如何判断你的时间序列问题是否可预测?
对于时间序列预测来说,这是一个棘手的问题。有一个叫做随机游走的工具可以帮助你理解你的时间序列预测问题的可预测性。
在本教程中,你将用Python了解随机游走及其特性。
完成本教程后,您将了解:
- 什么是随机游走,以及如何在Python中从头开始创建它。
- 如何分析随机游走的特性,并识别一个时间序列是否是随机游走。
- 如何为随机游走进行预测。
用我的新书开启你的项目 《Python时间序列预测入门》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019年9月更新:更新了使用最新API的示例。

使用 Python 进行时间序列预测的随机游走简介
照片由 Sam valadi 拍摄,保留部分权利。
随机序列
Python标准库包含 random模块,该模块提供了访问用于 生成随机数 的函数集。
randrange() 函数可用于生成0和上限之间的随机整数。
我们可以使用randrange() 函数生成一个包含1000个介于0到10之间的随机整数的列表。示例如下。
|
1 2 3 4 5 6 7 |
from random import seed from random import randrange from matplotlib import pyplot seed(1) series = [randrange(10) for i in range(1000)] pyplot.plot(series) pyplot.show() |
运行示例将绘制随机数序列。
它真是太混乱了。看起来不像时间序列。
随机序列
这不是随机游走。它只是一系列随机数。
初学者常犯的一个错误是认为随机游走就是随机数列表,而事实并非如此。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
随机游走
随机游走与随机数列表不同,因为序列中的下一个值是序列中前一个值的修改。
用于生成序列的过程强制了从一个时间步到下一个时间步的依赖性。这种依赖性提供了从步到步的一致性,而不是独立的随机数序列所提供的大的跳跃。
正是这种依赖性赋予了该过程“随机游走”或“醉汉的步子”的名称。
随机游走的一个简单模型如下:
- 从-1或1的随机数开始。
- 随机选择-1或1,并将其添加到前一个时间步的观测值中。
- 重复步骤2,直到你喜欢为止。
更简洁地说,我们可以将此过程描述为:
|
1 |
y(t) = B0 + B1*X(t-1) + e(t) |
其中y(t)是序列中的下一个值。B0是一个系数,如果设置为非零值,则会给随机游走增加一个常数漂移。B1是用于加权前一个时间步的系数,设置为1.0。X(t-1)是前一个时间步的观测值。e(t)是该时间点的白噪声或随机波动。
我们可以在Python中通过循环此过程并构建1000个时间步的随机游走列表来实现。完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from random import seed from random import random from matplotlib import pyplot seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) pyplot.plot(random_walk) pyplot.show() |
运行示例将创建一个随机游走的折线图。
我们可以看到它与我们上面的随机数序列非常不同。事实上,其形状和运动看起来像股市证券价格的真实时间序列。
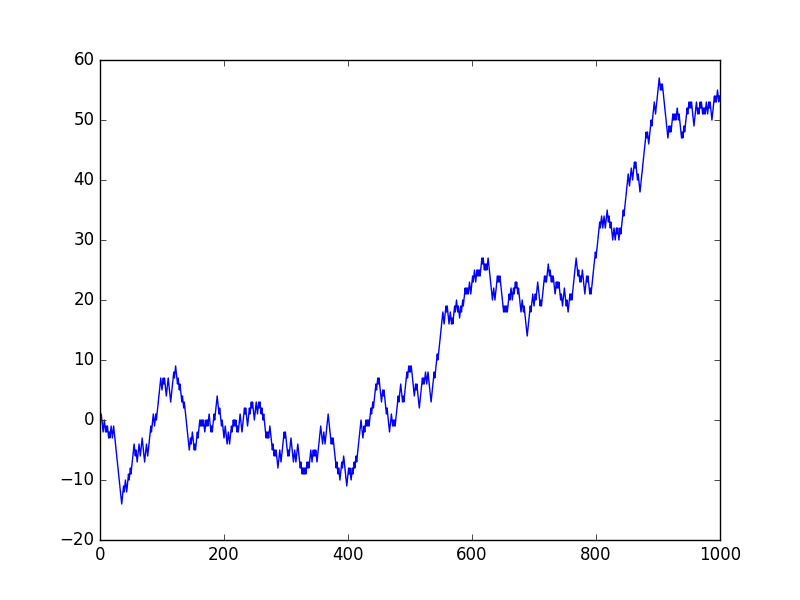
随机游走折线图
在接下来的章节中,我们将仔细研究随机游走的特性。这很有帮助,因为它将为你提供背景信息,帮助你识别未来分析的时间序列是否可能是随机游走。
让我们从考察自相关结构开始。
随机游走与自相关
我们可以计算每个观测值与先前时间步观测值之间的相关性。这些相关性的图称为自相关图或相关图。
鉴于随机游走的构建方式,我们预计它与前一个观测值具有强烈的自相关性,并且随着滞后值的增加,相关性会线性下降。
我们可以使用Pandas中的autocorrelation_plot()函数来绘制随机游走的相关图。
完整的示例如下所示。
请注意,在生成随机游走的每个示例中,我们都使用相同的随机数生成器种子,以确保我们获得相同的随机数序列,从而获得相同的随机游走。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from random import seed from random import random from matplotlib import pyplot from pandas.plotting import autocorrelation_plot seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) autocorrelation_plot(random_walk) pyplot.show() |
运行示例,我们通常会看到预期的趋势,在这种情况下,是跨越前几百个滞后观测值。
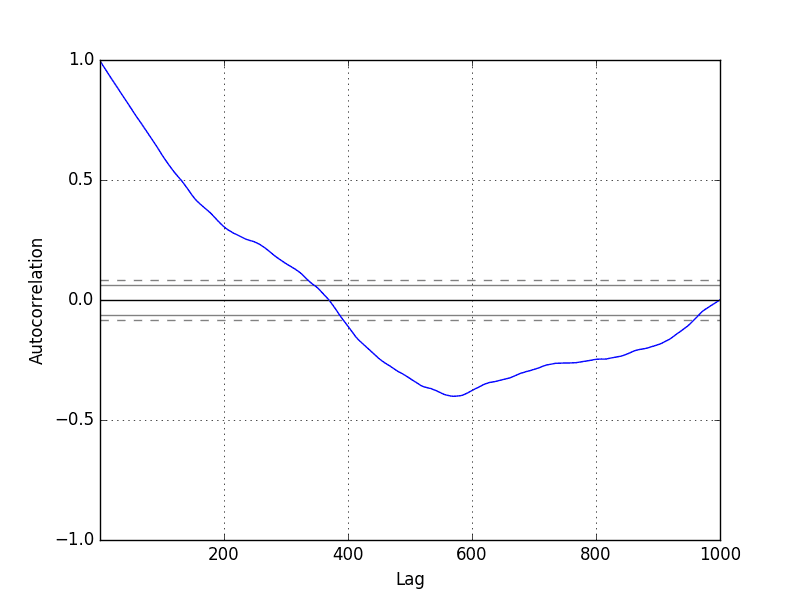
随机游走相关图
随机游走与平稳性
平稳时间序列是指其值不依赖于时间的时间序列。
鉴于随机游走的构建方式以及对自相关性进行审查的结果,我们知道随机游走中的观测值依赖于时间。
当前观测值是前一个观测值的随机步。
因此,我们可以预期随机游走是非平稳的。事实上,所有随机游走过程都是非平稳的。请注意,并非所有非平稳时间序列都是随机游走。
此外,非平稳时间序列的均值和/或方差随时间不恒定。回顾随机游走的折线图可能会暗示这一点。
我们可以使用统计显著性检验来确认这一点,特别是增广迪基-福勒检验。
我们可以使用statsmodels库中的adfuller()函数来执行此测试。完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from random import seed from random import random from statsmodels.tsa.stattools import adfuller # 生成随机游走 seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) # 统计检验 result = adfuller(random_walk) print('ADF Statistic: %f' % result[0]) print('p-value: %f' % result[1]) print('Critical Values:') for key, value in result[4].items(): print('\t%s: %.3f' % (key, value)) |
该检验的零假设是时间序列是非平稳的。
运行示例,我们可以看到检验统计量值为0.341605。这个值大于1%、5%和10%置信水平的所有临界值。因此,我们可以说该时间序列似乎是非平稳的,并且结果是统计偶然的可能性很小。
|
1 2 3 4 5 6 |
ADF统计量:0.341605 p值:0.979175 临界值 5%: -2.864 1%: -3.437 10%: -2.568 |
通过取一阶差分,我们可以使随机游走变得平稳。
也就是说,将每个观测值替换为它与前一个值之间的差值。
鉴于此随机游走的构建方式,我们预计这将产生一个由-1和1值组成的时间序列。这正是我们所看到的。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from random import seed from random import random from matplotlib import pyplot # 创建随机游走 seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) # 计算差分 diff = list() for i in range(1, len(random_walk)): value = random_walk[i] - random_walk[i - 1] diff.append(value) # 线图 pyplot.plot(diff) pyplot.show() |
运行示例会生成一个显示1000个-1和1的移动的折线图,真是太混乱了。
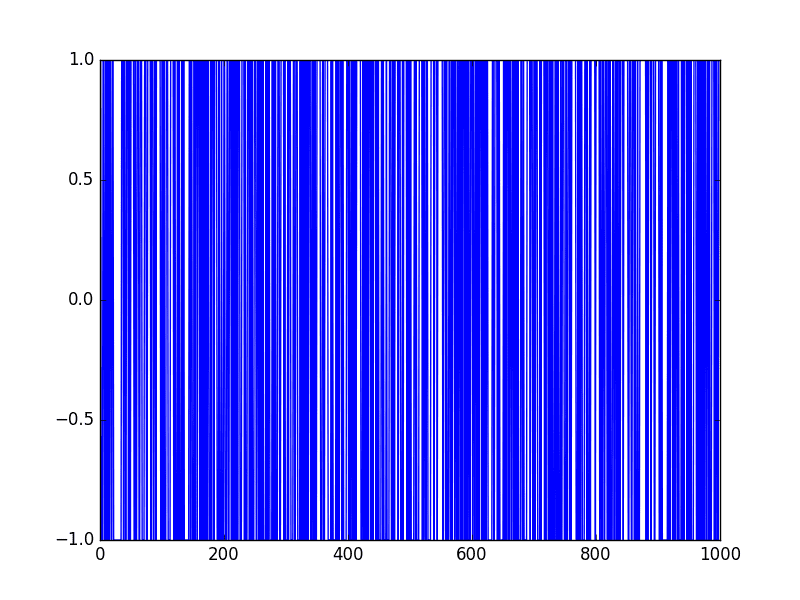
随机游走差分折线图
这张差分图也清楚地表明,我们实际上没有什么信息可供使用,除了一个随机移动序列。
没有可以学习的结构。
现在时间序列已经平稳,我们可以重新计算差分序列的相关图。完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from random import seed from random import random from matplotlib import pyplot from pandas.plotting import autocorrelation_plot # 创建随机游走 seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) # 计算差分 diff = list() for i in range(1, len(random_walk)): value = random_walk[i] - random_walk[i - 1] diff.append(value) # 线图 autocorrelation_plot(diff) pyplot.show() |
运行示例,我们可以看到滞后观测值之间没有显著关系,正如我们从随机游走的生成方式所预期的那样。
所有相关性都很小,接近于零,并且低于95%和99%的置信水平(除了几个统计上的巧合)。
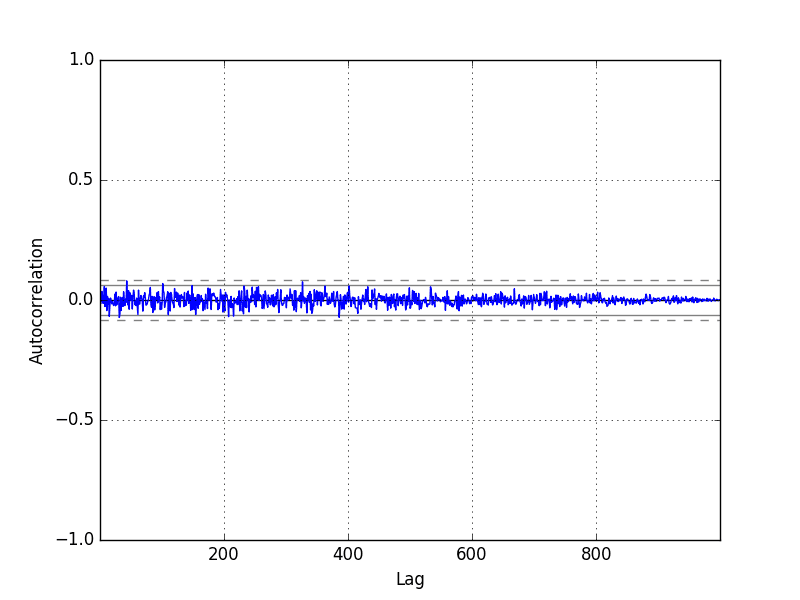
随机游走差分相关图
预测随机游走
随机游走是不可预测的,它无法合理地预测。
鉴于随机游走的构建方式,我们可以预期我们能做出的最佳预测是使用前一时间步的观测值作为下一个时间步将发生的事情。
仅仅因为我们知道下一个时间步将是前一个时间步的函数。
这通常被称为朴素预测,或持续性模型。
我们可以在Python中通过首先将数据集分成训练集和测试集,然后使用持续性模型通过滚动预测方法来预测结果来实现。一旦收集了测试集的所有预测,就计算均方误差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from random import seed from random import random from sklearn.metrics import mean_squared_error # 生成随机游走 seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) # 准备数据集 train_size = int(len(random_walk) * 0.66) train, test = random_walk[0:train_size], random_walk[train_size:] # 持续性 predictions = list() history = train[-1] for i in range(len(test)): yhat = history predictions.append(yhat) history = test[i] error = mean_squared_error(test, predictions) print('Persistence MSE: %.3f' % error) |
运行示例,模型均方误差估计为1。
这也符合预期,因为我们知道从一个时间步到下一个时间步的变化总是1,无论是正向还是负向,而这个预期误差的平方是1(1^2 = 1)。
|
1 |
持续性 MSE:1.000 |
初学者在随机游走方面犯的另一个错误是假设,如果误差范围(方差)是已知的,那么我们就可以使用随机游走生成过程来进行预测。
也就是说,如果我们知道误差是-1或1,那么为什么不通过将随机选择的-1或1加到前一个值上来进行预测呢?
我们可以在下面的Python中演示这种随机预测方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from random import seed from random import random from sklearn.metrics import mean_squared_error # 生成随机游走 seed(1) random_walk = list() random_walk.append(-1 if random() < 0.5 else 1) for i in range(1, 1000): movement = -1 if random() < 0.5 else 1 value = random_walk[i-1] + movement random_walk.append(value) # 准备数据集 train_size = int(len(random_walk) * 0.66) train, test = random_walk[0:train_size], random_walk[train_size:] # 随机预测 predictions = list() history = train[-1] for i in range(len(test)): yhat = history + (-1 if random() < 0.5 else 1) predictions.append(yhat) history = test[i] error = mean_squared_error(test, predictions) print('Random MSE: %.3f' % error) |
运行示例,我们可以看到该算法的性能确实比持续性方法差,均方误差为1.765。
|
1 |
随机 MSE:1.765 |
对于随机游走时间序列,持续性或朴素预测是我们能做的最佳预测。
你的时间序列是随机游走吗?
你的时间序列可能是随机游走。
检查你的时间序列是否为随机游走的一些方法如下:
- 时间序列显示出强烈的时间依赖性,这种依赖性以线性或类似模式衰减。
- 时间序列是非平稳的,使其平稳后,数据中没有明显可学习的结构。
- 持续性模型提供了最可靠的预测来源。
最后一点是时间序列预测的关键。使用持续性模型进行的基线预测可以快速确定你是否能做得更好。如果你不能,你可能正在处理一个随机游走。
许多时间序列是随机游走,特别是随时间变化的证券价格。
随机游走假说是一个关于股票市场价格是随机游走且无法预测的理论。
随机游走是指未来步长或方向无法根据过去历史预测。当该术语应用于股票市场时,它意味着股票价格的短期变化是不可预测的。
— 第26页,《随机游走华尔街:成功的投资的久经考验的策略》
人脑无处不见模式,我们必须警惕,不要自欺欺人,浪费时间为随机游走过程开发复杂的模型。
进一步阅读
如果你想深入了解随机游走,以下是一些进一步的资源。
- 《随机游走华尔街:成功的投资的久经考验的策略》
- 《醉汉的散步:随机性如何主宰我们的生活》
- 第7.3节 可预测性评估,《R语言时间序列预测实用指南》
- 第4.3节 随机游走,《R语言入门时间序列》。
- 随机游走(维基百科)
- Robert F. Nau 的 随机游走模型
总结
在本教程中,你了解了如何用Python探索随机游走。
具体来说,你学到了:
- 如何在Python中创建随机游走过程。
- 如何探索随机游走的自相关和非平稳结构。
- 如何为随机游走时间序列进行预测。
你对随机游走或本教程有任何疑问吗?
请在下面的评论中提出您的问题。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






期待这本书。🙂
谢谢Nader。
非常有趣,谢谢!能否在SAS或R代码中找到相同的代码?
提前感谢!
很高兴你觉得有趣,Doumbia。
抱歉,我没有R或SAS的随机游走示例。
这真是一篇很棒的文章!祝贺 & 谢谢!
谢谢daniel。
太棒了!非常感谢。
谢谢Eddmond。
y(t) = B0 + B1*X(t-1) + e(t)
有点糊涂。难道不应该是
y(t) = B0 + B1*y(t-1) + e(t)
是的,一样的。我习惯于从监督学习的角度来表述问题,抱歉。
信息丰富的帖子!
谢谢
谢谢Samih。
非常有趣。做得好!
谢谢Fabio。
是的,就像Nader一样,我期待着这本书。感谢您的见解。
谢谢K. W. Famolu。
很棒的文章。事实上,它将帮助许多像我一样(没有硬核统计/数学背景)试图学习时间序列分析和预测的人。
谢谢Jason。非常感激。
不客气Aninda,很高兴听到这个!
我听说股票数据总是随机游走,所以只做一些评论。它看起来很像随机游走,而且如果涉及的特征不够,简单的次日预测可能就是这样。
如果有人足够长时间地观察过股票数据,就会知道那些断点、轧空、止损等都会导致典型的模式,这些模式可以保持为随机游走,但绝对不是。而且至少即使是一些“下一个”的日值,也可以被神经网络很好地学习,比如一个LSTM模型,尽管这可能或多或少地被每个值内部的记忆所学习。总之,这是一个不错的训练集拟合。
http://pvoodoo.blogspot.com/2017/01/expected-aimlnn-results.html
感谢您的评论,Marko。
有趣的问题。
但如果训练和测试的种子相同,我认为这对于随机游走问题来说还不够好。
我期待关于它的其他报告。
谢谢你
Jason,您好,这篇文章信息量很大,很有趣。我同意一些时间序列是随机游走的,尤其是金融工具的价格,我actually 正在尝试构建一个模型来玩玩,我看了您关于 Keras 预测时间序列的一篇文章,我尝试的唯一前提是,“随机只不过是当前技术或方法无法计算的变量的复杂计算,因此是不可预测的”。到目前为止,我可以获得高达一个标准差的收敛,样本外预测偏差太大,没有用。谢谢
祝您的项目好运!
先生,感谢您的教程。您是否愿意制作一个关于通过深度神经网络模型进行精子细胞检测的教程,并在此类模型上进行训练?如果您有这方面的内容,请分享链接。谢谢!
ADF统计量:0.341605
p值:0.979175
临界值
5%: -2.864
1%: -3.437
10%: -2.568
p值和检验统计量表明我们拒绝H0(单位根,非平稳),并接受备择假设(平稳)。您说的正好相反,我有点困惑。
你确定吗?
我说的是序列不平稳(例如,拒绝 H0)。
Jason 你好,这是我使用你的方法分析我的时间序列的输出,
ADF 统计量:-21.866782
p值:0.000000
临界值
1%: -3.430
5%: -2.862
10%: -2.567
我的时间序列是随机游走吗?
该测试仅评论您的数据是否平稳。
从这个结果来看,您的数据看起来是平稳的。
我能得出结论我的时间序列不是随机游走吗?
如果您能通过预测模型做得比持续性模型更好。
你好 Jason,
感谢您精彩的教程,它们真的非常有帮助。
我想问您是否有一种方法可以从我们的数据中去除随机游走(我知道数据要么是随机游走,要么不是,但也许可以使其随机性降低等等)或者任何类似的东西?
提前感谢。
据我所知,没有。
Jason 你好。感谢您的有益帖子。
我现在知道如何生成随机游走序列,但我想知道如果我有一个遵循随机游走模型的时间序列,我该如何预测其未来的数值。
提前感谢。
也许可以查看 ACF/PACF 图并确认没有相关性。
还可以尝试建模并确认没有模型能够优于持续性预测。
嗨,Jason,
对于随机游走,需要多少个数据点才能进行统计检验?例如,如果我处理涉及患者的时间序列,其中每位患者大约有 8 个时间步长,那么我是否需要查看每位患者的随机游走,或者如何将它们结合起来,因为每位患者可能有不同的趋势?
好问题,不确定。超过 8 个,也许 30+。
当我们查看不同的患者时,这与为多个站点进行预测相同吗?在一个链接中
https://machinelearning.org.cn/faq/single-faq/how-to-develop-forecast-models-for-multiple-sites/
您在那里给出了一些建议。
您是否有任何帖子或示例解释了这种多站点预测,例如如何进行分组或混合方法等?
抱歉,没有,我认为这会因您的数据集而异。
随机游走数据会变为负值。您建议如何处理这种情况?并非所有股票价格都会出现负值。许多其他数据也不会出现负值。
它不是股票价格的模型,而是一个随机游走的模拟示例。
股票价格的短期波动是随机游走的另一个例子。
嗨,Jason,
我有多于 100 个特征和 1 个输出变量(分类)的问题,我正尝试使用 LSTM 来解决。即使我的特征是时间序列,分类决策也是使用一组不同的参数来完成的。
当我们有多个输入特征和 3 个可能的输出类别时,是否需要验证随机游走?如果是,您是否有像本教程这样针对这种情况的教程,因为它涉及回归?
提前感谢您的帮助。
我忘了提,这是一个时间序列分类问题。
如果您有输出类别,听起来像是一个时间序列分类问题。
也许可以先从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
#随机游走
Jason 你好,我正在阅读您的书,但在用我的数据替换您代码中的时间序列示例数据时遇到了困难。如何替换您的示例代码而不破坏它。假设我的时间序列数据源名为“series”。
谢谢
-Gonzalo
你到底遇到了什么问题?
嗨,Jason,
精彩的帖子!
具有随时间变化的漂移分量(例如 B0(t) != 常数,即分段常数)的情况如何?您将如何分析这类过程?
您在书中是否涵盖了这些问题?
来自维也纳的健康问候
Bernd
好问题。抱歉,我没有更多关于分析随机游走的内容。本教程仅旨在介绍该概念。
要深入研究,我建议参考“进阶阅读”部分列出的参考资料。
嗨,Jason,
非常好的帖子!关于异常值呢?例如,在销售量预测中,单个客户可以购买大量商品,并突然增加从一周到另一周的销量。此类异常值可能会决定一个信号是否可以预测,并最终胜过朴素预测。
您如何处理时间序列数据中的异常值?将极端值截断会是好方法吗?
此致,
Rudiger
好问题。
是的,您可以尝试删除、忽略、截断等异常值,然后看看哪种方法最适合您选择的模型和数据集。
history = train[-1]
for i in range(len(test))
yhat = history
predictions.append(yhat)
history = test[i]
您实际上是将测试数据添加到预测中,但有一个滞后,因为您使用最后一个训练值开始预测。
当您使用相同但移动过的测试数据时,这如何成为预测?
谢谢,
peter
是的,这被称为前向验证,是评估时间序列预测模型的标准方法,您可以在这里开始了解这些想法
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
感谢您清晰明了的解释。但是,随机游走差分自相关图应该在零滞后处显示值为 1.0 吗?话虽如此,我并不熟悉 Python 编程,所以我不知道您显示的内容是否与一阶差分随机游走序列的自相关函数相同。
是的,随机游走中 t-1 的相关性是 1.0。
我关注您所有的帖子。您做出了差异。感谢您分享这个精彩的指南。
谢谢。
您在教程中曾使用过加州每日女性出生总数的时间序列。我正在处理这个序列,我想知道这是否是随机游走序列。
我不这么认为,因为我们可以在该数据集上做出良好的预测。
感谢您提供有价值的教程。我已使用本教程中的方法来找出我的时间序列数据是否为随机游走。结果表明我的时间序列是随机游走。众所周知,当时间序列是随机游走时,您不能使用深度学习进行时间序列预测。在这种情况下,我们除了深度学习预测还有什么选择?
如果您的数据是随机游走,您就无法预测。您最好的选择是持续性模型。
嗨,Jason,
我有一个序列,其中 AD Fuller 检验的 p 值为 1。我取了该序列的 1 阶差分,该序列的 p 值为 0.7,这仍然表明是非平稳的。这是否意味着我正在处理的序列不是随机游走?如果是,如何检测它是什么?
谢谢,此致,
Sanjeet
Sanjeet 你好…以下资源可能有助您更清楚地了解
https://www.machinelearningplus.com/time-series/augmented-dickey-fuller-test/
嗨,Jason,
我对预测部分有点困惑,您假设最新的预测可以用于下一步预测。这个预测只是为了预测一个时间步长,但如果我们想预测一年呢?我认为最新的观测值将被用作恒定的预测。
Habib 你好…你说得对,这个区别很重要,需要澄清。
**随机游走模型**是一种简单的统计方法,它假设下一个时间步的最佳预测是最近的观测值。这种方法可以扩展到更长的预测范围,但它本身基于最近的观测值足以代表未来趋势的假设。
### 单步预测 vs. 多步预测
1. **单步预测:**
– 对于超前一步的预测,随机游走使用最近的观测值 \( y_t \) 作为下一个时间步 \( y_{t+1} \) 的预测。
2. **多步预测(例如,一年):**
– 如果我们想预测多个时间步(例如,一年,假设月度数据,这将是 12 个时间步),随机游走模型假设最后一个观测值被用作所有未来步骤的预测
\[
\hat{y}_{t+h} = y_t, \, \forall h \geq 1
\]
– 在这里,\( \hat{y}_{t+h} \) 是 \( t+h \) 步的预测值,而 \( y_t \) 是最后一个观测值。
这就是为什么在随机游走预测中
– 一步预测是 \( y_{t+1} = y_t \)。
– 两步预测是 \( y_{t+2} = y_t \),依此类推。
本质上,随机游走假设没有趋势、季节性或额外信息,将最近的值视为所有未来点的最可靠猜测。
### 长期预测的局限性
– **平稳性假设:** 随机游走假设平稳性(没有潜在的趋势或季节性)。在长远来看,这个假设可能失效,导致预测不准确。
– **缺乏动态特征:** 该模型不考虑季节性、趋势或自回归行为等模式,这可能使其在长期预测中的准确性较低。
### 长期预测的替代方案
如果您想预测一年,最好考虑以下模型,例如
– **自回归积分移动平均 (ARIMA):** 包含趋势和季节性。
– **时间序列季节性分解 (STL):** 分离和预测季节性成分。
– **机器学习模型:** 例如 LSTM 或 XGBoost,它们可以处理更复杂的模式。