sort(model.feature_importances_) for thresh in thresholds: # 使用阈值选择特征 selection = SelectFromModel(model, threshold=thresh, prefit=True) select_X_train = selection.transform(X_train) # 训练模型 selection_model = XGBClassifier() selection_model.fit(select_X_train, y_train) # 评估模型 select_X_test = selection.transform(X_test) predictions = selection_model.predict(select_X_test) accuracy = accuracy_score(y_test, predictions) print("Thresh=%.3f, n=%d, Accuracy: %.2f%%" % (thresh, select_X_train.shape[1], accuracy*100.0)) |
注意:您的结果可能会有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑运行几次示例并比较平均结果。
运行此示例会打印以下输出。
|
1 2 3 4 5 6 7 8 9 |
准确率:77.95% 阈值=0.071,n=8,准确率:77.95% 阈值=0.073,n=7,准确率:76.38% 阈值=0.084,n=6,准确率:77.56% 阈值=0.090,n=5,准确率:76.38% 阈值=0.128,n=4,准确率:76.38% 阈值=0.160,n=3,准确率:74.80% 阈值=0.186,n=2,准确率:71.65% 阈值=0.208,n=1,准确率:63.78% |
我们可以看到,模型的性能通常随着所选特征数量的减少而降低。
在这个问题上,特征与测试集准确率之间存在权衡,我们可以决定采用一个复杂性较低的模型(较少的属性,例如 n=4),并接受估计准确率从 77.95% 适度下降到 76.38%。
这在如此小的数据集上可能影响不大,但在更大的数据集上使用交叉验证作为模型评估方案可能是一种更有用的策略。
总结
在这篇文章中,您了解了如何访问特征并在训练好的 XGBoost 梯度提升模型中使用重要性。
具体来说,你学到了:
- 什么是特征重要性以及它通常如何在 XGBoost 中计算。
- 如何从 XGBoost 模型中访问和绘制特征重要性分数。
- 如何使用 XGBoost 模型的特征重要性进行特征选择。
您对 XGBoost 中的特征重要性或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。


 for Feature Selection in Python")



你好。我正在运行“select_X_train = selection.transform(X_train)”,其中 x_train 是包含几行因变量的数据。
我得到的错误是“select_X_train = selection.transform(X_train)”
请求您的帮助。
谢谢!
抱歉,错误是“TypeError: only length-1 arrays can be converted to Python scalars”。
检查您的 X_train 的形状,例如 print(X_train.shape)
您可能需要将其重塑为矩阵。
你如何解决这个问题?我也有同样的问题。
这可能有帮助
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
我尝试根据这篇帖子(最后一部分使用阈值)为 xgboost 选择特征,但由于我使用了网格搜索和管道,因此报告了此错误。
select_X_train = selection.transform(X_train)
文件“C:\Users\Markazi.co\Anaconda3\lib\site-packages\sklearn\feature_selection\base.py”,第 76 行,在 transform 中
mask = self.get_support()
文件“C:\Users\MM.co\Anaconda3\lib\site-packages\sklearn\feature_selection\base.py”,第 47 行,在 get_support 中
mask = self._get_support_mask()
文件“C:\Users\Markazi.co\Anaconda3\lib\site-packages\sklearn\feature_selection\from_model.py”,第 201 行,在 _get_support_mask 中
scores = _get_feature_importances(estimator)
文件“C:\Users\Markazi.co\Anaconda3\lib\site-packages\sklearn\feature_selection\from_model.py”,第 32 行,在 _get_feature_importances 中
% estimator.__class__.__name__)
ValueError: 底层估算器方法没有 `coef_` 或 `feature_importances_` 属性。要么将已拟合的估算器传递给 SelectFromModel,要么在调用 transform 之前调用 fit。
此致,
你好 sa,
考虑先不使用管道尝试示例,使其正常工作,然后再尝试添加额外的复杂性。
你好,Brownlee先生
谢谢
我之前已经尝试过不使用管道的示例,它运行良好。添加管道后,它可以提取特征重要性,但之后会失败。谢谢。
此致,
感谢您的帖子。我不明白特征重要性图的 x 轴中的“F-score”是什么意思……每个条形图旁边的数字是什么?
你好 Johnn,
您可以在这里了解有关 F1 分数的更多信息
https://en.wikipedia.org/wiki/F1_score
该数字是缩放后的重要性,它只相对于其他特征才有意义。
嗨,Jason,
您确定图表上的 F 分数与传统 F1 分数相关吗?
我找到了这个 github 页面,作者在那里展示了从 xgb 中提取特征重要性含义的多种方法。他对 F 度量的解释似乎与 F1 没有关系。
https://github.com/Far0n/xgbfi
重要性分数与 F 分数不同。上面的教程侧重于特征重要性分数。
你好 Johnn,
Gonçalo 说得对,问题不是 F1 分数。F1 分数与特征重要性图中的 F 分数完全不同。
特征重要性上下文中的 F 分数简单地表示一个特征在所有树中用于分割数据的次数。至少,如果您使用的是 Xgboost 的内置特征。
资源:https://github.com/dmlc/xgboost/blob/b4f952b/python-package/xgboost/core.py#L1639-L1661
希望这有助于澄清问题。
祝好,
D.
感谢分享!
plot_importance() 默认根据 importance_type = 'weight' 绘制特征重要性,即特征在树中出现的次数。
这与 clf.feature_importance_ 相比令人困惑,后者默认基于归一化增益值。
您可以使用此代码检查图表和 feature_importance_ 值之间的对应关系
# 如何从 plot_importance fscore 中获取 feature_importances_ (基于增益)
# 计算两种类型的特征重要性
# Weight = 特征在树中出现的次数
# Gain = 使用该特征的分割的平均增益 = 如果特征多次出现,则平均所有增益值
# Normalized gain = 平均增益占总平均增益的比例
k = clf.get_booster().trees_to_dataframe()
group = k[k['Feature']!='Leaf'].groupby('Feature').agg(fscore = ('Gain', 'count'),
feature_importance_gain = ('Gain', 'mean'))
# 特征重要性与 plot_importance(importance_type = 'weight') 相同,默认值
group['fscore'].sort_values(ascending=False)
# 特征重要性与 clf.feature_importance_ 默认值 = 'gain' 相同
group['feature_importance_gain_norm'] = group['feature_importance_gain']/group['feature_importance_gain'].sum()
group['feature_importance_gain_norm'].sort_values(by='feature_importance_gain_norm', ascending=False)
# 特征重要性与 plot_importance(importance_type = 'gain') 相同
group[['feature_importance_gain']].sort_values(by='feature_importance_gain', ascending=False)
注意
1. feature_importance_ 为零的特征不会显示在 trees_to_dataframe() 中。您可以使用以下代码检查它们是什么
X_train.columns[[ x not in k['Feature'].unique() for x in X_train.columns]]
2. 'weight' 和 'gain' 类型的重要性排名可能大不相同。在根据图表选择特征时要小心。我会选择增益而不是权重,因为增益反映了特征在分割时将相似实例分组到更同质的子节点的能力。
精彩的评论!
嗨,Jason,
您的帖子对我学习机器学习技术总是很有帮助!
特别是这篇 XGBoost 帖子真的帮助我完成了正在进行的面试项目。
任务不是 Kaggle 竞赛,而是我的技术面试!🙂
我使用了您的代码生成特征重要性排名,以及您用于描述技术的一些解释。
您可以在此处找到它:https://www.kaggle.com/soyoungkim/two-sigma-connect-rental-listing-inquiries/rent-interest-classifier
我还将您的链接放在参考部分。
如果我使用您的代码不合适,请告诉我。
干得好。
只要您注明出处,我很高兴。
嗨,Jason,
我对特征重要性有一些疑问。
我想在其他分类模型中使用 XGBoost 选择的特征,并且
我对如何获取正确的特征分数感到困惑,我的意思是是否有必要调整参数以获得最佳模型并获得相应的特征分数?换句话说,我如何才能在模型中获得正确的特征分数?
非常感谢。
分数是相对的。
您可以将它们用作过滤器,并选择分数高于 x(例如 0.5)的所有特征。
嗨,Jason,我知道选择一个阈值(比如 0.5)总是任意的……但有什么经验法则吗?
非常感谢。
是的,从 0.5 开始,如果需要再调整。
嗨,Jason,
是否有应打折的分数?例如,我的最高分是 0.27,然后是 0.15、0.13……我应该完全打折模型吗?谢谢!
分数是相对的。在您的特定数据集上测试不同的截止值。
一个不用担心阈值的好方法是使用类似 – CalibratedClassifierCV(clf, cv='prefit', method='sigmoid') 的东西。
它对您的分类器进行了 .5 校准,而不会影响您的基本分类器输出。
太棒了,感谢分享这个技巧!
我在这里还有更多关于这个主题的内容
https://machinelearning.org.cn/calibrated-classification-model-in-scikit-learn/
你好,先生,
对于 XGBoost 特征选择,我如何将 Y 轴更改为我的属性名称。非常感谢您。
好问题,我不太确定。您可能需要直接使用 xgboost API。
@Omogbehin,要自动获取 Y 标签,您需要将数组切换为 Pandas 数据框。这样,您就可以自动获取带标签的 Y 和 X。
column_names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv("diabetes.csv", names = column_names)
X = data.iloc[:,0:8]
Y = data.iloc[:,8]
model = XGBClassifier()
model.fit(X, Y)
from xgboost import plot_importance
plot_importance(model)
plt.show()
1. 您可以直接绘制 feature_importance,如下所示:
clf = xgb.XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'multi:softprob',
nthread=4,
# scale_pos_weight=1,
num_class=6,
seed=0,
verbosity=0).fit(X_train, y_train)
%matplotlib notebook
fig, ax = plt.subplots(figsize=(10,6))
xgb.plot_importance(clf, height = 0.4, grid = False, ax=ax, importance_type='weight')
fig.subplots_adjust(left = 0.35);
2. 或者您也可以输出基于归一化增益值(即增益/增益总和)的特征重要性列表
pd.Series(clf.feature_importances_, index=X_train.columns, name='Feature_Importance').sort_values(ascending=False)
很棒的技巧!
嗨,Jason,
XGBRegressor() 中可以使用“feature_importances_”吗?
抱歉,我一时不确定。
好的,我将尝试另一种特征选择方法。
谢谢
您好 Jason,我使用 XGBRegressor 并希望进行一些特征选择。然而,尽管“plot_importance(model)”命令有效,但当我使用 model.feature_importances_ 检索值时,它显示“AttributeError: 'XGBRegressor' object has no attribute 'feature_importances_”。有什么提示如何检索回归的特征重要性吗?
很抱歉听到这个消息 Richard。我不确定原因。
嗨,Jason,
您知道 RNN 或 LSTM 中一些用于质量变量重要性的方法吗?XGBoost 方法可以用于 RNN 或 LSTM 的回归问题吗?非常感谢。
也许可以,我还没试过。
你能解释一下决策树特征重要性是如何工作的吗?
嗨,Jason,当我在 Xgboost 对象中拟合我的模型时,它显示以下错误
OSError: [WinError -529697949] Windows Error 0xe06d7363
我正在使用 32 位 anaconda
import platform
platform.architecture()
('32bit', 'WindowsPE')
请告诉我如何解决这个问题
抱歉,我没有见过这个错误。
也许您可以发布到 stackoverflow?
你好,Jason。
SelectFromModel(model, threshold=thresh, prefit=True)
我想知道这部分中的 prefit = true 意味着什么。我在 sklearn 网站上查过,但我不明白。
它指定不再拟合模型,我们之前已经拟合过了。
嗨,Jason
你能获得人工神经网络的特征重要性吗?
如果可以,怎么做?
非常感谢。
也许吧,我没见过这样做。
你好,Jason。我正在做一个关于随机梯度提升的项目。我的数据库是临床数据,我认为特征重要性排名可以向临床医生反馈临床知识,即机器可以告诉我们哪些临床特征在区分疾病表型方面最重要。我所做的是在训练集上使用 SGB 预测疾病的表型,其中包含数据库中的所有变量,然后测试模型在测试集中的性能。如果测试结果良好(例如,高准确率和 kappa),那么我想说特征重要性排名是合理的,因为机器可以使用这些排名信息做出良好的预测(即特征重要性是机器从数据库中学到的知识,并且它是正确的,因为机器使用这些知识进行良好的分类)。反之,如果预测结果不佳,我想说特征重要性排名很差甚至错误。在这种情况下,进行特征选择是浪费时间,因为特征重要性不正确(要么是因为数据质量差,要么是机器学习算法不合适)。我可以问一下我的上述想法是否合理吗?
我的第二个问题是,我没有像您在帖子中那样进行特征选择以识别特征子集。我只是将排名列表顶部的几个特征视为最重要的临床特征,然后进行经典分析,如 t 检验,以确认这些特征在不同的表型中具有统计学差异。我仍然可以将其命名为特征选择或特征提取吗?我对这些术语有点困惑。谢谢,我正在等待您的回复。
抱歉,我不太明白。您能把问题精炼成一两句话吗?
是的,您仍然可以称之为特征选择。
谢谢你的回复。
正如您可能知道的,随机梯度提升 (SGB) 是一种内置特征选择的模型,它被认为比包装方法和过滤方法在特征选择方面更有效。但我怀疑我们是否总是可以信任 SGB 选择的特征,因为即使模型性能不佳(例如,测试准确率非常低),模型仍然会提供特征的重要性(相对影响)。在这种情况下,模型甚至可能是错误的,因此选择的特征也可能是错误的。所以我想听听您对此问题的看法。
谢谢。
也许可以比较用不同特征子集拟合的模型,看看是否能提高技能。
尝试使用在不同特征子集上拟合的模型集成,看看是否能进一步提高技能。
你好,Jason。
您能告诉我您在这里使用的特征选择方法是归类为过滤、包装还是嵌入式特征选择方法吗?
此致,
这里我们正在进行特征重要性或特征评分。它将是一个过滤器。
嗨,Brownlee,如果我有一个包含 118 个变量的数据集,但目标变量在 116 中,我想使用 6-115 和 117-118 变量作为因变量,我该如何修改代码 X = dataset[:,0:8]
y = dataset[:,8]
来获取 X 和 Y?
我没有弄清楚这个简单的问题。请帮忙。
谢谢,
嗨,Jason,
谢谢您的教程。
您是否注意到当您使用 model.get_importances_ 与 xgb.plot_importance(model) 时,重要性值差异很大?
我对刚训练的模型使用了这两种方法,看起来它们完全不同。此外,numpy 数组 feature_importances 与 plot_importance 函数返回的索引不直接对应。
换句话说,这两种方法给我的定性结果不同。有什么想法吗?
我没有注意到。也许可以在 xgboost 用户组或项目上提交一个工单?听起来像一个错误?
我的问题中有一个错别字
应该是 model.feature_importances,而不是 model.get_importances_。
更好的重要性估计
model.feature_importances_ 使用
Booster.get_fscore(),它使用
Booster.get_score(importance_type='weight')
这是对“增益”的估计(即所有树表示某个特征的次数)。
我认为最好使用 Booster.get_score(importance_type='gain') 来获得更精确的特征重要性评估。
总的来说,它描述了通过该特征分割分支的效果如何。
感谢分享。
嗨 Jason
感谢所有精彩的帖子。关于 Xgboost(或更一般的梯度提升树)中的特征重要性,您对 SHAP 有何看法?我不确定您是否已经发表过讨论 SHAP 的帖子,但它对于需要梯度提升树模型进行特征选择的人来说绝对有趣。
谢谢!
什么是 SHAP?
嗨 Jason
我想知道 Xgboost 中不同方法(如“weight”、“gain”或“cover”等)的特征重要性计算。
请告诉我如何实现?是否可以使用您在此处开发模型(使用 Xgbclassifier)的相同方式完成?
此外,根据您的代码,哪种默认方法提供了变量重要性?
(model.feature_importances_)
我需要使用 Xgboost 中的“weight”、“gain”或“cover”等保存大量特征(约 225 个)的重要性。
我不确定 xgboost 是否能提供这个,您可能需要自己实现。
您可以使用以下代码
model.get_booster().get_score(importance_type='type')
“type”可以填写“weight”、“gain”或“cover”。
default = 'weight'
参见:https://docs.xgboost.com.cn/en/latest/python/python_api.html
抱歉,我在使用 xgboost 建模时遇到了一个问题。我可以向您求助吗?我使用 predict 函数获取预测概率,但我得到了一些低于 0 或高于 1 的概率。我想知道我的问题出在哪里。您能帮我吗?非常感谢。
具体问题是什么?概率低?
在比较不同特征数量的模型性能时,是否需要进行网格搜索?例如,如果我想查看具有 8 个特征的模型是否比具有 4 个特征的模型表现更好,那么对两者都运行网格搜索是否是一个好的做法?
这取决于您拥有的时间和资源以及项目的目标。
也许比较具有不同输入特征的相同模型配置会是很好的第一步(例如,不进行网格搜索)。
我们如何使用(比如说)前 10 个特征来训练模型?我找不到在初始化时这样做的参数。
您必须使用特征选择方法来选择您想要使用的特征。没有最好的特征选择方法,只有对什么可能有用有不同的看法。
嗨,Jason,
读完您的书后,我成功地实现了一个模型。但是,我有一些问题,如果您能提供反馈,我将不胜感激。
Q1 – 在特征选择方面,当我们使用 XGBOOST 确定最重要的特征时,我们可以应用 PCA(主成分分析)、LDA(线性判别分析)或核 PCA 吗?
Q2 – 您认为我们应该在对分类值进行独热编码后应用标准缩放吗?再次强调,有些人说这在决策树之类的模型中是不必要的,但我想听听您的意见。
Q3 – 当我们使用 XGBOOST 时,是否需要担心虚拟变量陷阱?我找不到关于 XGBOOST 如何处理虚拟变量陷阱(即是否需要删除一列)的良好来源。
一如既往,我非常感谢您的反馈。
谢谢你。
您可以尝试降维方法,这真的取决于数据集和模型的配置,看看它们是否会有益。
XGBoost 不需要对数据进行重新缩放。标准化可能对高斯变量有用。测试一下看看。
虚拟变量可能很有用,特别是如果它们揭示了数据中不明显的级别分组(例如,添加标志变量)
一如既往,非常感谢 Jason。
对于对我的实验感兴趣的人
降维方法并没有真正起到多大作用。在我的案例中,XGBOOST 特征选择方法要好得多。
标准化既没有改变准确率分数,也没有改变预测结果。
保留虚拟变量使准确率提高了约 2%,我使用 KFold 测量了准确率。
谢谢
谢谢
干得好!
嗨,Jason,
感谢您的帖子。这真的很有帮助。
但我仍然对“重要性是根据每个属性分割点改进性能度量的量来计算单个决策树的”感到困惑。
如何计算“每个属性分割点改进性能度量的量”?
这是在构建每个单独的树时计算的。最终的重要性分数是这些分数的平均值。
嗨,Jason,我尝试通过 c++ 重新实现 python 训练的 xgboost 模型时遇到了一个问题。我构建了与 python 训练的相同决策树(使用 'model.dump_model' 函数),但我得到了不同的分数。我不知道为什么,也想不明白,您能给我一些提示吗?谢谢!
也许你的实现有区别?这可能是无数原因之一——抱歉我无法诊断。
你好,
当我运行这段代码时
plot_importance(model)
pyplot.show()
我收到一个错误
ValueError: tree must be Booster, XGBModel or dict instance
我该如何处理?
抱歉,我没有见过那个错误,我这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
有没有办法获取特征的符号以了解影响是积极的还是消极的。
据我所知,没有,抱歉。
当我点击链接:“names in the problem description”时,我收到 404 错误。
“f1, f2..” 名称没有用。我想要真实的列名。
谢谢,我已经更新了链接到
https://github.com/jbrownlee/Datasets/blob/master/pima-indians-diabetes.names
嗨,Jason,
再次感谢这篇精彩的帖子。就像我们使用随机森林进行特征选择时会记住一些技巧一样。
例如 – 基数高的分类变量/连续变量优先于其他变量(因为分割次数更多)
并且在 RF 特征重要性中看不到相关性。
XGBoost 是否也存在与随机森林类似的缺点??
是的,也许这篇文章会有所帮助
https://machinelearning.org.cn/configure-gradient-boosting-algorithm/
你好!
鉴于特征重要性是一个非常有趣的属性,我想问这是否是其他模型(如线性回归(及其正则化伙伴)、支持向量回归器或神经网络)中可以找到的特征,或者它是否是一个专门为基于树的模型定义的概念。我问这个问题是因为我不确定我是否可以将例如线性回归的系数视为特征重要性的类比。
谢谢!
是的,线性回归中的系数大小可以是重要性的标志。
SVM,则不然。
非常感谢!
不客气。
感谢您的所有帖子。我经常拜读您的博客。
我有一个问题。如果您有大量特征,您会想使用所有这些特征吗?我有一个包含超过 1,000 个特征的数据集,但并非所有这些特征都对这个我正在处理的分类问题有意义。我应该在应用 XGBoost 之前减少特征数量吗?如果应该,我该怎么做?
尝试使用所有特征进行建模,并将结果与在选定特征子集上拟合的模型进行比较,看看是否能提高性能。
嗨,Jason,
多重共线性是否会影响提升回归树的特征重要性?如果会,您会建议如何处理这个问题?
谢谢!
可能不会。
尝试使用和不使用共线性特征进行建模,并比较结果。
你好 Jason,
关于sklearn(随机森林)中类似方法的默认特征重要性,我推荐一篇有意义的文章
https://explained.ai/rf-importance/
作者指出,使用Gini的默认特征重要性实现存在偏差。
我曾多次观察到这种偏差,即高估添加到数据集中的人工随机变量的重要性。对于这个问题,所谓的排列重要性是一个解决方案,但代价是计算时间更长。
然而,还有其他方法,如“drop-col importance”(在同一来源中描述)。有趣的是,在处理生产数据时,我发现有些变量在排序分布的头部或尾部出现——这取决于我应用的是上述两种方法中的哪一种。
这有点令人困惑,现在我在使用RF进行特征选择时非常谨慎。
您在这个领域有什么经验或最佳实践可以分享吗?
此致!
感谢分享。
我最好的建议是把重要性作为一种建议,但要保持怀疑。测试多种方法,多个子集,让特征用确凿的证据在模型中发挥作用。
我的数据只有6列,其中我想预测其中一列,所以剩下5列。其中2个是分类变量,3个是数值变量。因此,我使用了https://scikit-learn.cn/stable/auto_examples/compose/plot_column_transformer_mixed_types.html来解决混合数据类型问题。但是当特征重要性大小与原始列数不匹配时怎么办?feature_importances_数组的大小是918
我的意思是它生成了额外的特征,或者它为分类变量的独热编码创建了一个特征值。
我检查了我的数据有1665个独特的品牌值。所以,它与feature_importances_数组大小不相同
对分类数据执行特征选择可能会令人困惑,因为它可能经过独热编码。
也许可以创建一个只包含数值特征的数据子集,并对其进行特征选择?
谢谢,但我发现一旦我尝试使用虚拟变量代替上面提到的列转换器方法,它就奏效了,这似乎是由于在转换过程中当xgboost booster选择特征名称时,信息有所丢失
很高兴听到这个消息。
有趣的评论,非常感谢!
我如何逆向工程决策树?也就是说,改变目标变量,从而让特征变量自我调整。
基本上,我想设定一个目标变量值,并获取所有可能产生该目标变量值的特征变量值。
逆向机器学习/预测建模非常困难,甚至可能无法实现。
你可以将一棵树转化为规则,并由此得出许多“结果”。
对于树的集成模型来说,这可能没有意义。
嗨,Jason,
感谢您的及时回复。我将尝试解决这个问题,并告诉您进展如何。
诚挚的问候
祝你好运!
最后如何提取n个最佳属性?
我在上面的教程中给出了一个例子。
谢谢杰森,非常有帮助!
有没有办法确定一个特征与结果变量是正相关还是负相关?
是的,你可以计算它们之间的相关性。
精确度:51.85%
阈值=0.030,n=10,精确度:46.81%
阈值=0.031,n=9,精确度:50.00%
阈值=0.032,n=8,精确度:47.83%
阈值=0.033,n=7,精确度:51.11%
阈值=0.035,n=6,精确度:48.78%
阈值=0.041,n=5,精确度:41.86%
阈值=0.042,n=4,精确度:58.62%
阈值=0.043,n=3,精确度:68.97%
阈值=0.045,n=2,精确度:62.96%
阈值=0.059,n=1,精确度:0.00%
嗨,Jason,感谢您的帖子,我很高兴阅读这种有用的机器学习文章。我有一个问题:上面的输出是我的示例。如您所见,当阈值=0.043且n=3时,精确度急剧上升。所以,我想仔细看看那个阈值,并想找出这3个特征的名称和相应的特征重要性。我如何实现这个目标?
每个特征都有一个从0到n的数据集中列的唯一索引。如果您知道列的名称,则可以将列索引映射到名称。
然后您可以在Python中自动化此操作。
希望这能有所帮助。
嗨!我正在使用xgb.train命令而不是XGBClassifier,因为这样快得多。顺便问一下,您知道为什么吗,以及是否可以通过XGBClassifier获得相同的性能(可能与线程数有关)?
总之,您知道如何通过xgb.train获得重要性特征吗?
非常感谢
你确定它更快吗?速度应该是一样的。
准确率从 n=7 时的 76.38 增加到 n=6 时的 77.56,有什么原因吗?
可能是输入的变化,也可能是学习算法的随机性。
一个公平的比较将使用重复的k折交叉验证,也许还需要进行显著性检验。
你好 Jason,
我正在处理一个不平衡的数据集,用于机器异常检测。我有590个特征和1567个观测值。我尝试使用这种方法来减少特征数量,因为我注意到存在多重共线性,但是,我的精确率和召回率结果没有显著变化,有时结果会变得非常奇怪。我想知道这可能预示着什么?
以下是特征选择的结果
阈值=0.000,n=211,f1_score:5.71%
precision_score:50.00%
recall_score:3.03%
accuracy_score:91.22%
阈值=0.000,n=210,f1_score:5.71%
precision_score:50.00%
recall_score:3.03%
accuracy_score:91.22%
阈值=0.000,n=209,f1_score:5.71%
precision_score:50.00%
recall_score:3.03%
accuracy_score:91.22%
阈值=0.000,n=208,f1_score:5.71%
precision_score:50.00%
recall_score:3.03%
accuracy_score:91.22%
阈值=0.000,n=207,f1_score:5.71%
precision_score:50.00%
recall_score:3.03%
accuracy_score:91.22%
.
.
.
阈值=0.006,n=55,f1_score:11.11%
precision_score:66.67%
recall_score:6.06%
accuracy_score:91.49%
阈值=0.006,n=54,f1_score:5.88%
precision_score:100.00%
recall_score:3.03%
accuracy_score:91.49%
阈值=0.007,n=53,f1_score:5.88%
precision_score:100.00%
recall_score:3.03%
accuracy_score:91.49%
阈值=0.007,n=52,f1_score:5.88%
precision_score:100.00%
recall_score:3.03%
accuracy_score:91.49%
.
.
.
阈值=0.007,n=47,f1_score:0.00%
precision_score:0.00%
recall_score:0.00%
accuracy_score:91.22%
UndefinedMetricWarning:F-score未定义,由于没有预测样本,因此设置为0.0。
“precision”、“predicted”、average、warn_for)
由于没有预测样本,精确率未定义并设置为0.0。
“precision”、“predicted”、average、warn_for)
很有趣,我不确定。
您可能需要深入研究数据的具体情况,以了解发生了什么。如果您正在使用交叉验证,那么可能有些折叠没有目标类别的例子——请使用分层交叉验证。
你说得对。我少数类别有104个例子,另一个类别有1463个。在这种情况下,你会建议过采样吗?
也许可以测试一下看看。
更多想法在这里
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
嗨
我有一个疑问,我们如何知道在模型中使用每个重要性作为阈值时选择的特征名称。
加载数据数组中的每一列都将映射到您的原始数据中的列。
如果您知道原始数据中的列名,就可以找出加载数据、模型或可视化中的列名。
你能尝试用shap库绘制基于树的算法的模型解释吗??
感谢您的建议。
Xgboost 多线性特征的重要性变量 –
我正在使用60个观测值*90个特征的数据(所有连续变量),响应变量也是连续的。这90个特征高度相关,其中一些可能存在冗余。我正在使用python中的增益特征重要性(xgb.feature_importances_),其总和为1。我运行xgboost 100次,并根据100次运行中平均变量重要性的排名选择特征。假设我选择了10个因子,然后再次使用相同的超参数在这些10个特征上运行xgboost,令人惊讶的是,在这些10个变量中,最重要的特征变得最不重要。对此有什么可行的解释吗?
目前还没有,不过这重要吗?
选择一个能带来最佳结果/最熟练模型的特征子集——任何重要性分数最多都只是“建议”。
在XGBoost模型中,我们推导出的最重要的特征表明哪个特征比其余特征更具影响力。
例如,如果最重要的特征是任职天数,我如何确定“更多任职天数”或“更少任职天数”会增加输出中的评级。
我如何确定它是积极影响还是消极影响?
我不确定我是否理解。重要性不是正向或负向的。
如果您有疑问:构建一个包含和不包含它的模型,并比较模型的性能。
我不明白特征重要性图中的F分数,它的值怎么会是100+。另外,如果这不是传统的F分数,您能指出它的定义/解释吗?(在xgb文档中找不到)
分数是相对的。
是否可以使用投票分类器集成的模型来绘制重要特征?
如果不能,那么在集成技术中绘制重要特征的替代方法是什么?
谢谢你
并不是真的。
大多数决策树集成模型都可以为您提供特征重要性。
谢谢您!
但是使用由随机森林、决策树、XGBoost和逻辑回归组成的投票分类器进行集成呢?
投票集成模型无法提供获取重要性分数的方法(据我所知),无论组合的是什么。
好的。
非常感谢!
不客气。
您好,首先感谢您的代码。
当我运行:“select_X_train = selection.transform(X_train)”时,我收到以下错误:“ValueError: Input contains NaN, infinity or a value too large for dtype('float64')。”
我的特征确实包含一些NaN值、虚拟变量和分类变量。您知道有没有什么办法可以在不更改数据的情况下解决这个问题吗?
提前感谢,
Daniel
您需要首先填充 NaN 值,或者删除包含 NaN 值的行
https://machinelearning.org.cn/handle-missing-data-python/
你好,
我在代码的这一行“select_X_train = selection.transform(X_train)”收到一个错误。错误信息很简单:“KeyError: weight'
我查了一些资料,发现SelectFromModel期望一个具有coef_或feature_importances_的估计器。显然XGBoostClassifier确实有这个属性。为什么它对我不起作用,却对其他人起作用?
请帮忙!
也许可以确认您的XGBoost版本是最新的?
我遇到了同样的错误。我通过pip安装了xgboost 1.0.2。
它在xgboost 0.90中有效,但在1.0.2中无效。
谢谢,我会调查的!
我增加了一个权宜之计。
太棒了!您真是一位大师。谢谢您。
谢谢您的美言。
请删除我的上一篇文章……xgboost 0.90 成功了
已完成。
你好,
我想在我的研究中使用“使用XGBoost特征重要性分数进行特征选择”方法和模型选择。我应该如何在论文/学位论文中引用它?
谢谢你
这会有帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-reference-or-cite-a-book-or-blog-post
我的xgb模型拟合一次需要很长时间,我想尝试许多阈值,那么我可以使用另一个简单的模型来找到最佳阈值吗?如果可以,您推荐哪种模型?
您可以尝试,但阈值应针对特定模型计算。
您好,先生。
我尝试运行print(model.feature_importances_)
但它返回一个包含所有“nan”的数组,如[nan nan nan … nan nan nan]
而且,当我尝试使用plot_importance(model)绘制模型时,它返回Booster.get_score()结果为空
您有什么建议吗?非常感谢
这很奇怪。也许检查一下你是否拟合了模型?
是的,它返回如下
XGBClassifier(base_score=0.5, booster=None, colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints=None,
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=0, num_parallel_tree=1,
objective='binary:logistic', random_state=0, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, subsample=1, tree_method=None,
validate_parameters=False, verbosity=None)
真有意思。
我一下子不确定,您可能需要尝试改变训练数据并查看效果。
您好,布朗利先生,
我正在用您关于XGB特征重要性和阈值的想法测试一个我最近正在调查的问题。我正在处理一些奇怪的结果,我想知道您是否可以帮忙。
首先,运行一段与您的代码类似的代码,以查看每个阈值(从所有特征开始到只剩1个特征结束)上的不同度量结果。之后,我检查这些度量并记录最佳结果以及产生这些(最佳)度量的特征数量。最后,我取出这些特征,并仅使用这些特征运行XGB算法,但这次结果与我上一步得到的结果不同。对此副作用有什么好的解释吗?
感谢您的宝贵时间
也许结果的差异是由于学习算法或测试工具的随机性。
也许可以设计一个健壮的测试工具,并在建模流程中执行特征选择。
亲爱的杰森
感谢您的程序
我有两个问题
1)如果我的目标数据不是分类或二进制数据,例如波士顿房价有许多价格目标,那么我在特征选择之前对价格进行编码吗?
2)特征选择和相关性必须有相同的结果吗?
首先感谢您的时间
不,那是一个回归问题
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-classification-and-regression
不,每种技术都会给你不同的特征重要性概念。你可以根据每个建议拟合一个模型,并发现实际能产生熟练模型的结果。
谢谢你的回答
不客气。
嗨。
如何获得输入变量对输出变量的影响(百分比)
一种方法是将每个分数转换为分数总和的比率。
嗨,Jason,
感谢您提供如此详细的教程——我学到了很多。
我有一个问题,在“使用XGBoost特征重要性分数进行特征选择”部分,您使用了
阈值 = sort(model.feature_importances_)
并沿着这些阈值进行for循环,以评估可能的模型。
有没有办法使用plot_importance()结果中的值作为阈值来做类似的事情?
我查看了plot_importance()返回的数据类型,它是一个matplotlib对象,而不是像model.feature_importances_那样的数组。
您能指导我如何实现这一点吗?
谢谢你
好问题,詹姆斯,是的,肯定有办法,但我暂时不确定。也许可以查看XGBoost库的API以找到合适的函数?
好的
还有一件事,在不同阈值和各自不同n个特征的结果中,如何找出每个阈值或这个n个特征场景中包含哪些特征?意思是,它们是哪些特征?您能展示一下吗?
抱歉,我没听懂你的问题。你能重述或详细说明一下吗?
Jason,
您的解释方式非常简单明了。请继续保持!
关于这个主题,我尝试了手动特征重要性和XGBoost内置的特征重要性,但得到了不同的排名。我不确定为什么?
谢谢。
我相信他们对绘图和自动方法使用了不同的评估函数。
杰森,做得太棒了,非常有帮助……!
如果我可以问一下两种特征重要性计算方法之间的区别,因为我得到了矛盾的结果和不匹配的数字。
例如:第一种方法输出在[0,1]之间,第二种方法输出结果>1,您能解释一下区别吗?🙂
除此之外,如果我们把特征重要性作为排名,并抛开两种方法之间不同尺度的问题,我遇到了矛盾的结果,即第一种方法中最重要的特征不是第二种方法中最重要的特征。
谢谢。
我相信内置方法使用不同的评分系统,您可以通过向函数传递参数来使其与您的评分系统保持一致。
你好,
看起来如果对 model.feature_importances_ 进行排序,model.feature_importances_ 和内置的 xgboost.plot_importance 的特征重要性结果是不同的。我认为您宁愿使用 model.get_fsscore() 来确定重要性,因为 xgboost 使用 fs 分数来确定和生成特征重要性图。
-雅各布
感谢分享。
特征重要性和特征选择方法有什么区别?
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-feature-selection-and-feature-importance
解释得很好,谢谢。那么,当我们运行特征选择时,是否应该期望选择最重要的变量?
谢谢!
XGBoost 在拟合模型的过程中会自动执行特征选择。
Jason,非常感谢您对XG-Boost的澄清。在XGBoost中,我使用了xgb.plot_importance,它通过F分数绘制所有特征。我如何绘制在拟合模型时使用的选定特征?
重要性分数本身反映了特征在拟合模型中使用的程度。
你好,
感谢您的智慧。
我正在使用Python和递归特征消除(RFE)。我正在尝试不同类型的模型,例如XGBClassifier、决策树或KNN。
但是,当模型是XGBClassifier或KNN时,RFE会给我以下错误。KNN不提供进行特征选择的逻辑,但XGBClassifier提供。
我做错了什么,或者XGBClassifier出现这个错误有什么解释吗?
错误:分类器未公开“coef_”或“feature_importances_”属性
不客气。
有意思。也许可以检查一下你的XGBoost库是否是最新的?
否则,也许XGBoost不能以这种方式使用——这很可惜。
你好,
当使用最小阈值时,我得到了一个空的select_X_train(所以通常所有其他阈值也会得到相同的结果)。有人能帮我找出原因吗?
此致!
是的,如果阈值过低,您将不会选择任何特征。请提高它。
你为什么在这里使用‘SelectFromModel’?
我们不能直接这样做吗?
regression_model2 = xgb.XGBRegressor(**tuned_params)
regression_model2.fit(X_imp_train,y_train,eval_set = [(X_imp_train,y_train),(X_imp_test,y_test)],verbose=False)
gain_importance_dict2temp = regression_model2.get_booster().get_score(importance_type='gain')
gain_importance_dict2temp = sorted(gain_importance_dict2temp.items(), key=lambda x: x[1], reverse=True)
#特征选择
feature_importance_len = len(gain_importance_dict2temp)
temmae = 10000.0
tempfeature_list = []
for i in range(1,feature_importance_len)
list_of_feature = [x for x,y in gain_importance_dict2temp[:feature_importance_len-i]]
print(list_of_feature)
X_imp_train3 = X_imp_train[list_of_feature]
X_imp_test3 = X_imp_test[list_of_feature]
regression_model = xgb.XGBRegressor(**tuned_params)
regression_model.fit(X_imp_train3,y_train,eval_set = [(X_imp_train3,y_train),(X_imp_test3,y_test)],verbose=False)
ypred= regression_model.predict(X_imp_test3)
我们使用从模型中选择,因为XGBoost模型具有特征重要性分数。
您基本上实现了选择模型自动执行的功能。
谢谢,你太棒了,我没想到你会回答这样的小问题。谢谢。
不客气。
按照完全相同的代码,但在投影特征选择结果的前几行后,在“select_x_train = selection.transform(x_train)”行中出现“ValueError: X has a different shape than during fitting.”错误。
请帮忙,非常感谢
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
谢谢回复。我添加了阈值的np.sort,问题解决了
threshold = np.sort(xgb.feature_importances_)
很高兴听到这个消息,埃里克!
嗨,Jason,我使用了算法A的标准版本,它具有特征x、y和z
然后我使用了特征工程为算法A添加了新特征(10个新特征)
我想使用特征重要性方法仅在10个特征中选择最重要的特征,而不删除任何(x,y,z特征)
我能否首先确定我希望在其上应用特征重要性方法的特征列表?
当然。你可以使用任何你喜欢的特征,例如算法选择的特征和你自己选择的特征的组合。
感谢您的回复
不客气。
感谢您的文章。
我决定使用DF读取Pima印第安人数据,并输入特征名称,以便在绘制特征重要性时能够看到它们。
我使用了以下代码将特征名称添加到model.feature_importances_的分数中,并对其进行排序以绘制图表
=======================
from pandas import DataFrame
cols=X.columns
new_df = DataFrame (cols)
importance = model.feature_importances_*100
importance = importance.round(2)
new_df2 = DataFrame (importance)
fi=pd.concat([new_df,new_df2],axis=1)
fi.columns=['Feature','score']
fi.set_index('Feature',inplace=True)
fi.sort_values(by='score', ascending=False, inplace=True)
=========================
将此图与plot_importance(model)生成的图进行比较,您会发现两者对特征的排名顺序不同。知道为什么吗?
我对著名的葡萄酒数据也做了同样的事情,结果两个图的特征重要性排序仍然不同。
值得注意的是,当使用catboost(与xgboost相比),然后使用SHAP来理解特征对模型的影响时,其图与(model.feature_importances_)方法非常相似。
我相信 plot_importance() 使用的指标与 feature_importances_ 不同。
我相信您可以配置绘图函数使用相同的分数,使分数相等。我建议查看API。
嗨,Jason,
感谢您的教程。feature_importances_ 的默认类型是什么,即weight、gain等?文档中不清楚。
先谢谢您了。
抱歉,我不记得了。如果文档不清楚,我建议您深入研究代码。
嗨,Jason,
感谢您的教程,它真的很有用!但是,我遇到了这个错误(ValueError: Shape of passed values is (59372, 40), indices imply (59372, 41)),出现在转换部分,您知道如何解决它吗?我也在Stack Overflow上发布了我的问题,但没有得到解决🙁
https://stackoverflow.com/questions/69362344/valueerror-shape-of-passed-values-is-59372-40-indices-imply-59372-41
似乎有一个差一错误。检查你如何预处理数据。
嘿,Jason先生……非常感谢您的精彩文章。
我正在使用基于KNN模块的XGBoost特征重要性评分进行特征选择,到目前为止它已经显示出很好的结果。
我有一个问题,当我运行负责特征选择的循环时,我想查看每次迭代中涉及的特征。有没有简单的方法可以做到这一点?
没有简单的方法。我敢打赌最好的方法是深入研究XGBoost代码,添加一两行来打印出来。
UserWarning: X has feature names, but SelectFromModel was fitted without feature names
warnings.warn(
你好,我在尝试查找特征重要性分数时遇到上述错误。DF中有带名称的特征。以下是我使用的代码。您能提供一个解决方案吗?谢谢。
代码
model = XGBClassifier()
model.fit(X_train, y_train)
# 对测试数据进行预测并评估
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
# 使用每个重要性作为阈值拟合模型
阈值 = sort(model.feature_importances_)
for thresh in thresholds
# 使用阈值选择特征
selection = SelectFromModel(model, threshold=thresh, prefit=True)
select_X_train = selection.transform(X_train)
# 训练模型
selection_model = XGBClassifier()
selection_model.fit(select_X_train, y_train)
# 评估模型
select_X_test = selection.transform(X_test)
predictions = selection_model.predict(select_X_test)
accuracy = accuracy_score(y_test, predictions)
print("Thresh=%.3f, n=%d, Accuracy: %.2f%%" % (thresh, select_X_train.shape[1], accuracy*100.0))
嗨,Swappy……看起来你只是使用了代码示例,而不是完整的程序列表。
我目前正在Kaggle蘑菇分类数据上应用XGBoost分类器,复制本文中的代码。当使用XGBClassifier时,重要特征的数量可以从原始的22个变量减少到6-8个,并且仍然具有很高的准确率。
然后我尝试在相同的数据上使用XGBRFClassifier,这进一步从最佳特征集中削减了一个变量。然而,它似乎在某个地方遇到了一个“障碍”,准确率从100下降到较低的值,接下来的2次削减,然后又回升到100,从那时起又恢复了下降趋势。
这看起来很不寻常,但这是正常的吗,还是模块出了问题?
感谢任何反馈。
Romy
嗨,Romy……以下内容可能会让您感兴趣
https://indiantechwarrior.com/why-does-the-loss-accuracy-fluctuate-during-the-training/
谢谢,我会去看看的。与此同时,我决定继续使用XGBClassifier,因为当我应用XGBRFClassirier时,我得到了一些奇怪的结果。
嗨,Jason,
感谢您的精彩内容。
假设我有20个预测变量(X)和一个目标变量(y)。
在建立模型之后,我想看看如果只改变其中一个预测变量而保持其余变量不变会发生什么。换句话说,我只想看看该特定预测变量对目标变量的影响。
有没有一种特定的方法可以做到这一点?
我曾考虑创建一个模拟数据集,其中所有其他预测变量保持不变,只更改我感兴趣的那个。然后预测y并绘制该特定预测变量的变化和y的变化。这有意义吗?因为当我这样做时,模拟数据的预测值是相同的……
嗨,乔……您的建议对于小型特征集来说通常是有效的。以下内容可能会让您感兴趣
https://towardsdatascience.com/the-art-of-finding-the-best-features-for-machine-learning-a9074e2ca60d
尝试添加一个随机列,训练它,你会看到随机列不仅重要性>0,而且具有相当大的重要性。
感谢您的反馈和建议,伊万!
尊敬的先生,
运行此代码时出现错误“AttributeError: ‘super’ object has no attribute ‘__sklearn_tags__'”
如何消除这个错误
嗨,rajkumar……错误
AttributeError: 'super' object has no attribute '__sklearn_tags__'通常是由于scikit-learn库版本与XGBoost库版本不兼容造成的。这个问题出现是因为最新版本的scikit-learn使用了__sklearn_tags__属性,而XGBoost的旧版本可能没有实现这个属性。以下是如何解决此错误的方法
—
### **修复错误的步骤**
1. **将XGBoost更新到最新版本**
– 确保您使用的是最新版本的
XGBoost,因为最近的版本已经解决了与scikit-learn的兼容性问题。– 运行以下命令进行更新
bash
pip install --upgrade xgboost
2. **更新scikit-learn**
– 同样,将您的
scikit-learn库更新到最新版本bash
pip install --upgrade scikit-learn
3. **检查库之间的兼容性**
– 使用已知能良好协同工作的
XGBoost和scikit-learn版本。例如–
XGBoost >= 1.6.0–
scikit-learn >= 0.244. **验证您的代码**
– 确保您的代码正确导入和使用了
XGBoost库。一个简单的实现应该像这样pythonfrom xgboost import XGBClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.datasets import make_classification
# 创建数据集
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# 拟合模型
model = XGBClassifier()
model.fit(X, y)
# 特征选择
selection = SelectFromModel(model, threshold=0.5, prefit=True)
X_selected = selection.transform(X)
print("Selected features shape:", X_selected.shape)
5. **重新安装库(如果问题仍然存在)**
– 如果更新无法解决问题,请尝试重新安装
scikit-learn和XGBoostbash
pip uninstall scikit-learn xgboost
pip install scikit-learn xgboost
—
### **补充说明**
– 如果您使用的是较旧的Python版本(<3.8),请考虑更新到Python 3.8或更高版本,因为某些库版本已放弃对旧Python版本的支持。
– 对于特定兼容性项目,请考虑使用虚拟环境来隔离依赖项
bash
python -m venv myenv
source myenv/bin/activate # 适用于Linux/Mac
myenv\Scripts\activate # 适用于Windows
pip install xgboost scikit-learn
按照这些步骤,您应该能够解决
__sklearn_tags__错误并成功运行您的代码。