上下文向量是 transformer 模型生成的强大表示,它们捕获了单词在特定上下文中的含义。在我们之前的教程中,我们探讨了如何生成这些向量以及一些基本应用。现在,我们将重点构建利用上下文向量解决现实问题的实际应用。
在本教程中,我们将实现几个应用来展示上下文向量的强大功能和多功能性。我们将使用 Hugging Face transformers 库从预训练模型中提取上下文向量,并围绕它们构建应用程序。具体来说,您将学习:
- 使用上下文向量构建语义搜索引擎
- 创建文档聚类和主题建模应用程序
- 开发文档分类系统
通过我的书籍《Hugging Face Transformers中的NLP》,快速启动您的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

上下文向量的进一步应用
照片作者:Matheus Bertelli。保留部分权利。
概述
这篇博文分为三部分;它们是:
- 构建语义搜索引擎
- 文档聚类
- 文档分类
构建语义搜索引擎
如果您想在一系列文档中查找特定文档,您可能会使用简单的关键字搜索。然而,这种方法受到关键字匹配精度的限制。您可能不记得文档中使用的确切措辞,只记得它的内容。在这种情况下,语义搜索更有效。
语义搜索允许您通过含义而不是关键字进行搜索。每个文档都由捕获其含义的上下文向量表示,查询也表示为上下文向量。然后,搜索引擎使用 L2 距离或余弦相似度等相似性度量来查找与查询最相似的文档。
既然您已经学习了如何使用 transformer 模型生成上下文向量,让我们来实现一个简单的语义搜索引擎。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import torch import numpy as np from sklearn.metrics.pairwise import cosine_similarity from transformers import AutoTokenizer, AutoModel def get_context_vector(text, model, tokenizer): """通过平均池化获取上下文向量""" # Tokenize 输入,获取模型输出 inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512) with torch.no_grad(): outputs = model(**inputs) # 平均池化:取输出在序列长度上的平均值 pooled_vector = torch.mean(outputs.last_hidden_state, dim=1) return pooled_vector[0] def semantic_search(query, documents, document_vectors, top_k=2): """搜索语料库""" # 计算查询和所有文档之间的相似度 query_vector = get_context_vector(query, model, tokenizer) similarities = cosine_similarity([query_vector], document_vectors)[0] # 获取最相似的 top-k 文档的索引 top_indices = np.argsort(similarities)[::-1][:top_k] # 返回 top-k 文档及其相似度得分 results = [] for idx in top_indices: results.append({ "document": documents[idx], "similarity": similarities[idx] }) return results # 加载预训练模型和分词器 tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") model = AutoModel.from_pretrained("bert-base-uncased") # 创建一个文档语料库并将其转换为上下文向量 documents = [ "Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed.", "Deep learning is a subset of machine learning that uses neural networks with many layers.", "Natural language processing is a field of AI that focuses on the interaction between computers and human language.", "Computer vision is an interdisciplinary field that deals with how computers can gain high-level understanding from digital images or videos.", "Reinforcement learning is about taking suitable actions to maximize reward in a particular situation." ] document_vectors = [get_context_vector(doc, model, tokenizer) for doc in documents] # 示例搜索 query = "How do computers learn from data?" results = semantic_search(query, documents, document_vectors) # 打印结果 print(f"Query: {query}\n") for i, result in enumerate(results): print(f"Result {i+1} (Similarity: {result["similarity"]:.4f}):") print(result["document"]) print() |
在此示例中,上下文向量是使用 get_context_vector() 函数创建的。您可以将文本作为字符串或字符串列表传递,然后分词器和模型会产生张量输出。此输出是形状为 (batch size, sequence length, hidden size) 的矩阵。序列中的并非所有 token 都是有效的,因此您可以使用分词器生成的注意力掩码来识别有效 token。
每个输入字符串的上下文向量通过对其所有有效 token 嵌入求平均值来计算。请注意,还有其他创建上下文向量的方法,例如使用 [CLS] token 或不同的池化策略。
在此示例中,您从一系列文档和一个查询字符串开始。您为两者生成上下文向量,在 semantic_search() 中,使用余弦相似度将查询向量与所有文档向量进行比较,以查找最相似的 top-k 文档。
以上代码的输出是:
|
1 2 3 4 5 6 7 |
Query: How do computers learn from data? Result 1 (Similarity: 0.7573) Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed. Result 2 (Similarity: 0.7342) Computer vision is an interdisciplinary field that deals with how computers can gain high-level understanding from digital images or videos. |
您可以看到,语义搜索引擎理解查询背后的含义,而不仅仅是匹配关键字。但是,结果的质量取决于上下文向量表示文档和查询的程度,以及所使用的相似性度量。
文档聚类
文档聚类将相似的文档分组在一起。当组织大量文档时,这很有用。虽然您可以手动分类文档,但这种方法非常耗时。聚类是一种自动的、无监督的过程——您无需提供任何标签。算法根据它们的相似性将文档分组到群集中。
有了每个文档的上下文向量,您就可以使用任何标准的聚类算法。下面,我们使用 K-means 聚类。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
import matplotlib.pyplot as plt import numpy as np import torch from sklearn.cluster import KMeans 从 sklearn.分解 导入 PCA from transformers import AutoTokenizer, AutoModel def get_context_vector(text, model, tokenizer): """通过平均池化获取上下文向量""" # Tokenize 输入,获取模型输出 inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512) with torch.no_grad(): outputs = model(**inputs) # 平均池化:取输出在序列长度上的平均值 pooled_vector = torch.mean(outputs.last_hidden_state, dim=1) return pooled_vector[0] # 创建一个文档语料库(更多文档用于聚类) documents = [ "Machine learning algorithms build models based on sample data to make predictions without being explicitly programmed.", "Deep learning uses neural networks with many layers to learn representations of data with multiple levels of abstraction.", "Neural networks are computing systems inspired by the biological neural networks that constitute animal brains.", "Convolutional neural networks are deep neural networks most commonly applied to analyzing visual imagery.", "Natural language processing is a subfield of linguistics, computer science, and artificial intelligence.", "Sentiment analysis uses NLP to identify and extract opinions within text to determine writer's attitude.", "Named entity recognition is a subtask of information extraction that seeks to locate and classify named entities in text.", "Computer vision is an interdisciplinary field that deals with how computers can gain high-level understanding from digital images.", "Image recognition is the ability of software to identify objects, places, people, writing and actions in images.", "Object detection is a computer technology related to computer vision and image processing." ] # 为所有文档生成上下文向量 tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") model = AutoModel.from_pretrained("bert-base-uncased") document_vectors = np.array([get_context_vector(doc, model, tokenizer) for doc in documents]) # 对文档执行 K-means 聚类 num_clusters = 3 kmeans = KMeans(n_clusters=num_clusters, random_state=42) cluster_labels = kmeans.fit_predict(document_vectors) # 打印每个群集中的文档 for i in range(num_clusters): print(f"\nCluster {i+1}:") cluster_docs = [documents[j] for j in range(len(documents)) if cluster_labels[j] == i] for doc in cluster_docs: print(f"- {doc}") # 在降维空间中可视化聚类 pca = PCA(n_components=2) reduced_vectors = pca.fit_transform(document_vectors) plt.figure(figsize=(10, 6)) colors = ["red", "blue", "green"] for i in range(num_clusters): # 绘制每个群集中的点 cluster_points = reduced_vectors[cluster_labels == i] plt.scatter(cluster_points[:, 0], cluster_points[:, 1], c=colors[i], label=f"Cluster {i+1}") plt.title("Document Clusters") plt.xlabel("PCA Component 1") plt.ylabel("PCA Component 2") plt.legend() plt.grid(True) plt.show() |
在此示例中,使用与上一个示例相同的 get_context_vector() 函数为文档语料库生成上下文向量。每个文档都被转换为固定大小的上下文向量。然后,K-means 聚类算法将文档分组。群集数设置为 3,但您可以尝试其他值以查看哪个最合适。
以上代码的输出是:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Cluster 1 - Deep learning uses neural networks with many layers to learn representations of data with multiple levels of abstraction. - Neural networks are computing systems inspired by the biological neural networks that constitute animal brains. - Convolutional neural networks are deep neural networks most commonly applied to analyzing visual imagery. - Sentiment analysis uses NLP to identify and extract opinions within text to determine writer's attitude. Cluster 2 - Natural language processing is a subfield of linguistics, computer science, and artificial intelligence. - Named entity recognition is a subtask of information extraction that seeks to locate and classify named entities in text. - Computer vision is an interdisciplinary field that deals with how computers can gain high-level understanding from digital images. - Image recognition is the ability of software to identify objects, places, people, writing and actions in images. - Object detection is a computer technology related to computer vision and image processing. Cluster 3 - Machine learning algorithms build models based on sample data to make predictions without being explicitly programmed. |
聚类的质量取决于上下文向量和聚类算法。要评估结果,您可以使用主成分分析 (PCA) 将聚类可视化为 2D。PCA 将向量降至其前两个主成分,这些可以绘制在散点图中。
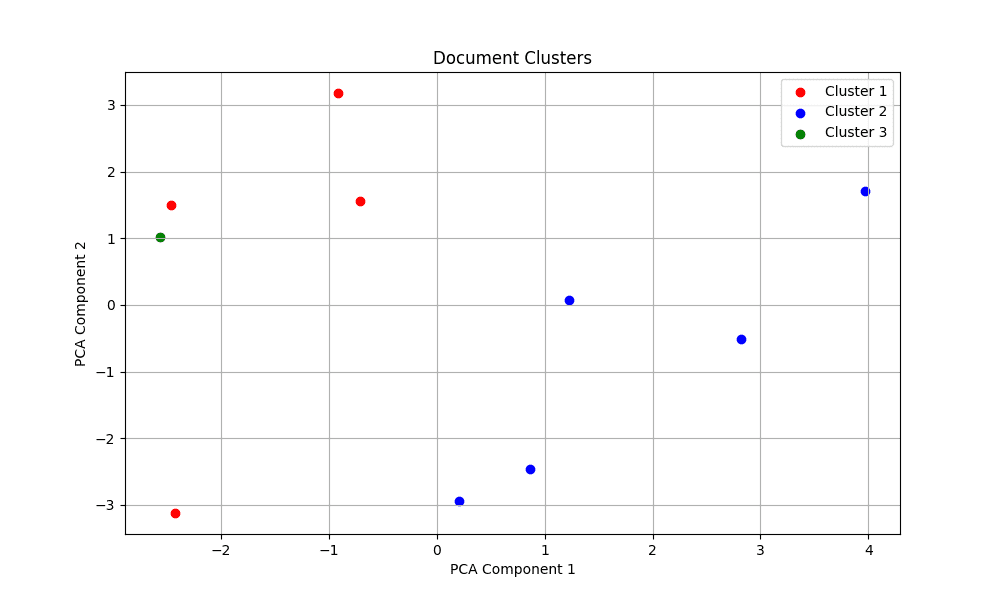 如果您看不到清晰的聚类——就像本例一样——这表明聚类效果不理想。您可能需要调整生成上下文向量的方式。但是,问题也可能是所有文档都与机器学习相关,因此强行将它们分成三个不同的群集可能没有意义。
如果您看不到清晰的聚类——就像本例一样——这表明聚类效果不理想。您可能需要调整生成上下文向量的方式。但是,问题也可能是所有文档都与机器学习相关,因此强行将它们分成三个不同的群集可能没有意义。
总的来说,文档聚类有助于自动发现文档集中的主题。要获得良好的结果,您需要一个中等大小且多样化的语料库,其中包含清晰的主题区分。
文档分类
如果您碰巧有文档的标签,您可以使用它们来训练分类器。这比聚类更进一步。有了标签,您就可以控制文档的 agrupamento。
您可能需要更多数据来训练一个可靠的分类器。下面,我们将使用逻辑回归分类器来对文档进行分类。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
from transformers import AutoTokenizer, AutoModel import torch import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report def get_context_vector(text, model, tokenizer): """通过平均池化获取上下文向量""" # Tokenize 输入,获取模型输出 inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512) with torch.no_grad(): outputs = model(**inputs) # 平均池化:取输出在序列长度上的平均值 pooled_vector = torch.mean(outputs.last_hidden_state, dim=1) return pooled_vector[0] # 创建带有标签的文本数据集 texts = [ "The stock market reached a new high today, with technology stocks leading the gains.", "The company reported strong quarterly earnings, exceeding analysts' expectations.", "Investors are optimistic about the economy despite recent inflation concerns.", "The new vaccine has shown high efficacy in clinical trials against all variants.", "Researchers have discovered a potential treatment for a previously incurable disease.", "The hospital announced expanded capacity to handle the increasing number of patients.", "The latest smartphone features a better camera and longer battery life.", "The software update includes new security features and performance improvements.", "The tech company unveiled its newest artificial intelligence system yesterday." ] labels = [ "Business", "Business", "Business", "Health", "Health", "Health", "Technology", "Technology", "Technology" ] # 为所有文本生成上下文向量 tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") model = AutoModel.from_pretrained("bert-base-uncased") text_vectors = np.array([get_context_vector(text, model, tokenizer) for text in texts]) # 将数据集分割为训练集和测试集,训练分类器,然后评估 X_train, X_test, y_train, y_test = train_test_split(text_vectors, labels, test_size=0.3, random_state=42) classifier = LogisticRegression(max_iter=1000) classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test) print(classification_report(y_test, y_pred)) # 分类新文本 new_texts = [ "The central bank has decided to keep interest rates unchanged.", "A new study shows that regular exercise can reduce the risk of heart disease.", "The new laptop has a faster processor and more memory than previous models." ] new_vectors = np.array([get_context_vector(text, model, tokenizer) for text in new_texts]) predictions = classifier.predict(new_vectors) # 打印预测结果 for text, prediction in zip(new_texts, predictions): print(f"Text: {text}") print(f"Category: {prediction}\n") |
上下文向量的生成方式与上一个示例相同。您不是进行聚类或手动比较相似度,而是向逻辑回归分类器提供一组标签(每个文档一个)。使用 scikit-learn 的实现,我们在训练集上训练模型,并在测试集上对其进行评估。
scikit-learn 的 classification_report() 函数提供了精确率、召回率、F1 分数和准确率等指标。结果如下所示:
|
1 2 3 4 5 6 7 8 9 |
精确率 召回率 f1分数 支持数 Business 0.50 1.00 0.67 1 Health 0.00 0.00 0.00 1 Technology 1.00 1.00 1.00 1 accuracy 0.67 3 macro avg 0.50 0.67 0.56 3 weighted avg 0.50 0.67 0.56 3 |
要使用训练好的分类器,请遵循相同的流程:使用 get_context_vector() 函数将新文本转换为上下文向量,然后将其传递给分类器以预测类别。运行上述代码时,您应该会看到:
|
1 2 3 4 5 6 7 8 |
Text: The central bank has decided to keep interest rates unchanged. Category: Business Text: A new study shows that regular exercise can reduce the risk of heart disease. Category: Health Text: The new laptop has a faster processor and more memory than previous models. Category: Technology |
请注意,分类器是在上下文向量上训练的,这些向量理想情况下捕获了文本的含义,而不仅仅是表面的关键字。因此,它应该能更有效地泛化到新输入,即使是那些包含未见过关键字的输入。
总结
在这篇文章中,您探讨了如何构建利用 transformer 模型生成的上下文向量的实际应用程序。具体来说,您实现了:
- 一个语义搜索引擎,用于查找与查询最相似的文档
- 一个文档聚类应用程序,用于将文档分组到有意义的类别中
- 一个文档分类系统,用于将文档分类到预定义的类别中
这些应用程序突显了上下文向量在理解和处理文本方面的强大功能和多功能性。通过利用 Transformer 模型的语义能力,您可以构建超越简单的关键词匹配或基于规则方法的复杂 NLP 系统。
想在您的NLP项目中使用强大的语言模型吗?

在您自己的机器上运行最先进的模型
...只需几行Python代码在我的新电子书中探索如何实现
使用 Hugging Face Transformers 进行自然语言处理
它涵盖了在以下任务上的实践示例和实际用例:文本分类、摘要、翻译、问答等等...
最终将高级NLP带入
您自己的项目
没有理论。只有实用的工作代码。






暂无评论。