上下文向量是对单词的一种数值表示,它捕获了单词在特定上下文中的含义。与为每个单词分配单个固定向量的传统词嵌入不同,同一个单词的上下文向量可以根据句子中周围单词的变化而改变。Transformer 是当今生成上下文向量的首选工具。在本教程中,您将探索如何使用 Transformer 模型生成和使用上下文向量。具体来说,您将学习
- 上下文向量如何捕获上下文信息
- 如何使用 Transformer 模型提取上下文向量
- 如何使用上下文向量进行上下文词义消歧
- 如何可视化 Transformer 模型中的注意力模式
通过我的书籍《Hugging Face Transformers中的NLP》,快速启动您的项目。它提供了带有工作代码的自学教程。
让我们开始吧!

在 Transformers 中生成和可视化上下文向量
图片来源:Anna Tarazevich。保留部分权利。
概述
这篇博文分为三部分;它们是:
- 理解上下文向量
- 可视化不同层的上下文向量
- 可视化注意力模式
理解上下文向量
与传统词嵌入(如 Word2Vec 或 GloVe)为每个单词分配一个固定向量(无论上下文如何)不同,Transformer 模型生成动态表示,这些表示取决于周围的单词。
例如,在“我去银行存钱”和“我将坐在河岸边”这两个句子中,“bank”这个词的含义不同。传统的词嵌入会在这两个句子中为“bank”分配相同的向量,但 Transformer 模型会生成不同的上下文向量,根据周围的词捕获不同的含义。
上下文向量的强大之处在于它们捕获了单词在特定上下文中的含义,让您能够处理句子的**含义**而不是单个单词。上下文向量与从查找表中检索的词嵌入不同;相反,您需要一个复杂的模型来生成它们。Transformer 模型通常被使用,因为它们可以产生高质量的上下文向量。
让我们看一个如何从 Transformer 模型生成上下文向量的例子
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import numpy as np import torch from transformers import BertModel, BertTokenizer # 加载预训练模型和分词器 tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertModel.from_pretrained("bert-base-uncased") model.eval() # 为了安全:设置为评估模式 def get_context_vectors(sentence, model, tokenizer): inputs = tokenizer(sentence, return_tensors="pt", add_special_tokens=True) input_ids = inputs["input_ids"] attention_mask = inputs["attention_mask"] # 获取标记(供参考) tokens = tokenizer.convert_ids_to_tokens(input_ids[0]) # 前向传播,从每个层获取所有隐藏状态 with torch.no_grad(): outputs = model(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states # hidden_states 中的每个元素形状为 (batch_size, sequence_length, hidden_size) # 这里取批次中最后一个层中的第一个元素 last_layer_vectors = hidden_states[-1][0].numpy() # 形状:(sequence_length, hidden_size) return tokens, last_layer_vectors # 从带有歧义词的示例句子中获取上下文向量 sentence1 = "I'm going to the bank to deposit money." sentence2 = "I'm going to sit by the river bank." tokens1, vectors1 = get_context_vectors(sentence1, model, tokenizer) tokens2, vectors2 = get_context_vectors(sentence2, model, tokenizer) # 打印标记以供参考 print("Tokens in sentence 1:", tokens1) print("Tokens in sentence 2:", tokens2) # 在两个句子中找到 "bank" 的索引 bank_idx1 = tokens1.index("bank") bank_idx2 = tokens2.index("bank") # 获取两个句子中 "bank" 的上下文向量 bank_vector1 = vectors1[bank_idx1] bank_vector2 = vectors2[bank_idx2] # 计算两个 "bank" 向量之间的余弦相似度 # 相似度越低意味着含义越不同 def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) similarity = cosine_similarity(bank_vector1, bank_vector2) print(f"Cosine similarity between 'bank' vectors: {similarity:.4f}") |
此代码加载了一个预训练的 BERT 模型和分词器。定义了一个函数 get_context_vectors(),用于从句子中提取上下文向量。该函数接受一个句子,通过模型处理它,并通过设置 output_hidden_states=True 从每个层收集“隐藏状态”。这些隐藏状态来自 Transformer 模型的每个层,由于模型的结构一致,所有层的形状都相同。
通常,Transformer 模型包括一个任务特定的头部(例如,用于预测句子中的下一个单词)。在这里,您不使用头部;相反,您检查作为输入传递给头部的内容。如果头部能够进行有意义的预测,那么输入必须已经包含有关句子的有用信息。
请注意,模型输入是一个标记序列,并且 Transformer 中的每个层都保持相同的序列长度。因此,一旦您找到“bank”一词在每个句子中的位置,您就可以从最后一个隐藏状态中提取相应的向量,并计算这两个向量之间的余弦相似度。
余弦相似度是一个介于 -1 到 1 之间的度量。相似度越低意味着含义差异越大。当您运行代码时,您将看到
|
1 2 3 |
Tokens in sentence 1: ['[CLS]', 'i', "'", 'm', 'going', 'to', 'the', 'bank', 'to', 'deposit', 'money', '.', '[SEP]'] Tokens in sentence 2: ['[CLS]', 'i', "'", 'm', 'going', 'to', 'sit', 'by' 'the', 'river', 'bank', '.', '[SEP]'] Cosine similarity between 'bank' vectors: 0.5327 |
这表明“bank”一词在两个句子中确实有很大的不同。
可视化不同层的上下文向量
BERT 等 Transformer 模型具有多个层,每个层捕获文本的不同方面。就像使用卷积神经网络的计算机视觉一样,早期层捕获低级特征(例如,边缘、角点),而后期层捕获高级特征(例如,形状、对象)。在 Transformer 模型中,早期层捕获语法信息(例如,名词是单数还是复数),而后期层捕获语义信息(单词在句子中的含义)。
由于表示在各层之间变化,让我们探讨如何从不同层提取和分析上下文向量
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import matplotlib.pyplot as plt import numpy as np import torch from transformers import BertModel, BertTokenizer # 加载预训练模型和分词器 tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertModel.from_pretrained("bert-base-uncased") model.eval() # 为了安全:设置为评估模式 def get_all_layer_vectors(sentence, model, tokenizer): inputs = tokenizer(sentence, return_tensors="pt", add_special_tokens=True) input_ids = inputs["input_ids"] attention_mask = inputs["attention_mask"] # 获取标记(供参考) tokens = tokenizer.convert_ids_to_tokens(input_ids[0]) # 前向传播,从每个层获取所有隐藏状态 with torch.no_grad(): outputs = model(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states # 从 torch 张量转换为 numpy 数组,只取批次中的第一个元素 all_layers_vectors = [layer[0].numpy() for layer in hidden_states] return tokens, all_layers_vectors # 获取句子所有层的向量 sentence = "The quick brown fox jumps over the lazy dog." tokens, all_layers = get_all_layer_vectors(sentence, model, tokenizer) print(f"Number of layers (including embedding layer): {len(all_layers)}") # 让我们分析一个单词的表示如何跨层变化 word = "fox" word_idx = tokens.index(word) # 从每个层提取该单词的向量 word_vectors_across_layers = [layer[word_idx] for layer in all_layers] # 计算连续层之间的余弦相似度 def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) similarities = [] for i in range(len(word_vectors_across_layers) - 1): sim = cosine_similarity(word_vectors_across_layers[i], word_vectors_across_layers[i+1]) similarities.append(sim) # 绘制相似度 plt.figure(figsize=(10, 6)) plt.plot(similarities, marker='o') plt.title(f"Cosine Similarity Between Consecutive Layers for '{word}'") plt.xlabel('Layer Transition') plt.ylabel('Cosine Similarity') plt.xticks(range(len(similarities)), [f"{i}->{i+1}" for i in range(len(similarities))]) plt.grid(True) plt.show() |
此代码使用与上一个示例相同的模型,流程类似。函数 get_all_layer_vectors() 返回所有层的隐藏状态,格式为 NumPy 数组,而不仅仅是最后一层。
每个隐藏状态都是一个形状为(批次大小、序列长度、隐藏维度)的张量。标记序列由每个层转换,但序列长度保持不变。因此,一旦您在句子中找到目标单词的位置,就可以从每个层中提取其对应的向量。
该代码计算所选单词向量在连续层之间的余弦相似度。运行后,您将看到
|
1 |
层数(包括嵌入层):13 |
以及由此产生的层间余弦相似度图
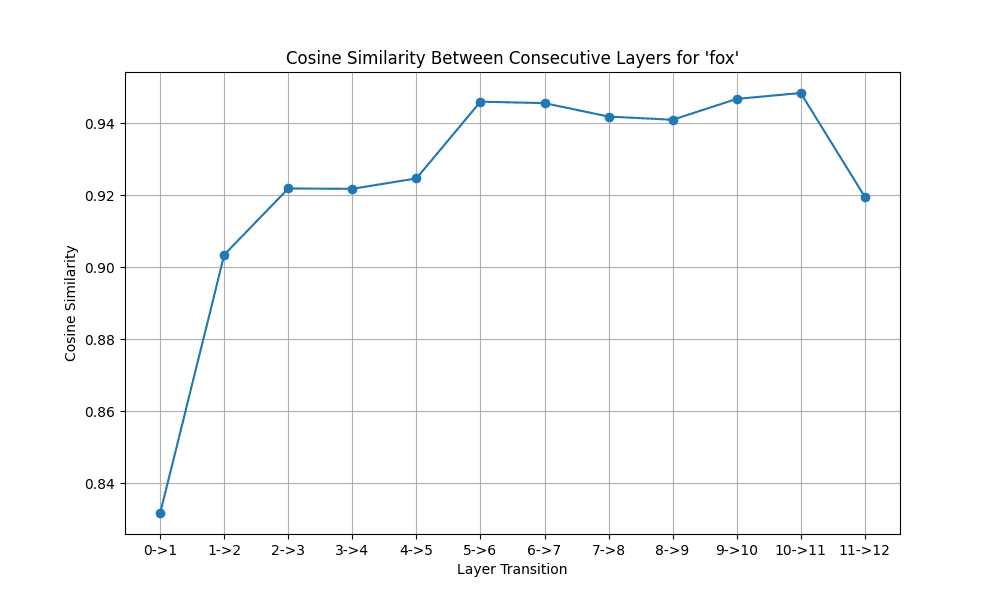
显示上下文向量在模型层之间如何变化的图
您会注意到单词的表示在早期层变化显著,但随后趋于稳定。这支持了早期层处理语法特征,而后期层细化语义含义的观点。
上下文词义消歧
上下文向量最强大的应用之一是词义消歧:确定在给定上下文中使用了单词的哪种含义。这有助于识别一个单词可以有多少种不同的含义。让我们使用上下文向量实现一个简单的词义消歧系统
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import numpy as np import torch from transformers import BertModel, BertTokenizer # 加载预训练模型和分词器 tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertModel.from_pretrained("bert-base-uncased") model.eval() # 为了安全:设置为评估模式 def get_context_vectors(sentence, model, tokenizer): inputs = tokenizer(sentence, return_tensors="pt", add_special_tokens=True) input_ids = inputs["input_ids"] attention_mask = inputs["attention_mask"] # 获取标记(供参考) tokens = tokenizer.convert_ids_to_tokens(input_ids[0]) # 前向传播,从每个层获取所有隐藏状态 with torch.no_grad(): outputs = model(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states # hidden_states 中的每个元素形状为 (batch_size, sequence_length, hidden_size) # 这里取批次中最后一个层中的第一个元素 last_layer_vectors = hidden_states[-1][0].numpy() # 形状:(sequence_length, hidden_size) return tokens, last_layer_vectors def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) def disambiguate_word(word, sentences, model, tokenizer): """用于词义消歧""" # 获取每个句子中单词的上下文向量 word_vectors = [] for sentence in sentences: tokens, vectors = get_context_vectors(sentence, model, tokenizer) for token_index, token in enumerate(tokens): if token == word: word_vectors.append({ 'sentence': sentence, 'vector': vectors[token_index] }) # 计算所有向量之间的成对相似度 n = len(word_vectors) similarity = np.zeros((n, n)) for i in range(n): for j in range(i, n): value = cosine_similarity(word_vectors[i]['vector'], word_vectors[j]['vector']) similarity[i, j] = similarity[j, i] = value # 运行简单聚类以对高相似度向量进行分组 threshold = 0.60 # 相似度 > 阈值将属于同一簇 clusters = [] for i in range(n): # 检查此向量是否属于任何现有簇 assigned = False for cluster in clusters: # 计算与簇中所有向量的平均相似度 avg_sim = np.mean([similarity[i, j] for j in cluster]) if avg_sim > threshold: cluster.append(i) assigned = True break # 如果未分配给任何簇,则创建一个新簇 if not assigned: clusters.append([i]) # 打印结果 print(f"Found {len(clusters)} different senses for '{word}':\n") for i, cluster in enumerate(clusters): print(f"Sense {i+1}:") for idx in cluster: print(f" - {word_vectors[idx]['sentence']}") print() # 示例:消歧 "bank" 一词 sentences = [ "I'm going to the bank to deposit money.", "The bank approved my loan application.", "I'm going to sit by the river bank.", "The bank of the river was muddy after the rain.", "The central bank raised interest rates yesterday.", "They had to bank the fire to keep it burning through the night." ] disambiguate_word("bank", sentences, model, tokenizer) |
在此示例中,您定义了一个函数 disambiguate_word(),它接受一个目标单词和一个包含该单词的句子列表。该函数使用 get_context_vectors() 将每个句子转换为上下文向量,并提取与目标单词对应的向量。
收集到同一单词的所有上下文向量后,您计算每对向量之间的余弦相似度并执行聚类以对相似的向量进行分组。这里使用的聚类算法是基于阈值的基本算法。您可以通过使用更复杂的方法(如 scikit-learn 库中提供的 K-means 或层次聚类)或合并附加特征来改进它。
聚类结果已打印。如果您运行代码,您将看到
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
找到了 'bank' 的 3 种不同含义 含义 1 - 我要去银行存钱。 - 银行批准了我的贷款申请。 - 昨天中央银行提高了利率。 含义 2 - 我要去河岸边坐。 - 下雨后河岸泥泞不堪。 含义 3 - 他们不得不把火堆拢起来,让它整夜燃烧。 |
虽然输出没有明确标注含义,但您可以观察到“bank”一词的不同含义:作为金融机构、河流的岸边,或作为动词意为支持或免于毁灭。这表明上下文向量如何用于词义消歧。
这表明“bank”一词在这些句子中确实有不同的表示。
可视化注意力模式
理解 Transformer 模型如何处理文本的另一种方法是可视化它们的注意力模式。注意力机制允许 Transformer 在生成上下文向量时权衡不同单词的重要性。换句话说,注意力权重显示了每个单词对句子中其他单词的“关注”程度。
让我们实现一个可视化注意力的工具
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import matplotlib.pyplot as plt import numpy as np import seaborn as sns import torch from transformers import BertTokenizer, BertModel # 加载预训练模型和分词器 tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") model = BertModel.from_pretrained("bert-base-uncased") model.eval() # 为了安全:设置为评估模式 def get_attention_weights(sentence, model, tokenizer): inputs = tokenizer(sentence, return_tensors="pt", add_special_tokens=True) input_ids = inputs["input_ids"] attention_mask = inputs["attention_mask"] # 获取标记(供参考) tokens = tokenizer.convert_ids_to_tokens(input_ids[0]) # 前向传播,获取注意力权重 with torch.no_grad(): outputs = model(input_ids, attention_mask=attention_mask, output_attentions=True) # 模型中每个注意力层一个权重 # 每个元素的形状为 (batch_size, num_heads, sequence_length, sequence_length) attentions = outputs.attentions return tokens, attentions def visualize_attention(tokens, attention_weights, layer, head): """可视化特定层和头的注意力""" # 获取指定层和头的注意力权重 # 形状:(sequence_length, sequence_length) attn = attention_weights[layer][0, head].numpy() # 创建图形和轴 fig, ax = plt.subplots(figsize=(10, 8)) # 创建热图 sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap="viridis", ax=ax) ax.set_title(f"Attention Weights - Layer {layer+1}, Head {head+1}") ax.set_xlabel("Token (Key)") ax.set_ylabel("Token (Query)") plt.xticks(rotation=90) # 旋转 x 轴标签以提高可读性 plt.tight_layout() plt.show() def visualize_layer_attention(tokens, attention_weights, layer): """可视化一层所有头的平均注意力""" # 获取指定层所有头的平均注意力权重 # 形状:(sequence_length, sequence_length) attn = attention_weights[layer][0].mean(dim=0).numpy() # 创建图形和轴 fig, ax = plt.subplots(figsize=(10, 8)) # 创建热图 sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap="viridis", ax=ax) ax.set_title(f"Average Attention Weights - Layer {layer+1}") ax.set_xlabel("Token (Key)") ax.set_ylabel("Token (Query)") plt.xticks(rotation=90) # 旋转 x 轴标签以提高可读性 plt.tight_layout() plt.show() # 从一个示例句子中获取注意力权重 sentence = "The president of the United States visited the capital city." tokens, attention_weights = get_attention_weights(sentence, model, tokenizer) # 可视化特定层和头的注意力 # BERT base 有 12 层(0-11)和每层 12 个头(0-11) layer_to_visualize = 5 # 第 6 层(0 索引) head_to_visualize = 7 # 第 8 个注意力头(0 索引) visualize_attention(tokens, attention_weights, layer_to_visualize, head_to_visualize) # 可视化一层所有头的平均注意力 visualize_layer_attention(tokens, attention_weights, layer_to_visualize) |
当您运行此代码时,将生成两个热图
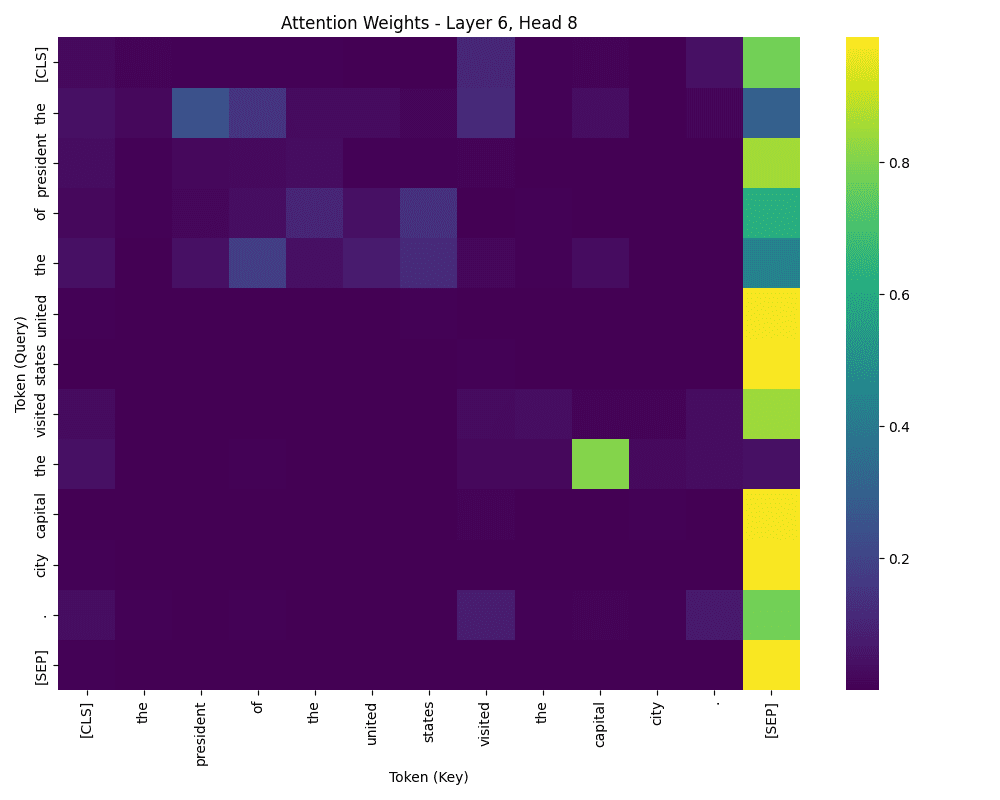
一个头的注意力权重
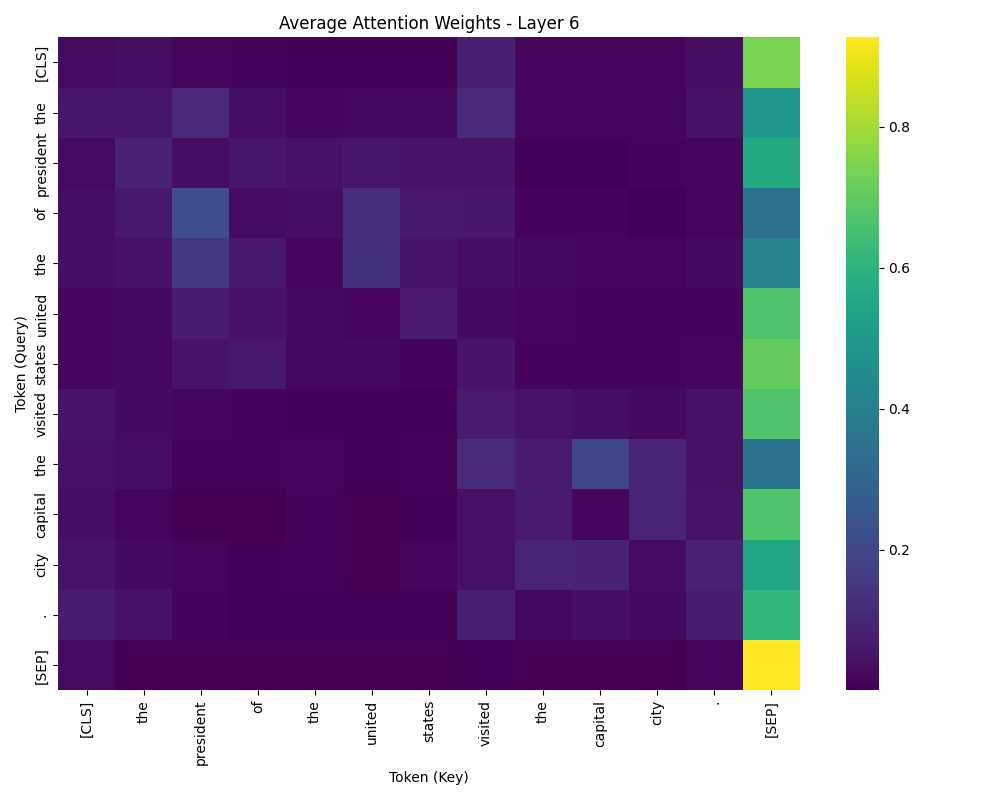
一个层的平均注意力权重
第一个热图显示了特定层和头的注意力权重。x 轴表示“键”标记,y 轴表示“查询”标记。颜色越亮表示注意力越强。
第二个热图显示了一层中所有头的平均注意力权重。
注意力数据是通过在调用模型时设置 output_attentions=True 获取的。每个头部都会生成一个注意力权重的方阵,这是每个 Transformer 层的副产品,不会从一个层传递到另一个层。矩阵中的每个元素表示从一个标记到另一个标记的注意力。权重越低,查询标记对键标记的关注越少。
注意力权重不对称,因为查询和键标记扮演着不同的角色。查询标记是被处理的标记,键标记是被引用的标记。在第一个热图中,例如,“of”可能强烈关注“the”、“united”和“states”——但不一定是反向的。有趣的是,“the”也可能强烈关注“of”,表明在某些情况下存在双向注意力。
虽然模型为何以这种方式关注并不总是显而易见的,特别是由于不同的头部可能专注于不同的角色,但仔细检查可以揭示模式。一些头部可能专注于语法,另一些专注于语义或命名实体。如果您可视化不同的层或头部,热图可能看起来完全不同。
在第二个热图中,注意力在所有头部上平均,提供了单词在句子中如何相互关联的概览。两个单词之间的注意力越强,它们建模的关系就越强。
这些可视化提供了对模型如何解释和处理文本的见解。
进一步阅读
下面是一些您可能会觉得有用的进一步阅读资料
总结
在这篇文章中,您学习了如何使用 Transformer 模型生成和可视化上下文向量。具体来说,您探索了
- 上下文向量如何捕获上下文信息
- 如何使用 Transformer 模型提取上下文向量
- 如何使用上下文向量进行上下文词义消歧
- 如何可视化 Transformer 模型中的注意力模式
想在您的NLP项目中使用强大的语言模型吗?

在您自己的机器上运行最先进的模型
...只需几行Python代码在我的新电子书中探索如何实现
使用 Hugging Face Transformers 进行自然语言处理
它涵盖了在以下任务上的实践示例和实际用例:文本分类、摘要、翻译、问答等等...
最终将高级NLP带入
您自己的项目
没有理论。只有实用的工作代码。






暂无评论。