随机子空间集成由在训练数据集的不同随机选择的输入特征(列)组上拟合的相同模型组成。
选择训练数据集中特征组的方法有很多,而特征选择是一类流行的数据准备技术,专门为此目的而设计。通过同一特征选择方法在不同配置下的选择的特征,以及完全不同的特征选择方法所选择的特征,都可以作为集成学习的基础。
在本教程中,您将学习如何使用 Python 开发特征选择子空间集成。
完成本教程后,您将了解:
- 特征选择为随机子空间选择输入特征组提供了一种替代方法。
- 如何开发和评估由单个特征选择技术选择的特征组成的集成。
- 如何开发和评估由多个不同特征选择技术选择的特征组成的集成。
开始您的项目,阅读我的新书《Python 集成学习算法》,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。

如何用 Python 开发特征选择子空间集成
照片由 Bernard Spragg. NZ 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 特征选择子空间集成
- 单个特征选择方法集成
- ANOVA F 检验集成
- 互信息集成
- 递归特征选择集成
- 组合特征选择集成
- 具有固定特征数的集成
- 具有连续特征数的集成
特征选择子空间集成
随机子空间方法或随机子空间集成是一种集成学习方法,它在训练数据集中的不同随机选择的列组上拟合模型。
在集成中用于训练每个模型的列选择上的差异会导致模型及其预测的多样性。每个模型都表现良好,尽管它们表现不同,产生不同的错误。
训练数据通常由一组特征描述。不同的特征子集,或称为子空间,提供了数据的不同视角。因此,在不同子空间中训练的个体学习器通常是多样的。
— 第 116 页,集成方法,2012。
随机子空间方法通常与决策树一起使用,然后通过简单统计量组合每个树的预测,例如为分类计算众数类别标签,或为回归计算平均预测。
特征选择是一种数据准备技术,它试图选择数据集中与目标变量最相关的列子集。流行的方法包括使用统计度量,例如互信息,以及在特征子集上评估模型并选择导致最佳模型性能的子集,称为递归特征消除(简称 RFE)。
每种特征选择方法对哪些特征与目标变量最相关都会有不同的想法或有根据的猜测。此外,特征选择方法可以针对从 1 到数据集中总列数的特定数量的特征进行定制,这是一个可以在模型选择过程中进行调整的超参数。
每组选定的特征都可以被视为输入特征空间的一个子集,这与随机子空间集成非常相似,尽管是通过度量而不是随机选择的。我们可以使用通过特征选择方法选择的特征作为一种集成模型。
这可能有许多实现方式,但也许有两种自然的方法包括:
- 一种方法:为从 1 到数据集中列总数中的每个特征数生成一个特征子空间,在每个子空间上拟合一个模型,并组合它们的预测。
- 多种方法:使用多种不同的特征选择方法生成一个特征子空间,在每个子空间上拟合一个模型,并组合它们的预测。
为了方便称呼,我们可以称之为“特征选择子空间集成”。
我们将在本教程中探讨这个想法。
让我们定义一个测试问题作为这次探索的基础,并建立一个性能基线,看看它是否比单个模型提供了优势。
首先,我们可以使用 make_classification() 函数创建一个合成的二元分类问题,包含 1000 个样本和 20 个输入特征,其中五个是冗余的。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 合成分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以建立一个性能基线。我们将为该数据集开发一个决策树,并使用重复分层 k 折交叉验证(重复 3 次,折数 10)对其进行评估。
结果将报告为所有重复和折叠的分类准确率的平均值和标准差。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在分类数据集上评估决策树 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5) # 定义随机子空间集成模型 model = DecisionTreeClassifier() # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告平均和标准差分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到单个决策树模型实现的分类准确率约为 79.4%。我们可以将其作为性能基线,以了解我们的特征选择集成是否能实现更好的性能。
|
1 |
平均准确率:0.794 (0.046) |
接下来,让我们探讨使用不同的特征选择方法作为基础来创建集成。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
单个特征选择方法集成
在本节中,我们将探讨创建基于单个特征选择方法所选特征的集成。
对于给定的特征选择方法,我们将反复应用它并选择不同数量的特征来创建多个特征子空间。然后,我们将分别训练一个模型(在本例中是决策树)并组合它们的预测。
有许多方法可以组合预测,但为了简单起见,我们将使用一个投票集成,它可以配置为分类使用硬投票或软投票,或者回归使用平均。为了使示例简单,我们将专注于分类并使用硬投票,因为决策树不预测校准的概率,因此软投票不太适用。
要了解有关投票集成的更多信息,请参阅教程
投票集成中的每个模型都是一个 Pipeline,其中第一步是配置为选择特定数量特征的特征选择方法,然后是决策树分类器模型。
我们将为输入数据集中的每个列数(从 1 到列总数)创建一个特征选择子空间。这只是为了简单起见而任意选择的,您可能需要尝试不同数量的特征,例如奇数数量的特征,或更复杂的集成方法。
因此,我们可以定义一个名为 get_ensemble() 的辅助函数,该函数为给定的输入特征数创建具有基于特征选择的成员的投票集成。然后,我们可以将此函数用作模板来探索使用不同的特征选择方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = ... # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
鉴于我们正在处理一个分类数据集,我们将探索三种不同的特征选择方法:
- ANOVA F 检验。
- 互信息。
- 递归特征选择。
让我们仔细看看每一个。
ANOVA F 检验集成
ANOVA 是“方差分析”的缩写,是一种参数统计假设检验,用于确定来自两个或多个数据样本(通常是三个或更多)的平均值是否来自同一分布。
F 统计量或 F 检验是一类统计检验,它计算方差值之间的比率,例如两个不同样本的方差,或者统计检验(如 ANOVA)的解释方差与未解释方差。ANOVA 方法是此处称为 ANOVA F 检验的 F 统计量的一种。
scikit-learn 机器学习库通过 f_classif() 函数提供了 ANOVA F 检验的实现。此函数可用于特征选择策略,例如通过 SelectKBest 类选择最重要的 k 个特征(值最大)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = SelectKBest(score_func=f_classif, k=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
将这些结合起来,下面的示例评估了一个投票集成,该集成由在 ANOVA F 检验选择的特征子空间上拟合的模型组成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 使用 anova f 检验选择特征创建集成的示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_classif from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = SelectKBest(score_func=f_classif, k=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5) # 获取集成模型 ensemble = get_ensemble(X.shape[1]) # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告平均和标准差分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能比单个模型(准确率约为 79.4%)有所提升,使用 ANOVA F 检验选择的特征的集成模型的平均准确率提高到约 83.2%。
|
1 |
平均准确率:0.832 (0.043) |
接下来,让我们探讨使用互信息。
互信息集成
来自信息论领域的互信息是信息增益(通常在决策树构建中使用)在特征选择中的应用。
互信息在两个变量之间计算,并衡量在一个变量已知另一个变量的值时,对第一个变量不确定性的减少。当考虑两个离散(分类或有序)变量的分布时,例如分类输入和分类输出数据,这是直接的。尽管如此,它也可以适用于数值输入和分类输出。
scikit-learn 机器学习库通过 mutual_info_classif() 函数提供了互信息在具有数值输入和分类输出变量的特征选择中的实现。与 f_classif() 类似,它可以在 SelectKBest 特征选择策略(和其他策略)中使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = SelectKBest(score_func=mutual_info_classif, k=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
将这些结合起来,下面的示例评估了一个投票集成,该集成由互信息选择的特征子空间上拟合的模型组成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 使用互信息选择特征创建集成的示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = SelectKBest(score_func=mutual_info_classif, k=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5) # 获取集成模型 ensemble = get_ensemble(X.shape[1]) # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告平均和标准差分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到比使用单个模型有所提升,尽管略低于使用 ANOVA F 检验选择的特征子空间,平均准确率为 82.7%。
|
1 |
平均准确率:0.827 (0.048) |
接下来,让我们探讨使用 RFE 选择的子空间。
递归特征选择集成
递归特征消除(简称 RFE)通过从训练数据集中所有特征开始,然后逐步删除特征直到剩余所需数量来搜索特征子集。
这是通过拟合模型核心使用的给定机器学习算法,对特征进行重要性排序,丢弃最重要的特征,然后重新拟合模型来实现的。此过程重复进行,直到剩余指定数量的特征。
有关 RFE 的更多信息,请参阅教程
RFE 方法可通过 scikit-learn 中的 RFE 类获得,并可直接用于特征选择。无需将其与 SelectKBest 类结合使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
将这些结合起来,下面的示例评估了一个投票集成,该集成由 RFE 选择的特征子空间上拟合的模型组成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 使用 RFE 选择特征创建集成的示例 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 RFE from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # 枚举训练数据集中的特征 for i in range(1, n_features+1): # 创建特征选择转换 fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=i) # 创建模型 model = DecisionTreeClassifier() # 创建管道 pipe = Pipeline([('fs',fs), ('m', model)]) # 将其作为元组添加到模型列表中以进行投票 models.append((str(i),pipe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5) # 获取集成模型 ensemble = get_ensemble(X.shape[1]) # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告平均和标准差分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到平均准确率与互信息特征选择相似,得分为约 82.3%。
|
1 |
平均准确率:0.823 (0.045) |
这是一个不错的开始,看看使用数量更少的集成成员(例如,每隔第二个、第三个或第五个选定特征数)是否能获得更好的结果会很有趣。
接下来,让我们看看是否可以通过组合在不同特征选择方法选择的特征子空间上拟合的模型来改进结果。
组合特征选择集成
在前一节中,我们看到通过使用单个特征选择方法作为数据集集成预测的基础,可以提升性能。
我们预计集成中的许多成员之间的预测会相关。这可以通过使用不同数量的选定输入特征作为集成基础,而不是从 1 到列总数的连续数量的特征来解决。
引入多样性的另一种方法是使用不同的特征选择方法选择特征子空间。
我们将探讨此方法的两个版本。对于第一个版本,我们将从每种方法中选择相同数量的特征;对于第二个版本,我们将为多种方法选择从 1 到列总数的连续特征数量。
具有固定特征数的集成
在本节中,我们将首次尝试使用多种特征选择技术选择的特征来构建集成。
我们将从数据集中选择任意数量的特征,然后使用三种特征选择方法中的每一种来选择一个特征子空间,分别拟合一个模型,并将它们作为投票集成的一部分。
下面的 get_ensemble() 函数实现了这一点,它将每种方法选择的指定特征数量作为参数。希望每种方法选择的特征足够不同且足够熟练,从而形成一个有效的集成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # anova fs = SelectKBest(score_func=f_classif, k=n_features) anova = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('anova', anova)) # 互信息 fs = SelectKBest(score_func=mutual_info_classif, k=n_features) mutinfo = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('mutinfo', mutinfo)) # rfe fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=n_features) rfe = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('rfe', rfe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
将这些结合起来,下面的示例评估了一个由使用不同特征选择方法选择的固定数量特征组成的集成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 由不同特征选择方法选择的固定数量特征组成的集成 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 RFE 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.feature_selection import f_classif from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models = list() # anova fs = SelectKBest(score_func=f_classif, k=n_features) anova = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('anova', anova)) # 互信息 fs = SelectKBest(score_func=mutual_info_classif, k=n_features) mutinfo = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('mutinfo', mutinfo)) # rfe fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=n_features) rfe = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('rfe', rfe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # 获取集成模型 ensemble = get_ensemble(15) # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告平均和标准差分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到比上一节中考虑的技术有适度的性能提升,平均分类准确率为 83.9%。
|
1 |
平均准确率:0.839 (0.044) |
更公平的比较可能是将其结果与构成集成的每个单独模型进行比较。
更新后的示例正是进行了这种比较。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# 将固定数量特征的集成与在每个特征集上拟合的单个模型进行比较 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 RFE 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.feature_selection import f_classif from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features): # 定义基础模型 models, names = list(), list() # anova fs = SelectKBest(score_func=f_classif, k=n_features) anova = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('anova', anova)) names.append('anova') # 互信息 fs = SelectKBest(score_func=mutual_info_classif, k=n_features) mutinfo = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('mutinfo', mutinfo)) names.append('mutinfo') # rfe fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=n_features) rfe = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('rfe', rfe)) names.append('rfe') # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') names.append('ensemble') return names, [anova, mutinfo, rfe, ensemble] # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # 获取集成模型 names, models = get_ensemble(15) # 评估每个模型 results = list() for model,name in zip(models,names): # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估数据集上的模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告性能 print('>%s: %.3f (%.3f)' % (name, mean(n_scores), std(n_scores))) results.append(n_scores) # 绘制结果以进行比较 pyplot.boxplot(results, labels=names) pyplot.show() |
运行示例会报告每个在选定特征上拟合的单个模型的平均性能,并以结合了所有三个模型的集成模型性能结束。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,结果表明,在选定特征上拟合的模型的集成比集成中的任何单个模型性能都更好,这符合我们的预期。
|
1 2 3 4 |
>anova: 0.811 (0.048) >mutinfo: 0.807 (0.041) >rfe: 0.825 (0.043) >ensemble: 0.837 (0.040) |
创建了一个图形来显示每组结果的箱线图,从而可以直接比较分布精度得分。
我们可以看到,集成模型的分布都偏向上方,并且具有更高的中位数分类精度(橙色线),这在视觉上证实了这一发现。
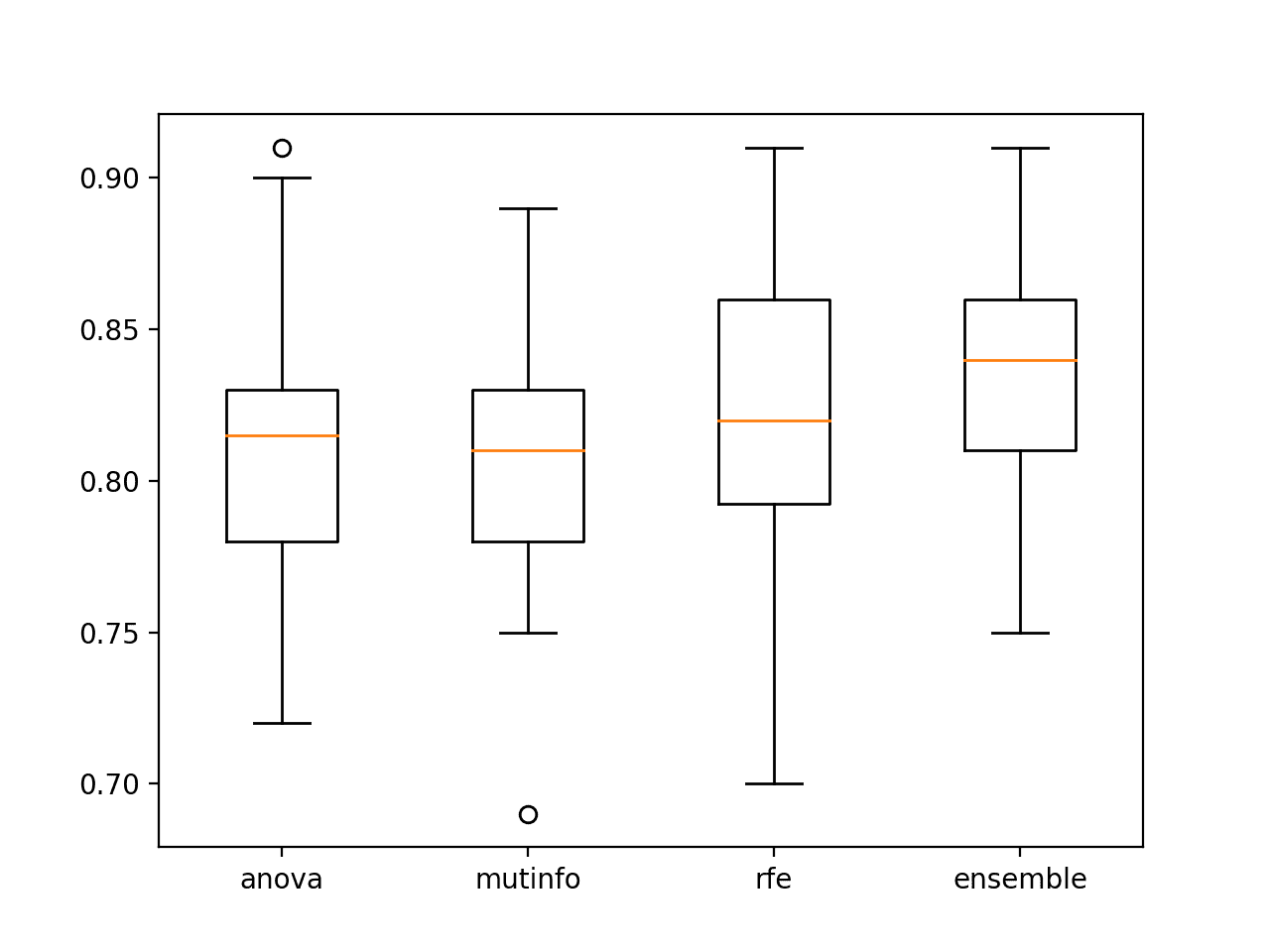
选定特征的单个模型拟合与集成的准确性箱线图
接下来,让我们探索为每种特征选择方法添加多个成员。
具有连续特征数的集成
我们可以将上一节的实验与上述实验结合起来。
具体来说,我们可以使用每种特征选择方法选择多个特征子空间,并在每个子空间上拟合一个模型,然后将所有模型添加到单个集成中。
在这种情况下,我们将选择与上一节相同的子空间,从 1 到数据集的列数,尽管在这种情况下,我们将对每种特征选择方法重复此过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 获取模型投票集成 def get_ensemble(n_features_start, n_features_end): # 定义基础模型 models = list() for i in range(n_features_start, n_features_end+1): # anova fs = SelectKBest(score_func=f_classif, k=i) anova = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('anova'+str(i), anova)) # 互信息 fs = SelectKBest(score_func=mutual_info_classif, k=i) mutinfo = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('mutinfo'+str(i), mutinfo)) # rfe fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=i) rfe = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('rfe'+str(i), rfe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble |
希望跨特征选择方法的选定特征的多样性能够进一步提升集成性能。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# 由多种特征选择方法选定的多个特征子集的集成 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.特征选择 导入 RFE 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import mutual_info_classif from sklearn.feature_selection import f_classif from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import VotingClassifier from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取模型投票集成 def get_ensemble(n_features_start, n_features_end): # 定义基础模型 models = list() for i in range(n_features_start, n_features_end+1): # anova fs = SelectKBest(score_func=f_classif, k=i) anova = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('anova'+str(i), anova)) # 互信息 fs = SelectKBest(score_func=mutual_info_classif, k=i) mutinfo = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('mutinfo'+str(i), mutinfo)) # rfe fs = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=i) rfe = Pipeline([('fs', fs), ('m', DecisionTreeClassifier())]) models.append(('rfe'+str(i), rfe)) # 定义投票集成 ensemble = VotingClassifier(estimators=models, voting='hard') return ensemble # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # 获取集成模型 ensemble = get_ensemble(1, 20) # 定义评估方法 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 在数据集上评估模型 n_scores = cross_val_score(ensemble, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例会报告集成的平均和标准差分类精度。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到如我们所期望的性能有所提升,其中组合的集成模型取得了约 86.0% 的平均分类精度。
|
1 |
平均精度:0.860 (0.036) |
使用特征选择来选择输入特征的子空间可能提供一种有趣的替代方法,或者可能补充随机子空间的选择。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 使用集成方法进行模式分类, 2010.
- 集成方法, 2012.
- 集成机器学习, 2012.
API
- sklearn.feature_selection.f_classif API.
- sklearn.feature_selection.mutual_info_classif API.
- sklearn.feature_selection.SelectKBest API.
- sklearn.feature_selection.RFE API.
文章
总结
在本教程中,您学习了如何使用 Python 开发特征选择子空间集成。
具体来说,你学到了:
- 特征选择为随机子空间选择输入特征组提供了一种替代方法。
- 如何开发和评估由单个特征选择技术选择的特征组成的集成。
- 如何开发和评估由多个不同特征选择技术选择的特征组成的集成。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……

 for Classification in Python")




您好,感谢您的知识。但我有一些问题。您写道
“我们可以看到,集成模型的分布都偏向上方,并且具有更高的中位数分类精度(橙色线),这在视觉上证实了这一发现”。
精度的中位数是什么意思?是针对一种方法通过交叉验证创建的不同子集的准确性中位数吗?在这种情况下如何解释偏度?最佳情况应该是什么样的?
不客气。
中位数是分布的中间值
https://en.wikipedia.org/wiki/Median
它在箱线图上由橙色线表示。
尊敬的Jason博士,
感谢您的教程。
您写道:“结合预测的方法有很多种…”
您能否列出其中一些以及它们在 Python 中的实现?我只找到了并尝试了一种其他方法——StackingClassifier (Regressor)。
是的,我有一些关于这个主题的文章正在计划中。敬请关注。
非常感谢您对这个主题的详细阐述以及代码片段。学到了很多。
不客气。
Jason 博士您好,
感谢您提供的这份实用教程。
我有一个问题。
如何查看集成方法中每个模型选择了哪些特征?
不客气。
如果您愿意,可以单独总结每个模型。您具体遇到了什么问题?
谢谢你。
我的主要问题是:集成方法 (scikit-learn) 中是否有显示每个估计器单独选择的特征的函数,还是应该手动定义此函数?
您可以检查您拟合的模型以找出特征的排名方式,但您为什么需要知道呢?
我想使用不同的模型来获得不同的子集,并通过它们进行投票,然后得到最终的子集。
目标是拥有一个可靠的子集以用于任何机器学习算法。
很有趣,让我知道您的进展。
当然,我会将结果通过电子邮件发送给您。
您好……您是否弄清楚了如何从集成模型中提取特征子集?
我也在研究这种集成特征选择方法,但卡在了提取最终特征子集上。
如果您已成功提取了集成特征,请告诉我您的进展。
谢谢
嗨,Jason!
再次祝贺您的工作,并感谢您的帖子!
我有两个问题
我可以添加更多的分类器模型吗?例如 SVM 和 Random Forest?
我尝试按照您的示例引入卡方检验,如下所示:
fs = SelectKBest (score_func = chi2, k = n_features)
chi2 = Pipeline ([(‘fs’, fs), (‘m’, DecisionTreeClassifier ())))
models.append ((‘chi2’, chi2))
names.append (‘chi2’)
但它给出了以下错误:
UnboundLocalError: local variable ‘chi2’ referenced before assignment
我哪里做错了?我已经声明过了。
谢谢。
您必须先完成所有数据准备,然后让一个模型进行预测。
Jason博士您好,
感谢您提供的所有帖子中的精彩信息。
关于这篇帖子,您能否告诉我如何列出集成中选定的特征名称?
如果您能获得已拟合的特征选择器,fs.get_feature_names_out() 将会打印出名称。
回复
“如果您能获得已拟合的特征选择器,fs.get_feature_names_out() 将会打印出名称。
”
Adrian,有什么方法可以做到吗?我一直不成功 :/
有什么错误消息吗?
NameError: name ‘fs’ is not defined
fs 应该是一个特征选择转换,例如 RFE 对象。
Esther,请提供您收到此错误的确切代码。
此致,
由于它产生了最高的准确性 (86%),我想获取该集成所选特征的列表,用于本教程“具有连续特征数的集成”部分下的代码。我只是不知道在哪里将行“fs.get_feature_names_out()”插入代码块。
在 for 循环的末尾。get_feature_names_out() 是 RFE 的一个成员函数:https://scikit-learn.cn/stable/modules/generated/sklearn.feature_selection.RFE.html
尊敬的 Brownlee 博士。
首先,感谢您撰写这篇关于特征选择集成的精彩文章。
我非常感谢您关于机器学习的所有内容。
我有一个关于特征选择方法的问题。是否可以聚合特征选择方法?
例如,假设我有近 300 个特征。我能否使用带有 f_classify 的 selecKBest 模型来选择 100 个最佳特征,然后使用 SequentialFeatureSelection 从这 100 个特征中选择 10 个最佳特征?您对此方法有何看法?
再次祝贺您的帖子,并感谢您的帮助。
诚挚地,Felipe。
Felipe,您太客气了!您的建议没有任何问题。请继续尝试,并将您的发现告诉我们。