使用机器学习方法对时间序列数据进行预测需要进行特征工程。
单变量时间序列数据集仅包含一系列观测值。为了使用监督学习算法,这些观测值必须被转换为输入和输出特征。
问题在于,对于时间序列问题,您可以构建的特征类型和数量几乎没有限制。诸如相关图之类的经典时间序列分析工具可以帮助评估滞后变量,但在选择其他类型的特征(例如从时间戳(年、月或日)派生的特征以及移动统计量,如移动平均)时,它们则不直接提供帮助。
在本教程中,您将学习如何在处理时间序列数据时使用机器学习工具中的特征重要性和特征选择。
完成本教程后,您将了解:
- 如何创建和解释滞后观测值的相关图。
- 如何计算和解释时间序列特征的特征重要性得分。
- 如何对时间序列输入变量执行特征选择。
通过我的新书开始您的项目《Python时间序列预测》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 更新于2019年6月:已修复缩进。
- 2019年8月更新:更新了数据加载以使用新的API。
- 更新于2020年9月:已更新代码以匹配API的更改。
教程概述
本教程分为以下5个步骤
- 月度汽车销售数据集:介绍我们将要使用的数据集。
- 使数据平稳:介绍如何使数据集平稳以进行分析和预测。
- 自相关图:介绍如何创建时间序列数据的相关图。
- 滞后变量的特征重要性:介绍如何计算和查看时间序列数据的特征重要性得分。
- 滞后变量的特征选择:介绍如何计算和查看时间序列数据的特征选择结果。
让我们从查看标准的时间序列数据集开始。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
月度汽车销售数据集
在本教程中,我们将使用月度汽车销售数据集。
该数据集描述了1960年至1968年间加拿大魁北克省的汽车销售数量。
单位是销售数量的计数,共有108个观测值。原始数据归功于Abraham和Ledolter(1983)。
下载数据集并将其保存到当前工作目录,文件名为“car-sales.csv”。请注意,您可能需要从文件中删除页脚信息。
以下代码将数据集加载为Pandas的Series对象。
|
1 2 3 4 5 6 7 8 9 10 |
# 时间序列的折线图 from pandas import read_csv from matplotlib import pyplot # 加载数据集 series = read_csv('car-sales.csv', header=0, index_col=0) # 显示前几行 print(series.head(5)) # 数据集的折线图 series.plot() pyplot.show() |
运行示例将打印数据的前5行。
|
1 2 3 4 5 6 7 |
月份 1960-01-01 6550 1960-02-01 8728 1960-03-01 12026 1960-04-01 14395 1960-05-01 14587 Name: Sales, dtype: int64 |
还提供了数据的折线图。
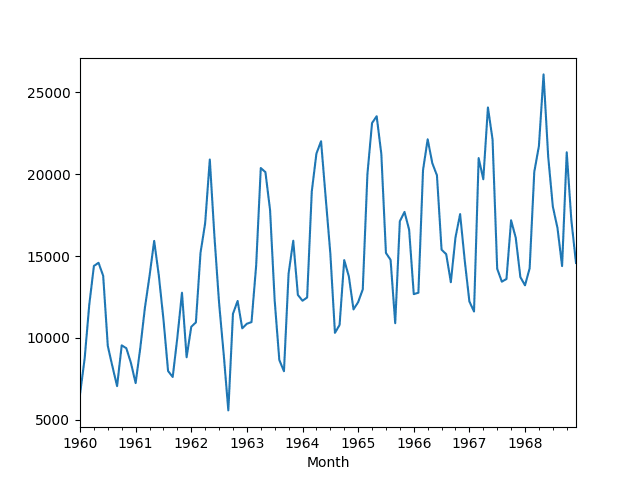
月度汽车销售数据集折线图
使数据平稳
我们可以看到数据中存在明显的季节性和上升趋势。
趋势和季节性是固定分量,可以添加到我们的任何预测中。它们很有用,但需要被移除,以便探索任何其他可以帮助进行预测的系统信号。
具有季节性和趋势被移除的时间序列称为平稳时间序列。
为了移除季节性,我们可以进行季节性差分,从而得到一个所谓的季节性调整后的时间序列。
季节性的周期似乎是一年(12个月)。下面的代码计算季节性调整后的时间序列,并将其保存到文件“seasonally-adjusted.csv”。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 对时间序列进行季节性调整 from pandas import read_csv from matplotlib import pyplot # 加载数据集 series = read_csv('car-sales.csv', header=0, index_col=0) # 季节性差分 differenced = series.diff(12) # 去除第一年的空数据 differenced = differenced[12:] # 将差分后的数据集保存到文件 differenced.to_csv('seasonally_adjusted.csv', index=False) # 绘制差分后的数据集 differenced.plot() pyplot.show() |
由于前12个月的数据没有先前的数据进行差分,因此必须将其丢弃。
平稳数据存储在“seasonally-adjusted.csv”中。创建了差分数据的折线图。
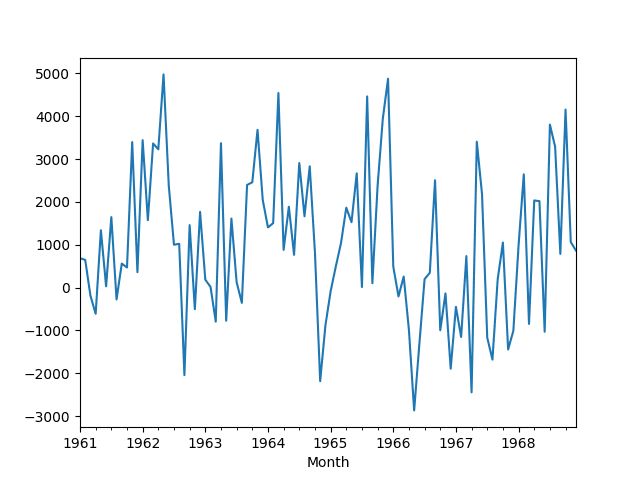
季节性差分的月度汽车销售数据集折线图
该图表明季节性和趋势信息已通过差分去除。
自相关图
传统上,时间序列特征是根据其与输出变量的相关性来选择的。
这被称为自相关,并且涉及绘制自相关图,也称为相关图。这些图显示了每个滞后观测值的相关性以及相关性是否在统计学上显著。
例如,以下代码绘制了月度汽车销售数据集中所有滞后变量的相关图。
|
1 2 3 4 5 6 |
from pandas import read_csv from statsmodels.graphics.tsaplots import plot_acf from matplotlib import pyplot series = read_csv('seasonally_adjusted.csv', header=0) plot_acf(series) pyplot.show() |
运行示例将创建数据的相关图,或自相关函数(ACF)图。
该图显示x轴上的滞后值,y轴上的相关性介于-1和1之间,分别表示负相关和正相关的滞后。
0滞后值处的1的相关性表明观测值与其自身之间有100%的正相关。
该图显示在1、2、12和17个月的滞后值处存在显著的相关性。
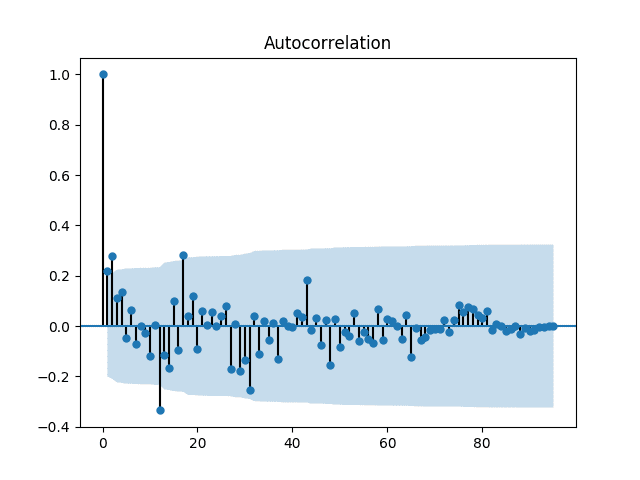
月度汽车销售数据集的相关图
此分析提供了良好的基线进行比较。
时间序列到监督学习
我们可以通过将滞后观测值(例如t-1)作为输入,并将当前观测值(t)作为输出变量,将单变量月度汽车销售数据集转换为监督学习问题。
我们可以在Pandas中使用shift函数创建移位观测值的新列来执行此操作。
下面的示例创建了一个包含12个月滞后值的新时间序列,以预测当前观测值。
12个月的移位意味着前12行数据无法使用,因为它们包含NaN值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import DataFrame # 加载数据集 series = read_csv('seasonally_adjusted.csv', header=0) # 重构为监督学习 dataframe = DataFrame() for i in range(12,0,-1): dataframe['t-'+str(i)] = series.shift(i).values[:,0] dataframe['t'] = series.values[:,0] print(dataframe.head(13)) dataframe = dataframe[13:] # 保存到新文件 dataframe.to_csv('lags_12months_features.csv', index=False) |
运行示例将打印前13行数据,显示无法使用的前12行和可用的第13行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
t-12 t-11 t-10 t-9 t-8 t-7 t-6 t-5 \ 1961-01-01 NaN NaN NaN NaN NaN NaN NaN NaN 1961-02-01 NaN NaN NaN NaN NaN NaN NaN NaN 1961-03-01 NaN NaN NaN NaN NaN NaN NaN NaN 1961-04-01 NaN NaN NaN NaN NaN NaN NaN NaN 1961-05-01 NaN NaN NaN NaN NaN NaN NaN NaN 1961-06-01 NaN NaN NaN NaN NaN NaN NaN 687.0 1961-07-01 NaN NaN NaN NaN NaN NaN 687.0 646.0 1961-08-01 NaN NaN NaN NaN NaN 687.0 646.0 -189.0 1961-09-01 NaN NaN NaN NaN 687.0 646.0 -189.0 -611.0 1961-10-01 NaN NaN NaN 687.0 646.0 -189.0 -611.0 1339.0 1961-11-01 NaN NaN 687.0 646.0 -189.0 -611.0 1339.0 30.0 1961-12-01 NaN 687.0 646.0 -189.0 -611.0 1339.0 30.0 1645.0 1962-01-01 687.0 646.0 -189.0 -611.0 1339.0 30.0 1645.0 -276.0 t-4 t-3 t-2 t-1 t 1961-01-01 NaN NaN NaN NaN 687.0 1961-02-01 NaN NaN NaN 687.0 646.0 1961-03-01 NaN NaN 687.0 646.0 -189.0 1961-04-01 NaN 687.0 646.0 -189.0 -611.0 1961-05-01 687.0 646.0 -189.0 -611.0 1339.0 1961-06-01 646.0 -189.0 -611.0 1339.0 30.0 1961-07-01 -189.0 -611.0 1339.0 30.0 1645.0 1961-08-01 -611.0 1339.0 30.0 1645.0 -276.0 1961-09-01 1339.0 30.0 1645.0 -276.0 561.0 1961-10-01 30.0 1645.0 -276.0 561.0 470.0 1961-11-01 1645.0 -276.0 561.0 470.0 3395.0 1961-12-01 -276.0 561.0 470.0 3395.0 360.0 1962-01-01 561.0 470.0 3395.0 360.0 3440.0 |
新数据集的前12行被移除,结果保存在文件“lags_12months_features.csv”中。
此过程可以重复使用任意数量的时间步,例如6个月或24个月,我建议进行尝试。
滞后变量的特征重要性
诸如装袋树、随机森林和极端树之类的决策树集成可以用来计算特征重要性得分。
这在机器学习中很常见,用于在开发预测模型时估计输入特征的相对有用性。
我们可以利用特征重要性来帮助估计为时间序列预测而构造的输入特征的相对重要性。
这一点很重要,因为我们不仅可以构造上面的滞后观测值特征,还可以基于观测值的时间戳、滚动统计量等创建特征。特征重要性是帮助我们区分在建模中有用的方法之一。
下面的示例加载了上一节创建的数据集的监督学习视图,拟合了随机森林模型(RandomForestRegressor),并总结了每个12个滞后观测值的相对特征重要性得分。
使用一个较大的树的数量是为了确保得分在一定程度上稳定。此外,初始化随机数种子以确保每次运行代码都能获得相同的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from pandas import read_csv from sklearn.ensemble import RandomForestRegressor from matplotlib import pyplot # 加载数据 dataframe = read_csv('lags_12months_features.csv', header=0) array = dataframe.values # 分割为输入和输出 X = array[:,0:-1] y = array[:,-1] # 拟合随机森林模型 model = RandomForestRegressor(n_estimators=500, random_state=1) model.fit(X, y) # 显示重要性得分 打印(模型.feature_importances_) # 绘制重要性得分 names = dataframe.columns.values[0:-1] ticks = [i for i in range(len(names))] pyplot.bar(ticks, model.feature_importances_) pyplot.xticks(ticks, names) pyplot.show() |
运行示例首先打印滞后观测值的重要性得分。
|
1 2 |
[ 0.21642244 0.06271259 0.05662302 0.05543768 0.07155573 0.08478599 0.07699371 0.05366735 0.1033234 0.04897883 0.1066669 0.06283236] |
然后将得分绘制成条形图。
该图显示了t-12观测值的高相对重要性,以及t-2和t-4观测值在一定程度上的重要性。
有趣的是,这与前面相关图的结果有所不同。
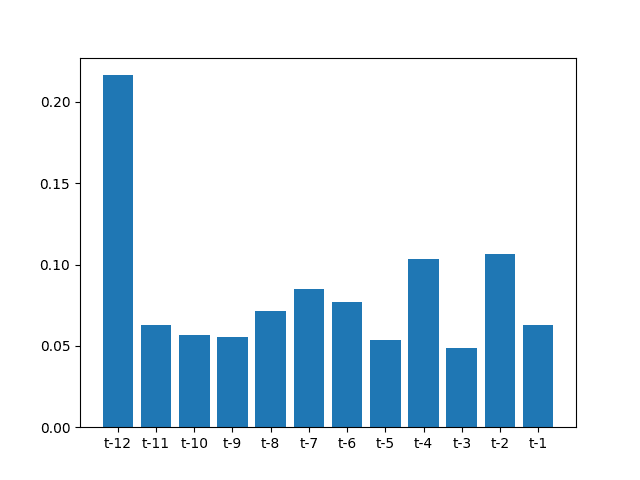
月度汽车销售数据集特征重要性得分条形图
此过程可以重复使用可以计算重要性得分的不同方法,例如梯度提升、极端树和装袋决策树。
滞后变量的特征选择
我们还可以使用特征选择来自动识别和选择最具预测性的输入特征。
一种流行的特征选择方法称为递归特征选择(RFE)。
RFE通过创建预测模型、加权特征和修剪权重最小的特征来工作,然后重复此过程,直到剩下所需数量的特征。
下面的示例使用RFE和随机森林预测模型,并将所需的输入特征数量设置为4。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from pandas import read_csv 从 sklearn.特征选择 导入 RFE from sklearn.ensemble import RandomForestRegressor from matplotlib import pyplot # 加载数据集 dataframe = read_csv('lags_12months_features.csv', header=0) # 分离输入和输出变量 array = dataframe.values X = array[:,0:-1] y = array[:,-1] # 执行特征选择 rfe = RFE(RandomForestRegressor(n_estimators=500, random_state=1), n_features_to_select=4) fit = rfe.fit(X, y) # 报告选定的特征 print('Selected Features:') names = dataframe.columns.values[0:-1] for i in range(len(fit.support_)): if fit.support_[i]: print(names[i]) # 绘制特征排名 names = dataframe.columns.values[0:-1] ticks = [i for i in range(len(names))] pyplot.bar(ticks, fit.ranking_) pyplot.xticks(ticks, names) pyplot.show() |
运行示例将打印出4个选定特征的名称。
毫不意外,结果与上一节中显示高重要性的特征相匹配。
|
1 2 3 4 5 |
选定的特征 t-12 t-6 t-4 t-2 |
此外,还会创建一个条形图,显示每个输入特征的特征选择排名(数字越小越好)。
月度汽车销售数据集特征选择排名条形图
此过程可以重复使用不同数量的特征来选择多于4个特征,并使用随机森林以外的不同模型。
总结
在本教程中,您了解了如何使用应用机器学习的工具来帮助在预测时从时间序列数据中选择特征。
具体来说,你学到了:
- 如何解释高度相关的滞后观测值的相关图。
- 如何计算和查看时间序列数据中的特征重要性得分。
- 如何使用特征选择来识别时间序列数据中最相关的输入变量。
您对时间序列数据特征选择有任何疑问吗?
在评论中提出您的问题,我将尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






Jason你好,非常喜欢你的博客!我想问一下您是否会出一个关于多元数组时间序列预测的系列?
非常感谢,
祝好,
安德鲁
是的,我希望很快能涵盖这个话题,Andrew。
请问您是否已经完成了?多元时间序列预测的特征选择
抱歉,我没有关于此主题的教程。
你好 Jason,
非常感谢这篇博文。我将非常期待看到多元时间序列预测是如何处理的。
继续保持好工作,
此致
Ben
谢谢Ben,我希望很快能涵盖多元时间序列。
你好,工作很棒,期待这个……你估计什么时候能完成?
是的,我这里有很多例子
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好 Jason,
我一直想知道你为什么选择只保留最后12个滞后用于特征重要性和特征选择研究。
因为我理解相关图表明您应该将研究推到第17个滞后(相关图显示1、2、12和17个滞后与当前状态相关)
我理解得对吗?
感谢您的辛勤工作!
是的,我把它写得很简洁。
这些行的输出
‘plot_acf(series)’
‘pyplot.show()’
与您的不一样。它只显示一条直线。
您可以检查一下吗?
谢谢
是的,plot_acf函数不起作用。
您具体遇到了什么问题?
您正在使用哪个版本的statsmodels?
我可以确认这个例子,请检查您是否拥有所有代码和相同的源数据。
我遇到了类似的问题。这是由于页脚,如果您在导入数据后不删除它或删除Series中的最后一行。
你好,Jason!
您能推荐一些关于递归特征选择和随机森林在时间序列特征选择方面的参考资料吗?
谢谢!
没有。我最好的建议是:尝试一下,获得结果,并利用它们来开发更好的模型。
嗨,Jason!
我仍然无法理解滞后变量的重要性?
滞后是应用于特征变量以查找与目标变量的相关性吗?
谢谢!
滞后是过去的观测值,是在先前时间点的观测值。
我们可以将它们用作学习模型的输入特征。因此,从抽象上讲,我们可以根据昨天发生的事情来预测今天。
昨天的观测值是滞后变量。
这有帮助吗?
亲爱的 Jason,
我正在尝试使用 X 尺寸为 (358,168) 和测试 y (358,24) 的代码,出现错误“ValueError: bad input shape (358, 24)”。我想从 X(358,168) 的 168 个特征中找出与 y(358,24) 的 24 个输出最相关的 12 个特征。
我的 y 矩阵有 24 个输出而不是 1 个。这可能是什么原因导致的错误?
X = array[:,0:168]
y = array[:,168:192]
rfe = RFE(RandomForestRegressor(n_estimators=500, random_state=1), 12)
fit = rfe.fit(X, y)
这可能输出变量太多了,大多数算法在 scikit-learn 中都期望单个输出变量。
我不知道有任何支持多个变量的,但我可能错了。
您或许可以考虑使用神经网络模型?
感谢您的评论,Jason。
实际上,我想做的是用 RFE 来确定最相关的特征,然后用这些特征来训练神经网络模型。您认为这是一个合理的方法吗?
对于多输出错误,我将为每个输出运行 RFE,而不是一次运行 24 个。
您可以尝试一下,如果有一个高度预测性的特征,那会很有意义,但我鼓励您测试多种配置。
感谢这篇很棒的教程。
我想知道您能否解释一下为什么 ACF 可能显示某些滞后具有统计学意义,而特征选择可能显示完全不同的滞后具有预测能力。
它们遵循不同的假设,并因此产生不同的结果。这是可以预期的。
你好,杰森,
谢谢你的帖子,我很喜欢!
我对此有点困惑
“这一点很重要,因为我们不仅可以构造上述滞后观测特征,还可以构造基于观测时间戳、滚动统计和其他许多特征。”
如果我已经移除了时间序列的季节性,添加“月份”到特征集 (“X”) 中有意义吗?另外,关于“其他许多”部分,如果我向 “X” 添加额外特征,平稳性是否仍然有意义?
如果没问题,为什么我们一开始就需要数据是平稳的?
如果有问题,我们如何确保在添加额外特征到 “X” 后数据仍然是平稳的?
是的,但您也可以探索非线性方法,它们在平稳性要求方面提供了更大的灵活性。
很棒的教程!我对时间序列数据有中等经验。我正在为一个二元分类任务检测时间序列金融数据最重要的特征。我大约有 400 个特征(在使数据平稳后,其中许多特征高度相关)。我该如何应用您上面展示的方法?获取例如每个特征的前 10 天?或者您有什么其他建议?
提前感谢!
我建议探索一套方法,看看哪些特征能带来最好的模型技能。
嗨,Jason,
这太棒了!如何使用 LSTM/keras 进行时间序列特征选择?在这种情况下,就不需要将时间序列分解成从 t 到 t-12 的不同滞后变量了。
我目前正在处理一个具有多个预测变量的时间序列问题。我需要知道哪些预测变量是重要的。这个过程是否与您在这里做的一样,还是我可以使用随机森林的特征重要性?
谢谢!
好问题。
可能有专门的方法,但我目前不了解——也许可以做一些研究。
我建议尝试网格搜索模型在不同的特征子集上,看看什么重要/能带来更好的模型技能。基本上就是 RFE 方法。
嗨,Jason,
我假设我们可以将此特征重要性和选择扩展到滞后变量之外
–“时间/季节性特征”,例如一天的小时、一年的月份等
– 取决于问题的外部变量
– 滚动特征,例如过去 n 天内温度值的最小值、最大值和平均值
基本上是您在下面链接中提供的特征,然后我们可以进行特征重要性和选择,您同意吗?
https://machinelearning.org.cn/basic-feature-engineering-time-series-data-python/
当然。我没有太多关于多元时间序列的资料,希望将来能涵盖更多。
我理解得对吗,特征选择/重要性/等过程发生在将模型拟合到训练数据之后?
在拟合模型之前应选择特征。
但请注意,整个过程是迭代的。会多次回到之前的步骤。
您的训练数据中的观测值不是 iid 的。您认为这对您的模型没问题吗?
使序列平稳可以消除时间依赖性。
RandomForestRegressor 使用 bootstrap。考虑到这是一个时间序列的示例,这是否会造成数据泄露?
怎么会呢?
这是一个更好的解释
https://stats.stackexchange.com/questions/25706/how-do-you-do-bootstrapping-with-time-series-data
嗨,Jason
我正在使用 RandomForest 对降雨变量进行预测。我有大约 15 个预测变量和 50 年的数据。当我根据预测变量(变量)预测降雨量时,我得到的值非常低,与原始降雨量相比。我的意思是,我完全错过了极端值。请建议。
此致,
Vishu
我在这里有一些建议
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
嗨,Jason,
感谢您的博客。我从您那里学到了很多。
我正在寻找一种用于时间序列的变量选择方法,如 RFE。但在阅读了这篇新帖子(https://machinelearning.org.cn/how-to-predict-whether-eyes-are-open-or-closed-using-brain-waves/)后,我怀疑是否可以使用一种使用 bootstrap 的方法。
我认为在使用 RFE 时,模型评估并未遵循观测值的时间顺序,这与您关于如何预测睁眼或闭眼的帖子中发生的情况相同,该帖子使用了未来信息来进行变量选择。您怎么看?谢谢!!
此致
这是一个挑战。您可以尝试经典的特征选择方法,如 RFE 和相关性,但要认识到存在偏差,然后根据建议构建模型,并将其性能与使用所有特征进行比较。
嗨,Jason,
非常感谢这篇博客。
我在 Sklearn 中使用简单线性回归。
我收到此错误(无法转换为浮点数:‘(TOP (S (S (NP *’)
我认为有必要对分类数据进行编码!
但是,我的数据集是用于自然语言处理的(来自 conll-2012 的数据)。
我可以使用另一个接受字符串变量的算法,或者有其他解决方案吗?
我在这里解释了如何处理文本数据。
https://machinelearning.org.cn/start-here/#nlp
谢谢 🙂
嗨,Jason,
感谢您的精彩教程。
不幸的是,我在运行代码时遇到了问题。我的电脑上代码的结果与您的相同,直到自相关图。在自相关图上,我的结果只显示一条零的直线。
接下来,出现以下错误。
runfile(‘C:/Users/Hossein/.spyder-py3/temp.py’, wdir=’C:/Users/Hossein/.spyder-py3′)
回溯(最近一次调用)
File “C:\Users\Hossein\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py”, line 2862, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File “”, line 1, in
runfile(‘C:/Users/Hossein/.spyder-py3/temp.py’, wdir=’C:/Users/Hossein/.spyder-py3′)
File “C:\Users\Hossein\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 705, in runfile
execfile(filename, namespace)
File “C:\Users\Hossein\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 102, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File “C:/Users/Hossein/.spyder-py3/temp.py”, line 48
dataframe[‘t-‘+str(i)] = series.shift(i)
^
IndentationError: 期望一个缩进块
看起来您没有复制带有缩进的代码,这里是如何复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
另外,我建议从命令行运行代码。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
感谢您的及时回复。
不幸的是,我仍然遇到同样的问题。我甚至在 https://repl.it 上尝试了您的代码,它显示了相同的错误。
dataframe[‘t-‘+str(i)] = series.shift(i)
^
IndentationError: 期望一个缩进块
也许可以再次尝试复制粘贴代码,并在您的文本编辑器中手动缩进?
在我看来,您自己粘贴代码时没有正确缩进,因为框中没有显示任何缩进(也可能是网站或浏览器的问题,您在代码框中看到任何缩进吗?)。
感谢您的教程,内容很棒。
您说得对,我已经为示例添加了缩进。
对此我很抱歉。
我终于找到了。
自相关图不显示,因为系列末尾有两个“nan”。
在读取以下行后添加“series=series[1:-2]”。
series = Series.from_csv(‘seasonally_adjusted.csv’, header=None)
关于时间序列到监督学习的另一个错误评论。
代码在“for”循环之后需要一个空格,如下所示:
for i in range(12,0,-1)
dataframe[‘t-‘+str(i)] = series.shift(i)
代码不起作用。在您创建带有移位列的 DataFrame 时,我遇到了值长度与索引长度不匹配的问题。我不知道您是如何用这些代码产生结果的。
很抱歉听到这个消息,我在这里为您提供一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
我有点难以理解特征重要性和选择结果。特别是,为什么在差分步骤中移除了 12 个月的季节性后,滞后 t-12 在预测时间序列方面仍然有如此大的影响?
也许季节性校正并未完全去除所有的季节性结构。
你好 Jason,
谢谢你的文章!
我的时间序列是每天的数据,持续 4 年零 10 个月。
我实际上正在为我的时间序列数据实现 SARIMAX,并且我包含了几个外生变量。
我实际上对您上面解释的外生变量和 10 个滞后进行了特征选择。
我在我的外生变量中包含了我的时间序列年平均值(即 364 个值,每个值代表 4 年的平均值)。
上述特征选择方法给出了 0.9 的平均值重要性,而其他外生变量和滞后值非常低。另一方面,我实现的 SARIMAX 也未能提高我的 RMSE(相对于将预测值设为平均值的 RMSE)。
所以总结一下,我的模型比平均值好不了多少。您认为我应该怎么做?
谢谢!
我建议只包含外生变量,前提是它们能提高模型的技能。
您好 Jason,感谢这篇有用的文章!是否有解释如何从多元时间序列预测中选择特征的教程?
我没有关于此主题的教程。
您好 Jason,好文章!
我想问一个关于使用 Arima 或 Arimax 等时间序列模型的一般问题。当我们对时间序列数据进行一阶或二阶差分以去除趋势和季节性时,我们是否必须在模型中传递趋势或季节性阶数,例如 arimax ( ts, order= (p,d,q) , seasoanlity= c(P,D,Q) )?或者如果我们传递(趋势和季节性)阶数,是否就不需要对输入时间序列进行差分?
如果您使用的是 ARIMA 或 SARIMA 模型,您可以使用适当的阶数参数让模型自行进行差分。
你好。Jason
复制并执行了相同的代码,但出现了一个错误。我该如何处理?
我的错误:输入包含 NaN、无穷大或对于 dtype(‘float32’) 过大的值。
听到这个消息我很难过,我这里有一些建议可能有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好,Jason。
您的博客给了我很大的帮助。
我有一个关于特征选择的问题。
如果我想将选定的滞后变量用作 LSTM 模型的输入变量,我该怎么做?
我真的很想知道如何使用选定的特征进行 LSTM。
我将等待回复。
谢谢!
您可以使用它们,我不确定我是否理解您遇到的问题?
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
谢谢你的回复。
根据上面的结果,选择了 t-12、t-6、t-4、t-2 作为变量。
那么,这 4 个特征应该用作 LSTM 模型中的变量,对吗?
还是您是指,当使用“series_to_supervised”函数制作数据集时,我应该将数字(12 或 6 或 4 或 2)输入到“n-in”和“n-out”因子中?
或者我只是将变量“t-12”、“t-6”、“t-4”、“t-2”输入模型?
我不明白如何将选定的特征用作变量。
谢谢你。
我明白了。通常我们不会选择滞后观测值作为 LSTM 的时间步长,而是提供所有时间步长,并让 LSTM 学习使用什么来做出良好的预测。
哦,我明白了。
那么……我们为什么选择特征?
特征选择的目的是什么?
您的意思是,如果我使用 LSTM 模型,就不一定需要选定的特征了?
我非常感谢您的建议。
对于线性模型以及开发静态机器学习模型(非 LSTM)来说,这可能很有用。
您好 Jason,感谢您的精彩文章。您能否给我们一个如何用多元时间序列做同样的事情?为 n 个特征循环上面的代码有帮助吗?
感谢您的建议。
抱歉,我没有关于此主题的多元时间序列特征选择的示例。
a) 所以如果我们想使用
t-12
t-6
t-4
t-2 作为特征,那么我们应该使用以下方法:
model=ARIMA(endog=y(t),exog=[y(t-12),y(t-6),y(t-4),y(t-2)])
b) 如果我们想使用 (t-2)、(t-1) 作为特征,那么 model_1、model_2 会得到相同的结果吗?
model_1=ARIMA(endog=y(t),exog=[y(t-1),y(t-2)])
model_1=ARIMA(endog=y(t),order=(2,0,0))
感谢分享。我们如何对特征重要性进行排序并显示重要比例?
当然可以。
亲爱的Jason
我发现您的许多文章和营地都令人鼓舞。
我想知道——在处理多元随机森林时间序列预测时——例如,我想使用每个预测变量的 12 个滞后值和输出变量的滞后值作为我模型的输入变量来预测结果。在训练我的模型后,我应该进行特征选择——这里我的想法是使用随机森林预测的变量重要性图/表(值为 %IncMSE)来选择最重要的变量。但我的问题是
我是否可以仅选择预测变量 x1 的滞后 2 和 5,以及 x2 的滞后 1、2 和 10,而不是每个变量的全部滞后序列?
希望我的问题有意义,您有时间回答我。
包含所有滞后观测值,让随机森林决定使用哪些以及忽略哪些,可能会更容易。
好的,非常感谢——您知道关于这个决定/权衡的好文献吗?
不一定,我建议运行实验并比较结果。一篇论文不会告诉你这样做。
亲爱的
那么在这种情况下,您是否只包含 t-12、t-6、t-4 和 t-2 作为预测变量,而不包含从 t-1 到 t-12 的所有滞后值?在您发布的一些其他文章中,我理解最佳做法是包含所有滞后值,然后让随机森林函数决定使用哪些以及不使用哪些?或者您指的是 RFE 吗?
您有此 R 代码的链接吗?
谢谢
通常,我建议将滞后值包含在高级模型中,并让它选择有用的值。
R 代码请参见此处
https://machinelearning.org.cn/books-on-time-series-forecasting-with-r/
是的,好的——谢谢您
当您说高级随机森林模型时,是指链接中“扩展 caret”子标题下的模型吗?您在训练之后进行随机森林预测?
https://machinelearning.org.cn/tune-machine-learning-algorithms-in-r/
这篇帖子展示了随机森林如何从头开始工作
https://machinelearning.org.cn/implement-random-forest-scratch-python/
你好,Jason。
这篇文章对我有很大帮助。这是一篇很棒的文章。但是,当我尝试在“时间序列到监督学习”部分进行移位时,我遇到了“无法设置没有定义索引的框架以及无法转换为 Series 的值”。我对 Python 很陌生,希望您能澄清这一点并帮助我。谢谢!
很抱歉听到这个消息,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
是的,我做的一切都是正确的,但我仍然得到同样的错误!希望尽快收到您的回复!
ValueError: Cannot set a frame with no defined index and a value that cannot be converted to a Series
谢谢,我已经更新了 API 更改的示例。
告诉我进展如何。
非常感谢!现在运行正常了!
不客气,感谢您的耐心!
嗨,杰森,
您能帮我看看如何使用此模型预测下个月的值吗?因为该模型是在滞后特征上训练的。
先谢谢了
调用 predict() 函数即可进行预测
https://machinelearning.org.cn/make-predictions-scikit-learn/
您好,我刚开始接触机器学习,并且正在处理一个预测问题。作为特征,我使用了滞后(1-7)和一个 isweekend 特征。管理团队对机器学习的专业知识不多,所以他们问我为什么只使用最近 7 天来预测,而不是使用过去所有的数据来预测?请帮助我理解这一点并尽快给我答复。
这是一个好问题。
我建议测试不同数量的历史数据,以找出最适合您特定数据集和模型的方法。
嗨,Jason,
感谢您的帖子。关于 RFE。
由于要保留的特征数量并非总是可以提前知道,那么使用 GridSearchCv 并为特征数量设置一个值列表,以便根据评分进行优化,是否有意义?
另外,如果数据集不平衡,您是否知道 RFE 可以稍微纠正随机森林在处理不平衡数据集时的困难(偏差)吗?
谢谢
Luigi
不客气。
是的。或者直接使用 rfecv。
只要您使用适当的指标来选择特征,RFE 就没问题。
Jason,感谢您出色的工作,
我有一个问题想问您,如果您能回答我,我将非常感激。
我有多元时间序列数据,其中包含咖啡价格和茶价格,频率为每周,并且我添加了每个变量的滞后版本。在根据您为滞后变量进行的特征选择步骤后,我发现与咖啡最相关的滞后特征是 coffee_t_1、coffee_t_2、coffee_t_3 和 coffee_t_4,与茶相关的滞后特征是 tea_t_1、tea_t_2 以及一些 date_time 特征。
在下一步中,我想通过随机森林来预测未来几周的咖啡价格。我计划输入特征 coffee_t_1、coffee_t_2、coffee_t_3、coffee_t_4、tea、tea_t_1、tea_t_2。这种方法是否适用于时间序列预测?输入滞后特征变量进行预测是否算作一种作弊?
谢谢
Deniz
不客气。
只要模型输入只包含预测时可用的数据(不包含未来的数据),它就应该是可以的。
不明白为什么滞后值 1 的特征重要性这么低。
计算结果就是如此。它特定于此输入数据。
您好,一如既往地感谢您提供的精彩教程。在时间序列转换为监督学习之后,ARMAX 是否适用?我们可以将 (T – X) 特征视为外生变量吗?或者在数据从单变量转换为监督学习后,您也可以只使用线性回归吗?
Charles,我建议您从 ARIMA 模型及其变体开始。如果这些模型满足您的性能标准,您可能不需要转向 CNN 和 LSTM 等深度学习模型,但如果您有时间,尝试这些模型类型进行比较也是有益的。
尊敬的 Jason Brownlee 先生,感谢您的文章。它非常鼓舞人心…
但我一直在想,是否有办法选择特征的最佳滞后值?我的意思是,哪个滞后值与目标“相关性最高”,或者对理解目标变化具有最大的预测能力(正如《经济学家》曾经称之为“领先指标”)。还是我们必须手动创建所有我们认为有意义的滞后特征,然后分析滞后特征 x 目标散点图,对于合理数量的滞后值,甚至绘制相关的滞后特征 x(无滞后)目标的 ACF/PACF 类图形?
我拒绝相信只有领域专家才能凭其自身经验指出每个特征的最佳滞后值,以用作“预测性”新特征。
提前感谢
Carlos Abdalad
Carlos,我建议您研究一下贝叶斯优化。
https://machinelearning.org.cn/what-is-bayesian-optimization/
您好,感谢您提供的精彩教程。
我的方程如下:(结合了多元时间序列和横截面数据)
Yt=Xq +X (p(t-1)) + Y(t-1)
描述
Yt= (X1+X2+X3+⋯)+ ((X(1(t-1) )+X(1(t-2) )+X(1(t-3)+..) )+(X(2(t-1) )+X(2(t-2) )+X(2(t-3)+..) )+⋯)+ (Y(t-1)+Y(t-2)+..)
现在我有 2 个问题
在特征选择讨论中,我们可以使用 Lasso 或 Ridge 吗?如果不行,在这个方程中我们可以用哪个模型代替 Lasso 或 Ridge?
在预测讨论中,我们可以为这个方程使用什么算法和模型?
非常感谢
Vahid,以下内容可能对您有帮助
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/