许多初学者最初会依赖训练-测试方法来评估他们的模型。这种方法很简单,并且似乎能清晰地表明模型在未见过的数据上的表现。然而,这种方法常常会导致对模型能力的不完全理解。在这篇博客中,我们将讨论为什么超越基本的训练-测试分割很重要,以及交叉验证如何提供对模型性能更全面的评估。加入我们,我们将指导您完成实现更深入、更准确的模型评估的关键步骤。
通过我的书《进阶数据科学》启动您的项目。它提供了带有可运行代码的自学教程。
让我们开始吧。

从训练-测试到交叉验证:提升您的模型评估能力
照片作者 Belinda Fewings。部分权利保留。
概述
这篇博文分为三部分;它们是:
- 模型评估:训练-测试与交叉验证
- 交叉验证的“为什么”
- 深入K折交叉验证
模型评估:训练-测试与交叉验证
机器学习模型的确定性在于其设计(例如,线性模型与非线性模型)及其参数(例如,线性回归模型中的系数)。在考虑如何拟合模型之前,您需要确保模型适合数据。
机器学习模型的性能是通过其在先前未见过(或测试)数据上的表现来衡量的。在标准的训练-测试分割中,我们将数据集分为两部分:大部分用于训练模型,小部分用于测试其性能。如果测试性能可接受,则模型是合适的。这种方法很简单,但并不总是最有效地利用我们的数据。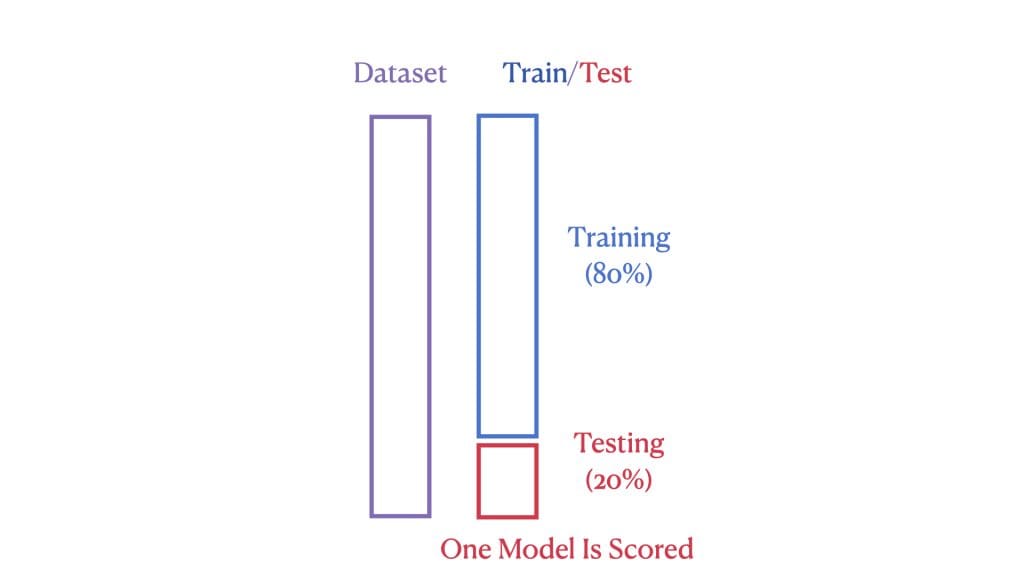
然而,通过交叉验证,我们更进一步。第二张图展示了5折交叉验证,其中数据集被分成五个“折”。在每次验证回合中,使用不同的折作为测试集,其余的作为训练集。这个过程重复五次,确保每个数据点都用于训练和测试。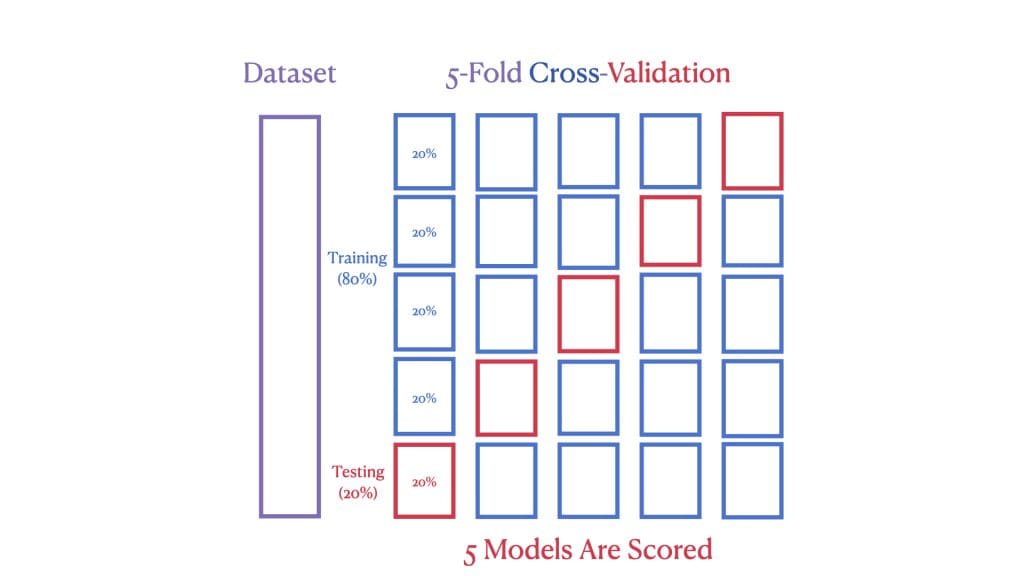
以下是一个说明上述内容的示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 加载Ames数据集 import pandas as pd Ames = pd.read_csv('Ames.csv') # 从scikit-learn导入线性回归、训练-测试、交叉验证 来自 sklearn.linear_model 导入 LinearRegression from sklearn.model_selection import train_test_split, cross_val_score # 选择特征和目标 X = Ames[['GrLivArea']] # 特征:GrLivArea,一个二维矩阵 y = Ames['SalePrice'] # 目标:SalePrice,一个一维向量 # 将数据分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 使用训练-测试的线性回归模型 模型 = LinearRegression() model.fit(X_train, y_train) train_test_score = round(model.score(X_test, y_test), 4) print(f"训练-测试 R^2 分数: {train_test_score}") # 执行5折交叉验证 cv_scores = cross_val_score(model, X, y, cv=5) cv_scores_rounded = [round(score, 4) for score in cv_scores] print(f"交叉验证 R^2 分数: {cv_scores_rounded}") |
训练-测试方法产生一个单一的R²分数,而交叉验证则为我们提供了五个不同的R²分数,每个数据折一个,从而更全面地了解模型的性能。
|
1 2 |
训练-测试 R^2 分数: 0.4789 交叉验证 R^2 分数: [0.4884, 0.5412, 0.5214, 0.5454, 0.4673] |
这五个R²分数大致相等,表明模型是稳定的。然后您可以决定该模型(即线性回归)是否提供可接受的预测能力。
交叉验证的“为什么”
理解模型性能在不同数据子集上的变异性在机器学习中至关重要。训练-测试分割方法虽然有用,但只给了我们模型在某个特定未见过数据集上表现快照。
交叉验证通过系统地使用多个数据折进行训练和测试,提供了对模型性能更稳健、更全面的评估。每个折都作为一个独立的测试,深入了解模型在不同数据样本上的预期表现。这种多重性不仅有助于识别潜在的过拟合,还确保了性能指标(在此例中为R²分数)不过于乐观或悲观,而是模型泛化到未见过数据的更可靠的指标。
为了直观地展示这一点,让我们考虑来自训练-测试分割和5折交叉验证过程的R²分数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 导入Seaborn和Matplotlib import seaborn as sns import matplotlib.pyplot as plt # 假设cv_scores_rounded包含您的交叉验证分数 # 并且train_test_score是您的单一训练-测试R^2分数 # 绘制交叉验证分数的箱线图 cv_scores_df = pd.DataFrame(cv_scores_rounded, columns=['交叉验证分数']) sns.boxplot(data=cv_scores_df, y='交叉验证分数', width=0.3, color='lightblue', fliersize=0) # 将单个分数叠加为点 plt.scatter([0] * len(cv_scores_rounded), cv_scores_rounded, color='blue', label='交叉验证分数') plt.scatter(0, train_test_score, color='red', zorder=5, label='训练-测试分数') # 绘制图表 plt.title('模型评估:交叉验证 vs. 训练-测试') plt.ylabel('R^2 分数') plt.xticks([0], ['评估分数']) plt.legend(loc='lower left', bbox_to_anchor=(0, +0.1)) plt.show() |
这个可视化突显了从单一训练-测试评估中获得的见解与交叉验证提供的更广泛视角之间的差异。
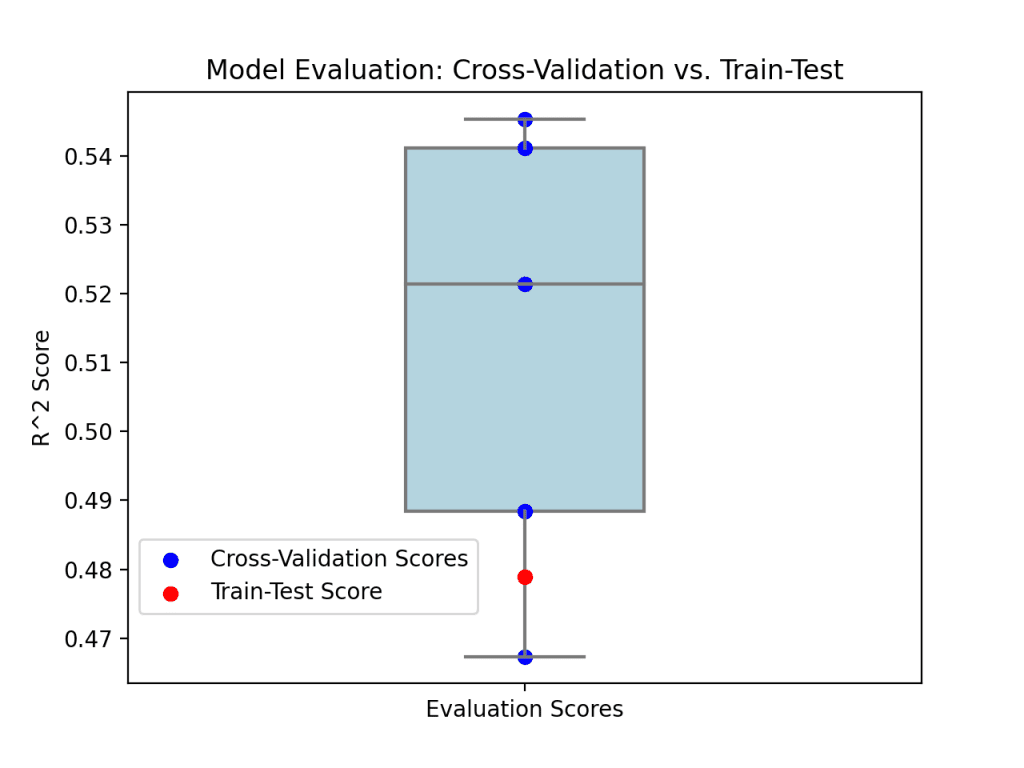
通过交叉验证,我们对模型的性能有了更深入的了解,使我们更接近开发有效且可靠的机器学习解决方案。
想开始学习进阶数据科学吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
深入K折交叉验证
交叉验证是可靠的机器学习模型评估的基石,其中cross_val_score()提供了执行此任务的快速自动化方法。现在,我们将注意力转向KFold类,它是scikit-learn的一个组件,它提供了对交叉验证折的深入了解。KFold类不仅提供分数,还提供了对模型在不同数据段上的性能的窗口。我们通过复制上述示例来演示这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 导入K-Fold及所需库 from sklearn.model_selection import KFold 来自 sklearn.linear_model 导入 LinearRegression from sklearn.metrics import r2_score # 选择特征和目标 X = Ames[['GrLivArea']].values # 转换为numpy数组以供KFold使用 y = Ames['SalePrice'].values # 转换为numpy数组以供KFold使用 # 初始化线性回归和K-Fold 模型 = LinearRegression() kf = KFold(n_splits=5) # 手动执行K-Fold交叉验证 for fold, (train_index, test_index) in enumerate(kf.split(X), start=1): # 将数据分割为训练集和测试集 X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # 拟合模型并预测 model.fit(X_train, y_train) y_pred = model.predict(X_test) # 计算并打印当前折的R^2分数 print(f"折 {fold}:") print(f"训练集大小: {len(train_index)}") print(f"测试集大小: {len(test_index)}") print(f"R^2 分数: {round(r2_score(y_test, y_pred), 4)}\n") |
此代码块将向我们展示每个训练集和测试集的大小以及每个折对应的R²分数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
折 1 训练集大小: 2063 测试集大小: 516 R^2 分数: 0.4884 折 2 训练集大小: 2063 测试集大小: 516 R^2 分数: 0.5412 折 3 训练集大小: 2063 测试集大小: 516 R^2 分数: 0.5214 折 4 训练集大小: 2063 测试集大小: 516 R^2 分数: 0.5454 折 5 训练集大小: 2064 测试集大小: 515 R^2 分数: 0.4673 |
KFold类在其透明性和对交叉验证过程的控制方面表现出色。虽然cross_val_score()将过程简化为一行,但KFold将其打开,允许我们查看数据分割的具体情况。当您需要以下操作时,这非常有价值:
- 了解数据是如何分割的。
- 在每次折叠前实现自定义预处理。
- 深入了解模型性能的一致性。
通过使用KFold类,您可以手动迭代每个分割并应用模型训练和测试过程。这不仅有助于确保您完全了解每个阶段使用的数据,还提供了修改过程以适应复杂需求的选项。
进一步阅读
API
- sklearn.model_selection.train_test_split API
- sklearn.model_selection.cross_val_score API
- sklearn.model_selection.KFold API
教程
Ames 住房数据集和数据字典
总结
在本帖中,我们探讨了通过交叉验证和KFold方法进行彻底模型评估的重要性。这两种技术都仔细地避免了数据泄露的陷阱,通过保持训练和测试数据分开,从而确保模型的性能得到准确衡量。此外,通过精确地验证每个数据点一次,并将其用于训练K-1次,这些方法提供了模型泛化能力的详细视图,增强了对其现实世界适用性的信心。通过实际示例,我们展示了如何将这些策略整合到您的评估过程中,可以带来更可靠、更稳健的机器学习模型,为应对新数据和未见过数据的挑战做好准备。
具体来说,你学到了:
cross_val_score()在自动化交叉验证过程中的效率。KFold如何提供对数据分割的详细控制,以进行量身定制的模型评估。- 这两种方法如何确保充分利用数据并防止数据泄露。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







暂无评论。