XGBoost 是一种算法,最近在结构化或表格数据的应用机器学习和 Kaggle 竞赛中占据主导地位。
XGBoost 是梯度提升决策树的一种实现,旨在提高速度和性能。
在这篇文章中,您将了解 XGBoost,并对其是什么、起源以及如何进一步学习进行温和的介绍。
阅读本文后,您将了解
- XGBoost 是什么以及该项目的目标。
- 为什么 XGBoost 必须成为您机器学习工具包的一部分。
- 在哪里可以学习更多,以便在您的下一个机器学习项目中使用 XGBoost。
通过我的新书《XGBoost With Python》启动您的项目,其中包括所有示例的分步教程和 Python 源代码文件。
让我们开始吧。
- 2021年2月更新:修复了失效链接。

应用机器学习 XGBoost 简明介绍
照片由 Sigfrid Lundberg 拍摄,保留部分权利。
在 Python 中使用 XGBoost 需要帮助吗?
参加我的免费 7 天电子邮件课程,探索 xgboost(含示例代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
什么是 XGBoost?
XGBoost 代表 eXtreme Gradient Boosting(极致梯度提升)。
然而,xgboost 这个名字实际上指的是工程目标,即突破提升树算法计算资源的极限。这就是许多人使用 xgboost 的原因。
—— 陈天奇,在 Quora 回答“R gbm(梯度提升机)和 xgboost(极致梯度提升)有什么区别?”这个问题时说
它是 陈天奇 创建的梯度提升机的一种实现,现在有许多开发人员贡献。它属于分布式机器学习社区或 DMLC 旗下更广泛的工具集合,DMLC 也是流行的 mxnet 深度学习库的创建者。
陈天奇在帖子 XGBoost 演变背后的故事和经验教训中提供了 XGBoost 创建的简短而有趣的故事。
XGBoost 是一个软件库,您可以下载并安装到您的机器上,然后通过各种接口访问。具体来说,XGBoost 支持以下主要接口:
- 命令行界面 (CLI)。
- C++(库编写的语言)。
- Python 接口以及 scikit-learn 中的模型。
- R 接口以及 caret 包中的模型。
- Julia。
- Java 和 JVM 语言,如 Scala 和 Hadoop 等平台。
XGBoost 特性
该库专注于计算速度和模型性能,因此功能不多。尽管如此,它确实提供了一些高级功能。
模型特性
模型的实现支持 scikit-learn 和 R 的功能,并新增了正则化等功能。支持三种主要的梯度提升形式:
- 梯度提升算法,也称为梯度提升机,包括学习率。
- 随机梯度提升,在行、列和每分裂列级别进行子采样。
- 正则化梯度提升,同时使用 L1 和 L2 正则化。
系统特性
该库提供了一个可在各种计算环境中使用 的系统,尤其是:
- 在训练期间利用所有 CPU 核心进行树构建的并行化。
- 使用机器集群训练超大型模型的分布式计算。
- 针对无法完全加载到内存中的超大型数据集的核外计算。
- 数据结构和算法的缓存优化,以充分利用硬件。
算法特性
算法的实现是为了计算时间和内存资源的效率而设计的。设计目标是最大限度地利用可用资源来训练模型。一些关键的算法实现特性包括:
- 稀疏感知实现,自动处理缺失数据值。
- 块结构支持树构建的并行化。
- 持续训练,以便您可以在新数据上进一步提升已拟合的模型。
XGBoost 是免费开源软件,可在宽松的 Apache-2 许可下使用。
为什么要使用 XGBoost?
使用 XGBoost 的两个原因也是该项目的两个目标:
- 执行速度。
- 模型性能。
1. XGBoost 执行速度
通常,XGBoost 很快。与梯度提升的其他实现相比,它真的很快。
Szilard Pafka 进行了一些客观基准测试,比较了 XGBoost 与其他梯度提升和袋装决策树实现的性能。他在 2015 年 5 月的博文“基准测试随机森林实现”中撰写了他的结果。
他还提供了所有 GitHub 上的代码以及更详细的带有具体数字的结果报告。
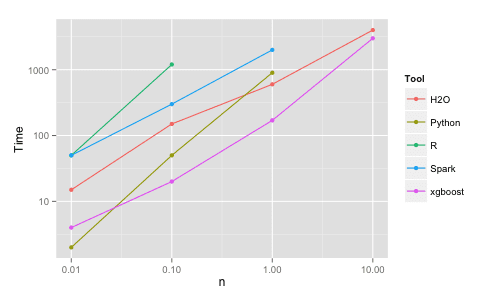
XGBoost 的基准性能,摘自基准测试随机森林实现。
他的结果表明,XGBoost 几乎总是比 R、Python Spark 和 H2O 的其他基准测试实现更快。
在他的实验中,他评论道:
我还尝试了 xgboost,这是一个流行的提升库,也能够构建随机森林。它速度快,内存效率高,精度高。
— Szilard Pafka,《基准测试随机森林实现》。
2. XGBoost 模型性能
XGBoost 在分类和回归预测建模问题上主导结构化或表格数据集。
证据是,它是 Kaggle 竞争数据科学平台上竞赛获胜者的首选算法。
例如,这里有一个不完整的、使用 XGBoost 获得第一、第二和第三名的竞赛获奖者列表,标题是:XGBoost:机器学习挑战获奖解决方案。
为了使这一点更具体,下面是一些来自 Kaggle 竞赛获胜者的深刻引言:
作为越来越多 Kaggle 竞赛的获胜者,XGBoost 再次向我们展示了它是一种值得拥有在您的工具箱中的出色全能算法。
—— Dato 获奖者访谈:第一名,Mad Professors
有疑问时,请使用 xgboost。
我喜欢表现出色的单一模型,我最好的单一模型是 XGBoost,它本身可以获得第 10 名。
我只使用了 XGBoost。
—— Liberty Mutual Property Inspection,获奖者访谈:第一名,Qingchen Wang
我唯一使用的有监督学习方法是梯度提升,由出色的 xgboost 包实现。
—— Recruit Coupon Purchase 获奖者访谈:第二名,Halla Yang
XGBoost 使用什么算法?
XGBoost 库实现了梯度提升决策树算法。
此算法有许多不同的名称,例如梯度提升、多元加性回归树、随机梯度提升或梯度提升机。
提升是一种集成技术,其中添加新模型以纠正现有模型所犯的错误。模型按顺序添加,直到无法再进行改进。一个流行的例子是AdaBoost 算法,它对难以预测的数据点进行加权。
梯度提升是一种方法,其中创建新模型来预测先前模型的残差或误差,然后将它们相加起来进行最终预测。它之所以被称为梯度提升,是因为它使用梯度下降算法在添加新模型时最小化损失。
这种方法支持回归和分类预测建模问题。
有关提升和梯度提升的更多信息,请参阅 Trevor Hastie 关于梯度提升机器学习的演讲。
官方 XGBoost 资源
关于 XGBoost 的最佳信息来源是该项目的官方 GitHub 仓库。
一个包含示例代码和帮助的优秀链接来源是精彩的 XGBoost 页面。
还有一个官方文档页面,其中包含适用于各种不同语言的入门指南、教程、操作指南等。
还有一些关于 XGBoost 的更正式的论文,值得一读,以获取更多关于该库的背景信息:
- 使用增强树发现希格斯玻色子, 2014.
- XGBoost:一个可扩展的树形增强系统, 2016.
关于XGBoost的演讲
当开始使用像 XGBoost 这样的新工具时,在深入研究代码之前,回顾一些关于该主题的演讲会很有帮助。
XGBoost:一个可扩展的树形增强系统
该库的创建者陈天奇于 2016 年 6 月在洛杉矶数据科学小组做了一次题为“XGBoost:一个可扩展的树形增强系统”的演讲。
您可以在此处查看他的演讲幻灯片
DataScience LA 博客上还有更多信息。
XGBoost:极致梯度提升
XGBoost R 接口的贡献者 Tong He 于 2015 年 12 月在纽约数据科学学院发表了题为“XGBoost:极致梯度提升”的演讲。
您可以在此处查看他的演讲幻灯片
纽约数据科学学院博客上还有更多关于这次演讲的信息。
安装 XGBoost
XGBoost 文档网站上提供了全面的安装指南。
它涵盖了 Linux、Mac OS X 和 Windows 上的安装。
它还涵盖了 R 和 Python 等平台上的安装。
R 中的 XGBoost
如果您是 R 用户,最好的入门点是 xgboost 包的 CRAN 页面。
从该页面可以访问 R 小插曲包 'xgboost' [pdf]。
此页面还链接了一些优秀的 R 教程,可帮助您入门:
- 发现您的数据
- XGBoost 演示
- xgboost:极致梯度提升 [pdf]
还有官方的XGBoost R 教程和使用 XGBoost 理解您的数据集教程。
Python 中的 XGBoost
安装说明可在 XGBoost 安装指南的 Python 部分中找到。
官方的 Python 包介绍是使用 Python 中的 XGBoost 时最好的起点。
要快速开始,您可以键入
|
1 |
sudo pip install xgboost |
在 XGBoost Python 功能演练中,还有一个出色的 Python 示例源代码列表。
总结
在这篇文章中,您发现了用于应用机器学习的 XGBoost 算法。
您学到了
- XGBoost 是一个用于开发快速高性能梯度提升树模型的库。
- XGBoost 在一系列困难的机器学习任务中取得了最佳性能。
- 您可以使用命令行、Python 和 R 来使用此库,并了解如何开始。
您使用过 XGBoost 吗?在下面的评论中分享您的经验。
您对 XGBoost 或这篇文章有什么问题吗?在下面的评论中提出您的问题,我将尽力回答。
发现赢得竞赛的算法!

在几分钟内开发您自己的 XGBoost 模型
...只需几行 Python 代码
在我的新电子书中探索如何实现
使用 Python 实现 XGBoost
它涵盖了自学教程,例如:
算法基础、缩放、超参数等等……
将 XGBoost 的强大功能带入您自己的项目
跳过学术理论。只看结果。






好信息,谢谢。只有一个问题。
gbm 与其最大的区别是归一化吗?
gbm 不进行归一化,但 xgboost 自动归一化变量并自动处理缺失值?我理解对了吗?
最大的区别是性能,而不是归一化。
我在 R 上运行了 xgboost。
然而,我发现输入值不能以因子形式执行。
对于 gbm,可以使用因子类型变量。
在这方面,xgboost 似乎有一些缺点。
您必须将分类变量转换为整数编码或独热编码。
强制将分类变量视为连续变量可以吗?
这取决于变量。如果变量是序数,可能说得通。如果不是,独热编码将是首选方法。
这似乎是您正在使用的xgboost实现的一个限制,而不是算法本身的限制。
xgboost 中决策树的单调性约束参考?
抱歉,我没有。
您能告诉我 XGBoost 是否也可以用于无监督学习——大型数据集的聚类吗?
如果可以,XGBoost 是否比其他无监督算法(如 K 均值聚类、DBSCAN 等)更具优势?
据我所知不是。梯度提升是一种监督学习算法。
Jason,我很想知道如何执行重复交叉验证以超参数调整模型参数。我使用 caret 包,它比在同一德国信用数据集上训练其他模型类型(如 ranger、gbm、glmnet)花费的时间长 20-30 倍。
它一直被吹捧为极快,但我没有观察到,而且我找到的大多数教程都采用了 caret。
谢谢你的建议,佩特罗斯。
你好 Jason,
您有没有尝试过安装和使用微软的 LightGBM?据说它比 XGBoost 更好更快。
我还没有,也许将来会尝试。
是的,XGboost 太棒了。一年前我创建了一个免费的在线课程,教你如何在 Python 中高效使用它——http://education.parrotprediction.teachable.com/p/practical-xgboost-in-python
酷,谢谢你的参考 Norbert。那也是我发布关于这个主题的书的时候。
下午好,关于 xgboost 不支持分类变量的事实,我在 caret 中用 xgbtree 和因子变量训练了以下模型,没有遇到任何问题(一个变量作为示例)。我做错了什么吗?
pase0.xgbTree_x=train(as.factor(PASE)~TIPO_CLIENTE,data=pase0,trControl=trainControl(method=’repeatedcv’,number=5,repeats=10,verboseIter = TRUE),method=’xgbTree’,allowParallel=TRUE,tuneGrid=xgb.tuning)
分类变量是 TIPO_CLIENTE
抱歉,我无法帮助您解决 R 中的 xgboost 问题。
您好,Brownlee 博士,有没有办法将我们所有的预测都放入测试数据集中,并将模型的预测作为测试数据集中的一列。我关心的是在这种情况下实例的顺序如何保留(即,与某个实例对应的预测应该与该实例在同一行)。您能对此问题提供一些见解吗?
谢谢!
输入的顺序将与输出的顺序匹配。
不确定这里是否合适,如果不合适请随意删除……但我只是想给您发个便条,感谢您的网站……每当它出现在搜索中(经常出现)时,我就知道我会获得一些高质量的信息。
谢谢你,布雷特,我真的很感激你的好意!
Jason,只想感谢您所做的一切精彩工作!您的文章是网上最好的文章之一!
谢谢 IanDz,我非常感谢您的支持!
Jason,
当您传递附加参数——训练集(或其子集)和标签时,Xgb 重要性输出除了 Gain、Cover 和 Frequency 之外,还包括 Split、RealCover 和 RealCover%。
虽然 Split 值可以理解,但您能帮助理解/解释只针对特定特征出现的 RealCover 和 RealCover% 吗?
此外,在这种扩展输出中,xgboost 重要性表中的条目数量应该从何种意义上推导出来?
谢谢
此文档更好地解释了该表
https://docs.xgboost.com.cn/en/latest/R-package/discoverYourData.html#feature-importance
我们可以将 XGBoost 应用于多标签分类问题吗?
请回复我。我正在研究多标签分类的基于树的方法。
也许吧。抱歉,我没有多标签预测的任何示例。我希望将来能涉及这个问题。
告诉我它是否适用于多标签分类。
也许吧,我不知道。
我认为您可以根据您的要求将目标函数设置为以下任何一个(来自 xgboost 文档:https://docs.xgboost.com.cn/en/latest/parameter.html)
multi:softmax: 设置 XGBoost 使用 softmax 目标进行多类分类,您还需要设置 num_class(类数)
multi:softprob: 与 softmax 相同,但输出一个 ndata * nclass 的向量,可以进一步重塑为 ndata * nclass 矩阵。结果包含每个数据点属于每个类的预测概率。
大家好
我非常想知道 Xgb 如何在学习(例如智能辅导——为用户选择合适的知识上下文)背景下使用。
我是这个领域的新手,但非常渴望将 AI 应用于学习。
我看到的一种方法是使用对话来了解已知和未知,以及需要了解什么。
期待您的专家提供提示和建议
首先将您的问题明确定义为监督学习问题,然后应用 xgboost。这个框架会有帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
我看到需要对因子变量进行独热编码。然而,在我的 R 实现中,当我包含因子时,XGBoost 在没有任何错误或警告消息的情况下执行。算法是否忽略这些变量?
我认为 R 会自动处理这些因子。
不,它们没有被忽略。
你好
我想知道在二分类情况下使用哪种方法最好:xgboost 还是带梯度下降的逻辑回归,以及为什么
非常感谢你
这是无法预知的。您必须测试一系列方法,并发现哪种方法最适合特定数据集。
所有的花里胡哨都具备,但算法的核心部分却呈现得极其糟糕。简直难以置信这在谷歌上能排第二。
很抱歉听到这个消息,托马斯。
你认为具体缺少什么?你希望看到什么?
两个主要观点
1) 比较 XGBoost 和 Spark Gradient Boosted Trees 使用单个节点是不正确的。Spark GBT 专为多计算机处理而设计,如果您添加更多节点,处理时间会显著缩短,而 Spark 管理集群。XGBoost 可以在分布式集群上运行,但是在 Hadoop 集群上。
2) XGBoost 和梯度提升树是基于偏差的。它们也减少方差,但不如基于方差的模型(如随机森林)好,所以当您处理 Kaggle 数据集时,XGBoost 表现良好,但当您处理真实世界和数据流问题时,随机森林是一个更稳定的模型(稳定性体现在处理数据流中经常出现的高方差数据)。
谢谢。
感谢您补充信息。但是,Kaggle 中的所有数据集不都是真实世界中的吗?
哪些数据集与随机森林相比在 XGBoost 中会更稳定?
我想是的。
表格数据通常最好用 xgboost 解决,而不是神经网络或其他方法。
先生,我可以知道 xgboost 的缺点吗?
好问题。
它可能会很慢。
它可能会创建一个复杂的模型。
…
嗨,感谢您这篇非常清晰的帖子!
只是想确认我理解得对:如果速度不是问题,xgboost 不会比经典的随机森林带来更多东西,对吗?
不,它是一种不同的算法,称为随机梯度提升,它在性能(技能)和速度方面都优于其他实现。
感谢您的这篇文章。是否可以使用 XGBOOST 分解因变量,就像线性模型中的系数乘以变量一样?
不完全是,不是。
尊敬的Jason博士,
在您的某个“速成课程”中,当使用“Pima 印第安人糖尿病发病数据集上的学习率”演示时,“piped”版本的 xgboost 崩溃了。
定义:“pipped”指的是 pip install –upgrade xgboost。
解决方案:虽然该解决方案对我有用,但我不能保证如果您的 xgboost 崩溃了它也会对您有用。这是为了从 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 获取 *.whl 版本。搜索 xgboost 并获取适合特定 Python 版本以及您使用的是 32 位还是 62 位 Python 解释器的 *.whl 文件。
例如,Python v3.6 和 64 位版本的直接链接是 https://download.lfd.uci.edu/pythonlibs/t7epjj8p/xgboost-0.90-cp36-cp36m-win_amd64.whl
然后,在您的命令窗口中,您说
谢谢你,
悉尼的Anthony
感谢分享。
一些研究论文使用 xgboost 进行特征工程,是否可以在研究论文中将其仅用作增强其他分类器方法预测的算法?
您可以随意使用 xgboost,例如用于特征选择。
至于在研究论文中描述其用途,我无法置评。
嗨,Jason,
感谢您撰写本文。我有一个疑问一直未能澄清,即使在尝试阅读xgboost的原始论文之后。像Adaboost一样,XGB也会为后续模型对每个样本进行不同的加权吗?
我相信是这样。这是“提升”的关键。
恕我直言,“..必须是您的一部分…”而不是“分开”
谢谢!已修复。
杰森,您能解释一下在这种情况下“结构化或表格数据”是什么意思吗?与……相对的。
XGBoost 适用于时间序列吗?
非常感谢您所有的优秀资料。
电子表格中的数据。一个数据表。
是的,如果我们将时间序列数据转换为表格数据,xgboost 可以用于时间序列。这是一个示例:
https://machinelearning.org.cn/xgboost-for-time-series-forecasting/
xgboost 是判别模型吗?
是的,因为您向它提供数据而不是它为您生成数据。
您好,关于我们是否可以在多实例分类中使用它有什么想法吗?例如,如果我们的数据集包含多个系统,并且每个系统都有多行。
或者您会推荐使用不同的方法吗?如果是,是什么方法?
提前感谢。
谢谢!您是否有,或者能引导我,了解 XGBoost 直觉/原理的通用介绍,以及它与其他方法有何不同?我并不真正寻找具体的编码示例,更多的是关于它如何在不同情况下应用的示例。例如,线性回归与 XGBoost 回归有何不同以及为何不同。我看到许多应用性的东西,但很少有关于直觉的。我正在寻找的是能够让我根据我对模型工作原理等的知识,将 XGBoost 包应用于我的问题(无论它可能是什么)的东西。尽管我有数学和统计学背景,但这并不是我真正想要的。但我希望直观地理解正在发生的事情 🙂
嗨,托马斯……您可能会发现以下讨论很有趣
https://www.kaggle.com/general/196541
我尝试将 XGBoost 分类器 (XGBC) 和随机森林分类器 (RFC) 应用于同一份 Pima-Indians-Diabetes 数据,并进行数据插补以消除缺失值接近 50% 的特征。在消除“test”特征(缺失数据接近 50%)后,RFC 的 MAE 低于 XGBC。然而,当我根据原始数据的一行测试预测时,RFC 错误分类了它,而 XGBC 正确预测了它。这是模型“不准确”的一部分,还是 MAE 不足以让我们选择要使用的模型?我只是想知道……感谢您的反馈。谢谢。
嗨,罗米……以下资源可能对调整您的 XGBoost 模型有所帮助
https://machinelearning.org.cn/tune-xgboost-performance-with-learning-curves/
这是一篇很棒的帖子。内容全面而又简洁。谢谢!
非常欢迎您,彭孙!我们感谢您的反馈和支持!