在预测建模项目中,可以使用各种不同类型的**数据准备技术**。
在某些情况下,数据的分布或机器学习模型的要求可能会提示所需的数据准备,尽管考虑到数据的复杂性和高维度、不断涌现的新机器学习算法以及从业者有限(尽管是人为的)的限制,这种情况很少发生。
相反,数据准备可以被视为建模流程中另一个需要调整的超参数。这引出了一个问题:如何知道在搜索中要考虑哪些数据准备方法,这对于专家和初学者来说都可能感到不知所措。
解决方案是以结构化的方式思考数据准备这个广阔的领域,并根据数据准备技术对原始数据的影响系统地评估它们。
在本教程中,您将发现一个框架,它提供了一种结构化的方法来思考和分组用于结构化数据的预测建模的数据准备技术。
完成本教程后,您将了解:
- 将数据准备视为机器学习建模流程中另一个需要调整的超参数所带来的挑战和困扰。
- 一个定义了五个数据准备技术组的框架,可供考虑。
- 属于每个组的数据准备技术示例,可以在您的预测建模项目中进行评估。
通过我的新书《机器学习数据准备》**启动您的项目**,其中包括**分步教程**和所有示例的**Python 源代码**文件。
让我们开始吧。

机器学习中数据准备技术的框架
图片来源:Phil Dolby,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 数据准备的挑战
- 数据准备框架
- 数据准备技术
数据准备的挑战
数据准备是指将原始数据转换为更适合预测建模的形式。
这可能是因为数据本身包含错误。也可能是因为所选算法对数据的类型和分布有要求。
为了使数据准备任务更具挑战性,通常情况下,为了从预测模型中获得最佳性能所需的数据准备可能并不明显,并且可能弯曲或违反正在使用的模型的期望。
因此,通常将应用于原始数据的选择和配置视为建模流程中另一个需要调整的超参数。
这种数据准备的框架在实践中非常有效,因为它允许您使用网格搜索和随机搜索等自动搜索技术来发现非直觉的数据准备步骤,从而产生熟练的预测模型。
鉴于数据准备技术的种类繁多,这种数据准备的框架也可能让初学者感到不知所措。
解决这种不知所措的办法是系统地思考数据准备技术。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据准备框架
有效的数据准备需要以结构化和系统化的方式组织和考虑可用的数据准备技术。
这可以确保为您的数据集探索了方法技术,并且不会跳过或忽略潜在的有效技术。
这可以通过使用框架来组织数据准备技术来实现,该框架考虑了它们对原始数据集的影响。
例如,结构化机器学习数据(例如我们可能存储在 CSV 文件中用于分类和回归的数据)由行、列和值组成。我们可以考虑在每个这些级别上操作的数据准备技术。
- 行的数据准备
- 列的数据准备
- 值的数据准备
行的数据准备可以是添加或删除数据集中数据行的技术。类似地,列的数据准备可以是添加或删除数据集中列(特征或变量)的技术。而值的数据准备可以是更改数据集中值(通常针对给定列)的技术。
还有一种数据准备不完全符合这种结构,那就是降维技术。这些技术同时改变列和值,例如将数据投影到较低维空间中。
- 列 + 值的数据准备
这提出了同时适用于行和值的技术问题。这可能包括以某种方式合并数据行的数据准备。
- 行 + 值的数据准备
我们可以在下图中总结这个框架和一些高层次的数据准备方法组。
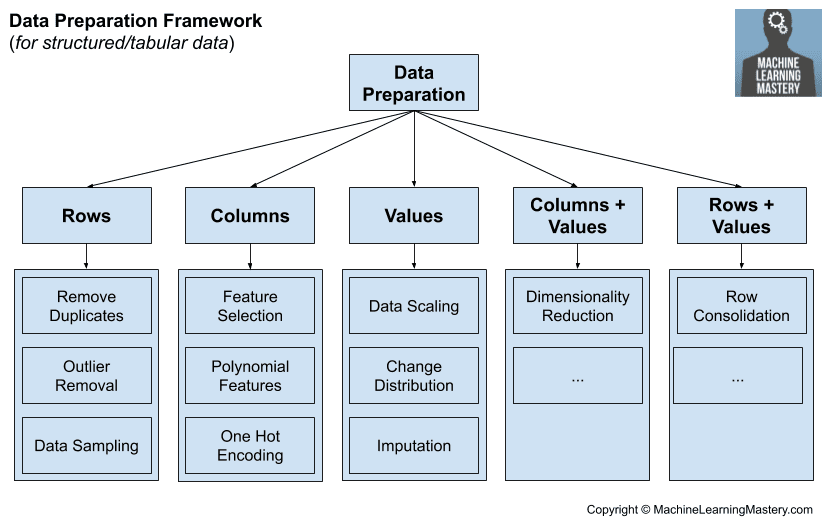
机器学习数据准备框架
现在我们有了一个根据其对数据的影响来思考数据准备的框架,让我们看看适合每个组的技术示例。
数据准备技术
本节探讨了上一节中定义的五个高层次数据准备技术组,并提出了可能属于每个组的具体技术。
我是否遗漏了您首选或最喜欢的数据准备技术之一?
在下面的评论中告诉我。
行的数据准备
此组用于添加或删除数据行的数据准备技术。
在机器学习中,行通常被称为样本、示例或实例。
这些技术通常用于扩充有限的训练数据集,或从数据集中删除错误或歧义。
首先想到的主要技术类别是通常用于不平衡分类的数据准备技术。
这包括 SMOTE 等技术,它们为欠代表的类别创建合成的训练数据行,以及随机欠采样,它删除过度代表的类别的示例。
有关 SMOTE 数据采样,请参阅教程
它还包括更高级的组合过采样和欠采样技术,这些技术试图识别和删除分类问题决策边界上的模糊示例,并删除它们或更改其类别标签。
有关这些类型的数据准备,请参阅教程
这类数据准备技术还包括用于识别和删除数据中异常值的算法。这些数据行可能远离数据集的概率质量中心,因此可能无法代表来自该领域的数据。
有关异常值检测和删除方法的更多信息,请参阅教程
列的数据准备
此组用于添加或删除数据列的数据准备技术。
在机器学习中,列通常被称为变量或特征。
这些技术通常需要用于降低预测问题的复杂性(维度)或分解复合输入变量或特征之间的复杂交互。
首先想到的主要技术类别是特征选择技术。
这包括使用统计数据根据每个数据类型对输入变量与目标变量的相关性进行评分的技术。
有关这些类型的数据准备技术,请参阅教程
这还包括系统地测试不同输入变量组合对机器学习模型预测能力影响的特征选择技术。
有关这些方法的更多信息,请参阅教程
相关的技术是使用模型根据预测模型的用途对输入特征的重要性进行评分的方法,称为特征重要性方法。这些方法通常用于数据解释,尽管它们也可以用于特征选择。
有关这些方法的更多信息,请参阅教程
这组方法还让我想起了创建或派生新数据列(新特征)的技术。这些通常被称为特征工程,尽管有时整个数据准备领域都被称为特征工程。
例如,可以创建表示指数次幂值或特征乘法组合的新特征,并将其作为新列添加到数据集中。
有关这些类型的数据准备技术,请参阅教程
这还可能包括改变变量类型的数据转换,例如为分类变量创建虚拟变量,通常称为独热编码。
有关这些类型的数据准备技术,请参阅教程
值的数据准备
此组用于更改数据中原始值的数据准备技术。
这些技术通常需要满足特定机器学习算法的期望或要求。
首先想到的主要技术类别是改变输入变量的尺度或分布的数据转换。
例如,标准化和归一化等数据转换会改变数值输入变量的尺度。序数编码等数据转换会改变分类输入变量的类型。
还有许多用于改变输入变量分布的数据转换。
例如,离散化或分箱将数值输入变量的分布更改为具有序数排名的分类变量。
有关此类型数据转换的更多信息,请参阅教程
幂转换可用于改变数据分布,以消除偏差并使分布更接近正态(高斯)分布。
有关此方法的更多信息,请参阅教程
分位数转换是一种灵活的数据准备技术,可以将数值输入变量映射到不同类型的分布,例如正态或高斯分布。
您可以在此处了解有关此数据准备技术的更多信息
属于此组的另一种数据准备技术是系统地更改数据集中值的方法。
这包括识别和替换缺失值的技术,通常称为缺失值插补。这可以通过统计方法或更高级的模型方法来实现。
有关这些方法的更多信息,请参阅教程
所有讨论的方法也可以被认为是特征工程方法(例如,适合前面讨论的数据准备方法组),如果转换结果作为新列附加到原始数据中。
列 + 值的数据准备
此组用于同时改变数据中列数和值的数据准备技术。
这让我想到的主要技术类别是降维技术,它们专门减少列数以及数值输入变量的尺度和分布。
这包括线性代数中使用的矩阵分解方法以及高维统计中使用的流形学习算法。
有关这些技术的更多信息,请参阅教程
尽管这些技术旨在在低维空间中创建行的投影,但也许这也为执行逆操作的技术打开了大门。也就是说,使用所有或一部分输入变量来创建到更高维空间的投影,也许可以分解复杂的非线性关系。
也许结果替换原始数据集的多项式变换将适合这类数据准备方法。
您知道还有哪些方法适合此组吗?
在下面的评论中告诉我。
行 + 值的数据准备
此组用于同时更改数据中行数和值的数据准备技术。
我之前没有明确考虑过这种类型的数据转换,但它符合所定义的框架。
我想到的方法组是聚类算法,其中数据集中所有或部分数据行都被替换为聚类中心(称为聚类质心)的数据样本。
相关的可能包括用从特定机器学习算法中提取的示例(行的聚合)替换行,例如支持向量机中的支持向量,或学习向量量化中提取的码本向量。
当然,如果这些聚合行只是添加到数据集中而不是替换行,那么它们将自然地适合上述“*行的数据准备*”组。
您知道还有哪些方法适合此组吗?
在下面的评论中告诉我。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
总结
在本教程中,您学习了一个框架,用于根据数据准备技术对原始数据的影响系统地对它们进行分组。
具体来说,你学到了:
- 将数据准备视为机器学习建模流程中另一个需要调整的超参数所带来的挑战和困扰。
- 一个定义了五个数据准备技术组的框架,可供考虑。
- 属于每个组的数据准备技术示例,可以在您的预测建模项目中进行评估。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







太棒了!那张图几乎解释了一切。感谢您发布如此有益的文章
不客气。很高兴它有帮助!
没错,这张图太棒了。非常感谢,Jason!
不客气。
对图表的一点反馈:我认为锦上添花的是,如果列中的步骤按“对于行,我们通常先做这个……,其次是这个……”等顺序排列。
感谢您的建议!
感谢您这篇信息量巨大的文章!
我邀请您阅读 Medium.com 上的文章“A framework for feature engineering and machine learning pipelines”。我认为它与您的文章非常互补。尽管作者只涉及管道的“特征工程”部分,但他提出了一个框架,其中新特征可以按特定顺序计算(仅是“行级操作”、“列级操作”等特征)。
这是链接:https://medium.com/manomano-tech/a-framework-for-feature-engineering-and-machine-learning-pipelines-ddb53867a420
附言:我刚刚完成硕士论文。我想感谢您在此网站上分享的所有代码和解释,因为它们对于解决我遇到的一些问题(例如使用 SMOTE 进行不平衡分类)非常有用。
感谢分享,Filipe。
你的论文做得很好!不客气。
你好 Jason,我是您博客的长期读者,但这是我第一次评论。我是一名数据科学家,几乎每天都会参考您的帖子/书籍。
我不得不说谢谢,因为这些“框架”帖子太有帮助了!这些“框架”帖子特别有助于在执行任务、重温旧主题或学习新主题时提供所有可能性的高级概述。这张简单的图表解决了“我不知道我不知道什么”的问题!这些可以作为读者了解您的每个优秀主题的入口点/路线图。
一个小小的建议,为了使这篇帖子真正全面(代表“数据准备”主题中的所有帖子),请将数据泄露添加到此帖子中,并链接您精彩的文章 https://machinelearning.org.cn/data-preparation-without-data-leakage/
继续努力!我很乐意看到您对新“框架”帖子的计划,因为我一直在收集一些主题的资源供个人使用(例如解释/调试机器学习预测),如果您有兴趣,我可以将它们发送给您 🙂
谢谢!
非常欢迎。
感谢您的建议。数据泄露更多的是在使用数据准备时需要考虑/避免的事情,而不是数据准备技术。它不完全符合,是正交的。
您也应该将此框架纳入您的《机器学习数据准备》一书中。
感谢您的建议。
我觉得它太高级了,或者与本书主题不符。
也许透视表可以证明一个行+列类别是合理的?
好建议
https://zh.wikipedia.org/wiki/Pivot_table
我看了你的博客,真的很有帮助。你非常简明地解释了机器学习课程。感谢分享这个博客。
谢谢。
嗨 Jason
干得漂亮!
只是一个小的评论。关于行的数据准备,我漏掉了名为实例选择的技术。我认为这是一个非常重要的补充主题。
祝好
谢谢你的建议!
你好 Jason,很棒的文章,组织得很好。
你能分享一些好的资源来了解“从学习向量量化中获取的码本向量”吗?
谢谢。
也许从这里开始
https://machinelearning.org.cn/implement-learning-vector-quantization-scratch-python/
谢谢你,Jason。
不客气。
谢谢你,Jason!
不客气。
谢谢你,Jason,你真是天赐之物。
不客气。
嗨,Jason,
一如既往,精彩的教程!
谢谢!
很棒的文章!非常感谢您分享您的知识。
谢谢!
Jason,你写了一系列很棒的文章。它将把我这样的机器学习新手带入“在机器学习方面变得更好”的课程。
我正在寻找简单的技术和示例,以从我开发的模型中进行预测。如果您能提供帮助,谢谢。
谢谢!
这将帮助您进行预测
https://machinelearning.org.cn/make-predictions-scikit-learn/
很棒的文章!您是否有关于“非结构化数据的数据准备框架”的讨论?我很想看看您的图表内容在非结构化情况下如何变化。
谢谢!
您所说的非结构化数据是什么意思?不是表格数据?像图像和文本?
嗨,Jason,
在您的框架中(行、列、值、列+值、行+值),您会将“分组依据”和“连接”操作归入哪个类别?
祝好,
哈拉尔德
也许是“数据准备”之前的步骤,例如反范式化。
我明白了……那么您认为“选择”(选择行)或“投影”(选择列)等操作不属于数据准备吗?
我想这会符合你的框架,因为“投影”也会减少列的数量……但是,你会如何分组这些操作呢? 🙂
它们确实如此,但收集数据或特定于领域的反范式化可能是更通用方法之前的步骤。
嗨,Jason,
我有超参数调整的例子(例如,列表 9.15:评估模型时比较 KNNImputer 转换中使用的邻居数量的例子)和比较算法的例子(例如,列表 13.1:比较多个算法的例子),但是否可以将其扩展到包括插补器和降维的各种组合?换句话说,对于每种算法,尝试两种或更多种插补方法,在这些方法中,尝试两种或更多种特征选择方法,在这些方法中进行超参数调整。您知道这样的例子吗?我提出的建议也可能是多余的/有更好的方法。
谢谢
当然,试试看是否有帮助。
你好,Jason。好帖子。我有一个问题,数据准备的第一步应该是什么?插补缺失数据还是缩放/标准化?谢谢!
这真的要看情况。
也许可以尝试不同的排序,看看哪种最适合您的数据/模型/管道。