特征选择是在开发预测模型时减少输入变量数量的过程。
为了降低建模的计算成本,并在某些情况下提高模型的性能,减少输入变量的数量是可取的。
基于统计的特征选择方法涉及使用统计数据评估每个输入变量与目标变量之间的关系,并选择与目标变量关系最强的那些输入变量。这些方法可能快速而有效,尽管统计度量的选择取决于输入和输出变量的数据类型。
因此,对于机器学习从业者来说,在执行基于过滤器的特征选择时,为数据集选择合适的统计度量可能是一个挑战。
在本帖中,您将了解如何为具有数值和分类数据的基于过滤器的特征选择选择统计度量。
阅读本文后,你将了解:
- 特征选择技术主要有两种:监督式和无监督式,而监督式方法又可分为包装式、过滤器式和内在式。
- 基于过滤器的特征选择方法使用统计度量来评估输入变量之间的相关性或依赖性,这些变量可以被过滤以选择最相关的特征。
- 特征选择的统计度量必须根据输入变量和输出或响应变量的数据类型仔细选择。
开始您的项目,阅读我的新书 《机器学习数据准备》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2019年11月:为分类和回归添加了一些实际示例。
- 更新于2020年5月:扩展并添加了参考文献。添加了图片。

如何开发乳腺癌患者生存的概率模型
图片来自 Tanja-Milfoil,保留部分权利。
概述
本教程分为4个部分,它们是:
- 特征选择方法
- 基于过滤器的特征选择方法的统计数据
- 数值输入,数值输出
- 数值输入,分类输出
- 分类输入,数值输出
- 分类输入,分类输出
- 特征选择的技巧
- 相关性统计
- 选择方法
- 转换变量
- 什么是最优方法?
- 实际示例
- 回归特征选择
- 分类特征选择
1. 特征选择方法
特征选择方法旨在减少输入变量的数量,只保留那些被认为对模型最有用,以预测目标变量的变量。
特征选择主要侧重于从模型中移除无信息或冗余的预测变量。
— 第 488 页,《应用预测建模》,2013。
一些预测建模问题具有大量的变量,这会减慢模型的开发和训练速度,并需要大量的系统内存。此外,当包含与目标变量无关的输入变量时,某些模型的性能可能会下降。
许多模型,特别是基于回归斜率和截距的模型,会为模型中的每个项估计参数。因此,无信息变量的存在会增加预测的不确定性,并降低模型的整体有效性。
— 第 488 页,《应用预测建模》,2013。
思考特征选择方法的一种方式是根据监督式和无监督式方法进行分类。
特征选择中一个重要的区别是监督式和无监督式方法。当在消除预测变量时忽略结果时,该技术就是无监督式。
— 第 488 页,《应用预测建模》,2013。
区别在于特征是基于目标变量还是不基于目标变量来选择的。无监督特征选择技术忽略目标变量,例如使用相关性去除冗余变量的方法。监督特征选择技术使用目标变量,例如去除不相关变量的方法。
另一种考虑特征选择机制的方法是包装式和过滤器式方法。这些方法几乎总是监督式的,并根据模型在保留数据集上的性能进行评估。
包装式特征选择方法会创建许多具有不同输入特征子集的模型,并根据性能指标选择导致最佳模型性能的特征。这些方法不关心变量类型,尽管它们可能计算成本高昂。RFE 是包装式特征选择方法的一个好例子。
包装式方法使用添加和/或移除预测变量的过程来评估多个模型,以找到最大化模型性能的最优组合。
— 第 490 页,《应用预测建模》,2013。
过滤器式特征选择方法使用统计技术来评估每个输入变量与目标变量之间的关系,并将这些分数作为选择(过滤)将用于模型中的输入变量的依据。
过滤器式方法在预测模型之外评估预测变量的相关性,然后仅对通过某些标准的预测变量进行建模。
— 第 490 页,《应用预测建模》,2013。
最后,一些机器学习算法在学习模型的同时会自动执行特征选择。我们可以将这些技术称为内在特征选择方法。
…有些模型包含内置的特征选择,这意味着模型将只包含有助于最大化准确性的预测变量。在这些情况下,模型可以选择并挑选最佳的数据表示。
— 第 28 页,《应用预测建模》,2013。
这包括像 Lasso 这样的正则化回归模型和决策树,包括随机森林等决策树的集成。
一些模型自然地对无信息预测变量具有抵抗力。例如,基于树和规则的模型、MARS 和 Lasso 会内在进行特征选择。
— 第 487 页,《应用预测建模》,2013。
特征选择也与降维技术相关,因为这两种方法都寻求减少预测模型的输入变量数量。区别在于特征选择是选择要保留或从数据集中删除的特征,而降维则创建数据的投影,从而生成全新的输入特征。因此,降维是特征选择的替代方案,而不是特征选择的一种类型。
我们可以总结特征选择如下。
- 特征选择:从数据集中选择输入特征的子集。
- 无监督式:不使用目标变量(例如,去除冗余变量)。
- 相关性
- 监督式:使用目标变量(例如,去除不相关变量)。
- 包装式:搜索性能良好的特征子集。
- RFE
- 过滤器式:根据特征与目标的关系选择特征子集。
- 统计方法
- 特征重要性方法
- 内在式:在训练过程中自动执行特征选择的算法。
- 决策树
- 包装式:搜索性能良好的特征子集。
- 无监督式:不使用目标变量(例如,去除冗余变量)。
- 降维:将输入数据投影到较低维度的特征空间。
下图总结了特征选择技术的层级结构。
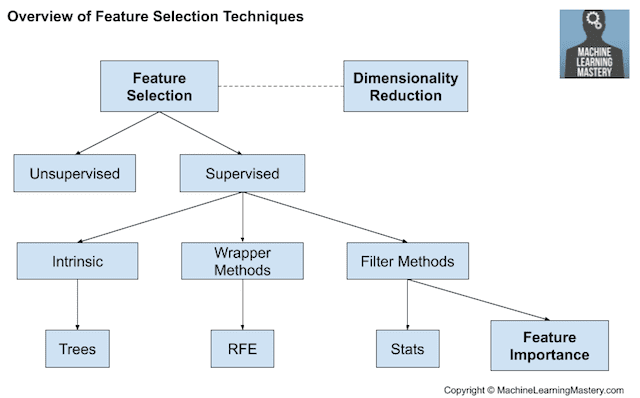
特征选择技术概述
在下一节中,我们将回顾一些可用于基于过滤器的特征选择的统计度量,以及不同的输入和输出变量数据类型。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
2. 基于过滤器的特征选择方法的统计数据
通常使用输入变量和输出变量之间的相关性统计度量作为基于过滤器的特征选择的基础。
因此,统计度量的选择高度依赖于变量的数据类型。
常见的数据类型包括数值型(如身高)和分类型(如标签),尽管每种类型都可以进一步细分,例如数值变量的整数和浮点数,以及分类变量的布尔型、有序型或名义型。
常见输入变量数据类型
- 数值变量
- 整数变量。
- 浮点数变量。
- 分类变量.
- 布尔变量(二分变量)。
- 有序变量。
- 名义变量。
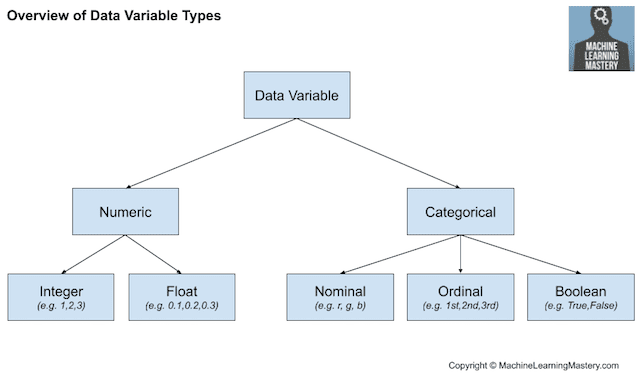
数据变量类型概述
对变量数据类型的了解越多,就越容易为基于过滤器的特征选择方法选择合适的统计度量。
在本节中,我们将考虑两个广泛的变量类型类别:数值型和分类型;此外,还要考虑两个主要的变量组:输入变量和输出变量。
输入变量是提供给模型的变量。在特征选择中,这是我们希望减小规模的变量组。输出变量是模型旨在预测的变量,通常称为响应变量。
响应变量的类型通常指示了正在执行的预测建模问题的类型。例如,数值输出变量表示回归预测建模问题,分类输出变量表示分类预测建模问题。
- 数值输出:回归预测建模问题。
- 分类输出:分类预测建模问题。
在基于过滤器的特征选择中使用的统计度量通常是逐个输入变量与目标变量进行计算的。因此,它们被称为单变量统计度量。这可能意味着在过滤过程中不考虑输入变量之间的任何交互作用。
大多数这些技术都是单变量的,意味着它们独立评估每个预测变量。在这种情况下,相关预测变量的存在使得选择重要但冗余的预测变量成为可能。这个问题明显的后果是选择了过多的预测变量,并因此出现了共线性问题。
— 第 499 页,《应用预测建模》,2013。
有了这个框架,让我们回顾一些可用于基于过滤器的特征选择的单变量统计度量。
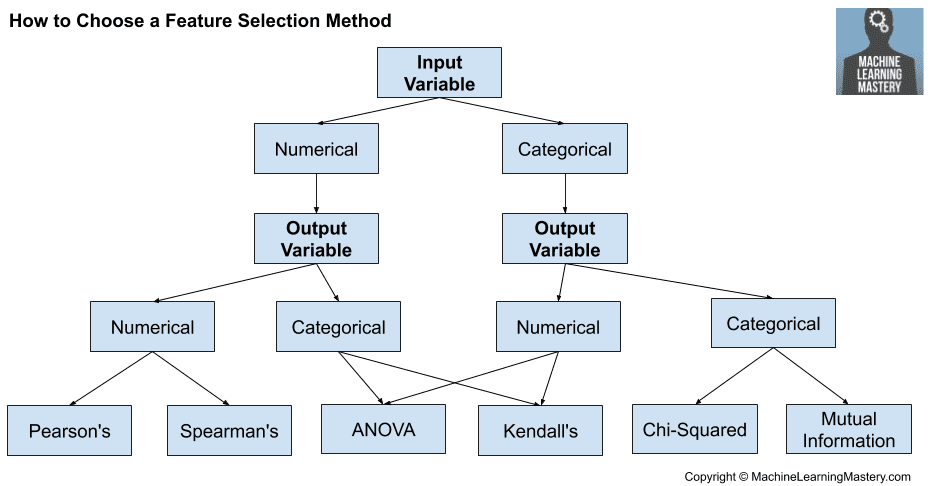
如何为机器学习选择特征选择方法
数值输入,数值输出
这是一个具有数值输入变量的回归预测建模问题。
最常用的技术是使用相关系数,例如皮尔逊系数用于线性相关,或秩方法用于非线性相关。
- 皮尔逊相关系数(线性)。
- 斯皮尔曼秩相关系数(非线性)
数值输入,分类输出
这是一个具有数值输入变量的分类预测建模问题。
这可能是分类问题中最常见的示例,
同样,最常用的技术是基于相关的,尽管在这种情况下,它们必须考虑到分类目标。
- ANOVA 相关系数(线性)。
- 肯德尔秩相关系数(非线性)。
肯德尔秩相关系数假设分类变量是有序的。
分类输入,数值输出
这是一个具有分类输入变量的回归预测建模问题。
这是一个奇怪的回归问题示例(例如,您不会经常遇到)。
尽管如此,您可以使用相同的“数值输入,分类输出”方法(如上所述),但反过来使用。
分类输入,分类输出
这是一个具有分类输入变量的分类预测建模问题。
分类数据最常用的相关度量是卡方检验。您也可以使用信息论领域的互信息(信息增益)。
- 卡方检验(列联表)。
- 互信息。
事实上,互信息是一种强大的方法,可用于分类和数值数据,例如,它对数据类型不敏感。
3. 特征选择的技巧
本节提供了一些使用基于过滤器的特征选择的额外考虑事项。
相关性统计
scikit-learn 库实现了大多数有用的统计度量。
例如
- 皮尔逊相关系数:f_regression()
- ANOVA:f_classif()
- 卡方:chi2()
- 互信息:mutual_info_classif() 和 mutual_info_regression()
此外,SciPy 库还提供了许多其他统计函数的实现,例如肯德尔秩相关系数(kendalltau)和斯皮尔曼秩相关系数(spearmanr)。
选择方法
scikit-learn 库还提供了许多不同的过滤方法,一旦为每个输入变量与目标变量计算了统计数据。
其中两个更受欢迎的方法包括
- 选择前 k 个变量:SelectKBest
- 选择前百分比的变量:SelectPercentile
我通常自己使用SelectKBest。
转换变量
考虑转换变量以访问不同的统计方法。
例如,您可以将分类变量转换为有序变量,即使它不是,并看看是否有任何有趣的结果。
您还可以将数值变量离散化(例如,分箱);尝试基于分类的方法。
一些统计度量假设变量的某些属性,例如皮尔逊相关系数假设观测值服从高斯概率分布且关系是线性的。您可以转换数据以满足测试的预期,也可以忽略预期并尝试测试,然后比较结果。
什么是最优方法?
没有最好的特征选择方法。
就像没有最好的输入变量集或最好的机器学习算法一样。至少不是普遍适用的。
相反,您必须通过仔细的系统实验来发现最适合您特定问题的方法。
尝试使用不同的统计度量选择的不同特征子集拟合的各种模型,并发现最适合您特定问题的方法。
4. 特征选择的实际示例
有一些可以直接复制粘贴并改编用于您自己项目的实际示例会很有帮助。
本节提供了特征选择案例的实际示例,您可以将其作为起点。
回归特征选择
(数值输入,数值输出)
本节演示了针对具有数值输入和数值输出的回归问题的特征选择。
使用 make_regression() 函数准备了一个测试回归问题。
特征选择通过 f_regression() 函数使用 皮尔逊相关系数 进行。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 数值输入和数值输出的皮尔逊相关特征选择 from sklearn.datasets import make_regression 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_regression # 生成数据集 X, y = make_regression(n_samples=100, n_features=100, n_informative=10) # 定义特征选择 fs = SelectKBest(score_func=f_regression, k=10) # 应用特征选择 X_selected = fs.fit_transform(X, y) print(X_selected.shape) |
运行示例首先创建回归数据集,然后定义特征选择并将其应用于数据集,返回所选输入特征的子集。
|
1 |
(100, 10) |
分类特征选择
(数值输入,分类输出)
本节演示了针对具有数值输入和分类输出的分类问题的特征选择。
使用 make_classification() 函数准备了一个测试回归问题。
特征选择通过 ANOVA F 度量使用 f_classif() 函数进行。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 数值输入和分类输出的 ANOVA 特征选择 from sklearn.datasets import make_classification 从 sklearn.特征选择 导入 SelectKBest from sklearn.feature_selection import f_classif # 生成数据集 X, y = make_classification(n_samples=100, n_features=20, n_informative=2) # 定义特征选择 fs = SelectKBest(score_func=f_classif, k=2) # 应用特征选择 X_selected = fs.fit_transform(X, y) print(X_selected.shape) |
运行示例首先创建分类数据集,然后定义特征选择并将其应用于数据集,返回所选输入特征的子集。
|
1 |
(100, 2) |
分类特征选择
(分类输入,分类输出)
有关分类输入和分类输出的特征选择示例,请参阅教程
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
文章
总结
在本帖中,您了解了如何为具有数值和分类数据的基于过滤器的特征选择选择统计度量。
具体来说,你学到了:
- 特征选择技术主要有两种:监督式和无监督式,而监督式方法又可分为包装式、过滤器式和内在式。
- 基于过滤器的特征选择方法使用统计度量来评估输入变量之间的相关性或依赖性,这些变量可以被过滤以选择最相关的特征。
- 特征选择的统计度量必须根据输入变量和输出或响应变量的数据类型仔细选择。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨,Jason,
感谢您写的博客。您是否有无监督特征选择方法的摘要?
帖子中列出的所有统计方法都是无监督的。
嗨
实际上,我的问题和 Mehmet 一样。如果我错了,请纠正我,本文的讨论是关于输入变量和目标变量的。据此,我理解的是给定监督学习问题的特征和标签。
但您的回答中却说是无监督!我有点困惑。
谢谢。
它们是应用于两个变量的统计检验,没有涉及监督学习模型。
我认为您说的无监督是指没有目标变量。那样的话您就无法进行特征选择。但您可以做其他事情,例如降维,例如 SVM 和 PCA。
但您提供的两个特征选择代码示例确实来自监督学习领域
– 回归特征选择(数值输入,数值输出)
– 分类特征选择(数值输入,分类输出)
您是否可能指监督学习是用于特征选择的一种可能的领域,但它不一定是唯一的应用领域?
也许我是在说这种特征选择只在监督学习上有意义,但它本身并不是一种监督学习算法——这个过程是以无监督的方式应用的。
好的,我想我明白了您的意思。
特征选择方法被用于监督学习问题,以减少输入特征的数量(或者您称之为“输入变量”),然而,所有这些方法本身都是以无监督的方式进行的。
这是我的理解。
您说的无监督是指像聚类的特征选择吗?
你好先生,
如果我们没有目标变量,是否可以在数值数据集的聚类之前应用特征选择?
不可以。特征选择需要目标变量——至少所有监督方法都需要。
您可以使用无监督方法来去除冗余输入。我还没有这方面的例子。
嗨 Jason,感谢您的帖子!
我已将皮尔逊选择作为目标变量和变量之间的过滤器方法。我的目标是二元的,而我的变量可以是分类的或连续的。皮尔逊相关性仍然是特征选择的有效选项吗?如果不是,当目标是二元的且变量是分类的或连续的时,能否告诉我其他过滤器方法?
不,皮尔逊相关性不合适。考虑 ANOVA F。
嗨 Jason,在 Herman 的情况下,将预测变量分为两组(数值变量和分类变量),然后分别与目标变量进行分析是否有效?您怎么看?谢谢!
嗨 Jenry…您可能会发现以下资源很有趣
https://inria.github.io/scikit-learn-mooc/python_scripts/03_categorical_pipeline_column_transformer.html
再次感谢您这篇简短而精彩的帖子。Lasso、RF、XGBoost 和 PCA 怎么样?这些也可以用来识别最佳特征。
是的,但在本帖中,我们关注的是单变量统计方法,也就是所谓的过滤器特征选择方法。
感谢您花时间澄清。
感谢分享。事实上,我一直在寻找这么好的博客很久了。
谢谢!
我希望它有所帮助。
请给出两个理由,说明在文档分类的特征选择方面为什么可以认为它是可取的。
文档分类的特征选择具体是什么样的?您是指减小词汇量的大小吗?
非常翔实的文章,内容很棒。
谢谢!
Jason 你好!感谢这篇翔实的帖子!我正试图将这些知识应用于住房价格预测问题,其中回归变量包括数值特征和分类特征。在您的图表中,(分类输入、数值输出)也指向 ANOVA。为了在住房价格案例中正确使用 ANOVA,我是否必须在 SelectKBest 之前对我的分类输入进行编码?
是的,至少需要对分类变量进行标签/整数编码。
你好 Jason!就像 YXZ 的情况一样
我有一个连续的数值输出和一组非二元分类输入,建议将这些分类输入编码为虚拟变量还是使用标签/整数编码器?我还想知道如何应用“反向”Kendall 秩相关方法来处理这种情况或 ANOVA,考虑到我的输出是连续的,哪种是我的最佳选择?
此致
我建议使用整数/序数编码,并尝试为分类数据或 RFE 决策树设计特征选择方法。
Jason 你好!我的数据集包含数值和分类特征。标签是分类性质的。找到特征重要性的最佳方法是什么?在应用 ANOVA/Kendall 之前,我应该进行 OneHotEncode 我的分类特征吗?
对不同变量类型使用单独的统计特征选择方法。
或者尝试 RFE。
嗨,Jason,
非常感谢这篇详细的文章。
我有一个问题,在对我的分类特征进行独热编码后,创建的列只有 0 和 1。我的输出变量是数值型,所有其他预测变量也是数值型。我可以使用皮尔逊/斯皮尔曼相关性来进行特征选择(以及消除多重共线性)吗?
现在,由于独热编码的列具有一定的顺序性(0 – absence,1 – presence),我认为相关矩阵会有用。
我尝试了这个,结果在业务上是合理的。只是想知道您的想法,这在根本上是正确的吗?
不,在二元属性上使用斯皮尔曼/皮尔逊相关性是没有意义的。
您直接对分类变量执行特征选择。
(0 – absence, 1- presence) 是布尔值,它为什么是序数?
是的,分类/布尔值。
如果您愿意,可以将其建模为序数关系,但这可能不适用于某些领域。
非常感谢您这篇精彩的帖子。我对机器学习非常陌生,所以有一个非常基础的问题。假设我有一组被标记为负面和正面的推文。我想进行一些情感分析。我提取了 3 个基本特征:1. 表情图标 2.感叹号 3.强度词(very, really)。我的问题是:如何将这些特征与 SVM 或其他机器学习算法一起使用?换句话说,我如何将提取的特征应用到 SVM 算法中?
我是否应该每次都用一个特征来训练我的数据集?我阅读了几篇文章,它们只说:我们应该提取特征并将它们部署到我们的算法中,但是怎么做呢?
请帮帮我。
文本需要数值表示,例如词袋模型。
这被称为自然语言处理,您可以在这里开始
https://machinelearning.org.cn/start-here/#nlp
谢谢您,先生
不客气。
嘿 Jason,
您能解释一下为什么我们要使用单变量选择方法进行特征选择吗?
因为我们应该使用相关矩阵,它给出每个因变量和自变量之间的相关性,以及两个自变量之间的相关性。
因此,使用相关矩阵我们也可以删除共线或冗余的特征。
所以你能解释一下何时我们应该使用单变量选择而不是相关矩阵吗?
是的,像统计测试这样的过滤器方法快速易于测试。
之后您可以继续使用 RFE 等包装器方法。
嗨 Jason
谢谢您提供有用的帖子。
我想知道使用哪种方法?
输入变量是
1. 年龄
2. 性别(但它有数字,1 为男性,2 为女性)
3. 工作时间 -
4. 学校成就(也有数字)
输出是数值型。
你能帮帮我吗?
也许可以注明每个变量是数值型还是分类型,然后遵循上述指南。
你好,Jason!
您的意思是,您需要根据上述图示的输入和输出参数为每个变量执行特征选择吗?是否有任何快捷方式,我可以只输入数据并生成特征分数,而无需担心输入和输出数据的类型?
是的,不同变量类型需要不同的特征选择。
快捷方式是使用不同的方法,如 RFE,或像 xgboost/random forest 这样可以为您进行特征选择的算法。
你好 Jason,
感谢您的精彩博文,我读了多篇,觉得它们非常有帮助。
我有一个关于特征选择的快速问题。
如果我想通过 VarianceThreshold 选择一些特征,这种方法是否只适用于数值输入?
我可以对分类输入进行编码,然后将 VarianceThreshold 应用于它们吗?
非常感谢!
谢谢!
是的,据我所料,这仅限于数值型。
嗨,Jason!
有没有办法显示 SelectKBest 选择的特征的名称?
在您的示例中,它只返回一个没有列名的 numpy 数组。
是的,您可以通过列名列表和特征进行循环,并使用 SelectKBest 类上的信息打印它们是否被选中。
嗨,Jason,
非常感谢这篇详细的博文。关于 f_classif 方法的直觉,有一个快速的问题。
为什么我们要选择 F 值高的特征?假设 y 取两个类 [0,1],而 feature1 被选中是因为它在与 y 的单变量 ANOVA 中具有高 F 统计量,这是否意味着当 y = 0 时 feature1 的均值与当 y = 1 时 feature 1 的均值在统计学上是不同的?因此 feature1 可能对预测 y 有用?
是的,值越大越好。但不要手动操作,请使用内置的选择方法。
请参考教程末尾的实际操作示例作为模板。
嗨,杰森,
因此,我正在处理一个包含超过十万个样本的 Dota2 数据集,该数据集由每场比赛的胜者和“英雄”组成。我正在尝试构建一个类似 [http://jmcauley.ucsd.edu/cse255/projects/fa15/018.pdf] 的获胜者预测模型。因此输入向量是
Xi= 如果英雄 i 在天辉方,则为 1,否则为 0。
X(119+i) = 如果英雄 i 在夜魇方,则为 1,否则为 0
向量 X 由 238 个条目组成,因为有 119 种英雄。每个向量表示每场比赛中使用的英雄的构成。每场比赛总是恰好包含 10 个英雄(5 个在天辉方,5 个在夜魇方)。
从这个设置开始,我将得到一个 100k x (222 + 1) 维的二进制矩阵,其中行表示样本数,列表示特征,+1 列表示标签向量(0 和 1,1 表示天辉方获胜)。
因此,如果我对两个列向量执行点积,我就可以得到英雄 i 在所有样本中与英雄 j 一起出现的次数。
因此,如果我对两个列向量执行哈达玛积,然后将结果与列标签向量进行点积,我就可以得到英雄 i 与英雄 j 一起出现并获胜的次数。
通过这些,我可以计算每个条目每个样本的权重,这些样本对应于向量标签。我可能会发现这些“新特征”与标签向量之间存在很高的相关性。但是我找不到统计学教科书中关于二元数据的此类问题。
我不确定能否立即提供好的建议,抱歉。
Jason 你好,感谢这篇文章。我完全理解这些不同的方法。我有一个问题。
假设。我有 3 个变量。X,Y,Z
X = 分类
Y = 数值
Z = 分类,因变量(我想预测的值)
现在,我没有发现 Y 和 Z 之间有任何关系,但我发现了 Y 和 Z 之间的关系。有没有可能如果我们一起包含 Y 来预测 Z,Y 可能会与 Z 建立关系?
如果有任何统计方法或研究,请提及它们。谢谢。
我建议简单地测试输入变量的每种组合,并使用产生最佳预测目标结果的组合——这比多元统计要简单得多。
一个建议是使用 DSD(Definitive Screening Design),一种实验设计 (DoE) 类型,它可以“在存在二阶效应的情况下估计主效应,仅需要比因子数多两倍的运行次数,并避免任何二阶效应对的混淆”[1]
DSD 还可以与两级分类因子进行增强,“其中实验可以估计二次效应,二次效应的估计随着更多分类因子的添加而减少”[2]
我们使用此方法来辅助用于工业过程应用的 CNN 的特征选择。
[1] B. Jones and C. J. Nachtsheim, “A Class of Three-Level Designs for Definitive Screening in the Presence of Second-Order Effects,” Journal of Quality Technology, vol. 43, no. 1, pp. 1-15, 2011
[2] B. Jones and C. J. Nachtsheim, “Definitive Screening Designs with Added Two-Level Categorical Factors,” Journal of Quality Technology, vol. 45, no. 2, pp. 121-129, 2013
好建议,谢谢分享 George!
当数据集中只有分类变量,包括名义、有序和二分变量时,如果我使用 Cramér’s V 或 Theil’s U(不确定性系数)来获得特征之间的相关性,是否是错误的?
谢谢
San
我不知道,抱歉。
非常好的文章。
我检测到了异常值,想知道如何估算每个特征对单个异常值的贡献?
我们只讨论一个观测值和它的标签,而不是整个数据集。
我找不到任何参考。
这听起来像是一个开放性问题。
也许可以探索从质心或到内点的距离度量?
或者每个特征的单变量分布度量?
感谢您的快速回复。
这是一个单类多值应用。
对于单个观测值,我需要找出对该类有最大影响的前 n 个特征。
根据大多数文章,我可以找到所有观测值中最重要的特征,但在这里我需要知道特定观测值中的情况。
只需在您的实例子集上拟合模型即可。
1)在特征选择算法(XGBosst、GA 和 PCA)的情况下,我们可以考虑哪种方法是包装器还是过滤器?
2)特征选择和降维有什么区别?
XGBoost 将被用作过滤器,GA 将是包装器,PCA 不是特征选择方法。
特征选择选择数据中的特征。降维,如 PCA,将特征转换或投影到较低的维度空间。
技术上来说,删除特征可以被视为降维。
非常感谢您的时间和回复。您愿意分享一些关于此的材料(以便我将其作为参考用于我的论文)吗?
此外,我很高兴了解这方面的优缺点;我是说,当我使用 XGBoost 作为过滤器特征选择,GA 作为包装器特征选择,PCA 作为降维时,那么可能有什么优缺点?
最好的问候!
如果您需要特征选择的理论,我建议进行文献综述。
我无法帮助您解决优缺点——这很大程度上是在浪费时间。我建议使用在特定数据集上“确实”有效的方法,而不是“可能”有效的方法。
我没明白你的意思。
我有一个异常记录。并且想知道哪些特征对该记录的异常值贡献最大。
谢谢,如果问题令人困惑,请原谅。
我建议这是一个开放性问题——也就是说,没有明显的答案。
我建议将其作为一个研究项目来发现什么最有效。
这样可以帮助您吗?哪些部分令人困惑——也许我可以进一步阐述?
谢谢你
应该对此进行研究。
感谢您的建议。
上述算法是否会跟踪“哪些”特征已被选中,还是只选择“最佳”特征数据?在确定了“最佳 k 个特征”之后,我们如何提取这些特征,理想情况下只提取这些特征,从新的输入中?
是的,您可以根据列索引找出哪些特征被选中。
嗨,Jason,
再次感谢您提供的精彩概述。这里有一个相对较新的软件包,介绍了 Phi_K 相关系数,它声称可以用于分类、有序和数值特征。据说它还可以捕捉非线性依赖关系。
https://phik.readthedocs.io/en/latest/#
最好的祝福
奥利弗
感谢分享。
Jason 你好,感谢这篇精彩的文章。
关于使用 ANOVA 的一个问题。鉴于分类变量和数值目标,您不应该假设每个分类值的样本之间方差齐性吗?根据我的学习,ANOVA 要求方差相等的假设。
也许可以。
通常,方法会优雅地失败而不是突然失败,这意味着当假设被违反时,您仍然可以可靠地使用它们。
你好 Jason,
感谢您的解释和与我们分享的精彩文章!
您在“如何为机器学习选择特征选择方法”表中清楚地解释了如何在不同变体中执行特征选择。
+ 数值输入,数值输出
皮尔逊相关系数(线性)。斯皮尔曼秩系数(非线性)。
+ 数值输入,分类输出
ANOVA 相关系数(线性)。肯德尔秩系数(非线性)。
+ 分类输入,数值输出
ANOVA 相关系数(线性)。肯德尔秩系数(非线性)。
+ 分类输入,分类输出
卡方检验(列联表)。互信息。
我想问一些关于包含数值和分类输入组合的数据集的问题。
1- 当我们有一个包含数值和分类输入的混合数据集时,应该应用哪些方法?(例如:总输入:50;数值:25 和分类:25。任务:分类问题,带有分类值)
2- 我应该应用一种标签编码方法(编码取决于特征中的标签,假设我应用了独热编码、目标编码)。从分类输入中获取数值。然后,我的问题就变成了数值输入、分类输出。在这种情况下,我应该应用方差分析相关系数(线性)和 Kendall 秩相关系数(非线性)技术吗?
3- 或者,对于包含数值和分类输入的混合分类(分类输出)问题,应用特征选择技术的更好方法是什么?
谢谢你。
不客气。
您可以使用一种独立的方法来处理每种数据类型,或者使用一种支持所有输入同时处理的包装器方法。
你好 Jason,
感谢这篇精彩的文章。我正在理解这些概念。
我有一些问题。
1. 我有一个数据集中包含 numberOfBytes、numberOfPackets 等数值数据。我还拥有一些其他特征,如 IP 地址(例如 10、15、20、23、3)和协议(例如 6、7、17,分别代表 TCP、UDP、ICMP)。
在这种情况下,IP 地址、协议等特征是数值还是分类?实际上它们代表类别且是名义值,但它们用数字表示。目标值也是数字(1-TCP 流量,2-UDP 正常流量,3-ICMP 正常流量,4-恶意流量)。我能将 IP 地址、协议视为分类吗?我能将目标视为分类吗?
2. 数据集是数值和分类数据的混合。那么对于这些类型的数据集可以进行哪些特征选择?
3. 请验证我的流程——
1) 加载数据集。
2) 将数据集分为训练集-测试集。
3) 对 IP 地址和协议执行 getdummies 并删除一个 dummy。
4) 对目标变量进行标签编码。
5) 对于训练集,使用卡方检验或互信息进行特征选择。
6) 选择前 20 个特征。
7) 对特征进行缩放……
8) 对模型进行交叉验证并取平均准确率。
应该在特征选择之前进行编码(dummy 或 onehot)吗?应该对编码后的特征进行缩放吗?
4. 根据您的经验,对于混合了分类和数值变量以及分类目标变量的数据集,您会怎么做?看到您提到了单独对每种变量类型进行特征选择。您能举个例子吗?
这类问题还有哪些其他选择?
5. 假设我使用 XGBoost 分类器来选择最佳特征。能否将 XGBoost 提供的这些最佳特征用于另一个模型(例如逻辑回归)进行分类?我总是看到将 XGBoost 返回的特征用于同一模型进行分类的示例。
也许您可以在文献中找到 IP 地址的合适表示方法,或者尝试几种您能想到的方法。
也许您可以使用不区分变量类型的 RFE。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
也许在某些选择技术之前需要进行编码。这取决于具体情况。
XGB 不执行特征选择,它可以用于特征重要性评分。
我混合了数值、有序和名义属性。
对于前两者,使用皮尔逊相关系数来确定与目标的相关性。
对于名义类型,我仍然找不到处理相关性的好参考。将其编码为数值似乎不正确,因为数值很可能表明某种有序关系,但对于名义属性不应如此。
有什么建议吗?
我还根据与目标相关性更高的转换属性测试了模型性能,但是,模型性能并未如预期那样提高。有什么建议可以进一步探索吗?
名义是“分类”;现在根据输出变量的类型遵循上述建议。
您好 Jason,当输出(即标签)是 0 或 1,代表“差”和“好”时,这被视为数值输出还是分类输出?
这是一个数字,我们可以在我们的应用程序中将其映射到类别。
那么这个响应变量应该被视为分类目标还是数值目标?
分类。
Jason,您没有展示分类输入和数值输出的示例。
您可以反转案例来处理:数值输入、分类输出。
先生,
在我的数据集中,有 29 个属性是“是/否”值(二元),其余是数值(浮点数)类型属性。类别有 7 个值(多类)。我想尝试这个数据集进行分类。哪些特征选择技术适合?请帮帮我!
致敬!
Thaung
一些想法
也许可以先建立一个包含所有特征的基线性能?
也许可以尝试为每种输入类型分别进行特征选择?
也许可以尝试一种包装器方法,如 RFE,它不区分输入类型?
您好 Jason,非常感谢您这项精彩且非常有用的工作。
1- 包装器方法:模型是去除不相关的特征,还是只分配较低的权重?
2- 过滤器方法:在使用单变量技术时,如何检测或防止所选变量之间的冗余?
3- t 统计量怎么样?
提前感谢。
包装器方法会测试不同的特征子集,并选择一个能带来最佳性能的子集。
删除冗余特征是在没有目标变量的情况下进行的。例如,可以删除高度相关的特征。
是的,我读过这个。我没有例子。
非常感谢。
不客气。
你好先生,
我是这个领域的新手,我想对一个数据集应用 UNSUPERVISED MTL NN 模型进行预测,为此我必须先进行聚类以获得目标值。我想应用一些特征选择方法来提高聚类和 MTL NN 方法的结果,我可以在我的数值数据集上应用哪些特征选择方法?
上面的教程解释得很清楚,也许可以再读一遍?
那么我们是在特征选择过程中选择的特征上训练最终的机器学习模型吗?
我们使用 fit_transform() 来处理 xtrain,那么在评估之前我们需要对 xtest 进行 transform() 吗?
是的,您可以调用 fit_transform 来选择特征,然后拟合一个模型。
理想情况下,您会在建模管道中使用特征选择。
那么在这篇知识性帖子之后,我还能问些什么?
我的数据集包含:
我拥有超过 80 个特征,其中一个特征是分类的(IP 地址)(我将使用 get_dummies 将其转换为数值),其他所有特征都是数值的。响应变量是 1(好)和 -1(坏)。
我将要做的是使用 sklearn 的方差阈值去除常数变量。然后使用 corr() 函数去除相关特征。
在完成所有这些之后,我想使用 kbest 和皮尔逊相关系数以及 Fisher 来获得一组表现良好的十个特征。
我这样做对吗?
我的数据集同时包含分类(将使用 get_dummies 转换为数值)和数值特征,并且响应变量为 1 和 -1,在这种情况下我可以使用皮尔逊吗?
如果目标是一个标签,那么这个问题就是分类问题,皮尔逊相关系数是不合适的。
嗨,Jason,
非常感谢这篇文章。
我同时拥有数值和分类特征。在进行过滤器方法或包装器方法之前,我是否应该对数值特征进行归一化/缩放?
可以尝试一下,看看它是否会对您的数据和模型产生影响。
您好 Jason,能否请您提供图 3“如何为机器学习选择特征选择方法”的参考(论文/书籍),以便我在我的论文中引用?这将非常有帮助。
您可以直接引用此网页。这将有所帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-reference-or-cite-a-book-or-blog-post
好文章。
我的数据有数千个特征。其中 10% 是分类特征,其余是连续特征。输出是分类的。
RFE 是否同时接受分类和连续输入
进行特征选择。如果是,我能否添加一个截止值来选择特征?
是的,它支持两种特征类型。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
是的,您可以指定要选择的特征数量。
感谢提供的链接和回复。
不客气。
你好,
很棒的文章。
我的特征基于时间。
在时间序列数据上运行特征选择的最佳方法是什么?
谢谢!
ACF 和 PACF 用于滞后输入。
https://machinelearning.org.cn/gentle-introduction-autocorrelation-partial-autocorrelation/
使用卡方检验与 (a) 数值输入和数值输出;(b) 分类输入和数值输出是否合适或有用?我也从文章中了解到,您给出了这些情况最常见和最适合的检验,但不是每种情况的绝对列表。我说的对吗?
可以这样做,但据我所理解,它是针对分类输入和分类输出变量的。
https://machinelearning.org.cn/chi-squared-test-for-machine-learning/
您好,很棒的文章!我有一个关于 RFE 如何预先对特征重要性进行排名的疑问,据我所理解,它是基于 coef 的绝对值(对于线性回归),如果我错了,请纠正我,因为有时当我手动对线性回归拟合后的特征的 coef 进行排名时,它与 RFE.ranking_ 不匹配。
谢谢!
好问题,您可以在这里了解更多关于 RFE 的信息。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
感谢这篇信息丰富的文章 Jason。
我理解这篇帖子专注于监督方法——也就是说,我们考虑每个输入变量与我们想要预测的目标输出变量的特定配对的数据类型,然后选择合适的统计方法来评估基于输入/输出变量数据类型组合的关系,如您的文章所示。
我想更好地理解您所说的无监督方法,即去除冗余变量(例如,防止多重共线性问题)。
如果我不从输入变量和输出变量的角度考虑问题,而是只想知道我数据集中任意两个变量之间的关系,那么我知道首先需要检查这两个变量的散点图是否显示线性或单调关系。
我认为接下来的逻辑是,如果两个属性显示线性关系,则使用皮尔逊相关系数来评估这两个属性之间的关系。如果两个属性显示单调关系(但不线性),则使用秩相关方法,例如 Spearman、Kendall。
我的问题是,在这种非输入/输出变量的情况下,每个属性对的数据类型是如何影响的?“如何为机器学习选择特征选择方法”的决策树是否仅适用于输入/输出变量的情况,还是数据类型的组合也会影响我描述的情况?
例如,我想知道我的数据集中的属性 1 和属性 2 是否相互关联。这两个属性都不是输出变量,也就是说,我没有尝试进行预测。如果属性 1 是分类属性,属性 2 是数值属性,那么我是否应该根据您的决策树使用 ANOVA 或 Kendall 中的一种?或者这个决策树不适用于我的情况?
我看到的许多在线示例似乎只使用皮尔逊相关系数来表示双变量关系,但我从阅读您的文章中知道这通常是不合适的。我真的很难理解每种不同情况的规则,包括哪些假设可以在实际环境中忽略,哪些不能,以便我知道哪种类型的相关性适用于哪种情况。
如果您能提供任何澄清或指向我进一步研究的主题,那将非常有帮助,谢谢!
删除低方差或高度相关的输入是另一个步骤,在上述特征选择之前进行。
可以使用相同类型的相关性度量,尽管我个人会坚持对数值使用皮尔逊/ Spearman,对分类使用卡方。例如,类型与类型,而不是跨类型。保持简单。
您好,为什么您说 Kendall 而不是 Kruskal-Wallis 来表示非参数而不是 ANOVA?
顺便说一句,您的文章是我的圣经!提前非常感谢!
谢谢!
Kendall's 通常用于非参数相关性估计(秩相关)。
Kruskal-Wallis 通常用于非参数样本均值比较。
您好!为了构建更健壮的模型,我们通常会通过交叉验证来检查它。那么在进行交叉验证时,每个折叠的结果可能不同,我应该如何进行?
不同的结果是指每次折叠都得到不同的有用特征。
是的,交叉验证过程会评估您的建模管道。
关键不在于每次运行选择了哪些具体特征,而在于管道的平均表现如何。
在获得性能估计后,您可以继续在您的数据上使用它,并选择将成为您最终模型一部分的特征。
这有帮助吗?
您好,感谢您的文章!
对于输入数值,输出分类。
有趣的是,参考文献并不直接,而且它们几乎不重叠(除了 ROC)。
1) 特征工程和选择,2019:http://www.feat.engineering/greedy-simple-filters.html#
->它没有评论 Kendall,只评论了 ANOVA F-Test(少量)。
->提到了 t-test 和 ROC 作为选项,但未在本篇文章中。
2) 应用预测建模,2013。第 18 章
->ANOVA 被提及一次,第 467 页(少量)->但不在分类章节(18.2)中。
->Chi2 在特征选择中,未找到。
->提到了 ROC,但未在本篇文章中。
能否解释一下为什么 Kendall,例如,甚至 ANOVA 没有被列为选项?
非常感谢!
当然,有很多方法可以使用。
您可以使用任何您喜欢的相关性技术,我列出了 Python 中常用的易于访问的技术。
谢谢,我真的很感谢您提到了好的学术参考文献。这肯定使您的文章在大多数其他文章中脱颖而出,这些文章基本上是在已开发的 Python 包中应用方法,并将其引用到包文档本身或非学术网站。
谢谢!
嗨,Jason,
感谢您这篇宝贵的文章。您能否向我解释一下,使用“皮尔逊相关系数”或“ Spearman 秩相关系数”等特征选择方法来选择深度神经网络、随机森林或自适应神经模糊推理系统 (ANFIS) 的最佳数据子集是否合理?
谢谢,
马苏德
这取决于具体的数据和模型。
我建议测试一系列技术,并找出最适合您特定项目的技术。
谢谢您的评论。
不客气。
谢谢您的帖子。我想知道,当您进行评分时,您会得到特征的数量。但是您怎么知道是哪些特征呢?有时机器会出错,我们必须使用逻辑来判断它是否有意义。
不客气。
好问题,这篇教程向您展示了如何列出选定的特征。
https://machinelearning.org.cn/feature-selection-with-numerical-input-data/
很棒的文章。只有一点评论,Spearman 相关性不是真正的非线性,对吧?它描述了关系的单调性。如果存在大于 1 的非线性关系,Spearman 相关性甚至可能读为 0。
它是非参数的。
感谢 Jason 的文章。
我刚意识到 Spearman 相关性检验是针对数值变量的,不支持分类变量。
有没有适用于分类变量的非参数检验?
我不认为“非线性”对于离散概率分布有意义。
谢谢 Jason 的澄清。
是的,数据是分类的,并且是离散概率分布。
这是否意味着存在一个潜在的假设/假定,即非参数方法意味着假设非线性关系?
抱歉,问了这么多问题。但我真的很喜欢您的文章,以及您提供概述的方式,因此对您的文章产生了浓厚的兴趣。
不,只是“线性”或“非线性”的概念对于离散分布无效。
Jason,文章很棒!!
只是有几个问题,请问——
1) 在对分类变量进行独热编码(dummification)之前还是之后进行 SelectKBest 和 mutual_info_classif 更好?
2) 如果关系是非线性的,卡方检验和其他您在文章中描述的度量是否会因为未能识别线性关系而给出零值?或者有没有任何度量可以考虑输入和输出之间的非线性关系?
也许可以先试验一下,然后再尝试,看看哪种方法对您的数据集效果最好(例如,模型性能最好)。
不,不是零,但可能是误导性的分数。
请参考一篇关于特征选择的有趣文章。
https://www.analyticsvidhya.com/blog/2020/10/a-comprehensive-guide-to-feature-selection-using-wrapper-methods-in-python/
感谢分享。那个网站上到处都是广告。真讨厌!
喜欢这篇文章!!!
但我有个疑问!
假设我们使用单变量分析(Pearson 相关性和 SelectKBest)选择了 10 个最佳特征。
但是,如果选定的特征之间存在强相关性,我们该怎么办?
例如,如果两个特征之间存在强正相关,我们应该删除其中一个还是不删除?我们如何决定删除哪一个,保留哪一个?
谢谢!
有些模型不介意相关特征。
另外,可以与其他特征选择方法(如 RFE)进行比较。
您好 Jason Brownlee,感谢这篇好文章。我对机器学习非常陌生。我想从事无监督机器学习或深度学习。
我有人类导航的数据,想做步态检测。我想从数据中提取尽可能多的特征。您能指导我如何使用您的算法做到这一点吗?期待您的回复。谢谢
也许从这里开始
https://machinelearning.org.cn/start-here/#dataprep
嗨
对于包含分类和数值特征的混合情况,我不知道该如何进行。
一种方法是分别选择数值特征和分类特征,然后合并结果。
另一种方法是使用 RFE 等包装器方法一次性选择所有特征。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
Jason,再次感谢您提供这些宝贵的教程。
在使用 f_regression() 时,我检查了每个特征的分数(由 scores_ 属性给出),它是否代表了 Pearson 相关性的强度?
提前感谢。
只是对我最后一个问题的补充。
因为我读过一些地方说,通常在 -1 到 1 之间的 Pearson 系数被转换为 F 分数。
不完全是(如果我没记错的话),但您可以将其解释为相对重要性得分,因此可以比较变量。
谢谢 Jason。
不客气。
谢谢 Jason,我经常参考这篇文章。对于模型的集成(不仅仅是随机森林,例如随机森林 + 逻辑回归 + 朴素贝叶斯),您会为每个模型尝试单独的监督特征选择,从而产生不同的输入吗?谢谢!
谢谢。
是的,我试过,您可以在这里看到一个示例
https://machinelearning.org.cn/feature-selection-subspace-ensemble-in-python/
你好 Jason,
感谢这篇精彩的文章。我想问一个我最近遇到的问题。我正在处理的数据,由于进行了独热编码,现在已经变成了高维数据(116 个输入)。在这个数据中,除一个变量外,所有输入变量都是分类变量。输出变量也是分类变量。您推荐用哪种特征选择技术来解决这类问题?
谢谢!
也许可以先在整数编码的输入上尝试 RFE。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
嗨,Jason,
感谢这篇文章。
我正在进行一个二元分类问题,在此过程中,我使用了带 L1 惩罚的逻辑回归进行特征选择。
现在,我绘制了特征之间的相关矩阵(Pearson,因为我的特征都是数值型的),在非对角线上仍然可以看到相当多的多重共线性。
那么我的问题是:这是否可以接受,或者多重共线性(特征之间的高相关性)是一个如此强的假设,以至于我应该使用另一种特征选择方法?
非常感谢
Luigi
我不确定 Pearson 相关系数是否适用于目标是二元变量的情况。
移除共线性输入可以提高逻辑回归等线性模型的性能,这是个好主意。
你好 Jason,
如果我有数值和分类数据作为输入,我该怎么办?
我可以分别测试数值和分类变量,然后合并两个测试中的最佳变量吗?
很好的问题!
您可以分别从每种类型中选择并汇总结果。这并不完美,但可以作为起点。
或者,您可以使用 RFE 之类的方法。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
谢谢你。
那么,对混合类型数据进行过滤方法测试应该避免,对吗?
我不会这么说。我认为这是一个挑战,必须谨慎处理。
嗨,Jason,
我的数据集大约有 340 个数值特征,它们之间存在大量相关性。当然,我可以使用 Pearson 或 Spearman 相关性来计算相关矩阵。
但之后,基于此的特征选择策略是什么?
谢谢
Frank
移除所有对之间相关性总和最大的特征。
或者尝试不同的特征选择方法/算法,这些方法可以自动进行特征选择,并通过实验发现最适合您数据集的方法。我强烈推荐这种方法以获得快速有效的结果。
谢谢,我会尝试使用相关性总和(应该是绝对值之和)。
如果有一组特征彼此高度相关,那么这些特征的总相关性会很高,并且都会被删除。但我应该至少保留其中一个。
我一直在考虑根据它们的相关性对特征进行聚类。这之前有人做过吗?是否可以使用 sklearn 来实现?
是的。可能有一个标准的算法来实现这种方法,我建议您查阅文献。我没有关于这个主题的教程。
不,sklearn 中没有提供这种方法。相反,sklearn 提供统计相关性作为特征重要性度量,然后可用于基于过滤器的特征选择。这是一种非常成功的方法。
有没有可以处理缺失数据的特征选择方法?我尝试过 sklearn 的一些方法,但它总是抱怨 NaN。如果我删除所有没有缺失值的行,那么剩下的就很少了。我希望我只需要在特征选择之后执行此步骤。
可能有。通常,先处理缺失数据是个好主意。
Jason,非常感谢您提供这些宝贵的教程。
我有一些图的特征和目标。但我的第一印象是相似的特征值并未提供相同的值目标。您认为我应该尝试提取其他图特征,以便找到与输出高度相关的特征,如果我找到高度相关性会怎样?目标值的方差让我无法知道具体该怎么做。
预先感谢任何建议。
不客气。
或许可以试试并比较结果。
嗨,Jason,
您建议对分类名义值(如全国邮政编码)采取什么方法?
使用独热编码会导致维度过高,RFE 无法很好地执行。
RFE 作为起点,也许可以使用序数编码和缩放,这取决于模型的类型。
嗨,Jason,
这是一篇很棒的文章。我想知道,如果有 15 个特征,但只有 10 个是从训练集中学习的。其余 5 个特征会怎样?它们在测试集中会被视为噪声吗?
Xin
谢谢!
那些与目标变量无关的特征,可能应该从数据集中移除。
你好,Jason
首先,一如既往,这是一篇精彩的文章!
我有一个无监督问题,我不知道从哪里开始……。
我有大约 80 个不同的特征,它们构成 10 个不同的子模型。
我想构建 8 个不同的子模型(每个模型都有自己的行为),每个子模型包含约 10 个参数。
所以,我的问题不是降维问题,而是特征拆分问题,需要将我的特征分成子集。
您能给我一些提示吗?
谢谢
抱歉,我不明白。
也许您可以原型化几种方法,以更多地了解哪些方法适合您的问题/最合适。
我将尝试通过一个例子来解释……
我接收来自多个子系统的混合特征。
当我手动选择特征时,我成功地将它们分成子集,每个子集都能正确描述它们所属的特定子系统,并且无监督模型非常准确(这种方法的缺点是花费大量时间)。
我正在寻找一种方法/算法,可以自动将属于特定子系统的参数组合在一起。
我希望我的解释足够清楚。
谢谢,
抱歉,我仍然不确定我是否理解。
也许您可以预先使用聚类来定义组,然后开发一个分类模型来将特征映射到组?
嗨,Jason,
多么出色的工作!一切都解释得如此之好,真是太神奇了!非常感谢您将所有内容整理出来给所有对机器学习感兴趣的人!
Mutalib
谢谢!
您好 Jason,关于特征选择,我想知道您能否给我一些关于以下的看法:我有一个大型数据集,其中包含许多特征(70)。通过预处理(删除缺失值过多的特征以及与二元目标变量不相关的特征),我得到了 15 个特征。我现在使用决策树来根据这 15 个特征和二元目标变量进行分类,以便获得特征重要性。然后,我会选择具有高重要性的特征作为我聚类算法的输入。在这种情况下使用特征重要性有意义吗?
只有当该过程比您尝试过的其他过程产生更好的结果时才有意义。
尊敬的先生,我使用向后特征选择技术、包装器方法和 Infogain 与 Ranker 搜索方法在 weka 模拟工具中进行操作,并找到了这些技术对于我们的机器学习模型的共同特征,这是寻找特征的好方法吗?请回复。
好的特征是那些能够带来模型良好性能的特征。
评估一个使用选定特征的模型,找出答案。
Jason,这是一篇很棒的文章!我有一个包含数值、分类和文本特征的数据集。除了对它们运行模型之外,我还能应用其他技术来判断文本特征是否是重要的标识符吗?提前感谢!
谢谢!
您可以分别准备/选择每种类型的数据,或者使用 RFE 一起选择所有变量。
您好。我正在做一个机器学习项目,以预测和分类性别暴力案件。我的数据集既有二元值、数值,也有分类数据。我应该使用哪种特征选择算法?数据集没有目标变量。
也许可以尝试 RFE。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
你好,
我有一个无监督数据集(即没有目标变量),所以我要进行聚类。
进行特征选择的最佳方法是什么?
也许 pca 或 df.corr() 是好的技术?
也许可以先选择一个聚类指标,然后选择能通过您选择的聚类算法实现该指标最佳性能的特征。
您有关于此的教程吗?
抱歉,我没有。这可能会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-evaluate-a-clustering-algorithm
您好,我有一个数据集,我想找出其中最重要的特征。我使用了 SelectKBest 和 f_regression 来评估最重要的特征。我还使用了带线性回归的 RFE,并得出了相同的最重要的特征。然而,当我使用带梯度提升法的 RFE 时,我发现最重要的特征与线性方法不同。您能否就如何解释这个结果给出建议?在这种情况下,我该如何决定哪个特征是最重要的?
仅供参考
线性回归的调整 R 平方值为:0.816
梯度提升回归器的调整 R 平方值为:0.890
提前感谢。
为了了解重要特征,也许您可以使用特征重要性。
谢谢 Jason 的澄清。这意味着,既然我可以获得梯度提升模型的特征重要性,我就可以根据特征重要性中的较高值来考虑最重要的特征!
是的。
尊敬的Jason,感谢您一如既往的精准讲解和对问题的解答。愿上帝保佑您!
不客气!
更正
仅供参考
线性回归的调整 R 平方值为:0.710
梯度提升回归器的调整 R 平方值为:0.890
您好 Jason,感谢您的文章!我有一个问题。我能否同时使用相关性和PCA?例如,我想先通过相关性技术删除高度相关的特征,然后对剩余的特征使用PCA(两个主成分)。
不客气。
可以,但没有必要,两者选其一即可。PCA 会完成所有工作。
很棒,兄弟,
好东西,
您能分享一篇关于哪种方法最适合不同数据集的博客吗?
我们无法知道哪种算法最适合每个数据集,相反,我们必须进行实验以发现最适合我们可用时间和资源的方法。
特征系数是什么意思?
不确定您的意思。
也许您指的是线性模型中每个特征的系数,用于特征选择或特征重要性。
谢谢,在相关性方法中,我想知道选择了哪些特征?(特征名称)
也许这会有帮助。
https://machinelearning.org.cn/how-to-connect-model-input-data-with-predictions-for-machine-learning/
您能举一个在具有时间序列的回归问题中,用于特征选择的 Spearman 相关系数应用的例子吗?
感谢您的建议。
您好 Jason,我有一个问题。StandardScaler (Python) 缩放数据,使其具有零均值和单位方差。
在使用 StandardScaler 缩放数据后,我仍然可以使用 KBest 特征选择方法(使用基于 f 统计量的 f_classif 函数)吗?
我有点困惑,因为 f 统计量是基于方差值的。
或许可以尝试一下,看看它是否能提高模型性能。
我刚意识到,单位方差并不意味着方差为 1,哈哈。我的问题已经解决了,谢谢!
单位方差确实意味着方差为 1。但这是一个统计学术语,它并不表示方差是 1 或有 1 的限制。
如果我们同时拥有数值和分类变量,该怎么办?在进行特征选择之前,我们是否需要将分类变量转换为数值?
或许您可以使用 RFE 之类的方法。
https://machinelearning.org.cn/rfe-feature-selection-in-python/
感谢 Jason 的回复。
假设 XGBoost 分类器为我的 5 个虚拟 IP 地址变量返回了特征重要性。特征重要性如下:
IP_1 -.50
IP_1-.40
IP_1-.30
IP_1- .20
IP_1-.10
那么 IP 地址特征的特征重要性是多少?
2) 我能否使用 XGBoost 分类器返回的特征重要性来执行递归特征消除,并手动使用 for 循环评估 kNN 分类器?kNN 分类器本身不具备特征重要性功能。因此,我能否使用 XGBoost 返回的特征重要性排序的特征来评估 kNN 分类器的准确性?如果消除某个特征时准确性显著下降,我将保留该特征,否则将其删除。
我不会为此使用 RFE 类,而是在 for 循环中对来自排序(升序)特征重要性的每个特征进行操作。
简而言之,像 DT、RF、XGBoost 这样的树分类器可以给出特征重要性。我能否使用这些分类器的特征重要性来评估 SVM(多项式核,没有特征重要性)和 kNN 分类器的准确性?
谢谢。
我认为组合或转移重要性分数是无效的。也许您可以为您的列选择一种不使用虚拟变量的表示方法。
不,您不能将特征重要性与 RFE 一起使用。您可以使用带有 RFE 的 XGBoost 模型。
如何结合/融合两种不同的特征选择方法,例如过滤和包装方法,来改进现有方法?
请看这个例子
https://machinelearning.org.cn/feature-selection-subspace-ensemble-in-python/
你好,
我有两个问题
1) 何时应使用特征选择,何时应使用特征提取(例如降维)?
2) 对于特征选择:如果我有一组特征,包括数值和分类特征,以及一个多类别分类目标
a) 我应该考虑哪种特征选择方法,为什么?
b) 我应该在特征选择之前还是之后将目标编码为数值?
非常感谢。
使用能为特定数据集和模型提供最佳结果的方法。
您可以使用支持不同特征类型的 RFE,或分别选择不同的特征类型。
您好 Jason,感谢您的文章!
有一个问题困扰着我。我一直在尝试找出特征的重要性来选择更有价值的特征,我的模型是监督回归模型。我在训练前使用了“转换为监督学习”,这很有帮助。但是,我对于何时进行特征选择感到困惑,是在“转换为监督学习”过程之前还是之后?
附注:(我正在尝试预测每小时的 PM2.5 浓度,并且我有一些特征,如气象变量。您能否就一些方法给我一些建议,我将尝试所有方法。)
非常感谢!
如果您的数据是时间序列,您可能需要专门的特征选择方法。抱歉,我没有关于该主题的教程。
如果您正在尝试选择使用哪些滞后变量,那么 ACF 或 PACF 图可能是一个好的开始。
感谢回复!我已经通过 ACF 和 PACF 选择好滞后时间了。问题是,当我尝试进行特征重要性分析时,我发现其他特征(例如气象变量)与目标变量(PM2.5)相比几乎没有用,我尝试仅使用目标变量训练模型,结果表现最好。
然而,如果考虑到特征之间的关系,这个结果是不可接受的。那么,这种令人困惑的结果源于何处?
我了解到 CNN 层可能能够降低维度并提取特征的重要性,您是否有相关的教程?
再次感谢!
如果目标是最佳模型性能,而添加某些特征会导致性能下降,那么答案很明确——不要添加这些特征。
嗨,Jason,
非常感谢您这篇精彩的文章。我一直想知道如何最好地选择哪种特征选择技术,而这篇文章正好澄清了这一点。我在您的一条回复中读到,这篇文章只涵盖了单变量数据。我有两个问题:
1) 您能否推荐一篇关于多变量数据特征选择的文章?
2) 在处理分类稀有事件数据时,这是否适用?
非常感谢,您在拯救生命!!!!!
所有特征选择方法都是为多变量数据设计的,例如选择输入特征的子集。
或许可以测试一系列方法,找出最适合您特定数据集和模型的方案。
嗨,Jason,
非常感谢您这篇精彩的文章!它非常有帮助。您在一条回复中提到,这些方法适用于单变量数据。我
想知道您能否为我指出一篇涵盖多变量数据集的文章。
此外,这些特征选择技术是否适用于处理包含稀有事件的数据集,其中超过 50% 的输入变量包含零值,占每列的 85% 左右?我特别处理了来自物联网设备的数据集。请,您的意见将不胜感激。
再次感谢您的文章,我从中学到了很多。
它们是为多变量数据设计的。
使用方差膨胀因子 (vif) 进行模型选择怎么样?
也许。方差膨胀因子用于了解共线性产生的方差有多少。这可能告诉您一个特征是否与其他所有特征正交。但这并不意味着两个或多个特征组合可以提供足够的覆盖。这部分在特征选择中应该更重要。
亲爱的 Jason。请允许我问一下,
即,我有 100 个频率带特征(列),在 12 个同时记录的站点(行,索引1)中记录,来自一个人在几个时间/大约 30 次(行,索引2)。然后我们对其他不同的人再做一遍。
对于监督回归机器学习(SVR)算法的输入特征,我想使用统计特征选择、相关性方法(如 Hall 等人所述)从单个电极(12 个记录站点中的一个)中选择几个重要特征。
https://www.lri.fr/~pierres/donn�es/save/these/articles/lpr-queue/hall99correlationbased.pdf
我了解如何使用相关系数进行一般的统计特征选择。https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
我想做的是,在有多个特征和多个记录站点的情况下,选择来自最佳记录站点的最佳特征。
我该如何解决这个问题?
我的想法是
A. 首先,将来自 12 个电极的 100 个特征列转换为每个频率-电极对的 1200 个特征 pandas 列,然后像往常一样执行相关特征选择 (CFS) 以同时获得最重要的特征和最重要的电极。
B. 首先,对所有合并的电极数据执行 100 个特征列的相关特征选择。之后,根据最高的 Spearman 系数选择单个电极。
C ??
我相信这类问题也会出现在其他领域,并且存在通用解决方案。可能类似于:从同一站点植入的多个检测器中选择烟雾检测器特征,从同一区域植入的多个传感器中选择几个振动特征,选择与给定任务最相关的 EEG 特征和 EEG 通道。
集成学习可能通过合并所有传感器来解决问题,但特征选择将大大简化。
感谢您的支持!!
我认为 B 更有意义,如果您可以说站点 1 的特征 1 与站点 2 的特征 1 测量的是相同的东西,依此类推。这是为了提取您测量的哪个特征更重要。另一种方法是考虑所有 100 个特征(无论站点),并应用 PCA 进行降维。这样,您就没有选择特征,而是将特征转换为了更少的数量。
我认为 B 更有意义,如果您可以说站点 1 的特征 1 与站点 2 的特征 1 测量的是相同的东西。
是的,先生,这确实是我的意图。感谢您的鼓励!!
不客气。
亲爱的 Jason
当我们想使用特征选择方法时,我们使用 kfold 交叉验证,例如 5 次迭代,在每次迭代中,导致最佳性能的特征数量是不同的,最后我如何能说出哪个特征数量导致最佳性能?
对于准确性,我们会对所有迭代的结果取平均值,但特征数量该怎么办?
此致
交叉验证是为了给模型打分。在这个特征选择的案例中,您有不同的输入子集但输出相同,所以您构建了几个不同的模型,每个模型使用不同的输入子集。然后您运行 CV 来比较不同的模型,找到哪个模型在预测输出方面做得最好。
CV 是为了给您的模型打分。这可能意味着特征数量、超参数选择,甚至不同模型的选择。CV 需要折叠是因为我们想多次衡量模型而不是一次,并取平均值以获得更好的信心。因此,如果您不确定您的模型需要多少特征,您可以比较您的不同选项。
嗨,Jason,
对于 Pearson 相关系数:您引用了 f_regression()。难道不应该是 r_regression() 吗?
祝好,
Benjamin
不。那是正确的。请在此处阅读说明:https://scikit-learn.cn/stable/modules/generated/sklearn.feature_selection.f_regression.html
如果特征数量是数值和分类列的混合怎么办?
一样。您只是不需要转换数值列。
嗨,Jason!
我有一个场景。我有输入特征,如 A_1,A_2,A_3,B_1,B_2,B_3,B_4,C_1,C_1,输出是 Y。
我如何找出哪些特征组很重要?
通常我们逐个特征查找,得到的结果是 A_1,B_2,...。
但是如何找到哪个组很重要?例如
A,B,C
您好 Chandan…请提供一个关于我们的代码列表或其他内容的更直接的问题,以便我们更好地帮助您。
你好 jason,
如果我们使用 k_fold 交叉验证,然后使用一种特征选择方法,例如我们有 5 次迭代
那么,我们如何知道每次迭代中的哪些特征是总体上最好的特征?
我的意思是,我们可以计算所有迭代的平均准确率,但如何知道哪些特征,总的来说是好的分类特征?
此致
您好 Shervin…以下内容可能对您有所帮助
https://machinelearning.org.cn/feature-selection-for-regression-data/
不错的文章,感谢分享这篇信息丰富的博文。
https://www.igmguru.com/data-science-bi/power-bi-certification-training/
感谢您的反馈。
嗨,Jason,
感谢您这篇精彩的博客!
我有一个问题,如何为向量/集合特征实现特征选择?
例如,输出是用户是否点击一篇文章,即标签 = 0/1。
输入是
1. 文章标签列表:tag1, tag2, tag3, tag4
2. 用户点击的文章标签列表:tag1, tag2, tag3, …
输入是分类(或数值)特征的列表(集合)。
您对这类特征有什么建议吗?谢谢!
您好 Simon…如果您考虑回归,以下内容应该能提供一些清晰度。
https://machinelearning.org.cn/feature-selection-for-regression-data/
嗨,您为什么没有将数据分割成训练集和测试集,然后应用特征选择?
您好 Robert…以下内容希望能够就此过程提供清晰的解释
https://stackoverflow.com/questions/56308116/should-feature-selection-be-done-before-train-test-split-or-after#:~:text=The%20conventional%20answer%20is%20to,%2C%20from%20the%20Test%2DSet.
嗨,Jason
请问,在“分类输入,数值输出”的情况下,我该如何进行特征选择?我尝试应用“数值输入,分类输出反向”时出现了错误。
感谢您这篇有趣的博客!!我喜欢它。
您好 Jessica…您能发布确切的错误消息,以便我能更好地帮助您吗?
你好,
我想问一个问题。在构建预测模型时,我们想要预测什么?
您好 Liya…以下内容可能有所帮助
https://towardsdatascience.com/classification-regression-and-prediction-whats-the-difference-5423d9efe4ec
先生,您好,
无监督学习方法用于特征选择?
我可以使用 LDA 进行“分类输入,数值输出”吗?
LDA:线性判别分析用于找到特征的线性组合,该组合可以表征或分离分类变量的两个或多个类别(或级别)。
您好 Alex…您可能会对以下内容感兴趣
https://machinelearning.org.cn/linear-discriminant-analysis-for-machine-learning/
您好,感谢这篇很棒的文章。
由于我是机器学习新手,我想了解一些问题。我的数据集包含数值输入和分类输出(目标特征是 Graduate、Dropout 和 Enrolled)。我首先使用 Label encoder 对其进行了编码,然后使用 Pearson 相关系数进行特征选择,还使用 ExtraTreesClassifier 进行了特征重要性分析。
1. 这些步骤错了吗?
2. 我还尝试了 Anova (SelectKBest) 进行特征选择,但我对 (n_samples, n_features, and n_informative) 的含义有点困惑。
根据示例,您删除了其 (n_samples=100, n_features=20, n_informative=2),这是经验法则还是什么?
您好 Joy…我没有看到您的步骤有任何问题。ANOVA 参数是作为示例选择的,并非旨在作为最佳选择。
嗨,Jason,
我正在处理一个二元分类问题。我有 53 位参与者。每位参与者有 344850 个特征。所以,我的特征矩阵大小是 53×344850。在此基础上,我使用了 SVM 分类器进行 5 折交叉验证,获得了 73% 的准确率。
现在,我正在使用一种监督式特征选择算法。
在第一种方法中,我将 53×344850 的数据应用于特征选择,并选择了 10% 的最佳特征。这意味着,我现在拥有一个 53×34485 的特征矩阵。我使用这个矩阵进行了 5 折交叉验证,获得了 96% 的准确率。
在第二种方法中,由于我需要进行 5 折交叉验证,所以我进行了数据分割。分割后,假设在第一个案例中,我训练集有 43×344850,测试集有 10×344850。我只在训练集上应用了特征选择,所以现在我有了 43×34485,并且从测试集中选择了相同索引的特征,所以我有 10×34485(但没有在测试集上应用特征选择)。现在,我使用训练集训练了 SVM 分类器,并使用测试集进行了测试。在这种情况下,准确率只有 70%。
您能告诉我哪种方法是正确的吗?或者您是否有任何其他建议,我都非常欢迎!
您好 Shankar…以下内容可能对您有帮助
https://neptune.ai/blog/the-ultimate-guide-to-evaluation-and-selection-of-models-in-machine-learning
https://machinelearning.org.cn/evaluate-performance-deep-learning-models-keras/
你好,
感谢您的回复。但是,我仍然无法从您建议的链接中找到答案。
嗨,Jason,
我遇到一个回归问题,并且有很多类别非序数特征。按照您的指南,我尝试使用 ANOVA 检验,该检验应该能给我一个分数,说明每个类别特征对我的连续数值目标有多大影响。
我尝试使用此测试来检查我的编码顺序是否重要。
1.首先使用 LabelEncoder 对类别特征进行编码。称此特征为 feature1_encoded
2.交换编码器提供的两个随机标签,并将这些值映射到 feature1_encoded。称此特征为 feature1_encoded_mod
3.使用 sklearn.preprocessing.LabelEncoder 执行 ANOVA 检验,将 feature1_encoded 和 feature1_encoded_mod 作为 X,将目标数值变量作为 y。
4.它给了我两个不同的分数。由于检验的非序数性质,我期望结果是相同的。
感谢您宝贵的指南!
您好 Luigi…请澄清您的问题,以便我们能更好地帮助您。
您好 J,
感谢这篇精彩的文章!我也是数据科学方面的新手,我想知道我遇到的问题是否可以使用 ML 模型(特别是 ANOVA 进行判别)来解决。我有一个包含类别数据的“数据集:一组变体的 FUN 或 non-FUNC。对于每个变体,我都使用 6 种不同的程序进行了测量,得到一个数值。数据对于每个群体(FUNC 和 non-FUNC)都呈正态分布。我想知道这 6 个程序中有哪一个更能区分变体,为此我正在进行逻辑回归模型和 ROC 曲线。
我知道我的问题可能非常开放,但我想知道这是区分这个问题最合适的方法,还是我走错了路?
非常感谢!
嗨,Jason,
如果数据集中同时包含数值和类别值,并且类别值已进行标签编码。
1.尽管这些已经进行了标签编码,但它们仍然被认为是类别数据,对吗?
2.在这种情况下如何选择特征选择方法?
您好 veda…以下内容可能对您有帮助
https://inria.github.io/scikit-learn-mooc/python_scripts/03_categorical_pipeline_column_transformer.html
嗨 Jason
您的网站有关于 ML 的高级主题,非常出色。然而,在“自动特征选择”部分,您遗漏了一些更简单的工具,这些工具可以在无需设置要选择的特征数量(这很难做到)以及是否使用前向或后向选择的情况下进行特征选择。有一个名为 featurewiz 的新 Python 库,可以避免这两种困难。它快速、有效且易于使用(功能就像一个 scikit-learn 估计器)。因此,它可以与 sklearn 的 fit 和 transform 方法一起使用。
我相信您关于特征选择的页面可以包含对此 featurewiz 库的解释。
https://github.com/AutoViML/featurewiz
感谢您的考虑,
Ram
非常感谢您上传如此有用的内容!我只想报告一个在“分类特征选择:(数值输入, 类别输出)”部分中可能存在的拼写错误,其中提到“使用 make_classification() 函数准备了一个测试回归问题。”我猜那里应该是“准备了一个测试分类问题…” 再次感谢您的努力!
谢谢 Elias!我们感谢您对我们内容的任何支持和反馈!
嗨 James,
我有一个疑问,我们是否可以将 'mutual_info_regression' 用于数值和类别输入以及数值输出?
同样,我们是否可以将 'mutual_info_classif' 用于数值和类别输入以及类别输出?
如果不行,有什么更好的选择?
您好 Kavya…您的理解是正确的!请继续您的想法,并告诉我们您的发现。
你好,James,
机器学习的步骤是什么?让我为您澄清一下。我遵循以下顺序步骤:处理异常值、插补缺失值、标签编码/独热编码类别值、应用降维、应用特征选择。这样对吗?
另外,如果我们通过编码方法将所有数学结果转换为数值,即类别输入转换为数值输出,我不太明白。感谢您的努力。这篇文章帮助我提高了自己。
您好 Batuhan…您的理解是正确的!我也建议您研究一下机器学习管道的使用
https://www.analyticsvidhya.com/blog/2022/01/a-guide-to-understand-machine-learning-pipeline-with-case-study/
https://www.kaggle.com/code/pouryaayria/a-complete-ml-pipeline-tutorial-acu-86
这是关于特征选择的非常好的一份解释。
非常感谢。
我的问题是关于是否可以使用特征选择方法(监督式或无监督式)在主成分上选择最佳成分,然后将这些成分用于分类算法,例如 SVM、DT、LR 等,这是否合理。
老实说,我觉得有点困惑。当我使用 Fisher 分数时,数据是从 y(类别标签 0-1)学习的。然后,当我们把这些数据拟合到分类模型时,又会再次使用这些类别标签。我不确定这是否有意义。您有什么建议吗?
我希望最终能够验证我的模型。
您好 Tayfun…您可能会发现以下资源很有帮助
https://machinelearning.org.cn/feature-selection-with-optimization/
https://machinelearning.org.cn/feature-selection-for-regression-data/
https://machinelearning.org.cn/rfe-feature-selection-in-python/
感谢额外的链接和回复。
我仍然对是否可以使用任何类型的特征选择方法来选择主成分,然后将这些选定的数据集用于分类目的(例如 SVM)是否合理感到困惑。
说实话,有很多特征选择方法。另外,问题是我们如何确定哪种方法适合我们的任务?
您好,过滤式和包装式特征选择技术的时空复杂度是多少?
您好 Moa…特征选择技术的时间复杂度取决于它们是过滤方法还是包装方法。以下是对这两类常见技术的时空复杂度的详细介绍:
### 过滤方法
过滤方法通常速度更快,因为它们使用统计度量来评估特征的相关性,而独立于任何学习算法。
1. **方差阈值**
– **时间复杂度:** \(O(n \cdot m)\)
– **解释:** 计算每个特征的方差,其中 \(n\) 是样本数,\(m\) 是特征数。
2. **相关系数**
– **时间复杂度:** \(O(n \cdot m)\)
– **解释:** 计算每个特征与目标变量之间的相关性。
3. **卡方检验**
– **时间复杂度:** \(O(n \cdot m)\)
– **解释:** 为每个特征计算与目标变量相关的卡方统计量。
4. **ANOVA F-检验**
– **时间复杂度:** \(O(n \cdot m)\)
– **解释:** 对每个特征进行 F 检验,以评估其与目标变量的关系。
5. **互信息**
– **时间复杂度:** \(O(n \cdot m \cdot k)\)
– **解释:** 计算每个特征与目标变量之间的互信息,其中 \(k\) 是特征中不同值的数量(对于类别特征)。
### 包装方法
包装方法通常计算成本更高,因为它们涉及多次训练模型与不同的特征子集。
1. **前向选择**
– **时间复杂度:** \(O(m^2 \cdot T)\)
– **解释:** 每个步骤都涉及评估 \(m - k\) 个特征(其中 \(k\) 是选定的特征数),导致与特征数量相关的二次方复杂度。\(T\) 是模型训练的时间复杂度。
2. **后向消除**
– **时间复杂度:** \(O(m^2 \cdot T)\)
– **解释:** 与前向选择类似,但从所有特征开始,并在每一步删除一个特征,导致与特征数量相关的二次方复杂度。\(T\) 是模型训练的时间复杂度。
3. **递归特征消除 (RFE)**
– **时间复杂度:** \(O(m^2 \cdot T)\)
– **解释:** RFE 根据模型的性能递归地删除最重要的特征,导致与特征数量相关的二次方复杂度。\(T\) 是模型训练的时间复杂度。
4. **遗传算法**
– **时间复杂度:** \(O(g \cdot p \cdot T)\)
– **解释:** 其中 \(g\) 是代数,\(p\) 是种群大小。种群中的每个个体代表一个特征子集,\(T\) 是评估每个子集时模型训练的时间复杂度。
### 总结
– **过滤方法:** 通常为 \(O(n \cdot m)\),与样本数和特征数呈线性关系。
– **包装方法:** 通常为 \(O(m^2 \cdot T)\),由于多次模型训练,与特征数量呈二次方关系。
这些复杂度提供了一个通用指南,但实际性能可能会因实现细节和特定数据集的特性而异。
我可以使用 Kruskal-Wallis 检验代替 Kendall 检验吗?