访问 Stable Diffusion 模型并生成高质量图像有很多方法。一种流行的方法是使用 Diffusers Python 库。它为 Stable Diffusion 提供了一个简单的接口,可以轻松利用这些强大的 AI 图像生成模型。diffusers 库降低了使用尖端生成式 AI 的门槛,从而实现了快速的实验和开发。这个库非常强大。您不仅可以用它根据文本提示生成图片,还可以利用 LoRA 和 ControlNet 来创建更好的图片。
在本帖中,您将了解 Hugging Face 的 Diffusers,如何生成图像,以及如何应用各种与 Stable Diffusion WebUI 类似的图像生成技术。具体来说,您将学习如何
- 构建一个 Diffusers Pipeline 并使用提示生成简单的图像。
- 加载微调模型的 LoRA 权重并生成宜家风格的图像。
- 构建 ControlNet OpenPose pipeline,使用参考图像生成图像。
通过我的书《掌握 Stable Diffusion 数字艺术》来启动您的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

通过 Diffusers 进一步优化 Stable Diffusion 流水线
照片由 Felicia Buitenwerf 拍摄。部分权利保留。
概述
这篇文章分为三个部分;它们是
- 在 Google Colab 上使用 Diffusers
- 加载 LoRA 权重
- ControlNet OpenPose
在 Google Colab 上使用 Diffusers
Hugging Face 的 diffusers 是一个 Python 库,允许您访问预训练的扩散模型来生成逼真的图像、音频和 3D 分子结构。您可以使用它进行简单的推理或训练自己的扩散模型。该库的特别之处在于,只需几行代码,您就可以从 Hugging Face Hub 下载模型并用于生成图像,这与 Stable Diffusion WebUI 类似。
您将使用 Google Colab 的免费 GPU 笔记本电脑,而不是在本地设置。为此,请访问 https://colab.research.google.com/ 并创建一个新的笔记本。要访问 GPU,您必须转到“Runtime”->“Change runtime type”并选择“T4 GPU”选项。
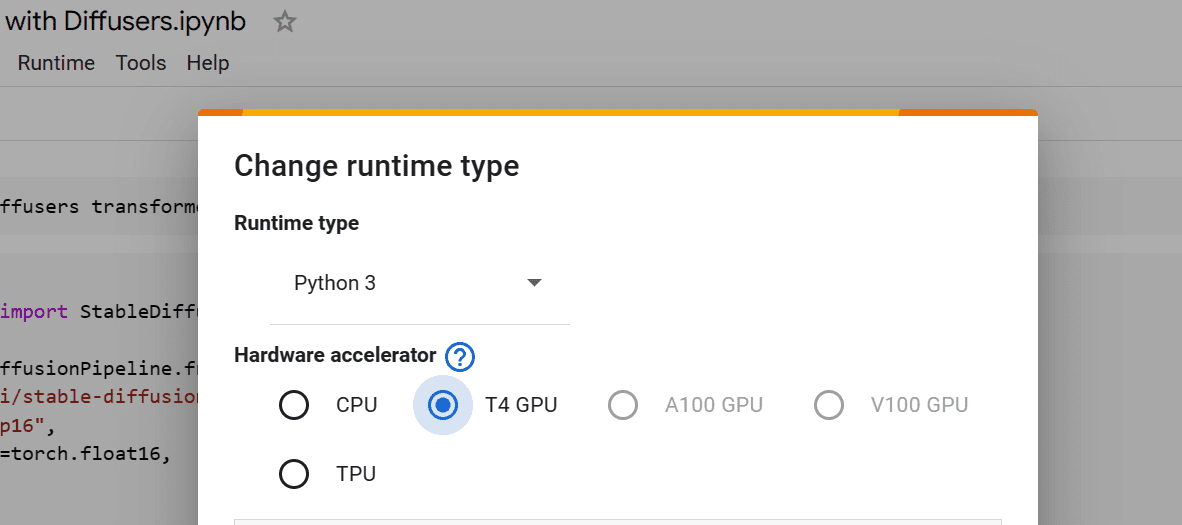
在 Google Colab 上选择 GPU
使用 Colab 可以让您免去拥有 GPU 设备来高效运行 Stable Diffusion 的负担。通过 Jupyter notebook 的特性,您只需将以下所有代码放在各自的单元格中运行即可。这对您进行实验会很方便。
之后,安装运行 diffusers pipeline 所需的所有 Python 库。您需要创建一个包含以下行的笔记本单元格
|
1 |
!pip install diffusers transformers scipy ftfy peft accelerate -q |
在 colab 笔记本中,行开头的 ! 表示这是一个系统命令,而不是 Python 代码。
要使用提示生成图像,您必须首先创建一个 Diffusion pipeline。接下来,您将下载并使用 Stable Diffusion XL 的“float 16”类型以节省内存。然后,您将设置一个 pipeline 以使用 GPU 作为加速器。
|
1 2 3 4 5 6 |
from diffusers import DiffusionPipeline import torch pipe_id = "stabilityai/stable-diffusion-xl-base-1.0" pipe = DiffusionPipeline.from_pretrained(pipe_id, torch_dtype=torch.float16) pipe.to("cuda"); |
为了生成一位年轻女性的图像,您将提供相同的通用提示给 pipeline。
|
1 2 3 4 5 6 |
prompt = "photo of young woman, sitting outside restaurant, color, wearing dress, " \ "rim lighting, studio lighting, looking at the camera, up close, perfect eyes" image = pipe(prompt).images[0] image |
正如您所见,只需几行代码即可获得出色的结果。

使用 Diffusers library 和 Stable Diffusion XL pipeline 生成的图像
与 Stable Diffusion WebUI 类似,您可以提供积极提示、否定提示、推理步数,设置随机种子,更改尺寸和引导比例,从而按您希望的方式生成图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
prompt = "Astronaut in space, realistic, detailed, 8k" neg_prompt = "ugly, deformed, disfigured, poor details, bad anatomy" generator = torch.Generator("cuda").manual_seed(127) image = pipe( prompt, num_inference_steps=50, generator=generator, negative_prompt=neg_prompt, height=512, width=912, guidance_scale=6, ).images[0] image |
图像完美,看起来就像一位数字艺术家花了近 200 小时创作出来的。

使用 Stable Diffusion XL pipeline 生成的另一张图片
加载 LoRA 权重
您不仅可以直接调用 pipeline,还可以将 LoRA 权重加载到 pipeline 中。LoRA 权重是针对特定类型图像进行微调的模型适配器。它们可以附加到基础模型上以产生自定义结果。接下来,您将使用 LoRA 权重生成宜家风格的说明图像。
您将通过提供 Hugging Face 链接、适配器在仓库中的位置以及适配器名称来下载并加载 LoRA 适配器 ostris/ikea-instructions-lora-sdxl。
|
1 2 3 4 5 |
pipe.load_lora_weights( "ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea", ) |
要生成宜家风格的图像,您将向 pipeline 提供一个简单的提示、推理步数、比例参数和手动种子。
|
1 2 3 4 5 6 7 8 9 10 |
prompt = "super villan" image = pipe( prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 0.9}, generator=torch.manual_seed(125), ).images[0] image |
您创建了一个带有说明的超级反派。虽然不完美,但可以用来为您的作品生成自定义图像。

使用 LoRA 生成的宜家风格图片
ControlNet OpenPose
让我们来看另一个扩展。您现在将使用 ControlNet OpenPose 模型通过参考图像生成控制图像。ControlNet 是一种神经网络架构,可以通过添加额外的条件来控制扩散模型。
您将安装 controlnet_aux 用于检测图像中的身体姿势。
|
1 |
!pip install controlnet_aux -q |
然后,您将通过以 fp16 类型从 Hugging Face Hub 加载模型来构建 ControlNet pipeline。之后,您将使用链接将 Pexels.com 的免费图像加载到我们的环境中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from diffusers import ControlNetModel, AutoPipelineForText2Image from diffusers.utils import load_image import torch controlnet = ControlNetModel.from_pretrained( "lllyasviel/control_v11p_sd15_OpenPose", torch_dtype=torch.float16, variant="fp16", ).to("cuda") original_image = load_image( "https://images.pexels.com/photos/1701194/pexels-photo-1701194.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2" ) |
为了显示图像网格,您将创建一个 Python 函数,该函数接受一个图像列表,并在 Colab 笔记本中以网格形式显示它们。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from PIL import Image def image_grid(imgs, rows, cols, resize=256): assert len(imgs) == rows * cols if resize is not None: imgs = [img.resize((resize, resize)) for img in imgs] w, h = imgs[0].size grid_w, grid_h = cols * w, rows * h grid = Image.new("RGB", size=(grid_w, grid_h)) for i, img in enumerate(imgs): x = i % cols * w y = i // cols * h grid.paste(img, box=(x, y)) return grid |
下一步,您将构建 OpenPose 检测器 pipeline 并将其输入到您加载的图像。为了并排查看原始图像和 OpenPose 图像,您将使用 image_grid 函数。
|
1 2 3 4 5 6 |
from controlnet_aux import OpenPoseDetector model = OpenPoseDetector.from_pretrained("lllyasviel/ControlNet") pose_image = model(original_image) image_grid([original_image,pose_image], 1, 2) |
检测器已成功生成人体姿势结构。

原始图像和检测到的姿势。请注意,为了匹配 Stable Diffusion 的默认设置,两张图片都采用了 1:1 的宽高比。
现在,您将把所有内容组合在一起。您将创建 Stable Diffusion 1.5 文本到图像 pipeline,并提供 ControlNet OpenPose 模型。您将使用 fp16 变体进行内存优化。
|
1 2 3 4 5 6 |
controlnet_pipe = AutoPipelineForText2Image.from_pretrained( "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16", ).to("cuda") |
您将使用相同的积极和消极提示生成四张图像,并在网格中显示它们。请注意,您提供的是姿势图像而不是原始图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
prompt = "a woman dancing in the rain, masterpiece, best quality, enchanting, " \ "striking, beach background" neg_prompt = "worst quality, low quality, lowres, monochrome, greyscale, " \ "multiple views, comic, sketch, bad anatomy, deformed, disfigured, " \ "watermark, multiple_views, mutation hands, watermark, bad facial" image = controlnet_pipe( prompt, negative_prompt=neg_prompt, num_images_per_prompt = 4, image=pose_image, ).images image_grid(image, 1, 4) |
结果非常棒。所有女性都以相同的姿势跳舞。有些变形,但您不能对 Stable Diffusion 1.5 抱有太多期望。

使用 ControlNet pipeline 生成的四张图像
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
总结
在本帖中,您了解了 Hugging Face Diffuser 库以及如何使用它来生成高质量的自定义图像。具体来说,您涵盖了
- 什么是 Diffusers,它是如何工作的?
- 如何应用高级设置和否定提示来生成一致的图像。
- 如何加载 LoRA 权重以生成宜家风格的图像。
- 如何使用 ControlNet OpenPose 模型控制 Stable Diffusion 输出。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,包含所有 Python可用代码,指导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等…所有这些都是为了帮助您创作令人惊叹的数字艺术。






抱歉,在 google 上不起作用,出现此错误消息,遵循 pipe = DiffusionPipeline.from_pretrained(pipe_id, torch_dtype=torch.float16)pipe.to(“cuda”); 命令。基本上没有“cuda”。错误消息“RuntimeError: Found no NVIDIA driver on your system”表明 PyTorch CUDA 扩展无法检测到您系统上兼容的 NVIDIA GPU 或其驱动程序。这通常发生在:无 NVIDIA GPU:您的系统未安装 NVIDIA GPU。缺少驱动程序:您有 NVIDIA GPU,但未安装相应的驱动程序。
CUDA 工具包问题:可能未安装或配置不当与 GPU 交互所需的 CUDA 工具包。
你好 Thomas… 看起来你正在尝试使用具有 GPU 加速功能的 PyTorch 模型,但你的系统没有兼容的 NVIDIA GPU 或所需的驱动程序和 CUDA 工具包。以下是一些解决此问题的步骤。
1. **检查 NVIDIA GPU**
– 确保您的系统已安装 NVIDIA GPU。您可以通过查看系统硬件规格或在终端中使用
nvidia-smi等命令来检查,如果安装了 NVIDIA GPU,这些命令应该会显示 GPU 详细信息。2. **安装 NVIDIA 驱动程序**
– 如果您有 NVIDIA GPU 但未安装驱动程序,可以从 [NVIDIA 网站](https://www.nvidia.com/Download/index.aspx) 下载并安装相应的驱动程序。请按照适用于您操作系统的安装说明进行操作。
3. **安装 CUDA 工具包**
– PyTorch 与 NVIDIA GPU 交互需要 CUDA 工具包。您可以从 [NVIDIA CUDA Toolkit 网站](https://developer.nvidia.com/cuda-downloads) 下载 CUDA 工具包。请确保安装与您的 GPU 和操作系统兼容的版本。
4. **验证安装**
– 安装驱动程序和 CUDA 工具包后,通过在终端中运行
nvidia-smi来验证安装,以检查 GPU 及其驱动程序的状态。5. **重新安装支持 CUDA 的 PyTorch**
– 确保您已安装支持 CUDA 的正确版本的 PyTorch。您可以使用以下命令重新安装:
sh
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cuXX
将
cuXX替换为相应的 CUDA 版本(例如,CUDA 11.3 使用cu113)。6. **检查 CUDA 路径**
– 确保 CUDA 二进制文件在您系统的 PATH 中。您可以通过编辑 shell 配置文件(例如
.bashrc、.zshrc)将它们添加到 PATH 中。sh
export PATH=/usr/local/cuda-X.X/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-X.X/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
将
X.X替换为您的 CUDA 版本。如果您的系统没有 NVIDIA GPU,您将无法使用 CUDA。在这种情况下,您可以通过修改代码删除
.to("cuda")部分,在 CPU 上运行模型。python
pipe = DiffusionPipeline.from_pretrained(pipe_id, torch_dtype=torch.float16)
# pipe.to("cuda") # Remove this line to use CPU
在 CPU 上运行模型会比使用 GPU 慢,但它可以在不需要 CUDA 的情况下工作。
如果您使用的是云服务或像 Google Colab 这样的特定环境,请确保您在该环境的设置中启用了 GPU 支持。例如,在 Google Colab 中,您可以通过转到
Runtime>Change runtime type并选择GPU作为硬件加速器来启用 GPU 支持。