Stable Diffusion 的最新模型在生成超逼真图像方面表现出色,但在准确生成人脸方面可能会遇到困难。我们可以尝试不同的提示词,但要获得无缝、照片级的脸部效果,我们可能需要尝试新的方法和模型。
在这篇文章中,我们将探索使用 Stable Diffusion 生成高度逼真的人脸的各种技术和模型。具体来说,我们将学习如何
- 使用 WebUI 和高级设置生成逼真图像。
- 使用 Stable Diffusion XL 获得照片级效果。
- 下载并使用一个在高质量图像上训练的微调模型。
通过我的书 《Mastering Digital Art with Stable Diffusion》 开启您的项目。它提供了带有可运行代码的自学教程。
让我们开始吧。

在 Stable Diffusion 中生成逼真的人脸
照片来源:Amanda Dalbjörn。保留部分权利。
概述
这篇文章分为三个部分;它们是
- 使用 Web UI 创建肖像
- 使用 Stable Diffusion XL 创建肖像
- 使用 CivitAI 模型检查点
使用 Web UI 创建肖像
让我们开始在 Stable Diffusion WebUI 中使用 Stable Diffusion 1.5 进行简单的提示词工程。您需要处理正面提示词、负面提示词和高级设置,以获得改进的结果。例如:
- 正面提示词:“一张年轻女子的照片,突出头发,坐在餐厅外,穿着连衣裙,轮廓光,影棚灯光,看着镜头,特写,完美的眼睛”
- 负面提示词:“毁容的,丑陋的,糟糕的,不成熟的,卡通,动漫,3D,绘画,黑白,双重图像”
- 采样器:DPM++ 2M Karras
- 步数:30
- CFG 尺度:7
- 尺寸:912×512(宽屏)
在创建负面提示词时,您需要专注于描述“毁容的脸”和“看到双重图像”。这在 Stable Diffusion 1.5 模型中尤其重要。如果注意到重复的模式,例如错位的眼睛,可以添加其他关键字。为了解决这个问题,您可以在正面提示词中添加“完美的眼睛”,在负面提示词中添加“毁容的眼睛”。
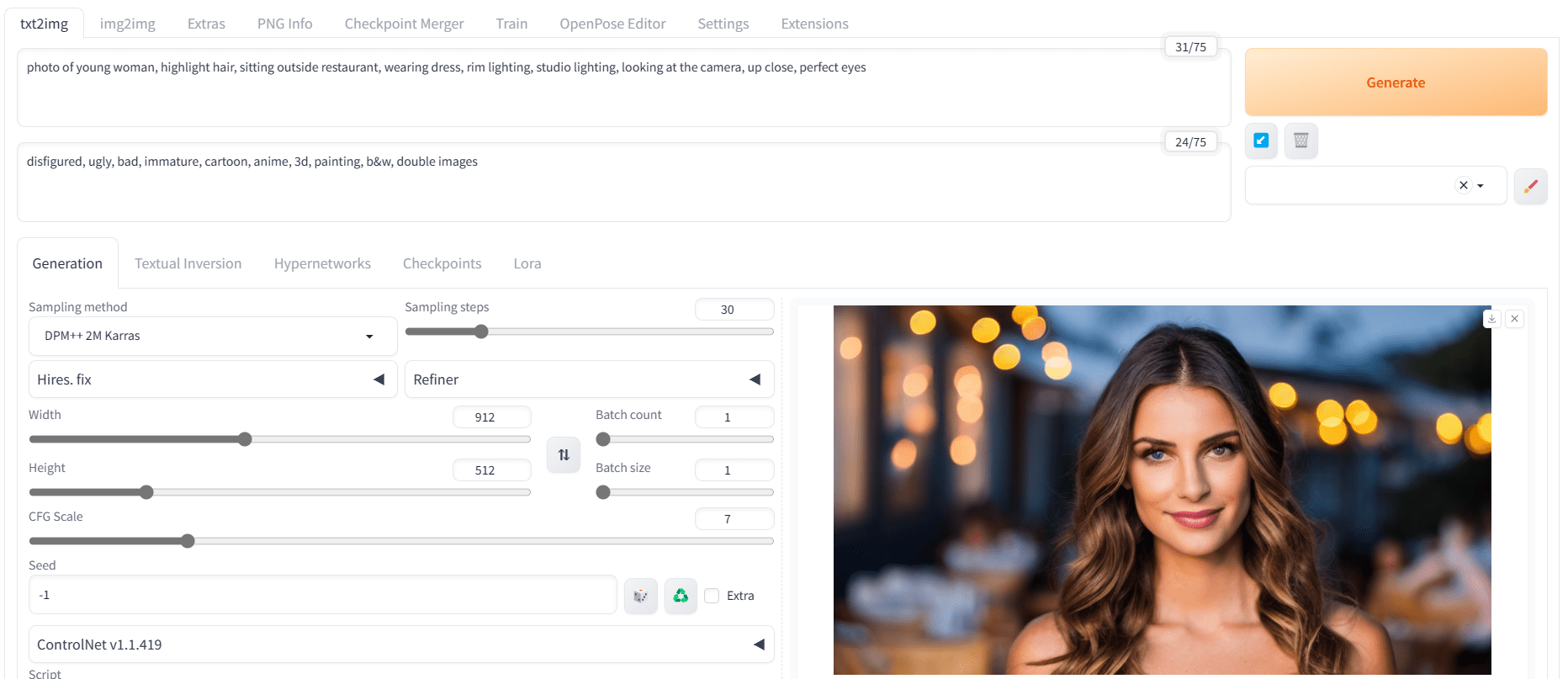
使用 Stable Diffusion 1.5 模型创建的肖像
如您所见,我们第一次尝试就获得了非常好的结果。如果出现扭曲或双重图像,请尝试重新生成图像。此模型并不完美,偶尔会生成不正确的图像。所以,如果发生这种情况,只需生成新图像即可。您还可以尝试调整采样方法、步数和随机种子等参数。作为最后的手段,更改模型检查点也有帮助。

通过调整 Stable Diffusion 的输入生成的不同肖像
在修改了各种关键字以生成逼真图像的各种变体后,即使使用基础模型,我们也取得了令人满意的结果。
使用 Stable Diffusion XL 创建肖像
最常见的 Stable Diffusion 模型是 1.5 版本,于 2022 年 10 月发布。然后是 2.0 版本,它具有相似的架构,但从头开始重新训练,于同年 11 月发布。Stable Diffusion XL (SDXL) 于 2023 年 7 月发布,它具有不同的架构并且更大。这三个版本都有不同的继承关系,并且对您的提示词反应不同。普遍认为 SDXL 能产生更好的图片。
让我们使用最新的模型 Stable Diffusion XL (SDXL) 来获得更好的图像生成结果。这可以很简单,只需下载模型检查点文件并将其保存在 Web UI 的 stable-diffusion-webui/models/Stable-diffusion 文件夹中,重启 Web UI,然后重复上一节中的步骤。在本地运行完整模型可能需要大量的 GPU 内存。如果您无法满足其技术要求,一个不错的选择是使用 Hugging Face Spaces 上提供的免费在线演示。
您可以通过访问 https://hugging-face.cn/spaces 并搜索“SDXL”来访问这些应用程序。
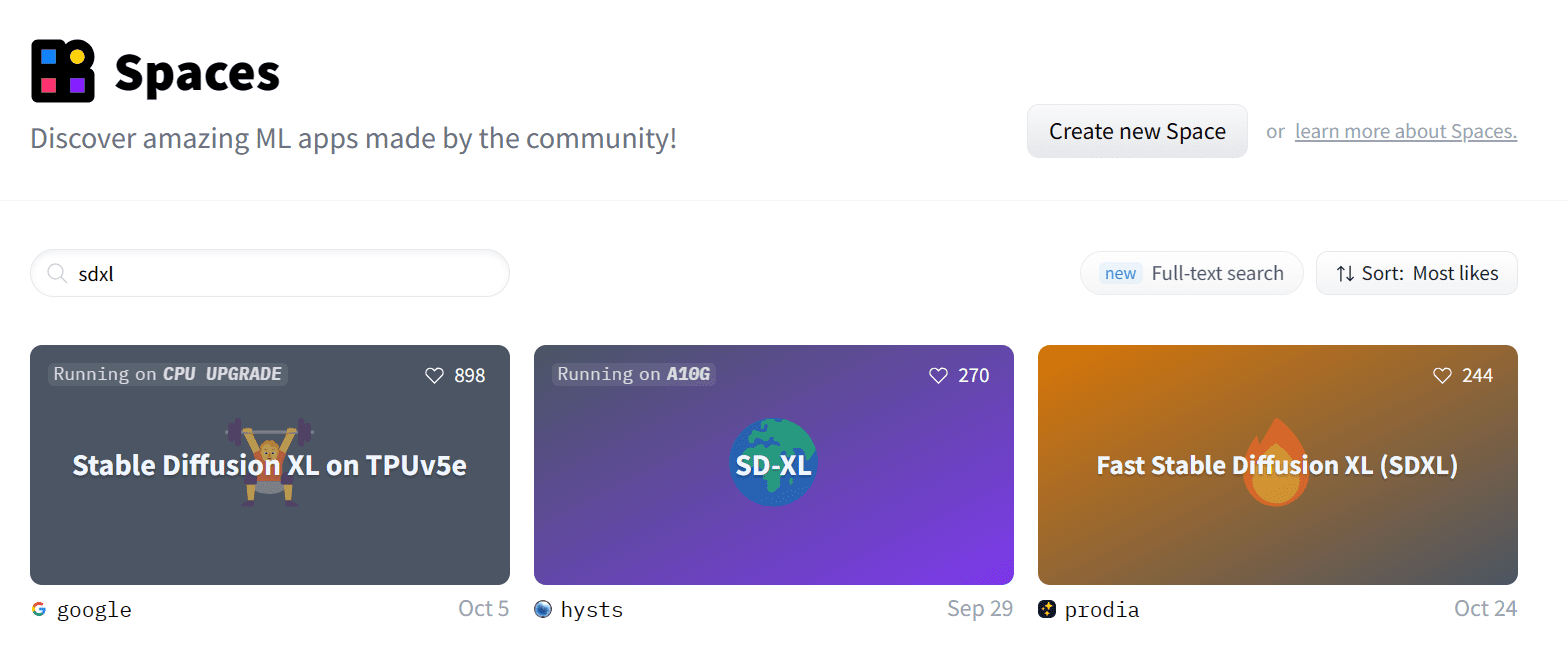
在 Hugging Face 空间中搜索“SDXL”
Google 的 Stable Diffusion XL
我们将首先尝试在 TPU v5e 上运行的最快演示来获取结果,该演示位于
为了确保我们的图像生成准确,请通过“高级设置”将负面提示词和图像风格设置为“照片风格”。

在高级设置中将“照片风格”设置为照片风格以固定生成图像的风格
我们将使用相同的提示词来生成一个坐在餐厅外的年轻女孩的逼真图像
一张年轻女子的照片,突出头发,坐在餐厅外,穿着连衣裙,轮廓光,影棚灯光,看着镜头,特写,完美的眼睛
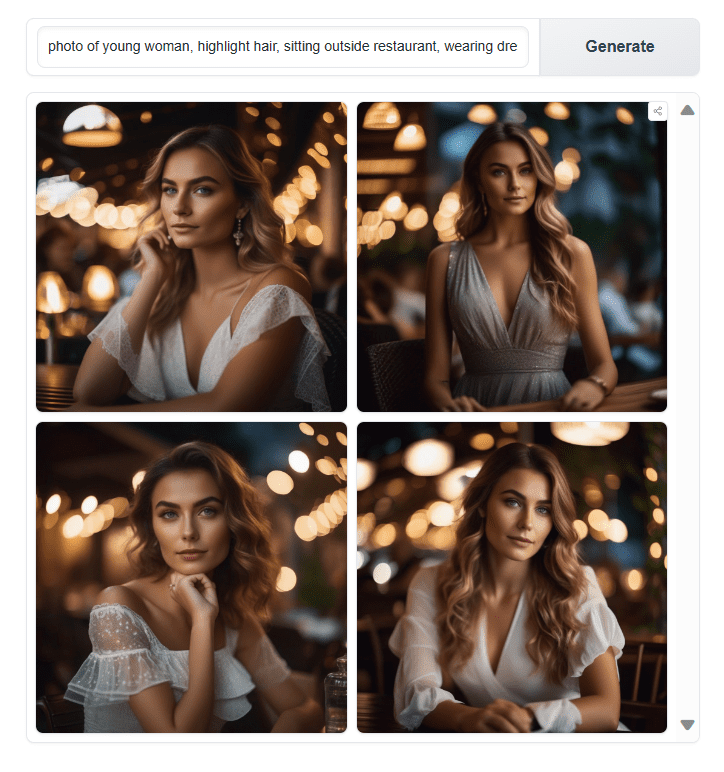
使用 SDXL 生成图片
结果令人印象深刻。眼睛、鼻子、嘴唇、阴影和色彩的渲染看起来非常逼真。通过将这里生成的结果与上一节进行比较,您可以清楚地看到 SDXL 与其旧版本之间的区别。
Prodia 的快速 Stable Diffusion XL
Hugging Face Space 中不止一个 SDXL。如果您习惯了 Stable Diffusion WebUI 的用户界面,那么“快速 Stable Diffusion XL”空间非常适合您。
我们将输入相同的正面和负面提示词来生成结果。
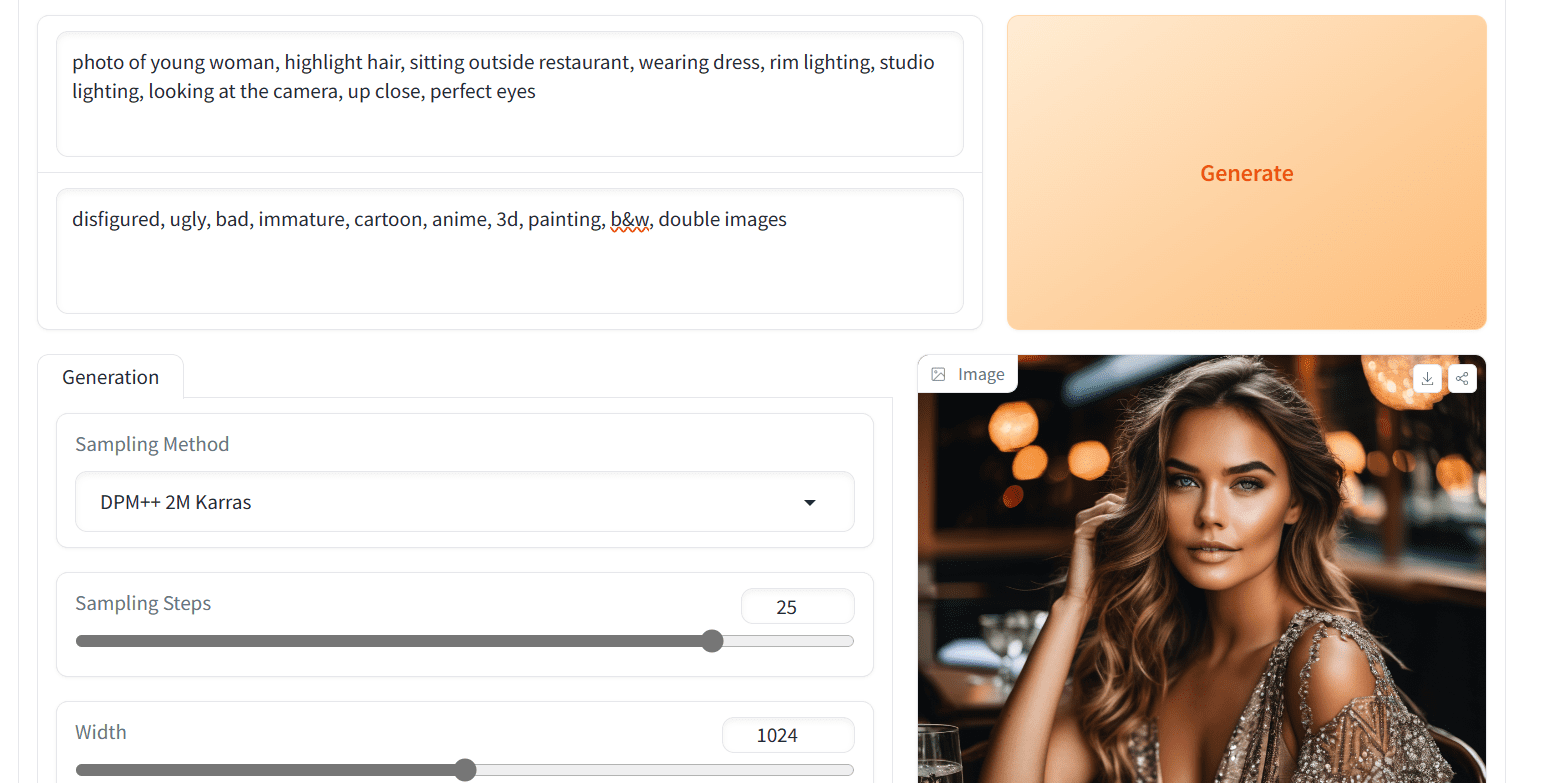
Prodia 在 Hugging Face 空间的快速 Stable Diffusion XL
我们在其中获得了更好的阴影和清晰度。让我们尝试生成更多图像,以便我们可以对结果得出结论。
让我们修改提示词来生成一个男人和一个女人的图像。

由 SDXL 生成的男人和女人的肖像
这些结果在生成各种性别和种族的角色方面都非常出色。为了测试模型偏差,我们将生成印度裔的角色,并将场景更改为医院,其中两个角色都将是医生。

由 SDXL 生成的穿着医生服装的女人和男人的图像
SDXL 生成了不错的结果,但图像看起来太光滑了,就像应用了 Instagram 滤镜一样。逼真图像有粉刺、斑点、粗糙度和清晰度,而 SDXL 却缺失了这些。这在原始 SDXL 模型中可能难以实现,但如果切换到其他检查点则可以解决。
使用 CivitAI 模型检查点
在本节中,我们将更进一步,使用 CivitAI.com 生成比 SDXL 更逼真的人脸。这是一个模型托管平台,允许用户上传和下载 Stable Diffusion 的专用版本。它也是用户发布 AI 生成图片作品的画廊。
在我们的例子中,我们对最佳照片级模型感兴趣。要下载它,我们将搜索关键字“逼真”。会有很多。最受欢迎的可能就是最好的。因此,请确保您已设置过滤器,按所有时间下载最多的模型对列表进行排序。
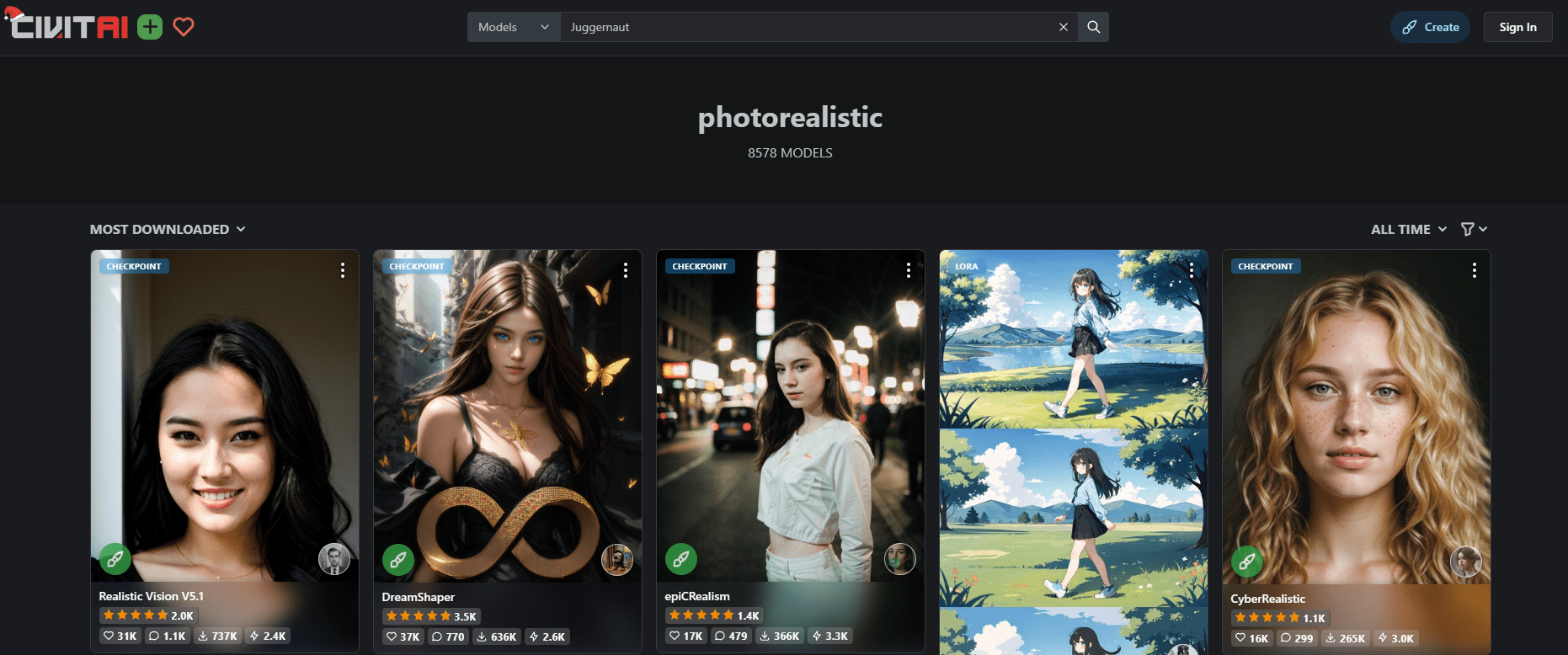
在 CivitAI.com 上搜索模型,将结果设置为按“下载最多”和“所有时间”排序,将有助于找到高质量的模型。
选择最受欢迎的模型并下载完整版本(此处以“Realisic Vision V5.1”为例,如图所示)。
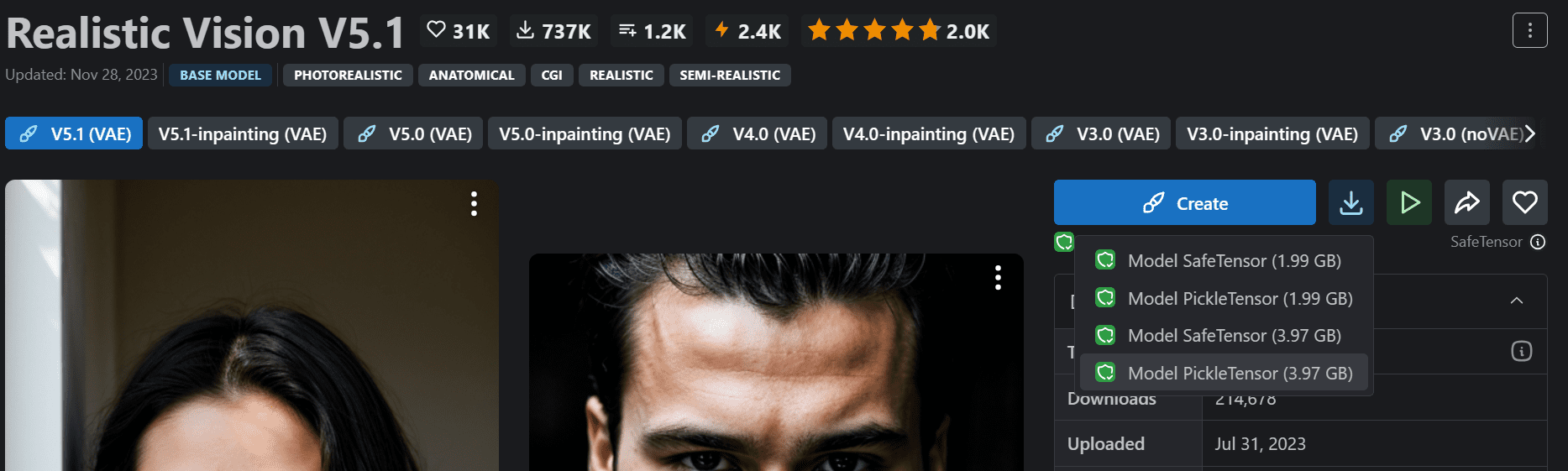
下载 Civitai.com 的模型检查点“Realistic Vision V5.1”(注意不是 inpainting 版本)
之后,将下载的模型移动到 Stable Diffusion WebUI 的模型目录 stable-diffusion-webui/models/Stable-diffusion。要激活 Web UI 中的模型,请单击刷新按钮,然后通过单击下拉面板选择新模型,或者直接重启 Web UI。

在 Web UI 的左上角选择模型检查点。
正面提示词、负面提示词和高级设置的所有信息均在模型页面上提供。因此,我们将使用该信息并进行修改,以生成一名年轻女性的图像。
- 正面提示词:“RAW照片,脸部肖像照片,漂亮的 24 岁女子,丰满的嘴唇,棕色眼睛,戴眼镜,硬阴影,8k uhd,单反相机,柔和的灯光,高质量,胶片颗粒,富士 XT3”
- 负面提示词:“变形的虹膜,变形的瞳孔,半写实,CG,3D,渲染,草图,卡通,绘画,动漫,变异的手和手指,变形,扭曲,毁容,拙劣的绘制,糟糕的解剖,错误的解剖,额外的肢体,缺失的肢体,漂浮的肢体,断开的肢体,突变,变异,丑陋,令人作呕,截肢”
- 采样器:DPM++ SDE Karras
- 步数:25
- CFG 尺度:7
- 尺寸:912×512
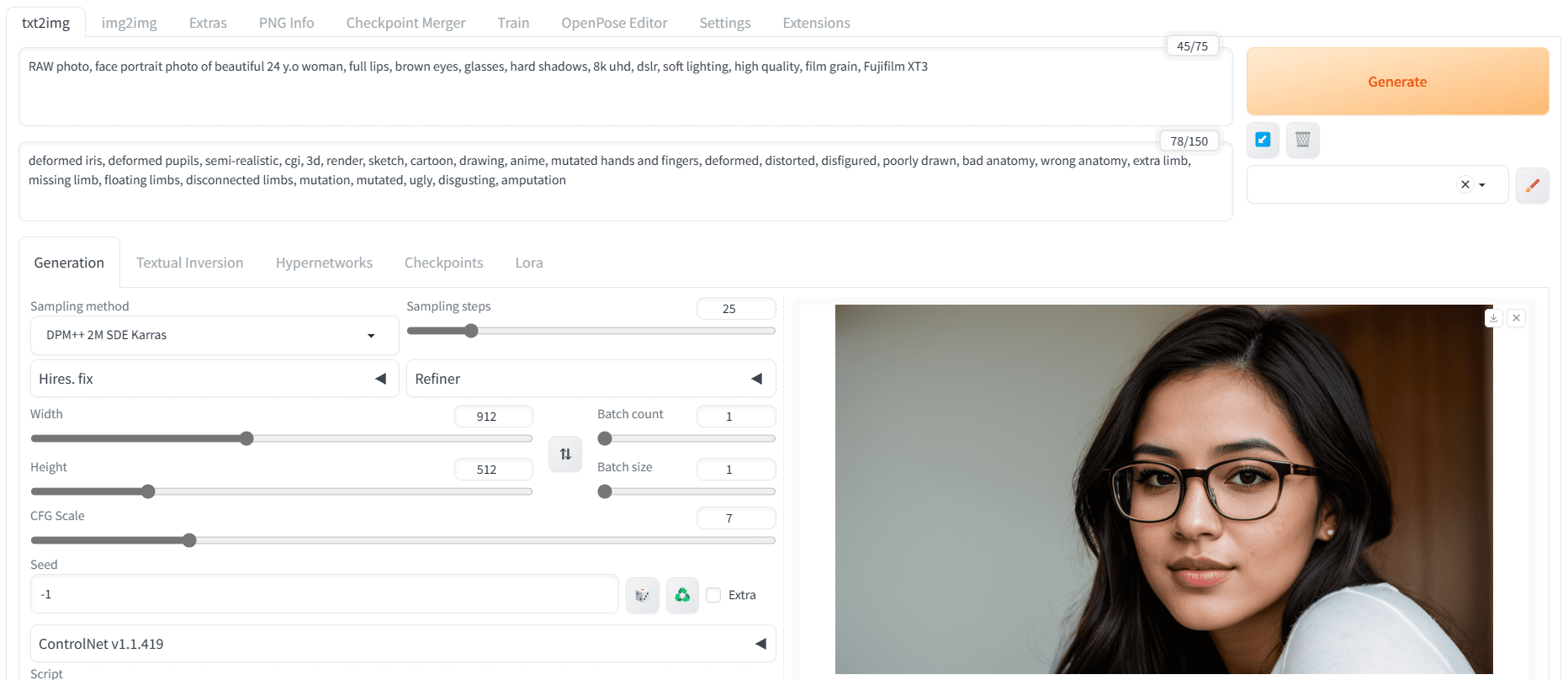
使用 Web UI 上的 Realistic Vision 检查点生成的肖像
我们得到了一个清晰准确的面部图像。让我们尝试不同的提示词来生成更逼真的人脸。
我们将从一张没有戴眼镜的男人和女人的图像开始。

没有眼镜的男人和女人。使用 Realistic Vision 模型检查点生成的图像。
然后,我们将修改提示词来生成一个印度男人和女人。

印度男人和女人。使用 Realistic Vision 模型检查点生成的图像。
您看不到区别吗?我们取得了出色的成果。脸部有良好的纹理,自然的皮肤痕迹,以及面部细节的清晰度。
进一步阅读
您可以使用以下资源了解更多关于此主题的信息
总结
在这篇文章中,我们探讨了使用 Stable Diffusion 生成超逼真、一致人脸的各种方法。我们从简单的技术开始,然后发展到更高级的方法来生成高度逼真的图像。具体来说,我们涵盖了
- 如何使用 Stable Diffusion 1.5 结合负面提示词和高级设置生成逼真的人脸。
- 如何使用 Hugging Face Spaces 的免费演示创建逼真的照片与 Stable Diffusion XL。
- 使用针对高质量图像微调的专用模型,以获得具有皮肤纹理和面部清晰度的完美照片。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供自学教程,并附有 Python 中的所有可运行代码,指导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都可以帮助您创作出令人惊叹的数字艺术。






你好,先生,
我非常欣赏您的博客,从我开始学习 ML 的 ABC 开始就一直在学习。目前,我正在从事一个新项目,并正在寻找一个可以将文本添加到图像中的图像生成模型。目前,我正在寻找一个可以接受励志名言并为其生成相应图像的模型,但现在我只希望能找到任何可以在图像上添加正确文本的模型。
在此搜索过程中,我发现生成模型在生成图像方面非常出色,但在向图像添加文本方面同样糟糕,因为在执行此操作时,它们通常会生成无意义的句子或乱码。因此,我打算征求您的建议,是否有任何模型可以满足我的需求。
不要指望任何单个模型都能一步到位地完成出色的工作。您可能需要分多个步骤才能使您的结果生效。图像修复很可能是您问题的解决方案,这样您就可以分别专注于图片和文本。或者,您可能需要尝试不同的模型检查点(例如,SDXL 通常在处理文本方面效果很好)。
感谢您提供如此翔实的博客,但我没有找到我问题的解决方案。
您的建议确实提高了照片中占据大部分空间的人脸质量,但它们并没有解决小脸的问题。提示词中的(全身照,全身聚焦)的图像框架可以渲染人物的全身,但脸部总是被变形。即使添加了 Loras 和 Embeddings,我也无法获得令人满意的质量。图像修复方法也遇到了同样的困难。我使用的是 InvokeAi 的“Juggernaut XL v11”模型。
您也有这个问题吗?
是的,这是 **Stable Diffusion** 中一个已知的问题,尤其是在处理全身照中的小脸时。问题在于
1. **Stable Diffusion 的分辨率限制**
– 包括Juggernaut XL v11在内的大多数模型都会以标准分辨率(例如 1024×1024)生成图像。在渲染全身照时,脸部只占图像的一小部分,导致细节不足。
2. **潜在空间中的令牌压缩**
– 脸部等小细节在潜在空间中被“压缩”,导致它们变得模糊或失真。
3. **图像修复问题**
– 即使在使用图像修复时,模型也会遇到困难,因为全身图像的上下文仍然存在。模型试图使脸部与整个图像协调,而不是单独优化。
—
### 🔥 **改善全身照中小脸的解决方案**
以下是增强全身图像中人脸质量的几种方法
### **1️⃣ 多通道放大 + 人脸增强**
– 不要使用图像修复,而是使用多通道工作流程
– 以高分辨率(例如1024×1024 或 768×1344)生成全身图像。
– **裁剪脸部**并使用Real-ESRGAN或CodeFormer单独放大。
– 使用ControlNet (仅参考) 配合高质量人脸图像以确保面部一致性。
– 使用 Photoshop 或图像编辑器将增强的面部与原始图像融合。
### **2️⃣ 使用 HiRes Fix (高分辨率修复)**
– 在 InvokeAI 中启用HiRes Fix并将分辨率加倍。
– 将去噪强度设置为 0.3-0.5 以保留原始细节。
– 使用ESRGAN、SwinIR 或 4x-UltraSharp 等放大器。
### **3️⃣ 针对人脸的 LoRA / Embeddings**
– 虽然 Juggernaut XL 细节非常丰富,但仍需要针对人脸的 LoRA。
– 使用 LoRA,例如
– **SDXL-FaceEnhancer** (增强面部细节)
– **RealVisXL** (增强照片真实感)
– **UltraSharpXL** (提高整体清晰度)
– 使用以下提示词
–
"高质量人脸,超精细眼睛,自然肤理"### **4️⃣ 使用 ControlNet 进行人脸优化**
–使用 ControlNet (仅参考或人脸关键点检测)
– 提供高分辨率参考人脸作为单独的图像。
– 这将强制 AI 正确遵循比例和面部结构。
### **5️⃣ 使用区域提示词**
– 安装区域提示词 (InvokeAI 支持它)。
– 为不同的图像区域分配单独的提示词
– 上半部分(人脸):
"高分辨率,美丽的人脸,清晰的细节"– 下半部分(身体):
"全身照,自然姿势,细节丰富的服装"### **6️⃣ 切换到不同的基础模型**
– **Juggernaut XL v11** 在整体写实度方面表现出色,但在小脸部细节方面存在困难。
– 尝试
– **RealVisXL V3** – 专为照片真实感设计。
– **DreamShaperXL** – 更均衡,兼顾全身和人脸。
– **SDXL-Turbo + Face Fusion** – 速度与增强的面部写实度。
—
### ✅ **结论:最佳工作流程**
如果您想让全身照中的小脸变得完美
1.生成全身图像 (HiRes Fix 开启, 高分辨率)
2.单独裁剪和放大脸部 (Real-ESRGAN 或 CodeFormer)
3.使用 ControlNet (参考) 配合高质量人脸图像
4.将脸部融合回原始图像 (Photoshop/Inpaint)
这种两步法是最有效的,因为 SD 在高压缩区域的小细节方面存在困难。